Eine technische Überprüfung der Website-Architektur, Konfiguration und Inhaltsstruktur, um festzustellen, ob KI-Crawler effektiv auf Inhalte zugreifen, sie verstehen und extrahieren können. Bewertet die robots.txt-Konfiguration, XML-Sitemaps, Crawlability der Seite, JavaScript-Rendering und die Fähigkeit zur Inhaltsextraktion, um Sichtbarkeit auf KI-gestützten Suchplattformen wie ChatGPT, Claude und Perplexity sicherzustellen.
AI-Zugänglichkeitsprüfung
Eine technische Überprüfung der Website-Architektur, Konfiguration und Inhaltsstruktur, um festzustellen, ob KI-Crawler effektiv auf Inhalte zugreifen, sie verstehen und extrahieren können. Bewertet die robots.txt-Konfiguration, XML-Sitemaps, Crawlability der Seite, JavaScript-Rendering und die Fähigkeit zur Inhaltsextraktion, um Sichtbarkeit auf KI-gestützten Suchplattformen wie ChatGPT, Claude und Perplexity sicherzustellen.
Was ist eine KI-Zugänglichkeitsprüfung?
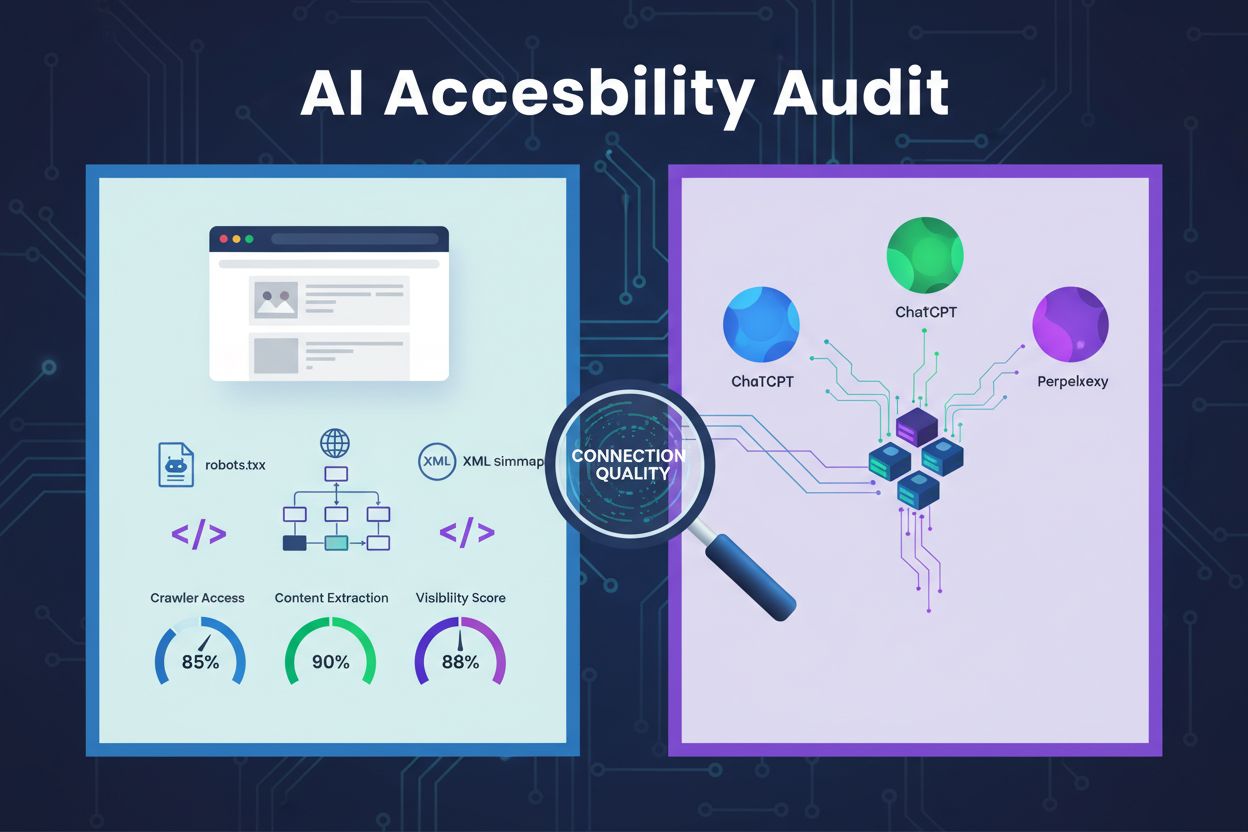
Eine KI-Zugänglichkeitsprüfung ist eine technische Überprüfung der Architektur, Konfiguration und Inhaltsstruktur Ihrer Website, um festzustellen, ob KI-Crawler effektiv auf Ihre Inhalte zugreifen, sie verstehen und extrahieren können. Im Gegensatz zu traditionellen SEO-Audits, die sich auf Keyword-Rankings und Backlinks konzentrieren, untersuchen KI-Zugänglichkeitsprüfungen die technischen Grundlagen, die es KI-Systemen wie ChatGPT, Claude und Perplexity ermöglichen, Ihre Inhalte zu entdecken und zu zitieren. Diese Prüfung bewertet zentrale Komponenten wie die robots.txt-Konfiguration, XML-Sitemaps, die Crawlability der Seite, das JavaScript-Rendering und die Fähigkeit zur Inhaltsextraktion, um sicherzustellen, dass Ihre Website im KI-gestützten Suchökosystem vollständig sichtbar ist.
