
Generative Engine Optimization (GEO)
Erfahren Sie, was Generative Engine Optimization (GEO) ist, wie es sich von SEO unterscheidet und warum es für die Sichtbarkeit von Marken in KI-basierten Suchm...
11 Min. Lesezeit

Entdecken Sie bahnbrechende akademische Forschung zur Generative Engine Optimization (GEO), darunter die Aggarwal et al. KDD-Studie, den GEO-bench-Benchmark und praktische Auswirkungen auf die Sichtbarkeit in der KI-Suche.
Der Aufstieg generativer, KI-gestützter Suchmaschinen hat die Landschaft des digitalen Marketings grundlegend verändert und akademische Forscher dazu veranlasst, neue Rahmenwerke zum Verständnis und zur Optimierung der Sichtbarkeit von Inhalten in diesem aufkommenden Paradigma zu entwickeln. Generative Engine Optimization (GEO) entstand 2024 als formale akademische Disziplin mit der Veröffentlichung des wegweisenden Papers “GEO: Generative Engine Optimization” von Pranjal Aggarwal, Vishvak Murahari und Kollegen von der Princeton University und dem Indian Institute of Technology Delhi, das auf der renommierten KDD-Konferenz (Knowledge Discovery and Data Mining) vorgestellt wurde. Diese grundlegende Forschung definierte GEO offiziell als Black-Box-Optimierungsrahmen, der Content-Ersteller dabei unterstützt, ihre Sichtbarkeit in KI-generierten Suchantworten zu verbessern, und schloss damit eine entscheidende Lücke, die von traditionellen SEO-Methoden hinterlassen wurde. Im Gegensatz zur traditionellen Suchmaschinenoptimierung, die sich auf Keyword-Rankings und Klickraten auf Suchergebnisseiten (SERPs) konzentriert, erkennt GEO an, dass generative Engines Informationen aus mehreren Quellen zu kohärenten, zitiergestützten Antworten zusammenfassen und so die Art und Weise, wie Sichtbarkeit erreicht und gemessen wird, grundlegend verändern. Die akademische Gemeinschaft erkannte, dass traditionelle SEO-Techniken – wie Keyword-Optimierung, Linkaufbau und technisches SEO – zwar weiterhin grundlegend sind, aber nicht ausreichen für den Erfolg in einer KI-gesteuerten Suchumgebung, in der Inhalte auffindbar, zitierbar und vertrauenswürdig genug sein müssen, um in synthetisierte Antworten aufgenommen zu werden.
Die Forschung von Aggarwal et al. führte eine umfassende Suite von Sichtbarkeitsmetriken ein, die speziell für generative Engines entwickelt wurden und über traditionelle, auf Rankings basierende Messungen hinausgehen, um die nuancierte Natur von KI-generierten Antworten zu erfassen. Die Studie identifizierte zwei primäre Impression-Metriken: Positionsbereinigte Wortanzahl, die die normalisierte Wortanzahl von Sätzen misst, die eine Quelle zitieren, wobei die Position der Zitation in der Antwort berücksichtigt wird, und Subjektiver Eindruck, der sieben Dimensionen wie Relevanz, Einfluss, Einzigartigkeit und die Wahrscheinlichkeit der Nutzerinteraktion bewertet. Durch strenge Auswertung auf ihrem neu geschaffenen GEO-bench-Benchmark testeten die Forscher neun verschiedene Optimierungsmethoden und zeigten, dass die effektivsten Strategien die Quellensichtbarkeit um bis zu 40 % bei der positionsbereinigten Wortanzahl und 28 % bei den subjektiven Eindrucksmetriken steigern konnten. Die Forschung ergab, dass Methoden, die Glaubwürdigkeit und Evidenz betonen – insbesondere Zitatzugabe (41 % Verbesserung), Statistikzugabe (38 % Verbesserung) und Quellenangabe (35 % Verbesserung) – traditionelle SEO-Taktiken wie Keyword-Stuffing, das die Sichtbarkeit tatsächlich verringerte, deutlich übertreffen. Wichtig ist auch, dass die Studie zeigte, dass die GEO-Effektivität je nach Bereich erheblich variiert, wobei bestimmte Methoden für bestimmte Suchanfrage-Typen und Inhaltskategorien effektiver sind – was die Notwendigkeit domänenspezifischer Optimierungsstrategien anstelle von One-size-fits-all-Ansätzen unterstreicht.
