
Entity Recognition
Entity Recognition ist eine KI-NLP-Fähigkeit zur Identifizierung und Kategorisierung benannter Entitäten im Text. Erfahren Sie, wie sie funktioniert, ihre Anwen...
9 Min. Lesezeit

Erkunden Sie, wie KI-Systeme Entitäten im Text erkennen und verarbeiten. Erfahren Sie mehr über NER-Modelle, Transformer-Architekturen und reale Anwendungen des Entitätenverständnisses.
Das Verständnis von Entitäten ist zu einer Eckpfeiler-Fähigkeit moderner KI-Systeme geworden und ermöglicht es Maschinen, die wichtigsten Akteure, Orte und Konzepte in unstrukturiertem Text zu identifizieren und zu verstehen. Von Suchmaschinen, die die Nutzerintention erfassen, bis hin zu Chatbots, die komplexe Fragen zu bestimmten Personen und Organisationen beantworten können, bildet die Entitätenerkennung die Grundlage für eine sinnvolle Mensch-Computer-Interaktion. Diese technische Fähigkeit ist branchenübergreifend kritisch – Finanzinstitute nutzen sie für Compliance-Monitoring, Gesundheitssysteme für das Management von Patientendaten und E-Commerce-Plattformen, um Produktnennungen und Kundenfeedback zu verstehen. Zu wissen, wie KI-Systeme Entitäten extrahieren und interpretieren, ist für alle, die NLP-Anwendungen in produktiven Umgebungen entwickeln oder einführen, unerlässlich.
Named Entity Recognition (NER) ist die NLP-Aufgabe, benannte Entitäten – spezifische, bedeutungsvolle Informationseinheiten – im Text zu identifizieren und in vordefinierte Kategorien zu klassifizieren. Diese Entitäten repräsentieren die konkreten Subjekte, die semantisches Gewicht in der Sprache tragen: Menschen, die handeln, Organisationen, die Entscheidungen treffen, Orte, an denen Ereignisse geschehen, Zeitangaben, die Ereignisse verankern, Geldwerte, die Transaktionen quantifizieren, und Produkte, die gekauft und verkauft werden. Die Klassifizierung von Entitäten ist wichtig, weil sie Rohtext in strukturierte Wissensdaten umwandelt, über die Maschinen nachdenken und auf deren Grundlage sie handeln können; ohne diese Fähigkeit kann ein System nicht zwischen „Apple das Unternehmen“ und „Apfel die Frucht“ unterscheiden oder verstehen, dass „John Smith“ und „J. Smith“ dieselbe Person bezeichnen. Die Fähigkeit, Entitäten korrekt zu klassifizieren, ermöglicht nachgelagerte Anwendungen wie Wissensgraphen, Informationsextraktion, Fragebeantwortung und Beziehungsdetektion.
