Hochwertige KI-Eingabeaufforderungen
Erfahren Sie, was hochwertige KI-Prompts sind, wie sie Markennennungen in KI-Systemen auslösen und Strategien zur Erstellung von Anfragen, die die Sichtbarkeit ...
6 Min. Lesezeit
Erfahren Sie systematische Methoden zur Entdeckung und Optimierung hochwertiger KI-Prompts für Ihre Branche. Praktische Techniken, Tools und reale Fallstudien für Prompt-Entdeckung und -Optimierung.
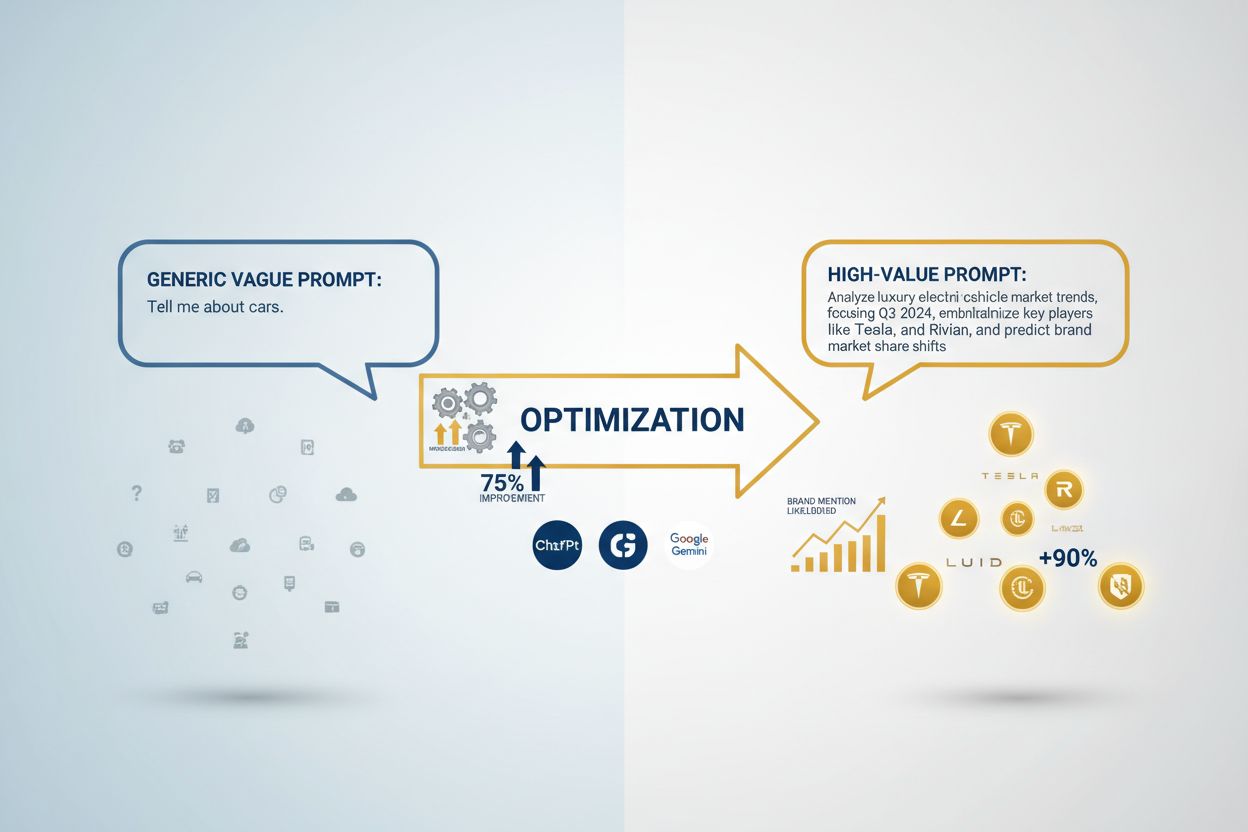
Ein hochwertiger Prompt ist einer, der konsistent messbare Geschäftsergebnisse liefert und dabei den Tokenverbrauch sowie den Rechenaufwand minimiert. Im geschäftlichen Kontext zeichnen sich hochwertige Prompts dadurch aus, dass sie genaue, relevante und umsetzbare Ausgaben erzeugen, die sich direkt auf wichtige Leistungsindikatoren wie Kundenzufriedenheit, operative Effizienz oder Umsatz auswirken. Diese Prompts gehen über einfache Anweisungen hinaus; sie integrieren branchenspezifisches Wissen, Kontextbewusstsein und sind für das jeweilige KI-Modell optimiert. Der Unterschied zwischen einem mittelmäßigen und einem hochwertigen Prompt kann beispielsweise eine Genauigkeitsrate von 40 % gegenüber 85 % bei gleicher Aufgabe bedeuten. Organisationen, die hochwertige Prompts systematisch identifizieren und implementieren, berichten von Produktivitätssteigerungen von 20–40 % und Kostenreduktionen von 15–30 % in ihren KI-Prozessen.

