AI-Crawler-Referenzkarte: Alle Bots auf einen Blick
Vollständiger Referenzleitfaden zu AI-Crawlern und Bots. Identifizieren Sie GPTBot, ClaudeBot, Google-Extended und 20+ weitere AI-Crawler mit User-Agents, Crawl-Raten und Blockierungsstrategien.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
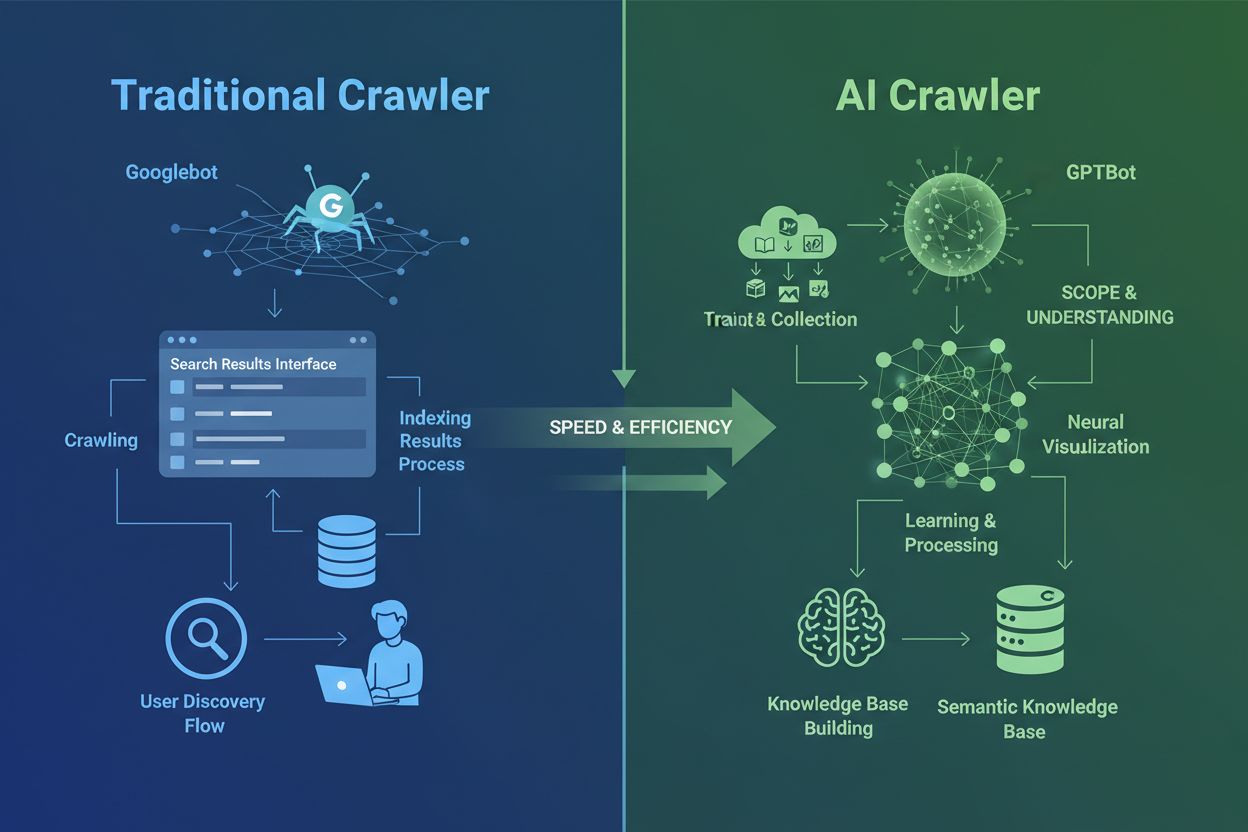
Verständnis von AI-Crawlern vs. traditionellen Crawlern
AI-Crawler unterscheiden sich grundlegend von den traditionellen Suchmaschinen-Crawlern, die Sie seit Jahrzehnten kennen. Während Googlebot und Bingbot Inhalte indexieren, um Nutzern Informationen über Suchergebnisse zugänglich zu machen, sammeln AI-Crawler wie GPTBot und ClaudeBot Daten gezielt zum Training großer Sprachmodelle. Diese Unterscheidung ist entscheidend: Traditionelle Crawler schaffen Wege für die menschliche Entdeckung, während AI-Crawler die Wissensdatenbanken von künstlichen Intelligenzen speisen. Laut aktuellen Daten entfallen fast 80 % des gesamten Bot-Traffics auf AI-Crawler, wobei Trainings-Crawler enorme Mengen an Inhalten konsumieren, aber nur minimale Verweiszugriffe an Publisher zurücksenden. Im Gegensatz zu traditionellen Crawlern, die mit dynamischen, JavaScript-lastigen Seiten Schwierigkeiten haben, nutzen AI-Crawler fortschrittliches maschinelles Lernen, um Inhalte kontextuell zu verstehen – ähnlich wie ein menschlicher Leser. Sie können Bedeutung, Ton und Zweck ohne manuelle Konfigurationsupdates interpretieren. Dies stellt einen Quantensprung in der Web-Indexierungstechnologie dar, der Website-Besitzer dazu zwingt, ihre Crawler-Management-Strategien grundlegend zu überdenken.
