Verständnis von KI-Zitatmechanismen
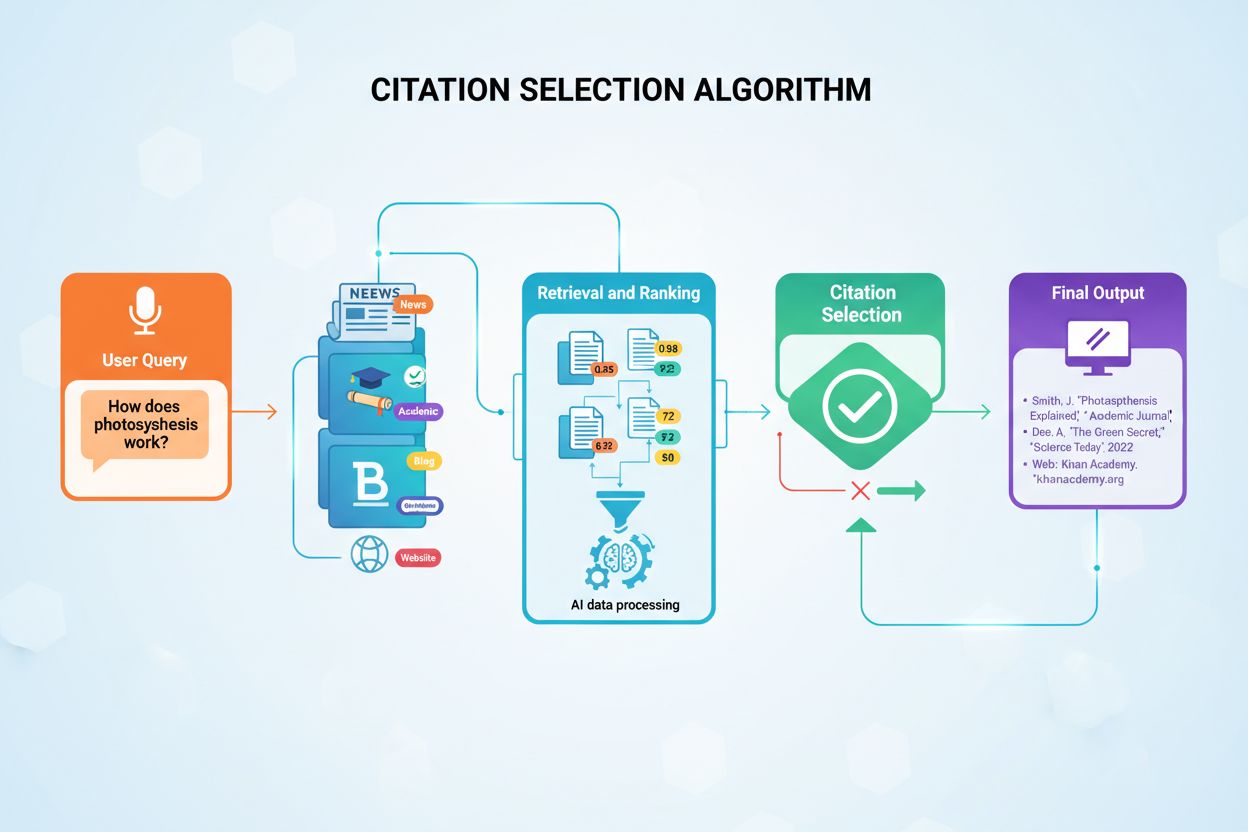
KI-Modelle wählen nicht zufällig Quellen für ihre Antworten aus. Stattdessen nutzen sie ausgefeilte Algorithmen, die in Millisekunden Hunderte von Signalen auswerten, um zu bestimmen, welche Quellen eine Attribution verdienen. Der Prozess, bekannt als Retrieval-Augmented Generation (RAG), unterscheidet sich grundlegend davon, wie klassische Suchmaschinen Inhalte ranken. Während Googles Algorithmus darauf abzielt, Seiten für die Sichtbarkeit in Suchergebnissen zu bewerten, priorisieren KI-Zitieralgorithmen Quellen, die die maßgeblichsten, relevantesten und vertrauenswürdigsten Informationen für spezifische Nutzeranfragen liefern. Diese Unterscheidung bedeutet, dass Sichtbarkeit in KI-generierten Antworten ein völlig anderes Set an Optimierungsprinzipien erfordert als traditionelles SEO.
