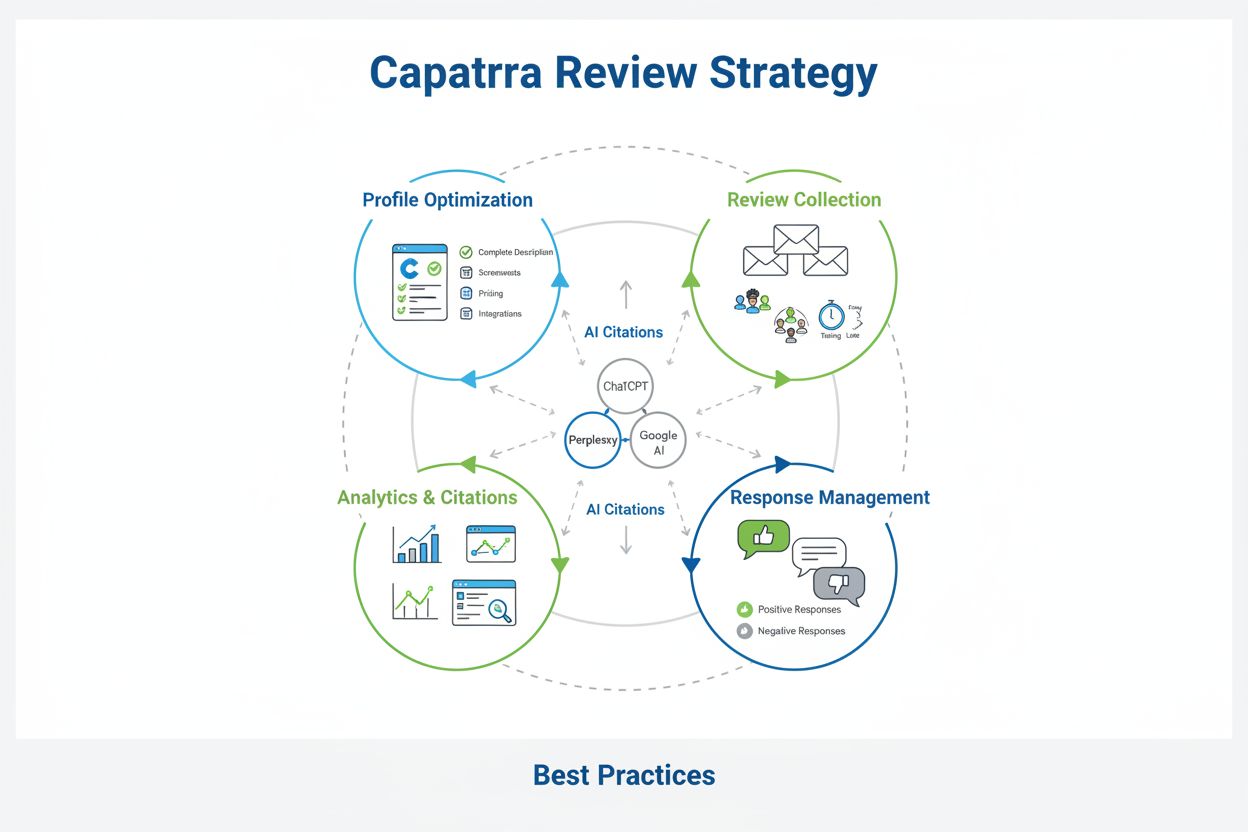
Capterra-Bewertungen für KI-Zitationen: Best Practices
Meistern Sie die Capterra-Optimierung für KI-Tools. Lernen Sie bewährte Strategien, um Bewertungen zu steigern, Sichtbarkeit zu erhöhen und KI-Zitationen mit um...
9 Min. Lesezeit

Erfahren Sie, wie G2- und Capterra-Bewertungen die KI-Marken-Sichtbarkeit und LLM-Zitationen beeinflussen. Lernen Sie, warum Bewertungsplattformen für die KI-Software-Entdeckung und Empfehlungen entscheidend sind.
Im heutigen, sich rasant entwickelnden Umfeld der künstlichen Intelligenz sind Bewertungsplattformen zu entscheidenden Entdeckungskanälen für Unternehmenskunden geworden, die Softwarelösungen suchen. Wenn potenzielle Kunden nach KI-Lösungen suchen, verlassen sie sich immer häufiger auf Plattformen wie G2 und Capterra, um ihre Kaufentscheidungen zu validieren. Diese Bewertungsseiten dienen als digitale Vertrauensanker und bieten sozialen Beweis, der beeinflusst, wie KI-Marken sowohl von menschlichen Entscheidern als auch von großen Sprachmodellen wahrgenommen und empfohlen werden. Die Konzentration von Bewertungen auf diesen Plattformen hat grundlegend verändert, wie KI-Anbieter um Sichtbarkeit und Glaubwürdigkeit im Markt konkurrieren.