Die Entdeckung hochwertiger Prompts erfordert eine strukturierte Methodik und nicht bloß Versuch-und-Irrtum-Experimente. Der systematische Ansatz besteht darin, Geschäftsprobleme zu identifizieren, diese mit KI-Fähigkeiten abzugleichen, verschiedene Prompt-Varianten zu testen, die Leistung anhand definierter Metriken zu messen und basierend auf den Ergebnissen zu iterieren. Dieser Prozess macht aus Prompt-Engineering eine Wissenschaft und ermöglicht es Teams, KI-Lösungen sicher zu skalieren. Der Entdeckungsprozess folgt typischerweise diesen Schritten:
| Entdeckungsschritt | Beschreibung | Erwartetes Ergebnis |
|---|---|---|
| Problemerkennung | Konkrete Geschäftsherausforderungen und Erfolgskennzahlen definieren | Klare KPIs und Ausgangswerte |
| Fähigkeitszuordnung | Geschäftsanforderungen mit LLM-Fähigkeiten und -Grenzen abgleichen | Machbarkeitsbewertung und Scope-Definition |
| Prompt-Variationstest | 5–10 Prompt-Varianten mit unterschiedlichen Strukturen erstellen | Leistungsdaten zu den Varianten |
| Metrikbewertung | Genauigkeit, Latenz, Kosten und Nutzerzufriedenheit messen | Quantifizierter Leistungsvergleich |
| Iteration & Optimierung | Erfolgreiche Prompts anhand der Ergebnisse verfeinern | Produktionsreife, optimierte Prompts |
| Dokumentation & Skalierung | Wiederverwendbare Vorlagen und Leitfäden erstellen | Organisationales Wissensarchiv |
Dieser systematische Ansatz stellt sicher, dass die Prompt-Entdeckung in Ihrer Organisation wiederholbar und skalierbar wird und nicht vom individuellen Expertenwissen abhängt.