| Entitätstyp | Definition | Beispiel |
|---|---|---|
| PERSON | Einzelne Menschen | “Steve Jobs”, “Marie Curie” |
| ORGANISATION | Unternehmen, Institutionen, Gruppen | “Microsoft”, “Vereinte Nationen”, “Harvard University” |
| ORT | Geografische Orte und Regionen | “New York”, “Amazonas”, “Silicon Valley” |
| DATUM | Zeitangaben und Zeiträume | “15. Januar 2024”, “nächster Dienstag”, “Q3 2023” |
| GELD | Geldwerte und Währungen | “50 Millionen $”, “100 €”, “5000 Yen” |
| PRODUKT | Waren, Dienstleistungen, Kreationen | “iPhone 15”, “Windows 11”, “ChatGPT” |
Moderne KI-Systeme verarbeiten Entitäten in einer mehrstufigen Pipeline, die mit der Tokenisierung beginnt – dem Aufteilen von Rohtext in diskrete Token, die als Grundeinheiten für die weitere Verarbeitung dienen. Jedes Token wird dann über Wort-Embeddings – dichte Vektoren, die semantische Bedeutung erfassen – in eine numerische Darstellung umgewandelt, die in neuronale Netzwerke eingespeist wird, die Kontext und Beziehungen verstehen. Transformer-basierte Modelle, die heute dominieren, verarbeiten ganze Sequenzen parallel statt sequentiell und können so Langstreckenabhängigkeiten und komplexe kontextuelle Beziehungen erfassen, die für genaues Entitätenverständnis entscheidend sind. Der Self-Attention-Mechanismus innerhalb von Transformern ermöglicht es jedem Token, die Bedeutung aller anderen Tokens in der Sequenz dynamisch zu gewichten, sodass reiche Kontextrepräsentationen entstehen, in denen die Bedeutung eines Wortes durch seinen umgebenden Kontext geprägt wird; so wird „Bank“ in „Flussufer“ anders verstanden als in „Sparkasse“. Vortrainierte Sprachmodelle wie BERT und GPT lernen allgemeine Sprachmuster aus riesigen Textkorpora, bevor sie auf Aufgaben der Entitätenerkennung feinabgestimmt werden, wodurch sie gelernte Repräsentationen von Syntax, Semantik und Weltwissen nutzen können. Die letzte Schicht von Entitätenerkennungssystemen arbeitet typischerweise mit einem Sequence-Labeling-Ansatz – oft als