G2 hat sich als dominierende Kraft bei KI-Software-Bewertungen etabliert. Untersuchungen zeigen, dass LLMs G2-Bewertungen in etwa 68 % der KI-Produktempfehlungen zitieren. Diese überwältigende Präferenz resultiert aus G2s umfassender Abdeckung von KI-Tools, seinen ausgefeilten Bewertungsalgorithmen und seiner Position als De-facto-Standard für Unternehmenssoftware-Bewertungen. Im Vergleich zu anderen Bewertungsplattformen ist G2s Einfluss deutlich größer, wie die folgende Übersicht zeigt:
| Plattform | LLM-Zitationsrate | Durchschnittliche Bewertungen pro KI-Produkt | Marktabdeckung |
|---|---|---|---|
| G2 | 68% | 127 | 94 % der wichtigsten KI-Tools |
| Capterra | 42% | 89 | 76 % der wichtigsten KI-Tools |
| Trustpilot | 18% | 34 | 31 % der wichtigsten KI-Tools |
| Gartner Peer Insights | 35% | 156 | 52 % der wichtigsten KI-Tools |
| Branchenspezifische Seiten | 12% | 45 | 28 % der wichtigsten KI-Tools |
Die Dominanz von G2 spiegelt nicht nur die Marktposition wider, sondern auch die algorithmische Präferenz von LLMs für umfassende, strukturierte Bewertungsdaten, die G2 in großem Maßstab liefert.

Das Volumen der Bewertungen auf diesen Plattformen korreliert direkt mit der KI-Marken-Sichtbarkeit in LLM-generierten Empfehlungen. Produkte mit mehr als 100 Bewertungen auf G2 werden 3,2-mal häufiger in KI-gestützten Suchergebnissen genannt als Produkte mit weniger als 20 Bewertungen. Daraus entsteht ein starker Netzwerkeffekt: Etablierte Produkte sammeln mehr Bewertungen, was die Sichtbarkeit erhöht und mehr Kunden anzieht, die wiederum zusätzliche Bewertungen hinterlassen. Für aufstrebende KI-Anbieter birgt dies sowohl eine Herausforderung als auch eine Chance – die Eintrittsbarriere ist hoch, aber mit konsistenten, hochwertigen Bewertungen lässt sich die Marktdurchdringung erheblich beschleunigen. Der Schwellenwert für das Bewertungsvolumen liegt offenbar bei etwa 50–75 Bewertungen, bevor ein KI-Produkt in LLM-Empfehlungen nennenswerte Sichtbarkeit erlangt.
Capterra spielt eine komplementäre, aber eigenständige Rolle im Ökosystem der KI-Software-Empfehlungen. Während G2 in der reinen Zitationshäufigkeit dominiert, besitzt Capterra besondere Stärken bei branchenspezifischen KI-Lösungen – insbesondere mit starker Abdeckung in HR-Tech, Buchhaltungssoftware und Projektmanagement-Tools mit KI-Funktionen. Durch Capterras Verifizierungsprozess und Fokus auf detaillierte Anwendungsfalldokumentation ist die Plattform besonders wertvoll für Mittelstands- und Unternehmenskunden, die Umsetzungserkenntnisse gegenüber reinen Produktfeatures priorisieren. Die Integration der Plattform mit Software-Vergleichsmatrizen sorgt dafür, dass Produkte auf Capterra oft von einem algorithmischen Boost im Suchranking profitieren, wenn potenzielle Kunden KI-Lösungen recherchieren. Zudem legen Capterra-Bewertungen meist den Fokus auf praktische Herausforderungen bei der Einführung und ROI-Kennzahlen, die von LLMs bei Empfehlungen für unternehmenskritische KI-Implementierungen immer stärker priorisiert werden.