Warum KI-Crawler nicht auf Ihre Inhalte zugreifen können
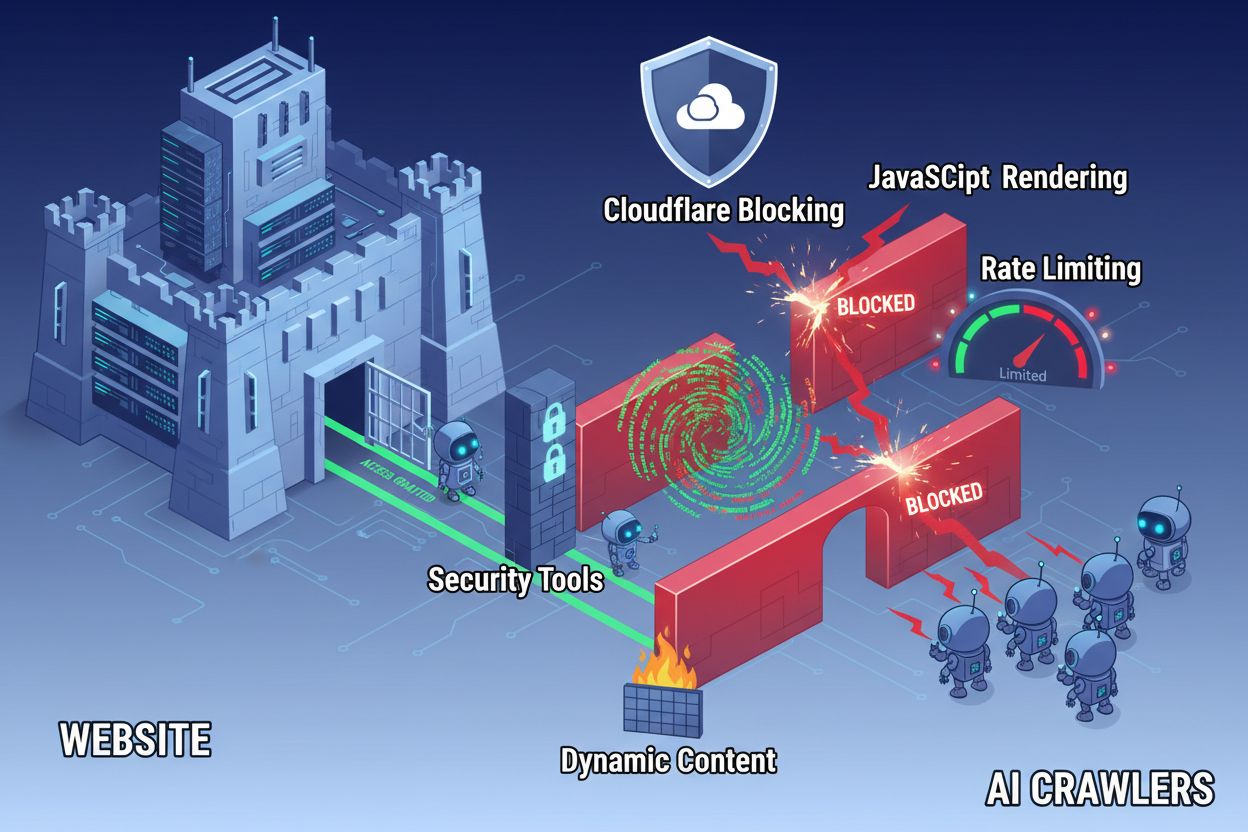
Trotz Fortschritten in der Webtechnologie stehen KI-Crawler vor erheblichen Hürden, wenn sie versuchen, moderne Websites zu durchsuchen. Die größte Herausforderung besteht darin, dass viele moderne Websites stark auf JavaScript-Rendering setzen, um Inhalte dynamisch anzuzeigen, doch die meisten KI-Crawler können kein JavaScript ausführen. Das bedeutet, dass etwa 60–90 % der modernen Website-Inhalte für KI-Systeme unsichtbar bleiben, obwohl sie in Browsern für Nutzer problemlos angezeigt werden. Darüber hinaus blockieren Sicherheitstools wie Cloudflare KI-Crawler standardmäßig, da diese als potenzielle Bedrohungen und nicht als legitime Indexierungsbots behandelt werden. Studien zeigen, dass 35 % der Unternehmensseiten unbeabsichtigt KI-Crawler blockieren und so wertvolle Inhalte für KI-Systeme unauffindbar machen.
Häufige Barrieren, die den Zugriff von KI-Crawlern verhindern:
JavaScript-Rendering-Einschränkungen – KI-Crawler können kein JavaScript ausführen und verpassen so dynamisch geladene Inhalte