Die Zitatentscheidung erfolgt über einen mehrstufigen Prozess, der mit der Eingabe einer Nutzeranfrage beginnt. Das KI-System wandelt die Frage in numerische Vektoren, sogenannte Embeddings, um, die die semantische Bedeutung der Anfrage repräsentieren. Diese Embeddings durchsuchen dann indexierte Inhaltsdatenbanken mit Millionen Dokumenten und suchen nach semantisch ähnlichen Inhaltsabschnitten. Das System ruft nicht einfach die ähnlichsten Inhalte ab, sondern wendet gleichzeitig mehrere Bewertungskriterien an, um potenzielle Quellen nach ihrer Zitierfähigkeit zu ranken. Dieser parallele Bewertungsprozess stellt sicher, dass die glaubwürdigsten, relevantesten und am besten strukturierten Quellen an die Spitze des Rankings gelangen.
Die Rolle von Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) bildet die Grundlage dafür, dass KI-Modelle überhaupt externe Quellen zitieren können. Im Gegensatz zu klassischen großen Sprachmodellen, die ausschließlich auf in der Entwicklung kodierten Trainingsdaten basieren, durchsuchen RAG-Systeme zur Laufzeit indexierte Dokumente, um relevante Informationen zu finden, bevor sie Antworten generieren. Dieser architektonische Unterschied erklärt, warum bestimmte Plattformen wie Perplexity und Google AI Overviews konsequent Zitate liefern, während andere wie das Basis-ChatGPT oft Antworten ohne explizite Quellenangabe erzeugen. Das Verständnis von RAG hilft zu erkennen, warum manche Inhalte zitiert werden, während gleichwertige Inhalte für KI unsichtbar bleiben.
Der RAG-Prozess läuft in vier Phasen ab, die bestimmen, welche Quellen letztlich Zitate erhalten. Erstens werden Dokumente in handhabbare Abschnitte von 200–500 Wörtern geteilt, damit KI-Systeme gezielt relevante Informationen extrahieren können, ohne ganze Artikel verarbeiten zu müssen. Zweitens werden diese Abschnitte mithilfe von maschinellen Lernmodellen, die semantische Bedeutung verstehen, in numerische Vektoren (Embeddings) umgewandelt. Drittens sucht das System bei Nutzeranfragen nach semantisch ähnlichen Vektoren per Vektor-Ähnlichkeitsabgleich und identifiziert Inhalte, die die Kernfragen adressieren. Viertens generiert die KI eine Antwort unter Einbezug der abgerufenen Inhalte als Kontext, und die Quellen mit dem größten Beitrag zur Antwort erhalten Zitate. Diese Architektur erklärt, warum Inhaltsstruktur, Klarheit und semantische Ausrichtung auf gängige Anfragen die Zitatwahrscheinlichkeit direkt beeinflussen.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Hauptfaktoren, die KI für die Auswahl von Zitaten nutzt
KI-Zitieralgorithmen bewerten Quellen anhand von fünf Kerndimensionen, die gemeinsam die Zitierwürdigkeit bestimmen. Diese Faktoren ergeben zusammen eine umfassende Bewertung der Quellenqualität; jede Dimension trägt zur Gesamtzitatbewertung bei.
| Zitierfaktor | Einflussniveau | Schlüsselsignale |
|---|
| Domain-Autorität | Sehr hoch (25–30%) | Backlink-Profil, Domainalter, Knowledge-Graph-Präsenz, Wikipedia-Nennungen |
| Inhaltsaktualität | Hoch (20–25%) | Veröffentlichungsdatum, Update-Frequenz, Aktualität von Statistiken und Daten |
| Semantische Relevanz | Hoch (20–25%) | Übereinstimmung Anfrage/Inhalt, Themenspezifität, direkte Antwortpräsenz |
| Informationsstruktur | Mittel-hoch (15–20%) | Überschriftenhierarchie, scannbares Format, Schema-Markup-Implementierung |
| Faktendichte | Mittel (10–15%) | Konkrete Datenpunkte, Statistiken, Expertenzitate, Zitatketten |
Autorität ist der am stärksten gewichtete Faktor bei KI-Zitatentscheidungen. Untersuchungen von 150.000 KI-Zitaten zeigen, dass Reddit und Wikipedia zusammen 40,1 % bzw. 26,3 % aller LLM-Zitate ausmachen – ein Beleg dafür, wie maßgeblich etablierte Autorität die Auswahl beeinflusst. KI-Systeme bewerten Autorität durch diverse Vertrauenssignale, darunter Domainalter, Qualität des Backlink-Profils, Präsenz in Knowledge Graphs und externe Validierung. Websites mit Domain-Autoritätswerten über 60 erzielen konsistent höhere Zitatquoten bei ChatGPT, Perplexity und Gemini. Autorität beschränkt sich aber nicht nur auf Domain-Metriken; auch Autoren-Credibility spielt eine Rolle: Inhalte mit namentlich genannten Experten und überprüfbaren Qualifikationen werden bevorzugt gegenüber anonymen Beiträgen behandelt.
