Originaldaten erstellen, die von KI zitiert werden wollen
Erfahren Sie, wie Sie originale Daten und Forschung erstellen, die von KI-Systemen aktiv zitiert werden. Entdecken Sie Strategien, um Ihre Daten für ChatGPT, Perplexity, Google Gemini und Claude auffindbar zu machen und nachhaltige KI-Sichtbarkeit aufzubauen.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
Im Zeitalter der künstlichen Intelligenz sind Originaldaten zum neuen Wettbewerbsvorteil für Marken geworden, die Sichtbarkeit jenseits klassischer Suchrankings anstreben. Da KI-Plattformen wie ChatGPT, Perplexity, Google Gemini und Claude zunehmend bestimmen, wie Zielgruppen Informationen entdecken, haben sich die Sichtbarkeitsregeln grundlegend verändert. Anstatt um Position Null in Googles Suchergebnissen zu konkurrieren, müssen Organisationen heute Daten schaffen, die KI-Systeme aktiv zitieren und referenzieren möchten. Dieser Wandel spiegelt eine umfassendere Verlagerung vom Content-getriebenen SEO zu dem, was Experten „Generative Engine Optimization“ (GEO) nennen, wider, bei der KI-Zitate klassische Rankings als wichtigsten Sichtbarkeitsfaktor ablösen. Die Plattformen, die Informationen zu direkten Antworten verdichten – sei es durch Retrieval-Augmented Generation (RAG) oder modelleigene Synthese – bevorzugen Quellen, die klare, extrahierbare und maßgebliche Originalforschung liefern. Organisationen, die diesen Wandel verstehen und in die Erstellung von Originaldaten, eigene Forschung und einzigartige Einblicke investieren, positionieren sich, um plattformübergreifend KI-Zitate zu erhalten – und damit Bewusstsein und Glaubwürdigkeit bei Zielgruppen zu schaffen, die klassische Suchergebnisse womöglich nie sehen.
Wie KI-Systeme Daten entdecken und zitieren
Verschiedene KI-Plattformen nutzen grundlegend unterschiedliche Architekturen für das Auffinden und Zitieren von Quellen – was direkt beeinflusst, wie Ihre Originaldaten gefunden und gewürdigt werden. Das Verständnis dieser Mechanismen ist entscheidend, um die Content-Sichtbarkeit im KI-Umfeld zu optimieren. Der Unterschied zwischen modelleigener Synthese (KI generiert Antworten aus Trainingsdatenmustern) und Retrieval-Augmented Generation (KI sucht Live-Quellen und synthetisiert aus abgerufenen Ergebnissen) erklärt, warum einige Plattformen explizite Zitate liefern, während andere Antworten ohne Quellenangabe bieten. Plattformen mit RAG-Systemen können ihre Antworten auf konkrete Quellen zurückführen – das macht Zitate nachvollziehbar und transparent. Modelleigene Systeme hingegen stützen sich auf probabilistisches Wissen aus dem Training, wodurch Quellenangaben schwierig oder ohne Plugins unmöglich werden.
