
Wie Bylines KI-Zitate und Inhaltszuordnung beeinflussen
Erfahren Sie, wie Autoren-Bylines KI-Zitate beeinflussen, warum namentliche Autorschaft die Sichtbarkeit in ChatGPT und Perplexity erhöht und wie Sie Bylines fü...
11 Min. Lesezeit
Entdecken Sie, wie Autorennennungen die Zitierungen durch KI beeinflussen. Erfahren Sie, warum namentliche Autorschaft 1,9-mal mehr Zitierungen von ChatGPT und Perplexity erhält und wie Sie Byline-Optimierung für maximale KI-Sichtbarkeit nutzen.
In der digitalen Publishing-Landschaft steht die Byline für weit mehr als nur einen Namen am Anfang eines Artikels – sie dient als zentrales Vertrauenssignal, das KI-Systeme zur Bewertung von Inhaltsglaubwürdigkeit und Zitierwürdigkeit nutzen. Studien zeigen, dass Inhalte mit namentlicher Autorennennung 1,9-mal häufiger von KI-Systemen wie ChatGPT, Perplexity und Google AI Overviews zitiert werden als anonyme oder ausschließlich unternehmensbezogene Beiträge. Dieser Zitierungs-Multiplikatoreffekt basiert darauf, dass KI-Modelle das E-E-A-T-Framework (Experience, Expertise, Authoritativeness und Trustworthiness) priorisieren, das maßgeblich davon abhängt, individuelle Expertise zu identifizieren und zu verifizieren. KI-Systeme wurden so entwickelt, dass sie erkennen: Verantwortlichkeit steigert Glaubwürdigkeit – ist ein echter Name und ein Ruf mit Inhalten verbunden, wird die Information in Trainingsdaten und Suchalgorithmen höher gewichtet. Die Präsenz einer Byline verwandelt Inhalte von einer gesichtslosen Unternehmensmitteilung in eine persönliche Expertisebehauptung, die KI-Systeme als stärkeres Autoritätssignal interpretieren. Dieses Verständnis ist für Content-Ersteller und Marken essenziell, um ihre Sichtbarkeit in KI-generierten Antworten und Zitierungen zu maximieren.

KI-Systeme bewerten die Glaubwürdigkeit eines Autors durch einen ausgefeilten Prozess, der mit dem Prinzip der Verantwortlichkeit beginnt – der Erkenntnis, dass namentlich genannte Personen für ihre Aussagen verantwortlich gemacht werden können, wodurch ihre Behauptungen verlässlicher erscheinen als anonyme Inhalte. Beim Verarbeiten von Inhalten extrahieren KI-Modelle Autoren-Metadaten aus verschiedenen Quellen, darunter Bylines, Autorenbiografien, Publikationshistorie und fachliche Qualifikationen, um ein Glaubwürdigkeitsprofil zu erstellen. Der Unterschied zwischen individueller und unternehmensbezogener Zuordnung ist dabei besonders relevant; KI-Systeme priorisieren konsequent Inhalte, die von namentlich genannten Personen verfasst wurden, gegenüber generischen Unternehmensstatements, da persönliche Autorschaft direkte Fachkompetenz und Verantwortlichkeit impliziert. Diese Präferenz erzeugt einen Kumulationseffekt: Autoren, die regelmäßig unter eigenem Namen veröffentlichen, bauen eine Autorität auf, die die Zitierwahrscheinlichkeit ihrer künftigen Inhalte erhöht. Die Daten zeigen deutliche Unterschiede, wie verschiedene Inhaltsarten anhand von Autorschaftssignalen bewertet werden:
| Inhaltsmerkmal | Zitierhäufigkeit | Einflussfaktor |
|---|---|---|
| Namentliche Byline | 89,2 % der zitierten Inhalte | 1,9-mal mehr Zitierungen |
| Autor mit Qualifikationen | 76,4 % der zitierten Inhalte | 2,3-mal mehr Zitierungen |
| Ich-Perspektive + Byline | 64,1 % der zitierten Inhalte | 1,67-mal mehr Zitierungen |
| Anonym/Unternehmen nur | 31,4 % der zitierten Inhalte | Basiswert |
| Keine Autorenzuordnung | 10,8 % der zitierten Inhalte | 89 % weniger Zitierungen |
Diese Kennzahlen belegen: Qualifikationen verstärken den Byline-Effekt auf das 2,3-Fache, während die Kombination aus Ich-Perspektive und Byline einen 1,67-fachen Multiplikator bringt – mehrere Autoritätssignale wirken also synergetisch, um die Zitierhäufigkeit zu steigern.