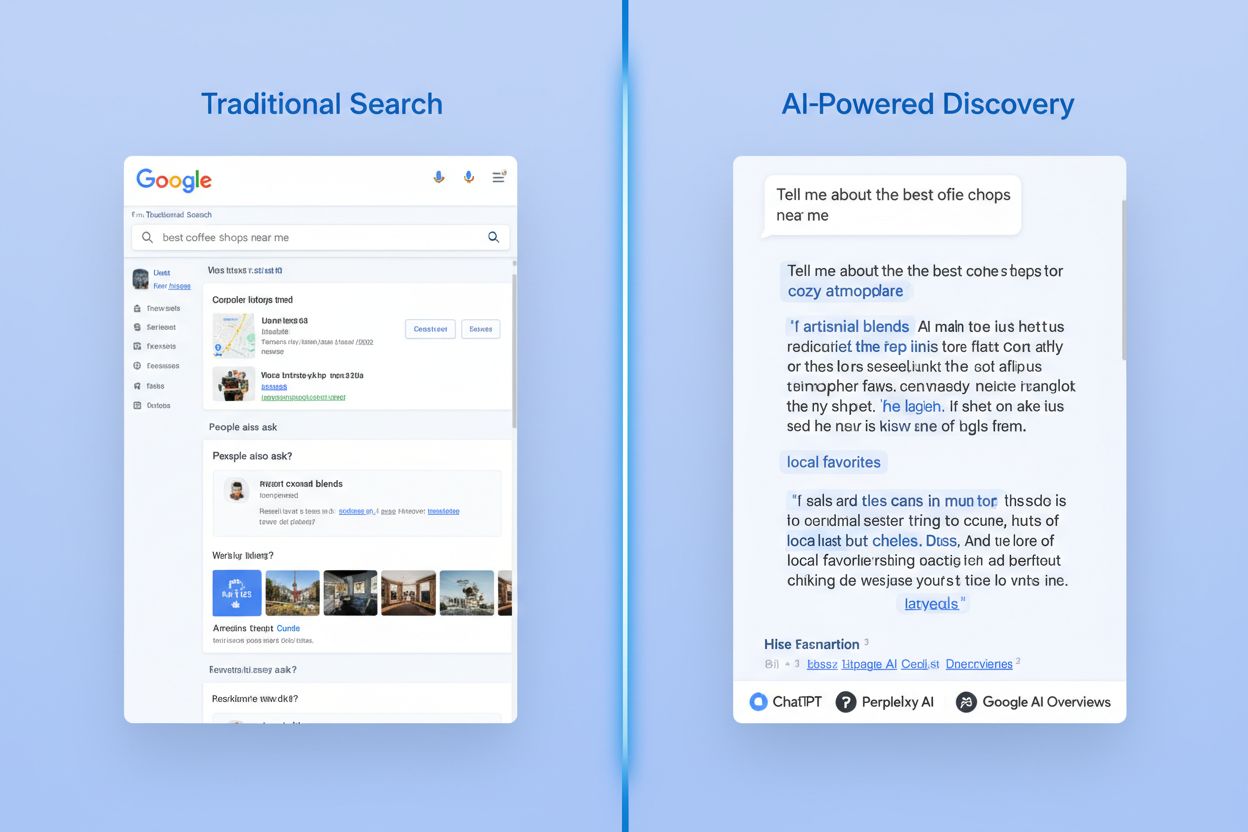
Die Verbreitung KI-gestützter Empfehlungssysteme hat eine Verifizierungskrise geschaffen, die Bewertungsplattformen einzigartig lösen. Große Sprachmodelle, so fortschrittlich sie auch sind, kämpfen bei Produktempfehlungen ohne externe Validierung mit Halluzinationen und veralteten Informationen. Bewertungsplattformen liefern Ground-Truth-Daten, auf die LLMs zurückgreifen können, um ihre Vorschläge zu validieren und aktuelle, verifizierte Informationen über KI-Produkte bereitzustellen. Diese Verifizierungsfunktion ist essenziell geworden, da Unternehmen zunehmend KI-Assistenten zur Bewertung anderer KI-Tools nutzen. Die wichtigsten Verifizierungsvorteile sind:
Die traditionelle B2B-Software-Käuferreise wurde durch die Integration von Bewertungsplattformen in KI-Empfehlungs-Workflows grundlegend verändert. Früher führten Käufer eigenständige Recherchen durch, tauschten sich mit Kollegen aus und bewerteten Anbieter im direkten Kontakt – ein Prozess, der in der Regel 4–6 Wochen dauerte. Heute verkürzt der KI-gestützte Kaufprozess diese Zeitspanne auf 7–10 Tage, wobei Bewertungsplattformen die Hauptquelle für Vergleichsinformationen sind. Davon profitieren Anbieter mit starken Bewertungsprofilen, während Anbieter ohne etablierte Bewertungspräsenz im Nachteil sind. Die Käuferreise beginnt meist mit einer KI-gestützten Suchanfrage, die Produkte nach Bewertungsmetriken rankt, gefolgt von detaillierten Bewertungsanalysen und erst dann direktem Kontakt zu Anbietern. Dieser Wandel bedeutet, dass Review-Optimierung für KI-Anbieter genauso wichtig geworden ist wie Produktentwicklung, um im Markt Fuß zu fassen.