KI-Plattform
Zitatmethode
Priorität der Datenquelle
Sichtbarkeitsauswirkung
ChatGPT
Modelleigen (Standard); verlinkte Zitate mit Plugins/Browsing aktiviert
Trainingsdaten + Live-Web bei Aktivierung; priorisiert aktuelle, maßgebliche Quellen bei aktiver Suche
Gering ohne Plugins; mittel mit Suche aktiviert; Zitate erscheinen im Antworttext, wenn verfügbar
Perplexity
Retrieval-first mit nummerierten Inline-Zitaten
Live-Web-Suchergebnisse; bevorzugt frische, direkt relevante Quellen; betont Quellenprominenz
Hoch; nummerierte Zitate mit klaren Quell-Links; Quellen auf Platz 1 erhalten überproportionalen Traffic
Google Gemini
Integriert mit Google Search und Knowledge Graph
Live-indizierte Seiten + Knowledge Graph-Entitäten; bevorzugt Seiten mit strukturierten Daten und E-E-A-T-Signalen
Hoch; Zitate erscheinen als Quell-Links in KI-Overviews; strukturierte Daten verbessern Zitatwahrscheinlichkeit
Claude
Modelleigen (Standard); Websuche-Funktionen ab 2025
Mittel; Zitate erscheinen bei aktivierter Websuche; Gewicht auf Genauigkeit und Quellglaubwürdigkeit
Die praktischen Folgen sind erheblich: Plattformen wie Perplexity und Google Gemini, die aktiv das Live-Web durchsuchen, können Ihre Inhalte direkt nach Veröffentlichung zitieren – vorausgesetzt, sie erfüllen die Qualitäts- und Relevanzkriterien. ChatGPT und Claude, die stärker auf Trainingsdaten setzen, brauchen länger, um Ihre Originalforschung zu integrieren, bieten aber über Plugins und Integrationen andere Sichtbarkeitschancen. Für Content-Ersteller bedeutet das: Verstehen Sie, welche Plattformen Ihre Zielgruppe nutzt, und optimieren Sie Ihre Daten entsprechend – sei es durch gut strukturierte, extrahierbare Inhalte für Perplexitys Live-Retrieval oder durch den Aufbau von Autoritätssignalen, die die Aufnahme in Trainingsdaten modelleigener Systeme begünstigen.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Strukturierte Daten haben sich von einer netten SEO-Ergänzung zu einer strategischen Notwendigkeit für KI-Sichtbarkeit entwickelt. Mit Schema-Markup auf Basis von Schema.org helfen Sie nicht nur Google, Ihre Inhalte zu verstehen – Sie schaffen eine maschinenlesbare Ebene, auf die KI-Systeme ihre Antworten zuverlässig stützen können. Diese strukturierte Datenschicht, oft als „Inhalts-Wissensgraph“ bezeichnet, definiert explizit Entitäten (Personen, Produkte, Dienstleistungen, Standorte, Organisationen) und deren Beziehungen. Damit können KI-Systeme wesentlich einfacher erfassen, was Ihre Marke ist, was sie anbietet und wie sie zu verstehen ist. Laut aktueller BrightEdge-Forschung zeigen Seiten mit robustem Schema-Markup höhere Zitat-Raten in Googles KI-Overviews, was darauf hindeutet, dass strukturierte Daten die Zitatwahrscheinlichkeit direkt beeinflussen. Das aufkommende Model Context Protocol (MCP), das sowohl von OpenAI als auch Google DeepMind übernommen wurde, stellt die nächste Entwicklungsstufe dar – es funktioniert im Wesentlichen als standardisierte API, um KI-Modelle an strukturierte Datenquellen anzubinden. Durch skalierte Schema-Implementierung schaffen Unternehmen eine Grundlage, die Halluzinationen in KI-Antworten verringert, Faktenbezug verbessert und ihre Daten für Retrieval-Systeme besser auffindbar macht. Das ist besonders wichtig, weil KI-Systeme, die nur auf unstrukturiertem Text trainiert sind, oft Genauigkeitsprobleme haben; strukturierte Daten liefern den Kontext, der LLMs zuverlässigere, zitierbare Antworten ermöglicht, die Ihre Originalforschung mit Zuversicht referenzieren.
Daten erstellen, die KI-Systeme zitieren möchten
Die effektivste Strategie, um KI-Zitate zu erhalten, ist die Erstellung von Originaldaten, die extrahierbar, maßgeblich und an die Art und Weise angepasst sind, wie KI-Systeme Informationen abrufen und verarbeiten. Statt zu hoffen, dass Ihre bestehenden Inhalte zitiert werden, sollten Sie gezielt Datenprodukte entwerfen, die KI-Plattformen leicht entdecken, verstehen und referenzieren können. Die wichtigsten Strategien für zitierfähige Originaldaten sind:
Führen Sie Originalforschung mit transparenter Methodik durch: KI-Systeme bevorzugen Quellen mit nachvollziehbaren Forschungspraktiken. Veröffentlichen Sie Studien, Umfragen und Analysen mit klar dokumentierter Methodik, Stichprobengröße und Einschränkungen. Wenn Sie Ihre Arbeitsweise offenlegen, können KI-Plattformen Ihre Ergebnisse mit Autorität zitieren. Beispiele sind Branchen-Benchmarks, Studien zum Kundenverhalten, Marktforschung und eigene Datenanalysen, die Wettbewerber nicht replizieren können.
