
Einbettung
Erfahren Sie, was Einbettungen sind, wie sie funktionieren und warum sie für KI-Systeme unerlässlich sind. Entdecken Sie, wie Text in numerische Vektoren umgewa...
11 Min. Lesezeit

Erfahren Sie, wie Vektor-Einbettungen KI-Systemen ermöglichen, semantische Bedeutungen zu verstehen und Inhalte mit Anfragen abzugleichen. Entdecken Sie die Technologie hinter semantischer Suche und KI-gestütztem Content-Matching.

Vektor-Einbettungen sind das numerische Fundament moderner künstlicher Intelligenzsysteme. Sie verwandeln Rohdaten in mathematische Repräsentationen, die Maschinen verstehen und verarbeiten können. Im Kern wandeln Einbettungen Text, Bilder, Audio und andere Inhaltstypen in Zahlenarrays um – typischerweise mit Dutzenden bis Tausenden von Dimensionen – die die semantische Bedeutung und kontextuelle Beziehungen innerhalb dieser Daten erfassen. Diese numerische Repräsentation ist grundlegend dafür, wie KI-Systeme Content-Matching, semantische Suche und Empfehlungsaufgaben durchführen. So können Maschinen nicht nur erkennen, welche Wörter oder Bilder vorhanden sind, sondern auch, was sie tatsächlich bedeuten. Ohne Einbettungen hätten KI-Systeme Schwierigkeiten, die feinen Beziehungen zwischen Konzepten zu erfassen und wären daher essenzielle Infrastruktur für jede moderne KI-Anwendung.
Die Umwandlung von Rohdaten in Vektor-Einbettungen erfolgt durch ausgefeilte neuronale Netzmodelle, die auf riesigen Datensätzen trainiert werden, um bedeutungsvolle Muster und Beziehungen zu erlernen. Wenn Sie Text in ein Einbettungsmodell eingeben, wird er durch mehrere Schichten neuronaler Netze geleitet, die schrittweise semantische Informationen extrahieren und schließlich einen Vektor fester Größe erzeugen, der das Wesentliche dieses Inhalts repräsentiert. Beliebte Einbettungsmodelle wie Word2Vec, GloVE und BERT verfolgen jeweils unterschiedliche Ansätze – Word2Vec nutzt flache neuronale Netze, die auf Geschwindigkeit optimiert sind, GloVE kombiniert globale Matrixfaktorisierung mit lokalen Kontextfenstern, während BERT eine Transformator-Architektur verwendet, um bidirektionalen Kontext zu verstehen.
| Modell | Datentyp | Dimensionen | Haupteinsatzgebiet | Wichtigster Vorteil |
|---|---|---|---|---|
| Word2Vec | Text (Wörter) | 100-300 | Wortbeziehungen | Schnell, effizient |
| GloVE | Text (Wörter) | 100-300 | Semantische Beziehungen | Kombiniert globalen und lokalen Kontext |
| BERT | Text (Sätze/Dokumente) | 768-1024 | Kontextuelles Verständnis | Bidirektionales Kontextbewusstsein |
| Sentence-BERT | Text (Sätze) | 384-768 | Satzähnlichkeit | Für semantische Suche optimiert |
| Universal Sentence Encoder | Text (Sätze) | 512 | Cross-linguale Aufgaben | Sprachunabhängig |
Diese Modelle erzeugen hochdimensionale Vektoren (oft 300 bis 1.536 Dimensionen), wobei jede Dimension unterschiedliche Aspekte von Bedeutung, von grammatikalischen Eigenschaften bis zu konzeptuellen Beziehungen, einfängt. Der Vorteil dieser numerischen Repräsentation besteht darin, dass sie mathematische Operationen ermöglicht – Sie können Vektoren addieren, subtrahieren und vergleichen, um Beziehungen zu entdecken, die im Rohtext unsichtbar wären. Dieses mathematische Fundament ermöglicht semantische Suche und intelligentes Content-Matching im großen Maßstab.
