KI-Training blockieren, Suche erlauben: Selektive Steuerung von Crawlern
Erfahren Sie, wie Sie selektives Blockieren von KI-Crawlern implementieren, um Ihre Inhalte vor Trainings-Bots zu schützen und dennoch in KI-Suchergebnissen sichtbar zu bleiben. Technische Strategien für Publisher.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
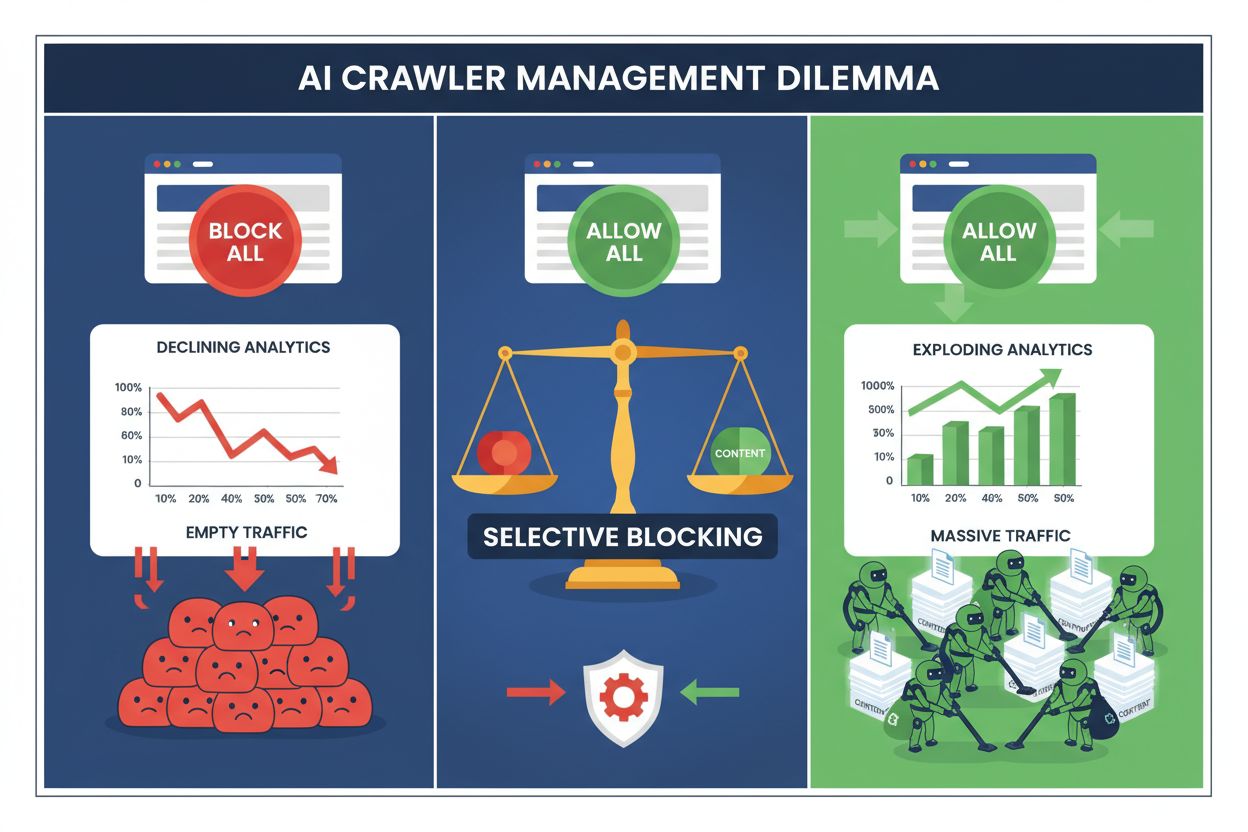
Publisher stehen heute vor einer unmöglichen Wahl: Entweder alle KI-Crawler blockieren und wertvollen Suchmaschinen-Traffic verlieren, oder alle zulassen und zusehen, wie die eigenen Inhalte unbezahlte Trainingsdaten speisen. Mit dem Aufstieg generativer KI ist ein gespaltenes Crawler-Ökosystem entstanden, in dem dieselben robots.txt-Regeln unterschiedslos für Suchmaschinen mit Umsatzpotenzial und Trainings-Crawler, die nur Wert entziehen, gelten. Dieses Paradoxon zwingt fortschrittliche Publisher, selektive Crawler-Steuerungsstrategien zu entwickeln, die zwischen verschiedenen KI-Bots nach ihrem tatsächlichen Einfluss auf Geschäftskennzahlen unterscheiden.