Machen Sie Daten durch strukturierte Formate extrahierbar: KI-Systeme bevorzugen Inhalte, die als Tabellen, Listen, Vergleichsmatrizen und FAQ-ähnliche Q&A-Paare organisiert sind – im Gegensatz zu reinem Fließtext. Eine Vergleichstabelle von Wettbewerbsfeatures wird weit eher zitiert als dieselbe Information im Prosatext. Nutzen Sie Überschriften, Aufzählungen und visuelle Hierarchien, die zentrale Erkenntnisse für KI-Systeme sofort auffindbar machen.
Sorgen Sie für Datenaktualität und sichtbare Aktualitätssignale: KI-Plattformen, insbesondere solche mit Live-Web-Retrieval, bevorzugen aktuelle Informationen. Ergänzen Sie sichtbare Veröffentlichungsdaten, Update-Zeitstempel und regelmäßige Inhaltsaktualisierungen. Zeigen Sie, dass Ihre Daten gepflegt und aktuell sind, werden sie von KI-Systemen als zuverlässiger eingestuft als veraltete Quellen – besonders wichtig für zeitkritische Daten wie Preise, Statistiken und Markttrends.
Stellen Sie Autoren- und Markenautorität her: KI-Systeme bewerten vor dem Zitieren die Glaubwürdigkeit einer Quelle. Schaffen Sie klare Autorenprofile (mit relevanter Expertise), organisatorische Autorität (Backlinks, Erwähnungen in Medien, Branchenanerkennung) und Signale für Fachkompetenz. Wird Ihre Marke als führend in Ihrer Kategorie wahrgenommen, werden Sie von KI-Systemen häufiger und prominenter zitiert.
Definieren Sie Entitäten und Beziehungen klar: Definieren Sie zentrale Entitäten explizit – Ihr Unternehmen, Produkte, Dienstleistungen, Teammitglieder und Branchenbegriffe. Verwenden Sie strukturierte Daten, um Beziehungen zwischen diesen Entitäten festzulegen. Wenn ein KI-System genau versteht, wer Sie sind und wie Sie zu Branchenkonzepten stehen, kann es Sie akkurater und kontextueller zitieren.