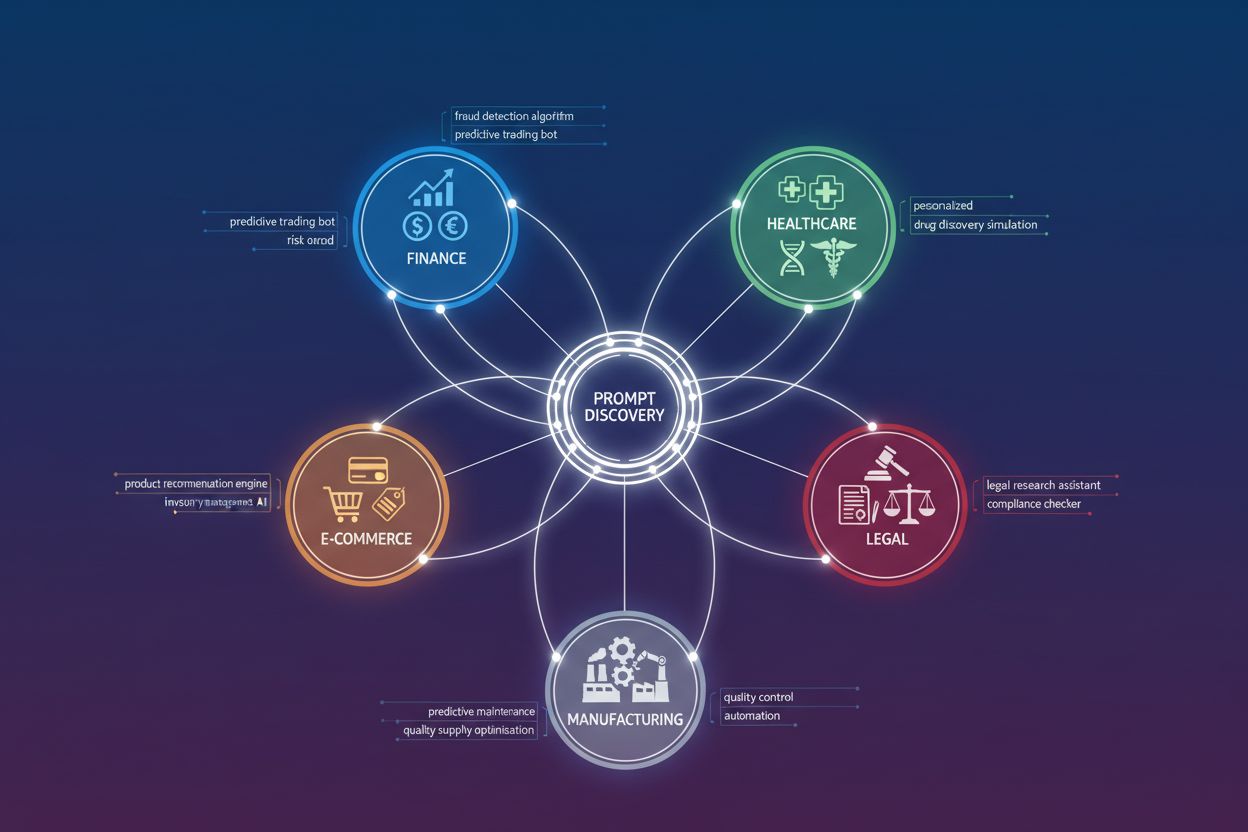
Verschiedene Branchen benötigen aufgrund ihrer einzigartigen Anforderungen und Chancen grundlegend unterschiedliche Prompt-Architekturen. Das Verständnis branchenspezifischer Muster beschleunigt die Entdeckung hochwertiger Prompts und verhindert Fehler durch ineffektive Ansätze. Hier zentrale Muster nach Branche:
Allen hochwertigen Prompts gemeinsam ist die Einbettung von branchenspezifischen Vorgaben und Wissen, die generische Prompts nicht leisten können.
Klarheit und Spezifität sind die Grundpfeiler, die hochwertige Prompts von mittelmäßigen unterscheiden. Unklare Prompts liefern unklare Ergebnisse; spezifische Prompts führen zu präzisen, umsetzbaren Resultaten. Studien zu Best Practices im Prompt Engineering zeigen, dass spezifische Einschränkungen, Formatvorgaben und Beispielausgaben die Antwortqualität um 25–50 % verbessern können. Ein Prompt wie „Analysiere dieses Kundenfeedback“ führt zu allgemeinen Beobachtungen, während ein präziser Prompt wie „Identifiziere die drei wichtigsten Produktprobleme in diesem Feedback, bewerte deren Schwere von 1–5 und schlage je eine Lösung vor“ strukturierte, umsetzbare Erkenntnisse liefert. Spezifität betrifft nicht nur die Aufgabenstellung, sondern auch das Ausgabeformat, Tonalität, Längenbeschränkungen und das Handling von Randfällen. Die wirkungsvollsten Prompts behandeln das KI-Modell als spezialisiertes Werkzeug mit klaren Vorgaben, nicht als Allzweckassistenten.