Conditional Random Field (CRF) oder einfacher Klassifikationskopf implementiert –, der jedem Token auf Basis der kontextuellen Repräsentationen der neuronalen Netze Entitätslabels zuweist. Diese Architektur ermöglicht es KI-Systemen, nicht nur zu verstehen, welche Entitäten vorhanden sind, sondern auch, wie sie zueinander stehen und welche Rollen sie im Kontext des Textes spielen.
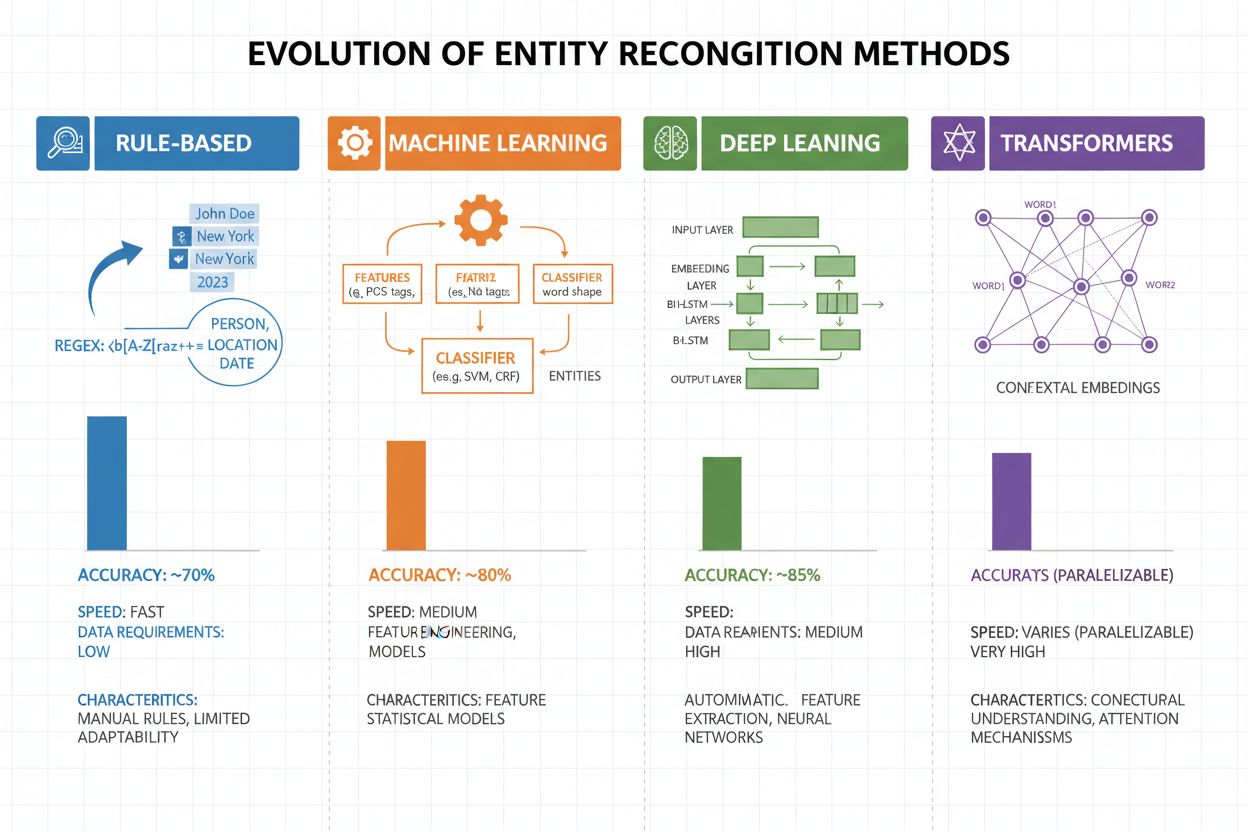
Entitätenerkennung hat sich in den letzten zwei Jahrzehnten dramatisch weiterentwickelt: von einfachen, regelbasierten Ansätzen zu hochentwickelten neuronalen Architekturen. Frühe Systeme arbeiteten mit handgefertigten Regeln und Wörterbüchern, nutzten reguläre Ausdrücke und Mustererkennung zur Identifikation von Entitäten – Methoden, die interpretierbar und mit wenig Trainingsdaten auskamen, aber schlecht generalisierten und wartungsintensiv waren. Mit dem Aufkommen des maschinellen Lernens kamen überwachte Ansätze wie Support Vector Machines (SVM) und Conditional Random Fields (CRF), die durch Feature Engineering aus gelabelten Daten lernten und die Genauigkeit deutlich verbesserten, aber weiterhin Experten für das Design sinnvoller Features benötigten. Deep-Learning-Methoden, insbesondere LSTMs und BiLSTMs, automatisierten die Merkmalsextraktion, indem sie Repräsentationen direkt aus Rohtext lernten, und erreichten deutlich höhere Genauigkeit ohne manuelles Feature Engineering, verlangten jedoch größere gelabelte Datensätze. Transformer-Modelle wie BERT und RoBERTa revolutionierten das Feld, indem sie mit Self-Attention Langstreckenabhängigkeiten und kontextuelle Nuancen erfassten, State-of-the-Art-Ergebnisse (BERT: 90,9 % F1 auf CoNLL-2003) erzielten und Transfer Learning von vortrainierten Modellen ermöglichten. Der Zielkonflikt zwischen Komplexität und Genauigkeit hat sich grundlegend verschoben: Während regelbasierte Systeme in ressourcenarmen Umgebungen und hochspezialisierten Domänen weiterhin wertvoll sind, dominieren Transformer-Modelle dort, wo ausreichende Rechenleistung und gelabelte Daten verfügbar sind. Leichtere Alternativen wie DistilBERT bieten einen Mittelweg für Produktionssysteme mit Latenzanforderungen.