Aktualität fungiert als kritischer Zeitfilter, der bestimmt, ob Inhalte überhaupt noch für eine Zitation infrage kommen. Inhalte, die innerhalb von 48–72 Stunden veröffentlicht oder aktualisiert wurden, werden bevorzugt gerankt, während Content-Decay sofort einsetzt und die Sichtbarkeit ohne Updates nach 2–3 Tagen messbar abnimmt. Diese Aktualitätspräferenz spiegelt das Engagement der KI-Plattformen für aktuelle Informationen wider – insbesondere bei sich schnell entwickelnden Themen, bei denen veraltete Angaben Nutzer in die Irre führen könnten. Dennoch kann Evergreen-Content mit aktuellen Updates neue, aber weniger fundierte Inhalte übertreffen. Dies zeigt, dass die Kombination aus Basisqualität und zeitlicher Frische wichtiger ist als jeder Faktor allein. Unternehmen, die ihre Inhalte quartalsweise oder jährlich aktualisieren, erzielen höhere Zitatquoten als solche, die einmal veröffentlichen und dann nicht mehr pflegen.
Relevanz misst die semantische Passung zwischen Nutzeranfragen und Dokumenteninhalt. Quellen, die die Kernfrage direkt und ohne viel Abschweifung beantworten, schneiden besser ab als umfassende, aber weniger fokussierte Ressourcen. KI-Systeme bewerten Relevanz durch Embedding-Ähnlichkeit, indem sie die numerische Repräsentation der Anfrage mit der von Dokumentabschnitten vergleichen. Das bedeutet, dass in natürlicher, gesprächsnaher Sprache verfasste Inhalte, die typische Suchanfragen widerspiegeln, besser abschneiden als Keyword-optimierte Texte für klassische Suchmaschinen. FAQ-artige Inhalte und Frage-Antwort-Paare sind besonders gut auf die Arbeitsweise von KI-Systemen abgestimmt und daher besonders zitierwürdig.
Struktur umfasst sowohl Informationsarchitektur als auch technische Umsetzung. Klare hierarchische Organisation mit beschreibenden Überschriften, logischem Aufbau und scannbarem Format hilft KI-Systemen, Inhaltsgrenzen zu erkennen und relevante Informationen zu extrahieren. Strukturierte Daten mit Schema-Markup wie FAQ-, Artikel- und Organisationsschema erhöhen die Zitatwahrscheinlichkeit um bis zu 10 %. Inhalte mit prägnanten Zusammenfassungen, Aufzählungslisten, Vergleichstabellen und Frage-Antwort-Paaren werden bevorzugt gegenüber dichten Absätzen mit versteckten Erkenntnissen behandelt. Diese Strukturpräferenz spiegelt das Training der KI-Systeme auf gut organisierte Informationen wider, die vollständige, kontextuelle Antworten liefern.
Faktendichte bezieht sich auf die Konzentration spezifischer, überprüfbarer Informationen im Inhalt. Quellen mit konkreten Datenpunkten, Statistiken, Datumsangaben und Beispielen übertreffen rein konzeptionelle Inhalte. Noch wichtiger: Quellen, die selbst autoritative Referenzen zitieren, schaffen Vertrauenskaskaden – KI-Systeme übernehmen das Vertrauen aus den zitierten Quellen. Inhalte mit belegenden Nachweisen und Verlinkungen zu Primärquellen erzielen höhere Zitatquoten als unbelegte Behauptungen. Diese Faktendichte-Anforderung bedeutet, dass jede wesentliche Aussage mit einer Quelle samt Veröffentlichungsdatum und Expertennachweis belegt sein sollte.
Verschiedene KI-Plattformen setzen unterschiedliche Zitatstrategien um, die ihre Architektur und Philosophie widerspiegeln. Das Verständnis dieser plattformspezifischen Präferenzen hilft Content-Erstellern, für mehrere KI-Systeme gleichzeitig zu optimieren.