Die wahre Stärke von Einbettungen zeigt sich in der semantischen Ähnlichkeit, also der Fähigkeit, zu erkennen, dass unterschiedliche Wörter oder Phrasen im Vektorraum im Wesentlichen dasselbe bedeuten können. Wenn Einbettungen effektiv erstellt werden, gruppieren sich semantisch ähnliche Konzepte im hochdimensionalen Raum natürlich – „König“ und „Königin“ liegen beieinander, ebenso wie „Auto“ und „Fahrzeug“, auch wenn es unterschiedliche Wörter sind. Um diese Ähnlichkeit zu messen, verwenden KI-Systeme Distanzmetriken wie die Kosinusähnlichkeit (misst den Winkel zwischen Vektoren) oder das Skalarprodukt (misst Betrag und Richtung), die quantifizieren, wie nah zwei Einbettungen beieinanderliegen. Eine Anfrage zu „Automobiltransport“ hätte zum Beispiel eine hohe Kosinusähnlichkeit zu Dokumenten über „Autoreisen“, sodass das System Inhalte auf Basis der Bedeutung statt nur anhand exakter Schlüsselwörter abgleicht. Dieses semantische Verständnis unterscheidet moderne KI-Suche vom einfachen Schlüsselwortabgleich – so verstehen Systeme Nutzerintention und liefern wirklich relevante Ergebnisse.
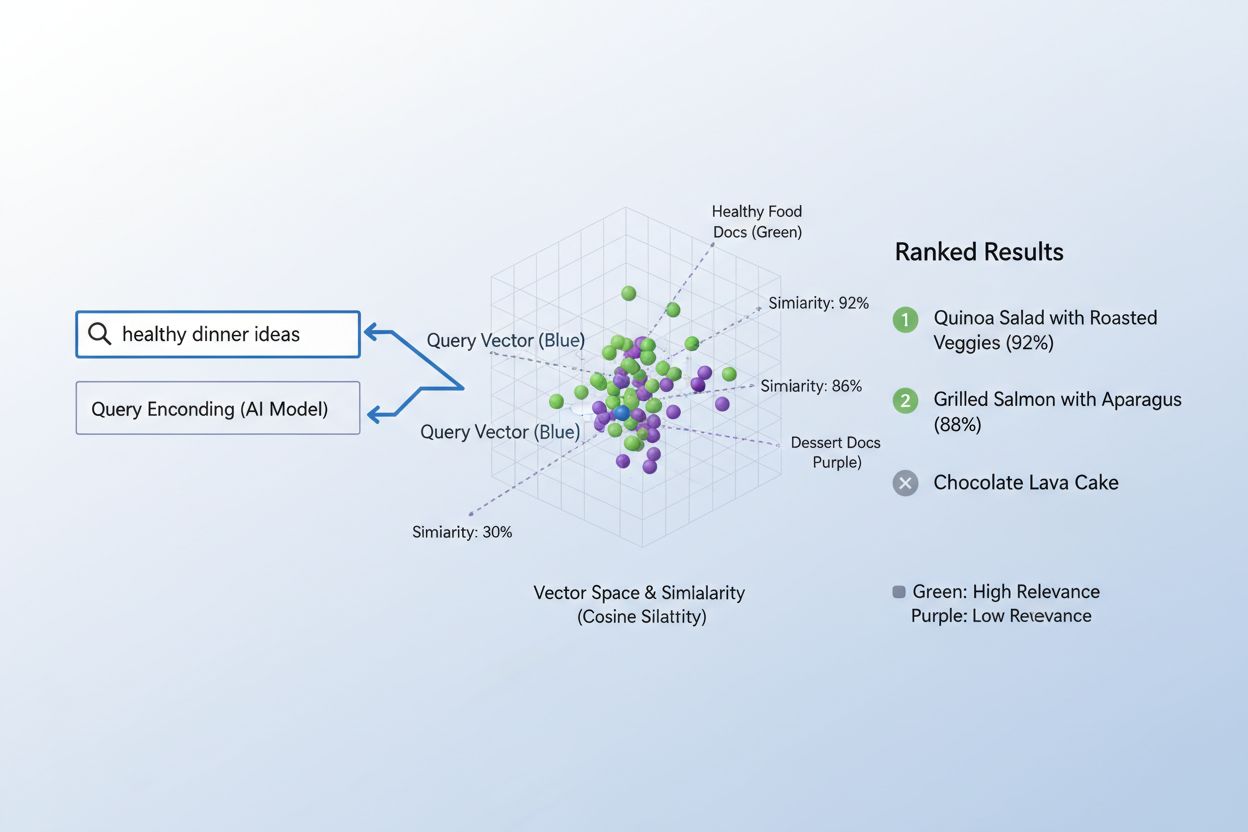
Das Abgleichen von Inhalten mit Anfragen via Einbettungen folgt einem eleganten zweistufigen Workflow, der alles von Suchmaschinen bis zu Empfehlungssystemen antreibt. Zuerst werden sowohl die Nutzeranfrage als auch die verfügbaren Inhalte unabhängig voneinander mit demselben Modell in Einbettungen umgewandelt – eine Anfrage wie „Best Practices für maschinelles Lernen“ wird zu einem Vektor, ebenso jeder Artikel, jedes Dokument oder Produkt in der Systemdatenbank. Anschließend berechnet das System die Ähnlichkeit zwischen der Anfrage-Einbettung und jeder Inhalts-Einbettung, meist mit Kosinusähnlichkeit, was einen Wert liefert, der die Relevanz jedes Inhalts