
Differenzieller Crawler-Zugang
Erfahren Sie, wie Sie KI-Crawler selektiv je nach Geschäftszielen zulassen oder blockieren. Implementieren Sie differenziellen Crawler-Zugang, um Inhalte zu sch...
8 Min. Lesezeit

Erfahren Sie, wie Sie mit robots.txt steuern, welche KI-Bots auf Ihre Inhalte zugreifen. Vollständiger Leitfaden zum Blockieren von GPTBot, ClaudeBot und anderen KI-Crawlern mit praktischen Beispielen und Konfigurationsstrategien.
Die Landschaft des Web-Crawlings hat sich in den letzten zwei Jahren grundlegend verändert: Sie geht über die bekannte Suchmaschinen-Indexierung hinaus und reicht in die komplexe Welt des KI-Modelltrainings. Während Googles Googlebot lange als vorhersehbarer Besucher auf Publisher-Seiten galt, trifft nun eine neue Generation von Crawlern mit völlig anderen Absichten und Nutzungsverhalten ein. OpenAIs GPTBot zeigt ein Crawl-to-Refer-Verhältnis von etwa 1.700:1 – er crawlt 1.700 Seiten, um nur eine Weiterleitung zu Ihrer Seite zu erzeugen, während Anthropics ClaudeBot sogar mit einem Verhältnis von 73.000:1 operiert. Zum Vergleich: Bei Google liegt das Verhältnis bei 14:1, wobei Crawling-Aktivität zu signifikantem Traffic führt. Dieser fundamentale Unterschied zwingt Content Creator zu einer unternehmerischen Entscheidung: Wer diesen Bots ungehinderten Zugriff gewährt, liefert Trainingsdaten für KI-Modelle, die mit dem eigenen Traffic und Umsatz konkurrieren, erhält aber kaum Kompensation oder Traffic zurück. Publisher müssen nun aktiv abwägen, ob das Wertversprechen von KI-Bot-Zugriff zum eigenen Geschäftsmodell passt – die robots.txt-Konfiguration wird so von einer rein technischen zu einer strategischen Geschäftsentscheidung.