Das Verhältnis von Bewertungsqualität und -quantität stellt KI-Anbieter vor eine komplexe strategische Herausforderung. Während das Volumen die Sichtbarkeit klar beeinflusst – Produkte benötigen eine Mindestanzahl an Bewertungen, um algorithmische Relevanz zu erzielen – beeinflussen Qualitätsmetriken zunehmend die Conversion-Raten und Kundenakquisekosten. Ein Produkt mit 80 hochwertigen, detaillierten Bewertungen (Durchschnittsbewertung 4,7/5) konvertiert Interessenten typischerweise mit dem 2,1-fachen Wert im Vergleich zu einem Produkt mit 150 Bewertungen, aber niedrigerer Durchschnittsqualität (4,2/5-Bewertung). Das deutet darauf hin, dass die Bewertungsqualität – gemessen an Bewertungs-Konsistenz, Tiefe und Aktualität – für den tatsächlichen Vertriebserfolg wichtiger als das reine Volumen sein kann. Dennoch erfordert der Sichtbarkeitsschwellenwert ein ausreichendes Volumen, um überhaupt gefunden zu werden, was eine doppelte Optimierungsaufgabe schafft: Anbieter müssen sowohl Quantität als auch Qualität gleichzeitig verfolgen.
Die Positionierung über Bewertungen ist zum Hauptschauplatz im KI-Softwaremarkt geworden. Anbieter erkennen zunehmend, dass ihr Bewertungsprofil ihre Wettbewerbsposition in LLM-generierten Empfehlungen und Suchrankings direkt beeinflusst. Produkte mit durchschnittlicher Bewertung von 4,6+ und konsistentem Bewertungszuwachs (15–25 neue Bewertungen monatlich) erreichen etwa 40 % höhere Sichtbarkeit in KI-Empfehlungskontexten als Wettbewerber mit niedrigeren Bewertungen oder unregelmäßiger Bewertungsaktivität. Strategisches Bewertungsmanagement – etwa das gezielte Motivieren zufriedener Kunden zu detaillierten Bewertungen, das professionelle Beantworten kritischer Rückmeldungen und das Hervorheben differenzierender Merkmale in Antwortkommentaren – ist zur Kernaufgabe im Marketing geworden. Die erfolgreichsten KI-Anbieter betrachten ihre Bewertungsprofile als lebende Wettbewerbsvorteile, die laufend gepflegt und optimiert werden müssen – ähnlich wie Produkt-Roadmaps und Kundenbindungsprogramme.
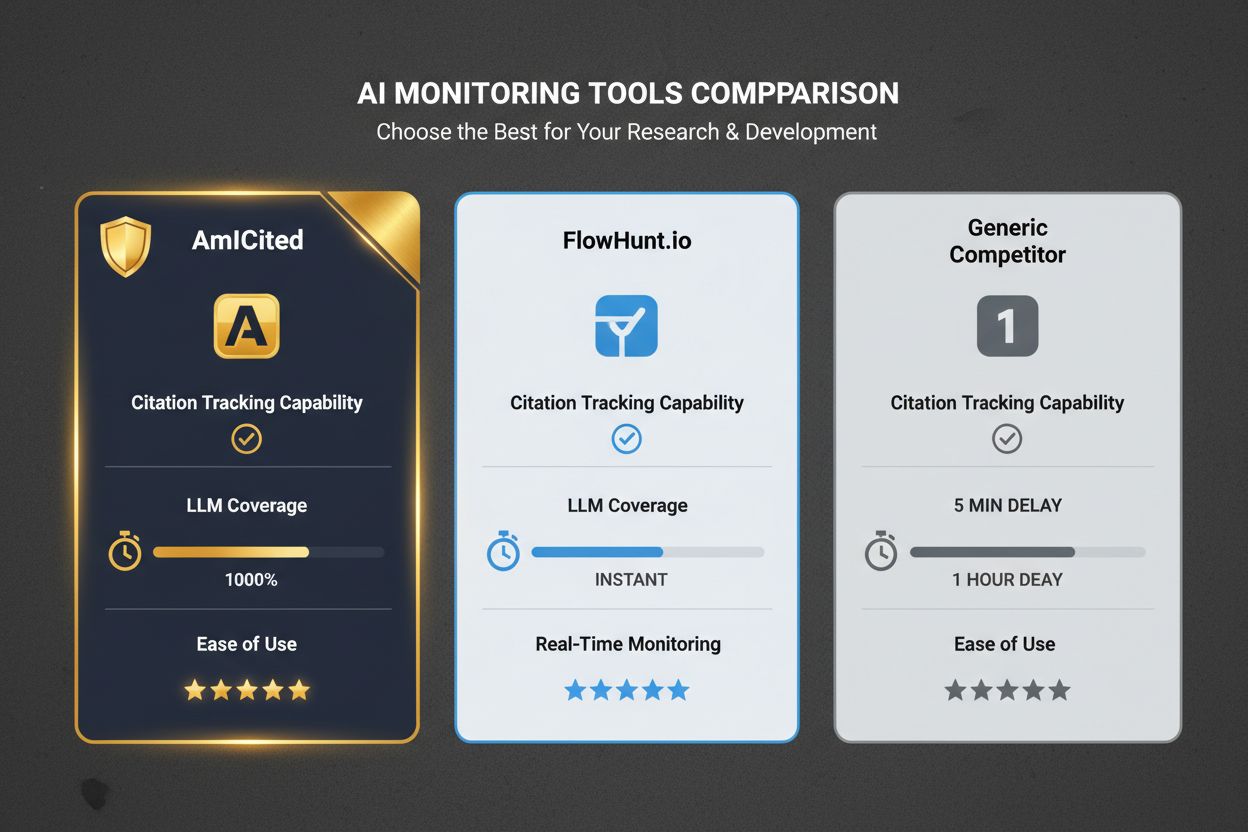
