Vollständige Liste der KI-Crawler 2025: Jeder Bot, den Sie kennen sollten
Umfassender Leitfaden zu KI-Crawlern im Jahr 2025. Identifizieren Sie GPTBot, ClaudeBot, PerplexityBot und mehr als 20 weitere KI-Bots. Erfahren Sie, wie Sie Crawler mit robots.txt und fortgeschrittenen Techniken blockieren, zulassen oder überwachen können.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
KI-Crawler sind automatisierte Bots, die systematisch Daten von Websites durchsuchen und sammeln – ihr Zweck hat sich in den letzten Jahren jedoch grundlegend verändert. Während herkömmliche Suchmaschinen-Crawler wie Googlebot darauf ausgerichtet sind, Inhalte für Suchergebnisse zu indexieren, konzentrieren sich moderne KI-Crawler auf das Sammeln von Trainingsdaten für große Sprachmodelle und generative KI-Systeme. Laut aktuellen Daten von Playwire machen KI-Crawler mittlerweile etwa 80 % des gesamten KI-Bot-Traffics aus – ein dramatischer Anstieg in Umfang und Vielfalt automatisierter Website-Besucher. Dieser Wandel spiegelt die umfassendere Transformation wider, wie künstliche Intelligenz entwickelt und trainiert wird: weg von öffentlich verfügbaren Datensätzen hin zur Echtzeit-Erfassung von Webinhalten. Das Verständnis dieser Crawler ist für Website-Betreiber, Publisher und Content-Ersteller inzwischen unerlässlich geworden, um fundierte Entscheidungen über ihre digitale Präsenz zu treffen.
Drei Kategorien von KI-Crawlern
KI-Crawler lassen sich anhand ihrer Funktion, ihres Verhaltens und ihrer Auswirkungen auf Ihre Website in drei klare Kategorien einteilen. Trainings-Crawler bilden mit etwa 80 % des KI-Bot-Traffics das größte Segment und sind darauf ausgelegt, Inhalte für das Training von Machine-Learning-Modellen zu sammeln; diese Crawler arbeiten meist mit hohem Volumen und minimalem Referral-Traffic, sind also bandbreitenintensiv, aber führen selten Besucher auf Ihre Seite zurück. Such- und Zitations-Crawler operieren mit moderatem Volumen und sind speziell dazu bestimmt, Inhalte für KI-gestützte Suchergebnisse und Anwendungen zu finden und zu referenzieren; im Gegensatz zu Trainings-Crawlern können diese Bots tatsächlich Traffic auf Ihre Website bringen, wenn Nutzer über KI-generierte Antworten auf Ihre Inhalte klicken. Nutzer-gesteuerte Fetcher sind die kleinste Kategorie und werden auf Abruf aktiv, wenn Nutzer explizit die Inhaltsabfrage über KI-Anwendungen wie die Browsing-Funktion von ChatGPT anfordern; diese Crawler haben ein geringes Volumen, aber eine hohe Relevanz für individuelle Nutzeranfragen.
OpenAI betreibt das vielfältigste und aggressivste Crawler-Ökosystem im KI-Bereich mit mehreren Bots, die unterschiedliche Aufgaben in ihrer Produktpalette übernehmen. GPTBot ist ihr primärer Trainings-Crawler, verantwortlich für das Sammeln von Inhalten zur Verbesserung von GPT-4 und zukünftigen Modellen, und hat laut Cloudflare-Daten ein atemberaubendes 305% Wachstum beim Crawler-Traffic verzeichnet; dieser Bot arbeitet mit einem 400:1 Crawl-zu-Referral-Verhältnis, das heißt, er lädt Inhalte 400-mal herunter, bevor er einen Besucher auf Ihre Seite zurückführt. OAI-SearchBot erfüllt eine völlig andere Funktion: Er sucht und zitiert Inhalte für die Suchfunktion von ChatGPT, verwendet die Inhalte aber nicht zum Modelltraining. ChatGPT-User stellt die rasanteste Wachstumskategorie dar, mit einem bemerkenswerten 2.825%igen Anstieg beim Traffic, und wird aktiv, wenn Nutzer die “Mit Bing durchsuchen”-Funktion aktivieren, um Echtzeit-Inhalte auf Abruf abzurufen. Diese Crawler lassen sich anhand ihrer User-Agent-Strings identifizieren: GPTBot/1.0, OAI-SearchBot/1.0 und ChatGPT-User/1.0. OpenAI bietet IP-Verifizierungsmethoden an, um legitimen Crawler-Traffic von ihrer Infrastruktur zu bestätigen.