Die Kombination aus Ich-Perspektive und Autorennennung erzeugt sogenannte “authentische Fachkompetenzsignale” – Marker, die KI-Systeme als Hinweis auf echte, gelebte Erfahrung statt bloßer Zweitberichterstattung erkennen. Inhalte, die persönliche Erzählungen mit namentlicher Byline verbinden, erfahren einen Anstieg der Zitierhäufigkeit um 67 % gegenüber dritte-persönlichen Unternehmensbeiträgen, da KI-Systeme diese Kombination als Beleg dafür deuten, dass der Autor direktes Wissen teilt und nicht nur Informationen zusammenfasst. Persönliche Erfahrung ist für KI-Systeme besonders wertvoll, da sie eine Art von Expertise darstellt, die weder leicht kopiert noch erfunden werden kann; wenn ein Autor etwa „Ich habe festgestellt“ oder „Aus meiner Erfahrung“ schreibt – kombiniert mit Name und Qualifikationen –, stufen KI-Modelle dies als besonders verlässliche Informationsquelle ein. Besonders effektiv ist dieser Ansatz bei Produktbewertungen, Fallstudien, How-to-Anleitungen und persönlichen Methodik-Artikeln, bei denen persönliche Autorität mit dem Inhaltsformat einhergeht. So wird der Autor vom unsichtbaren Informationslieferanten zur sichtbaren Expertin, deren Ruf direkt mit der Glaubwürdigkeit des Inhalts verbunden ist – und KI-Systeme zitieren und referenzieren diese Arbeit häufiger.
Verschiedene KI-Plattformen verarbeiten und priorisieren Byline-Informationen mit jeweils eigenen Mechanismen, die Content-Ersteller kennen müssen, um die Zitier-Visibilität zu optimieren. ChatGPT analysiert Byline-Metadaten aus Trainingsdaten, extrahiert Autorenangaben aus HTML-Headern, Schema-Markup und Publikationsmetadaten und erstellt daraus Glaubwürdigkeitsprofile, die die Zitierung beeinflussen. Perplexity zeigt Autorennamen und Veröffentlichungsdaten explizit im Antwortformat an – Byline-Prominenz ist hier also ein direkter Faktor für Nutzervertrauen und Zitier-Visibilität, da Leser die Quelle sofort verifizieren können. Google AI Overviews extrahiert Autoreninformationen aus Schema-Markup und priorisiert Inhalte mit korrekt implementiertem Article-Schema samt Autorenfeld – eine technisch saubere Umsetzung ist hier entscheidend für die Sichtbarkeit in Google-KI-Zusammenfassungen. Claude priorisiert Inhalte mit klaren Autorsignalen, darunter Bylines, Autorenbiografien und Publikationskontext, und behandelt diese Elemente als zentrale Bestandteile der Quellbewertung. Um das Zitierungspotenzial plattformübergreifend zu maximieren, sollten diese Schlüsselelemente umgesetzt werden:
Effektive Bylines für KI-Optimierung gehen weit über die bloße Namensnennung hinaus; vielmehr sollten Bylines als umfassende Autoritätsstatements fungieren, die KI-Systemen mehrere Glaubwürdigkeitsmerkmale liefern. Best Practices sind die Kombination aus Autorenname mit relevanten Qualifikationen (Zertifikate, Abschlüsse, Berufsbezeichnungen), Jahren an Erfahrung im Themengebiet und einer kurzen Expertisebeschreibung, die erklärt, warum gerade diese Person zu dem Thema schreiben darf. Schema-Markup ist unverzichtbar für KI-Zitierungsoptimierung – nur mit dem Article-Schema von schema.org und korrekt ausgefüllten Autorenfeldern können KI-Systeme Autorschaftsinformationen zuverlässig extrahieren und prüfen, unabhängig vom Seitendesign. Konsistenz bei Namenskonventionen ist essenziell: Wer einmal als „Sarah Chen“, dann als „S. Chen“ und ein anderes Mal als „Sarah Chen, PhD“ auftritt, erschwert es KI-Systemen, ein zusammenhängendes Profil zu erstellen – der kumulierende Autoritätsvorteil geht verloren. Zur Autorenprofil-Optimierung gehören dedizierte Autoren-Seiten mit Biografie, Fachgebieten, Publikationshistorie und Social Proof, auf die KI-Systeme bei der Glaubwürdigkeitsbewertung zurückgreifen. Die Monitoring-Funktionen von AmICited.com ermöglichen die Nachverfolgung, wie Ihre Bylines von verschiedenen KI-Systemen verarbeitet und zitiert werden, und liefern datengestützte Einblicke, welche Autorenformate und Qualifikationsdarstellungen die höchste Zitierhäufigkeit erzeugen.
