Entdecken Sie, wie Retrieval-Augmented Generation KI-Zitate transformiert und eine genaue Quellenzuordnung sowie fundierte Antworten in ChatGPT, Perplexity und Google AI Overviews ermöglicht.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
Große Sprachmodelle haben die KI revolutioniert, weisen aber einen kritischen Mangel auf: Wissensgrenzen. Diese Modelle werden mit Daten bis zu einem bestimmten Zeitpunkt trainiert und können daher keine Informationen jenseits dieses Datums abrufen. Neben dieser Alterung leiden traditionelle LLMs unter Halluzinationen—sie erzeugen selbstsicher falsche Informationen, die plausibel klingen, und geben keine Quellen für ihre Behauptungen an. Wenn Unternehmen aktuelle Marktdaten, eigene Forschung oder überprüfbare Fakten benötigen, versagen traditionelle LLMs und lassen die Nutzer mit Antworten zurück, denen sie weder vertrauen noch die sie überprüfen können.
Was ist RAG – Kern-Definition & Komponenten
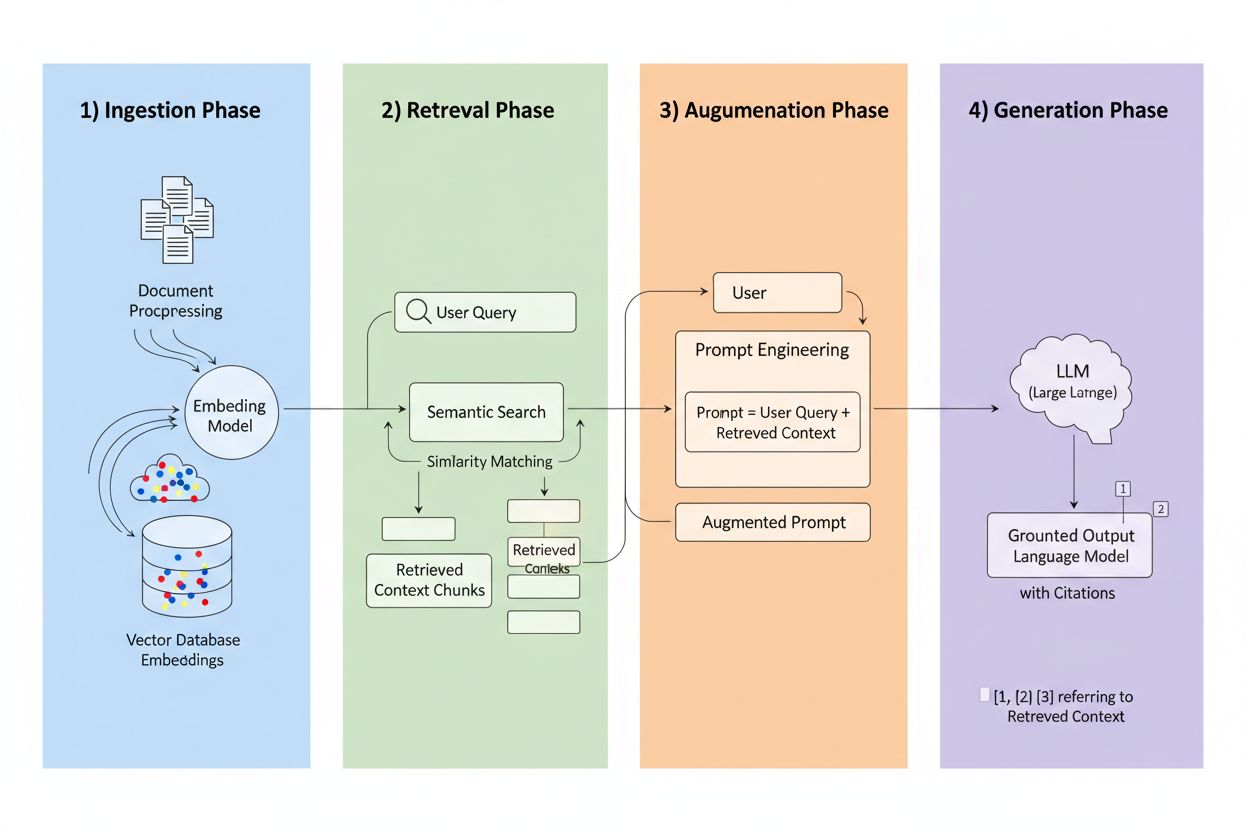
Retrieval-Augmented Generation (RAG) ist ein Framework, das die generative Kraft von LLMs mit der Präzision von Information-Retrieval-Systemen verbindet. Anstatt sich ausschließlich auf Trainingsdaten zu verlassen, holen RAG-Systeme relevante Informationen aus externen Quellen, bevor sie Antworten generieren, und schaffen so eine Pipeline, die Antworten auf tatsächliche Daten stützt. Die vier Kernkomponenten arbeiten zusammen: Ingestion (Umwandlung von Dokumenten in durchsuchbare Formate), Retrieval (Auffinden der relevantesten Quellen), Augmentation (Anreicherung des Prompts mit abgerufenen Kontexten) und Generation (Erstellung der finalen Antwort mit Zitaten). So vergleicht sich RAG mit traditionellen Ansätzen:
Aspekt
Traditionelles LLM
RAG-System
Wissensquelle
Statische Trainingsdaten
Externe indizierte Quellen
Zitierfähigkeit
Keine/halluziniert
Rückverfolgbar zu Quellen
Genauigkeit
Fehleranfällig
Faktenbasiert
Echtzeit-Daten
Nein
Ja
Halluzinationsrisiko
Hoch
Gering
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Wie RAG Retrieval funktioniert – Technischer Deep Dive
Die Retrieval-Engine ist das Herzstück von RAG und weit ausgefeilter als einfaches Keyword-Matching. Dokumente werden in Vektor-Embeddings umgewandelt—mathematische Repräsentationen, die semantische Bedeutung erfassen—und ermöglichen so das Auffinden konzeptuell ähnlicher Inhalte, selbst wenn die genauen Wörter nicht übereinstimmen. Das System teilt Dokumente in handhabbare Stücke, typischerweise 256–1024 Tokens, um den Kontext zu erhalten und gleichzeitig die Präzision beim Retrieval zu steigern. Die fortschrittlichsten RAG-Systeme verwenden hybride Suche, die semantische Ähnlichkeit mit traditionellem Keyword-Matching kombiniert, um sowohl konzeptuelle als auch exakte Übereinstimmungen zu erfassen. Ein Reranking-Mechanismus bewertet anschließend diese Kandidaten, oft mithilfe von Cross-Encoder-Modellen, die die Relevanz genauer einschätzen als das initiale Retrieval. Die Relevanz berechnet sich aus mehreren Signalen: semantische Ähnlichkeit, Keyword-Überschneidungen, Metadaten-Matching und Domain-Autorität. Der gesamte Prozess erfolgt innerhalb von Millisekunden und liefert Nutzern schnelle, präzise Antworten ohne wahrnehmbare Verzögerung.