Achten Sie auf korrekte Attribution und Quellennachweis: Wenn Ihre Originaldaten auf anderen Quellen aufbauen, zitieren Sie diese transparent. KI-Systeme erkennen und belohnen Quellen, die eigene Quellen offenlegen. Das schafft eine Zitatkette, die Vertrauen und Zitatwahrscheinlichkeit im gesamten Ökosystem erhöht.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Messen und Optimieren von KI-Zitaten
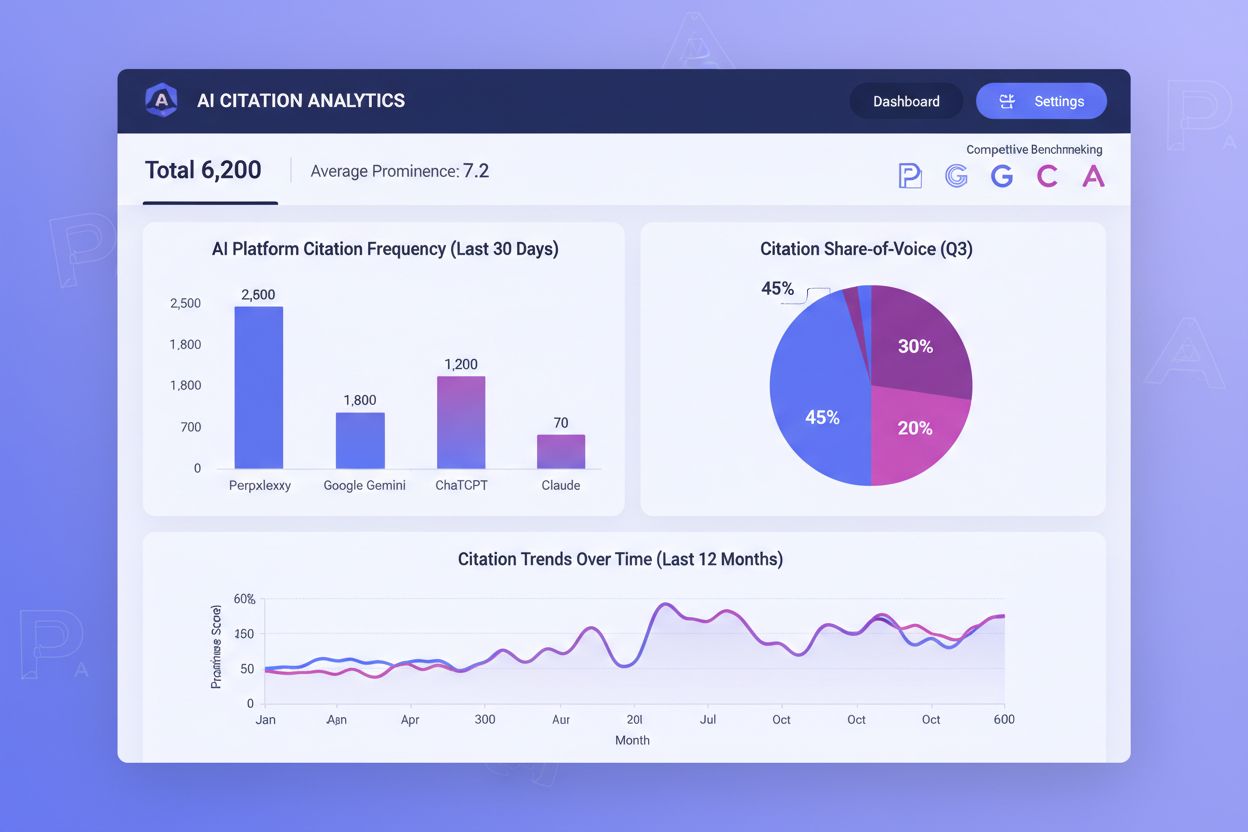
Die Überwachung von KI-Zitaten ist heute so wichtig wie die Beobachtung klassischer Suchrankings – dennoch fehlt den meisten Organisationen Einblick, wie oft ihre Inhalte plattformübergreifend zitiert werden. Zitatfrequenz, Zitatprominenz und Share-of-Voice sind die drei zentralen Metriken für Ihren Erfolg in der KI-basierten Auffindbarkeit. Die Zitatfrequenz misst, wie oft Ihre Inhalte in KI-Antworten für Ihre Zielanfragen erscheinen – werden Sie bei 40 % der relevanten Prompts zitiert, Konkurrenten bei 60 %, besteht klarer Optimierungsbedarf. Die Zitatprominenz ist noch entscheidender: Ein Zitat an erster Stelle in Perplexitys nummerierter Liste verschafft deutlich mehr Sichtbarkeit als eines an fünfter Stelle. Der Share-of-Voice zeigt Ihre Wettbewerbsposition – wenn Ihre Marke bei 25 % der wichtigen Suchanfragen zitiert wird, der stärkste Wettbewerber aber bei 50 %, verlieren Sie viel Sichtbarkeit.