Das Ökosystem der wichtigsten AI-Crawler
Das Feld der AI-Crawler ist zunehmend überfüllt, da große Technologieunternehmen im Wettrennen um eigene große Sprachmodelle stehen. OpenAI, Anthropic, Google, Meta, Amazon, Apple und Perplexity betreiben jeweils mehrere spezialisierte Crawler, die unterschiedliche Funktionen innerhalb ihrer jeweiligen AI-Ökosysteme erfüllen. Unternehmen setzen mehrere Crawler ein, weil verschiedene Zwecke unterschiedliches Verhalten erfordern: Manche Crawler konzentrieren sich auf die massenhafte Sammlung von Trainingsdaten, andere übernehmen das Echtzeit-Suchindexieren und wiederum andere holen Inhalte bedarfsgesteuert ab, wenn Nutzer sie anfordern. Wer dieses Ökosystem verstehen will, muss drei Haupt-Crawler-Kategorien unterscheiden: Trainings-Crawler, die Daten zur Modellverbesserung sammeln; Such- und Zitations-Crawler, die Inhalte für AI-gestützte Suche indexieren; und nutzergetriggerte Fetcher, die aktiviert werden, wenn User gezielt Inhalte über AI-Assistenten anfordern. Die folgende Tabelle gibt einen schnellen Überblick über die wichtigsten Akteure:
Unternehmen
Crawler-Name
Hauptzweck
Crawl-Rate
Trainingsdaten
OpenAI
GPTBot
Modelltraining
100 Seiten/Stunde
Ja
OpenAI
ChatGPT-User
Echtzeit-Benutzeranfragen
2400 Seiten/Stunde
Nein
OpenAI
OAI-SearchBot
Suchindexierung
150 Seiten/Stunde
Nein
Anthropic
ClaudeBot
Modelltraining
500 Seiten/Stunde
Ja
Anthropic
Claude-User
Echtzeit-Webzugriff
<10 Seiten/Stunde
Nein
Google
Google-Extended
Gemini AI-Training
Variabel
Ja
Google
Gemini-Deep-Research
Research-Feature
<10 Seiten/Stunde
Nein
Meta
Meta-ExternalAgent
AI-Modelltraining
1100 Seiten/Stunde
Ja
Amazon
Amazonbot
Serviceverbesserung
1050 Seiten/Stunde
Ja
Perplexity
PerplexityBot
Suchindexierung
150 Seiten/Stunde
Nein
Apple
Applebot-Extended
AI-Training
<10 Seiten/Stunde
Ja
Common Crawl
CCBot
Offenes Datenset
<10 Seiten/Stunde
Ja
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
OpenAI betreibt drei verschiedene Crawler, die jeweils spezifische Rollen im ChatGPT-Ökosystem erfüllen. Diese Crawler zu verstehen ist wichtig, da OpenAI’s GPTBot einer der aggressivsten und am weitesten verbreiteten AI-Crawler im Internet ist:
GPTBot – OpenAIs primärer Trainings-Crawler, der systematisch öffentlich verfügbare Daten sammelt, um GPT-Modelle wie ChatGPT und GPT-4o zu trainieren und zu verbessern. Dieser Crawler arbeitet mit etwa 100 Seiten pro Stunde und respektiert robots.txt-Anweisungen. OpenAI veröffentlicht offizielle IP-Adressen unter https://openai.com/gptbot.json zur Verifizierung.
ChatGPT-User – Dieser Crawler erscheint, wenn ein echter Nutzer mit ChatGPT interagiert und gezielt eine bestimmte Webseite durchsuchen lässt. Er arbeitet mit deutlich höheren Raten (bis zu 2400 Seiten/Stunde), da er durch Nutzeraktionen und nicht durch systematisches Crawlen ausgelöst wird. Inhalte, auf die ChatGPT-User zugreift, werden nicht für das Modelltraining verwendet und sind daher für die Echtzeit-Sichtbarkeit in ChatGPT-Suchergebnissen relevant.
