Trainingsdatenoptimierung vs. Echtzeit-Abfrage: Optimierungsstrategien
Vergleichen Sie Optimierungsstrategien für Trainingsdaten und Echtzeit-Abfrage für KI. Erfahren Sie, wann Feintuning und wann RAG sinnvoll ist, was die Kosten bedeuten und wie hybride Ansätze für optimale KI-Leistung eingesetzt werden können.
Veröffentlicht am Jan 3, 2026.Zuletzt geändert am Jan 3, 2026 um 3:24 am
Trainingsdatenoptimierung und Echtzeit-Abfrage stehen für grundlegend verschiedene Ansätze, KI-Modelle mit Wissen auszustatten. Trainingsdatenoptimierung bedeutet, dass Wissen direkt in die Parameter eines Modells eingebettet wird – durch Feintuning auf domänenspezifischen Datensätzen entsteht statisches Wissen, das nach dem Training fest im Modell verankert bleibt. Echtzeit-Abfrage hingegen hält Wissen extern und ruft relevante Informationen während der Inferenz dynamisch ab, wodurch Zugriff auf dynamische Informationen möglich wird, die sich von Anfrage zu Anfrage ändern können. Der zentrale Unterschied liegt darin, wann das Wissen in das Modell integriert wird: Trainingsdatenoptimierung erfolgt vor dem Einsatz, Echtzeit-Abfrage bei jeder einzelnen Inferenz. Diese grundlegende Differenz zieht sich durch alle Aspekte der Implementierung – von Infrastruktur-Anforderungen über Genauigkeitsmerkmale bis hin zu Compliance-Fragen. Das Verständnis dieses Unterschieds ist entscheidend für Organisationen, die eine Optimierungsstrategie wählen müssen, die zu ihren spezifischen Anwendungsfällen und Rahmenbedingungen passt.
Wie Trainingsdatenoptimierung funktioniert
Trainingsdatenoptimierung funktioniert, indem die internen Parameter eines Modells systematisch durch die Einwirkung kuratierter, domänenspezifischer Datensätze während des Feintunings angepasst werden. Wenn ein Modell Trainingsbeispiele wiederholt sieht, verinnerlicht es schrittweise Muster, Terminologie und Fachwissen durch Backpropagation und Gradientenanpassungen, die die Lernmechanismen des Modells umformen. So können Unternehmen spezialisiertes Wissen – von medizinischer Terminologie über rechtliche Rahmenbedingungen bis zu unternehmenseigenen Geschäftslogiken – direkt in die Gewichte und Biases des Modells einbetten. Das