Auswirkungen von KI-Crawlern auf Serverressourcen: Was Sie erwarten können
Erfahren Sie, wie KI-Crawler Serverressourcen, Bandbreite und Leistung beeinflussen. Entdecken Sie echte Statistiken, Strategien zur Abschwächung und Infrastruktur-Lösungen für ein effektives Management der Bot-Last.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
Verhalten und Skalierung von KI-Crawlern verstehen
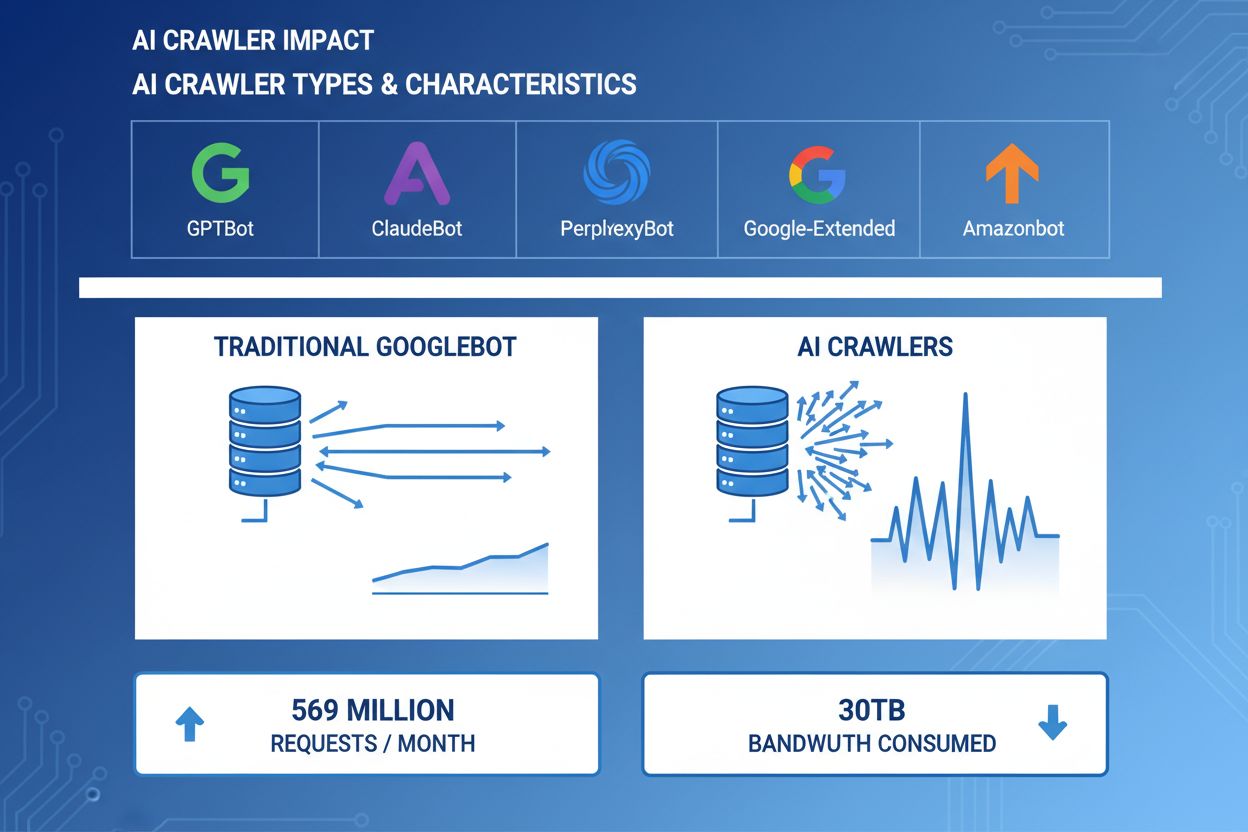
KI-Crawler sind zu einer bedeutenden Kraft im Web-Traffic geworden, da große KI-Unternehmen ausgeklügelte Bots einsetzen, um Inhalte für Training und Abruf zu indexieren. Diese Crawler arbeiten im großen Maßstab und erzeugen etwa 569 Millionen Anfragen pro Monat im gesamten Web und verbrauchen weltweit über 30 TB Bandbreite. Die wichtigsten KI-Crawler sind GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) und Amazonbot (Amazon) – alle mit unterschiedlichen Crawling-Mustern und Ressourcenanforderungen. Das Verständnis des Verhaltens und der Eigenschaften dieser Crawler ist für Website-Administratoren unerlässlich, um Serverressourcen richtig zu verwalten und fundierte Entscheidungen über Zugriffsrichtlinien zu treffen.