Cloudflare- und Sicherheits-Tool-Blockierungen – Standard-Sicherheitskonfigurationen behandeln KI-Bots als Bedrohung
Rate-Limiting und Crawl-Beschränkungen – Serverseitige Einschränkungen verhindern umfassende Inhaltsindexierung
Komplexe Seitenarchitektur – Verschachtelte URLs und schwache interne Verlinkung erschweren die Navigation für Crawler
Dynamische Inhalte und Lazy Loading – Inhalte, die erst bei Nutzerinteraktion geladen werden, bleiben für Crawler verborgen
Zentrale Komponenten einer KI-Zugänglichkeitsprüfung
Eine umfassende KI-Zugänglichkeitsprüfung untersucht mehrere technische und strukturelle Elemente, die beeinflussen, wie KI-Systeme mit Ihrer Website interagieren. Jede Komponente spielt eine spezifische Rolle dabei, ob Ihre Inhalte auf KI-gestützten Suchplattformen sichtbar werden. Der Prüfungsprozess umfasst die Testung der Crawlability, die Überprüfung von Konfigurationsdateien, die Einschätzung der Inhaltsstruktur und das Monitoring des Verhaltens realer Crawler. Durch die systematische Bewertung dieser Komponenten können Sie gezielte Barrieren identifizieren und spezifische Lösungen zur Verbesserung Ihrer KI-Sichtbarkeit umsetzen.