| GEO-Methode | Verbesserung der positionsbereinigten Wortanzahl | Verbesserung subjektiver Eindruck | Am besten geeignet für |
|---|---|---|---|
| Zitatzugabe | 41% | 28% | Historische, narrative und personenbezogene Inhalte |
| Statistikzugabe | 38% | 24% | Recht, Regierung, Meinungs- und datengesteuerte Themen |
| Quellenangabe | 35% | 22% | Faktische Anfragen und glaubwürdigkeitsabhängige Themen |
| Sprachoptimierung | 26% | 21% | Allgemeine Lesbarkeit und Nutzererfahrung |
| Fachbegriffe | 22% | 21% | Spezialisierte und technische Bereiche |
| Autoritativer Ton | 21% | 23% | Debatten- und historische Inhalte |
| Leicht verständlich | 20% | 20% | Zugang für ein breites Publikum |
| Einzigartige Wörter | 5% | 5% | Begrenzte Wirksamkeit in allen Bereichen |
| Keyword-Stuffing | -8% | 1% | Kontraproduktiv für KI-Engines |
Um eine strenge akademische Bewertung von GEO-Methoden zu ermöglichen, stellte das Forschungsteam GEO-bench vor – den ersten groß angelegten Benchmark, der speziell für generative Engines entwickelt wurde und aus 10.000 vielfältigen Suchanfragen besteht, die sorgfältig aus neun verschiedenen Datenquellen ausgewählt und in sieben verschiedene Kategorien unterteilt wurden. Dieser umfassende Benchmark schließt eine entscheidende Lücke in der Forschungslandschaft, da es vor dieser Arbeit kein standardisiertes Evaluierungsframework gab, um Optimierungsstrategien gegen generative Engines zu testen. Der Benchmark umfasst Anfragen aus mehreren Bereichen und spiegelt unterschiedliche Nutzerintentionen wider – 80 % informationell, 10 % transaktional und 10 % navigational – und bildet damit reale Suchverhaltensmuster ab. Jede Anfrage in GEO-bench ist mit bereinigtem Textinhalt aus den Top-5-Google-Suchergebnissen angereichert, wodurch relevante Quellen für die Antwortgenerierung bereitgestellt werden und sichergestellt ist, dass die Bewertung realistische Informationsabrufszenarien widerspiegelt.