für die Anfrage angibt. Diese Ähnlichkeitswerte werden dann gerankt und die am höchsten bewerteten Inhalte als relevanteste Ergebnisse präsentiert. In einer realen Suchmaschine kodiert das System bei einer Suche nach „wie man neuronale Netze trainiert“ Ihre Anfrage, vergleicht sie mit Millionen von Dokumenteinbettungen und liefert Artikel zu Deep Learning, Modelloptimierung und Trainingsmethoden – ganz ohne exakte Schlüsselwortübereinstimmung. Dieser Abgleichsprozess geschieht in Millisekunden und ist damit für Echtzeitanwendungen mit Millionen Nutzern gleichzeitig praktikabel.
Verschiedene Arten von Einbettungen erfüllen je nach Anwendungsfall unterschiedliche Zwecke. Wort-Einbettungen erfassen die Bedeutung einzelner Wörter und eignen sich für Aufgaben, die feingranulares semantisches Verständnis erfordern. Satz- und Dokumenteinbettungen aggregieren Bedeutung über längere Textspannen hinweg und sind ideal, um ganze Anfragen mit vollständigen Artikeln oder Dokumenten abzugleichen. Bild-Einbettungen stellen visuelle Inhalte numerisch dar, sodass Systeme visuell ähnliche Bilder finden oder Bilder mit Textbeschreibungen abgleichen können. Benutzer- und Produkt-Einbettungen erfassen Verhaltensmuster und Charakteristika und treiben Empfehlungssysteme an, die Vorschläge anhand der Präferenzen der Nutzer machen. Die Wahl der Einbettungsart ist ein Trade-off: Wort-Einbettungen sind recheneffizient, verlieren aber Kontext; Dokumenteinbettungen erhalten die volle Bedeutung, benötigen jedoch mehr Rechenleistung. Domänenspezifische Einbettungen, die auf spezialisierten Datensätzen wie medizinischer Literatur oder juristischen Dokumenten feinabgestimmt sind, übertreffen oft allgemeine Modelle in branchenspezifischen Anwendungen, erfordern aber zusätzliche Trainingsdaten und Rechenressourcen.