Crawler-Name
Unternehmen
Zweck
Anfrage-Muster
GPTBot
OpenAI
Trainingsdaten für ChatGPT- und GPT-Modelle
Aggressiv, hochfrequente Anfragen
ClaudeBot
Anthropic
Trainingsdaten für Claude-AI-Modelle
Mittlere Frequenz, respektvolles Crawling
PerplexityBot
Perplexity AI
Echtzeit-Suche und Antwortgenerierung
Mittel- bis hochfrequent
Google-Extended
Google
Erweiterte Indexierung für KI-Funktionen
Kontrolliert, befolgt robots.txt
Amazonbot
Amazon
Produkt- und Inhaltsindexierung
Variabel, handelsorientiert
Metriken zum Ressourcenverbrauch von Servern
KI-Crawler verbrauchen Serverressourcen in mehreren Dimensionen und haben messbare Auswirkungen auf die Infrastrukturleistung. Die CPU-Auslastung kann während Spitzenaktivität von Crawlern um 300 % oder mehr ansteigen, da Server Tausende gleichzeitige Anfragen verarbeiten und HTML-Inhalte parsen. Der Bandbreitenverbrauch zählt zu den sichtbarsten Kosten – eine einzige populäre Website kann täglich Gigabytes an Crawler ausliefern. Der Speicherbedarf steigt erheblich, da Server Verbindungspools verwalten und große Datenmengen zum Verarbeiten puffern. Datenbankabfragen vervielfachen sich, wenn Crawler Seiten anfordern, die dynamische Inhalte erzeugen, was zusätzlichen I/O-Druck verursacht. Die Festplatten-I/O wird zum Engpass, wenn Server Inhalte aus dem Speicher lesen müssen, um Crawler-Anfragen zu bedienen – insbesondere bei Seiten mit großen Inhaltsbibliotheken.