Die neun in GEO-bench integrierten Datensätze umfassen:
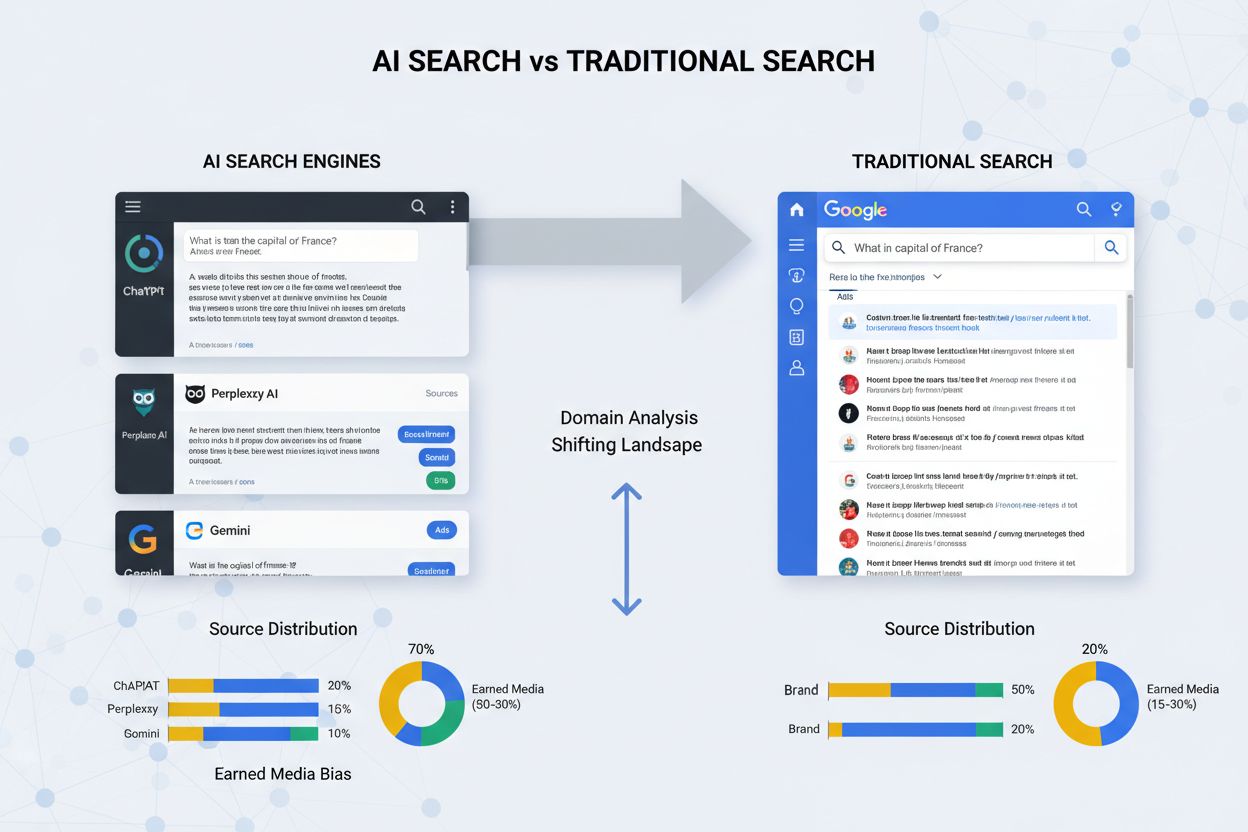
Über GEO-spezifische Optimierung hinaus hat die akademische Forschung fundamentale Unterschiede in der Informationsbeschaffung von KI-Suchmaschinen im Vergleich zu traditionellen Suchmaschinen wie Google aufgezeigt. Eine umfassende Vergleichsstudie von Chen et al., die ChatGPT, Perplexity, Gemini und Claude mit Google über mehrere Bereiche hinweg analysierte, enthüllte eine systematische und überwältigende Bevorzugung von Earned Media in KI-Engines: Earned-Quellen machen je nach Engine und Anfragetyp 60–95 % der Zitate aus. Dies steht im starken Kontrast zu Googles ausgewogenerem Ansatz mit einem erheblichen Anteil an Brand- (25–40 %) und Social-Inhalten (10–20 %) neben Earned-Quellen. Die Forschung zeigte, dass die Domain-Überlappung zwischen KI-Engines und Google bemerkenswert gering ist – je nach Bereich nur 15–50 % –, was darauf hindeutet, dass KI-Systeme Antworten im Wesentlichen aus anderen Informationsökosystemen als traditionelle Suchmaschinen synthetisieren. Bemerkenswert ist, dass KI-Engines Social-Plattformen wie Reddit und Quora fast vollständig aus ihren Antworten ausschließen, während Google häufig nutzergenerierte Inhalte und Community-Diskussionen einbezieht. Diese Erkenntnis hat tiefgreifende Auswirkungen auf Content-Strategien, da Sichtbarkeit bei Google nicht automatisch Sichtbarkeit in KI-generierten Antworten bedeutet und für jedes Suchparadigma eigene Optimierungsansätze erforderlich sind.