ChatGPT-Zitatmuster zeigen eine starke Vorliebe für enzyklopädische und autoritative Quellen. Wikipedia taucht in etwa 35 % der ChatGPT-Zitate auf, was die Abhängigkeit des Modells von etablierten, gemeinschaftlich überprüften Informationen belegt. Die Plattform meidet nutzergenerierte Foreninhalte, es sei denn, die Anfrage verlangt explizit Community-Meinungen, und bevorzugt Quellen mit klaren Attributionen und nachprüfbaren Fakten gegenüber Meinungsinhalten. Dieser konservative Ansatz spiegelt das Training von ChatGPT mit hochwertigen Quellen wider und die Philosophie, Genauigkeit über Vollständigkeit zu stellen. Wer ChatGPT-Zitate erzielen möchte, sollte eine Präsenz in Knowledge Graphs aufbauen, Wikipedia-Einträge anlegen und Inhalte mit enzyklopädischer Tiefe und Neutralität erstellen.
Google-KI-Systeme wie Gemini und AI Overviews nutzen vielfältigere Quelltypen, was die breitere Indexierungsphilosophie von Google widerspiegelt. Reddit-Beiträge machen etwa 5 % der AI-Overviews-Zitate aus; zudem werden Inhalte bevorzugt, die in den organischen Suchergebnissen oben erscheinen – ein Synergieeffekt zwischen klassischem SEO und KI-Zitatquoten. Googles KI-Systeme zitieren häufiger neuere Quellen und nutzergenerierte Inhalte als ChatGPT, vorausgesetzt, sie weisen Relevanz und Autorität auf. Das bedeutet, dass starke traditionelle SEO-Leistung mit KI-Zitaterfolg auf Googles Plattformen korreliert, auch wenn die Korrelation nicht perfekt ist.
Perplexity-KI-Präferenzen legen Wert auf Transparenz und direkte Quellenangabe. Die Plattform gibt typischerweise 3–5 Quellen pro Antwort mit direkten Links an, bevorzugt branchenspezifische Bewertungsseiten, Expertenpublikationen und datenbasierte Inhalte. Domain-Autorität spielt eine große Rolle – etablierte Publikationen werden bevorzugt, während Community-Inhalte nur in etwa 1 % der Zitate erscheinen, meist bei Produktempfehlungen. Die Designphilosophie von Perplexity will Nutzern ermöglichen, Informationen direkt zu überprüfen, was die Plattform besonders wertvoll für das Tracking der Markenwahrnehmung macht. Unternehmen, die für Perplexity optimieren wollen, sollten datenreiche Inhalte, branchenspezifische Ressourcen und von Experten verfasste Beiträge mit klarer Autorität erstellen.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Domain-Autorität und Vertrauenssignale
Domain-Autorität dient in KI-Algorithmen als Vertrauensindikator und signalisiert, dass eine Quelle über längere Zeit Glaubwürdigkeit aufgebaut hat. Systeme bewerten Autorität über mehrere Vertrauenssignale, die etwa 5 % der gesamten Zitatwahrscheinlichkeit ausmachen – bei YMYL-Themen (Your Money, Your Life: Gesundheit, Finanzen, Sicherheit) steigt dieser Anteil deutlich. Wichtige Autoritätsindikatoren sind Domainalter, SSL-Zertifikate, Datenschutzrichtlinien und Compliance-Merkmale wie SOC 2 oder DSGVO-Zertifizierung. Diese technischen Signale verstärken sich in Kombination mit Inhaltsqualitätsmetriken, sodass technisch solide Seiten mit exzellenten Inhalten technisch schwache Seiten immer übertreffen – unabhängig von der Inhaltsqualität.
Backlink-Profile beeinflussen die Quellwahrnehmung in KI-Algorithmen erheblich. KI-Modelle bewerten die Autorität verlinkender Domains, die Relevanz des Linkkontexts und die Vielfalt des Backlink-Portfolios. Untersuchungen zeigen, dass zehn Backlinks aus großen Publikationen mehr bewirken als 100 von Seiten mit geringer Autorität – die Qualität der Links zählt deutlich mehr als die reine Anzahl. Experten-Attribution erhöht die Zitatwahrscheinlichkeit deutlich: Inhalte mit namentlich genannten Autoren und überprüfbaren Qualifikationen schneiden erheblich besser ab als anonyme Beiträge. Author-Schema-Markup und ausführliche Biografien helfen KI-Systemen, Expertise zu validieren, während externe Erwähnungen in Branchenpublikationen die Glaubwürdigkeit zusätzlich stärken. Unternehmen sollten auf Backlinks von hochautoritativen Quellen, Autoren-Credibility und Erwähnungen in Branchenpublikationen setzen.