OAI-SearchBot – Speziell für die Suchfunktionalität von ChatGPT entwickelt, indexiert dieser Crawler Inhalte für Echtzeit-Suchergebnisse, ohne Trainingsdaten zu sammeln. Er arbeitet mit etwa 150 Seiten pro Stunde und hilft Ihren Inhalten, bei relevanten Nutzerfragen in ChatGPT-Suchergebnissen zu erscheinen.
OpenAIs Crawler respektieren robots.txt-Anweisungen und arbeiten von verifizierten IP-Bereichen aus, wodurch sie im Vergleich zu weniger transparenten Mitbewerbern relativ einfach zu verwalten sind.
Anthropics Claude-Crawler
Anthropic, das Unternehmen hinter Claude AI, betreibt mehrere Crawler mit unterschiedlichen Zwecken und Transparenzstufen. Das Unternehmen ist mit Dokumentation weniger offen als OpenAI, aber das Verhalten der Crawler lässt sich gut durch Serverlog-Analysen nachvollziehen:
ClaudeBot – Anthropics Haupt-Trainings-Crawler, der Webinhalte sammelt, um Claudes Wissensbasis und Fähigkeiten zu verbessern. Dieser Crawler arbeitet mit etwa 500 Seiten pro Stunde und ist das primäre Ziel, wenn Sie verhindern möchten, dass Ihre Inhalte für Claudes Modelltraining verwendet werden. Der vollständige User-Agent-String lautet Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com).
Claude-User – Wird aktiviert, wenn Claude-Nutzer Echtzeit-Webzugriff anfordern; dieser Crawler holt Inhalte bedarfsgesteuert und in sehr geringem Umfang. Er respektiert Authentifizierung und versucht nicht, Zugriffsbeschränkungen zu umgehen, was ihn ressourcenschonend macht.
Claude-SearchBot – Unterstützt Claudes interne Suchfunktionen, sodass Ihre Inhalte in Claudes Suchergebnissen erscheinen, wenn Nutzer Fragen stellen. Dieser Crawler arbeitet mit sehr geringem Volumen und dient primär der Indexierung, nicht dem Training.
Ein zentrales Problem bei Anthropics Crawlern ist das Crawl-zu-Referenz-Verhältnis: Cloudflare-Daten zeigen, dass für jede Weiterleitung, die Anthropic auf eine Website sendet, seine Crawler bereits etwa 38.000 bis 70.000 Seiten besucht haben. Dieses massive Ungleichgewicht bedeutet, dass Ihre Inhalte weit aggressiver konsumiert als zitiert werden – eine wichtige Frage hinsichtlich fairer Vergütung für die Nutzung von Inhalten.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Googles AI-Trainings-Crawler
Googles Ansatz beim AI-Crawling unterscheidet sich deutlich von dem der Konkurrenz, da das Unternehmen eine strikte Trennung zwischen Suchindexierung und AI-Training einhält. Google-Extended ist der spezielle Crawler, der Daten für das Training von Gemini (ehemals Bard) und andere Google-AI-Produkte sammelt – völlig separat vom traditionellen Googlebot:
Der User-Agent-String für Google-Extended lautet: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0. Diese Trennung ist beabsichtigt und für Website-Betreiber vorteilhaft, da Sie Google-Extended per robots.txt blockieren können, ohne Ihre Sichtbarkeit in der Google-Suche zu beeinträchtigen. Google gibt offiziell an, dass das Blockieren von Google-Extended keinerlei Einfluss auf Suchrankings oder die Aufnahme in AI Overviews hat, obwohl einige Webmaster Bedenken äußern, die man im Auge behalten sollte. Gemini-Deep-Research ist ein weiterer Google-Crawler, der Geminis Research-Feature unterstützt, mit sehr geringem Volumen und minimaler Serverlast. Ein bedeutender technischer Vorteil von Googles Crawlern ist ihre Fähigkeit, JavaScript auszuführen und dynamische Inhalte zu rendern – im Gegensatz zu den meisten Mitbewerbern. Das bedeutet, dass Google-Extended React-, Vue- und Angular-Anwendungen effektiv crawlen kann, während OpenAIs GPTBot und Anthropics ClaudeBot dazu nicht in der Lage sind. Für Betreiber von JavaScript-lastigen Anwendungen ist dieser Unterschied für die AI-Sichtbarkeit entscheidend.