resultierende Modell ist hochspezialisiert für den Zielbereich und erreicht oft eine Leistung, die mit deutlich größeren Modellen vergleichbar ist: Forschungsarbeiten von Snorkel AI zeigten, dass feingetunte kleinere Modelle so gut abschneiden können wie Modelle, die 1.400-mal größer sind. Wichtige Merkmale der Trainingsdatenoptimierung sind:
Permanente Wissensinjektion: Nach dem Training ist das Wissen Teil des Modells und erfordert keine externen Abfragen mehr
Reduzierte Inferenz-Latenz: Keine Abfrageverzögerung bei der Vorhersage, was schnellere Antwortzeiten ermöglicht
Konsistenter Stil und Formatierung: Modelle erlernen domänenspezifische Kommunikationsmuster und Konventionen
Offline-Betrieb möglich: Modelle funktionieren unabhängig von externen Datenquellen
Hohe Anfangskosten für Rechenleistung: Erfordert beträchtliche GPU-Ressourcen und vorbereitete, gelabelte Trainingsdaten
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
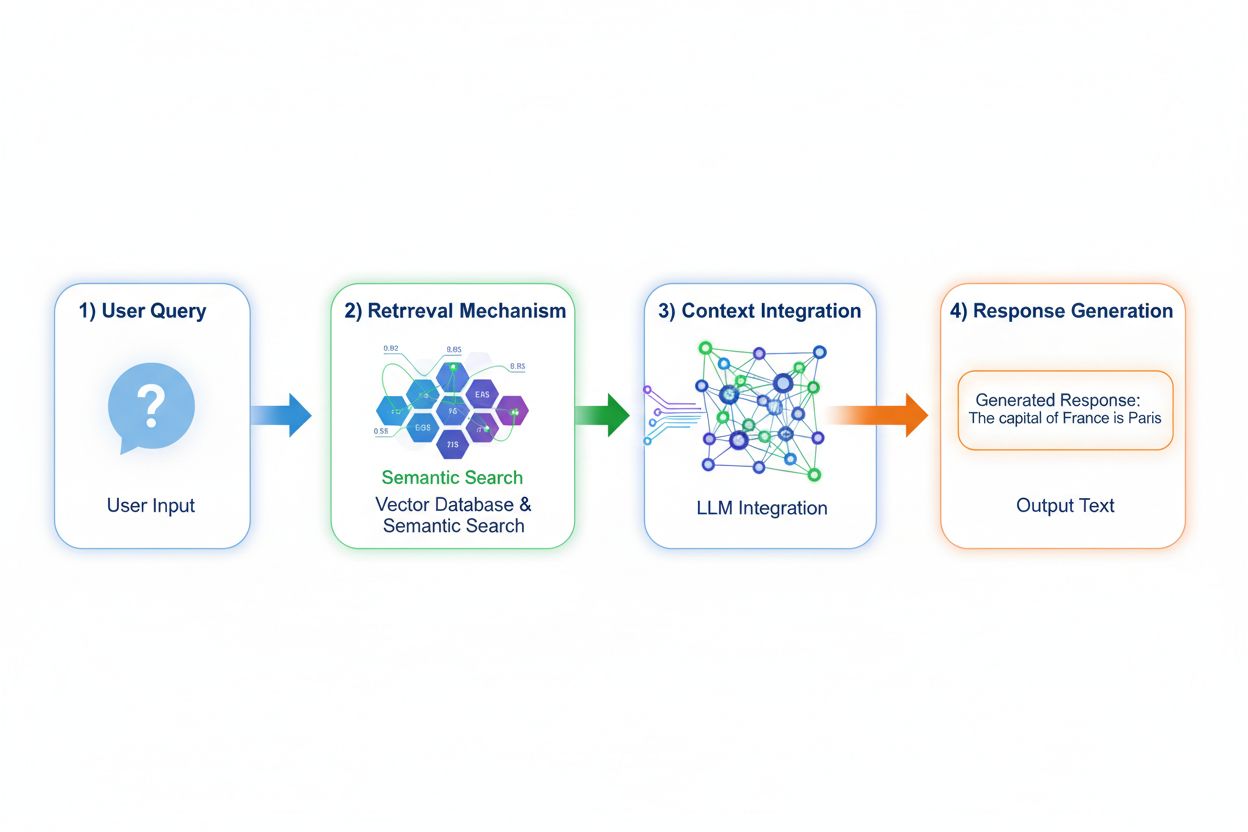
Retrieval Augmented Generation (RAG) verändert grundlegend, wie Modelle auf Wissen zugreifen, indem ein vierstufiger Prozess implementiert wird: Query-Encoding, semantische Suche, Kontext-Ranking und Generierung mit Grounding. Gibt ein Nutzer eine Anfrage ein, wird diese zunächst mittels Embedding-Modellen in eine dichte Vektor-Darstellung umgewandelt, dann in einer Vektordatenbank mit indizierten Dokumenten oder Wissensquellen durchsucht. In der Retrieval-Phase werden mit semantischer Suche kontextuell relevante Passagen gefunden und nach Relevanz bewertet. Abschließend generiert das Modell Antworten und verweist explizit auf genutzte Quellen; die Ausgabe basiert auf tatsächlichen Daten statt auf im Modell gelernten Parametern. Diese Architektur ermöglicht es Modellen, auf Informationen zuzugreifen, die zum Trainingszeitpunkt nicht existierten, und macht RAG besonders wertvoll für Anwendungen, die aktuelle Informationen, proprietäre Daten oder häufig aktualisierte Wissensbasen benötigen. Der RAG-Mechanismus verwandelt das Modell im Grunde von einem statischen Wissensspeicher in einen dynamischen Informations-Synthesizer, der neue Daten ohne Neutrainierung einbeziehen kann.