Trainings- vs. Such-Crawler verstehen
Die KI-Crawler-Landschaft teilt sich in zwei Hauptkategorien mit sehr unterschiedlichen Zielen und geschäftlichen Auswirkungen. Trainings-Crawler – betrieben von Unternehmen wie OpenAI, Anthropic und Google – sind darauf ausgelegt, riesige Mengen an Textdaten zu verarbeiten, um große Sprachmodelle zu entwickeln und zu verbessern. Such-Crawler hingegen indexieren Inhalte für Auffindbarkeit und Recherche. Trainings-Bots verursachen etwa 80 % aller KI-bedingten Bot-Aktivitäten, generieren aber keinerlei direkten Umsatz für Publisher, während Such-Crawler wie Googlebot und Bingbot jährlich Millionen von Besuchen und Werbeeinblendungen liefern. Die Unterscheidung ist wichtig, da ein einziger Trainings-Crawler so viel Bandbreite verbrauchen kann wie tausende menschliche Nutzer, während Such-Crawler auf Effizienz optimiert sind und meist Ratenbegrenzungen respektieren.
Bot-Name
Betreiber
Hauptzweck
Traffic-Potenzial
GPTBot
OpenAI
Modelltraining
Keiner (Datenauszug)
Claude Web Crawler
Anthropic
Modelltraining
Keiner (Datenauszug)
Googlebot
Google
Suchindexierung
243,8 Mio. Besuche (April 2025)
Bingbot
Microsoft
Suchindexierung
45,2 Mio. Besuche (April 2025)
Perplexity Bot
Perplexity AI
Suche + Training
12,1 Mio. Besuche (April 2025)
Die Zahlen sind eindeutig: Allein der Crawler von ChatGPT schickte im April 2025 243,8 Millionen Besuche an Publisher, aber diese Besuche generierten keinerlei Klicks, Werbeeinblendungen oder Umsatz. Gleichzeitig führte der Traffic von Googlebot zu echter Nutzerinteraktion und Monetarisierung. Dieses Unterscheidungsmerkmal ist der erste Schritt zu einer selektiven Blockierungsstrategie, die Ihre Inhalte schützt und dennoch die Suchsichtbarkeit erhält.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Das pauschale Blockieren aller KI-Crawler ist für die meisten Publisher wirtschaftlich selbstschädigend. Während Trainings-Crawler Wert entziehen, ohne zu kompensieren, bleiben Such-Crawler eine der zuverlässigsten Traffic-Quellen in einer zunehmend fragmentierten digitalen Landschaft. Das wirtschaftliche Argument für selektives Blockieren basiert auf mehreren Schlüsselfaktoren:
Abhängigkeit vom Suchtraffic: 40–60 % des Publisher-Traffics stammen meist von Suchmaschinen und entsprechen Millionen an jährlichen Werbeeinnahmen
ROI von Trainings-Crawlern: Kein direkter Umsatz durch Trainings-Crawler, aber erhebliche Bandbreitenkosten und Wertverlust der Inhalte
Wettbewerbsnachteil: Publisher, die alle Crawler blockieren, verlieren Sichtbarkeit, während Wettbewerber mit erlaubten Such-Crawlern Ranking-Vorteile erzielen
Langfristige Sichtbarkeit: Suchmaschinenindexierung wirkt sich langfristig aus, während der Zugriff für Trainings-Crawler keinen bleibenden Nutzen bringt
Publisher, die selektive Blockierungsstrategien umsetzen, berichten, dass sie ihren Suchtraffic halten oder sogar verbessern und gleichzeitig unerlaubte Content-Extraktion um bis zu 85 % reduzieren. Der strategische Ansatz erkennt an, dass nicht alle KI-Crawler gleich sind und eine differenzierte Policy den Unternehmensinteressen deutlich besser dient als ein radikaler Rundum-Block.