Anthropics und Googles KI-Crawler
Anthropic, das Unternehmen hinter Claude, betreibt einen der selektivsten, aber intensivsten Crawler-Betriebe der Branche. ClaudeBot ist ihr primärer Trainings-Crawler und arbeitet mit einem außergewöhnlichen 38.000:1 Crawl-zu-Referral-Verhältnis, das heißt, er lädt Inhalte im Verhältnis zum zurückgesendeten Traffic wesentlich aggressiver herunter als die Bots von OpenAI; dieses extreme Verhältnis spiegelt den Fokus von Anthropic auf umfassende Datensammlung fürs Modelltraining wider. Claude-Web und Claude-SearchBot übernehmen unterschiedliche Aufgaben – ersterer bedient nutzergesteuerte Inhaltsabrufe, letzterer konzentriert sich auf Such- und Zitationsfunktionen. Google hat seine Crawler-Strategie für das KI-Zeitalter angepasst, indem es Google-Extended eingeführt hat, ein spezielles Token, das es Websites ermöglicht, das KI-Training zuzulassen und gleichzeitig die traditionelle Googlebot-Indexierung zu blockieren, sowie Gemini-Deep-Research, das für User von Googles KI-Produkten tiefgehende Rechercheanfragen bearbeitet. Viele Website-Betreiber diskutieren, ob sie Google-Extended blockieren sollen, da es vom gleichen Unternehmen stammt, das den Such-Traffic kontrolliert – die Entscheidung ist daher komplexer als bei KI-Crawlern von Drittanbietern.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meta, Apple, Amazon und Perplexity
Meta hat sich mit Meta-ExternalAgent zu einem bedeutenden Akteur im KI-Crawler-Bereich entwickelt, der etwa 19 % des KI-Crawler-Traffics ausmacht und zum Training ihrer KI-Modelle sowie für Features in Facebook, Instagram und WhatsApp genutzt wird. Meta-WebIndexer übernimmt eine ergänzende Funktion und konzentriert sich auf die Web-Indexierung für KI-gestützte Features und Empfehlungen. Apple hat Applebot-Extended eingeführt, um Apple Intelligence – ihre On-Device-KI-Funktionen – zu unterstützen; dieser Crawler wächst stetig, da das Unternehmen KI-Fähigkeiten über iPhone, iPad und Mac ausbaut. Amazon betreibt Amazonbot für Alexa und Rufus, ihren KI-Shopping-Assistenten, was ihn besonders für E-Commerce-Seiten und produktbezogene Inhalte relevant macht. PerplexityBot ist eines der spektakulärsten Wachstumsthemen im Crawler-Bereich, mit einem erstaunlichen 157.490%igen Anstieg beim Traffic, was das explosive Wachstum von Perplexity AI als Such-Alternative widerspiegelt; trotz dieses enormen Wachstums bleibt das absolute Volumen im Vergleich zu OpenAI und Google noch geringer, aber der Trend zeigt eine rapide steigende Bedeutung.