Performance- und Genauigkeitsvergleich
Die Genauigkeit und das Halluzinationsverhalten dieser Ansätze unterscheiden sich deutlich und beeinflussen die Praxistauglichkeit. Die Trainingsdatenoptimierung erzeugt Modelle mit tiefgehendem Domänenverständnis, aber begrenzter Fähigkeit, Wissensgrenzen zu erkennen; bei Fragen außerhalb des Trainingsbereichs können feingetunte Modelle plausibel klingende, aber falsche Antworten liefern. RAG reduziert Halluzinationen deutlich, da Antworten auf abgerufenen Dokumenten basieren – das Modell kann keine Informationen behaupten, die nicht in der Quelle stehen, was die Fantasie begrenzt. Allerdings birgt RAG andere Genauigkeitsrisiken: Findet die Retrieval-Phase keine relevanten Quellen oder werden irrelevante Dokumente hoch bewertet, entstehen Antworten auf Basis schlechter Kontexte. Datenaktualität wird für RAG-Systeme kritisch; Trainingsdatenoptimierung bildet einen statischen Wissensstand zum Trainingszeitpunkt ab, während RAG kontinuierlich den aktuellen Stand der Quelldokumente widerspiegelt. Quellenangabe ist ein weiterer Unterschied: RAG ermöglicht von Haus aus die Zitierung und Verifizierung von Behauptungen, während feingetunte Modelle keine spezifischen Quellen für ihr Wissen nennen können – das erschwert Fact-Checking und Compliance.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kosten- und Infrastruktur-Implikationen
Die Kostenprofile dieser Ansätze unterscheiden sich grundlegend und müssen von Organisationen sorgfältig abgewogen werden. Trainingsdatenoptimierung erfordert hohe Rechenaufwände zu Beginn: GPU-Cluster, die Modelle über Tage oder Wochen feintunen, Datenannotationsdienste zur Erstellung gelabelter Datensätze und ML-Engineering für effektive Trainingspipelines. Nach dem Training sind die Betriebskosten gering, da für Inferenz nur Standard-Serving-Infrastruktur ohne externe Abfragen benötigt wird. RAG-Systeme kehren dieses Kostenprofil um: Geringere Anfangskosten, da kein Feintuning nötig ist, aber laufende Infrastrukturkosten für Vektordatenbanken, Embedding-Serving, Retrieval-Dienste und Dokumenten-Indexierung. Wichtige Kostenfaktoren sind:
Feintuning: GPU-Stunden (10.000–100.000+ $ pro Modell), Datenannotation (0,50–5 $ pro Beispiel), Engineering-Aufwand
RAG-Infrastruktur: Lizenzen für Vektordatenbanken, Betrieb von Embedding-Modellen, Speicherung und Indexierung von Dokumenten, Optimierung der Abfragelatenz
Skalierbarkeit: Feingetunte Modelle skalieren linear mit dem Anfragevolumen; RAG-Systeme skalieren mit Anfragevolumen und Wissensbasisgröße
Wartung: Feintuning erfordert periodisches Neutrainieren; RAG laufende Dokumentenaktualisierung und Indexpflege
Sicherheit und Compliance-Aspekte
Sicherheits- und Compliance-Fragen unterscheiden sich zwischen den Ansätzen grundlegend und betreffen insbesondere regulierte Branchen. Feingetunte Modelle schaffen Datenschutzprobleme, da Trainingsdaten in den Modellgewichten eingebettet werden; eine Extraktion oder Prüfung des Wissens erfordert komplexe Techniken, und Privatsphäre wird zum Thema, wenn sensible Trainingsdaten das Modellverhalten beeinflussen. Compliance mit Regelwerken wie DSGVO wird schwierig, da das Modell Trainingsdaten „behalten“ kann und sich diese nur schwer löschen oder anpassen lassen. RAG-Systeme bieten andere Sicherheitsprofile: Wissen verbleibt in externen, prüfbaren Quellen statt in Modellparametern, sodass Sicherheitskontrollen und Zugriffsbeschränkungen einfach umsetzbar sind. Unternehmen können feingranulare Berechtigungen für Retrieval-Quellen implementieren, nachvollziehen, auf welche Dokumente das Modell für jede Antwort zugegriffen hat, und sensible Informationen schnell entfernen, indem sie Quelldokumente aktualisieren – ohne Neutrainierung. Allerdings bringt RAG neue Risiken rund um Schutz der Vektordatenbank, Sicherheit der Embedding-Modelle und das Verhindern von Datenlecks in abgerufenen Dokumenten mit sich. HIPAA-regulierte Gesundheitsorganisationen und DSGVO-pflichtige Unternehmen in Europa bevorzugen oft die Transparenz und Auditierbarkeit von RAG, während Organisationen mit Fokus auf Portabilität und Offline-Betrieb die Eigenständigkeit von Feintuning schätzen.
