Content Pruning
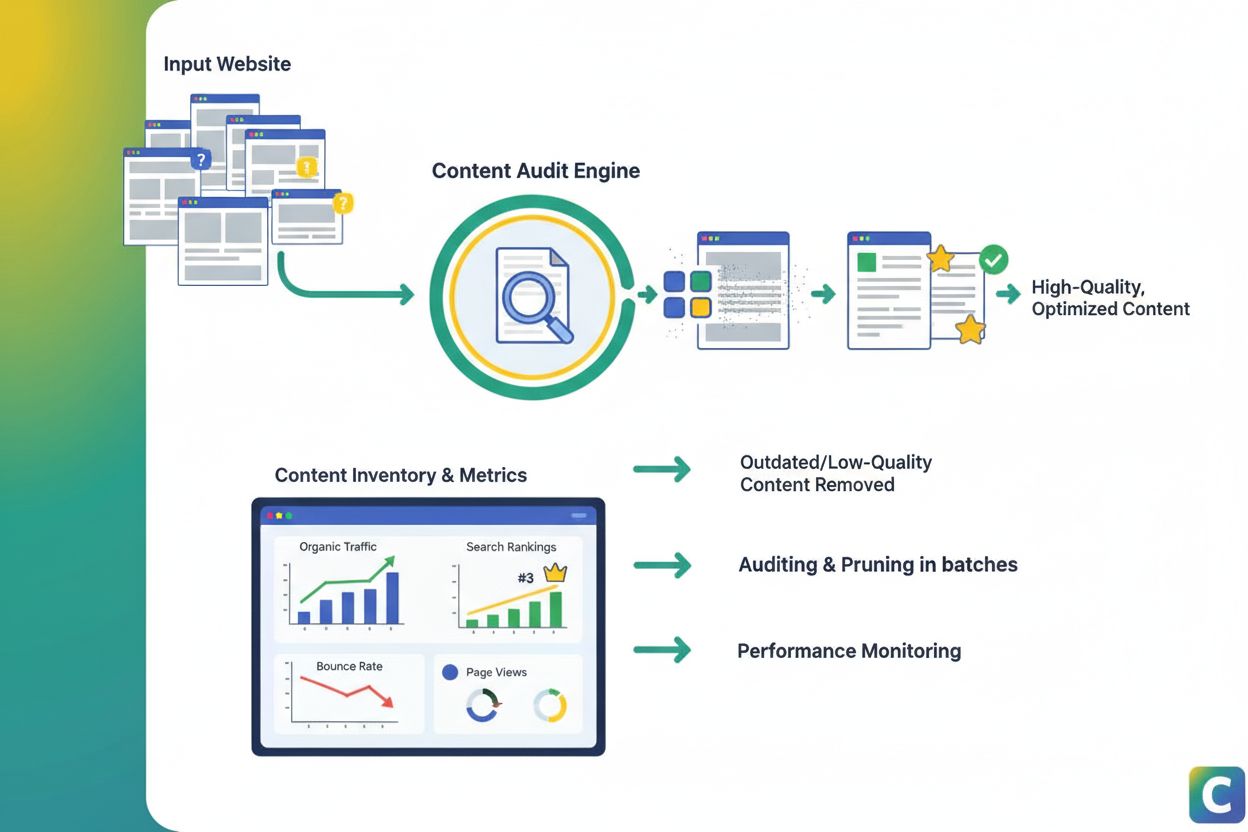
Content Pruning ist das strategische Entfernen oder Aktualisieren von leistungsschwachen Inhalten, um SEO, Nutzererlebnis und Sichtbarkeit zu verbessern. Erfahr...
14 Min. Lesezeit

Erfahren Sie, was Content Pruning für KI ist, wie es funktioniert, welche verschiedenen Pruning-Methoden es gibt und warum es für die Bereitstellung effizienter KI-Modelle auf Edge-Geräten und in ressourcenbeschränkten Umgebungen unerlässlich ist.
Content Pruning für KI ist eine Technik, bei der gezielt redundante oder weniger wichtige Parameter, Gewichte oder Tokens aus KI-Modellen entfernt werden, um deren Größe zu verringern, die Inferenzgeschwindigkeit zu erhöhen und den Speicherverbrauch zu senken, während die Leistungsqualität erhalten bleibt.