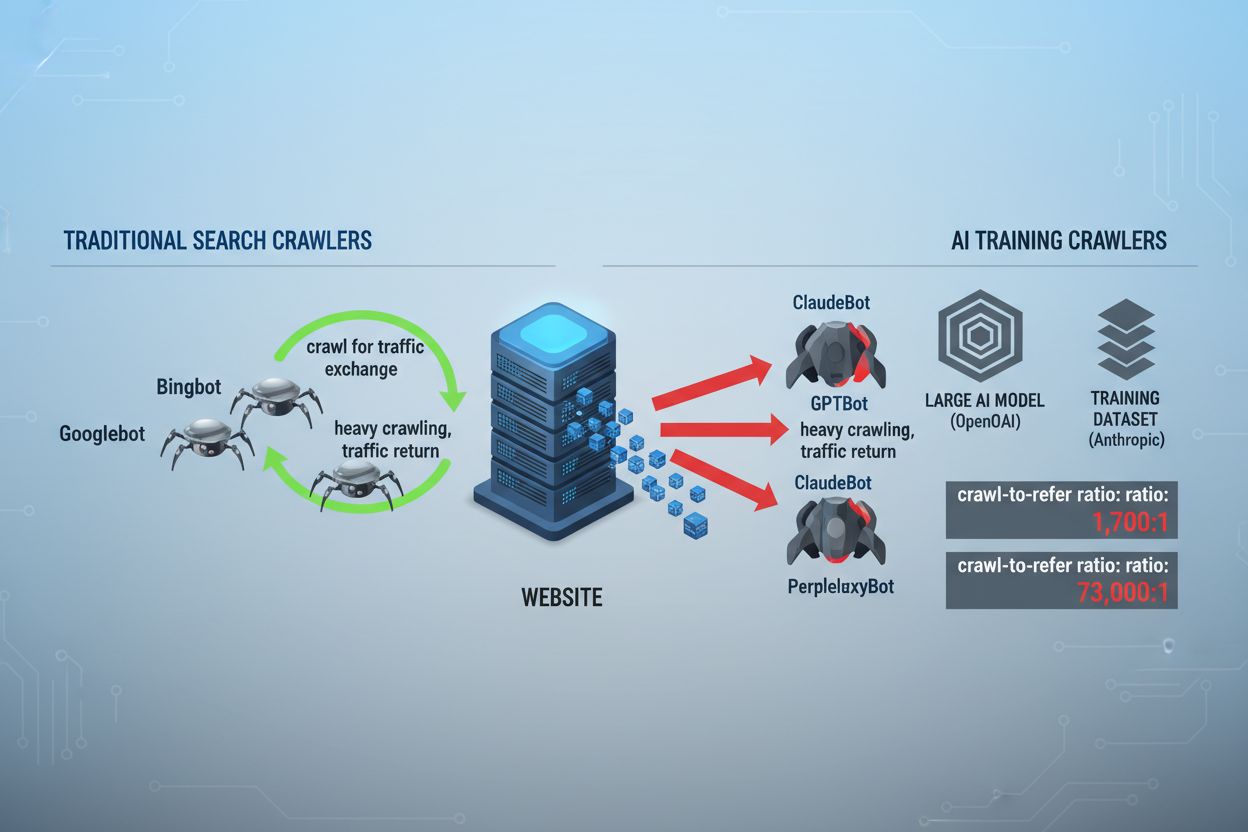
KI-Crawler operieren in drei unterschiedlichen Kategorien, die jeweils andere Zwecke erfüllen und unterschiedliche Blockierungsstrategien benötigen. Trainings-Crawler sind darauf ausgelegt, große Mengen an Inhalten aufzunehmen, um KI-Grundmodelle zu trainieren – dazu gehören OpenAIs GPTBot, Anthropics ClaudeBot, Googles Google-Extended, Perplexitys PerplexityBot, Metas Meta-ExternalAgent, Apples Applebot-Extended sowie neue Player wie Amazonbot, Bytespider und cohere-ai. Such-Crawler hingegen dienen KI-gestützten Suchfunktionen und liefern dem Publisher in der Regel Traffic zurück, etwa OpenAIs OAI-SearchBot, Anthropics Claude-Web und die Suchfunktionalität von Perplexity. Nutzergetriggerte Agenten bilden eine dritte Kategorie, bei der Inhalte bedarfsabhängig abgerufen werden, wenn ein Nutzer explizit Informationen anfordert – z. B. durch ChatGPT-User oder direkt von Endnutzern initiierte Claude-Web-Interaktionen. Diese Taxonomie zu kennen, ist entscheidend, denn Ihre Blockierungsstrategie sollte Ihre Geschäftsziele widerspiegeln: Sie möchten vielleicht Such-Crawler zulassen, die Traffic bringen, aber Trainings-Crawler blockieren, die Inhalte ohne Gegenleistung konsumieren. Jedes große KI-Unternehmen betreibt eigene, spezialisierte Crawler-Flotten, deren Unterscheidung meist über den jeweiligen User-Agent-String läuft – deshalb sind genaue Identifikation und gezieltes Blockieren für eine wirksame robots.txt-Konfiguration unerlässlich.