Der Zitier-Vorteil
Hier verändert RAG das Zitier-Landschaft grundlegend: Wenn ein System Informationen aus einer bestimmten indizierten Quelle abruft, wird diese Quelle rückverfolgbar und überprüfbar. Jeder Textabschnitt kann dem ursprünglichen Dokument, der URL oder der Publikation zugeordnet werden, sodass das Zitieren automatisch statt halluziniert erfolgt. Dieser grundlegende Wandel schafft eine nie dagewesene Transparenz in KI-Entscheidungen—Nutzer sehen genau, welche Quellen die Antwort beeinflusst haben, können Aussagen eigenständig prüfen und die Glaubwürdigkeit der Quelle selbst einschätzen. Anders als bei traditionellen LLMs, in denen Zitate oft erfunden oder generisch sind, beruhen RAG-Zitate auf tatsächlichen Retrieval-Ereignissen. Diese Rückverfolgbarkeit schafft enorm viel Vertrauen, da Menschen Informationen validieren können und nicht auf Glauben angewiesen sind. Für Content-Ersteller und Publisher bedeutet das, dass ihre Arbeit durch KI-Systeme entdeckt und anerkannt werden kann—und somit völlig neue Sichtbarkeitskanäle erschlossen werden.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Qualitätsfaktoren von Zitaten in RAG-Systemen
Nicht alle Quellen sind in RAG-Systemen gleich, und mehrere Faktoren bestimmen, welche Inhalte am häufigsten zitiert werden:
Autorität: Domain-Reputation, Backlink-Profile und Präsenz in Wissensgraphen signalisieren Vertrauenswürdigkeit für Retrieval-Algorithmen
Aktualität: Inhalte, die im 48–72-Stunden-Takt aktualisiert werden, schneiden besser ab, da Frische auf aktive Pflege und Zuverlässigkeit hinweist
Relevanz: Semantische Übereinstimmung mit Nutzeranfragen entscheidet, ob Inhalte überhaupt in Retrieval-Ergebnissen erscheinen
Struktur: Klare Hierarchie, beschreibende Überschriften und semantische Markups helfen Systemen, Informationen korrekt zu erkennen und zu extrahieren
Faktische Dichte: Inhalte mit präzisen Daten, Statistiken und Zitaten liefern mehr „retrievable nuggets“ als allgemeine Übersichten
Wissensgraph: Präsenz in Wikipedia, Wikidata oder branchenspezifischen Wissensdatenbanken erhöht die Zitierwahrscheinlichkeit erheblich
Jeder Faktor verstärkt den anderen—ein gut strukturierter, häufig aktualisierter Artikel von einer autoritativen Domain mit starken Backlinks und Wissensgraph-Präsenz wird in RAG-Systemen zum Zitiermagneten. Das schafft ein neues Optimierungsparadigma, bei dem Sichtbarkeit weniger von SEO-Traffic abhängt, sondern davon, eine vertrauenswürdige, strukturierte Informationsquelle zu werden.