Weitere wichtige AI-Crawler
Neben den Technologieriesen betreiben zahlreiche andere Organisationen AI-Crawler, die Beachtung verdienen. Meta-ExternalAgent, still und leise im Juli 2024 gestartet, durchsucht Webinhalte zum Training von Metas AI-Modellen und zur Verbesserung der Produkte von Facebook, Instagram und WhatsApp. Dieser Crawler arbeitet mit etwa 1100 Seiten pro Stunde und erhält trotz seines aggressiven Verhaltens weniger öffentliche Aufmerksamkeit als andere. Bytespider, von ByteDance (TikToks Muttergesellschaft) betrieben, hat sich seit seinem Start im April 2024 als einer der aggressivsten Crawler im Internet etabliert. Dritthersteller-Monitoring deutet darauf hin, dass Bytespider weit aggressiver crawlt als GPTBot oder ClaudeBot, wobei genaue Faktoren variieren. Einige Berichte legen nahe, dass er robots.txt-Anweisungen nicht immer konsequent beachtet, weshalb IP-basierte Blockierung zuverlässiger ist.
Perplexitys Crawler umfassen PerplexityBot für die Suchindexierung und Perplexity-User für das Echtzeit-Abrufen von Inhalten. Perplexity steht im Verdacht, robots.txt-Anweisungen zu ignorieren, auch wenn das Unternehmen die Einhaltung behauptet. Amazonbot treibt Alexas Frage-Antwort-Fähigkeiten an, respektiert das robots.txt-Protokoll und arbeitet mit etwa 1050 Seiten pro Stunde. Applebot-Extended, eingeführt im Juni 2024, entscheidet darüber, wie bereits von Applebot indexierte Inhalte für das AI-Training von Apple verwendet werden – crawlt jedoch keine Webseiten direkt. CCBot, betrieben von Common Crawl (einer Non-Profit-Organisation), erstellt offene Webarchive, die von mehreren AI-Unternehmen wie OpenAI, Google, Meta und Hugging Face genutzt werden. Neue Crawler von Unternehmen wie xAI (Grok), Mistral und DeepSeek tauchen zunehmend in Serverlogs auf und signalisieren einen weiteren Ausbau des AI-Crawler-Ökosystems.
Vollständige AI-Crawler-Referenztabelle
Nachfolgend finden Sie eine umfassende Referenztabelle verifizierter AI-Crawler, deren Zwecke, User-Agent-Strings und robots.txt-Blockiersyntax. Diese Tabelle wird regelmäßig anhand von Serverlog-Analysen und offizieller Dokumentation aktualisiert. Jeder Eintrag wurde – sofern möglich – anhand offizieller IP-Listen geprüft:
Crawler-Name
Unternehmen
Zweck
User-Agent
Crawl-Rate
IP-Verifizierung
Robots.txt-Syntax
GPTBot
OpenAI
Trainingsdatensammlung
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
100/Stunde
✓ Offiziell
User-agent: GPTBot Disallow: /
ChatGPT-User
OpenAI
Echtzeit-Benutzeranfragen
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0
2400/Stunde
✓ Offiziell
User-agent: ChatGPT-User Disallow: /
OAI-SearchBot
OpenAI
Suchindexierung
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3
150/Stunde
✓ Offiziell
User-agent: OAI-SearchBot Disallow: /
ClaudeBot
Anthropic
Trainingsdatensammlung
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
500/Stunde
✓ Offiziell
User-agent: ClaudeBot Disallow: /
Claude-User
Anthropic
Echtzeit-Webzugriff
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0)
<10/Stunde
✗ Nicht verfügbar
User-agent: Claude-User Disallow: /
Claude-SearchBot
Anthropic
Suchindexierung
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0)
<10/Stunde
✗ Nicht verfügbar
User-agent: Claude-SearchBot Disallow: /
Google-Extended
Google
Gemini AI-Training
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0)
Variabel
✓ Offiziell
User-agent: Google-Extended Disallow: /
Gemini-Deep-Research
Google
Research-Feature
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research)
<10/Stunde
✓ Offiziell
User-agent: Gemini-Deep-Research Disallow: /
Bingbot
Microsoft
Bing-Suche & Copilot
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0)
Nicht alle AI-Crawler dienen demselben Zweck, und diese Unterscheidungen zu kennen ist entscheidend für fundierte Blockierentscheidungen. Trainings-Crawler machen rund 80 % des gesamten AI-Bot-Traffics aus und sammeln Inhalte gezielt zum Aufbau von Datensätzen für große Sprachmodelle. Sobald Ihre Inhalte in ein Trainingsdatenset aufgenommen wurden, werden sie Teil des permanenten Wissens des Modells – was eventuell dazu führt, dass Nutzer Ihre Seite nicht mehr für Antworten besuchen müssen. Trainings-Crawler wie GPTBot, ClaudeBot und Meta-ExternalAgent arbeiten mit hohem Volumen und systematischen Crawling-Mustern, liefern aber kaum oder gar keinen Referral-Traffic an Publisher zurück.