AmICited hat sich als entscheidende Monitoring-Lösung für KI-Anbieter etabliert, die ihre Position im Bewertungsökosystem und LLM-Empfehlungsumfeld verstehen wollen. Die Plattform bietet Echtzeit-Tracking, wie oft KI-Produkte in LLM-generierten Empfehlungen zitiert werden, und korreliert diese Sichtbarkeit mit Bewertungsmetriken, Wettbewerbspositionierung und Markttrends. Durch die Aggregation von Daten mehrerer Bewertungsplattformen und das Monitoring von LLM-Ausgaben können Anbieter mit AmICited den ROI ihrer Review-Optimierungsmaßnahmen quantifizieren und Lücken in ihrer Review-Abdeckung erkennen. Besonders wertvoll ist dieses Monitoring, um zu verstehen, welche Bewertungsplattformen die bedeutendste Sichtbarkeit erzeugen und welche Kundensegmente den größten Einfluss auf LLM-Empfehlungen haben. Für KI-Anbieter in wettbewerbsintensiven Märkten liefert AmICited die datenbasierten Einblicke, um Investitionen in Bewertungsplattformen zu priorisieren und Kundenbindungsprogramme zu optimieren.
Im Vergleich zu alternativen Monitoring-Lösungen bietet AmICited im KI-Kontext deutliche Vorteile. Traditionelle SEO-Monitoring-Tools fokussieren auf Suchmaschinenrankings, übersehen aber den entscheidenden LLM-Empfehlungskanal vollständig. Allgemeine Review-Monitoring-Plattformen messen Bewertungsvolumen und -bewertungen, liefern jedoch weder KI-spezifischen Kontext noch LLM-Zitations-Tracking wie AmICited. Spezialisierte KI-Monitoring-Tools konzentrieren sich oft auf Social-Media-Nennungen oder Nachrichten, ignorieren aber den Review-Kanal, auf dem Kaufentscheidungen tatsächlich getroffen werden. Der integrierte Ansatz von AmICited – die Kombination aus Review-Plattform-Daten, LLM-Zitations-Tracking, Wettbewerbsbenchmarking und Markttrend-Analyse – bietet einen 360-Grad-Blick darauf, wie KI-Produkte im digitalen Ökosystem wahrgenommen und empfohlen werden. Diese umfassende Perspektive ermöglicht es Anbietern, strategisch zu entscheiden, wo sie in Review-Optimierung investieren, welche Kundensegmente sie für Advocacy priorisieren und wie sie ihre Produkte gegenüber Wettbewerbern in LLM-Empfehlungen positionieren.