Neue und spezialisierte Crawler
Neben den großen Playern sind zahlreiche neue und spezialisierte KI-Crawler aktiv, die Daten von Websites im gesamten Internet sammeln. Bytespider von ByteDance (der Muttergesellschaft von TikTok) verzeichnete einen dramatischen 85%igen Rückgang beim Crawler-Traffic – dies deutet auf eine Strategiewende oder einen geringeren Bedarf an Trainingsdaten hin. Cohere, Diffbot und der CCBot von Common Crawl sind spezialisierte Crawler, die sich auf bestimmte Anwendungsfälle konzentrieren – vom Training von Sprachmodellen bis zur Extraktion strukturierter Daten. You.com, Mistral und DuckDuckGo betreiben jeweils eigene Crawler, um ihre KI-gestützten Such- und Assistentenfunktionen zu unterstützen, was die wachsende Komplexität der Crawler-Landschaft weiter erhöht. Es tauchen regelmäßig neue Crawler auf, da Start-ups und etablierte Unternehmen fortlaufend KI-Produkte starten, die Webdaten benötigen. Über diese neuen Crawler informiert zu bleiben, ist entscheidend, denn Blockieren oder Zulassen kann Ihre Sichtbarkeit auf neuen KI-gestützten Entdeckungsplattformen und Anwendungen erheblich beeinflussen.
Wie man KI-Crawler identifiziert
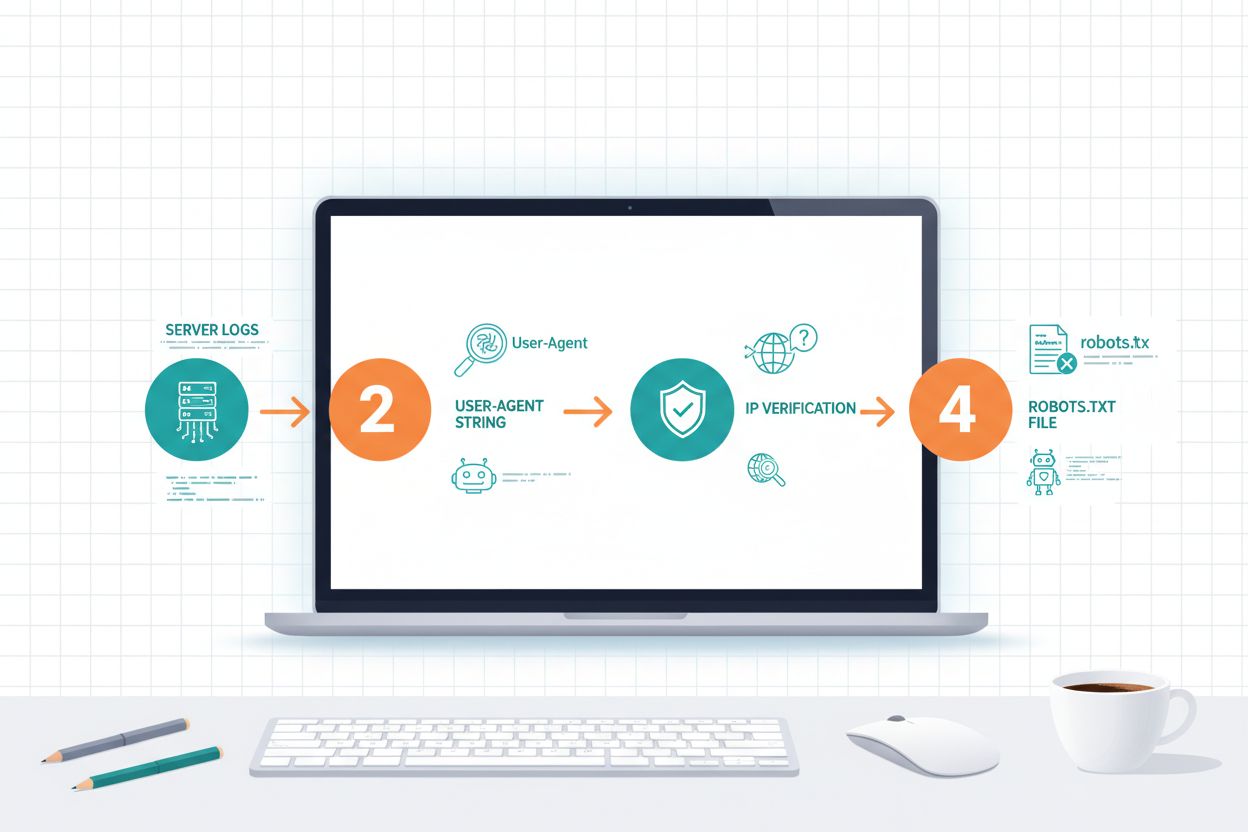
Die Identifikation von KI-Crawlern erfordert das Verständnis, wie sie sich ausweisen und eine Analyse Ihrer Server-Traffic-Muster. User-Agent-Strings sind die Hauptmethode zur Identifikation, da sich jeder Crawler mit einem bestimmten Bezeichner im HTTP-Request ankündigt – etwa verwendet GPTBotGPTBot/1.0, ClaudeBotClaude-Web/1.0 und PerplexityBotPerplexityBot/1.0. Durch die Analyse Ihrer Server-Logs (meist unter /var/log/apache2/access.log auf Linux-Servern oder IIS-Logs unter Windows) sehen Sie, welche Crawler wie oft auf Ihre Seite zugreifen. IP-Verifizierung ist eine weitere wichtige Technik: Sie können überprüfen, ob ein Crawler tatsächlich von den legitimen IP-Bereichen von OpenAI oder Anthropic kommt – diese werden von den Unternehmen zu Sicherheitszwecken veröffentlicht. Ihre robots.txt-Datei zeigt, welche Crawler Sie explizit zugelassen oder blockiert haben; der Vergleich mit dem tatsächlichen Traffic