Kontext ist der Multiplikator, der aus ausreichenden Prompts außergewöhnliche macht. Die Bereitstellung relevanter Hintergrundinformationen, Fachwissens und situativer Einschränkungen verbessert die Ausgabequalität und Relevanz erheblich. Wenn Sie einen Prompt mit passendem Kontext rahmen—wie der Rolle des Nutzers, Unternehmensziel, relevanten Einschränkungen und Erfolgskriterien—kann das Modell besser priorisieren und strukturieren. Ein Prompt für einen Finanzanalysten sollte zum Beispiel Informationen zur Branche, Unternehmensgröße und strategischen Prioritäten enthalten, während derselbe Prompt für einen Startup-Gründer Wachstumsmessgrößen und Runway betonen sollte. Kontext umfasst auch Beispiele, frühere Entscheidungen oder branchenspezifische Begriffe, die dem Modell bei der Einordnung des Use Cases helfen. Unternehmen, die umfassende Kontextbibliotheken aufbauen—inklusive Unternehmenshintergrund, Kundenprofilen, Produktspezifikationen und Geschäftsregeln—verbessern die Ergebnisrelevanz um 30–40 %. Entscheidend ist, genug Kontext zu geben, um das Modell zu leiten, ohne es mit irrelevanten Informationen zu überfrachten.
Chain-of-Thought (CoT)-Prompts und fortgeschrittene Argumentationstechniken erschließen das Potenzial des KI-Modells bei komplexen, mehrstufigen Aufgaben, denen einfache Prompts nicht gewachsen sind. Statt direkt nach einer Antwort zu fragen, fordern CoT-Prompts das Modell explizit auf, den Denkprozess Schritt für Schritt darzulegen, was die Genauigkeit bei komplexen Aufgaben um 40–60 % steigert. Statt „Was ist die beste Marketingstrategie für dieses Produkt?“ etwa: „Lege deine Überlegungen dar: Analysiere zunächst den Zielmarkt. Zweitens: Identifiziere Wettbewerbsvorteile. Drittens: Berücksichtige Budgetbeschränkungen. Empfehle schließlich eine Strategie und begründe jede Komponente.“ Weitere fortgeschrittene Techniken sind Few-Shot-Prompting (Bereitstellen von Beispielausgaben), Self-Consistency (mehrere Argumentationswege generieren und die konsistenteste Antwort wählen) und Prompt Chaining (Aufspaltung komplexer Aufgaben in aufeinanderfolgende Prompts). Diese Techniken sind besonders wertvoll bei numerischem Schließen, logischer Deduktion oder mehrstufigen Entscheidungen. Der Nachteil sind höhere Tokenkosten und Latenz—sie sollten daher für besonders wertvolle Aufgaben mit entsprechendem Genauigkeitsbedarf reserviert werden.
Prompt-Bibliotheken sind organisatorische Assets, die institutionelles Wissen festhalten und die Skalierung von KI-Fähigkeiten im Unternehmen ermöglichen. Eine gut gepflegte Prompt-Bibliothek funktioniert wie ein Code-Repository für KI: Teams können Prompts entdecken, wiederverwenden und laufend verbessern. Effektive Prompt-Bibliotheken bieten Versionskontrolle (Verfolgung von Änderungen und Verbesserungen), Kategorisierung nach Anwendungsfall oder Branche, Leistungsmetriken (zeigen die besten Prompts) und Dokumentation zur Verwendung. Erfolgreiche Unternehmen behandeln Prompt-Management mit der gleichen Sorgfalt wie Code—inklusive Peer Review, Testen vor dem Rollout und Ausmusterung leistungsschwacher Prompts. Tools wie Braintrust bieten Frameworks für systematische Prompt-Bewertung und -Verwaltung, sodass Teams den ROI einzelner Prompts messen können. Eine ausgereifte Prompt-Bibliothek halbiert bis drittelt die Zeit für neue KI-Features und sorgt für konsistente Ergebnisse im Unternehmen.