Wie verschiedene KI-Plattformen RAG für Zitate nutzen
Verschiedene KI-Plattformen implementieren RAG mit unterschiedlichen Strategien und erzeugen damit variierende Zitiermuster. ChatGPT gewichtet Wikipedia-Quellen stark: Studien zeigen, dass etwa 26–35 % der Zitate allein von Wikipedia stammen, was deren Autorität und strukturierte Form widerspiegelt. Google AI Overviews nutzen eine vielfältigere Auswahl und greifen auf Nachrichtenportale, wissenschaftliche Arbeiten und Foren zurück – Reddit erscheint trotz geringer Autorität in etwa 5 % aller Zitate. Perplexity AI zitiert typischerweise 3–5 Quellen pro Antwort und zeigt eine Vorliebe für branchenspezifische Publikationen und aktuelle Nachrichten, um Vollständigkeit und Aktualität zu optimieren. Diese Plattformen gewichten Domain-Autorität unterschiedlich—manche priorisieren klassische Marker wie Backlinks und Domainalter, andere legen mehr Wert auf Aktualität und semantische Relevanz. Das Verständnis dieser plattformspezifischen Retrieval-Strategien ist für Content-Ersteller entscheidend, denn die Optimierung für das RAG-System einer Plattform kann sich erheblich von anderen unterscheiden.
RAG vs traditionelle Suche – Auswirkungen auf Zitate
Der Aufstieg von RAG stellt die klassische SEO-Logik auf den Kopf. Bei der Suchmaschinenoptimierung korrelieren Zitate und Sichtbarkeit direkt mit Traffic—nur wer Klicks bekommt, zählt. RAG kehrt diese Gleichung um: Inhalte können zitiert werden und KI-Antworten beeinflussen, ohne jeglichen Traffic zu generieren. Ein gut strukturierter, autoritativer Artikel kann täglich in Dutzenden KI-Antworten erscheinen, ohne einen einzigen Klick zu erhalten, weil Nutzer ihre Antwort direkt aus der KI-Zusammenfassung bekommen. Das heißt: Autoritätssignale sind wichtiger denn je, denn sie sind der primäre Bewertungsmechanismus für RAG-Systeme zur Einschätzung von Quellenqualität. Konsistenz über alle Plattformen hinweg wird entscheidend—wenn Ihre Inhalte auf Ihrer Website, LinkedIn, Branchendatenbanken und Wissensgraphen erscheinen, sehen RAG-Systeme verstärkte Autoritätssignale. Die Präsenz in Wissensgraphen wird von einem „Nice-to-have“ zur essenziellen Infrastruktur, da diese strukturierten Datenbanken die primären Retrieval-Quellen vieler RAG-Implementierungen sind. Das Zitier-Spiel hat sich grundlegend gewandelt: von „Traffic generieren“ zu „vertrauenswürdige Informationsquelle werden“.
