
Was sind Rich Results und helfen sie der KI?
Erfahren Sie, wie Rich Results und strukturierte Daten die KI-Suchmaschinen, LLMs und die Sichtbarkeit von Inhalten in KI-gestützten Antworten von ChatGPT, Perp...
11 Min. Lesezeit

Erfahren Sie, welche Schema-Typen für die KI-Sichtbarkeit am wichtigsten sind. Entdecken Sie, wie LLMs strukturierte Daten interpretieren und setzen Sie Schema-Markup-Strategien um, die Ihre Marke in KI-Antworten zitieren lassen.
Jahrelang drehte sich Schema-Markup vor allem darum, Rich Results zu erzielen – jene auffälligen Sternebewertungen, Produktkarten und FAQ-Akkordeons, die in klassischen Suchergebnissen erschienen. Heute ist dieses Vorgehen zunehmend überholt. Große Sprachmodelle und KI-Antwortmaschinen interpretieren Schema-Markup grundlegend anders: Sie nutzen es nicht für kosmetische Aufwertungen, sondern zum Aufbau von Knowledge Graphs und zum Verständnis von Entitätenbeziehungen im großen Maßstab. Mit etwa 45 Millionen Websites (12,4 % aller registrierten Domains), die mittlerweile eine Form von schema.org-Markup implementieren, stehen KI-Systemen nie dagewesene Mengen strukturierter Daten zum Lernen und Referenzieren zur Verfügung. Der Wandel ist tiefgreifend: Schema-Markup beeinflusst heute, ob Ihre Marke in KI-generierten Antworten zitiert wird, wie genau Modelle Ihre Produkte und Dienstleistungen darstellen und ob Ihre Inhalte in einer AI-first-Suchlandschaft als vertrauenswürdige Quelle gelten.
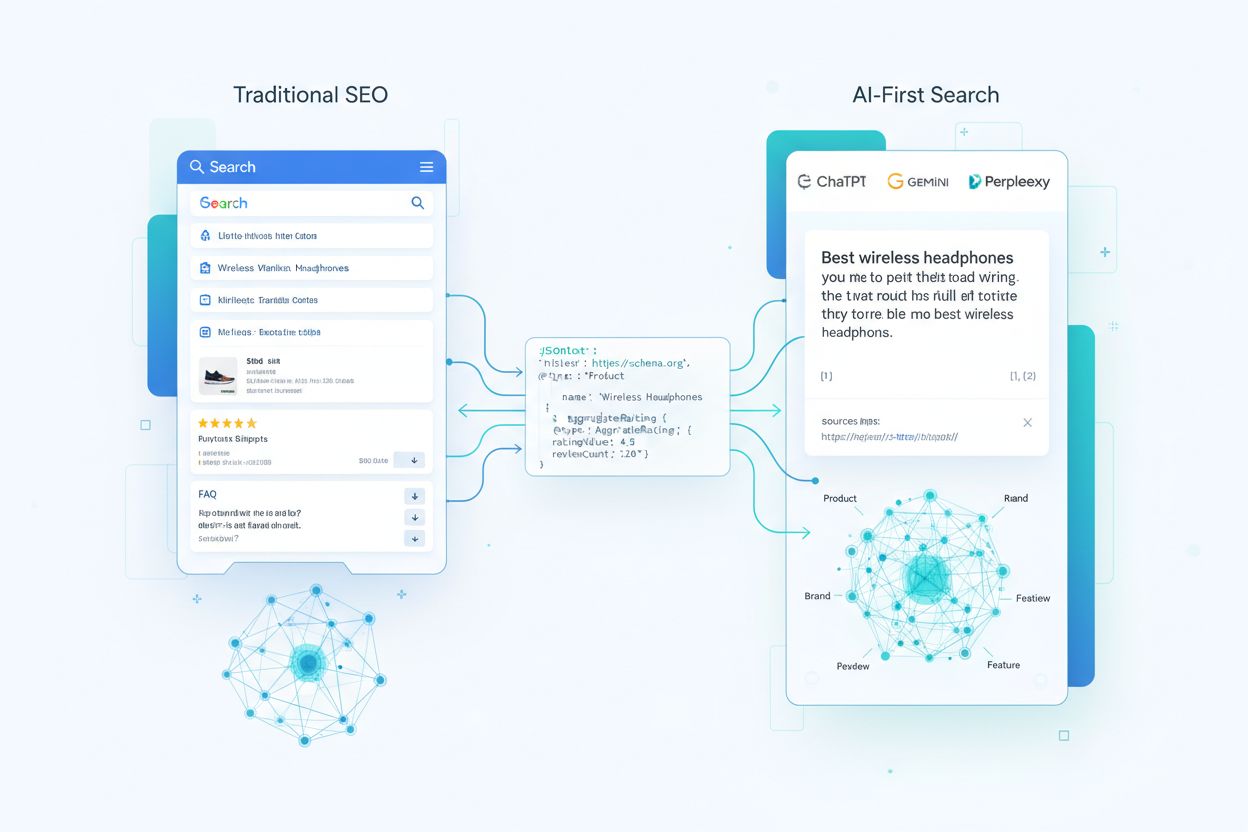
Um zu verstehen, wie KI-Systeme Schema-Markup nutzen, muss man den Weg Ihrer strukturierten Daten vom ersten Crawling bis zur LLM-generierten Antwort nachvollziehen. Wenn ein Crawler Ihre Seite besucht, extrahiert er JSON-LD-, Microdata- oder RDFa-Blöcke und normalisiert sie zusammen mit unstrukturiertem Text und Medien in einen Index. Diese strukturierten Daten werden Teil eines Web-weit reichenden Knowledge Graphs, in dem Entitäten über Beziehungen verbunden und für semantische Suche mit Embeddings versehen werden. In Retrieval-Augmented Generation (RAG)-Systemen kann Schema direkt in die Chunks integriert werden, die Vektorindizes befüllen – ein einzelner Chunk kann sowohl eine Produktbeschreibung als auch das zugehörige JSON-LD-Markup enthalten und bietet Modellen somit sowohl narrativen Kontext als auch strukturierte Schlüssel-Wert-Attribute. Verschiedene LLM-Architekturen nutzen Schema unterschiedlich: Manche legen Modelle auf bestehende Suchindizes und Knowledge Graphs, andere verwenden Multi-Source-Retrieval-Pipelines, die sowohl auf strukturierte als auch unstrukturierte Inhalte zugreifen. Die entscheidende Erkenntnis ist: Gut implementiertes Schema wirkt wie ein Vertrag mit dem Modell, der in hochstrukturierter Form festlegt, welche Fakten Ihrer Seite Sie als kanonisch und vertrauenswürdig betrachten.
| Architekturtyp | Schema-Nutzung | Zitationsauswirkung | Schlüsselfelder |
|---|---|---|---|
| Traditionelle Suche + LLM-Layer | Erweitert bestehenden Knowledge Graph | Hoch – Modelle zitieren gut strukturierte Quellen | Organization, Product, Article |
| Retrieval-Augmented Generation | In Vektor-Chunks integriert | Mittel-Hoch – Schema hilft bei Präzision | Alle Typen mit detaillierten Eigenschaften |
| Multi-Source-Antwortmaschinen | Für Entitätenauflösung verwendet | Mittel – konkurriert mit anderen Signalen | Person, LocalBusiness, Service |
| Konversationelle KI | Unterstützt Kontextverständnis | Variabel – abhängig von Trainingsdaten | FAQPage, HowTo, BlogPosting |
Nicht alle Schema-Typen sind im KI-Zeitalter gleich bedeutend. Organization-Markup bildet den Anker Ihres gesamten Entitäten-Netzwerks und hilft Modellen, Ihre Markenidentität, Autorität und Beziehungen zu verstehen. Product-Schema ist für E-Commerce und Einzelhandel essenziell, da es KI-Systemen ermöglicht, Merkmale, Preise und Bewertungen quellenübergreifend zu vergleichen. Article- und BlogPosting-Markup helfen Modellen, Longform-Inhalte für erklärende Suchanfragen und Thought Leadership zu identifizieren. Person-Schema ist entscheidend, um Autoren-Glaubwürdigkeit und Expertenzuschreibung in KI-generierten Antworten zu etablieren. FAQPage-Markup bildet direkt konversationsorientierte Suchanfragen ab, die KI-Assistenten beantworten sollen. Für SaaS- und B2B-Unternehmen sind SoftwareApplication- und Service-Typen ebenso wichtig, da sie häufig in „Beste Tools für X“-Vergleichen und Feature-Bewertungen auftauchen. Für lokale Unternehmen und Gesundheitsdienstleister sorgen LocalBusiness- und MedicalOrganization-Typen für geografische Präzision und regulatorische Klarheit. Die echte Differenzierung entsteht jedoch nicht durch die bloße Typenwahl, sondern durch die erweiterten Eigenschaften, die Sie darauf aufbauen – Konsistenz über Seiten hinweg, klare Entitäten-IDs und explizite Beziehungsabbildungen.