Such- und Zitations-Crawler indexieren Inhalte für AI-gestützte Sucherlebnisse und können tatsächlich etwas Traffic durch Zitationen zurücksenden. Wenn Nutzer Fragen in ChatGPT oder Perplexity stellen, helfen diese Crawler, relevante Quellen anzuzeigen. Im Gegensatz zu Trainings-Crawlern arbeiten Such-Crawler wie OAI-SearchBot und PerplexityBot mit mittlerem Volumen, retrieval-orientiertem Verhalten und bieten oft Attribution und Links. Nutzergetriggerte Fetcher werden nur aktiviert, wenn Nutzer gezielt Inhalte über AI-Assistenten anfordern. Wenn jemand eine URL in ChatGPT einfügt oder Perplexity bittet, eine bestimmte Seite zu analysieren, holen diese Fetcher die Inhalte auf Abruf. Nutzergetriggerte Fetcher arbeiten mit sehr geringem Volumen und vereinzelten Anfragen – nicht automatisiert – und laut AI-Unternehmen werden sie nicht für das Modelltraining verwendet. Diese Kategorisierung hilft Ihnen, strategisch zu entscheiden, welche Crawler Sie zulassen und welche blockieren – abgestimmt auf Ihre Geschäftsziele.
So identifizieren Sie Crawler auf Ihrer Seite
Der erste Schritt im AI-Crawler-Management ist zu wissen, welche Crawler Ihre Website tatsächlich besuchen. Ihre Serverzugriffsprotokolle enthalten detaillierte Aufzeichnungen jeder Anfrage, einschließlich des User-Agent-Strings, der den Crawler identifiziert. Die meisten Hosting-Kontrollpanels bieten Protokollanalysetools, Sie können aber auch Rohprotokolle direkt einsehen. Bei Apache-Servern finden Sie die Protokolle meist unter /var/log/apache2/access.log, bei Nginx unter /var/log/nginx/access.log. Mit grep können Sie die Protokolle nach Crawler-Aktivitäten filtern:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
Dieser Befehl zeigt die 20 letzten Anfragen großer AI-Crawler. Die Google Search Console bietet Statistik zu Google-Bots, allerdings nur für Google-Crawler. Cloudflare Radar liefert globale Einblicke in AI-Bot-Traffic-Muster und hilft herauszufinden, welche Crawler besonders aktiv sind. Um zu prüfen, ob ein Crawler legitim oder gefälscht ist, vergleichen Sie die Anforderungs-IP mit offiziellen IP-Listen großer Unternehmen. OpenAI veröffentlicht verifizierte IPs unter https://openai.com/gptbot.json, Amazon unter https://developer.amazon.com/amazonbot/ip-addresses/, und andere pflegen ähnliche Listen. Ein gefälschter Crawler, der einen legitimen User-Agent von einer nicht verifizierten IP-Adresse vortäuscht, sollte sofort blockiert werden, da er vermutlich böswilliges Scraping betreibt.
robots.txt-Implementierungsleitfaden
Die robots.txt-Datei ist Ihr zentrales Werkzeug zur Steuerung des Crawler-Zugriffs. Diese einfache Textdatei, im Root-Verzeichnis Ihrer Website abgelegt, gibt Crawlern an, welche Bereiche Ihrer Seite sie betreten dürfen. Um spezifische AI-Crawler zu blockieren, fügen Sie Einträge wie diese hinzu:
Dies weist GPTBot an, 10 Sekunden zwischen Anfragen zu warten und das private Verzeichnis zu meiden. Für einen ausgewogenen Ansatz, bei dem Such-Crawler erlaubt und Trainings-Crawler blockiert werden:
Die meisten seriösen AI-Crawler respektieren robots.txt-Anweisungen, einige aggressive Crawler ignorieren sie jedoch komplett. Deshalb ist robots.txt allein für einen vollständigen Schutz nicht ausreichend.
Erweiterte Blockierungsstrategien
Robots.txt ist nur eine Empfehlung, keine Durchsetzung – Crawler können Ihre Anweisungen ignorieren, wenn sie möchten. Für stärkeren Schutz gegen Crawler, die robots.txt ignorieren, setzen Sie IP-basierte Blockierung auf Serverebene ein. Dieses Vorgehen ist sicherer, da das Fälschen einer IP-Adresse schwieriger ist als das Vortäuschen eines User-Agents. Sie können verifizierte IPs aus offiziellen Quellen auf die Allowlist setzen und alle anderen Anfragen, die sich als AI-Crawler ausgeben, blockieren.