Inhalte für RAG-Zitate optimieren
Um RAG-Zitate zu maximieren, muss sich die Content-Strategie von Traffic- auf Quellenoptimierung verlagern. Setzen Sie Update-Zyklen von 48–72 Stunden für Evergreen-Inhalte, um Retrieval-Systemen zu signalisieren, dass Ihre Informationen aktuell bleiben. Implementieren Sie strukturierte Daten-Markups (Schema.org, JSON-LD), damit Systeme den Inhalt und dessen Beziehungen verstehen können. Stimmen Sie Ihre Inhalte semantisch auf gängige Frage-Muster ab—verwenden Sie natürliche Sprache, wie Menschen Fragen stellen, nicht nur, wie sie suchen. Formatieren Sie Inhalte mit FAQ- und Q&A-Abschnitten, da diese direkt dem Frage-Antwort-Muster von RAG-Systemen entsprechen. Entwickeln oder pflegen Sie Wikipedia- und Wissensgraph-Einträge, da sie die primären Retrieval-Quellen für die meisten Plattformen sind. Bauen Sie Backlink-Autorität durch gezielte Partnerschaften und Zitate anderer autoritativer Quellen auf, denn Link-Profile bleiben starke Autoritätssignale. Und halten Sie schließlich Konsistenz über alle Plattformen—stellen Sie sicher, dass Ihre Kernaussagen, Daten und Botschaften auf Website, Social Profiles, Branchendatenbanken und Wissensgraphen übereinstimmen, um verstärkte Zuverlässigkeitssignale zu erzeugen.
Die Zukunft von RAG und Zitaten
RAG-Technologie entwickelt sich rasant weiter und bringt einige Trends hervor, die das Zitierverhalten verändern. Noch ausgefeiltere Retrieval-Algorithmen gehen über semantische Ähnlichkeit hinaus und erfassen tiefergehende Anfragen und Kontexte, wodurch die Zitierrelevanz steigt. Spezialisierte Wissensdatenbanken werden für einzelne Bereiche entstehen—medizinspezifische RAG-Systeme nutzen kuratierte medizinische Literatur, Rechtssysteme greifen auf Rechtsprechung und Gesetze zurück—und eröffnen neuen Zitierquellen für autoritative Domains. Integration in Multi-Agenten-Systeme ermöglicht es RAG, mehrere spezialisierte Retriever zu koordinieren und Erkenntnisse aus verschiedenen Wissensquellen für umfassendere Antworten zu kombinieren. Echtzeit-Datenzugriff verbessert sich deutlich, sodass RAG-Systeme Live-Informationen aus APIs, Datenbanken und Streaming-Quellen einbinden können. Agentic RAG—bei dem KI-Agenten eigenständig entscheiden, was abgerufen, wie es verarbeitet und wann iteriert wird—wird dynamischere Zitiermuster ermöglichen und Quellen möglicherweise mehrfach zitieren, wenn Agenten ihre Argumentation weiterentwickeln.
Die Rolle von AmICited beim Monitoring von RAG-Zitaten
Während RAG bestimmt, wie KI-Systeme Quellen finden und zitieren, wird das Verständnis der eigenen Zitierleistung essenziell. AmICited überwacht KI-Zitate plattformübergreifend und verfolgt, welche Ihrer Quellen in ChatGPT, Google AI Overviews, Perplexity und aufkommenden KI-Systemen erscheinen. Sie sehen welche spezifischen Quellen zitiert werden, wie oft sie erscheinen und in welchem Kontext—so erkennen Sie, welche Inhalte bei RAG-Retrieval-Algorithmen Anklang finden. Unsere Plattform hilft Ihnen, Zitiermuster im gesamten Content-Portfolio zu verstehen und herauszufinden, was einzelne Beiträge zitierwürdig und andere unsichtbar macht. Messen Sie die Sichtbarkeit Ihrer Marke in KI-Antworten mit Kennzahlen, die im RAG-Zeitalter zählen—über klassische Traffic-Analysen hinaus. Führen Sie eine Wettbewerbsanalyse Ihrer Zitierleistung durch und sehen Sie, wie Ihre Quellen im Vergleich zu Mitbewerbern in KI-generierten Antworten abschneiden. In einer Welt, in der KI-Zitate Sichtbarkeit und Autorität bestimmen, ist der klare Einblick in die eigene Zitierleistung keine Option, sondern der Schlüssel zur Wettbewerbsfähigkeit.
Häufig gestellte Fragen
Was ist der Unterschied zwischen RAG und traditionellen LLMs?
Traditionelle LLMs basieren auf statischen Trainingsdaten mit Wissensgrenzen und können nicht auf Echtzeitinformationen zugreifen, was häufig zu Halluzinationen und nicht überprüfbaren Behauptungen führt. RAG-Systeme rufen Informationen aus externen indizierten Quellen ab, bevor sie Antworten generieren, und ermöglichen so genaue Zitate und fundierte Antworten auf Grundlage aktueller, überprüfbarer Daten.
Wie verbessert RAG die Genauigkeit von Zitaten?
RAG verfolgt jedes abgerufene Informationsstück bis zur ursprünglichen Quelle zurück, sodass Zitate automatisch und überprüfbar und nicht halluziniert sind. Dadurch entsteht eine direkte Verbindung zwischen Antwort und Quellmaterial, sodass Nutzer Behauptungen eigenständig überprüfen und die Glaubwürdigkeit der Quelle einschätzen können.