Wikipedia- und Knowledge-Graph-Präsenz steigern Zitatquoten dramatisch – unabhängig von anderen Faktoren. Quellen, die in Wikipedia referenziert werden, genießen große Vorteile, weil Knowledge Graphs als maßgebliche Quellen dienen, auf die KI-Modelle wiederholt bei diversen Anfragen zugreifen. Google Knowledge Panel-Informationen fließen direkt in das Verständnis von Entitätsbeziehungen und Autorität ein. Unternehmen ohne Wikipedia-Präsenz haben Schwierigkeiten, trotz hochwertiger Inhalte konsistente Zitate zu erzielen – Knowledge-Graph-Entwicklung sollte deshalb für KI-Sichtbarkeit Priorität haben. So entsteht eine Vertrauensbasis, auf die Sprachmodelle bei der Recherche regelmäßig zurückgreifen.
Inhaltsmerkmale, die Zitate fördern
Gesprächsnahe Anfrageausrichtung markiert einen fundamentalen Wandel im Vergleich zur klassischen SEO-Optimierung. Inhalte, die als Frage-Antwort-Paare strukturiert sind, schneiden in Retrieval-Algorithmen besser ab als Keyword-optimierte Inhalte. FAQ-Seiten und Inhalte, die natürliche Suchanfragen spiegeln, werden bevorzugt, weil KI-Systeme auf Gesprächsdaten trainiert sind und natürliche Sprachmuster besser verstehen als reine Keyword-Ketten. Das bedeutet: Inhalte, die wie Antworten auf die Frage eines Freundes wirken, übertreffen Texte, die für Suchmaschinen geschrieben wurden. Unternehmen sollten ihre Inhalte auf gesprächsnahen Ton, direkte Antworten auf häufige Fragen und natürliche Sprachmuster überprüfen.
Zitatqualität innerhalb von Inhalten schafft Vertrauenskaskaden, die über einzelne Quellen hinausreichen. KI-Systeme bewerten, ob Aussagen mit Daten und Belegen untermauert werden. Inhalte, die autoritative Referenzen zitieren, übernehmen deren Glaubwürdigkeit – ein Multiplikatoreffekt. Quellen mit Belegen und Verlinkungen zu Primärquellen erzielen höhere Zitatquoten als unbelegte Behauptungen. Das bedeutet: Jede wesentliche Aussage sollte mit einer Quelle samt Veröffentlichungsdatum und Expertennachweis belegt sein. Unternehmen sollten für zitierwürdige Inhalte 5–8 seriöse Quellen recherchieren und nennen, 2–3 Expertenzitate mit vollständigen Qualifikationen einbauen sowie 3–5 aktuelle Statistiken mit Veröffentlichungsdatum ergänzen.
Konsistenz über Plattformen hinweg beeinflusst, wie KI-Systeme die Glaubwürdigkeit einer Quelle bewerten. Findet die KI konsistente Informationen über mehrere Quellen hinweg, steigt das Vertrauen für Zitate aus diesem Cluster. Quellen, die dem allgemeinen Konsens widersprechen, werden nur dann priorisiert, wenn sie überzeugende Gegenbelege liefern. Diese Konsistenzpräferenz bedeutet, dass kohärente Narrative über eigene, verdiente und geteilte Kanäle hinweg die Zitierbarkeit einzelner Quellen stärken. Unternehmen, die KI-Reputationsmanagement betreiben, müssen konsistente Botschaften über alle digitalen Kanäle sicherstellen – von Corporate Websites über Social Media bis zu Branchenpublikationen und Drittplattformen.
Optimierungsstrategien für KI-Zitate
Update-Frequenz-Strategie ist im KI-Zeitalter wichtiger als im klassischen SEO. Die Veröffentlichungsfrequenz beeinflusst die Zitatquote direkt – KI-Plattformen bevorzugen jüngst aktualisierte Inhalte. Unternehmen sollten bestehende Inhalte alle 48–72 Stunden aktualisieren, um Aktualitätssignale aufrechtzuerhalten; es sind aber keine vollständigen Überarbeitungen nötig. Neue Datenpunkte, aktualisierte Statistiken oder Erweiterungen mit aktuellen Entwicklungen reichen aus, um die Zitierfähigkeit zu erhalten. Content-Management-Systeme, die Update-Frequenz und Frische tracken, helfen, auch bei zunehmend gewichteter Aktualität wettbewerbsfähig zu bleiben. Dieser kontinuierliche Ansatz unterscheidet sich fundamental vom klassischen SEO, bei dem Inhalte oft jahrelang ohne Änderungen ranken konnten.