Transformer-Modelle haben die Entitätenerkennung grundlegend verändert, indem sie die sequentielle Verarbeitung durch parallele Self-Attention-Mechanismen ersetzt haben, die alle Tokens eines Satzes gleichzeitig betrachten und so ein tieferes Kontextverständnis als bisherige Architekturen ermöglichen. BERT und seine Varianten (RoBERTa, DistilBERT, ALBERT) nutzen bidirektionales Pre-Training auf riesigen unlabeled Korpora, um universelle Sprachrepräsentationen zu lernen, die syntaktische und semantische Informationen erfassen, bevor sie auf NER-Aufgaben mit relativ kleinen gelabelten Datensätzen feinabgestimmt werden. Das Pre-Training-und-Feintuning-Paradigma ist besonders mächtig für die Entitätenerkennung: Modelle, die auf Milliarden von Tokens vortrainiert wurden, entwickeln robuste Repräsentationen von Sprachstrukturen und Entitätenmustern, die dann mit wenigen tausend gelabelten Beispielen domänenspezifisch angepasst werden können – das reduziert den Datenbedarf drastisch. Transformer brillieren beim Entitätenverständnis durch ihren Multi-Head-Attention-Mechanismus, der es unterschiedlichen Attention-Heads erlaubt, sich auf verschiedene Arten von Entitätenbeziehungen zu spezialisieren – manche Heads erfassen syntaktische Grenzen, andere semantische Assoziationen zwischen Entitäten und Kontext. Mehrsprachige Entitätenerkennung wurde durch Modelle wie mBERT und XLM-RoBERTa revolutioniert, die auf über 100 Sprachen gleichzeitig vortrainiert werden und Zero-Shot- und Few-Shot-Transfer für ressourcenarme Sprachen und cross-linguale Entity Linking ermöglichen. Neue Modelle wie GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) gehen noch weiter und ermöglichen instruktionsbasierte Entitätenerkennung, bei der Modelle beliebige Entitätentypen anhand natürlicher Sprachprompts erkennen können – ohne aufgabenspezifisches Feintuning. Das markiert den Wandel hin zu flexibleren, generalisierbaren Entitätenverständnissystemen.
Trotz erheblicher Fortschritte stehen Entitätenerkennungssysteme vor anhaltenden Praxisproblemen, wobei Mehrdeutigkeit und Kontextsensitivity zu den schwierigsten gehören – das Wort „Apple“ erfordert je nach Kontext das Verständnis, ob die Frucht oder das Technologieunternehmen gemeint ist, und selbst modernste Modelle tun sich mit solcher semantischen Disambiguierung in verrauschtem oder mehrdeutigem Text schwer. Unbekannte Entitäten (OOV) sind eine weitere fundamentale Herausforderung: Modelle, die auf Standarddatensätzen trainiert wurden, begegnen möglicherweise nie seltenen Entitäten, neuen Eigennamen oder falsch geschriebenen Varianten und klassifizieren diese dann falsch oder erkennen sie überhaupt nicht. Domänenanpassung bleibt problematisch, weil auf Nachrichtendaten trainierte Modelle (wie CoNLL-2003) bei biomedizinischen, juristischen oder Social-Media-Texten oft schlecht abschneiden – dort unterscheiden sich Entitätenverteilungen und Sprachmuster teils dramatisch und erfordern teure Neuannotationen und Feintuning für jede neue Domäne. Fehler bei der Grenzerkennung – Systeme erkennen zwar, dass eine Entität existiert, bestimmen aber Start- oder Endpunkt falsch – sind besonders häufig bei mehrwortigen Entitäten und verschachtelten Strukturen; so muss z. B. zwischen „New York City“ und „New York“ unterschieden oder mit Entitäten wie „Chief Executive Officer of Apple Inc.“ umgegangen werden. Mehrsprachige Komplexität verschärft die Herausforderungen, da verschiedene Sprachen unterschiedliche Groß- und Kleinschreibungen, morphologische Strukturen und Benennungsmuster aufweisen und auf Englisch trainierte Modelle in anders strukturierten Sprachen oft versagen. Datenknappheit für Spezialdomänen wie seltene Krankheiten, neue Technologien oder proprietäre Firmennomenklatur ist ein Engpass, da manuelle Annotation teuer ist – hier muss abgewogen werden zwischen akzeptierter geringerer Genauigkeit und Investition in domänenspezifische Datenaufbereitung.