Content Pruning für KI ist eine grundlegende Optimierungstechnik, die eingesetzt wird, um die Rechenkomplexität und den Speicherbedarf von künstlichen Intelligenzmodellen zu reduzieren, ohne die Leistungsfähigkeit signifikant zu beeinträchtigen. Dieser Prozess beinhaltet das systematische Identifizieren und Entfernen von redundanten oder weniger wichtigen Komponenten aus neuronalen Netzen, einschließlich einzelner Gewichte, ganzer Neuronen, Filter oder sogar Tokens in Sprachmodellen. Das Hauptziel ist es, schlankere, schnellere und effizientere Modelle zu schaffen, die effektiv auf ressourcenbeschränkten Geräten wie Smartphones, Edge-Computing-Systemen und IoT-Geräten eingesetzt werden können.
Das Konzept des Prunings ist von biologischen Systemen inspiriert, insbesondere vom synaptischen Pruning im menschlichen Gehirn, bei dem während der Entwicklung überflüssige neuronale Verbindungen entfernt werden. Auch bei KI-Modellen erkennt man, dass trainierte neuronale Netze oft viele Parameter enthalten, die nur minimal zum Endergebnis beitragen. Durch das Entfernen dieser überflüssigen Komponenten können Entwickler die Modellgröße erheblich reduzieren, während durch sorgfältiges Fine-Tuning die Genauigkeit erhalten oder sogar verbessert werden kann.
Content Pruning basiert auf dem Prinzip, dass nicht alle Parameter in einem neuronalen Netz gleich wichtig für die Vorhersage sind. Während des Trainings entwickeln neuronale Netze komplexe Verbindungen, von denen viele redundant werden oder nur einen vernachlässigbaren Beitrag zur Entscheidungsfindung leisten. Pruning identifiziert diese weniger kritischen Komponenten und entfernt sie, was zu einer sparsamen Netzwerkarchitektur führt, die weniger Rechenressourcen benötigt.
Die Wirksamkeit des Prunings hängt von mehreren Faktoren ab, darunter die verwendete Pruning-Methode, der Grad der Aggressivität der Strategie und das anschließende Fine-Tuning. Verschiedene Ansätze zielen auf unterschiedliche Aspekte neuronaler Netze ab. Einige Methoden konzentrieren sich auf einzelne Gewichte (unstrukturiertes Pruning), während andere ganze Neuronen, Filter oder Kanäle entfernen (strukturiertes Pruning). Die Wahl der Methode beeinflusst sowohl die Effizienz des resultierenden Modells als auch die Kompatibilität mit moderner Hardware.
| Pruning-Typ | Ziel | Vorteile | Herausforderungen |
|---|---|---|---|
| Gewichts-Pruning | Einzelne Verbindungen/Gewichte | Maximale Komprimierung, spärliche Netze | Beschleunigt Hardwareausführung ggf. nicht |
| Strukturiertes Pruning | Neuronen, Filter, Kanäle | Hardwarefreundlich, schnellere Inferenz | Weniger Komprimierung als unstrukturiert |
| Dynamisches Pruning | Kontextabhängige Parameter | Adaptive Effizienz, Echtzeitanpassung | Komplexe Implementierung, höherer Overhead |
| Layer-Pruning | Ganze Schichten oder Blöcke | Deutliche Größenreduktion | Risiko von Genauigkeitsverlust, erfordert sorgfältige Validierung |
Unstrukturiertes Pruning, auch als Gewichts-Pruning bekannt, arbeitet auf granularer Ebene, indem einzelne Gewichte aus den Gewichtsmatrizen des Netzwerks entfernt werden. Dabei werden meist Werte-basierten Kriterien verwendet, wobei Gewichte nahe Null als weniger wichtig betrachtet und eliminiert werden. Das resultierende Netzwerk wird spärlich, wobei nur ein Bruchteil der ursprünglichen Verbindungen während der Inferenz aktiv bleibt. Unstrukturiertes Pruning kann beeindruckende Komprimierungsraten erreichen – manchmal werden über 90 % der Parameter entfernt – aber die resultierenden spärlichen Netze führen nicht immer zu proportionalen Geschwindigkeitssteigerungen auf Standardhardware ohne spezielle Unterstützung für spärliche Berechnungen.