Grundlegende Schema-Eigenschaften wie name, description und URL sind mittlerweile Standard; 72,6 % der Seiten auf Googles erster Ergebnisseite nutzen bereits irgendeine Form von Schema-Markup. Die Eigenschaften, die wirkliche Differenzierung für die KI-Sichtbarkeit schaffen, sind jene „verbindenden Gewebe“, die Modellen helfen, Entitäten aufzulösen, Beziehungen zu verstehen und Bedeutungen zu entwirren. Hier sind die wichtigsten erweiterten Eigenschaften:
Diese Eigenschaften machen aus Schema ein semantisches Navigationssystem, das Modelle sicher nutzen können. Wenn Sie sameAs verwenden, um Ihre Organisation mit der Wikipedia-Seite zu verlinken, fügen Sie nicht nur Metadaten hinzu – Sie teilen dem Modell mit: „Dies ist die maßgebliche Quelle für Fakten über uns.“ Mit additionalProperty für Produktspezifikationen oder Service-Features liefern Sie genau die Attribute, nach denen KI-Systeme suchen, wenn sie Vergleiche oder Empfehlungen zusammenstellen.
Die meisten Unternehmen behandeln Schema-Markup als einmalige Implementierungsaufgabe, aber nachhaltiger Wettbewerbsvorteil in KI-getriebener Suche erfordert, es als laufende Data-Governance-Disziplin zu begreifen. Ein nützliches Modell ist ein vierstufiges Reifegradmodell, das Teams hilft, ihren Status quo zu erkennen und die nächsten Schritte zu planen:
Level 1 – Basis-Rich-Result-Schema konzentriert sich auf minimales Markup ausgewählter Templates, vor allem um Sterne, Produktkarten oder FAQ-Snippets zu erzielen. Governance ist locker, Konsistenz gering, Ziel ist die optische Aufwertung statt semantischer Klarheit.
Level 2 – Entitätenzentrierte Abdeckung standardisiert Organization-, Product-, Article- und Person-Markup über wichtige Templates hinweg, führt konsistent @id-Werte ein und ergänzt grundlegende sameAs-Links zur Vermeidung von Entitätenverwechslungen.
Level 3 – Knowledge-Graph-integriertes Schema richtet Schema-IDs an internen Datenmodellen (CMS, PIM, CRM) aus, nutzt about/mentions/additionalType-Eigenschaften umfangreich und kodiert seitenübergreifende Beziehungen, sodass Modelle verstehen, wie Content-Nodes miteinander und mit externen Entitäten verbunden sind.
Level 4 – LLM-optimiertes & RAG-abgestimmtes Schema strukturiert Markup gezielt für konversationsorientierte Suchanfragen und KI-Snippet-Formate, stimmt Schema auf interne RAG-Pipelines ab und verankert Messung sowie Iteration als Kernpraktiken.
Die meisten Marken stagnieren derzeit bei Level 1–2 – das heißt, die Grundimplementierung ist inzwischen Hygienefaktor, kein Differenzierungsmerkmal mehr. Der Schritt zu Level 3–4 macht Schema-LLM-Optimierung zum nachhaltigen Wettbewerbsvorteil, denn so können Modelle Ihre Entitäten zuverlässig über viele Anfragen und Oberflächen hinweg interpretieren.
Verschiedene Branchen haben unterschiedliche Entitäten, Risikoprofile und Nutzerintentionen, daher kann fortgeschrittene Schema-Nutzung kein Einheitsansatz sein. Die Grundprinzipien – Entitätenklarheit, Beziehungsmodellierung und inhaltliche Abstimmung – bleiben konstant, aber die betonten Schema-Typen und Eigenschaften sollten widerspiegeln, wie Menschen tatsächlich in Ihrem Bereich suchen.