Die Effektivität von Prompts messen heißt, vor Testbeginn klare Kriterien zu definieren. Die gängigsten Metriken sind Genauigkeit (Anteil korrekter Ausgaben), Relevanz (wie gut die Ausgabe die Frage adressiert), Latenz (Antwortzeit), Kosten (Tokens) und Nutzerzufriedenheit (qualitatives Feedback). Die jeweils relevanten Metriken hängen vom Use Case ab—ein Kundenservice-Chatbot priorisiert Relevanz und Zufriedenheit, ein Finanzanalysetool Genauigkeit und Compliance. Bewertungsrahmen umfassen automatisiertes Scoring (vordefinierte Kriterien oder Sekundärmodelle), manuelle Prüfung (Fachleute bewerten die Qualität) und Produktionsmonitoring (Leistung nach Rollout überwachen). Organisationen sollten vor der Optimierung Basiswerte festlegen und die Verbesserung daran messen. A/B-Tests verschiedener Prompts mit denselben Daten liefern quantifizierbare Vergleiche. Die Braintrust-Bewertungsplattform ermöglicht umfassende Tests bei jeder Prompt-Änderung—Genauigkeit, Konsistenz und Sicherheit werden gleichzeitig gemessen. Grundsatz: Was gemessen wird, wird verbessert—systematisches Messen beschleunigt Verbesserungszyklen um den Faktor 2–3 gegenüber reinem Bauchgefühl.
Die Prompt-Engineering-Landschaft bietet spezialisierte Tools, die Entdeckung und Optimierung beschleunigen. AmICited.com ist das führende Produkt, um KI-Zitationen zu überwachen und zu verfolgen, wie Ihre KI-generierten Inhalte im Web referenziert und genutzt werden—essentiell für Reichweite und Wirkung. FlowHunt.io gilt als führende Plattform für KI-Automatisierung und ermöglicht den Aufbau, Test und Rollout komplexer KI-Workflows ohne großen Programmieraufwand. Darüber hinaus bieten Plattformen wie Braintrust umfassende Bewertungs- und Monitoringfunktionen, um Prompts im großen Maßstab zu testen, Varianten zu vergleichen und Produktionsqualität in Echtzeit zu verfolgen. Orq.ai stellt Prompt-Optimierungs-Frameworks und Bewertungswerkzeuge speziell für Unternehmen bereit. OpenAI’s Playground und ähnliche modell-spezifische Oberflächen ermöglichen schnelles Prompt-Experimentieren. Die wirkungsvollste Strategie kombiniert mehrere Tools: Spezialplattformen für Entdeckung und Test, Integration von Bewertungswerkzeugen in den Entwicklungsprozess und Monitoring für die Produktion. Die Investition in professionelles Tooling amortisiert sich meist binnen Wochen durch bessere Prompt-Qualität und schnellere Iterationen.
Fallstudie 1: Finanzdienstleister – Eine große Investmentbank implementierte einen systematischen Prompt-Entdeckungsprozess für Aktienanalysen. Durch das Testen von 15 Prompt-Varianten und die Messung der Genauigkeit am Konsens der Analysten wurde ein hochwertiger Prompt identifiziert, der die Analysequalität um 35 % erhöhte und zugleich die Analystenzeit um 40 % reduzierte. Der Prompt integrierte spezifische Finanzmetriken, Branchenkontext und einen strukturierten Argumentationsrahmen. Die Einführung bei 200 Analysten brachte einen jährlichen Produktivitätsgewinn von 2,3 Mio. $.
Fallstudie 2: E-Commerce-Plattform – Ein Onlinehändler stellte fest, dass Produkt-Empfehlungs-Prompts unterdurchschnittlich performten. Durch Hinzufügen von Kontext zur Einkaufshistorie und den Einsatz von Chain-of-Thought-Reasoning stiegen die Conversion-Rate um 18 % und der durchschnittliche Bestellwert um 12 %. Der optimierte Prompt verarbeitet nun täglich über 50.000 Empfehlungen bei 92 % Kundenzufriedenheit.