Tools wie AmICited.com sind mittlerweile unverzichtbare Lösungen, um KI-Zitate plattformübergreifend zu überwachen. Diese Plattformen zeigen, welche Ihrer Seiten in Perplexity, Google AI Overviews, ChatGPT mit Suche und anderen KI-Systemen zitiert werden – und damit, welche Inhalte KI-Sichtbarkeit bringen. Durch die Beobachtung von Zitiermustern im Zeitverlauf identifizieren Sie, welche Inhaltstypen, Themen und Formate die meisten Zitate erzielen und können Erfolgsrezepte replizieren. Wettbewerbs-Benchmarking mit diesen Tools zeigt exakt, wo Sie Zitate an Konkurrenten verlieren und wo gezielte Optimierung sinnvoll ist. Die Auswertung zeigt, ob Ihre Zitatprobleme plattformübergreifend bestehen oder spezifisch für einzelne Systeme sind – werden Sie z. B. oft von Perplexity, aber kaum von Google AI Overviews zitiert, sollte Ihre Optimierungsstrategie entsprechend angepasst werden. Positionsgewichtete Metriken erkennen, dass frühe Zitate überproportionalen Wert liefern; ein Tool, das Zitate an erster Stelle stärker gewichtet als niedrigere Positionen, liefert praktischere Erkenntnisse als reine Zählungen. Wenn Sie KI-Zitat-Tracking als festen Bestandteil Ihrer Content-Strategie behandeln, können Sie Ihre Originaldaten laufend optimieren, um sowohl Zitatfrequenz als auch -prominenz zu erhöhen – und so Ihre Sichtbarkeit in einer KI-dominierten Suchlandschaft gezielt steigern.
Nachhaltige Datenstrategie für KI-Sichtbarkeit aufbauen
Originaldaten, die KI-Zitate erhalten, zu erstellen, kann kein einmaliges Projekt sein – es erfordert eine nachhaltige, abteilungsübergreifende Datenstrategie, die Daten als strategischen Vermögenswert mit laufender Investition und Governance behandelt. Erfolgreiche Organisationen im KI-Umfeld implementieren strukturierte Prozesse für kontinuierliche Datenaktualisierung, damit Originalforschung stets aktuell und relevant bleibt. Das bedeutet, regelmäßige Aktualisierungszyklen für wichtige Datensätze einzuführen, Statistiken bei neuen Erkenntnissen zu erneuern und die Aktualitätssignale zu pflegen, die KI-Systeme zur Bewertung der Quellglaubwürdigkeit nutzen. Über bloße Inhaltsupdates hinaus stimmen erfolgreiche Unternehmen ihre Datenstrategie abteilungsübergreifend über Marketing, SEO, Content, Produkt und Data-Teams durch Entitäten-Governance ab – gemeinsame Definitionen und Taxonomien, die eine konsistente, korrekte Darstellung von Marke, Produkten und Branchenbegriffen über alle Kontaktpunkte hinweg sicherstellen.
Die fortschrittlichste Herangehensweise behandelt strukturierte Daten und Inhalts-Wissensgraphen als unternehmensweite Infrastruktur. Statt Schema-Markup seitenweise einzuführen, bauen führende Organisationen umfassende Inhalts-Wissensgraphen, die alle Entitäten, Themen und Beziehungen über ihre digitalen Assets hinweg verknüpfen. Das erfordert technisches Know-how – Tools und Prozesse zur Verwaltung von Schema-Markup im großen Stil – und organisatorische Abstimmung zu Datenqualitätsstandards. Richtig aufgebaut, erfüllt diese Infrastruktur einen doppelten Zweck: Sie verbessert die externe KI-Sichtbarkeit und ermöglicht zugleich interne KI-Initiativen. Laut Gartners „AI Mandates for the Enterprise Survey 2024“ sind Datenverfügbarkeit und -qualität das größte Hindernis für erfolgreiche KI-Implementierung; mit Investitionen in strukturierte Daten und Entitäten-Governance lösen Sie sowohl externe Sichtbarkeitsprobleme als auch interne KI-Anforderungen. Die Gewinner bei KI-Sichtbarkeit behandeln die Erstellung von Originaldaten nicht als Marketing-Taktik, sondern als grundlegende Geschäftsfähigkeit – mit dedizierten Ressourcen, klarer Verantwortlichkeit und kontinuierlicher Optimierung auf Basis von Zitat-Tracking und Wettbewerbs-Benchmarking.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Originaldaten und regulären Inhalten für KI-Zitate?