offenbart, ob die Crawler Ihre Richtlinien respektieren. Tools wie Cloudflare Radar bieten Echtzeit-Transparenz zu Crawler-Traffic-Mustern und helfen, die aktivsten Bots auf Ihrer Seite zu identifizieren. Praktische Schritte zur Identifikation sind: Bot-Traffic in der Analytics-Plattform prüfen, rohe Server-Logs nach User-Agent-Mustern durchsuchen, IP-Adressen mit veröffentlichten Crawler-IP-Bereichen abgleichen und Online-Crawler-Verification-Tools zur Bestätigung verdächtiger Traffic-Quellen nutzen.
Die Abwägung: Blockieren oder zulassen?
Ob Sie KI-Crawler zulassen oder blockieren, hängt von verschiedenen, teils gegensätzlichen geschäftlichen Überlegungen ab – eine Standardlösung gibt es nicht. Die wichtigsten Abwägungen sind:
Sichtbarkeit in KI-Anwendungen: Wenn Sie Crawler zulassen, erscheinen Ihre Inhalte in KI-gestützten Suchergebnissen, Entdeckungsplattformen und KI-Assistenten-Antworten – das kann Traffic aus neuen Quellen bringen
Bandbreite und Serverlast: Trainings-Crawler verbrauchen erhebliche Bandbreite und Serverressourcen; manche Seiten berichten von 10–30 % mehr Traffic allein durch KI-Bots, was die Hosting-Kosten erhöht
Schutz der Inhalte vs. Traffic-Potenzial: Das Blockieren von Crawlern schützt Ihre Inhalte vor der Nutzung im KI-Training, verhindert aber auch mögliche Traffic-Zuflüsse durch KI-gestützte Entdeckungsplattformen
Referral-Traffic-Potenzial: Such- und Zitations-Crawler wie PerplexityBot und OAI-SearchBot können Traffic auf Ihre Seite bringen, während Trainings-Crawler wie GPTBot oder ClaudeBot das in der Regel nicht tun
Wettbewerbsposition: Wettbewerber, die Crawler zulassen, können in KI-Anwendungen sichtbar werden, während Sie unsichtbar bleiben – das kann Ihre Marktposition in KI-gestützten Entdeckungsplattformen beeinflussen
Da 80 % des KI-Bot-Traffics von Trainings-Crawlern mit geringem Referral-Potenzial stammen, wählen viele Publisher den Weg, Trainings-Crawler zu blockieren und Such- sowie Zitations-Crawler zuzulassen. Die Entscheidung hängt letztlich von Ihrem Geschäftsmodell, Inhaltstyp und Ihren strategischen Prioritäten für KI-Sichtbarkeit versus Ressourcennutzung ab.