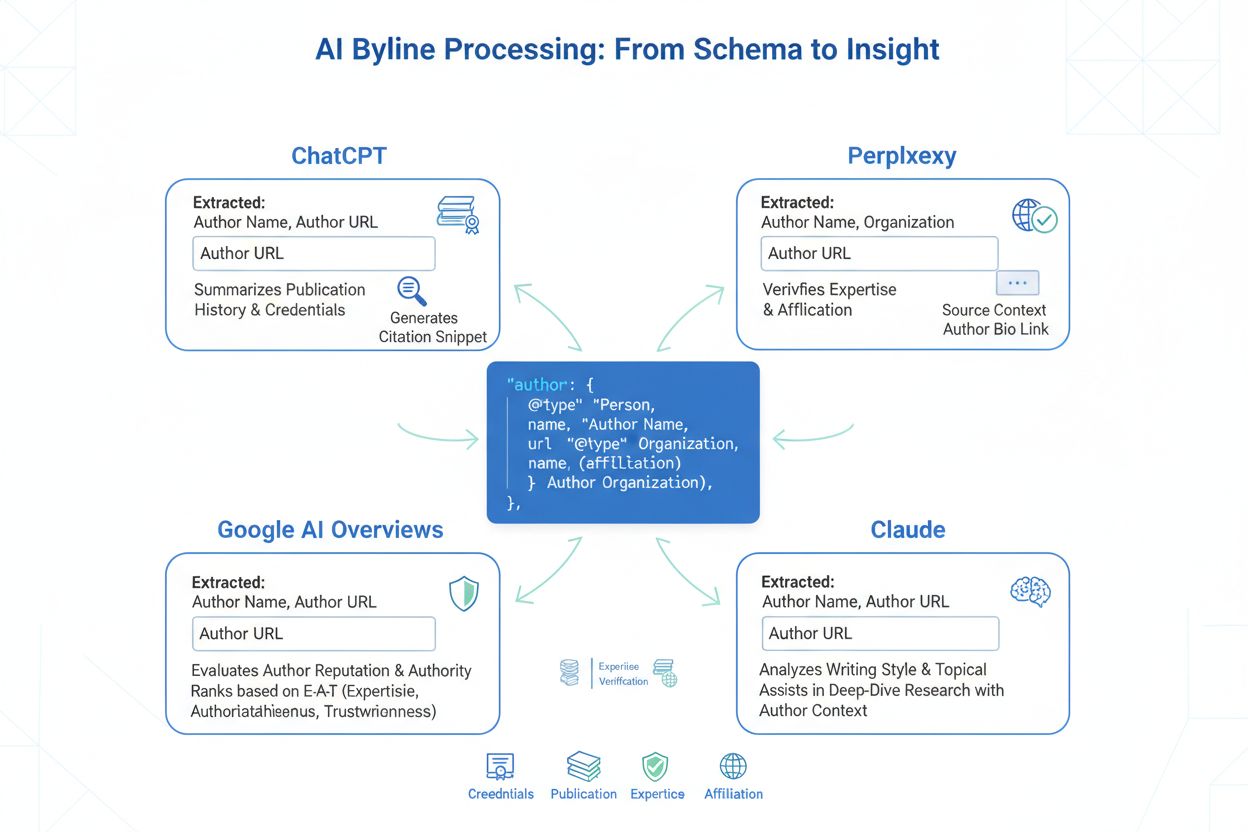
Der mächtigste Aspekt der Byline-Strategie ist ihr Kumulationseffekt: Jeder unter konsequentem Autorenname veröffentlichte Artikel baut Autorität auf, was die Wahrscheinlichkeit erhöht, dass künftige Inhalte von KI-Systemen zitiert werden. Publiziert ein Autor mehrere Artikel zu verwandten Themen, erkennen KI-Systeme das Expertise-Muster und behandeln den Namen selbst als Glaubwürdigkeitsmerkmal – ähnlich wie Leser vertraute Bylines schätzen. Publikationshistorie ist ein starkes Autoritätssignal: KI-Systeme analysieren Breite, Tiefe und Beständigkeit des Werkes, um das Fachniveau festzustellen – jemand mit 50 Artikeln zu einem Thema wiegt schwerer als jemand mit nur einem Beitrag. Der Doppel-Branding-Ansatz – also die Kombination aus individueller Byline und Unternehmenszuordnung – erzeugt einen Synergieeffekt, bei dem sowohl der persönliche Ruf als auch der des Unternehmens sich gegenseitig verstärken und das Zitierungspotenzial maximieren. KI-Systeme verifizieren Autorenexpertise, indem sie Bylines mit Publikationshistorie, sozialen Signalen, beruflichen Profilen und Inhaltskonsistenz abgleichen – so entstehen immer ausgefeiltere Glaubwürdigkeitsbewertungen. Diese Langzeitperspektive bedeutet: Wer heute konsequent auf glaubwürdige Bylines setzt, profitiert über Monate und Jahre exponentiell, da sich die Autorenautorität kumuliert.