Strukturiertes Pruning verfolgt einen anderen Ansatz, indem ganze Gruppen von Parametern gleichzeitig entfernt werden, wie vollständige Filter in Faltungs-Schichten, ganze Neuronen in voll verbundenen Schichten oder gesamte Kanäle. Diese Methode ist besonders wertvoll für den praktischen Einsatz, da die resultierenden Modelle von Natur aus mit moderner Hardware wie GPUs und TPUs kompatibel sind. Wenn komplette Filter aus Faltungsschichten entfernt werden, sind die Einsparungen sofort spürbar, ohne dass spezielle Operationen für spärliche Matrizen benötigt werden. Studien haben gezeigt, dass strukturiertes Pruning die Modellgröße um 50–90 % verringern kann, während die Genauigkeit mit der des Originals vergleichbar bleibt.
Dynamisches Pruning ist ein ausgefeilterer Ansatz, bei dem der Pruning-Prozess während der Inferenz des Modells anhand des jeweils verarbeiteten Inputs angepasst wird. Diese Technik nutzt externen Kontext wie Sprecher-Embeddings, Ereignis-Hinweise oder sprachspezifische Informationen, um dynamisch zu steuern, welche Parameter aktiv sind. In Retrieval-augmented Generation-Systemen kann dynamisches Pruning die Kontextgröße um ca. 80 % reduzieren und gleichzeitig die Antwortgenauigkeit verbessern, indem irrelevante Informationen ausgefiltert werden. Dieser adaptive Ansatz ist besonders für multimodale KI-Systeme wertvoll, die verschiedenartige Eingaben effizient verarbeiten müssen.
Iteratives Pruning und Fine-Tuning zählt zu den am weitesten verbreiteten Ansätzen in der Praxis. Bei dieser Methode wird ein zyklischer Prozess angewandt: Ein Teil des Netzwerks wird gepruned, die verbleibenden Parameter werden feinjustiert, um verlorene Genauigkeit wiederherzustellen, die Leistung wird bewertet und der Prozess wiederholt. Die iterative Natur ermöglicht es Entwicklern, Modellkomprimierung und Leistungserhalt sorgfältig auszubalancieren. Statt alle überflüssigen Parameter auf einmal zu entfernen – was die Leistung des Modells stark beeinträchtigen könnte – wird die Komplexität des Netzwerks schrittweise reduziert, sodass das Modell sich anpassen und lernen kann, welche verbleibenden Parameter am wichtigsten sind.
One-Shot-Pruning ist eine schnellere Alternative, bei der die gesamte Pruning-Operation in einem Schritt nach dem Training erfolgt, gefolgt von einer Fine-Tuning-Phase. Dieser Ansatz ist recheneffizienter als iterative Methoden, birgt aber ein höheres Risiko eines Genauigkeitsverlustes, wenn zu viele Parameter auf einmal entfernt werden. One-Shot-Pruning eignet sich besonders, wenn für iterative Prozesse nur begrenzte Ressourcen zur Verfügung stehen, erfordert aber in der Regel ein umfangreicheres Fine-Tuning, um die Leistung wiederherzustellen.
Sensitivitätsanalyse-basiertes Pruning nutzt einen ausgefeilteren Bewertungsmechanismus, indem gemessen wird, wie stark die Verlustfunktion des Modells steigt, wenn bestimmte Gewichte oder Neuronen entfernt werden. Parameter mit minimalem Einfluss auf die Verlustfunktion werden als sichere Kandidaten für das Pruning identifiziert. Dieser datengesteuerte Ansatz ermöglicht differenziertere Pruning-Entscheidungen als rein wertbasierte Methoden und führt häufig zu einer besseren Genauigkeitserhaltung bei gleichem Komprimierungsgrad.
Die Lottery-Ticket-Hypothese präsentiert einen interessanten theoretischen Rahmen, nach dem sich in großen neuronalen Netzen ein kleineres, sparsames Subnetz – das „Winning Ticket“ – verbirgt, das bei gleicher Initialisierung eine vergleichbare Genauigkeit wie das Originalnetz erreichen kann. Diese Hypothese hat das Verständnis von Redundanz in Netzen vertieft und neue Pruning-Methoden inspiriert, die versuchen, diese effizienten Subnetze zu identifizieren und zu isolieren.
Content Pruning ist aus zahlreichen KI-Anwendungen, bei denen Recheneffizienz entscheidend ist, nicht mehr wegzudenken. Der Einsatz auf mobilen und eingebetteten Geräten ist einer der wichtigsten Anwendungsfälle, da geprunete Modelle fortschrittliche KI-Funktionen auf Smartphones und IoT-Geräten mit begrenzter Rechenleistung und Akkukapazität ermöglichen. Bilderkennung, Sprachassistenten und Echtzeitübersetzungen profitieren alle von gepruneten Modellen, die die Genauigkeit erhalten und gleichzeitig minimale Ressourcen verbrauchen.