Für Apache-Server nutzen Sie .htaccess-Regeln, um Crawler serverseitig zu blockieren:
Dies liefert eine 403-Forbidden-Antwort an passende User-Agents, unabhängig von robots.txt. Firewall-Regeln bieten eine zusätzliche Schutzebene, indem Sie verifizierte IP-Bereiche aus offiziellen Quellen zulassen und alle anderen blockieren. Die meisten Web Application Firewalls und Hosting-Anbieter ermöglichen Regeln, die nur Anfragen von verifizierten IPs erlauben und andere blockieren. HTML-Meta-Tags bieten granulare Kontrolle auf Seitenebene. Amazon und einige andere Crawler respektieren das noarchive-Attribut:
<metaname="robots"content="noarchive">
Dies weist Crawler an, die Seite nicht für das Modelltraining zu verwenden, aber ggf. andere Indexierungsfunktionen zuzulassen. Wählen Sie die Blockiermethode je nach technischer Kompetenz und Ziel-Crawler. IP-Blockierung ist am zuverlässigsten, aber technisch aufwendiger; robots.txt ist am einfachsten, aber gegen nicht regelkonforme Crawler weniger effektiv.
Überwachung und Verifizierung
Das Implementieren von Crawler-Blockaden ist nur die halbe Miete – Sie müssen überprüfen, ob sie tatsächlich greifen. Regelmäßiges Monitoring hilft, Probleme frühzeitig zu erkennen und neue, bislang unbekannte Crawler zu identifizieren. Kontrollieren Sie Ihre Serverprotokolle wöchentlich auf ungewöhnliche Bot-Aktivitäten, insbesondere auf User-Agent-Strings mit Begriffen wie “bot”, “crawler”, “spider” oder Firmennamen wie “GPT”, “Claude” oder “Perplexity”. Richten Sie Alerts für plötzliche Anstiege beim Bot-Traffic ein, die auf neue Crawler oder aggressives Verhalten bestehender Bots hindeuten. Google Search Console zeigt Crawl-Statistiken für Google-Bots und hilft, Googlebot- und Google-Extended-Aktivitäten zu überwachen. Cloudflare Radar bietet globale Einblicke in AI-Crawler-Traffic und hilft, neue Crawler zu identifizieren.
Um zu überprüfen, ob Ihre robots.txt-Blockaden funktionieren, rufen Sie die Datei direkt unter ihredomain.de/robots.txt auf und kontrollieren Sie, ob alle User-Agents und Anweisungen korrekt gelistet sind. Für serverseitige Blockaden überwachen Sie Ihre Zugriffsprotokolle auf Anfragen von blockierten Crawlern. Wenn Sie trotzdem Anfragen von blockierten Crawlern sehen, ignorieren diese entweder Ihre Anweisungen oder fälschen ihren User-Agent. Testen Sie Ihre Implementierung, indem Sie die Crawler-Zugriffe in Ihren Analytics und Serverprotokollen prüfen. Vierteljährliche Überprüfungen sind essenziell, da sich die AI-Crawler-Landschaft schnell wandelt. Neue Crawler tauchen regelmäßig auf, bestehende Crawler ändern ihren User-Agent, und Unternehmen führen neue Bots ohne Vorankündigung ein. Planen Sie regelmäßige Überprüfungen Ihrer Blockliste, um Ergänzungen zu erkennen und Ihre Implementierung aktuell zu halten.
AI-Zitationen mit AmICited.com verfolgen
Während das Crawler-Management wichtig ist, ist es ebenso entscheidend zu wissen, wie AI-Systeme Ihre Inhalte tatsächlich zitieren und referenzieren. AmICited.com bietet umfassendes Monitoring, wie Ihre Marke und Inhalte in AI-generierten Antworten bei ChatGPT, Perplexity, Google Gemini und anderen AI-Plattformen erscheinen. Statt nur Crawler zu blockieren, hilft Ihnen AmICited.com, die tatsächliche Auswirkung von AI-Crawlern auf Ihre Sichtbarkeit und Autorität zu verstehen. Die Plattform verfolgt, welche AI-Systeme Ihre Inhalte zitieren, wie häufig Ihre Marke in AI-Antworten erscheint und wie sich diese Sichtbarkeit auf Traffic und Autorität auswirkt. Durch das Monitoring Ihrer AI-Zitate können Sie fundierte Entscheidungen darüber treffen, welche Crawler Sie auf Basis echter Sichtbarkeitsdaten zulassen – und nicht nur auf Annahmen. AmICited.com lässt sich in Ihre gesamte Content-Strategie integrieren und zeigt Ihnen, welche Themen und Inhaltstypen die meisten AI-Zitate generieren. Dieser datengetriebene Ansatz hilft, Ihre Inhalte für AI-Entdeckung zu optimieren und zugleich Ihr wertvollstes geistiges Eigentum zu schützen. Mit Ihren AI-Zitationsmetriken treffen Sie strategische Entscheidungen über die Crawler-Freigabe, die zu Ihren Unternehmenszielen passen.