Für E-Commerce und Einzelhandel sind Produkte, Angebote, Rezensionen und Ihre Organisation die primären Entitäten. Jede produktstarke Seite sollte detailliertes Product-Markup mit Identifikatoren (SKU, GTIN), Marke, Modell, Maßen, Materialien und Unterscheidungsmerkmalen über additionalProperty bereitstellen. Kombinieren Sie dies mit Offers (Preis und Verfügbarkeit) und AggregateRating-Strukturen, damit Modelle Social Proof verstehen. Darüber hinaus: Denken Sie, wie Käufer fragen – „Ist das wasserdicht?“, „Gibt es Garantie?“, „Wie ist die Rückgabepolitik?“ Kodieren Sie diese Antworten als FAQPage-Markup auf derselben URL und sorgen Sie dafür, dass Produktattribute und FAQ-Inhalte synchron bleiben, um Antwortmaschinen die richtige Seite zur Zitation zu erleichtern.
Für SaaS- und B2B-Dienstleistungen sind die Entitäten abstrakter, lassen sich aber gut auf SoftwareApplication-, Service- und Organization-Schema abbilden. Für jedes Kernprodukt oder Angebot definieren Sie eine SoftwareApplication- oder Service-Entität mit klarer Kategorie, unterstützten Plattformen, Integrationen und Preismodellen; nutzen Sie additionalProperty-Felder für Features, die oft in „Beste Tools für X“-Vergleichen erscheinen. Verknüpfen Sie diese über provider- oder offers-Beziehungen mit Ihrer Organisation und über Person-Markup mit Ihren Expert:innen. Auf der Content-Seite helfen Article-, BlogPosting-, FAQPage- und HowTo-Strukturen LLMs, Ihre besten Inhalte für evaluative und lehrende Suchanfragen zu erkennen.
Für lokale, medizinische und regulierte Branchen können LocalBusiness-, MedicalOrganization- und verwandte MedicalEntity-Typen Adressen, Einzugsgebiete, Fachgebiete, akzeptierte Versicherungen und Öffnungszeiten weit weniger zweideutig als Freitext abbilden. Das ist relevant, wenn ein KI-Assistent gefragt wird: „Finde einen Kinderkardiologen in meiner Nähe, der meine Versicherung akzeptiert“ oder „Empfiehl eine Notfallpraxis, die jetzt geöffnet hat“. Seien Sie in diesen Bereichen besonders vorsichtig, dass das Schema nicht übertrieben oder sensible Details preisgibt – markieren Sie nur Fakten, die Sie in vielen Kontexten wiederverwendet wissen wollen, und lassen Sie medizinisch oder regulatorisch relevante Attribute von Compliance- und Rechtsabteilungen prüfen.
LLM-Verhalten ist inhärent stochastisch, daher erreichen Sie keine pixelgenaue Attribution allein durch Schema-Änderungen. Was Sie tun können: Ein leichtgewichtiges Monitoring-System aufbauen, das in regelmäßigen Abständen KI-Antworten für ein festes Query-Set abfragt. Verfolgen Sie, welche Entitäten genannt, welche URLs zitiert werden, wie Ihre Marke beschrieben wird und ob Schlüsselfakten (Preis, Fähigkeiten, Compliance) plattformübergreifend korrekt sind – etwa auf ChatGPT, Gemini, Perplexity und Bing Copilot. Wenn etwas schief läuft – halluzinierte Features, fehlende Erwähnungen oder Zitate, die Aggregatoren statt Ihrer Seiten bevorzugen – prüfen Sie zuerst auf widersprüchliche oder unvollständige Signale. Widerspricht der Onpage-Text dem Schema? Fehlen sameAs-Links oder verweisen sie auf veraltete Profile? Behaupten mehrere Seiten, die kanonische Quelle für dieselbe Entität zu sein? Planen Sie strategisch mindestens vierteljährliche Schema-Reviews, um neue Angebote, Content-Cluster und Veränderungen in den Antwortmaschinen zu berücksichtigen.