Originaldaten beziehen sich auf eigene Forschung, einzigartige Datensätze und primäre Erkenntnisse, die Sie selbst erstellt oder entdeckt haben. KI-Systeme bevorzugen Originaldaten, da sie maßgebliche, extrahierbare Informationen liefern, auf die sie sich beim Zitieren verlassen können. Reguläre Inhalte fassen oft bestehende Informationen zusammen und sind daher für KI-Zitate weniger wertvoll. Originaldaten werden zur Grundlage für KI-Sichtbarkeit, da Plattformen wie Perplexity und Google Gemini aktiv nach Quellen mit einzigartigen Einblicken und Forschung suchen und diese zitieren.
Wie entdecken und zitieren verschiedene KI-Plattformen meine Originaldaten?
Verschiedene KI-Plattformen nutzen unterschiedliche Entdeckungsmechanismen. Perplexity und Google Gemini verwenden Retrieval-Augmented Generation (RAG), das heißt, sie durchsuchen das Live-Web und können Ihre Inhalte direkt nach Veröffentlichung zitieren. ChatGPT und Claude stützen sich stärker auf Trainingsdaten, sodass es länger dauern kann, bis Ihre Inhalte aufgenommen werden, dafür bieten sich andere Sichtbarkeitschancen. Alle Plattformen profitieren von strukturierten Daten (Schema-Markup), die Ihre Daten maschinenlesbar und leichter verständlich machen – das erhöht die Wahrscheinlichkeit für Zitate über alle Systeme hinweg.
Welche Rolle spielen strukturierte Daten bei KI-Zitaten?
Strukturierte Daten mit dem Vokabular von Schema.org schaffen eine maschinenlesbare Ebene, auf die sich KI-Systeme bei ihren Antworten zuverlässig stützen können. Wenn Sie Schema-Markup implementieren, definieren Sie explizit Entitäten (Ihr Unternehmen, Produkte, Dienstleistungen) und deren Beziehungen, was es KI-Systemen erheblich erleichtert, Ihre Inhalte korrekt zu verstehen und zu zitieren. Studien zeigen, dass Seiten mit robustem Schema-Markup höhere Zitat-Raten in KI-Overviews erhalten. Strukturierte Daten reduzieren auch Halluzinationen, indem sie KI-Systemen klare, faktenbasierte Informationen zur Referenzierung liefern.
Welche Arten von Originaldaten werden am ehesten von KI zitiert?
KI-Systeme zitieren am häufigsten Originalforschung mit transparenter Methodik, eigene Datensätze, Branchen-Benchmarks, Studien zum Kundenverhalten, Marktanalysen und einzigartige Einblicke, die Wettbewerber nicht nachbilden können. Daten in extrahierbaren Formaten – Tabellen, Vergleichsmatrizen, Listen und FAQ-ähnliche Q&A – erhalten mehr Zitate als dieselben Informationen in Fließtext. Aktuelle, frische Daten mit sichtbarem Veröffentlichungsdatum und regelmäßigen Updates werden gegenüber veralteten Informationen bevorzugt. Autoritätssignale wie Autoren-Credentials und organisatorische Anerkennung erhöhen ebenfalls die Zitatwahrscheinlichkeit.
Wie kann ich messen, ob meine Originaldaten von KI-Systemen zitiert werden?
Tools wie AmICited.com verfolgen KI-Zitate plattformübergreifend und zeigen Ihnen, wie oft Ihre Inhalte in Antworten von ChatGPT, Perplexity, Google AI Overviews und Claude erscheinen. Diese Tools messen Zitatfrequenz (wie oft Sie zitiert werden), Zitatprominenz (Position in der Antwort) und Share-of-Voice (Ihre Zitate im Vergleich zu Wettbewerbern). Durch die Überwachung dieser Kennzahlen erkennen Sie, welche Inhaltstypen und Themen die meisten Zitate generieren – und können Ihre Datenstrategie entsprechend optimieren. Positionsgewichtete Kennzahlen berücksichtigen, dass Zitate an erster Stelle wertvoller sind als solche auf niedrigeren Positionen.