Entitätenverständnis ist heute in vielen Branchen unverzichtbar und verändert, wie Organisationen Wert aus unstrukturiertem Text ziehen. Bei der Informationsextraktion und dem Aufbau von Wissensgraphen ermöglicht die Entitätenerkennung die automatische Befüllung strukturierter Datenbanken aus Dokumenten, was Suchmaschinen und Empfehlungssysteme antreibt, die Beziehungen zwischen Personen, Orten und Konzepten verstehen. Gesundheitsorganisationen nutzen Entitätenverständnis, um Medikamentennamen, Dosierungen, Symptome und Patientendaten aus klinischen Notizen zu erfassen – das verbessert die klinische Entscheidungsunterstützung und ermöglicht Pharmakovigilanzsystemen, Nebenwirkungen im großen Maßstab zu erkennen. Finanzinstitute extrahieren mit Entitätenerkennung Börsenticker, Geldwerte und Marktgeschehen aus Nachrichten und Berichten, sodass algorithmische Handelssysteme und Risikomanagement-Plattformen auf marktrelevante Informationen in Echtzeit reagieren können. Legal-Tech-Unternehmen setzen Entitätenverständnis ein, um automatisch Parteien, Daten, Verpflichtungen und Haftungsklauseln in Verträgen zu erkennen – das verkürzt die Durchsicht von Dokumenten von Wochen auf Stunden. Kundenservice- und Chatbot-Plattformen extrahieren mit Entitätenerkennung Benutzerabsichten und relevante Zusammenhänge – wie Bestellnummern, Produktnamen oder Problemtypen – und ermöglichen so präzisere Weiterleitung und schnellere Lösung. E-Commerce-Plattformen identifizieren mit Entitätenverständnis Produktnamen, Marken, Features und Spezifikationen aus Kundenrezensionen und Suchanfragen und verbessern so Produktsuche und Personalisierung. Content-Empfehlungssysteme nutzen Entitätenerkennung, um zu verstehen, mit welchen Entitäten Nutzer interagieren, und ermöglichen dadurch anspruchsvollere kollaborative Filterung und inhaltsbasierte Empfehlungen, die Engagement und Umsatz steigern.
Für die produktive Umsetzung eines Entitätenverständnissystems sind sorgfältige Datenaufbereitung, Modellwahl und Evaluation erforderlich. Beginnen Sie mit hochwertig annotierten Daten: Definieren Sie klare Entitätentypen, nutzen Sie Inter-Annotator-Agreement-Metriken für Konsistenz und streben Sie mindestens 500–1000 gelabelte Beispiele pro Entitätentyp an – domänenspezifische Anwendungen benötigen oft mehr. Die Modellwahl hängt von Ihren Anforderungen ab: Regelbasierte Systeme bieten Interpretierbarkeit und niedrige Latenz für klar definierte Domänen, klassische ML-Modelle (CRF, SVM) liefern gute Ergebnisse mit moderaten Datenmengen, während Transformer-Modelle (BERT, RoBERTa) State-of-the-Art-Genauigkeit bieten, aber mehr Rechenleistung und Daten verlangen. Trainings- und Feintuning-Strategien sollten Data Augmentation gegen Klassenungleichgewicht, Kreuzvalidierung gegen Overfitting und sorgfältiges Hyperparameter-Tuning (Learning Rate, Batch-Größe) umfassen. Evaluieren Sie Ihr System mit Precision (korrekt erkannte Entitäten), Recall (gefundene Entitäten im Verhältnis zu allen vorhandenen) und F1-Score (harmonisches Mittel), jeweils separat nach Entitätentyp, um Schwachstellen zu identifizieren. Für den Betrieb sind Latenzanforderungen (Batch- vs. Echtzeitverarbeitung), Skalierbarkeit und Integration in bestehende Datenpipelines zu beachten; nach dem Rollout sollte die Überwachung von Performance-Drift, False-Positive-Raten und Nutzerfeedback Retraining-Zyklen anstoßen.