Komponente
Zweck
Auswirkung auf KI-Sichtbarkeit
Robots.txt-Konfiguration
Steuert, welche Crawler auf bestimmte Bereiche der Seite zugreifen dürfen
Leiten Crawler zu wichtigen Seiten und Inhaltsstrukturen
Hoch – Hilft KI-Systemen, Inhalte zu priorisieren und zu entdecken
Crawlability der Seite
Stellt sicher, dass Seiten ohne Authentifizierung oder komplexe Navigation erreichbar sind
Kritisch – Blockierte Seiten sind für KI-Systeme unsichtbar
JavaScript-Rendering
Bestimmt, ob dynamische Inhalte für Crawler sichtbar sind
Kritisch – 60–90 % der Inhalte können ohne Pre-Rendering fehlen
Inhaltsextraktion
Bewertet, wie leicht KI-Systeme Inhalte parsen und verstehen können
Hoch – Schlechte Struktur verringert Zitierwahrscheinlichkeit
Sicherheitskonfiguration
Steuert Firewall- und Schutzregeln für den Crawler-Zugriff
Kritisch – Zu restriktive Regeln blockieren legitime KI-Bots
Schema-Markup-Implementierung
Liefert maschinenlesbaren Kontext zu Inhalten
Mittel – Verbessert KI-Verständnis und Zitierwahrscheinlichkeit
Interne Verlinkungsstruktur
Schafft semantische Beziehungen zwischen Seiten
Mittel – Hilft KI, Themenautorität und Relevanz zu erkennen
Robots.txt-Konfiguration für KI-Crawler
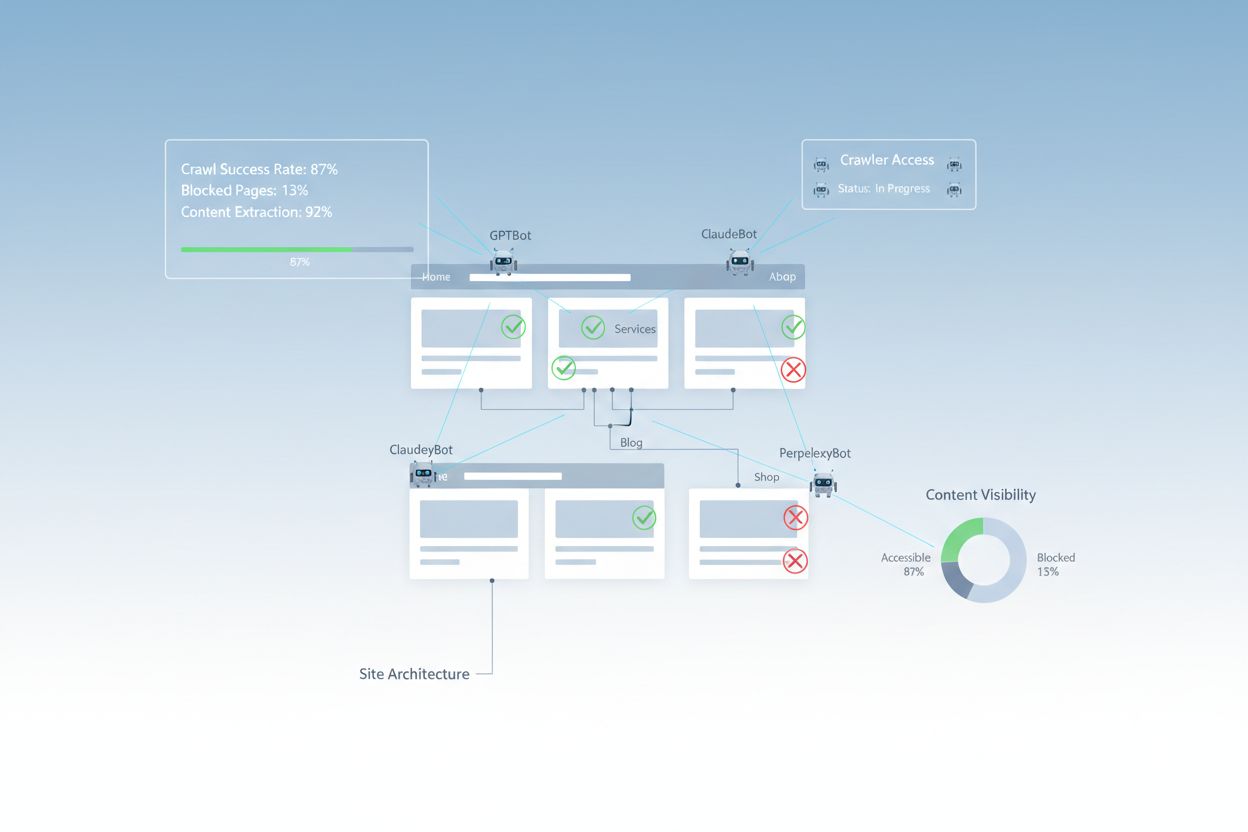
Ihre robots.txt-Datei ist das zentrale Mittel, um zu steuern, welche Crawler Ihre Website durchsuchen dürfen. Sie befindet sich im Root-Verzeichnis Ihrer Domain und enthält Anweisungen, ob Crawler bestimmte Bereiche Ihrer Seite betreten dürfen. Für die KI-Zugänglichkeit ist eine korrekte Konfiguration essenziell, denn fehlerhafte Regeln können große KI-Crawler wie GPTBot (OpenAI), ClaudeBot (Anthropic) und PerplexityBot (Perplexity) komplett aussperren. Wichtig ist, diese Crawler explizit zuzulassen und gleichzeitig durch Blockierung bösartiger Bots und Schutz sensibler Bereiche für Sicherheit zu sorgen.