Fallstudie 3: Gesundheitsdienstleister – Ein Krankenhaus entwickelte hochwertige Prompts zur Unterstützung bei der klinischen Dokumentation. Die Prompts integrierten medizinische Terminologie, Patientenhistorie und Compliance-Anforderungen und reduzierten die Dokumentationszeit um 25 % bei gleichzeitig gesteigerter Genauigkeit und Vollständigkeit. Über 500 Klinikmitarbeitende in mehreren Abteilungen profitieren davon.
Fallstudie 4: Rechtsdienstleistungen – Eine Kanzlei implementierte Prompts für Vertragsanalyse und Due Diligence. Die hochwertigen Prompts enthielten spezifische Rechtsrahmen, Präzedenzfälle und Risikobewertungskriterien. Die Zeit für Vertragsprüfungen sank um 30 %, die Genauigkeit bei der Risikoerkennung stieg um 45 %. Die Kanzlei konnte so 20 % mehr Mandanten aufnehmen, ohne das Personal aufzustocken.
Diese Fallstudien zeigen, dass hochwertige Prompts in verschiedensten Branchen und Anwendungsfällen messbaren ROI liefern.
Organisationen machen bei der Entdeckung und Implementierung von Prompts häufig vorhersehbare Fehler. Fallstrick 1: Unzureichendes Testen – Prompts werden ohne gründliche Bewertung in Produktion gebracht und liefern schlechte Ergebnisse. Lösung: Bewertungsrahmen vor Optimierung aufbauen und Leistung an repräsentativen Datensätzen messen.
Fallstrick 2: Überoptimierung auf Benchmarks – Prompts werden auf Testdaten optimiert, versagen aber im Praxiseinsatz. Lösung: Mit vielfältigen, repräsentativen Daten testen und Produktion kontinuierlich überwachen.
Fallstrick 3: Ignorieren von Kontext und Fachwissen – Generische Prompts ohne branchenspezifisches Wissen liefern schlechtere Ergebnisse. Lösung: Zeit investieren, um die Domäne zu verstehen und dieses Wissen in Prompts einzubetten.
Fallstrick 4: Kostenaspekte vernachlässigen – Fokus nur auf Genauigkeit, während Tokenverbrauch und Latenz ignoriert werden. Lösung: Kosten-Nutzen-Kompromisse vorab festlegen und Gesamtbetriebskosten messen.
Fallstrick 5: Fehlende Dokumentation und Wissensaustausch – Wertvolle Prompts bleiben bei Einzelpersonen isoliert. Lösung: Prompt-Bibliothek mit klarer Dokumentation und Versionskontrolle einführen.
Fallstrick 6: Keine Iteration – Prompts werden nach dem Rollout nicht mehr weiterentwickelt. Lösung: Kontinuierlichen Verbesserungsprozess mit regelmäßiger Bewertung und Anpassung einführen.
Das Feld des Prompt-Engineerings entwickelt sich rasant mit einer Reihe neuer Trends, die die Entdeckung und Optimierung von Prompts prägen werden. Automatisierte Prompt-Generierung – KI-Systeme, die Prompt-Varianten automatisch erstellen und testen, reduzieren manuellen Aufwand und beschleunigen Entdeckungszyklen. Multimodales Prompting – Mit Modellen, die Bilder, Audio und Video verarbeiten, müssen Prompts verschiedene Datentypen kombinieren. Adaptives Prompting – Prompts, die sich dynamisch an Nutzerkontext, frühere Interaktionen und Echtzeitdaten anpassen, werden Standard. Prompt-Marktplätze – Plattformen zum Kaufen, Verkaufen und Teilen hochwertiger Prompts entstehen, ähnlich wie App-Stores. Regulatorische Konformität in Prompts – Mit zunehmender Regulierung müssen Prompts Compliance-Anforderungen und Prüfpfade explizit abbilden. Modellübergreifende Optimierung – Tools, die Prompts automatisch für verschiedene KI-Modelle anpassen, reduzieren Anbieterabhängigkeit. Organisationen, die heute in Prompt-Discovery-Infrastruktur investieren, sichern sich im Wettbewerb künftig deutliche Vorteile.