Das Ökosystem der Entitätenverständnis-Tools bietet Lösungen für jeden Maßstab und Anwendungsfall. Open-Source-Bibliotheken wie spaCy stellen produktionsreife NER-Pipelines mit starker Performance (89,22 % F1 auf Standardbenchmarks) und hervorragender Dokumentation bereit – ideal für Teams mit ML-Expertise; NLTK ist lehrreich und bietet grundlegende NER-Funktionen; Hugging Face Transformers ermöglicht den Zugriff auf State-of-the-Art-vortrainierte Modelle, die mit wenig Code domänenspezifisch feinabgestimmt werden können. Cloudbasierte Managed Services nehmen Infrastrukturprobleme ab: Google Cloud Natural Language API, AWS Comprehend und IBM Watson NLP bieten vortrainierte Entitätenerkennung mit Unterstützung für mehrere Sprachen und Typen, skalieren automatisch und integrieren sich nahtlos in Cloud-Datenpipelines. Spezialisierte Frameworks wie Flair (auf PyTorch-Basis, mit starker Sequence-Labeling-Unterstützung) und DeepPavlov (mit vortrainierten Modellen für viele Sprachen und Domänen) richten sich an Forscher und Teams mit Bedarf an mehr Customizing als bei Standardbibliotheken. Die Entscheidung zwischen Eigenentwicklung und Einsatz von Fertiglösungen hängt ab von Datensensibilität (On-Premises vs. Cloud), benötigter Genauigkeit, Domänenspezifik und Teamkompetenz: Nutzen Sie Managed APIs für allgemeine Anwendungen mit Standardtypen, Open-Source-Lösungen für domänenspezifische Anpassungen mit internen Daten und Eigenentwicklungen nur, wenn bestehende Lösungen Genauität oder Latenzanforderungen nicht erfüllen können.
Die Zukunft des Entitätenverständnisses wird von großen Sprachmodellen geprägt, die der Aufgabe beispiellose Flexibilität und Performance verleihen. Modelle wie GPT-4 und Claude zeigen beeindruckende Few-Shot- und Zero-Shot-Entitätenerkennung, sodass Organisationen benutzerdefinierte Entitätentypen mit wenigen Beispielen oder sogar nur durch natürliche Sprachbeschreibungen erkennen können – das reduziert den Annotierungsaufwand drastisch und beschleunigt den Mehrwert. Multimodales Entitätenverständnis entwickelt sich als neues Feld und kombiniert Text, Bilder und strukturierte Daten, um Entitäten in Dokumenten, Rechnungen und Webseiten mit reicherem Kontext zu erkennen – das ermöglicht Anwendungen wie automatisierte Dokumentenverarbeitung und visuelle Suche. Echtzeitverarbeitung wird durch Modelldistillation und Edge-Deployment immer besser und macht anspruchsvolle Entitätenerkennung auf Mobil- und IoT-Geräten möglich – das eröffnet neue Anwendungen in Augmented Reality, Echtzeitübersetzung und autonomen Systemen. Domänenspezifisches Feintuning bringt spezialisierte Modelle für Biomedizin, Recht und Finanzen hervor, die allgemeine Modelle um Größenordnungen übertreffen – dank domänenadaptivem Pre-Training und Transfer Learning ist das immer leichter zugänglich. Mit der Reife dieser Technologien wird Entitätenverständnis zur unsichtbaren Basisschicht von KI-Systemen, die Maschinen ein menschenähnliches semantisches Weltverständnis ermöglicht – und neue Möglichkeiten eröffnet, die wir erst zu erahnen beginnen.
Da KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews immer stärker in die Informationsbeschaffung und -nutzung integriert werden, ist es entscheidend zu verstehen, wie diese Systeme Entitäten – einschließlich Ihrer Marke – erkennen und referenzieren. Entitätenverständnis ist der Mechanismus, mit dem KI-Systeme Erwähnungen von Unternehmen, Produkten, Personen und Konzepten identifizieren und verarbeiten. Durch die Überwachung, wie KI-Systeme Ihre Marke mittels Entitätenerkennung verstehen und referenzieren, gewinnen Sie Einblicke in:
Genau das überwacht AmICited – indem verfolgt wird, wie KI-Systeme Ihre Marke als Entität auf verschiedenen KI-Plattformen erkennen und referenzieren. Wenn Sie Entitätenerkennung verstehen, verstehen Sie auch besser, wie KI-Systeme Ihr Unternehmen wahrnehmen und kommunizieren.
Entitätenerkennung (NER) identifiziert und klassifiziert Entitäten im Text (z. B. 'Apple' als ORGANISATION), während Entity Linking diese Entitäten mit Wissensbasen oder kanonischen Referenzen verbindet (z. B. Verlinkung von 'Apple' mit der Wikipedia-Seite von Apple Inc.). Die Entitätenerkennung ist der erste Schritt; Entity Linking fügt semantische Verankerung hinzu.
