Die strategische Praxis, KI-Crawler selektiv zuzulassen oder zu blockieren, um zu steuern, wie Inhalte für das Training oder die Echtzeit-Abfrage genutzt werden. Dies umfasst den Einsatz von robots.txt-Dateien, serverseitigen Kontrollen und Überwachungstools, um zu bestimmen, welche KI-Systeme auf Ihre Inhalte zugreifen dürfen und zu welchem Zweck.
KI-Crawler-Management
Die strategische Praxis, KI-Crawler selektiv zuzulassen oder zu blockieren, um zu steuern, wie Inhalte für das Training oder die Echtzeit-Abfrage genutzt werden. Dies umfasst den Einsatz von robots.txt-Dateien, serverseitigen Kontrollen und Überwachungstools, um zu bestimmen, welche KI-Systeme auf Ihre Inhalte zugreifen dürfen und zu welchem Zweck.
Was ist KI-Crawler-Management?
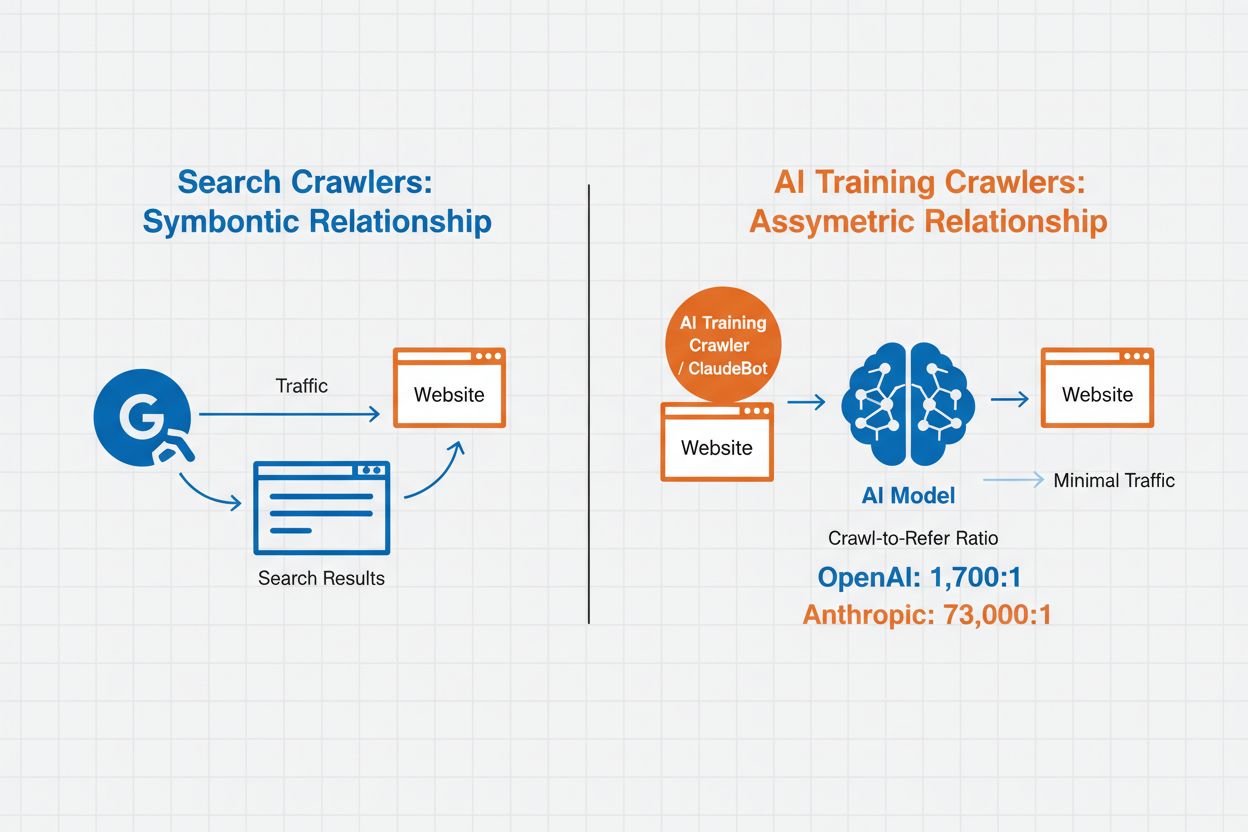
KI-Crawler-Management bezeichnet die Praxis, zu steuern und zu überwachen, wie künstliche Intelligenz-Systeme auf Website-Inhalte zugreifen und diese für Training und Suchzwecke nutzen. Im Gegensatz zu herkömmlichen Suchmaschinen-Crawlern, die Inhalte für Websuchergebnisse indexieren, sind KI-Crawler speziell darauf ausgelegt, Daten für das Training großer Sprachmodelle oder KI-gestützte Suchfunktionen zu sammeln. Das Ausmaß dieser Aktivität variiert je nach Organisation erheblich – die Crawler von OpenAI arbeiten mit einem Crawl-to-Refer-Verhältnis von 1.700:1, das heißt, sie greifen 1.700 Mal auf Inhalte zu, bevor sie eine Referenz liefern, während das Verhältnis bei Anthropic bei 73.000:1 liegt, was den enormen Datenverbrauch moderner KI-Systeme verdeutlicht. Effektives Crawler-Management ermöglicht es Website-Betreibern zu entscheiden, ob ihre Inhalte zum KI-Training beitragen, in KI-Suchergebnissen erscheinen oder vor automatisiertem Zugriff geschützt bleiben.