Robots.txt: Die Basis-Schicht
Die robots.txt-Datei bleibt der wichtigste Mechanismus, um Crawler-Berechtigungen zu kommunizieren – und sie ist überraschend effektiv, wenn sie richtig konfiguriert ist. Diese einfache Textdatei im Root-Verzeichnis Ihrer Website nutzt User-Agent-Direktiven, um festzulegen, welche Crawler auf welche Inhalte zugreifen dürfen. Für selektive KI-Crawler-Steuerung können Sie Suchmaschinen erlauben und Trainings-Crawler gezielt blockieren.
Hier ein praktisches Beispiel, das Trainings-Crawler blockiert und Suchmaschinen erlaubt:
Damit erhalten wohlverhaltende Crawler klare Anweisungen, während Ihre Website weiterhin in Suchergebnissen auffindbar bleibt. Allerdings ist robots.txt grundsätzlich ein freiwilliger Standard – er setzt voraus, dass Crawler-Betreiber Ihre Vorgaben respektieren. Wer auf Einhaltung Wert legt, braucht zusätzliche Durchsetzungsebenen.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Serverseitige Durchsetzung: Nachdruck verleihen
Robots.txt alleine garantiert keine Einhaltung, da etwa 13 % der KI-Crawler diese Vorgaben ignorieren – oft absichtlich oder aus Nachlässigkeit. Serverseitige Durchsetzung auf Webserver- oder Anwendungsebene gibt Ihnen eine technische Rückversicherung, die unbefugte Zugriffe unabhängig vom Crawler-Verhalten verhindert. So werden Anfragen auf HTTP-Ebene blockiert, bevor sie nennenswerte Bandbreite oder Ressourcen verbrauchen.
Die serverseitige Blockierung mit Nginx ist einfach und sehr effektiv:
# In Ihrem Nginx-Server-Block
location/ {
# Trainings-Crawler auf Server-Ebene blockieren
if($http_user_agent ~*(GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return403;
}
# Falls nötig, nach IP-Bereichen blockieren (bei User-Agent-Spoofing)
if($remote_addr ~*"^(192\.0\.2\.|198\.51\.100\.)") {
return403;
}
# Normale Anfragebearbeitung fortsetzen
proxy_passhttp://backend;
}
Diese Konfiguration liefert blockierten Crawlern eine 403-Forbidden-Antwort, verbraucht minimale Ressourcen und signalisiert klar, dass der Zugriff verweigert wird. Zusammen mit robots.txt entsteht so eine Zwei-Ebenen-Abwehr, die sowohl regelkonforme als auch -widrige Crawler erfasst. Die Umgehungsquote von 13 % sinkt bei richtiger Serverkonfiguration nahezu auf null.
CDN- und WAF-Kontrollen
Content Delivery Networks und Web Application Firewalls bieten eine weitere Durchsetzungsebene, die Anfragen bereits vor Ihren Ursprungsservern filtert. Dienste wie Cloudflare, Akamai und AWS WAF ermöglichen es, Regeln zu erstellen, die bestimmte User-Agents oder IP-Bereiche am Edge blockieren, sodass böswillige oder unerwünschte Crawler Ihre Infrastruktur gar nicht erst belasten. Diese Services pflegen aktuelle Listen bekannter Trainings-Crawler-IP-Bereiche und User-Agents und blockieren diese automatisch – ohne manuelle Konfiguration.