Strategische Platzierung auf Aggregator-Seiten eröffnet KI-Systemen mehrere Entdeckungspfade. Wer in Branchenübersichten, Expertenlisten oder Bewertungsportalen gelistet wird, schafft zusätzliche Gelegenheiten, von KI-Systemen entdeckt zu werden. Eine einzelne Erwähnung in einer häufig zitierten Publikation eröffnet zahlreiche neue Wege zur eigenen Website. Medienarbeit und Content-Partnerschaften gewinnen für KI-Sichtbarkeit an Wert, ebenso die gezielte Präsenz in branchenspezifischen Datenbanken und Verzeichnissen. Unternehmen sollten daher Branchenübersichten, Expertenlisten und Bewertungsseiten gezielt für ihre KI-Strategie ansteuern.
Strukturierte Daten-Implementierung erhöht die Zitatwahrscheinlichkeit, indem sie Inhalte maschinenlesbar macht. Schema-Markup in KI-lesbaren Formaten hilft Plattformen, spezifische Fakten ohne Auswertung unstrukturierter Texte zu extrahieren. FAQ-Schema, Artikel-Schema mit Autorenangabe und Organisationsschema bieten maschinenlesbare Signale, die von Retrieval-Algorithmen priorisiert werden. JSON-LD-Strukturierte Daten ermöglichen eine effiziente Extraktion und verbessern sowohl die Zitatwahrscheinlichkeit als auch die Genauigkeit der zitierten Informationen. Unternehmen mit umfassendem Schema-Markup erzielen messbar höhere Zitatquoten bei mehreren KI-Plattformen.
Wikipedia- und Knowledge-Graph-Entwicklung zahlt sich trotz des erforderlichen Aufwands langfristig aus. Der Aufbau einer Wikipedia-Präsenz erfordert neutrale, gut belegte Beiträge, die Wikipedias redaktionelle Standards erfüllen. Parallel dazu sollten Wikidata-, Google-Knowledge-Panel- und branchenspezifische Profiloptimierungen erfolgen, um die Vertrauensbasis zu schaffen, auf die KI-Systeme regelmäßig zurückgreifen. Diese Knowledge-Graph-Einträge dienen als maßgebliche Quellen, die Modelle bei diversen Anfragen konsultieren – Knowledge-Graph-Entwicklung ist somit strategische Pflicht für Unternehmen mit KI-Sichtbarkeitsambitionen.
Erfolgsmessung bei KI-Zitaten
Unternehmen sollten die Zitatfrequenz regelmäßig durch manuelle Tests relevanter Anfragen bei ChatGPT, Google AI Overviews, Perplexity und anderen Plattformen überprüfen. Regelmäßiges Prompt-Testing zeigt, welche Inhalte erfolgreich zitiert werden und wo noch Lücken bei der KI-Repräsentation bestehen. Diese Testmethodik bietet direkte Sichtbarkeit der Zitatperformance und zeigt Optimierungspotenziale auf. KI-Zitieralgorithmen verändern sich laufend mit wachsendem Trainingsdatensatz und weiterentwickelten Retrieval-Strategien; Content-Strategien müssen daher auf Basis von Performance-Daten angepasst werden. Wenn Inhalte trotz früherer Zitate plötzlich nicht mehr erscheinen, sollte man sie mit aktuellen Informationen aktualisieren oder semantisch besser ausrichten.
Mehrere Quellen können für eine einzelne Anfrage zitiert werden – das eröffnet Co-Zitationsmöglichkeiten statt Nullsummen-Konkurrenz. Unternehmen profitieren davon, umfassende Inhalte zu erstellen, die bestehende vielzitierte Quellen ergänzen statt duplizieren. Wettbewerbsanalysen zeigen, welche Marken in bestimmten Kategorien die KI-Sichtbarkeit dominieren und helfen, Lücken und Chancen zu erkennen. Die Überwachung der Zitatentwicklung im Zeitverlauf zeigt Trends und identifiziert URLs, die den Erfolg treiben – so können Unternehmen erfolgreiche Strategien replizieren und skalieren.