Autonome Systeme wie selbstfahrende Fahrzeuge und Drohnen benötigen Echtzeit-Entscheidungen mit minimaler Latenz. Geprunete neuronale Netze erlauben es diesen Systemen, Sensordaten zu verarbeiten und kritische Entscheidungen unter strikten Zeitvorgaben zu treffen. Der geringere Rechenaufwand führt direkt zu schnelleren Reaktionszeiten – ein Muss für sicherheitskritische Anwendungen.
In Cloud- und Edge-Computing-Umgebungen reduziert Pruning sowohl die Rechenkosten als auch den Speicherbedarf für den Einsatz großer Modelle. Unternehmen können mehr Nutzer mit der gleichen Infrastruktur bedienen oder ihre Rechenkosten erheblich senken. Besonders Edge-Computing profitiert, da geprunete Modelle anspruchsvolle KI-Verarbeitung auf Geräten außerhalb zentraler Rechenzentren ermöglichen.
Die Bewertung der Effektivität von Pruning erfordert die Berücksichtigung mehrerer Kennzahlen über die reine Reduktion der Parameteranzahl hinaus. Inferenzlatenz – die Zeit, die ein Modell benötigt, um aus einer Eingabe ein Ergebnis zu generieren – ist eine entscheidende Kennzahl, die das Nutzererlebnis bei Echtzeitanwendungen direkt beeinflusst. Effektives Pruning sollte die Inferenzlatenz deutlich verringern und so schnellere Reaktionen ermöglichen.
Modellgenauigkeit und F1-Scores müssen während des Pruning-Prozesses erhalten bleiben. Die grundlegende Herausforderung besteht darin, eine hohe Komprimierung ohne Einbußen bei der Vorhersageleistung zu erreichen. Gut konzipierte Pruning-Strategien halten die Genauigkeit innerhalb von 1–5 % des Ursprungsmodells, während die Parameteranzahl um 50–90 % reduziert wird. Die Reduzierung des Speicherbedarfs ist ebenso wichtig, da sie bestimmt, ob Modelle auf ressourcenbeschränkten Geräten eingesetzt werden können.
Studien, die große, spärliche Modelle (große Netze mit vielen entfernten Parametern) mit kleinen, dichten Modellen (kleine Netze, von Grund auf trainiert) mit identischem Speicherbedarf vergleichen, zeigen durchweg, dass große, spärliche Modelle ihren kleinen, dichten Pendants überlegen sind. Das unterstreicht den Wert, mit großen, gut trainierten Netzen zu beginnen und diese gezielt zu prunen, anstatt von Anfang an kleine Netze zu trainieren.
Genauigkeitsverluste sind nach wie vor die größte Herausforderung beim Content Pruning. Aggressives Pruning kann die Modellleistung erheblich beeinträchtigen und erfordert eine sorgfältige Abstimmung der Intensität. Entwickler müssen den optimalen Punkt finden, an dem die Komprimierung maximal ist, ohne dass die Genauigkeit unvertretbar leidet. Dieser Punkt variiert je nach Anwendung, Modellarchitektur und akzeptierten Leistungsgrenzen.
Hardware-Kompatibilitätsprobleme können die praktischen Vorteile des Prunings einschränken. Während unstrukturiertes Pruning spärliche Netze mit weniger Parametern schafft, ist moderne Hardware auf dichte Matrixoperationen optimiert. Spärliche Netze laufen auf Standard-GPUs ohne spezielle Bibliotheken für spärliche Berechnungen oft nicht schneller. Strukturiertes Pruning umgeht diese Einschränkung, da dichte Berechnungsmuster erhalten bleiben – allerdings auf Kosten einer weniger aggressiven Komprimierung.
Der Rechenaufwand der Pruning-Methoden selbst kann erheblich sein. Iteratives Pruning und sensitivitätsbasierte Ansätze erfordern mehrere Trainingsdurchläufe und sorgfältige Bewertung, was viele Ressourcen verbraucht. Entwickler müssen die einmaligen Kosten des Prunings gegen die laufenden Einsparungen durch effizientere Modelle abwägen.
Generaliserungsprobleme treten auf, wenn zu aggressiv gepruned wird. Zu stark geprunete Modelle können auf Trainings- und Validierungsdaten gut abschneiden, aber auf neuen, unbekannten Daten schlecht generalisieren. Ausgedehnte Validierung und sorgfältige Tests auf vielfältigen Datensätzen sind unerlässlich, um die robuste Leistung gepruneter Modelle im Produktionseinsatz sicherzustellen.