Die Wirksamkeit von Bylines unterscheidet sich je nach Inhaltsformat deutlich, sodass formatabhängige Optimierungsstrategien nötig sind, um die KI-Zitierhäufigkeit zu maximieren. How-to-Guides und Tutorials profitieren enorm von Bylines, weil KI-Systeme erkennen, dass Schritt-für-Schritt-Anleitungen bei ausgewiesener Expertise des Autors deutlich mehr Gewicht haben – eine Anleitung „Wie Sie Ihre Website optimieren“ eines namentlich genannten SEO-Spezialisten wird viel öfter zitiert als dieselbe Information ohne Namensnennung. Listenartikel und Vergleichsberichte performen mit Bylines samt relevanter Qualifikationen besonders gut, da KI-Systeme die Autorenexpertise nutzen, um die Qualität der Empfehlungen zu bewerten. Nachrichtenartikel und aktuelle Berichterstattung benötigen Bylines zur Glaubwürdigkeitsprüfung – KI-Systeme stufen namentlich genannte Journalisten und Reporter als verlässlichere Quellen ein als anonyme News-Aggregatoren. Meinungs- und Analyseartikel profitieren insbesondere von Ich-Perspektiven-Bylines in Verbindung mit Qualifikationen, da KI-Systeme den Standpunkt und die Kompetenz des Autors verstehen müssen, um dessen Sichtweise richtig einzuordnen. Formatspezifische Muster zeigen: How-to-Inhalte mit Bylines erreichen eine 2,1-fache Zitierhäufigkeit, Meinungsbeiträge mit Qualifikationen 1,8-fache Raten und Nachrichtenartikel mit Journalisten-Bylines 1,6-fache Raten. Der zentrale Grundsatz für alle Formate: Die Fachkompetenz muss zum Inhaltstyp passen – die Byline eines Finanzberaters wiegt bei Investmentartikeln mehr, die eines Arztes bei Gesundheitsthemen, die eines Entwicklers bei technischen Tutorials. KI-Systeme erkennen und belohnen diese naheliegenden Fachzuordnungen.