Beispielkonfiguration der robots.txt für KI-Crawler:
Diese Konfiguration gestattet führenden KI-Crawlern explizit den Zugriff auf Ihre öffentlichen Inhalte und schützt gleichzeitig administrative und private Bereiche. Die Sitemap-Anweisungen helfen den Crawlern, Ihre wichtigsten Seiten effizient zu finden.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
XML-Sitemaps für KI-Discovery
Eine XML-Sitemap dient als Wegweiser für Crawler, listet die zu indexierenden URLs auf und liefert Metadaten zu jeder Seite. Für KI-Systeme sind Sitemaps besonders wertvoll, da sie Crawlern die Struktur Ihrer Seite vermitteln, wichtige Inhalte priorisieren und Seiten auffindbar machen, die beim normalen Crawling übersehen werden könnten. Im Gegensatz zu traditionellen Suchmaschinen, die Seitenstrukturen über Links erschließen, profitieren KI-Crawler stark von expliziten Hinweisen, welche Seiten besonders wichtig sind. Eine gut strukturierte Sitemap mit den richtigen Metadaten erhöht die Wahrscheinlichkeit, dass Ihre Inhalte von KI-Systemen entdeckt, verstanden und zitiert werden.
Beispielstruktur einer XML-Sitemap für KI-Optimierung:
<?xml version="1.0" encoding="UTF-8"?><urlsetxmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><!-- Hochpriorisierte Inhalte für KI-Crawler --><url><loc>https://yoursite.com/about</loc><lastmod>2025-01-03</lastmod><priority>1.0</priority></url><url><loc>https://yoursite.com/products</loc><lastmod>2025-01-03</lastmod><priority>0.9</priority></url><url><loc>https://yoursite.com/blog/ai-guide</loc><lastmod>2025-01-02</lastmod><priority>0.8</priority></url><url><loc>https://yoursite.com/faq</loc><lastmod>2025-01-01</lastmod><priority>0.7</priority></url></urlset>
Das priority-Attribut signalisiert KI-Crawlern die Wichtigkeit der Seiten, während lastmod die Aktualität der Inhalte angibt. So können KI-Systeme Crawl-Ressourcen gezielt einsetzen und die Inhaltsstruktur besser verstehen.
Technische Barrieren und Lösungen
Über Konfigurationsdateien hinaus gibt es zahlreiche technische Hürden, die KI-Crawler am effektiven Zugriff auf Ihre Inhalte hindern können. JavaScript-Rendering bleibt die größte Herausforderung, denn moderne Webframeworks wie React, Vue und Angular rendern Inhalte dynamisch im Browser und hinterlassen KI-Crawlern leere HTML-Seiten. Cloudflare und ähnliche Sicherheitstools blockieren KI-Crawler oft standardmäßig, da sie hohe Anfrageraten als potenziellen Angriff interpretieren. Rate-Limiting kann eine vollständige Indexierung verhindern, während komplexe Seitenarchitektur und dynamisches Inhaltsladen den Zugriff zusätzlich erschweren. Glücklicherweise gibt es verschiedene Lösungen, um diese Barrieren zu überwinden.