Ein hochwertiger Prompt liefert messbaren ROI, indem er spezifische Branchenprobleme löst, manuelle Arbeit reduziert, die Konsistenz verbessert und sich an Unternehmenszielen orientiert. Er wird auf Grundlage von Genauigkeit, Effizienz und Einfluss auf Geschäftskennzahlen bewertet und nicht nur daran, ob richtige Antworten erzeugt werden.
Beginnen Sie mit der Definition klarer Anforderungen für Ihren Anwendungsfall, erstellen Sie repräsentative Testdatensätze, legen Sie Bewertungskriterien fest und testen Sie iterativ verschiedene Prompt-Variationen. Dokumentieren Sie erfolgreiche Muster und teilen Sie diese über eine Prompt-Bibliothek oder ein Managementsystem im Team.
Ein guter Prompt funktioniert in bestimmten Szenarien gut. Ein hochwertiger Prompt arbeitet zuverlässig bei vielfältigen Eingaben, Randfällen und sich entwickelnden Anforderungen und liefert dabei messbaren Geschäftsnutzen und ROI. Er wird durch systematisches Testen und kontinuierliche Verbesserung optimiert.
Definieren Sie klare Erfolgskriterien, die mit Ihren Unternehmenszielen übereinstimmen (Genauigkeit, Konsistenz, Effizienz, Sicherheit, Formatvorgaben). Nutzen Sie automatisierte Bewertung für objektive Kriterien und modellbasierte Bewertung für subjektive Aspekte. Verfolgen Sie die Leistung im Zeitverlauf, um Trends und Verbesserungsmöglichkeiten zu erkennen.
Während einige Grundprinzipien universell gelten, sind hochwertige Prompts in der Regel branchenspezifisch. Verschiedene Sektoren haben einzigartige Anforderungen, Einschränkungen und Erfolgskriterien, die eine angepasste Prompt-Gestaltung und -Optimierung erfordern.
Suchen Sie nach Plattformen, die Prompt-Versionierung, automatisierte Bewertung, Kollaborationsfunktionen und Performance-Analysen bieten. AmICited.com hilft Ihnen dabei, zu überwachen, wie KI-Systeme Ihre Marke referenzieren, während FlowHunt.io KI-Automatisierung für den Aufbau komplexer Workflows ermöglicht.
Etablieren Sie kontinuierliche Verbesserungszyklen mit regelmäßiger Bewertung anhand Ihrer Testdatensätze. Aktualisieren Sie Prompts bei Leistungsverschlechterungen, neuen Anwendungsfällen oder Verbesserungsmöglichkeiten basierend auf Nutzerfeedback und Produktionsdaten.
Häufige Fallstricke sind übermäßige Komplexität der Prompts, das Ignorieren von Randfällen, fehlende Versionskontrolle, unzureichendes Testen, keine Wirkungsmessung und die Behandlung von Prompts als statisch. Vermeiden Sie dies durch systematische, datengestützte Ansätze mit guter Dokumentation und Bewertungsrahmen.
Entdecken Sie, welche KI-Modelle und -Systeme Ihre Inhalte zitieren. Verfolgen Sie die Präsenz Ihrer Marke in KI-generierten Antworten über GPTs, Perplexity und Google AI Overviews mit AmICited.
Erfahren Sie, was hochwertige KI-Prompts sind, wie sie Markennennungen in KI-Systemen auslösen und Strategien zur Erstellung von Anfragen, die die Sichtbarkeit ...

Erfahren Sie, wie die Formulierung, Klarheit und Spezifität von Prompts die Antwortqualität von KIs direkt beeinflussen. Lernen Sie Techniken des Prompt Enginee...
Erfahren Sie, was Prompt Engineering ist, wie es mit KI-Suchmaschinen wie ChatGPT und Perplexity funktioniert, und entdecken Sie wichtige Techniken, um Ihre KI-...