| Unternehmen | Trainings-Crawler | Such-Crawler | Nutzergetriggerter Agent |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Verwendet Standard-Googlebot) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Um Ihre robots.txt effektiv zu konfigurieren, benötigen Sie eine aktuelle, vollständige Liste der User-Agents von KI-Bots – doch dieses Feld entwickelt sich rasant, da ständig neue Modelle und Crawler-Strategien entstehen. Die wichtigsten Trainings-Crawler sind: GPTBot (OpenAIs Haupt-Trainings-Crawler), ClaudeBot (Anthropics Trainings-Crawler), anthropic-ai (Anthropics alternative Kennung), Google-Extended (Googles KI-Trainings-Token), PerplexityBot (Perplexitys Crawler), Meta-ExternalAgent (Metas Trainings-Crawler), Applebot-Extended (Apples KI-Trainingsvariante), CCBot (Common Crawl), Amazonbot (Amazon), Bytespider (ByteDance), cohere-ai (Cohere), DuckAssistBot (DuckDuckGo) und YouBot (You.com). Such-Crawler, die typischerweise Traffic zurückführen, sind z. B. OAI-SearchBot, Claude-Web und PerplexityBot (im Suchmodus). Die Herausforderung: Diese Liste bleibt nie statisch – ständig tauchen neue KI-Unternehmen auf, bestehende launchen neue Crawler für neue Produkte, und User-Agent-Strings ändern oder erweitern sich. Behandeln Sie Ihre robots.txt daher als lebendiges Dokument, das Sie mindestens vierteljährlich überprüfen und aktualisieren sollten – abonnieren Sie ggf. Branchenressourcen und überwachen Sie Ihre Server-Logs auf unbekannte User-Agents, die auf neue KI-Crawler hindeuten könnten. Wer seine User-Agent-Liste nicht aktuell hält, riskiert, entweder ungewollt neue Trainings-Crawler zuzulassen – oder berechtigte Such-Crawler unnötig zu blockieren.
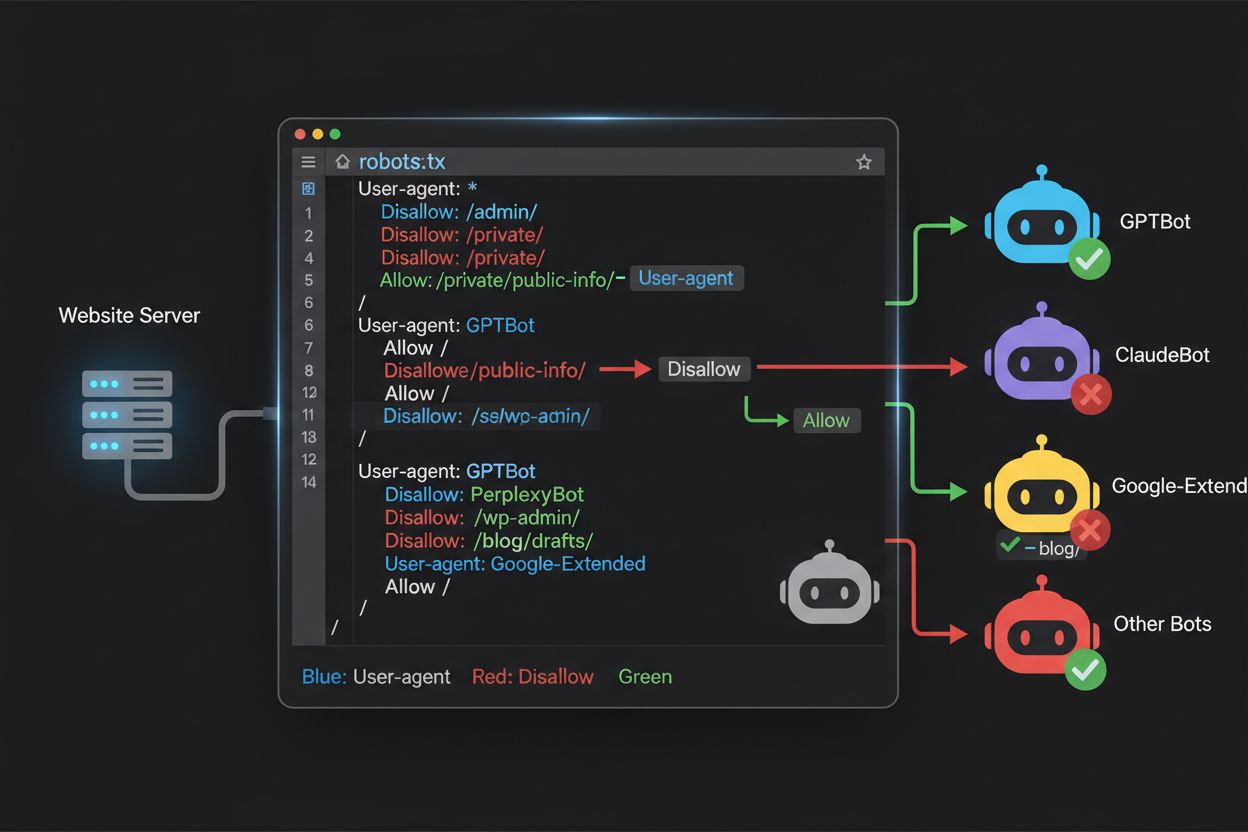
Die robots.txt-Datei liegt im Stammverzeichnis Ihrer Domain (yourdomain.com/robots.txt) und verwendet eine simple Syntax, um Bots, die das Protokoll respektieren, Crawling-Präferenzen mitzuteilen. Jede Regel beginnt mit einer User-Agent-Direktive, auf die mindestens eine Disallow-Direktive folgt, die angibt, welche Pfade der Bot nicht aufrufen darf. Um alle wichtigen KI-Trainings-Crawler zu blockieren, während traditionelle Suchmaschinen