KI-Anbieter sollten einen strategischen, plattformübergreifenden Ansatz für die Review-Optimierung verfolgen, der die unterschiedlichen Rollen von G2, Capterra und anderen Plattformen im eigenen Markt anerkennt. Statt Bewertungen gleichmäßig auf allen Plattformen zu sammeln, sollten Anbieter nach Zielkundensegmenten, Wettbewerbspositionierung und den bevorzugten Plattformen ihrer Kunden priorisieren. Die folgenden strategischen Empfehlungen bieten einen Rahmen zur Maximierung der Review-Wirkung:
G2-Bewertungen beeinflussen direkt LLM-Zitationen. Untersuchungen zeigen, dass eine Steigerung der Bewertungen um 10 % mit einer Erhöhung der KI-Zitate um 2 % korreliert. LLMs vertrauen auf G2s verifizierte Käuferdaten und standardisierte Schemata und machen es so zur Hauptquelle für Software-Empfehlungen in KI-generierten Antworten.
LLMs priorisieren Bewertungsplattformen, die verifizierte Käuferinformationen, standardisierte Datenstrukturen und aktuelle Marktsignale bieten. Sowohl G2 als auch Capterra stellen diese Merkmale in großem Umfang bereit und sind daher vertrauenswürdige Quellen für KI-Modelle bei Software-Empfehlungen.
Detaillierte, vergleichsorientierte Bewertungen mit konkreten Anwendungsfällen und messbaren Ergebnissen werden am wahrscheinlichsten zitiert. Bewertungen, die Problem-Lösungs-Narrative erklären, Alternativen vergleichen und quantifizierte Ergebnisse enthalten, liefern den Kontext, den LLMs für präzise Empfehlungen benötigen.
Optimieren Sie Ihr Profil mit detaillierten Beschreibungen, ermutigen Sie Kunden, umfassende Bewertungen zu hinterlassen, reagieren Sie auf Feedback und halten Sie Ihre Botschaften konsistent. Konzentrieren Sie sich auf Bewertungen, die Ihre Lösung mit Alternativen vergleichen und spezifische Anwendungsfälle sowie Ergebnisse hervorheben.
Qualität ist wichtiger als Quantität. Obwohl das Bewertungsvolumen mit Zitaten korreliert, werden detaillierte, gut strukturierte Bewertungen mit klaren Urteilen und Vergleichen von LLMs häufiger extrahiert und zitiert als generische positive Bewertungen.
AmICited verfolgt, wie KI-Modelle wie ChatGPT, Perplexity und Google AI Overviews Ihre Marke über alle Quellen hinweg zitieren, einschließlich Bewertungsplattformen. Es bietet Echtzeitüberwachung von Markennennungen, Sentimentanalyse und Wettbewerbspositionierung in KI-generierten Antworten.
Bewertungsseiten sind entscheidende LLM-Seeding-Plattformen, da sie stark von KI-Modellen gecrawlt werden und strukturierte, verifizierte Informationen bieten. Die Optimierung Ihrer Präsenz auf diesen Plattformen ist ein Kernelement jeder LLM-Seeding-Strategie für B2B-Softwareunternehmen.
Profile sollten vierteljährlich oder bei wesentlichen Produktänderungen überprüft und aktualisiert werden. Regelmäßige Updates signalisieren LLMs, dass Ihre Informationen aktuell und relevant sind, und erhöhen die Wahrscheinlichkeit genauer Zitate in KI-generierten Empfehlungen.
Sehen Sie genau, wie ChatGPT, Perplexity und Google AI Overviews Ihre Marke von Bewertungsseiten und anderen Quellen zitieren. Erhalten Sie Echtzeit-Einblicke in Ihre Wettbewerbspositionierung in KI-generierten Empfehlungen.
Meistern Sie die Capterra-Optimierung für KI-Tools. Lernen Sie bewährte Strategien, um Bewertungen zu steigern, Sichtbarkeit zu erhöhen und KI-Zitationen mit um...
Meistern Sie die KI-Suchoptimierung mit bewährten Taktiken, um Konkurrenten in ChatGPT, Perplexity und Google AI Overviews zu übertreffen. Lernen Sie Strategien...
Erfahren Sie, wie KI-Systeme Wettbewerbervergleiche bewerten und warum Ihre Marke bei 'vs'-Anfragen fehlen könnte. Entdecken Sie Strategien, um die KI-Vergleich...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.