Robots.txt für KI-Crawler konfigurieren
Die robots.txt-Datei ist Ihr zentrales Werkzeug zur Kommunikation von Crawler-Richtlinien an KI-Bots – allerdings sollten Sie wissen, dass die Einhaltung freiwillig und technisch nicht durchsetzbar ist. Robots.txt arbeitet mit User-Agent-Matching, sodass Sie unterschiedliche Regeln für verschiedene Crawler erstellen können; Sie können zum Beispiel GPTBot blockieren, aber OAI-SearchBot zulassen, oder alle Trainings-Crawler blockieren und Such-Crawler erlauben. Laut aktueller Forschung haben nur 14 % der Top-10.000-Domains KI-spezifische Robots.txt-Regeln implementiert – die meisten Websites haben ihre Crawler-Richtlinien also noch nicht für das KI-Zeitalter optimiert. Die Datei nutzt eine einfache Syntax, in der Sie den User-Agent-Namen angeben, gefolgt von Disallow- oder Allow-Direktiven; Sie können Wildcards verwenden, um mehrere Crawler mit ähnlichen Namensmustern zu erfassen.
Hier sind drei praktische Robots.txt-Konfigurationsszenarien:
Denken Sie daran, dass robots.txt nur beratenden Charakter hat und böswillige oder nicht-konforme Crawler Ihre Direktiven vollständig ignorieren können. Das User-Agent-Matching ist nicht case-sensitiv – gptbot, GPTBot und GPTBOT bezeichnen denselben Crawler; mit User-agent: * erstellen Sie Regeln für alle Crawler.
Erweiterte Schutzmethoden
Neben robots.txt bieten verschiedene fortgeschrittene Methoden stärkeren Schutz vor unerwünschten KI-Crawlern – jede hat unterschiedliche Wirksamkeit und Komplexität in der Umsetzung. IP-Verifizierung und Firewall-Regeln ermöglichen es, Traffic aus bestimmten IP-Bereichen bekannter KI-Crawler zu blockieren; Sie erhalten die IP-Bereiche aus der Dokumentation der Crawler-Betreiber und können Ihre Firewall oder Web Application Firewall (WAF) entsprechend konfigurieren – regelmäßige Wartung ist nötig, da sich IP-Bereiche ändern. .htaccess-Blocking auf Server-Ebene schützt Apache-Server, indem User-Agent-Strings und IP-Adressen vor Auslieferung der Inhalte geprüft werden – das ist zuverlässiger als robots.txt, da es auf Server-Ebene durchgesetzt wird und nicht auf die Compliance der Crawler angewiesen ist.
Hier ein praktisches .htaccess-Beispiel für erweitertes Crawler-Blocking:
# KI-Trainings-Crawler auf Server-Ebene blockieren<IfModulemod_rewrite.c> RewriteEngine On# Blockierung nach User-Agent-String RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Blockierung nach IP-Adresse (Beispiel-IPs – durch tatsächliche Crawler-IPs ersetzen) RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Bestimmte Crawler zulassen, andere blockieren RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule># Ansatz mit HTML-Meta-Tags (in den Seitenkopf einfügen)# <meta name="robots" content="noarchive, noimageindex"># <meta name="googlebot" content="noindex, nofollow">
HTML-Meta-Tags wie <meta name="robots" content="noarchive"> und <meta name="googlebot" content="noindex"> bieten Kontrolle auf Seitenebene, sind aber weniger zuverlässig als serverseitige Blockierung, da Crawler sie erst beim Auslesen des HTML erkennen können. Wichtig zu wissen: IP-Spoofing ist technisch möglich – fortgeschrittene Akteure könnten legitime Crawler-IPs imitieren; die Kombination mehrerer Methoden bietet daher besseren Schutz als die alleinige Abhängigkeit von einer Methode. Jede Methode hat ihre Vorteile: robots.txt ist einfach umzusetzen, aber nicht verbindlich, IP-Blocking ist zuverlässig, aber wartungsintensiv, .htaccess bietet Durchsetzung auf Server-Ebene und Meta-Tags granulare Kontrolle auf Seitenebene.