Praktischer Entscheidungsrahmen
Die Wahl zwischen den Ansätzen erfordert die Bewertung individueller Rahmenbedingungen und Use-Case-Merkmale. Feintuning ist zu bevorzugen, wenn Wissen stabil ist und sich selten ändert, wenn niedrige Latenz bei der Inferenz entscheidend ist, wenn Modelle offline oder in abgeschotteten Umgebungen laufen müssen oder wenn konsistenter Stil und domänenspezifische Formatierung wichtig sind. Echtzeit-Abfrage empfiehlt sich, wenn Wissen regelmäßig aktualisiert wird, Quellenangabe und Auditierbarkeit für Compliance wichtig sind, die Wissensbasis zu groß für eine Einbettung ins Modell ist oder Informationen ohne Neutrainieren aktualisiert werden müssen. Typische Anwendungsfälle verdeutlichen diese Unterschiede:
Feintuning: Chatbots für stabilen Produkt-Support, spezialisierte medizinische Diagnoseassistenten, Analyse juristischer Dokumente mit etabliertem Fallrecht
RAG: Nachrichten-Zusammenfassung mit aktuellen Ereignissen, Support für häufig aktualisierte Produktkataloge, Rechercheassistenten mit Zugriff auf dynamische Fachliteratur
Entscheidungsrahmen: Beurteilen Sie Wissensstabilität, Compliance-Anforderungen, Latenz, Aktualisierungshäufigkeit und Infrastruktur
Hybride Ansätze und kombinierte Strategien
Hybride Ansätze kombinieren Feintuning und RAG, um die Vorteile beider Strategien zu nutzen und deren jeweilige Schwächen auszugleichen. Unternehmen können Modelle auf grundlegende Domänenkenntnisse und Kommunikationsmuster feintunen und über RAG aktuelle, detaillierte Informationen abrufen – das Modell lernt wie es über einen Bereich denken soll und ruft welche konkreten Fakten ab. Diese Kombistrategie ist besonders effektiv bei Anwendungen, die sowohl spezialisiertes Fachwissen als auch aktuelle Informationen benötigen: Ein Finanzberater-Bot, der auf Investment-Prinzipien und Fachterminologie feingetunt ist, kann via RAG Echtzeit-Marktdaten und Firmenkennzahlen einbinden. Reale Hybrid-Implementierungen umfassen Gesundheitssysteme, die auf medizinischem Wissen und Protokollen feingetunt sind und patientenbezogene Daten via RAG abrufen, sowie juristische Plattformen, die auf juristische Argumentation feingetunt sind und aktuelle Rechtsprechung recherchieren. Die Synergieeffekte umfassen weniger Halluzinationen (durch Grounding in Quellen), besseres Domänenverständnis (durch Feintuning), schnellere Inferenz bei Standardanfragen (durch gecachtes Wissen) und Flexibilität bei der Aktualisierung von Spezialwissen ohne Neutrainierung. Mit zunehmender Rechenleistung und Komplexität der Anwendungsfälle setzen immer mehr Organisationen auf diese Optimierungsstrategie, um sowohl Tiefe als auch Aktualität sicherzustellen.
Überwachung von KI-Antworten und Zitations-Tracking
Die Fähigkeit, KI-Antworten in Echtzeit zu überwachen, wird mit zunehmender Skalierung dieser Optimierungsstrategien immer wichtiger – vor allem, um zu verstehen, welcher Ansatz für welche Anwendungsfälle bessere Ergebnisse liefert. KI-Monitoring-Systeme verfolgen Modellausgaben, Retrieval-Qualität und Nutzerzufriedenheit und ermöglichen es Unternehmen, zu messen, ob feingetunte Modelle oder RAG-Systeme ihre Anwendung besser bedienen. Zitations-Tracking macht zentrale Unterschiede sichtbar: RAG-Systeme generieren von Haus aus Quellenangaben und schaffen eine Prüfspur, welche Dokumente die jeweilige Antwort beeinflusst haben, während feingetunte Modelle keine Möglichkeit für Antwortüberwachung oder Attribution bieten. Für Markenschutz und Wettbewerbsanalyse ist das entscheidend – Unternehmen müssen verstehen, wie KI-Systeme ihre Mitbewerber zitieren, ihre Produkte referenzieren oder Informationen attribuieren. Tools wie AmICited.com schließen diese Lücke, indem sie überwachen, wie KI-Systeme Marken und Firmen mit unterschiedlichen Optimierungsstrategien zitieren und so Echtzeit-Tracking von Zitiermustern und -häufigkeiten ermöglichen. Durch umfassende Überwachung können Unternehmen messen, ob ihre gewählte Optimierungsstrategie (Feintuning, RAG oder Hybrid) tatsächlich die Zitiergenauigkeit verbessert, Halluzinationen über Mitbewerber reduziert und eine angemessene Attribution an autoritative Quellen wahrt. Dieser datengetriebene Ansatz ermöglicht eine kontinuierliche Optimierungs- und Strategieanpassung basierend auf realen Ergebnissen statt theoretischer Annahmen.