Arten von KI-Crawlern
KI-Crawler lassen sich je nach Zweck und Nutzungsmuster in drei Kategorien einteilen. Trainingscrawler sind darauf ausgelegt, Daten für die Entwicklung von Machine-Learning-Modellen zu sammeln und verbrauchen große Mengen an Inhalten, um KI-Fähigkeiten zu verbessern. Such- und Zitationscrawler indexieren Inhalte, um KI-gestützte Suchfunktionen zu ermöglichen und Quellenangaben in KI-generierten Antworten bereitzustellen – so können Nutzer Ihre Inhalte über KI-Oberflächen entdecken. Nutzerinitiierte Crawler arbeiten auf Abruf, wenn Nutzer mit KI-Tools interagieren, etwa wenn ein ChatGPT-Nutzer ein Dokument hochlädt oder die Analyse einer bestimmten Webseite anfordert. Das Verständnis dieser Kategorien hilft Ihnen, fundierte Entscheidungen zu treffen, welche Crawler Sie je nach Content-Strategie und Geschäftszielen zulassen oder blockieren.
Crawler-Typ
Zweck
Beispiele
Trainingsdaten verwendet
Training
Modellentwicklung und -verbesserung
GPTBot, ClaudeBot
Ja
Suche/Zitation
KI-Suchergebnisse und Quellenangaben
Google-Extended, OAI-SearchBot, PerplexityBot
Variiert
Nutzerinitiiert
Analyse von Inhalten auf Abruf
ChatGPT-User, Meta-ExternalAgent, Amazonbot
Kontextabhängig
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Das Management von KI-Crawlern beeinflusst direkt den Traffic, Umsatz und Wert Ihrer Website-Inhalte. Wenn Crawler Ihre Inhalte ohne Gegenleistung konsumieren, verlieren Sie die Möglichkeit, davon durch Empfehlungen, Werbeeinblendungen oder Nutzerinteraktion zu profitieren. Viele Websites berichten von signifikanten Traffic-Rückgängen, da Nutzer Antworten direkt in KI-generierten Ergebnissen finden und nicht mehr auf die Originalquelle klicken – dies unterbricht Empfehlungs-Traffic und damit verbundene Werbeeinnahmen. Neben finanziellen Aspekten spielen rechtliche und ethische Überlegungen eine Rolle – Ihre Inhalte sind geistiges Eigentum, und Sie haben das Recht, deren Nutzung sowie Attribution oder Vergütung zu steuern. Zudem kann uneingeschränkter Crawler-Zugriff die Serverlast und Bandbreitenkosten erhöhen, insbesondere durch Crawler mit aggressiven Zugriffsraten, die keine Drosselung respektieren.