Ressource
Auswirkung
Praxisbeispiel
CPU
200–300 % Spitzen während Spitzen-Crawling
Server-Load-Average steigt von 2,0 auf 8,0
Bandbreite
15–40 % des monatlichen Gesamtverbrauchs
500-GB-Seite liefert monatlich 150 GB an Crawler
Speicher
20–30 % Zunahme des RAM-Verbrauchs
8-GB-Server benötigt bei Crawler-Aktivität 10 GB
Datenbank
2–5-fache Erhöhung der Abfragelast
Antwortzeiten steigen von 50 ms auf 250 ms
Festplatten-I/O
Anhaltend hohe Leseoperationen
Auslastung steigt von 30 % auf 85 %
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
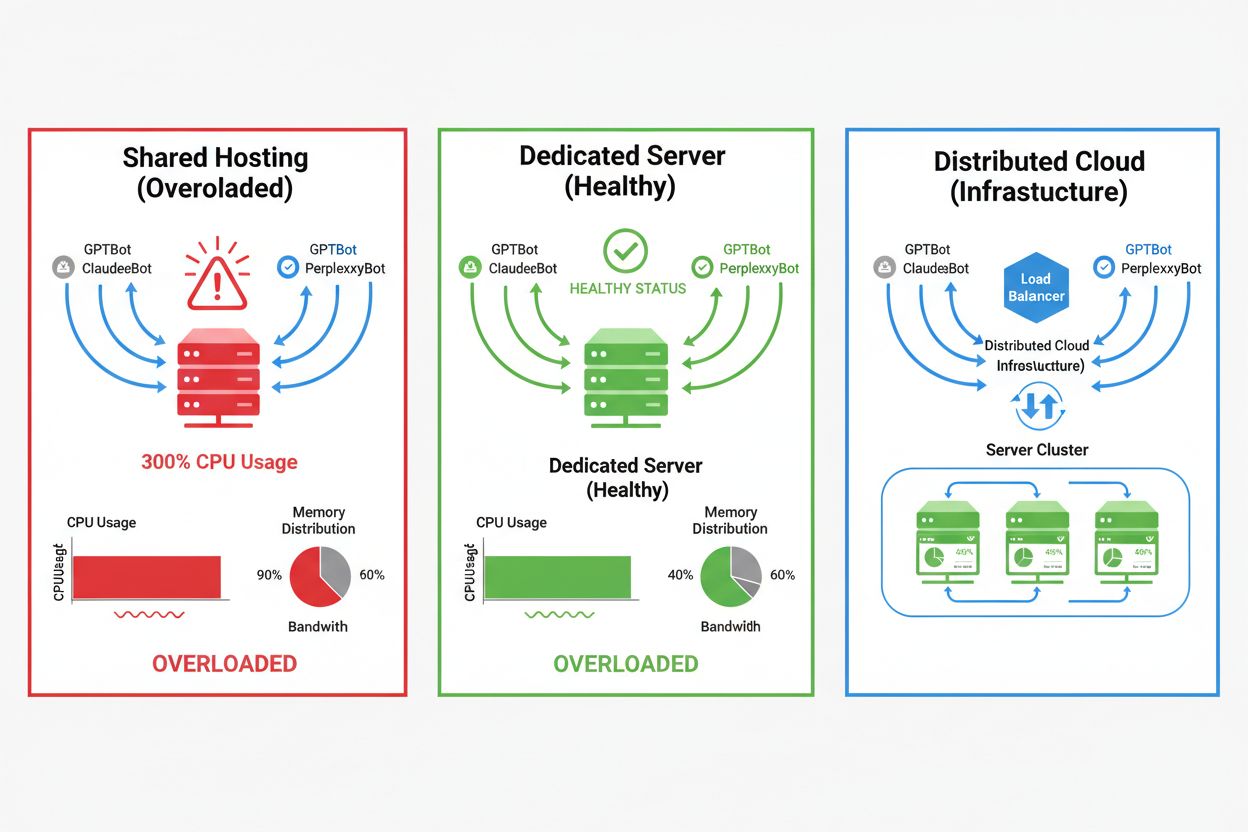
Die Auswirkungen von KI-Crawlern variieren je nach Hosting-Umgebung erheblich. Besonders Shared-Hosting-Umgebungen sind stark betroffen. Im Shared Hosting wird das „Noisy Neighbor Syndrome“ zum Problem: Wenn eine Website auf einem geteilten Server viel Crawler-Traffic anzieht, verbraucht sie Ressourcen, die sonst anderen gehosteten Seiten zur Verfügung stünden, was die Leistung für alle Nutzer verschlechtert. Dedizierte Server und Cloud-Infrastrukturen bieten bessere Isolation und Ressourcenzusagen, sodass Sie Crawler-Traffic aufnehmen können, ohne andere Dienste zu beeinträchtigen. Aber auch dedizierte Infrastrukturen erfordern sorgfältige Überwachung und Skalierung, um die kumulierte Last mehrerer gleichzeitig arbeitender KI-Crawler zu bewältigen.