zugelassen bleiben, erstellen Sie für jeden Trainings-Crawler einen eigenen User-Agent-Block mit „Disallow: /“ (sperrt alle Inhalte). Gleichzeitig stellen Sie sicher, dass Suchmaschinen wie Googlebot, Bingbot und suchorientierte Variationen wie OAI-SearchBot weiterhin Zugriff haben. Eine korrekt konfigurierte robots.txt sollte außerdem einen Verweis auf Ihre XML-Sitemap enthalten, damit Suchmaschinen Ihre Inhalte effizient finden. Die richtige Konfiguration ist entscheidend – ein einziger Syntaxfehler, ein falscher User-Agent-String oder ein fehlerhaft platzierter Buchstabe können Ihre ganze Strategie wirkungslos machen. Testen Sie Ihre Konfiguration daher immer vor dem Livegang.
# KI-Trainings-Crawler blockieren
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Klassische Suchmaschinen zulassen
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Sitemap-Verweis
Sitemap: https://yoursite.com/sitemap.xml
Viele Publisher stehen vor einer schwierigen Entscheidung: Sie möchten in KI-gestützten Suchergebnissen sichtbar bleiben und Referral-Traffic erhalten, aber verhindern, dass ihre Inhalte als Trainingsdaten für konkurrierende KI-Modelle genutzt werden. Diese selektive Strategie erfordert die Unterscheidung zwischen Such- und Trainings-Crawlern derselben Firma – z. B. OAI-SearchBot (für Suchfunktionen und Traffic) erlauben, aber GPTBot (für Modelltraining) blockieren. Ebenso können Sie PerplexityBots Suchcrawler erlauben, aber den Trainingsmodus sperren, oder Claude-Web für nutzergetriebene Suchen zulassen, während ClaudeBots Trainingsaktivitäten blockiert werden. Der geschäftliche Grund ist klar: Suchcrawler arbeiten meist mit einem deutlich besseren Crawl-to-Refer-Verhältnis, da sie Traffic zurückbringen; Trainingscrawler konsumieren Inhalte dagegen in großem Umfang ohne spürbaren Gegenwert. Diese Strategie verlangt eine sorgfältige Konfiguration und laufende Überwachung, da Firmen ihre Crawler-Strategien oder User-Agents gelegentlich ändern. Prüfen Sie regelmäßig Ihre Server-Logs, ob die gewünschten Crawler Zugriff haben und blockierte tatsächlich ausgeschlossen werden, und passen Sie die robots.txt an die Entwicklung des KI-Markts an.