Lösungen zur Verbesserung des KI-Crawler-Zugriffs:
Pre-Rendering oder statische HTML-Auslieferung umsetzen – Generieren Sie statische Versionen von JavaScript-gerenderten Seiten für Crawler
Cloudflare und Sicherheits-Tools richtig konfigurieren – Whitelisten Sie legitime KI-Crawler und schützen Sie sich gleichzeitig vor bösartigen Bots
Seitenarchitektur optimieren – Vereinfachen Sie URL-Strukturen und verbessern Sie interne Verlinkungen für eine bessere Navigation
Lazy-Loading-Erkennung implementieren – Stellen Sie sicher, dass dynamisch geladene Inhalte auch für Crawler zugänglich sind
Plattformen zur KI-Crawler-Unterstützung nutzen – Dienste wie Alli AI erkennen automatisch KI-Crawler und liefern optimierte Inhalte aus
Serverprotokolle überwachen – Verfolgen Sie Crawler-Aktivitäten, um Zugriffsprobleme zu identifizieren und zu beheben
Angemessene Crawl-Delays festlegen – Stellen Sie ausreichend Bandbreite für Crawler-Anfragen bereit, ohne Server zu überlasten
Eigene KI-Sitemaps erstellen – Priorisieren Sie hochwertige Inhalte für KI-Systeme getrennt von traditionellen Sitemaps
Inhaltsextraktion und semantische Struktur
KI-Systeme müssen Ihre Inhalte nicht nur erreichen, sondern auch verstehen können. Inhaltsextraktion bezieht sich darauf, wie effektiv KI-Crawler Ihre Seiten parsen, verstehen und relevante Informationen extrahieren können. Hierbei ist die semantische HTML-Struktur entscheidend: Sie nutzen korrekte Überschriftenhierarchien, beschreibende Texte und eine logische Gliederung, um Bedeutung zu vermitteln. Sind Ihre Inhalte mit klaren Überschriften (H1, H2, H3), beschreibenden Absätzen und logischem Aufbau versehen, können KI-Systeme wichtige Informationen leichter erkennen und den Kontext verstehen. Schema-Markup liefert zusätzlich maschinenlesbare Metadaten und teilt KI-Systemen explizit mit, worum es auf Ihrer Seite geht – das erhöht die Wahrscheinlichkeit einer Zitierung erheblich.
Eine saubere semantische Struktur umfasst auch die Nutzung von semantischen HTML-Elementen wie <article>, <section>, <nav> und <aside> anstelle generischer <div>-Tags. So verstehen KI-Systeme den Zweck und die Wichtigkeit einzelner Inhaltsbereiche besser. In Kombination mit strukturierten Daten wie FAQ-, Produkt- oder Organisationsschema wird Ihr Content für KI-Systeme deutlich zugänglicher und die Wahrscheinlichkeit steigt, in KI-generierten Antworten und Ergebnissen aufzutauchen.
Monitoring- und Verifikationstools
Nach der Umsetzung von Verbesserungen sollten Sie sicherstellen, dass KI-Crawler tatsächlich auf Ihre Inhalte zugreifen können, und die laufende Performance überwachen. Serverprotokolle liefern direkten Nachweis über Crawler-Aktivitäten – Sie sehen, welche Bots Ihre Website besucht und welche Seiten sie abgerufen haben und ob Fehler aufgetreten sind. Google Search Console gibt Einblicke, wie Googles Crawler mit Ihrer Website interagieren, während spezialisierte KI-Sichtbarkeits-Monitoring-Tools zeigen, wie Ihre Inhalte auf verschiedenen KI-Plattformen erscheinen. AmICited.com überwacht gezielt, wie KI-Systeme Ihre Marke auf ChatGPT, Perplexity und Google AI Overviews referenzieren und zeigt, welche Seiten wie oft zitiert werden.
Tools und Methoden zur Überwachung des KI-Crawler-Zugriffs:
Server-Log-Analyse – Prüfen Sie Zugriffsprotokolle auf GPTBot, ClaudeBot, PerplexityBot und andere KI-Crawler-User-Agents
Google Search Console – Überwachen Sie Crawl-Statistiken, Abdeckungsprobleme und den Indexierungsstatus
robots.txt-Testtools – Prüfen Sie, ob Ihre robots.txt-Datei korrekt konfiguriert und erreichbar ist
Schema-Markup-Validatoren – Testen Sie die Implementierung strukturierter Daten mit dem Schema.org-Validator
AmICited.com – Überwachen Sie KI-Marken-Erwähnungen und Zitierungen auf führenden KI-Plattformen
Eigene Monitoring-Dashboards – Setzen Sie Alarme für Crawler-Aktivitätsmuster und Zugriffsanomalien
Crawl-Simulationstools – Testen Sie vorab, wie bestimmte Crawler mit Ihrer Website interagieren
Best Practices für KI-Zugänglichkeit
Die Optimierung Ihrer Website für KI-Crawler erfordert einen strategischen, kontinuierlichen Ansatz. Statt KI-Zugänglichkeit als einmaliges Projekt zu betrachten, etablieren erfolgreiche Organisationen fortlaufende Überwachungs- und Verbesserungsprozesse. Die wirksamste Strategie vereint korrekte technische Konfiguration mit Inhaltsoptimierung – so sind sowohl Ihre Infrastruktur als auch Ihre Inhalte KI-ready.