Überwachung und Verifizierung
Die Umsetzung von Crawler-Richtlinien ist nur die halbe Miete – Sie müssen aktiv überwachen, ob Crawler Ihre Vorgaben befolgen und Ihre Strategie anhand realer Traffic-Muster anpassen. Server-Logs sind Ihre zentrale Datenquelle, meist unter /var/log/apache2/access.log auf Linux-Servern oder im IIS-Logs-Verzeichnis bei Windows-Servern; dort können Sie nach bestimmten User-Agent-Strings suchen und sehen, welche Crawler wann und wie oft auf Ihre Seite zugreifen. Analyseplattformen wie Google Analytics, Matomo oder Plausible lassen sich so konfigurieren, dass Bot-Traffic getrennt von menschlichen Besuchern erfasst wird – so sehen Sie Entwicklung und Verhalten verschiedener Crawler im Zeitverlauf. Cloudflare Radar gibt Ihnen Echtzeit-Einblick in Crawler-Traffic-Muster im Internet und zeigt, wie Ihr Seiten-Traffic im Vergleich zum Branchendurchschnitt aussieht. Um zu überprüfen, ob Crawler Ihre Blockierungen respektieren, können Sie Online-Tools zur Prüfung Ihrer robots.txt verwenden, Server-Logs auf blockierte User-Agents untersuchen und IP-Adressen mit veröffentlichten Crawler-IP-Bereichen abgleichen, um sicherzustellen, dass der Traffic tatsächlich von legitimen Quellen stammt. Praktische Monitoring-Schritte sind: wöchentliche Log-Analysen zur Crawler-Volumen-Überwachung, Alerts für ungewöhnliche Crawler-Aktivitäten einrichten, monatliche Überprüfung des Analytics-Dashboards auf Bot-Traffic-Trends sowie quartalsweise Revision Ihrer Crawler-Richtlinien, damit sie zu Ihren Geschäftsziele passen. Regelmäßige Überwachung hilft, neue Crawler zu erkennen, Richtlinienverstöße zu entdecken und datengestützte Entscheidungen über Zulassen oder Blockieren zu treffen.
Die Zukunft der KI-Crawler
Die KI-Crawler-Landschaft entwickelt sich weiterhin rasant – ständig treten neue Player auf und bestehende Crawler erweitern ihre Fähigkeiten oft in unerwartete Richtungen. Neue Crawler von Unternehmen wie xAI (Grok), Mistral und DeepSeek beginnen, Webdaten im großen Stil zu sammeln, und mit jedem neuen KI-Startup ist zu erwarten, dass ein eigener Crawler zur Unterstützung des Modelltrainings und der Produkteinbindung auftaucht. Agentische Browser sind ein neues Feld der Crawler-Technologie: Systeme wie ChatGPT Operator und Comet können wie menschliche Nutzer mit Websites interagieren, Buttons klicken, Formulare ausfüllen und komplexe Oberflächen durchqueren; diese browserbasierten Agenten sind besonders herausfordernd, da sie sich schwerer identifizieren und blockieren lassen als klassische Crawler. Das Problem mit browserbasierten Agenten ist, dass sie sich möglicherweise nicht eindeutig im User-Agent-String ausweisen und IP-Blocking durch den Einsatz von Residential-Proxies oder verteilter Infrastruktur umgehen können. Neue Crawler erscheinen regelmäßig, oft ohne Vorwarnung – es ist daher unerlässlich, Entwicklungen im KI-Bereich zu beobachten und die eigenen Richtlinien entsprechend anzupassen. Der Trend deutet darauf hin, dass der Crawler-Traffic weiter wächst – Cloudflare meldet einen 18%igen Anstieg des gesamten Crawler-Traffics von Mai 2024 bis Mai 2025 – und dieses Wachstum wird sich voraussichtlich mit der weiteren Verbreitung von KI-Anwendungen beschleunigen. Website-Betreiber und Publisher müssen wachsam und anpassungsfähig bleiben, ihre Crawler-Richtlinien regelmäßig überprüfen und Entwicklungen im Auge behalten, um in dieser sich schnell wandelnden Landschaft effektiv zu bleiben.