CDN-Kontrollen bieten mehrere Vorteile gegenüber serverseitiger Durchsetzung: Sie entlasten den Ursprungsserver, ermöglichen geografisches Blockieren und bieten Echtzeit-Analysen über geblockte Anfragen. Viele CDN-Anbieter bieten inzwischen KI-spezifische Blockierungsregeln als Standardfunktion an, da die Sorge um unbefugte Trainingsdatennutzung weit verbreitet ist. Wer Cloudflare nutzt, kann mit der Option „AI Crawler blockieren“ im Sicherheitsbereich mit einem Klick Schutz gegen Trainings-Crawler aktivieren und bleibt gleichzeitig für Suchmaschinen erreichbar.
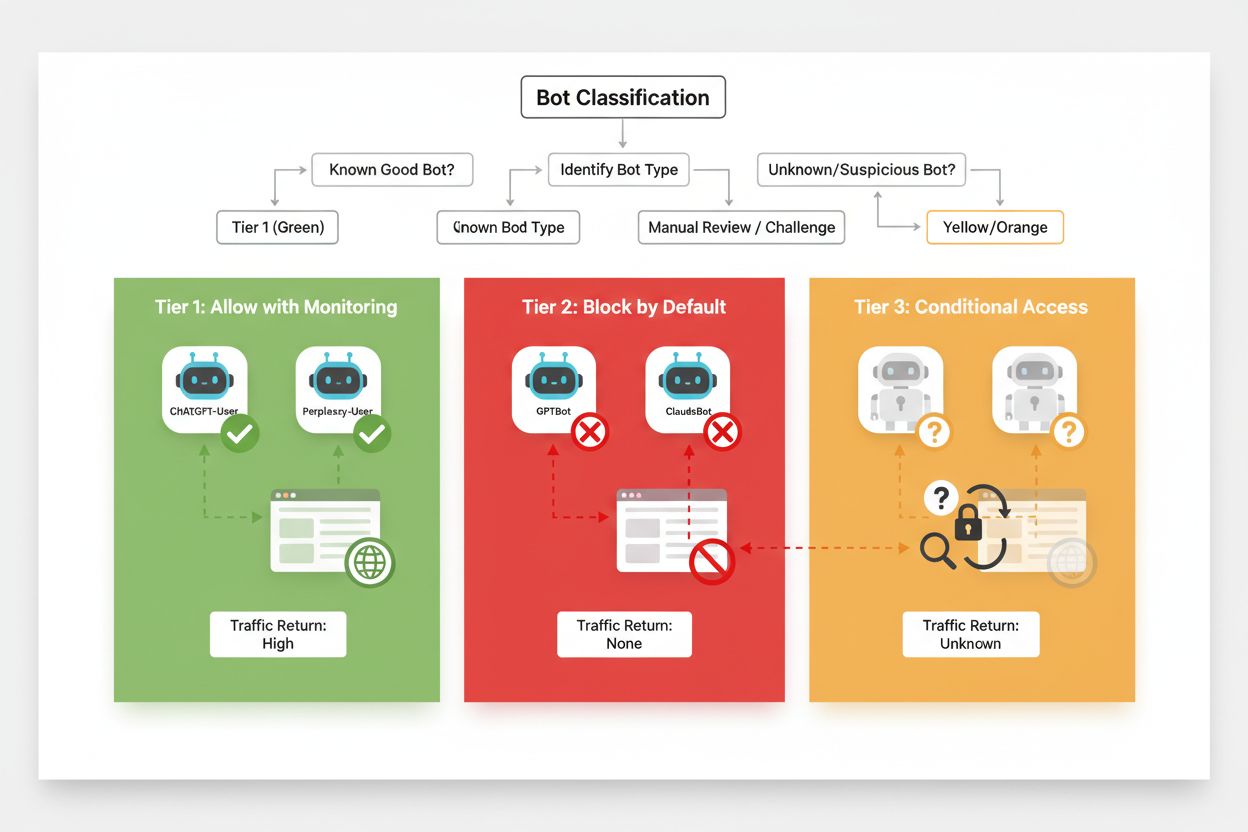
Ihr Framework zur Bot-Klassifizierung
Effektives selektives Blockieren erfordert einen systematischen Ansatz zur Klassifizierung von Crawlern nach Geschäftsrelevanz und Vertrauenswürdigkeit. Statt alle KI-Crawler gleich zu behandeln, sollten Publisher ein Drei-Stufen-Framework umsetzen, das den tatsächlichen Wert und das Risiko jedes Crawlers widerspiegelt. Dieses Framework erlaubt differenzierte Entscheidungen, die Inhaltschutz und Geschäftschancen ausbalancieren.