Wesentliche Unterschiede zwischen Hosting-Umgebungen:
Shared Hosting: Begrenzte Ressourcen, keine Isolation, Crawler-Traffic betrifft andere Seiten direkt, minimale Kontrolle über Crawler-Zugriff
CDN + Origin: Verteilter Traffic, Edge-Caching, Crawler-Traffic wird am Edge absorbiert, Origin-Server geschützt
Bandbreiten- und Kostenimplikationen
Die finanziellen Auswirkungen des KI-Crawler-Traffics gehen über die reinen Bandbreitenkosten hinaus und umfassen sowohl direkte als auch versteckte Ausgaben, die Ihre Bilanz erheblich beeinträchtigen können. Direkte Kosten sind erhöhte Bandbreitengebühren Ihres Hosting-Providers, die je nach Traffic-Volumen und Crawler-Intensität monatlich Hunderte oder Tausende Euro ausmachen können. Versteckte Kosten entstehen durch erhöhte Infrastruktur-Anforderungen – Sie müssen eventuell auf höherwertige Hosting-Tarife umsteigen, zusätzliche Caching-Ebenen einführen oder gezielt in CDN-Dienste investieren, um Crawler-Traffic zu bewältigen. Die ROI-Berechnung wird komplex, da KI-Crawler Ihrem Unternehmen nur minimalen direkten Mehrwert bieten, aber Ressourcen verbrauchen, die zahlenden Kunden oder einer besseren Nutzererfahrung zugutekommen könnten. Viele Website-Betreiber stellen fest, dass die Kosten für die Aufnahme von Crawler-Traffic den potenziellen Nutzen durch KI-Modelltraining oder Sichtbarkeit in KI-gestützten Suchergebnissen übersteigen.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Auswirkungen auf die Nutzererfahrung
KI-Crawler-Traffic verschlechtert die Nutzererfahrung legitimer Besucher direkt, indem er Serverressourcen verbraucht, die sonst für menschliche Nutzer zur Verfügung stünden. Core Web Vitals-Metriken werden messbar schlechter: Largest Contentful Paint (LCP) steigt um 200–500 ms, Time to First Byte (TTFB) verschlechtert sich um 100–300 ms während starker Crawler-Aktivität. Diese Leistungsverschlechterungen ziehen negative Kettenreaktionen nach sich: Langsamere Seiten laden verringern die Nutzerbindung, erhöhen die Absprungraten und senken letztlich Konversionsraten für E-Commerce- und Lead-Generierungsseiten. Auch das Suchmaschinen-Ranking leidet, da Googles Algorithmus die Core Web Vitals als Rankingfaktor einbezieht – so entsteht ein Teufelskreis, in dem Crawler-Traffic Ihre SEO-Leistung indirekt verschlechtert. Nutzer, die langsame Ladezeiten erleben, verlassen Ihre Seite eher und besuchen Mitbewerber, was sich direkt auf Umsatz und Markenwahrnehmung auswirkt.
Überwachungs- und Erkennungsstrategien
Effektives Management von KI-Crawler-Traffic beginnt mit umfassender Überwachung und Erkennung, damit Sie das Ausmaß des Problems verstehen, bevor Sie Lösungen umsetzen. Die meisten Webserver protokollieren User-Agent-Strings, die den Crawler identifizieren, der jede Anfrage stellt – dies ist die Grundlage für Traffic-Analysen und Filterentscheidungen. Serverprotokolle, Analyseplattformen und spezialisierte Monitoring-Tools können diese User-Agent-Strings auswerten, um Crawler-Traffic-Muster zu erkennen und zu quantifizieren.
Wichtige Erkennungsmethoden und Tools:
Log-Analyse: Serverprotokolle nach User-Agent-Strings (GPTBot, ClaudeBot, Google-Extended, CCBot) durchsuchen, um Crawler-Anfragen zu identifizieren
Analyseplattformen: Google Analytics, Matomo und ähnliche Tools können Crawler-Traffic von menschlichen Nutzern trennen
Echtzeit-Monitoring: Tools wie New Relic und Datadog bieten Echtzeiteinblicke in Crawler-Aktivitäten und Ressourcenverbrauch
DNS Reverse Lookup: Crawler-IP-Adressen mit veröffentlichten IP-Bereichen von OpenAI, Anthropic und anderen KI-Unternehmen abgleichen
Verhaltensanalyse: Verdächtige Muster wie schnelle, aufeinanderfolgende Anfragen, ungewöhnliche User-Agent-Kombinationen oder Zugriffe auf sensible Bereiche erkennen
Abwehrstrategien – robots.txt und Rate Limiting
Die erste Verteidigungslinie gegen übermäßigen KI-Crawler-Traffic ist eine gut konfigurierte robots.txt-Datei, die den Crawler-Zugriff auf Ihre Website explizit steuert. Diese einfache Textdatei im Stammverzeichnis Ihrer Website ermöglicht es Ihnen, bestimmte Crawler auszuschließen, die Crawling-Frequenz zu begrenzen und Crawler auf eine Sitemap mit gewünschten Inhalten zu verweisen. Rate Limiting auf Anwendungs- oder Serverebene bietet einen zusätzlichen Schutz, indem Anfragen bestimmter IP-Adressen oder User-Agents gedrosselt werden, um Ressourcenerschöpfung zu verhindern. Diese Strategien sind nicht blockierend und reversibel und daher ideale Startpunkte, bevor Sie zu restriktiveren Maßnahmen greifen.