Do’s für KI-Zugänglichkeit:
✅ Lassen Sie führende KI-Crawler explizit in Ihrer robots.txt-Datei zu
✅ Erstellen und pflegen Sie aktuelle XML-Sitemaps mit Priority-Metadaten
✅ Implementieren Sie Schema-Markup für zentrale Inhaltstypen (FAQ, HowTo, Produkt, Organisation)
✅ Verwenden Sie semantisches HTML mit korrekter Überschriftenhierarchie und logischer Struktur
✅ Überwachen Sie regelmäßig Serverprotokolle, um Crawler-Aktivitäten und Probleme zu erkennen
✅ Testen Sie Ihre Konfiguration mit verschiedenen Validierungstools vor dem Livegang
✅ Halten Sie Inhalte aktuell und aktualisieren Sie die lastmod-Daten in Sitemaps
✅ Setzen Sie Pre-Rendering oder statische HTML-Auslieferung für JavaScript-lastige Seiten ein
✅ Konfigurieren Sie Sicherheitstools so, dass legitime KI-Crawler auf der Whitelist stehen
Don’ts für KI-Zugänglichkeit:
❌ Blockieren Sie nicht einfach alle KI-Crawler, ohne die Auswirkungen auf Ihr Business zu kennen
❌ Verlassen Sie sich nicht nur auf “User-agent: *"-Regeln – konfigurieren Sie führende KI-Crawler explizit
❌ Nutzen Sie keine zu restriktiven robots.txt-Regeln, die versehentlich legitime Bots aussperren
❌ Ignorieren Sie keine JavaScript-Rendering-Probleme bei modernen Webframeworks
❌ Vergessen Sie nicht, robots.txt und Sitemaps bei Änderungen der Seitenarchitektur zu aktualisieren
❌ Gehen Sie nicht davon aus, dass alle Crawler robots.txt respektieren – einige ignorieren sie
❌ Vernachlässigen Sie die Sicherheit nicht – balancieren Sie KI-Zugänglichkeit und Schutz vor bösartigen Bots aus
❌ Erstellen Sie keine Sitemaps mit veralteten oder doppelten Inhalten
Die erfolgreichste KI-Zugänglichkeitsstrategie betrachtet Crawler als Partner der Inhaltsverbreitung – nicht als Bedrohung, die blockiert werden muss. Indem Sie Ihre Website technisch sauber, korrekt konfiguriert und semantisch klar gestalten, maximieren Sie die Chancen, dass KI-Systeme Ihre Inhalte entdecken, verstehen und in ihren Antworten an Nutzer zitieren.
Häufig gestellte Fragen
Was ist der Unterschied zwischen einer KI-Zugänglichkeitsprüfung und einem traditionellen SEO-Audit?
KI-Zugänglichkeitsprüfungen konzentrieren sich auf semantische Struktur, maschinenlesbare Inhalte und Zitierwürdigkeit für KI-Systeme, während traditionelle SEO-Audits Schlüsselwörter, Backlinks und Suchrankings betonen. KI-Audits untersuchen, ob Crawler auf Ihre Inhalte zugreifen und sie verstehen können, während SEO-Audits sich auf Ranking-Faktoren für Googles Suchergebnisse konzentrieren.
Wie erkenne ich, ob KI-Crawler auf meine Website zugreifen können?
Überprüfen Sie Ihre Serverprotokolle auf KI-Crawler-User-Agents wie GPTBot, ClaudeBot und PerplexityBot. Verwenden Sie die Google Search Console, um Crawl-Aktivitäten zu überwachen, testen Sie Ihre robots.txt-Datei mit Validierungstools und nutzen Sie spezialisierte Plattformen wie AmICited, um zu verfolgen, wie KI-Systeme Ihre Inhalte plattformübergreifend referenzieren.
Was sind die häufigsten Barrieren, die den Zugriff von KI-Crawlern verhindern?
Die häufigsten Barrieren sind JavaScript-Rendering-Einschränkungen (KI-Crawler können kein JavaScript ausführen), Cloudflare- und Sicherheits-Tool-Blockierungen (35 % der Unternehmensseiten blockieren KI-Crawler), Rate-Limiting, das eine umfassende Indexierung verhindert, komplexe Seitenarchitektur und dynamisches Inhaltsladen. Jede Barriere erfordert unterschiedliche Lösungen.