In der Praxis ermöglichen Einbettungen einige der wirkungsvollsten KI-Anwendungen unseres Alltags – von den Suchergebnissen, die Sie sehen, bis zu den Ihnen online empfohlenen Produkten. Semantische Suchmaschinen nutzen Einbettungen, um die Intention von Anfragen zu verstehen und relevante Inhalte unabhängig von exakten Schlüsselwortübereinstimmungen zu liefern. Empfehlungssysteme bei Netflix, Amazon und Spotify setzen Benutzer- und Artikel-Einbettungen ein, um vorherzusagen, was Sie als Nächstes sehen, kaufen oder hören möchten. Inhaltsmoderationssysteme identifizieren mit Einbettungen schädliche Inhalte, indem sie Nutzerbeiträge mit Einbettungen bekannter Richtlinienverstöße vergleichen. Frage-Antwort-Systeme finden per semantischer Ähnlichkeit den passenden Wissensdatenbank-Artikel zur Nutzerfrage. Personalisierungs-Engines nutzen Einbettungen, um Nutzerpräferenzen zu verstehen und Erlebnisse individuell anzupassen. Anomalieerkennungssysteme erkennen ungewöhnliche Muster, indem sie feststellen, wann neue Datenpunkte weit von erwarteten Einbettungsclustern entfernt liegen. Bei AmICited nutzen wir Einbettungen, um zu überwachen, wie KI-Systeme im Internet eingesetzt werden, indem wir Nutzeranfragen und Inhalte abgleichen, um zu verfolgen, wo KI-generierte oder KI-unterstützte Inhalte erscheinen – so helfen wir Marken, ihren KI-Fußabdruck zu verstehen und eine korrekte Zuordnung sicherzustellen.
Die effektive Umsetzung von Einbettungen erfordert besondere Aufmerksamkeit für technische Aspekte, die sowohl Leistung als auch Kosten beeinflussen. Die Modellauswahl ist entscheidend: Es gilt, die semantische Qualität der Einbettungen gegen die Rechenanforderungen abzuwägen. Größere Modelle wie BERT liefern reichhaltigere Repräsentationen, benötigen aber mehr Rechenleistung als leichtere Alternativen. Die Dimensionalität ist ein wichtiger Trade-off: Höherdimensionale Einbettungen erfassen mehr Nuancen, verbrauchen aber mehr Speicher und verlangsamen Ähnlichkeitsberechnungen; niedrigdimensionale Einbettungen sind schneller, können aber semantische Informationen verlieren. Um das Matching im großen Maßstab effizient zu gestalten, kommen spezielle Indexierungsstrategien wie FAISS (Facebook AI Similarity Search) oder Annoy (Approximate Nearest Neighbors Oh Yeah) zum Einsatz, die durch die Organisation von Vektoren in Baumstrukturen oder Locality-Sensitive Hashing ähnliche Einbettungen in Millisekunden statt Sekunden finden. Feinabstimmung von Einbettungsmodellen auf domänenspezifische Daten kann die Relevanz für spezialisierte Anwendungen stark verbessern, benötigt jedoch gelabelte Trainingsdaten und zusätzlichen Rechenaufwand. Organisationen müssen ständig Geschwindigkeit und Genauigkeit, Rechenkosten und semantische Qualität sowie allgemeine Modelle gegenüber spezialisierten Alternativen basierend auf ihren spezifischen Anwendungsfällen und Rahmenbedingungen abwägen.
Die Zukunft der Einbettungen bewegt sich hin zu mehr Raffinesse, Effizienz und Integration in umfassendere KI-Systeme – das verspricht noch leistungsfähigere Möglichkeiten zur Inhaltsabstimmung und zum -verständnis. Multimodale Einbettungen, die gleichzeitig Text, Bilder und Audio verarbeiten, entstehen und ermöglichen Systeme, die über unterschiedliche Inhaltstypen hinweg abgleichen – etwa Bilder zu Textanfragen finden oder umgekehrt – und schaffen damit völlig neue Möglichkeiten der Inhaltsentdeckung und des -verständnisses. Forschende entwickeln immer effizientere Einbettungsmodelle, die vergleichbare semantische Qualität mit deutlich weniger Parametern liefern, sodass fortschrittliche KI-Fähigkeiten auch für kleinere Unternehmen und Edge-Geräte zugänglich werden. Die Integration von Einbettungen mit großen Sprachmodellen führt zu Systemen, die nicht nur Inhalte semantisch abgleichen, sondern auch Kontext, Nuancen und Intention in nie dagewesenem Maße verstehen können. Da KI-Systeme immer weiter im Internet verbreitet sind, wird es immer wichtiger, nachverfolgen, überwachen und verstehen zu können, wie Inhalte abgeglichen und genutzt werden – hier setzt AmICited an und nutzt Einbettungen, um Organisationen beim Monitoring ihrer Markenpräsenz, beim Verfolgen von KI-Nutzungsmustern und beim Sicherstellen der korrekten Verwendung und Attribution ihrer Inhalte zu unterstützen. Das Zusammenwirken besserer Einbettungen, effizienterer Modelle und ausgefeilter Überwachungstools schafft eine Zukunft, in der KI-Systeme transparenter, verantwortlicher und stärker an menschlichen Werten ausgerichtet sind.