# robots.txt - Blockiert KI-Crawler, aber erlaubt legitime Suchmaschinen
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Erlaube Google und Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Crawl-Delay für alle anderen Bots
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Erweiterter Schutz – WAF- und CDN-Lösungen
Web Application Firewalls (WAF) und Content Delivery Networks (CDN) bieten fortschrittlichen, unternehmensgerechten Schutz gegen unerwünschten Crawler-Traffic durch Verhaltensanalysen und intelligente Filterung. Cloudflare und ähnliche CDN-Anbieter bieten integrierte Bot-Management-Funktionen, die KI-Crawler anhand von Verhaltensmustern, IP-Reputation und Anfrageeigenschaften erkennen und blockieren können – ohne manuelle Konfiguration. WAF-Regeln können so eingestellt werden, dass sie verdächtige Anfragen abfragen, bestimmte User-Agents drosseln oder Traffic von bekannten Crawler-IP-Bereichen vollständig blockieren. Diese Lösungen arbeiten am Edge, filtern schädlichen Traffic, bevor er Ihren Origin-Server erreicht, und reduzieren so die Belastung Ihrer Infrastruktur erheblich. Der Vorteil von WAF- und CDN-Lösungen liegt in ihrer Anpassungsfähigkeit an neue Crawler und sich verändernde Angriffsmuster, ohne dass manuelle Updates an Ihrer Konfiguration nötig sind.
Sichtbarkeit und Schutz ausbalancieren
Ob Sie KI-Crawler blockieren, hängt von einer sorgfältigen Abwägung zwischen dem Schutz Ihrer Serverressourcen und der Wahrung der Sichtbarkeit in KI-gestützten Suchergebnissen und Anwendungen ab. Das komplette Blockieren aller KI-Crawler schließt die Möglichkeit aus, dass Ihre Inhalte in ChatGPT-Suchergebnissen, Perplexity-Antworten oder anderen KI-basierten Discovery-Mechanismen erscheinen – was potenziell Referral-Traffic und Markenpräsenz verringert. Umgekehrt verursacht uneingeschränkter Crawler-Zugriff erhebliche Kosten und kann die Nutzererfahrung verschlechtern, ohne einen messbaren Nutzen für Ihr Unternehmen zu bringen. Die optimale Strategie hängt von Ihrer individuellen Situation ab: Hoch frequentierte Websites mit viel Ressourcen können Crawler zulassen, ressourcenbeschränkte Seiten sollten jedoch die Nutzererfahrung priorisieren, indem sie Crawler-Zugriff blockieren oder drosseln. Die strategische Entscheidung sollte Branche, Zielgruppe, Inhaltstyp und Geschäftsziele berücksichtigen, statt einen Einheitsansatz zu verfolgen.
Infrastruktur-Skalierungslösungen
Websites, die KI-Crawler-Traffic aufnehmen möchten, können durch Infrastrukturskalierung die Leistung aufrechterhalten und die erhöhte Last abfedern. Vertikale Skalierung – also Server-Upgrades mit mehr CPU, RAM und Bandbreite – bietet eine unkomplizierte, aber teure Lösung, die irgendwann physische Grenzen erreicht. Horizontale Skalierung – die Verteilung des Traffics auf mehrere Server per Load Balancer – ermöglicht langfristig bessere Skalierbarkeit und Ausfallsicherheit. Cloud-Infrastruktur-Plattformen wie AWS, Google Cloud und Azure bieten Auto-Scaling, das bei Traffic-Spitzen automatisch zusätzliche Ressourcen bereitstellt und in ruhigen Zeiten wieder reduziert, um Kosten zu sparen. Content Delivery Networks (CDN) können statische Inhalte am Edge cachen, wodurch die Last auf Ihrem Origin-Server verringert und die Leistung für menschliche Nutzer und Crawler verbessert wird. Datenbankoptimierung, Query-Caching und Verbesserungen auf Anwendungsebene können zudem den Ressourcenverbrauch pro Anfrage senken und so die Effizienz steigern, ohne zusätzliche Infrastruktur zu benötigen.