Korrektes Schema-Markup ist das technische Fundament, damit KI-Systeme Byline-Informationen zuverlässig extrahieren und verifizieren können – unerlässlich für maximales Zitierungspotenzial. Das Article-Schema von schema.org liefert das Standardformat, das KI-Systeme erwarten; wichtige Felder sind Autorenname, Autoren-URL, Autorenorganisation, Veröffentlichungsdatum und Änderungsdatum – jedes Feld trägt zur Gesamtbewertung der Glaubwürdigkeit bei. Für optimale Umsetzung sind insbesondere das Autorenname-Feld (identisch mit Ihrer konsistenten Byline), das Autoren-URL-Feld (Verlinkung zu Ihrem Autorenprofil oder Ihrer Website) und das Autorenorganisation-Feld (Ihr Unternehmen oder Ihre Institution) erforderlich. Über das Article-Schema hinaus sorgt das Person-Schema für Autorenprofile für ein umfassendes Autoritätssignal, indem KI-Systemen detaillierte Angaben zur Expertise, Qualifikation, sozialen Profilen und Publikationshistorie geliefert werden. Dieser mehrschichtige Schema-Ansatz ermöglicht es KI-Systemen, Autorschaftsangaben anspruchsvoll zu verifizieren, indem sie Byline, Autorenprofil, Publikationshistorie und Qualifikationen miteinander abgleichen. Best Practices sind die Validierung des gesamten Schema-Markups über den Google Rich Results Test, Konsistenz zwischen sichtbarem Byline-Text und Markup sowie regelmäßige Aktualisierung der Autoreninformationen bezüglich aktueller Qualifikationen und Zugehörigkeiten.
Viele Organisationen schmälern ihr Zitierungspotenzial durch vermeidbare Fehler bei der Byline-Umsetzung, die KI-Systeme verwirren und Glaubwürdigkeitssignale abschwächen. Die häufigsten Fehler mit negativen Auswirkungen auf die Zitierhäufigkeit sind:
Uneinheitliche Autorennamen sind besonders problematisch, weil KI-Systeme so kein kohärentes Autorenprofil aufbauen können – jede Variante gilt potenziell als andere Person und der kumulierende Autoritätsvorteil verpufft. Bylines ohne Qualifikationen liefern keine zusätzlichen Autoritätssignale, die die Zitierhäufigkeit auf das 2,3-fache steigern könnten – das Potenzial bleibt ungenutzt. Fehlendes Schema-Markup führt dazu, dass selbst gut umgesetzte Bylines von KI-Systemen – speziell Google AI Overviews und andere strukturierte Daten nutzende Plattformen – nicht zuverlässig erkannt werden. Generische Unternehmenszuweisungen untergraben aktiv die Zitierhäufigkeit, weil KI-Systeme Inhalte von gesichtslosen Organisationen zugunsten namentlicher Autoren abwerten. All diese Fehler sind durch ein Audit bestehender Inhalte und die Einführung standardisierter Byline-Prozesse leicht zu beheben.
Die Wirksamkeit Ihrer Byline-Strategie lässt sich nur durch systematische Überwachung der Zitierungen in verschiedenen KI-Systemen belegen – hier ist die Monitoring-Plattform von AmICited.com unverzichtbar. AmICited.com verfolgt die Autorensichtbarkeit über ChatGPT, Perplexity, Google AI Overviews und andere große KI-Systeme hinweg und zeigt Ihnen genau, wie oft Ihre Bylines in KI-generierten Antworten erscheinen und welche Byline-Formate die höchste Zitierhäufigkeit erzielen. Indem Sie die Zitierhäufigkeit vor und nach der Byline-Optimierung messen, quantifizieren Sie den ROI Ihrer Autorschaftsstrategie und identifizieren, welche Byline-Formate, Qualifikationsdarstellungen und Autorenprofile die besten Resultate liefern. Die Analysen von AmICited.com zeigen, welche Byline-Formate für Ihren Content-Typ und Ihre Branche am besten funktionieren, sodass Sie Ihren Ansatz kontinuierlich auf Basis echter Daten und nicht bloßer Annahmen verbessern können. Die Plattform ermöglicht fortlaufende Optimierung, indem sie Zitierungstrends im Zeitverlauf aufzeigt, neue Muster in der KI-Bewertung Ihrer Inhalte erkennt und Chancen zur Stärkung der Autorensignale markiert. Um Ihre Byline-Performance zu überwachen und den Zitierungseffekt Ihrer Autorschaftsstrategie messbar zu machen, starten Sie Ihr Monitoring am besten noch heute mit AmICited.com – so stellen Sie sicher, dass Ihre Expertise als Autor zu maximalen KI-Zitierungen und Sichtbarkeit führt.
Studien zeigen, dass Inhalte mit klarer Autorennennung 1,9-mal mehr Zitierungen von KI-Systemen wie ChatGPT und Perplexity erhalten als anonyme oder ausschließlich unternehmensbezogene Inhalte. Enthält die Byline zudem professionelle Qualifikationen, steigt der Zitierungsmultiplikator auf 2,3 – ein deutlicher Beweis für die enorme Wirkung namentlicher Autorschaft auf die KI-Sichtbarkeit.