Überwachen Sie Ihre Marke in KI-Antworten
Neben dem Management des Crawler-Zugriffs auf Ihre Website ist es ebenso wichtig zu verstehen, wie Ihre Inhalte in KI-generierten Antworten verwendet und zitiert werden. AmICited.com ist eine spezialisierte Plattform, die dieses Problem löst, indem sie verfolgt, wie KI-Crawler Ihre Inhalte sammeln und überwacht, ob Ihre Marke und Ihre Inhalte in KI-Anwendungen korrekt zitiert werden. Die Plattform zeigt Ihnen, welche KI-Systeme Ihre Inhalte nutzen, wie oft Ihre Informationen in KI-Antworten erscheinen und ob eine ordnungsgemäße Quellenangabe erfolgt. Für Publisher und Content-Ersteller bietet AmICited.com wertvolle Einblicke in Ihre Sichtbarkeit im KI-Ökosystem – Sie können so die Wirkung Ihrer Entscheidung, Crawler zuzulassen oder zu blockieren, messen und den tatsächlichen Wert der KI-basierten Entdeckung bewerten. Durch das Monitoring Ihrer Zitate über mehrere KI-Plattformen hinweg treffen Sie informierte Entscheidungen zu Ihren Crawler-Richtlinien, erkennen Möglichkeiten zur Verbesserung der Sichtbarkeit Ihrer Inhalte in KI-Antworten und stellen sicher, dass Ihr geistiges Eigentum korrekt attribuiert wird. Wenn Sie Ihre Markenpräsenz im KI-Web wirklich verstehen wollen, bietet AmICited.com die Transparenz und Monitoring-Funktionen, die Sie brauchen, um informiert zu bleiben und den Wert Ihrer Inhalte in dieser neuen Ära der KI-getriebenen Entdeckung zu schützen.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Trainings-Crawlern und Such-Crawlern?
Trainings-Crawler wie GPTBot und ClaudeBot sammeln Inhalte, um Datensätze für die Entwicklung großer Sprachmodelle zu erstellen und werden Teil der Wissensbasis der KI. Such-Crawler wie OAI-SearchBot und PerplexityBot indexieren Inhalte für KI-gestützte Sucherfahrungen und können durch Zitate Referral-Traffic an Publisher zurücksenden.
Sollte ich alle KI-Crawler oder nur Trainings-Crawler blockieren?
Das hängt von Ihren geschäftlichen Prioritäten ab. Das Blockieren von Trainings-Crawlern schützt Ihre Inhalte davor, in KI-Modelle integriert zu werden. Das Blockieren von Such-Crawlern kann Ihre Sichtbarkeit auf KI-gestützten Entdeckungsplattformen wie ChatGPT Search oder Perplexity verringern. Viele Publisher entscheiden sich für selektives Blockieren, das sich auf Trainings-Crawler konzentriert, während Such- und Zitations-Crawler zugelassen werden.
Wie kann ich überprüfen, ob ein Crawler legitim oder gefälscht ist?
Die zuverlässigste Überprüfungsmethode ist der Abgleich der Anfragen-IP mit den offiziell veröffentlichten IP-Bereichen der Crawler-Betreiber. Große Unternehmen wie OpenAI, Anthropic und Amazon veröffentlichen die IP-Adressen ihrer Crawler. Sie können auch Firewall-Regeln verwenden, um verifizierte IPs auf die Allowlist zu setzen und Anfragen von nicht verifizierten Quellen, die sich als KI-Crawler ausgeben, zu blockieren.