Monitoring-Tools und Best Practices
Kontinuierliche Überwachung und Optimierung sind entscheidend, um trotz anhaltendem KI-Crawler-Traffic die optimale Leistung zu erhalten. Spezialisierte Tools schaffen Transparenz über Crawler-Aktivitäten, Ressourcenverbrauch und Leistungskennzahlen und ermöglichen datenbasierte Entscheidungen zu Crawler-Management-Strategien. Die umfassende Überwachung von Anfang an erlaubt es Ihnen, Baselines zu definieren, Trends zu erkennen und die Wirksamkeit von Gegenmaßnahmen im Zeitverlauf zu messen.
Unverzichtbare Monitoring-Tools und Praktiken:
Server-Monitoring: New Relic, Datadog oder Prometheus für Echtzeitmetriken zu CPU, Speicher und Festplatten-I/O
Log-Analyse: ELK Stack, Splunk oder Graylog zum Parsen und Auswerten von Serverprotokollen zur Identifikation von Crawler-Mustern
Spezialisierte Lösungen: AmICited.com bietet spezialisiertes Monitoring für KI-Crawler-Aktivitäten und detaillierte Einblicke, welche KI-Modelle auf Ihre Inhalte zugreifen
Performance-Tracking: Google PageSpeed Insights, WebPageTest und Core Web Vitals Monitoring zur Messung der Auswirkungen auf die Nutzererfahrung
Alerting: Konfigurieren Sie Alarme für Ressourcenspitzen, ungewöhnliche Traffic-Muster und Leistungsverschlechterungen für schnelle Reaktionen
Langfristige Strategie und zukünftige Überlegungen
Das Feld des KI-Crawler-Managements entwickelt sich stetig weiter. Neue Standards und Brancheninitiativen prägen die Interaktion zwischen Websites und KI-Unternehmen. Der llms.txt-Standard ist ein aufkommender Ansatz, KI-Unternehmen strukturierte Informationen über Nutzungsrechte und Präferenzen zu liefern – und könnte eine differenziertere Alternative zum vollständigen Blockieren oder Erlauben bieten. Branchendiskussionen über Kompensationsmodelle deuten darauf hin, dass KI-Unternehmen künftig womöglich für den Zugriff auf Trainingsdaten bezahlen, was die Wirtschaftlichkeit des Crawler-Traffics grundlegend ändern würde. Um Ihre Infrastruktur zukunftssicher zu machen, sollten Sie sich über neue Standards informieren, Branchenentwicklungen beobachten und Ihre Crawler-Management-Strategien flexibel gestalten. Beziehungen zu KI-Unternehmen aufbauen, an Branchendiskussionen teilnehmen und sich für faire Kompensationsmodelle einsetzen wird immer wichtiger, je zentraler KI für Web-Discovery und Inhaltskonsum wird. Die Websites, die in dieser sich wandelnden Landschaft erfolgreich sind, werden jene sein, die Innovation mit Pragmatismus verbinden: Sie schützen ihre Ressourcen und bleiben zugleich offen für legitime Chancen auf Sichtbarkeit und Partnerschaften.
Häufig gestellte Fragen
Was ist der Unterschied zwischen KI-Crawlern und Suchmaschinen-Crawlern?
KI-Crawler (GPTBot, ClaudeBot) extrahieren Inhalte für das LLM-Training, ohne zwangsläufig Traffic zurückzusenden. Suchmaschinen-Crawler (Googlebot) indexieren Inhalte für die Sichtbarkeit in der Suche und senden typischerweise Verweis-Traffic. KI-Crawler arbeiten aggressiver mit größeren Batch-Anfragen und ignorieren bandbreitensparende Richtlinien.