Akademische Forschung hat zweifelsfrei gezeigt, dass GEO-Wirksamkeit nicht über alle Bereiche hinweg gleich ist und Content-Ersteller ihre Optimierungsstrategien an ihre jeweilige Branche und Anfragetypen anpassen müssen. Die Studie von Aggarwal et al. identifizierte klare Muster, welche Optimierungsmethoden für verschiedene Inhaltskategorien am besten funktionieren: Zitatzugabe ist am effektivsten für People & Society, Erklärung und Geschichtsbereiche, in denen Narrative und direkte Zitate Authentizität verleihen; Statistikzugabe dominiert in Recht & Regierung, Debatten und Meinungsbeiträgen, wo datenbasierte Evidenz Argumente stärkt; und Quellenangabe ist bei Aussagen, Fakten und Recht & Regierung-Anfragen am wirkungsvollsten, wo die Überprüfung der Glaubwürdigkeit entscheidend ist. Die Forschung zeigt auch, dass informationelle Anfragen (erkundend, wissenssuchend) anders auf Optimierung reagieren als transaktionale Anfragen (mit Kaufabsicht), wobei informationelle Inhalte stärker von umfassender Abdeckung und Autoritätssignalen profitieren, während transaktionale Inhalte klare Produktinformationen, Preise und Vergleichsdaten benötigen. Die Wirksamkeit verschiedener Methoden variiert auch je nachdem, ob Inhalte auf bekannte Marken oder Nischenanbieter abzielen; Nischenmarken benötigen aggressivere Earned-Media-Strategien und Autoritätsaufbau, um den inhärenten “Big Brand Bias” in KI-Engines zu überwinden. Diese domänenspezifische Variation unterstreicht, dass erfolgreicher GEO ein tiefes Verständnis des Informationsökosystems und der Nutzerintentionen im eigenen Bereich erfordert – statt generischer Optimierungstaktiken für alle Inhaltstypen.
Akademische Forschung zur Sprachsensibilität zeigt, dass unterschiedliche KI-Engines mehrsprachige Anfragen mit drastisch unterschiedlichen Ansätzen behandeln, sodass Marken für globale Sichtbarkeit sprachspezifische Strategien entwickeln müssen, anstatt sich auf einfache Übersetzungen zu verlassen. Die Studie von Chen et al. ergab, dass Claude eine bemerkenswert hohe sprachübergreifende Domain-Stabilität aufweist und dieselben maßgeblichen englischsprachigen Quellen für chinesische, japanische, deutsche, französische und spanische Anfragen wiederverwendet. Dies deutet darauf hin, dass der Aufbau von Autorität in erstklassigen englischsprachigen Publikationen Sichtbarkeit über verschiedene Sprachen auf Claude-basierten Systemen übertragen kann. Im krassen Gegensatz dazu zeigt GPT nahezu keine sprachübergreifende Domain-Überlappung und tauscht sein gesamtes Quellensystem bei Anfragen in anderen Sprachen aus – Sichtbarkeit in englischen Suchanfragen bringt für nicht-englische Suchen keinen Vorteil, sondern erfordert den separaten Aufbau von Autorität in lokalen Medien. Perplexity und Gemini liegen dazwischen, mit mittlerer sprachübergreifender Stabilität und sowohl Wiederverwendung von Autoritätsdomains als auch erheblicher Lokalisierung auf Zielsprachquellen. Die Forschung zeigt auch, dass die Sprachauswahl von Websites je nach Engine variiert: GPT und Perplexity bevorzugen bei nicht-englischen Anfragen stark zielsprachige Inhalte, während Claude selbst bei nicht-englischen Eingaben weiterhin einen englischlastigen Ansatz verfolgt. Diese Erkenntnisse sind für multinationale Marken entscheidend: Erfolg in nicht-englischen Märkten erfordert nicht nur Übersetzung, sondern gezielten Aufbau von Earned Media und Autoritätssignalen im jeweiligen Informationsökosystem – und die Strategie hängt davon ab, welche KI-Engines für das Unternehmen am wichtigsten sind.