Beeinflusst das Blockieren von Google-Extended mein Suchranking?
Google gibt offiziell an, dass das Blockieren von Google-Extended keinen Einfluss auf das Suchranking oder die Aufnahme in AI Overviews hat. Allerdings haben einige Webmaster Bedenken geäußert, daher sollten Sie Ihre Suchperformance nach dem Blockieren überwachen. AI Overviews in der Google-Suche folgen den normalen Googlebot-Regeln, nicht Google-Extended.
Wie oft sollte ich meine KI-Crawler-Blockliste aktualisieren?
Neue KI-Crawler entstehen regelmäßig, daher sollten Sie Ihre Blockliste mindestens vierteljährlich überprüfen und aktualisieren. Verfolgen Sie Ressourcen wie das ai.robots.txt-Projekt auf GitHub für von der Community gepflegte Listen. Kontrollieren Sie monatlich Ihre Server-Logs, um neue Crawler zu identifizieren, die Ihre Seite besuchen und noch nicht in Ihrer Konfiguration enthalten sind.
Können KI-Crawler robots.txt-Direktiven ignorieren?
Ja, robots.txt ist eine Empfehlung und nicht durchsetzbar. Gutartige Crawler großer Unternehmen respektieren robots.txt-Direktiven in der Regel, aber einige Crawler ignorieren diese. Für stärkeren Schutz setzen Sie Blockierungen auf Server-Ebene via .htaccess oder Firewall-Regeln um und verifizieren Sie legitime Crawler anhand veröffentlichter IP-Adressbereiche.
Welchen Einfluss haben KI-Crawler auf die Bandbreite meiner Website?
KI-Crawler können erhebliche Serverlast und Bandbreitennutzung verursachen. Einige Infrastrukturprojekte berichten, dass das Blockieren von KI-Crawlern den Bandbreitenverbrauch von 800GB auf 200GB täglich reduziert und so etwa 1.500 $ monatlich spart. Hochfrequentierte Publisher können durch selektive Blockierung erhebliche Kosteneinsparungen erzielen.
Wie kann ich überwachen, welche KI-Crawler auf meine Seite zugreifen?
Überprüfen Sie Ihre Server-Logs (in der Regel unter /var/log/apache2/access.log auf Linux) auf User-Agent-Strings bekannter Crawler. Nutzen Sie Analyseplattformen wie Google Analytics oder Cloudflare Radar, um Bot-Traffic separat zu verfolgen. Richten Sie Benachrichtigungen für ungewöhnliche Crawler-Aktivitäten ein und führen Sie vierteljährliche Überprüfungen Ihrer Crawler-Richtlinien durch.
Überwachen Sie Ihre Marke in KI-Antworten
Verfolgen Sie, wie KI-Plattformen wie ChatGPT, Perplexity und Google AI-Overviews auf Ihre Inhalte verweisen. Erhalten Sie Echtzeit-Benachrichtigungen, wenn Ihre Marke in KI-generierten Antworten erwähnt wird.
So erkennen Sie KI-Crawler in Server-Logs: Vollständiger Leitfaden zur Erkennung
Erfahren Sie, wie Sie KI-Crawler wie GPTBot, PerplexityBot und ClaudeBot in Ihren Server-Logs identifizieren und überwachen. Entdecken Sie User-Agent-Strings, M...
AI-Crawler-Referenzkarte: Alle Bots auf einen Blick
Vollständiger Referenzleitfaden zu AI-Crawlern und Bots. Identifizieren Sie GPTBot, ClaudeBot, Google-Extended und 20+ weitere AI-Crawler mit User-Agents, Crawl...
Sollten Sie KI-Crawler blockieren oder zulassen? Entscheidungsrahmen
Erfahren Sie, wie Sie strategische Entscheidungen zum Blockieren von KI-Crawlern treffen. Bewerten Sie Inhaltstyp, Traffic-Quellen, Geschäftsmodelle und Wettbew...
10 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.