Stufe
Klassifizierung
Beispiele
Maßnahme
Stufe 1: Umsatzbringer
Suchmaschinen und Traffic-Quellen
Googlebot, Bingbot, Perplexity Bot
Vollzugriff erlauben, Crawlability optimieren
Stufe 2: Neutral/Unbewiesen
Neue/emergente Crawler mit unklarer Absicht
Kleine KI-Startups, Forschungs-Bots
Eng überwachen, ggf. mit Ratenbegrenzung erlauben
Stufe 3: Wert-Abzieher
Trainings-Crawler ohne direkten Nutzen
GPTBot, Claude-Web, CCBot
Komplett blockieren, auf mehreren Ebenen durchsetzen
Die Umsetzung dieses Frameworks erfordert laufende Recherche zu neuen Crawlern und deren Geschäftsmodellen. Publisher sollten regelmäßig ihre Zugriffsprotokolle prüfen, neue Bots identifizieren, deren Betreiber und Geschäftsbedingungen recherchieren und die Klassifizierung anpassen. Ein Crawler, der als Stufe 3 startet, kann in Stufe 2 aufsteigen, wenn der Betreiber Umsatzbeteiligung anbietet; ein ehemals vertrauenswürdiger Crawler kann in Stufe 3 fallen, wenn er Ratenbegrenzungen oder robots.txt verletzt.
Monitoring und Anpassung Ihrer Strategie
Selektives Blockieren ist keine einmalige Konfiguration, sondern verlangt laufende Überwachung und Anpassung im Wandel des Crawler-Ökosystems. Publisher sollten umfassendes Logging und Analysen implementieren, um zu überwachen, welche Crawler auf ihre Inhalte zugreifen, wie viel Bandbreite sie verbrauchen und ob sie die festgelegten Regeln respektieren. Diese Daten sind die Grundlage für strategische Entscheidungen, welche Crawler Sie erlauben, blockieren oder begrenzen.
Die Analyse Ihrer Zugriffsprotokolle zeigt Verhaltensmuster von Crawlern, die Ihre Policy informierter machen:
# Alle KI-Crawler, die Ihre Website besuchen, identifizierengrep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Bandbreite für bestimmte Crawler berechnengrep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot Bandbreite: " sum/1024/1024 " MB"}'# 403-Antworten an geblockte Crawler überwachengrep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Solche Auswertungen – idealerweise wöchentlich oder monatlich – zeigen, ob Ihre Blockierungsstrategie funktioniert, ob neue Crawler aufgetaucht sind und ob bereits blockierte Bots ihr Verhalten geändert haben. Diese Erkenntnisse fließen in Ihr Klassifizierungs-Framework zurück und stellen sicher, dass Ihre Policies weiterhin zu Geschäftszielen und technischer Realität passen.
Typische Implementierungsfehler
Publisher machen beim selektiven Blockieren von Crawlern häufig Fehler, die die Strategie untergraben oder unerwünschte Nebenwirkungen auslösen. Wer diese Stolperfallen kennt, kann von Anfang an eine effektivere Policy implementieren.
Alle Crawler pauschal blockieren: Der häufigste Fehler ist zu breite Blockierung, bei der Suchmaschinen mit blockiert werden und die Sichtbarkeit verloren geht.