# KI-Suchcrawler erlauben
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Trainingscrawler blockieren
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Selbst erfahrene Webmaster machen oft Fehler, die ihre robots.txt-Strategie wirkungslos machen und ihre Inhalte für genau jene Crawler öffnen, die sie blockieren wollten. Häufiger Fehler 1: Einzelne User-Agent-Zeilen ohne nachfolgende Disallow-Direktive – zum Beispiel „User-Agent: GPTBot“ schreiben und dann mit einer neuen Regel beginnen, ohne anzugeben, was GPTBot nicht darf; dadurch bleibt der Bot komplett ungesperrt. Fehler 2: Falscher Speicherort, Dateiname oder Groß-/Kleinschreibung; die Datei muss exakt „robots.txt“ heißen (klein geschrieben), im Stammverzeichnis der Domain liegen und mit HTTP-Statuscode 200 ausgeliefert werden – liegt sie im Unterverzeichnis oder heißt „Robots.txt“ oder „robots.TXT“, bleibt sie für Crawler unsichtbar. Fehler 3: Leere Zeilen innerhalb eines Regelblocks, die von vielen robots.txt-Parsern als Blockende interpretiert werden, wodurch nachfolgende Direktiven ignoriert oder falsch zugeordnet werden. Fehler 4: Groß-/Kleinschreibung in Pfaden – User-Agent-Namen sind nicht case-sensitive, aber die Pfade in Disallow-Direktiven schon: „Disallow: /Admin“ blockiert nicht „/admin“ oder „/ADMIN“. Fehler 5: Falsche Wildcard-Nutzung – das Sternchen (*) steht für eine beliebige Zeichenfolge, wird aber oft falsch eingesetzt, z. B. „Disallow: .pdf“ statt „Disallow: /.pdf“ oder „Disallow: /*pdf“, um Dateiendungen zu blockieren. Zudem bauen manche Publisher zu komplexe Regelwerke mit widersprüchlichen Disallow-Direktiven oder berücksichtigen keine URL-Parameter, wodurch legitime Inhalte blockiert oder unerwünschte erreichbar bleiben. Nutzen Sie immer einen robots.txt-Validator vor dem Livegang, um Fehler zu entdecken.
Häufige Fehler, die Sie vermeiden sollten:
Google-Extended ist ein Sonderfall in der robots.txt-Konfiguration, denn es handelt sich nicht um einen klassischen Crawler, sondern um ein Steuerungs-Token. Im Gegensatz zu Googlebot, der Ihre Seite für Google Search indexiert, signalisiert Google-Extended, ob Ihre Inhalte zum Training von Googles Gemini-KI-Modellen und für AI Overviews in Suchergebnissen genutzt werden dürfen. Wer Google-Extended blockiert, verhindert, dass Inhalte für Gemini-Training und AI Overviews genutzt werden – das hat aber keinen Einfluss auf die Sichtbarkeit in der klassischen Google-Suche, denn Googlebot indexiert weiterhin normal. Die Entscheidung hat großen Einfluss: Blockieren Sie Google-Extended, erscheinen Ihre Inhalte nicht in AI Overviews (die in Google Search immer prominenter werden), bleiben aber vor der Verwendung als Trainingsdaten geschützt. Erlauben Sie Google-Extended, können Ihre Inhalte in AI Overviews auftauchen (was Traffic bringen kann), tragen aber auch zum Gemini-Training bei. Publisher sollten genau abwägen: Nachrichtenportale und Content-Creator, deren Geschäftsmodell auf direktem Traffic basiert, profitieren womöglich vom Blockieren, während andere die Sichtbarkeit in AI Overviews begrüßen. Diese Entscheidung sollte bewusst und nicht aus Gewohnheit getroffen werden, da sie langfristige Auswirkungen auf Sichtbarkeit und Traffic in Googles Suchökosystem hat.
Das Testen Ihrer robots.txt-Konfiguration ist unerlässlich, da Fehler sowohl Ihre Sichtbarkeit in Suchmaschinen als auch Ihre Content-Schutzstrategie massiv beeinflussen können. Die Google Search Console bietet einen eingebauten robots.txt-Tester, mit dem Sie prüfen können, ob bestimmte User-Agents auf bestimmte URLs zugreifen dürfen – geben Sie z. B. „GPTBot“ und einen Pfad ein, und Google zeigt, ob der Bot laut aktueller Konfiguration Zugriff hätte. Der Merkle Robots.txt Tester bietet ähnliche Funktionen mit benutzerfreundlicher Oberfläche und ausführlichen Erklärungen. TechnicalSEO.com stellt ein weiteres Tool zur Verfügung, das Ihre Syntax validiert und zeigt, wie verschiedene Bots behandelt werden. Für umfassenderes Monitoring gibt es Knowatoa AI Search Console mit speziellen Tools zur Überwachung von KI-Crawlern und Validierung Ihrer Regeln gegen die zu blockierenden Bots. Ihr Validierungs-Workflow sollte das Hochladen der robots.txt in eine Staging-Umgebung umfassen, um zu prüfen, dass wichtige Seiten weiterhin zugänglich sind, geblockte KI-Bots tatsächlich ausgeschlossen werden und die Sitemap korrekt referenziert ist. Erst nach erfolgreichem Test sollten Sie die Datei live schalten – und die ersten Tage weiter die Logs überwachen, um unvorhergesehene Probleme zu erkennen.