Eine Vektor-Einbettung ist eine numerische Darstellung von Daten (Text, Bilder, Audio) in einem hochdimensionalen Raum, die semantische Bedeutung und Beziehungen erfasst. Sie wandelt abstrakte Daten in Zahlenarrays um, die Maschinen mathematisch verarbeiten und analysieren können.
Einbettungen wandeln abstrakte Daten in Zahlen um, die Maschinen verarbeiten können, sodass KI Muster, Ähnlichkeiten und Beziehungen zwischen verschiedenen Inhalten erkennen kann. Diese mathematische Darstellung ermöglicht es KI-Systemen, Bedeutung zu erfassen, anstatt nur Schlüsselwörter abzugleichen.
Beim Schlüsselwortabgleich werden exakte Wortübereinstimmungen gesucht, während semantische Ähnlichkeit die Bedeutung versteht. So können Systeme auch verwandte Inhalte finden, selbst wenn keine identischen Wörter vorkommen – zum Beispiel wird 'Automobil' mit 'Auto' aufgrund der semantischen Beziehung und nicht wegen einer exakten Textübereinstimmung abgeglichen.
Ja, Einbettungen können Text, Bilder, Audio, Benutzerprofile, Produkte und mehr darstellen. Unterschiedliche Einbettungsmodelle sind für verschiedene Datentypen optimiert, von Word2Vec für Text bis zu CNNs für Bilder und Spektrogrammen für Audio.
AmICited verwendet Einbettungen, um zu verstehen, wie KI-Systeme Ihre Marke semantisch abgleichen und referenzieren – über verschiedene KI-Plattformen und Antworten hinweg. Dies hilft dabei, die Präsenz Ihrer Inhalte in KI-generierten Antworten zu verfolgen und eine korrekte Zuordnung sicherzustellen.
Wichtige Herausforderungen sind die Wahl des richtigen Modells, das Management der Rechenkosten, der Umgang mit hochdimensionalen Daten, das Finetuning für spezielle Bereiche und das Ausbalancieren von Geschwindigkeit und Genauigkeit bei Ähnlichkeitsberechnungen.
Einbettungen ermöglichen semantische Suche, die die Nutzerabsicht versteht und relevante Ergebnisse auf Basis der Bedeutung statt nur durch Schlüsselwortabgleich liefert. So können Suchsysteme auch inhaltlich verwandte Inhalte finden, die nicht exakt die Suchbegriffe enthalten.
Große Sprachmodelle verwenden Einbettungen intern, um Text zu verstehen und zu generieren. Einbettungen sind grundlegend dafür, wie diese Modelle Informationen verarbeiten, Inhalte abgleichen und kontextuell passende Antworten erzeugen.
Vektor-Einbettungen treiben KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews an. AmICited verfolgt, wie diese Systeme Ihre Inhalte zitieren und referenzieren, damit Sie die Präsenz Ihrer Marke in KI-generierten Antworten verstehen.
Erfahren Sie, was Einbettungen sind, wie sie funktionieren und warum sie für KI-Systeme unerlässlich sind. Entdecken Sie, wie Text in numerische Vektoren umgewa...

Erfahren Sie, wie Embeddings in KI-Suchmaschinen und Sprachmodellen funktionieren. Verstehen Sie Vektordarstellungen, semantische Suche und ihre Rolle bei KI-ge...
Erfahren Sie, wie die Vektorensuche maschinelle Lern-Einbettungen nutzt, um ähnliche Elemente anhand von Bedeutung statt exakter Schlüsselwörter zu finden. Vers...