Die akademische Forschung zu GEO betont konsequent, dass Autorität und E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) grundlegend für die Sichtbarkeit in der KI-Suche sind, wobei KI-Engines systematisch Quellen bevorzugen, die als autoritativ und vertrauenswürdig gelten. Die überwältigende Präferenz für Earned Media, die in mehreren Studien dokumentiert wurde, spiegelt die Abhängigkeit der KI-Engines von Drittbestätigung als Autoritätsindikator wider – Inhalte, die unabhängig geprüft, zitiert und von renommierten Publikationen empfohlen wurden, signalisieren KI-Systemen, dass die Quelle glaubwürdig ist und in synthetisierte Antworten aufgenommen werden sollte. Die Forschung zeigt, dass Backlinks von hochautoritären Domains als entscheidende Autoritätssignale für KI-Engines fungieren – ähnlich wie im klassischen SEO, aber noch wichtiger, da KI-Systeme Linkprofile nutzen, um zu beurteilen, ob eine Quelle als Zitat vertrauenswürdig ist. Die Studien zeigen, dass Autor-Credentials, institutionelle Zugehörigkeit und nachgewiesene Expertise den Willen von KI-Engines, eine Quelle zu zitieren, stark beeinflussen. Für Content-Ersteller ist es daher unerlässlich, ihre Qualifikationen und ihr Wissen klar im eigenen Fachgebiet auszuweisen. Wichtig ist auch, dass E-E-A-T-Signale verdient und nicht nur behauptet werden müssen – bloßes Behaupten von Expertise auf der eigenen Website hat kaum Einfluss, im Gegensatz zur Bestätigung dieser Expertise durch Drittberichte, Expertenempfehlungen und Zitate von maßgeblichen Quellen. Diese Erkenntnis verschiebt den Optimierungsfokus grundlegend von On-Page-Signalen auf Off-Page-Autoritätsaufbau – Earned Media Relations und strategische Partnerschaften sind somit zentrale Bestandteile jeder GEO-Strategie.
Die akademische GEO-Forschung führt zu mehreren umsetzbaren Strategien für Content-Ersteller, die ihre Sichtbarkeit in KI-generierten Antworten verbessern wollen. Erstens müssen Inhalte für die Maschinenlesbarkeit strukturiert sein – mit Schema-Markup und klarer hierarchischer Gliederung, damit KI-Engines Informationen leicht parsen und extrahieren können. Das bedeutet die Implementierung detaillierter schema.org-Markups für Produkte, Artikel, Bewertungen und andere Entitäten, die Nutzung klarer Überschriftenhierarchien und die Organisation von Informationen in scanbaren Formaten wie Tabellen und Aufzählungen. Zweitens sollten Inhalte für Begründungen optimiert werden, d.h. sie müssen Vergleichsfragen explizit beantworten und deutliche Gründe liefern, warum eine Quelle überlegen ist. Dazu gehören detaillierte Vergleichstabellen mit Wettbewerbern, stichpunktartige Pro-und-Contra-Listen und klar hervorgehobene Alleinstellungsmerkmale, die KI-Systeme leicht als Rechtfertigungsattribute extrahieren können. Drittens muss Earned Media Aufbau eine zentrale strategische Priorität werden – Ressourcen werden von der eigenen Content-Erstellung auf PR, Medienarbeit und Expertenkooperationen verlagert, um Features und Zitate in maßgeblichen Publikationen zu erhalten, die von KI-Engines bevorzugt werden. Viertens müssen Sichtbarkeitsmetriken über klassische KPIs hinausgehen: Marken sollten neue Kennzahlen wie KI-Zitate, Erwähnungen in KI-generierten Antworten und Sichtbarkeit über verschiedene generative Engines hinweg verfolgen, anstatt sich nur auf Klickraten und Suchrankings zu verlassen. Schließlich sollten domänenspezifische Optimierungsstrategien generische Ansätze ersetzen – Content-Ersteller sollten recherchieren, welche GEO-Methoden in ihrem eigenen Bereich am besten funktionieren, und ihre Optimierung entsprechend den akademischen Erkenntnissen zur domänenspezifischen Wirksamkeit anpassen.