Entscheidung: Blockieren oder zulassen?
Ob Sie AI-Crawler zulassen oder blockieren, hängt ganz von Ihrer geschäftlichen Situation und Ihren Prioritäten ab. Lassen Sie AI-Crawler zu, wenn: Sie eine Nachrichten- oder Blog-Seite betreiben, bei der Sichtbarkeit in AI-Antworten viel Traffic bringt; Ihr Unternehmen davon profitiert, als Quelle in AI-generierten Antworten genannt zu werden; Sie am AI-Training teilnehmen möchten, um das Modellverständnis Ihrer Branche mitzuprägen; oder Sie damit einverstanden sind, dass Ihre Inhalte für AI-Entwicklung genutzt werden. Nachrichtenverlage, Bildungsanbieter und Thought Leader profitieren oft von AI-Sichtbarkeit, weil Zitate Traffic und Autorität schaffen.
Blockieren Sie AI-Crawler, wenn: Sie proprietäre Inhalte oder Geschäftsgeheimnisse schützen möchten, Ihnen Serverressourcen fehlen, um aggressives Crawling zu verkraften, Sie sich Sorgen um unentgeltliche Content-Nutzung machen, Sie die Kontrolle über Ihr geistiges Eigentum behalten wollen oder Performance-Probleme durch Bot-Traffic hatten. E-Commerce-Seiten mit Produktinfos, SaaS-Unternehmen mit proprietärer Doku und Publisher mit Paywall-Inhalten blockieren häufig Trainings-Crawler. Der zentrale Trade-off ist der zwischen Content-Schutz und Sichtbarkeit auf AI-gestützten Discovery-Plattformen. Trainings-Crawler zu blockieren schützt Ihre Inhalte, kann aber Ihre Sichtbarkeit in AI-Antworten verringern. Suchcrawler zu blockieren mindert Ihre Präsenz in AI-gestützten Suchergebnissen. Viele Publisher verfolgen einen selektiven Blockieransatz: Sie erlauben Such- und Zitations-Crawler wie OAI-SearchBot und PerplexityBot, blockieren aber aggressive Trainings-Crawler wie GPTBot und ClaudeBot. So erreichen sie Sichtbarkeit in AI-Suchergebnissen und schützen sich vor unbegrenzter Trainingsdatennutzung. Ihre Entscheidung sollte zu Geschäftsmodell, Content-Strategie und Ressourcen passen.
Neue Crawler und kommende Trends
Das AI-Crawler-Ökosystem wächst rasant, da ständig neue Unternehmen auf den Markt drängen und bestehende Akteure weitere Bots launchen. xAIs Grok-Crawler taucht bereits in Serverlogs auf, da das Unternehmen seine AI-Plattform skaliert. Mistrals MistralAI-User-Crawler unterstützt das Echtzeit-Fetching für den Mistr
Häufig gestellte Fragen
Was ist der Unterschied zwischen AI-Crawlern und Suchmaschinen-Crawlern?
AI-Crawler wie GPTBot und ClaudeBot sammeln Inhalte speziell zum Training großer Sprachmodelle, während Suchmaschinen-Crawler wie Googlebot Inhalte indexieren, damit Menschen sie über Suchergebnisse finden können. AI-Crawler speisen die Wissensdatenbanken von AI-Systemen, während Such-Crawler Benutzern helfen, Ihre Inhalte zu entdecken. Der entscheidende Unterschied liegt im Zweck: Training versus Auffindbarkeit.
Beeinträchtigt das Blockieren von AI-Crawlern mein Suchmaschinenranking?
Nein, das Blockieren von AI-Crawlern beeinflusst Ihr traditionelles Suchranking nicht. AI-Crawler wie GPTBot und ClaudeBot sind völlig unabhängig von Suchmaschinen-Crawlern wie Googlebot. Sie können Google-Extended (für AI-Training) blockieren und gleichzeitig Googlebot (für die Suche) zulassen. Jeder Crawler hat einen anderen Zweck, und das Blockieren eines Crawlers wirkt sich nicht auf den anderen aus.
Wie erkenne ich, welche AI-Crawler meine Website besuchen?
Überprüfen Sie Ihre Serverzugriffsprotokolle, um zu sehen, welche User-Agents Ihre Website besuchen. Suchen Sie in den User-Agent-Strings nach Bot-Namen wie GPTBot, ClaudeBot, CCBot und Bytespider. Die meisten Hosting-Kontrollpanels bieten Protokollanalyse-Tools. Sie können auch die Google Search Console nutzen, um Crawl-Aktivitäten zu überwachen, allerdings werden dort nur Google-Crawler angezeigt.