Nur auf robots.txt setzen: Zu glauben, dass robots.txt allein unbefugte Zugriffe verhindert, ignoriert die 13 % Crawler, die sie komplett umgehen.
Nicht überwachen und anpassen: Die Policy einmalig festzulegen und nie zu überprüfen führt dazu, neue Bots zu verpassen, sich nicht an Geschäftsmodelle anzupassen und ggf. nützliche Bots auszuschließen.
Nur nach User-Agent blockieren: Fortgeschrittene Crawler fälschen oder rotieren ihre User-Agents, sodass Blocking nach User-Agent ohne zusätzliche IP-Regeln und Ratenbegrenzung wirkungslos ist.
Ratenbegrenzung ignorieren: Selbst erlaubte Crawler können ohne Rate Limiting übermäßige Bandbreite verbrauchen und so die Performance für menschliche Nutzer beeinträchtigen.
Der Weg nach vorne: Schutz und Sichtbarkeit ausbalancieren
Die Zukunft des Verhältnisses zwischen Publishern und KI-Crawlern wird wahrscheinlich mehr auf Verhandlung und Vergütungsmodelle hinauslaufen als auf bloßes Blockieren. Bis dahin bleibt selektive Crawler-Steuerung der praktikabelste Weg, Inhalte zu schützen und zugleich sichtbar zu bleiben. Publisher sollten ihre Blocking-Strategie als dynamische Policy begreifen, die sich mit dem Crawler-Ökosystem weiterentwickelt und regelmäßig hinterfragt, welche Crawler auf Basis von Geschäftsrelevanz und Vertrauenswürdigkeit Zugang verdienen.
Am erfolgreichsten sind die Publisher, die eine gestufte Verteidigung implementieren – also robots.txt-Direktiven, serverseitige Durchsetzung, CDN-Kontrollen und laufendes Monitoring zu einer umfassenden Strategie kombinieren. Diese schützt sowohl vor regelkonformen als auch -widrigen Crawlern und bewahrt den Suchmaschinen-Traffic, der Umsatz und Nutzerinteraktion bringt. Während KI-Unternehmen den Wert von Publisher-Inhalten zunehmend anerkennen und Vergütungs- oder Lizenzmodelle anbieten, bleibt das heute aufgebaute Framework flexibel an neue Geschäftsmodelle anpassbar – und wahrt Ihre Kontrolle über digitale Assets.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Trainings-Crawlern und Such-Crawlern?
Trainings-Crawler wie GPTBot und ClaudeBot sammeln Daten zum Aufbau von KI-Modellen, ohne Traffic auf Ihre Website zurückzuführen. Such-Crawler wie OAI-SearchBot und PerplexityBot indexieren Inhalte für KI-Suchmaschinen und können erheblichen Referral-Traffic auf Ihre Seite bringen. Dieses Unterscheidungsmerkmal ist entscheidend für eine effektive selektive Blockierungsstrategie.
Kann ich KI-Trainings-Bots blockieren, während ich KI-Such-Bots erlaube?
Ja, das ist die Kernstrategie der selektiven Crawler-Steuerung. Sie können robots.txt verwenden, um Trainings-Bots zu verbieten und Such-Bots zu erlauben. Für Bots, die robots.txt ignorieren, setzen Sie serverseitige Kontrollen ein. So schützen Sie Ihre Inhalte vor unbefugtem Training und bleiben gleichzeitig in KI-Suchergebnissen sichtbar.
Respektieren KI-Crawler robots.txt?
Die meisten großen KI-Unternehmen behaupten, robots.txt zu respektieren, aber die Einhaltung ist freiwillig. Untersuchungen zeigen, dass etwa 13 % der KI-Bots robots.txt-Anweisungen komplett umgehen. Daher ist eine serverseitige Durchsetzung für Publisher, die ihre Inhalte schützen wollen, unerlässlich.
Wie viel Traffic liefern KI-Suchmaschinen tatsächlich?