Test-Tools:
Robots.txt ist nur eine erste Verteidigungslinie, denn sie funktioniert nach dem Ehrenkodex: Bots, die das Protokoll respektieren, befolgen Ihre Regeln – bösartige oder schlecht programmierte Crawler ignorieren robots.txt jedoch und greifen dennoch auf Ihre Inhalte zu. Branchendaten zeigen, dass robots.txt etwa 40–60 % des unerwünschten Crawler-Traffics aufhält – der Rest ignoriert das Protokoll oder umgeht es gezielt. Wer stärkeren Schutz braucht, benötigt zusätzliche Ebenen: Die Web Application Firewall (WAF) von Cloudflare ermöglicht Regeln, die Traffic nach User-Agent, IP-Adresse oder Verhalten blockieren und so auch bots abwehren, die robots.txt ignorieren. Serverseitige Tools wie .htaccess (Apache) oder entsprechende Nginx-Konfiguration blockieren User-Agents oder IP-Ranges, bevor sie überhaupt zur Anwendung durchdringen. IP-Blocking ist effektiv, wenn Sie die IP-Ranges eines Crawlers kennen, erfordert aber laufende Pflege. Tools wie Fail2ban blockieren IPs automatisch, die sich verdächtig verhalten (z. B. übermenschliches Request-Tempo). Vorsicht bei zu aggressiver Blockierung: Sie könnten legitimen Traffic ausschließen, etwa von echten Nutzern, die über VPNs oder Proxy-IPs surfen. Die beste Strategie kombiniert robots.txt als höfliche Bitte, User-Agent-Blocking auf Serverebene für Bots, die robots.txt ignorieren, und Verhaltens-Monitoring für fortschrittliche Crawler mit gefälschten User-Agents oder verteilten IPs. Führen Sie diese Ebenen schrittweise ein und testen Sie jeweils, um keine echten Nutzer unbeabsichtigt auszuschließen.
Zu wissen, was tatsächlich auf Ihre Seite zugreift, ist entscheidend, um zu prüfen, ob Ihre robots.txt wie gewünscht funktioniert und um neue Crawler zu erkennen, die ggf. blockiert werden müssen. Die Server-Log-Analyse ist hierfür das wichtigste Werkzeug: Ihre Webserver-Logs (Apache, Nginx etc.) enthalten alle Requests inklusive User-Agent, IP-Adresse, Zeitstempel und angeforderter Ressource. Mit Tools wie grep können Sie gezielt nach User-Agents suchen: „grep ‘GPTBot’ /var/log/apache2/access.log“ zeigt alle Zugriffe von GPTBot – so prüfen Sie, ob Ihre Blockierung greift. Fortgeschrittene Analysen erlauben es, Crawlrate, aufgerufene Seiten und Respektierung der robots.txt zu untersuchen. Automatisches Monitoring kann Sie benachrichtigen, wenn neue oder unerwartete Crawler auftauchen – besonders wertvoll, da sich die KI-Crawler-Landschaft rasch wandelt. Viele Publisher nutzen Log-Aggregation (z. B. ELK Stack, Splunk oder Cloud-Lösungen) für zentrale Analyse über mehrere Server. Monitoring ist kein einmaliges Projekt, sondern eine dauerhafte Aufgabe – neue Bots und User-Agent-Strings erscheinen regelmäßig, Crawler-Verhalten ändert sich. Ein regelmäßiger Überwachungsrhythmus (wöchentlich oder monatlich) hilft, auf Veränderungen zu reagieren und Ihre robots.txt stets aktuell zu halten.