Wie viel Bandbreite können KI-Crawler verbrauchen?
Praxisbeispiele zeigen über 30 TB pro Monat von einzelnen Crawlern. Der Verbrauch hängt von der Seitengröße, dem Inhaltsvolumen und der Crawling-Frequenz ab. OpenAIs GPTBot allein erzeugte 569 Millionen Anfragen in einem einzigen Monat im Vercel-Netzwerk.
Schadet das Blockieren von KI-Crawlern meinem SEO?
Das Blockieren von KI-Trainingscrawlern (GPTBot, ClaudeBot) wirkt sich nicht auf das Google-Ranking aus. Das Blockieren von KI-Suchcrawlern kann jedoch die Sichtbarkeit in KI-gestützten Suchergebnissen wie Perplexity oder ChatGPT Search verringern.
Woran erkenne ich, dass mein Server von Crawlern überlastet wird?
Achten Sie auf unerklärliche CPU-Spitzen (300 %+), erhöhten Bandbreitenverbrauch ohne mehr menschliche Besucher, langsamere Ladezeiten und ungewöhnliche User-Agent-Strings in den Serverprotokollen. Auch Core Web Vitals-Metriken können sich signifikant verschlechtern.
Lohnt sich das Upgrade auf dediziertes Hosting für das Crawler-Management?
Für Websites mit erheblichem Crawler-Traffic bietet dediziertes Hosting bessere Ressourcenisolation, Kontrolle und Kostenplanbarkeit. Shared Hosting-Umgebungen leiden unter dem 'Noisy Neighbor Syndrome', bei dem der Crawler-Traffic einer Website alle gehosteten Seiten beeinflusst.
Welche Tools sollte ich zur Überwachung von KI-Crawler-Aktivitäten verwenden?
Nutzen Sie die Google Search Console für Googlebot-Daten, Server-Access-Logs für detaillierte Traffic-Analysen, CDN-Analytics (Cloudflare) und spezialisierte Plattformen wie AmICited.com für umfassende Überwachung und Nachverfolgung von KI-Crawlern.
Kann ich einige Crawler zulassen und andere blockieren?
Ja, über robots.txt-Direktiven, WAF-Regeln und IP-basiertes Filtern. Sie können nützliche Crawler wie Googlebot zulassen und ressourcenintensive KI-Trainingscrawler durch user-agent-spezifische Regeln blockieren.
Wie erkenne ich, ob KI-Crawler die Leistung meiner Website beeinflussen?
Vergleichen Sie Servermetriken vor und nach der Umsetzung von Crawler-Kontrollen. Überwachen Sie Core Web Vitals (LCP, TTFB), Ladezeiten, CPU-Auslastung und User-Experience-Metriken. Tools wie Google PageSpeed Insights und Server-Monitoring-Plattformen liefern detaillierte Einblicke.
Überwachen Sie heute die Auswirkungen Ihrer KI-Crawler
Erhalten Sie Echtzeit-Einblicke, wie KI-Modelle auf Ihre Inhalte zugreifen und Ihre Serverressourcen mit der spezialisierten Überwachungsplattform von AmICited beeinflussen.
Sollten Sie KI-Crawler blockieren oder zulassen? Entscheidungsrahmen
Erfahren Sie, wie Sie strategische Entscheidungen zum Blockieren von KI-Crawlern treffen. Bewerten Sie Inhaltstyp, Traffic-Quellen, Geschäftsmodelle und Wettbew...
Verstehen Sie, wie KI-Crawler wie GPTBot und ClaudeBot funktionieren, wo sie sich von traditionellen Such-Crawlern unterscheiden und wie Sie Ihre Website für Si...
So erlaubst du KI-Bots das Crawlen deiner Website: Umfassender robots.txt- & llms.txt-Leitfaden
Erfahre, wie du KI-Bots wie GPTBot, PerplexityBot und ClaudeBot das Crawlen deiner Website erlaubst. Konfiguriere robots.txt, richte llms.txt ein und optimiere ...
12 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.