Erheblich und zunehmend. ChatGPT lieferte im April 2025 243,8 Millionen Besuche an 250 Nachrichten- und Medienwebsites – ein Anstieg von 98 % gegenüber Januar. Wenn Sie diese Crawler blockieren, verlieren Sie diese neue Traffic-Quelle. Für viele Publisher machen KI-Such-Traffic inzwischen 5–15 % des gesamten Referral-Traffics aus.
Wie überwache ich am besten, welche Bots meine Website besuchen?
Analysieren Sie regelmäßig Ihre Server-Logs mit grep-Befehlen, um Bot-User-Agents zu identifizieren, Crawl-Frequenzen zu verfolgen und die Einhaltung Ihrer robots.txt-Regeln zu kontrollieren. Überprüfen Sie die Logs mindestens monatlich, um neue Bots, ungewöhnliche Verhaltensmuster und Verstöße von blockierten Bots zu erkennen. Diese Daten sind die Grundlage für strategische Entscheidungen zu Ihrer Crawler-Policy.
Was passiert, wenn ich alle KI-Crawler blockiere?
Sie schützen Ihre Inhalte vor unbefugtem Training, verlieren aber die Sichtbarkeit in KI-Suchergebnissen, verpassen neue Traffic-Quellen und potenziell Erwähnungen Ihrer Marke in KI-generierten Antworten. Publisher, die pauschal blockieren, verzeichnen oft einen Rückgang der Suchsichtbarkeit um 40–60 % und verpassen Chancen auf Markensichtbarkeit über KI-Plattformen.
Wie oft sollte ich meine Crawler-Blocking-Strategie aktualisieren?
Mindestens monatlich, da ständig neue Bots auftauchen und bestehende ihr Verhalten ändern. Die KI-Crawler-Landschaft verändert sich schnell – neue Betreiber starten Crawler, bestehende fusionieren oder benennen ihre Bots um. Regelmäßige Überprüfungen stellen sicher, dass Ihre Policy zu Ihren Unternehmenszielen und den technischen Gegebenheiten passt.
Was ist das Crawl-to-Referral-Verhältnis und warum ist es wichtig?
Es ist das Verhältnis zwischen gecrawlten Seiten und tatsächlich zurückgesandten Besuchern. Anthropic crawlt 38.000 Seiten pro zurückvermitteltem Besucher, OpenAI hat ein Verhältnis von 1.091:1 und Perplexity liegt bei 194:1. Niedrigere Verhältnisse bedeuten einen besseren Gegenwert für den erlaubten Crawler. Diese Kennzahl hilft Ihnen, zu entscheiden, welche Crawler auf Basis ihres tatsächlichen Geschäftswerts Zugang bekommen sollten.
Überwachen Sie, wie KI-Tools auf Ihre Inhalte verweisen
AmICited verfolgt, welche KI-Plattformen Ihre Marke und Inhalte zitieren. Erhalten Sie Einblicke in Ihre KI-Sichtbarkeit und stellen Sie eine korrekte Zuordnung über ChatGPT, Perplexity, Google KI-Überblicke und mehr sicher.
Sollte ich GPTBot das Crawlen meiner Website erlauben? Überall widersprüchliche Empfehlungen
Community-Diskussion darüber, ob man GPTBot und andere KI-Crawler zulassen sollte. Website-Betreiber teilen Erfahrungen, Auswirkungen auf Sichtbarkeit und strat...
Cloudflare und KI-Bots: Zugriffsmanagement am Edge
Erfahren Sie, wie Cloudflares Edge-basierte KI-Crawl Control Ihnen hilft, den Zugriff von KI-Crawlern auf Ihre Inhalte mit granularen Richtlinien und Echtzeit-A...
WAF-Regeln für KI-Crawler: Mehr als nur Robots.txt
Erfahren Sie, wie Web Application Firewalls fortschrittliche Kontrolle über KI-Crawler bieten – weit über robots.txt hinaus. Implementieren Sie WAF-Regeln, um I...
8 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.