Mehrere Muster beeinträchtigen die Schema-Wirksamkeit für KI-Systeme immer wieder. Inhalte mit Schema zu markieren, die tatsächlich auf der Seite nicht sichtbar sind, schafft ein Vertrauensdefizit – Modelle lernen, Quellen abzuwerten, bei denen Schema und sichtbarer Inhalt auseinandergehen. Übermäßig generische Typen ohne Spezifizierung zu nutzen (z. B. alles als „Thing“ oder „CreativeWork“ markieren) liefert kein semantisches Signal; Modelle benötigen präzise Typen für Kontextverständnis. Das Kopieren von Standardschema über Seiten hinweg ohne Anpassung der Entitätsdetails ist wohl der häufigste Fehler – wenn jede Produktseite identisches Organization-Markup hat oder jeder Artikel denselben Autor beansprucht, können Modelle Inhalte nicht unterscheiden und stufen sie als schwach ein. Inkonsistente Entitäten-IDs über Seiten hinweg (verschiedene @id-Werte für dieselbe Organisation oder Produkt) zerstören die Entitätenauflösung und zwingen Modelle, verwandte Inhalte als separate Entitäten zu behandeln. Fehlende sameAs-Links zu maßgeblichen Profilen machen es Modellen schwer, Ihre Marke von Namensvettern zu unterscheiden. Schließlich signalisieren widersprüchliche Angaben zwischen Schema und Seitentext Unzuverlässigkeit; behauptet das Schema, ein Produkt sei verfügbar, steht aber auf der Seite „ausverkauft“, vertrauen Modelle weder dem einen noch dem anderen.
Schema-Markup wandelt sich von einer kosmetischen SEO-Taktik zur Basistechnologie für AI-first-Suche. Verbundenes Schema-Markup – bei dem Sie Beziehungen zwischen Entitäten explizit über Eigenschaften wie sameAs, about und mentions definieren – baut Knowledge Graphs, in denen sich KI-Systeme sicher bewegen können. Der Wettbewerbsvorteil liegt nicht mehr bei denen, die fragen: „Welches Mindest-Schema brauchen wir für ein Rich Result?“, sondern bei denen, die fragen: „Welche strukturierte Darstellung macht unsere Inhalte einer Maschine eindeutig, auch außerhalb der SERP?“ Dieser Wandel treibt Unternehmen zu vollständiger, vernetzter und entitätenzentrierter Schema-Architektur. Da KI-gestützte Suche zum primären Entdeckungsweg wird, entwickelt sich Schema-LLM-Optimierung von einer technischen Spielerei zu einer Kern-Disziplin im SEO. Unternehmen, die die Reifegrade vom Basis-Rich-Result-Schema bis hin zu knowledge-graph-integrierten und LLM-optimierten Mustern durchlaufen, schaffen nachhaltige Barrieren in der KI-getriebenen Auffindbarkeit, sorgen für Zitate als Autorität und Sichtbarkeit als vertrauenswürdige Quelle.
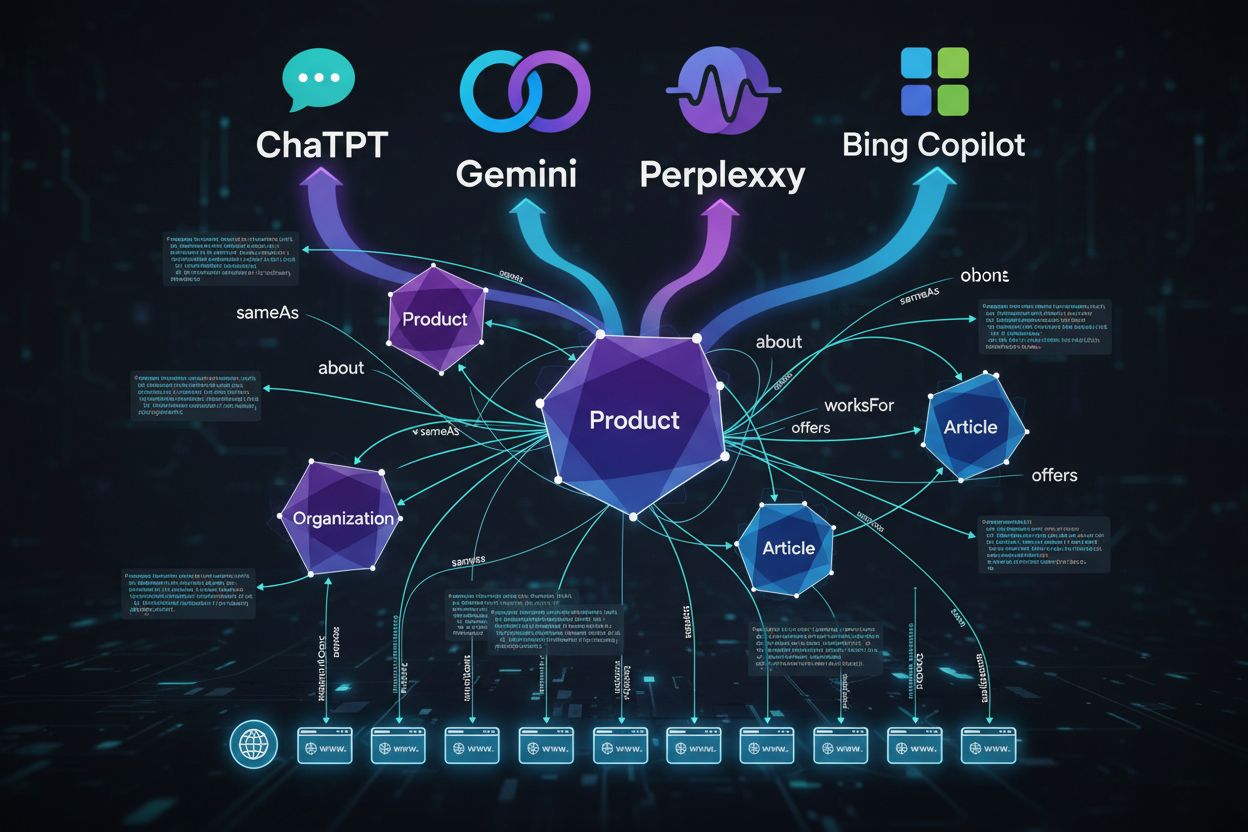