Welche Faktoren bestimmen, welche Quellen in RAG-Systemen zitiert werden?
RAG-Systeme bewerten Quellen anhand von Autorität (Domain-Reputation und Backlinks), Aktualität (Inhalte, die innerhalb von 48-72 Stunden aktualisiert wurden), semantischer Relevanz zur Anfrage, Inhaltsstruktur und -klarheit, faktischer Dichte mit spezifischen Datenpunkten sowie Präsenz in Wissensgraphen wie Wikipedia. Diese Faktoren wirken zusammen und bestimmen die Zitierwahrscheinlichkeit.
Wie kann ich meine Inhalte für RAG-Zitate optimieren?
Aktualisieren Sie Inhalte alle 48-72 Stunden, um Aktualitätssignale aufrechtzuerhalten, implementieren Sie strukturierte Daten-Markups (Schema.org), stimmen Sie Inhalte semantisch auf gängige Anfragen ab, verwenden Sie FAQ- und Q&A-Formate, entwickeln Sie eine Präsenz in Wikipedia und Wissensgraphen, bauen Sie Backlink-Autorität auf und sorgen Sie für Konsistenz auf allen Plattformen.
Warum ist die Präsenz in Wissensgraphen für KI-Zitate wichtig?
Wissensgraphen wie Wikipedia und Wikidata sind die primären Abrufquellen für die meisten RAG-Systeme. Die Präsenz in diesen strukturierten Datenbanken erhöht die Zitierwahrscheinlichkeit erheblich und schafft grundlegende Vertrauenssignale, auf die KI-Systeme bei unterschiedlichsten Anfragen immer wieder zurückgreifen.
Wie oft sollte ich Inhalte für RAG-Sichtbarkeit aktualisieren?
Inhalte sollten alle 48-72 Stunden aktualisiert werden, um starke Aktualitätssignale in RAG-Systemen aufrechtzuerhalten. Es sind keine vollständigen Neufassungen erforderlich – das Hinzufügen neuer Datenpunkte, das Aktualisieren von Statistiken oder das Erweitern von Abschnitten mit aktuellen Entwicklungen reicht aus, um die Zitierfähigkeit zu erhalten.
Welche Rolle spielt die Domain-Autorität bei RAG-Zitaten?
Die Domain-Autorität fungiert als Zuverlässigkeitsindikator in RAG-Algorithmen und macht etwa 5 % der Zitierwahrscheinlichkeit aus. Bewertet wird sie anhand des Domainalters, SSL-Zertifikaten, Backlink-Profilen, Expertenzuordnung und der Präsenz in Wissensgraphen, die alle zusammen die Quellenauswahl beeinflussen.
Wie hilft AmICited beim Monitoring von RAG-Zitaten?
AmICited verfolgt, welche Ihrer Quellen in KI-generierten Antworten auf ChatGPT, Google AI Overviews, Perplexity und anderen Plattformen erscheinen. Sie sehen Zitierhäufigkeit, Kontext und Wettbewerbsleistung und verstehen so, was Inhalte im RAG-Zeitalter zitierwürdig macht.
Überwachen Sie die KI-Zitate Ihrer Marke
Verstehen Sie, wie Ihre Marke in KI-generierten Antworten auf ChatGPT, Perplexity, Google AI Overviews und weiteren Plattformen erscheint. Verfolgen Sie Zitiermuster, messen Sie die Sichtbarkeit und optimieren Sie Ihre Präsenz in der KI-gesteuerten Suchlandschaft.
Wie Retrieval-Augmented Generation funktioniert: Architektur und Prozess
Erfahren Sie, wie RAG LLMs mit externen Datenquellen kombiniert, um präzise KI-Antworten zu generieren. Verstehen Sie den fünfstufigen Prozess, die Komponenten ...
Was ist RAG in der KI-Suche: Vollständiger Leitfaden zur Retrieval-Augmented Generation
Erfahren Sie, was RAG (Retrieval-Augmented Generation) in der KI-Suche ist. Entdecken Sie, wie RAG die Genauigkeit verbessert, Halluzinationen reduziert und Cha...
Wie gehen RAG-Systeme mit veralteten Informationen um?
Erfahren Sie, wie Retrieval-Augmented Generation Systeme die Aktualität ihrer Wissensbasis sicherstellen, veraltete Daten verhindern und durch Indexierungsstrat...
9 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.