Was ist der Unterschied zwischen Zitatfrequenz und Zitatprominenz?
Die Zitatfrequenz misst, wie oft Ihre Inhalte in KI-Antworten für Ihre Zielanfragen zitiert werden – wenn Sie bei 40 % der relevanten Prompts zitiert werden, ist das Ihre Zitatfrequenz. Die Zitatprominenz misst, an welcher Stelle Ihr Zitat in der Antwort erscheint – ein Zitat an erster Stelle in Perplexitys nummerierter Liste bringt deutlich mehr Sichtbarkeit als eines an fünfter Stelle. Beide Kennzahlen sind für die KI-Sichtbarkeit wichtig, aber die Prominenz ist oft entscheidender, da Nutzer eher auf frühe Zitate klicken oder mit ihnen interagieren. Effektive Optimierung erfordert die gleichzeitige Verbesserung beider Kennzahlen.
Wie oft sollte ich meine Originaldaten aktualisieren, um den KI-Zitatwert zu erhalten?
Originaldaten sollten in einem regelmäßigen Rhythmus aktualisiert werden, der dem Innovationsgrad Ihrer Branche entspricht. In schnelllebigen Bereichen wie Technologie oder Finanzen sind monatliche oder vierteljährliche Updates erforderlich, in langsameren Branchen genügen jährliche Aktualisierungen. Entscheidend sind sichtbare Aktualitätssignale – Veröffentlichungsdaten, Update-Zeitstempel und Hinweise auf Auffrischungen –, die KI-Systemen zeigen, dass Ihre Daten aktuell und zuverlässig sind. Regelmäßige Updates erhöhen auch Ihre Chancen, von Retrieval-basierten Systemen wie Perplexity zitiert zu werden, die frische Informationen bevorzugen. Behandeln Sie Datenpflege als fortlaufende operative Aufgabe, nicht als einmaliges Projekt.
Kann ich mit AmICited.com auch Zitate von Wettbewerbern verfolgen?
Ja, AmICited.com bietet Funktionen für Wettbewerbs-Benchmarking, die Ihre Zitat-Performance im Vergleich zu definierten Wettbewerbern zeigen. Sie sehen, welche Wettbewerber häufiger oder prominenter zitiert werden und auf welchen KI-Plattformen. Diese Wettbewerbsanalysen zeigen genau, wo Sie Zitate verlieren und welche Optimierungsstrategien Ihnen helfen können, aufzuholen. Mit diesem Verständnis der Zitatlandschaft können Sie Ihre Datenerstellung und -optimierung gezielt auf die wirkungsvollsten Chancen ausrichten und so sicherstellen, dass Ihre Originaldaten die Sichtbarkeit erhalten, die sie verdienen.
Überwachen Sie noch heute Ihre KI-Zitate
Verfolgen Sie, wie oft Ihre Originaldaten in ChatGPT, Perplexity, Google AI Overviews und anderen KI-Plattformen zitiert werden. Erhalten Sie umsetzbare Einblicke, um Ihre Inhalte für maximale KI-Sichtbarkeit zu optimieren.
Datengetriebene PR: Forschung erstellen, die von KI zitiert werden will
Erfahren Sie, wie Sie Originalforschung und datengetriebene PR-Inhalte erstellen, die von KI-Systemen aktiv zitiert werden. Entdecken Sie die 5 Merkmale zitierw...
Originalforschung: Der 30–40% Sichtbarkeits-Boost für KI-Zitationen
Entdecken Sie, wie Originalforschung und First-Party-Daten einen Sichtbarkeits-Boost von 30–40% bei KI-Zitationen in ChatGPT, Perplexity und Google KI-Überblick...
Verbindung von KI-Sichtbarkeit mit Geschäftsergebnissen in Berichten
Erfahren Sie, wie Sie KI-Sichtbarkeitsmetriken mit messbaren Geschäftsergebnissen verknüpfen. Verfolgen Sie Markennennungen in ChatGPT, Perplexity und Google AI...
6 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.