Traditionelles Schema konzentrierte sich auf Rich Results (Sterne, Snippets). Bei KI geht es beim Schema um Entitätenklarheit, Beziehungen und Knowledge Graphs. KI-Systeme nutzen Schema, um zu verstehen, worum es bei Ihren Inhalten semantisch geht, nicht nur um visuelle Verbesserungen.
Organization, Product, Article, Person und FAQPage sind grundlegend. Für SaaS zusätzlich SoftwareApplication und Service. Für lokale/medizinische Bereiche LocalBusiness und MedicalOrganization. Die Wichtigkeit variiert je nach Branche und Nutzerintention.
Nein. Beginnen Sie mit Organization und Ihren wichtigsten Seiten (Produkte, Dienstleistungen, Schlüsselartikel). Erweitern Sie die Abdeckung schrittweise je nach Geschäftsmodell und dort, wo KI-Antworten am wertvollsten wären.
Schema-Änderungen können KI-Zitate innerhalb von Wochen beeinflussen, aber der Zusammenhang ist probabilistisch. Planen Sie vierteljährliche Überprüfungen und kontinuierliches Monitoring über mehrere KI-Plattformen hinweg, um Auswirkungen zu verfolgen.
sameAs verlinkt Ihre Entität mit kanonischen Profilen (Wikipedia, LinkedIn), um Verwechslungen zu vermeiden. about/mentions verdeutlicht, worauf sich Ihre Seite tatsächlich konzentriert, und hilft Modellen, Nuancen und Kontext zu verstehen.
Nein. Schema funktioniert am besten, wenn es mit hochwertigem, gut strukturiertem Onpage-Content abgestimmt ist. Modelle benötigen sowohl strukturierte Daten als auch narrativen Kontext, um Ihre Seiten sicher zu zitieren.
Überwachen Sie KI-Antworten auf Plattformen (ChatGPT, Gemini, Perplexity, Bing) für Ihre Zielanfragen. Verfolgen Sie Entitätennennungen, URL-Zitate, Fakten-Genauigkeit und Markenbeschreibung. Beobachten Sie Trends über Wochen/Monate.
JSON-LD ist das empfohlene Format für die meisten Anwendungsfälle. Es ist leichter zu implementieren, zu warten und beeinträchtigt das HTML nicht. Microdata und RDFa sind in modernen Implementierungen weniger verbreitet.
Verfolgen Sie, wie KI-Systeme Ihre Marke in ChatGPT, Gemini, Perplexity und Google AI Overviews zitieren. Erhalten Sie Einblicke, welche Schema-Typen die Sichtbarkeit erhöhen.
Erfahren Sie, wie Rich Results und strukturierte Daten die KI-Suchmaschinen, LLMs und die Sichtbarkeit von Inhalten in KI-gestützten Antworten von ChatGPT, Perp...
Entdecken Sie, welche Schema-Markup-Typen Ihre Sichtbarkeit in KI-Suchmaschinen wie ChatGPT, Perplexity und Gemini steigern. Lernen Sie JSON-LD-Implementierungs...
Schema-Markup ist standardisierter Code, der Suchmaschinen hilft, Inhalte zu verstehen. Erfahre, wie strukturierte Daten SEO verbessern, Rich Results ermögliche...