Zukünftige Trends und neue Muster
Die Branche entwickelt sich hin zu immer ausgefeilteren hybriden und adaptiven Ansätzen, die je nach Anfrageeigenschaften und Wissensbedarf dynamisch zwischen Optimierungsstrategien wählen. Zu den neuen Best Practices gehört, Feintuning mit Retrieval-Unterstützung zu kombinieren, bei dem Modelle darauf trainiert werden, abgerufene Informationen effektiv zu nutzen, statt Fakten zu memorieren; adaptive Routingsysteme leiten Anfragen wahlweise an feingetunte Modelle für stabiles Wissen oder an RAG-Systeme für dynamische Informationen. Trends zeigen eine zunehmende Verbreitung spezialisierter Embedding-Modelle und Vektordatenbanken für bestimmte Fachbereiche, was präzisere semantische Suche und weniger Abfragerauschen ermöglicht. Unternehmen entwickeln Muster für kontinuierliche Modellverbesserung, indem sie periodische Feintuning-Updates mit Echtzeit-RAG-Erweiterung kombinieren – so entstehen Systeme, die sich laufend verbessern und trotzdem immer auf aktuelle Informationen zugreifen. Die Weiterentwicklung von Optimierungsstrategien spiegelt die zunehmende Erkenntnis wider, dass kein Ansatz alle Anwendungsfälle optimal bedient; künftige Systeme werden vermutlich intelligente Auswahlmechanismen implementieren, die je nach Anfragekontext, Wissensstabilität, Latenzanforderungen und Compliance-Vorgaben zwischen Feintuning, RAG und Hybrid-Ansätzen wechseln. Mit zunehmender Reife der Technologien wird der Wettbewerbsvorteil weniger in der Wahl einer einzelnen Strategie liegen, sondern im gekonnten Aufbau adaptiver Systeme, die die Stärken jedes Ansatzes flexibel kombinieren.
Häufig gestellte Fragen
Was ist der Hauptunterschied zwischen Trainingsdatenoptimierung und Echtzeit-Abfrage?
Bei der Trainingsdatenoptimierung wird Wissen direkt in die Parameter eines Modells durch Feintuning eingebettet, wodurch statisches Wissen entsteht, das nach dem Training unverändert bleibt. Echtzeit-Abfrage hält Wissen extern und ruft relevante Informationen dynamisch bei der Inferenz ab, sodass Zugriff auf dynamische Informationen möglich ist, die sich zwischen Anfragen ändern können. Der zentrale Unterschied ist, wann das Wissen integriert wird: Trainingsdatenoptimierung erfolgt vor dem Einsatz, während Echtzeit-Abfrage bei jedem Inferenzaufruf stattfindet.
Wann sollte ich Feintuning statt RAG verwenden?
Verwenden Sie Feintuning, wenn Wissen stabil ist und sich voraussichtlich nicht häufig ändert, wenn niedrige Inferenzlatenz entscheidend ist, wenn Modelle offline laufen müssen oder wenn konsistenter Stil und domänenspezifische Formatierung wichtig sind. Feintuning ist ideal für spezialisierte Aufgaben wie medizinische Diagnostik, Analyse juristischer Dokumente oder Kundenservice mit stabilen Produktinformationen. Allerdings erfordert Feintuning erhebliche Anfangsressourcen und wird unpraktisch, wenn sich Informationen häufig ändern.
Kann ich Trainingsdatenoptimierung mit Echtzeit-Abfrage kombinieren?
Ja, hybride Ansätze kombinieren Feintuning und RAG, um die Vorteile beider Strategien zu nutzen. Organisationen können Modelle auf grundlegende Domänenkenntnisse feintunen und gleichzeitig RAG einsetzen, um auf aktuelle, detaillierte Informationen zuzugreifen. Dieser Ansatz ist besonders effektiv für Anwendungen, die sowohl spezialisiertes Fachwissen als auch aktuelle Informationen benötigen, wie z. B. Finanzberatungs-Bots oder Gesundheitssysteme, die sowohl medizinisches Wissen als auch patientenspezifische Daten benötigen.
Wie reduziert RAG Halluzinationen im Vergleich zu Feintuning?