Moderne, auf Transformern basierende Modelle wie BERT erreichen 90,9 % F1-Score auf Standard-Benchmarks wie CoNLL-2003. Die Genauigkeit variiert jedoch stark je nach Domäne – Modelle, die auf Nachrichten trainiert wurden, schneiden bei biomedizinischen oder sozialen Medientexten schlecht ab. Die tatsächliche Genauigkeit hängt stark von der Domänenanpassung und der Datenqualität ab.
Ja, mehrsprachige Modelle wie mBERT und XLM-RoBERTa unterstützen über 100 Sprachen gleichzeitig. Die Leistung variiert jedoch je nach Sprache aufgrund von Unterschieden bei Großschreibung, Morphologie und verfügbaren Trainingsdaten. Sprachspezifische Modelle übertreffen in kritischen Anwendungen typischerweise mehrsprachige Modelle.
Regelbasierte Systeme verwenden handgefertigte Muster und Wörterbücher (schnell, interpretierbar, aber fragil). ML-basierte Systeme lernen aus gelabelten Daten (flexibler, bessere Generalisierung, benötigen aber Trainingsdaten und Feature-Engineering). Moderne Deep-Learning-Ansätze automatisieren die Merkmalextraktion und erreichen überlegene Genauigkeit.
Regelbasierte Systeme benötigen nur Musterdefinitionen. Traditionelle ML-Modelle erfordern 300–500 gelabelte Beispiele. Transformer-Modelle funktionieren mit 800+ Beispielen, profitieren aber von Transfer Learning – vortrainierte Modelle erzielen durch Feintuning mit nur 100–200 domänenspezifischen Beispielen gute Ergebnisse.
Zentrale Herausforderungen sind: Mehrdeutigkeit (dasselbe Wort mit unterschiedlichen Bedeutungen), unbekannte Entitäten, Domänenanpassung (Modelle, die auf einer Domäne trainiert wurden, versagen in einer anderen), Fehler bei der Grenzerkennung, Mehrsprachigkeit und Datenknappheit für spezialisierte Domänen. Diese erfordern sorgfältiges Systemdesign und domänenspezifisches Feintuning.
Kontext ist entscheidend – 'Bank' bedeutet in 'Flussufer' etwas anderes als in 'Sparkasse'. Moderne Transformer verwenden Self-Attention, um den Kontext aller umgebenden Tokens zu gewichten, sodass sie Entitäten auf Grundlage des linguistischen und semantischen Kontexts disambiguieren können. Schlechte Kontextverarbeitung ist eine Hauptfehlerquelle bei der Entitätenerkennung.
Zukünftige Entwicklungen umfassen: große Sprachmodelle, die Zero-Shot-Entitätenerkennung ermöglichen, multimodales Verständnis durch Kombination von Text und Bildern, Echtzeitverarbeitung auf Edge-Geräten und Fortschritte beim domänenspezifischen Feintuning. Entitätenverständnis wird zur unsichtbaren Basisschicht, die Maschinen ein menschenähnliches semantisches Weltverständnis ermöglicht.
AmICited verfolgt Entitäten-Erwähnungen in KI-Systemen wie ChatGPT, Perplexity und Google AI Overviews. Verstehen Sie in Echtzeit, wie KI Ihre Marke versteht und referenziert.
Entity Recognition ist eine KI-NLP-Fähigkeit zur Identifizierung und Kategorisierung benannter Entitäten im Text. Erfahren Sie, wie sie funktioniert, ihre Anwen...

Erfahren Sie, wie KI-Systeme Beziehungen zwischen Entitäten in Text erkennen, extrahieren und verstehen. Entdecken Sie Techniken zur Entitätsbeziehungsextraktio...

Erfahren Sie, wie Sie die Sichtbarkeit von Entitäten in der KI-Suche aufbauen. Beherrschen Sie Knowledge-Graph-Optimierung, Schema-Markup und Entity-SEO-Strateg...