Sollte ich KI-Crawler auf meiner Website blockieren oder zulassen?
Die meisten Unternehmen profitieren davon, KI-Crawler zuzulassen, da sie die Markenpräsenz in KI-gestützten Suchergebnissen und Konversationsschnittstellen erhöhen. Die Entscheidung hängt jedoch von Ihrer Content-Strategie, Ihrer Wettbewerbspositionierung und Ihren Unternehmenszielen ab. Sie können robots.txt verwenden, um bestimmte Crawler selektiv zuzulassen und andere basierend auf Ihren Anforderungen zu blockieren.
Wie oft sollte ich eine KI-Zugänglichkeitsprüfung durchführen?
Führen Sie vierteljährlich oder immer dann, wenn Sie wesentliche Änderungen an Ihrer Seitenarchitektur, Content-Strategie oder Sicherheitskonfiguration vornehmen, eine umfassende Überprüfung durch. Überwachen Sie Crawler-Aktivitäten kontinuierlich über Serverprotokolle und spezialisierte Tools. Aktualisieren Sie Ihre robots.txt und Sitemaps, sobald Sie neue Inhaltsbereiche veröffentlichen oder URL-Strukturen ändern.
Wie hängt robots.txt mit dem Zugriff von KI-Crawlern zusammen?
Robots.txt ist Ihr primäres Mittel zur Steuerung des Zugriffs von KI-Crawlern. Eine korrekte Konfiguration erlaubt explizit wichtige KI-Crawler (GPTBot, ClaudeBot, PerplexityBot) und schützt gleichzeitig sensible Bereiche. Eine fehlerhafte robots.txt kann KI-Crawler komplett blockieren, sodass Ihre Inhalte für KI-Systeme unabhängig von deren Qualität unsichtbar bleiben.
Kann ich meine KI-Sichtbarkeit ohne technische Änderungen verbessern?
Technische Optimierung ist wichtig, aber Sie können die KI-Sichtbarkeit auch durch Inhaltsoptimierung verbessern – mit semantischer HTML-Struktur, Schema-Markup, besserer interner Verlinkung und vollständigen Inhalten. Technische Barrieren wie JavaScript-Rendering und Sicherheitstool-Blockierungen erfordern jedoch meist technische Lösungen für vollständige KI-Zugänglichkeit.
Welche Tools kann ich verwenden, um die KI-Zugänglichkeit meiner Website zu prüfen?
Nutzen Sie Server-Log-Analyse zur Überwachung der Crawler-Aktivität, Google Search Console für Crawl-Statistiken, robots.txt-Validatoren zur Überprüfung der Konfiguration, Schema-Markup-Validatoren für strukturierte Daten und spezialisierte Plattformen wie AmICited zur Überwachung von KI-Zitaten. Viele SEO-Tools wie Screaming Frog bieten ebenfalls Crawler-Simulationsfunktionen zur Prüfung der KI-Zugänglichkeit.
Überwachen Sie Ihre KI-Sichtbarkeit auf allen Plattformen
Verfolgen Sie, wie ChatGPT, Perplexity, Google AI Overviews und andere KI-Systeme Ihre Marke mit AmICited referenzieren. Erhalten Sie Echtzeit-Einblicke in Ihre KI-Suchsichtbarkeit und optimieren Sie Ihre Content-Strategie.
Wie man ein KI-Sichtbarkeits-Audit durchführt: Die vollständige Methodik
Erlernen Sie die vollständige Schritt-für-Schritt-Methodik zur Durchführung eines KI-Sichtbarkeits-Audits. Entdecken Sie, wie Sie Marken-Nennungen, Zitationen u...
Welche Tools prüfen die KI-Crawlability? Top Monitoring-Lösungen
Entdecken Sie die besten Tools zur Überprüfung der KI-Crawlability. Erfahren Sie, wie Sie den Zugriff von GPTBot, ClaudeBot und PerplexityBot auf Ihre Website m...
Entdecken Sie die besten kostenlosen KI-Sichtbarkeitstools, um die Erwähnung Ihrer Marke in ChatGPT, Perplexity und Google KI-Overviews zu überwachen. Vergleich...
8 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.