RAG reduziert Halluzinationen erheblich, indem Antworten auf abgerufenen Dokumenten basieren – das Modell kann keine Informationen behaupten, die in den Quellen nicht erscheinen, was natürliche Grenzen gegen Erfindungen schafft. Feingetunte Modelle hingegen können bei Fragen außerhalb des Trainingsbereichs plausibel klingende, aber falsche Informationen generieren. Die Quellenangabe von RAG ermöglicht außerdem die Überprüfung von Aussagen, während feingetunte Modelle keine spezifischen Quellen für ihr Wissen nennen können.
Was sind die Kostenimplikationen der jeweiligen Ansätze?
Feintuning erfordert hohe Anfangskosten: GPU-Stunden (10.000–100.000+ $ pro Modell), Datenannotation (0,50–5 $ pro Beispiel) und Ingenieurszeit. Nach dem Training bleiben die Betriebskosten relativ niedrig. RAG-Systeme haben geringere Anfangskosten, aber laufende Infrastruktur-Ausgaben für Vektordatenbanken, Embedding-Modelle und Abfragedienste. Feingetunte Modelle skalieren linear mit dem Anfragevolumen, während RAG-Systeme mit Anfragevolumen und Wissensbasisgröße skalieren.
Wie hilft Echtzeit-Abfrage beim KI-Zitations-Tracking?
RAG-Systeme generieren von Natur aus Zitate und Quellenangaben und schaffen so eine Prüfspur darüber, welche Dokumente jede Antwort beeinflusst haben. Das ist entscheidend für Markenschutz und Wettbewerbsanalyse – Organisationen können verfolgen, wie KI-Systeme ihre Mitbewerber zitieren und ihre Produkte referenzieren. Tools wie AmICited.com überwachen, wie KI-Systeme Marken über verschiedene Optimierungsstrategien hinweg zitieren, und bieten Echtzeit-Tracking von Zitiermustern und -häufigkeit.
Welcher Ansatz ist besser für stark regulierte Branchen?
RAG ist in der Regel besser für stark regulierte Branchen wie Gesundheitswesen und Finanzen geeignet. Wissen verbleibt in externen, prüfbaren Datenquellen statt in Modellparametern, sodass Sicherheitskontrollen und Zugriffsbeschränkungen einfach umsetzbar sind. Organisationen können fein abgestufte Berechtigungen implementieren, prüfen, auf welche Dokumente das Modell zugegriffen hat und sensible Informationen schnell entfernen, ohne neu trainieren zu müssen. HIPAA-regulierte Gesundheitsorganisationen und DSGVO-pflichtige Unternehmen bevorzugen oft die Transparenz und Prüfbarkeit von RAG.
Wie überwache ich die Wirksamkeit meiner gewählten Optimierungsstrategie?
Implementieren Sie KI-Monitoring-Systeme, die Modellausgaben, Abfragequalität und Benutzerzufriedenheit messen. Bei RAG-Systemen sollten Sie die Abrufgenauigkeit und Zitierqualität überwachen. Bei feingetunten Modellen sollten Sie die Genauigkeit bei domänenspezifischen Aufgaben und die Halluzinationsrate verfolgen. Nutzen Sie Tools wie AmICited.com, um zu überwachen, wie Ihre KI-Systeme Informationen zitieren und die Leistung verschiedener Optimierungsstrategien anhand realer Ergebnisse vergleichen.
Überwachen Sie, wie KI-Systeme Ihre Marke zitieren
Verfolgen Sie Echtzeit-Zitate über GPTs, Perplexity und Google AI Overviews hinweg. Verstehen Sie, welche Optimierungsstrategien Ihre Mitbewerber nutzen und wie diese in KI-Antworten referenziert werden.
So optimieren Sie Ihre Inhalte für KI-Trainingsdaten und KI-Suchmaschinen
Erfahren Sie, wie Sie Ihre Inhalte für die Aufnahme in KI-Trainingsdaten optimieren. Entdecken Sie Best Practices, um Ihre Website durch richtige Inhaltsstruktu...
Entdecken Sie Echtzeit-KI-Adaptation – die Technologie, mit der KI-Systeme kontinuierlich aus aktuellen Ereignissen und Daten lernen. Erfahren Sie, wie adaptive...
So lehnen Sie das KI-Training auf großen Plattformen ab
Vollständiger Leitfaden zum Ablehnen der Datensammlung für KI-Training auf ChatGPT, Perplexity, LinkedIn und anderen Plattformen. Erfahren Sie Schritt-für-Schri...
8 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.