Ihre robots.txt-Konfiguration für KI-Crawler ist letztlich eine Umsatz-Entscheidung und verdient die gleiche strategische Beachtung wie jede andere geschäftskritische Maßnahme. Wer Trainings-Crawlern ungehinderten Zugang gewährt, gibt KI-Modellen Trainingsdaten, die irgendwann mit dem eigenen Traffic und Umsatz konkurrieren – für Geschäftsmodelle, die auf direktem Traffic, Suchsichtbarkeit oder Werbung beruhen, liefern Sie damit kostenlos Trainingsdaten für konkurrierende Produkte. Wer hingegen alle KI-Crawler blockiert, verliert Sichtbarkeit und Referral-Traffic aus KI-Suchergebnissen und von KI-Assistenten – ein Bereich, der immer wichtiger wird. Die optimale Strategie hängt vom Geschäftsmodell ab: Anzeigenfinanzierte Publisher profitieren womöglich, wenn sie Suchcrawler zulassen (die Traffic und Anzeigenimpressionen bringen), aber Trainingscrawler blockieren. Publisher mit Paywall setzen oft auf striktes Blockieren, um Inhalte vor Zusammenfassungen oder Nachbildungen durch KI zu schützen. Wer auf Markenbekanntheit und Thought Leadership setzt, begrüßt vielleicht Sichtbarkeit in KI-Suchen. Entscheidend ist: Treffen Sie die Entscheidung bewusst – viele Publisher haben robots.txt nie für KI-Bots konfiguriert und erlauben so alle Bots standardmäßig, ohne dies aktiv zu wollen. Zusätzlich empfiehlt sich die Nutzung von Schema-Markup für korrekte Attribution, wenn Inhalte von KI-Systemen verwendet werden, damit Traffic und Anerkennung auch bei KI-Referenzen zu Ihrer Seite zurückfließen. Ihre robots.txt-Konfiguration sollte Ihre bewusste Geschäftsstrategie abbilden und regelmäßig überprüft und angepasst werden, wenn sich die KI-Landschaft oder Ihre eigenen Prioritäten ändern.
Die KI-Crawler-Landschaft entwickelt sich rasant: Neue Unternehmen launchen KI-Produkte, bestehende Firmen bringen neue Crawler, User-Agent-Strings ändern oder erweitern sich regelmäßig. Ihre robots.txt sollte daher kein statisches, sondern ein lebendiges Dokument sein, das Sie mindestens vierteljährlich überprüfen und aktualisieren. Etablieren Sie einen Prozess, um Branchennews zu neuen KI-Crawlern zu verfolgen, abonnieren Sie relevante Newsletter oder Blogs, und auditieren Sie regelmäßig Ihre Server-Logs auf unbekannte User-Agents. Finden Sie neue Crawler, recherchieren Sie deren Zweck und Geschäftsmodell und entscheiden Sie, ob sie zu Ihrer Content-Schutzstrategie passen – dann aktualisieren Sie Ihre robots.txt entsprechend. Überwachen Sie zudem die Effektivität Ihrer Regeln, z. B. anhand von Crawler-Traffic, Verhältnis von Crawler-Requests zu Nutzerzugriffen und Veränderungen Ihrer organischen Sichtbarkeit oder Referral-Traffic aus KI-Suchergebnissen. Viele Publisher stellen nach Monaten im Realbetrieb fest, dass ihre Strategie angepasst werden muss – etwa, weil das Blockieren eines bestimmten Crawlers ungewollte Folgen hatte oder das Zulassen eines Bots wertvolleren Traffic bringt als erwartet. Seien Sie bereit, Ihre Strategie auf Basis realer Daten zu iterieren. Kommunizieren Sie Ihre robots.txt-Strategie auch an relevante Unternehmensbereiche – SEO, Content, Geschäftsführung – damit Entscheidungen konsistent und bewusst getroffen werden. So bleibt Ihr Content-Schutz wirksam und Ihre Geschäftsziele im KI-Zeitalter gewahrt.