Obwohl die akademische GEO-Forschung wertvolle Einblicke bietet, erkennen die Forscher wichtige Grenzen an, die bei der Anwendung dieser Erkenntnisse berücksichtigt werden sollten. Die zeitliche Natur der Forschung bedeutet, dass die Ergebnisse das Verhalten der KI-Engines zu einem bestimmten Zeitpunkt widerspiegeln; da sich diese Systeme weiterentwickeln, Algorithmen ändern und sich Wettbewerbsdynamiken verschieben, können die spezifischen quantitativen Ergebnisse veralten, sodass regelmäßige Neubewertungen und kontinuierliches Monitoring der GEO-Wirksamkeit erforderlich sind. Die Black-Box-Natur von KI-Engines stellt eine grundlegende Herausforderung dar, da Forschende keinen Zugang zu internen Rankingmodellen, Trainingsdaten oder Algorithmen haben – die Forschung kann also genau beschreiben, was passiert (welche Quellen werden zitiert), aber die wirklichen Mechanismen hinter diesen Entscheidungen bleiben letztlich abgeleitet und nicht endgültig bewiesen. Die in der Forschung verwendeten Klassifikationssysteme (Brand, Earned, Social) sind konstruierte Rahmen, die zwar logisch sind, aber subjektive Einschätzungen zur Domain-Kategorisierung beinhalten, die unter alternativen Klassifikationsschemata zu anderen Ergebnissen führen könnten. Außerdem fokussierte sich die Forschung primär auf englischsprachige Anfragen und westliche Märkte, mit nur begrenzten Untersuchungen, wie GEO-Prinzipien in nicht-englischen oder aufstrebenden Märkten funktionieren, deren Informationsökosysteme sich deutlich unterscheiden können. Als zukünftige Forschungsrichtungen identifizieren Akademiker die Entwicklung ausgefeilterer Sichtbarkeitsmetriken, die nuancierte Aspekte von KI-Zitaten erfassen, die Untersuchung der Interaktion von GEO-Strategien mit neuen KI-Fähigkeiten wie multimodaler Suche und Conversational Agents sowie Längsschnittstudien, um zu verfolgen, wie sich die GEO-Wirksamkeit mit der Reife von KI-Engines und der Anpassung der Nutzer entwickelt.
Da generative KI die Informationsgewinnung weiterhin verändert, erweitert sich die akademische GEO-Forschung, um neue Herausforderungen und Chancen in dieser sich schnell entwickelnden Landschaft zu adressieren. Multimodale Suche – bei der KI-Engines Informationen aus Text, Bildern, Videos und anderen Medientypen synthetisieren – ist ein neues Forschungsfeld für GEO und erfordert Optimierungsstrategien, die über reine Textinhalte hinausgehen. Konversationelle und agentische KI-Systeme, die im Namen von Nutzern handeln können (z. B. Käufe tätigen, Reservierungen buchen, Transaktionen ausführen), werden neue GEO-Ansätze erfordern, die Inhalte nicht nur zitierbar, sondern auch maschinenausführbar machen. Die akademische Gemeinschaft erkennt zunehmend die Notwendigkeit von prinzipiengeleiteten GEO-Methoden und Managed Services, die über Einzelmaßnahmen hinausgehen und umfassende, kontinuierliche Optimierungsstrategien für mehrere KI-Engines parallel bieten. Die Forschung untersucht auch, wie sich GEO-Strategien anpassen müssen, wenn KI-Engines reifen und konsolidieren: Erste Erkenntnisse deuten darauf hin, dass sich mit der Marktkonsolidierung auf wenige dominante Plattformen die Optimierungsstrategien zwar standardisieren, aber weiterhin von klassischem SEO unterscheiden werden. Schließlich untersuchen Akademiker die breiteren Auswirkungen von GEO auf die Creator Economy und das digitale Publishing – insbesondere, wie der Wandel zu KI-synthetisierten Antworten die Traffic-Verteilung, Geschäftsmodelle und die Existenzfähigkeit kleinerer Publisher und Content-Ersteller in einer KI-dominierten Suchlandschaft beeinflusst. Diese neuen Forschungsrichtungen deuten darauf hin, dass sich GEO als Fachgebiet weiterentwickeln wird, wobei die akademische Forschung eine Schlüsselrolle dabei spielt, Content-Ersteller, Marken und Publisher bei der grundlegenden Transformation der Informationsgewinnung und -nutzung im Zeitalter der generativen KI zu unterstützen.
Generative Engine Optimization (GEO) ist ein Rahmenwerk zur Optimierung der Sichtbarkeit von Inhalten in KI-generierten Suchantworten, anstatt in traditionellen, gerankten Suchergebnissen. Im Gegensatz zu SEO, das sich auf Keyword-Rankings und Klickraten konzentriert, betont GEO, als Quelle in synthetisierten KI-Antworten zitiert zu werden. Dies erfordert andere Strategien hinsichtlich Autorität, Inhaltsstruktur und Earned Media.