Respektieren alle AI-Crawler die robots.txt-Anweisungen?
Nicht alle AI-Crawler respektieren robots.txt gleichermaßen. OpenAI's GPTBot, Anthropics ClaudeBot und Google-Extended halten sich in der Regel an robots.txt-Regeln. Bytespider und PerplexityBot stehen im Verdacht, robots.txt-Anweisungen nicht immer konsequent zu beachten. Bei Crawlern, die robots.txt nicht respektieren, müssen Sie IP-basierte Blockierungen auf Serverebene über Ihre Firewall oder .htaccess-Datei implementieren.
Sollte ich alle AI-Crawler oder nur Trainings-Crawler blockieren?
Die Entscheidung hängt von Ihren Zielen ab. Blockieren Sie Trainings-Crawler, wenn Sie proprietäre Inhalte oder begrenzte Serverressourcen haben. Lassen Sie Such-Crawler zu, wenn Sie Sichtbarkeit in AI-gestützten Suchergebnissen und Chatbots wünschen, was Traffic bringen und Autorität aufbauen kann. Viele Unternehmen wählen einen selektiven Ansatz, indem sie bestimmte Crawler zulassen und aggressive wie Bytespider blockieren.
Wie oft sollte ich meine AI-Crawler-Blockliste aktualisieren?
Es kommen regelmäßig neue AI-Crawler hinzu, daher sollten Sie Ihre Blockliste mindestens vierteljährlich überprüfen und aktualisieren. Verfolgen Sie Ressourcen wie das ai.robots.txt-Projekt auf GitHub für Community-gepflegte Listen. Überprüfen Sie monatlich Ihre Serverprotokolle, um neue Crawler zu identifizieren, die in Ihrer aktuellen Konfiguration noch nicht enthalten sind. Die AI-Crawler-Landschaft entwickelt sich schnell und Ihre Strategie sollte sich entsprechend anpassen.
Kann ich überprüfen, ob ein Crawler legitim oder gefälscht ist?
Ja, vergleichen Sie die Anforderungs-IP-Adresse mit offiziellen IP-Listen, die von großen Unternehmen veröffentlicht werden. OpenAI veröffentlicht verifizierte IPs unter https://openai.com/gptbot.json, Amazon unter https://developer.amazon.com/amazonbot/ip-addresses/, und andere pflegen ähnliche Listen. Ein Crawler, der einen legitimen User-Agent von einer nicht verifizierten IP-Adresse vortäuscht, sollte sofort blockiert werden, da es sich wahrscheinlich um schädliches Scraping handelt.
Welchen Einfluss haben AI-Crawler auf die Performance meiner Website?
AI-Crawler können erhebliche Bandbreite und Serverressourcen verbrauchen. Bytespider und Meta-ExternalAgent gehören zu den aggressivsten Crawlern. Einige Publisher berichten, dass sie den Bandbreitenverbrauch von 800 GB auf 200 GB täglich durch das Blockieren von AI-Crawlern senken konnten, was etwa 1.500 $ pro Monat spart. Überwachen Sie Ihre Serverressourcen während Spitzenzeiten und setzen Sie bei Bedarf Ratenbegrenzungen für aggressive Bots ein.
Übernehmen Sie die Kontrolle über Ihre AI-Sichtbarkeit
Verfolgen Sie, welche AI-Crawler Ihre Inhalte zitieren, und optimieren Sie Ihre Sichtbarkeit in ChatGPT, Perplexity, Google Gemini und mehr.
Was ist die Crawlhäufigkeit für KI-Suche? Das Verhalten von KI-Bots verstehen
Erfahren Sie, wie KI-Suchcrawler die Crawlhäufigkeit für Ihre Website bestimmen. Entdecken Sie, wie ChatGPT, Perplexity und andere KI-Engines Inhalte anders cra...
Der vollständige Leitfaden zum Blockieren (oder Zulassen) von KI-Crawlern
Erfahren Sie, wie Sie KI-Crawler wie GPTBot und ClaudeBot mit robots.txt, serverseitiger Blockierung und erweiterten Schutzmethoden blockieren oder zulassen. Vo...
Server-seitiges Rendering vs. CSR: Auswirkungen auf die KI-Sichtbarkeit
Erfahren Sie, wie SSR- und CSR-Rendering-Strategien die Sichtbarkeit für KI-Crawler, Markenzitate in ChatGPT und Perplexity sowie Ihre gesamte Präsenz in der KI...
8 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.