KI-Systeme sind nach dem E-E-A-T-Framework (Experience, Expertise, Authoritativeness, Trust) trainiert, das auf der Identifizierung individueller Fachkompetenz und Verantwortlichkeit basiert. Namentliche Autoren schaffen persönliche Verantwortung für die inhaltliche Richtigkeit, was KI-Systeme als stärkeres Glaubwürdigkeitsmerkmal einstufen als unpersönliche Unternehmensangaben.
Eine effektive Byline sollte den vollständigen Namen des Autors, beruflichen Titel oder Qualifikationen, relevante Berufserfahrung in Jahren sowie die Unternehmenszugehörigkeit enthalten. Beispiel: 'Dr. Sarah Chen, Senior Healthcare Technology Specialist mit 12 Jahren Branchenerfahrung bei TechCorp.' Dieser umfassende Ansatz liefert KI-Systemen mehrere Glaubwürdigkeitsmerkmale.
Schema-Markup ist entscheidend für die KI-Zitierungsoptimierung. Die Verwendung von schema.orgs Article-Schema mit korrekt ausgefüllten Autorenfeldern stellt sicher, dass KI-Systeme Autorschaftsinformationen zuverlässig extrahieren und verifizieren können. Ohne korrektes Schema-Markup werden selbst gut umgesetzte Bylines möglicherweise nicht von Plattformen wie Google AI Overviews erkannt.
Ja, erheblich. Inhalte, die Ich-Perspektive mit namentlicher Byline kombinieren, erhalten 67 % mehr Zitierungen als dritte-persönliche Unternehmensinhalte. Diese Kombination erzeugt 'authentische Fachkompetenzsignale', die KI-Systeme als Hinweise auf echte, gelebte Erfahrung und nicht auf Berichterstattung aus zweiter Hand erkennen.
Zu den häufigsten Fehlern zählen die uneinheitliche Verwendung von Autorennamen in verschiedenen Artikeln, Bylines ohne Qualifikationen, fehlendes Schema-Markup, Zuordnung von Inhalten an generische Unternehmenseinheiten sowie mangelnde Konsistenz der Autorenprofile. Jeder dieser Fehler verringert das Zitierungspotenzial und erschwert KI-Systemen den Aufbau kohärenter Autorenprofile.
AmICited.com bietet eine umfassende Überwachung, wie Ihre Bylines in ChatGPT, Perplexity, Google AI Overviews und anderen KI-Systemen dargestellt werden. Die Plattform zeigt die Zitierhäufigkeit, welche Byline-Formate für Ihren Inhaltstyp am besten funktionieren, und liefert datengestützte Einblicke für kontinuierliche Optimierung.
Ja, die Wirksamkeit der Byline variiert je nach Format. How-to-Guides mit Bylines erreichen eine 2,1-fache Zitierhäufigkeit, Meinungsbeiträge mit Qualifikationen erzielen 1,8-fache Raten, und Nachrichtenartikel mit Journalisten-Bylines kommen auf 1,6-fache Raten. Entscheidend ist, dass die Fachkompetenz zur Inhaltsart passt – die Byline eines Finanzberaters hat beispielsweise bei Investmentartikeln mehr Gewicht.
Verfolgen Sie, wie Ihre Byline und Autorschaftsangaben in ChatGPT, Perplexity, Google AI Overviews und anderen KI-Plattformen erscheinen. Erhalten Sie Echtzeit-Einblicke in Ihre Zitierungsleistung und optimieren Sie Ihre Autorschaftsstrategie.
Erfahren Sie, wie Autoren-Bylines KI-Zitate beeinflussen, warum namentliche Autorschaft die Sichtbarkeit in ChatGPT und Perplexity erhöht und wie Sie Bylines fü...

Erfahren Sie, wie Expertenzitate die KI-Zitationsrate um 41 % verbessern. Entdecken Sie Strategien zur Zitat-Ergänzung für ChatGPT, Perplexity und Google AI Ove...
Erfahren Sie, wie Expertenzitate die Sichtbarkeit Ihrer Marke in KI-Suchmaschinen wie ChatGPT und Perplexity steigern. Entdecken Sie Strategien, um Zitate zu er...