Erfolgreiches Content Pruning erfordert ein systematisches Vorgehen, das auf bewährten Praktiken aus Forschung und Anwendung basiert. Starten Sie mit größeren, gut trainierten Netzen statt zu versuchen, kleine Netze von Grund auf zu trainieren. Größere Netze bieten mehr Redundanz und Flexibilität für das Pruning, und die Forschung zeigt, dass geprunete große Netze kleinen, von Anfang an trainierten Netzen überlegen sind.
Verwenden Sie iteratives Pruning mit sorgfältigem Fine-Tuning, um die Komplexität des Modells schrittweise zu verringern und gleichzeitig die Leistung zu erhalten. Dieser Ansatz bietet eine bessere Kontrolle über den Genauigkeits-Effizienz-Tradeoff und ermöglicht es dem Modell, sich an die Entfernung von Parametern anzupassen. Setzen Sie strukturiertes Pruning für den praktischen Einsatz ein, wenn Hardware-Beschleunigung wichtig ist, da so Modelle entstehen, die auf Standardhardware effizient laufen, ohne spezielle Unterstützung für spärliche Berechnungen zu benötigen.
Validieren Sie umfassend auf vielfältigen Datensätzen, um sicherzustellen, dass geprunete Modelle auch außerhalb der Trainingsdaten gut generalisieren. Überwachen Sie mehrere Leistungskennzahlen wie Genauigkeit, Inferenzlatenz, Speicherverbrauch und Energiebedarf, um die Wirksamkeit des Prunings ganzheitlich zu bewerten. Berücksichtigen Sie die Zielumgebung, wenn Sie Pruning-Strategien auswählen, da verschiedene Geräte und Plattformen unterschiedliche Optimierungseigenschaften aufweisen.
Das Feld des Content Pruning entwickelt sich stetig weiter, mit neuen Techniken und Methoden. Kontextuell adaptives Token-Pruning (CATP) ist ein innovativer Ansatz, der semantische Ausrichtung und Feature-Vielfalt nutzt, um gezielt nur die relevantesten Tokens in Sprachmodellen zu behalten. Diese Technik ist besonders für große Sprachmodelle und multimodale Systeme wertvoll, in denen Kontextmanagement entscheidend ist.
Die Integration mit Vektordatenbanken wie Pinecone und Weaviate ermöglicht ausgefeiltere Kontext-Pruning-Strategien durch effizientes Speichern und Abrufen relevanter Informationen. Diese Integrationen unterstützen dynamische Pruning-Entscheidungen auf Basis semantischer Ähnlichkeit und Relevanzbewertung und verbessern so Effizienz und Genauigkeit.
Die Kombination mit anderen Komprimierungstechniken wie Quantisierung und Wissensdistillation erzeugt Synergieeffekte, die noch aggressivere Modellkomprimierung ermöglichen. Modelle, die gleichzeitig geprunet, quantisiert und distilliert werden, können Komprimierungsraten von 100x oder mehr erreichen und dabei akzeptable Leistungen beibehalten.
Da KI-Modelle weiterhin an Komplexität zunehmen und die Einsatzszenarien immer vielfältiger werden, bleibt Content Pruning eine entscheidende Technik, um fortschrittliche KI im gesamten Spektrum der Computerumgebungen – von leistungsstarken Rechenzentren bis hin zu ressourcenbeschränkten Edge-Geräten – zugänglich und praktisch zu machen.
Entdecken Sie, wie AmICited Ihnen hilft, zu verfolgen, wann Ihre Inhalte in KI-generierten Antworten bei ChatGPT, Perplexity und anderen KI-Suchmaschinen erscheinen. Sorgen Sie für Ihre Markenpräsenz in der KI-gestützten Zukunft.
Content Pruning ist das strategische Entfernen oder Aktualisieren von leistungsschwachen Inhalten, um SEO, Nutzererlebnis und Sichtbarkeit zu verbessern. Erfahr...

Erfahren Sie, wie Sie Ihre Inhalte für KI-Suchmaschinen wie ChatGPT, Perplexity und Gemini konsolidieren und optimieren. Entdecken Sie Best Practices für Strukt...
Erfahren Sie, wie Sie dünnen Content für KI-Systeme wie ChatGPT und Perplexity verbessern. Entdecken Sie Strategien, um Tiefe hinzuzufügen, die Content-Struktur...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.