Nein. Das Blockieren von KI-Trainings-Crawlern wie GPTBot, ClaudeBot und CCBot beeinflusst Ihr Google- oder Bing-Ranking nicht. Klassische Suchmaschinen nutzen andere Crawler (Googlebot, Bingbot), die unabhängig agieren. Blockieren Sie diese nur, wenn Sie komplett aus den Suchergebnissen verschwinden möchten.
Große Crawler von OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) und Perplexity (PerplexityBot) geben offiziell an, robots.txt-Direktiven zu respektieren. Kleinere oder weniger transparente Bots können Ihre Konfiguration jedoch ignorieren – darum gibt es gestufte Schutzstrategien.
Das hängt von Ihrer Strategie ab. Wenn Sie nur Trainings-Crawler (GPTBot, ClaudeBot, CCBot) blockieren, schützen Sie Ihre Inhalte vor Modelltraining, ermöglichen aber weiterhin Such-Crawlern, Sie in KI-Suchergebnissen anzuzeigen. Bei kompletter Blockierung verschwinden Sie vollständig aus KI-Ökosystemen.
Überprüfen Sie Ihre Konfiguration mindestens vierteljährlich. KI-Unternehmen führen regelmäßig neue Crawler ein. Anthropic fusionierte zum Beispiel ihre 'anthropic-ai'- und 'Claude-Web'-Bots zu 'ClaudeBot' und gab diesem neuen Bot vorübergehend unbegrenzten Zugang zu Websites, die ihre Regeln nicht aktualisiert hatten.
Robots.txt ist eine Datei im Stammverzeichnis Ihrer Domain und gilt für alle Seiten, während Meta-Robots-Tags HTML-Direktiven auf einzelnen Seiten sind. Robots.txt wird zuerst geprüft und kann Crawler komplett vom Zugriff ausschließen, während Meta-Tags erst gelesen werden, wenn die Seite aufgerufen wird. Nutzen Sie beides für umfassende Kontrolle.
Ja. Sie können in robots.txt pfadspezifische Disallow-Regeln verwenden (z. B. 'Disallow: /premium/' für Premium-Inhalte) oder Meta-Robots-Tags auf einzelnen Seiten nutzen. So schützen Sie sensible Bereiche und erlauben Crawlern den Zugriff auf andere Bereiche.
Wenn ein Bot robots.txt ignoriert, brauchen Sie zusätzliche Schutzmaßnahmen wie Server-Blocking (.htaccess), IP-Blocking oder WAF-Regeln. Robots.txt stoppt etwa 40–60 % unerwünschter Crawler – gestufter Schutz ist für umfassende Abwehr wichtig.
Nutzen Sie Test-Tools wie den robots.txt-Tester der Google Search Console, den Merkle Robots.txt Tester oder TechnicalSEO.com, um Ihre Konfiguration zu validieren. Überwachen Sie Ihre Server-Logs auf Crawler-Aktivitäten, um zu prüfen, ob geblockte Bots ausgeschlossen und erlaubte Bots auf Ihre Inhalte zugreifen.
Robots.txt ist nur der erste Schritt. Nutzen Sie AmICited, um zu verfolgen, welche KI-Systeme Ihre Inhalte zitieren, wie oft Sie referenziert werden, und für korrekte Attribution über GPTs, Perplexity, Google AI Overviews und mehr zu sorgen.
Erfahren Sie, wie Sie KI-Crawler selektiv je nach Geschäftszielen zulassen oder blockieren. Implementieren Sie differenziellen Crawler-Zugang, um Inhalte zu sch...

Erfahren Sie, wie Web Application Firewalls fortschrittliche Kontrolle über KI-Crawler bieten – weit über robots.txt hinaus. Implementieren Sie WAF-Regeln, um I...

Erfahren Sie, wie KI-Suchcrawler die Crawlhäufigkeit für Ihre Website bestimmen. Entdecken Sie, wie ChatGPT, Perplexity und andere KI-Engines Inhalte anders cra...