Das KDD-Papier 2024 von Aggarwal et al. von der Princeton University und dem IIT Delhi stellte das erste umfassende Rahmenwerk für GEO vor, einschließlich Sichtbarkeitsmetriken, Optimierungsmethoden und dem GEO-bench-Benchmark. Diese wegweisende Studie zeigte, dass die Sichtbarkeit von Inhalten in generativen Engines durch gezielte Optimierungsstrategien um bis zu 40 % verbessert werden kann und etablierte GEO als ein legitimes akademisches Fachgebiet.
GEO-bench ist der erste groß angelegte Benchmark zur Bewertung der Generative Engine Optimization und besteht aus 10.000 vielfältigen Suchanfragen aus 25 Bereichen. Er bietet ein standardisiertes Evaluierungsframework für die Prüfung von GEO-Methoden und zum Vergleich ihrer Wirksamkeit über verschiedene Suchanfrage-Typen, Bereiche und KI-Engines hinweg. So wird eine fundierte akademische Forschung und praktische Optimierungsstrategien ermöglicht.
Akademische Forschung zeigt, dass die effektivsten GEO-Methoden das Hinzufügen von Zitaten (41 % Verbesserung), das Einfügen von Statistiken (38 % Verbesserung) und das Angeben von Quellen (35 % Verbesserung) sind. Diese Methoden wirken, indem sie glaubwürdige Zitate, relevante Statistiken und Aussagen aus maßgeblichen Quellen hinzufügen, die von KI-Engines beim Syntheseprozess von Antworten stark bevorzugt werden.
Forschungsergebnisse zeigen, dass KI-Suchmaschinen wie ChatGPT und Claude eine starke Tendenz zu Earned Media (60-95 %) aufweisen, während Google eine ausgewogenere Mischung aus Brand-, Earned- und Social-Quellen beibehält. KI-Engines priorisieren konsistent keine nutzergenerierten Inhalte und sozialen Plattformen, sondern bevorzugen Drittanbieter-Bewertungen, redaktionelle Outlets und autoritative Publikationen.
Autorität und E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) sind grundlegend für den Erfolg im GEO. Akademische Forschung zeigt, dass KI-Engines Inhalte aus Quellen bevorzugen, die als autoritativ gelten. Earned Media Coverage, Backlinks von renommierten Domains und nachgewiesene Expertise sind entscheidende Faktoren für Sichtbarkeit in KI-generierten Antworten.
Forschung zeigt, dass verschiedene KI-Engines mehrsprachige Suchanfragen unterschiedlich behandeln. Claude weist eine hohe sprachübergreifende Stabilität auf und nutzt englischsprachige Autoritätsdomains wieder, während GPT stark lokalisiert und aus Zielsprachen-Ökosystemen schöpft. Daraus folgt, dass Marken sprachspezifische Autoritätsstrategien entwickeln müssen, anstatt sich auf einfache Übersetzungen zu verlassen.
Akademische GEO-Forschung zeigt, dass Content-Ersteller Earned Media Coverage aufbauen, Inhalte maschinenlesbar mit Schema-Markup strukturieren, begründungsreiche Inhalte mit klaren Vergleichen und Wertversprechen schaffen und neue Metriken wie KI-Zitate und Sichtbarkeit anstelle traditioneller Klickraten verfolgen sollten.
Verfolgen Sie, wie Ihre Inhalte in KI-generierten Antworten bei ChatGPT, Perplexity, Google AI Overviews und anderen generativen Engines erscheinen. Erhalten Sie Echtzeit-Einblicke in Ihre GEO-Performance.
Erfahren Sie, was Generative Engine Optimization (GEO) ist, wie es sich von SEO unterscheidet und warum es für die Sichtbarkeit von Marken in KI-basierten Suchm...

Erfahren Sie, warum Generative Engine Optimization (GEO) für Unternehmen im Jahr 2025 unverzichtbar ist. Lernen Sie, wie KI-gestützte Suche die Markenpräsenz un...
Erfahren Sie, wie Sie GEO-Maßnahmen über KI-Plattformen wie ChatGPT, Perplexity und Google AI Overviews skalieren. Entdecken Sie das 12-Schritte-Framework, um d...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.