Robots.txt und technische Kontrollen
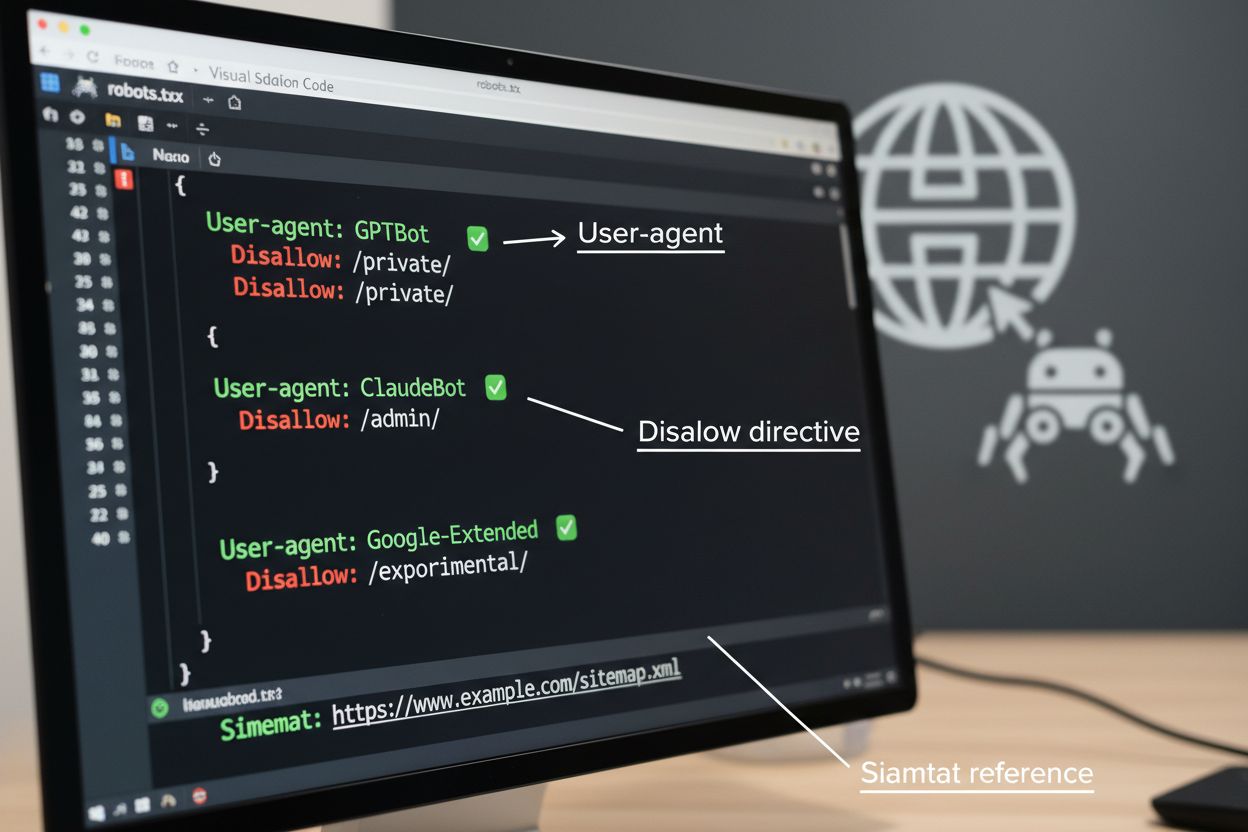
Die robots.txt-Datei ist das grundlegende Werkzeug, um Crawler-Zugriffe zu steuern, und wird im Root-Verzeichnis der Website platziert, um automatisierten Agenten Crawl-Präferenzen mitzuteilen. Über User-agent-Direktiven werden spezifische Crawler angesprochen und mit Disallow- oder Allow-Regeln der Zugriff auf bestimmte Pfade und Ressourcen geregelt. robots.txt hat jedoch wichtige Grenzen – sie ist ein freiwilliger Standard, dessen Einhaltung von den Crawlern abhängt, und bösartige oder schlecht programmierte Bots ignorieren sie oft vollständig. Zudem verhindert robots.txt nicht, dass Crawler auf öffentlich zugängliche Inhalte zugreifen; sie bittet lediglich um Beachtung Ihrer Wünsche. Daher sollte robots.txt Teil eines mehrschichtigen Ansatzes und nicht Ihre einzige Verteidigungslinie sein.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Erweiterte Kontrollmethoden
Über robots.txt hinaus bieten verschiedene fortgeschrittene Techniken stärkeren Schutz und feinere Steuerung des Crawler-Zugriffs. Diese Methoden greifen auf unterschiedlichen Ebenen Ihrer Infrastruktur und lassen sich für umfassenden Schutz kombinieren:
.htaccess-Regeln: Serverseitige Direktiven, mit denen spezifische User-Agents oder IP-Bereiche gesperrt werden, bevor Inhalte ausgeliefert werden
IP Allowlisting/Blocklisting: Zugriffsbeschränkung anhand der IP-Adressen bekannter KI-Crawler – erfordert jedoch fortlaufende Aktualisierung der IP-Listen
Cloudflare WAF-Lösungen: Einsatz von Web Application Firewall-Regeln zur Identifikation und Blockierung von Crawler-Traffic anhand von Verhaltensmustern und Signaturen
HTTP-Header (X-Robots-Tag): Versand von Crawler-Anweisungen direkt in den Response-Headern – ermöglicht seiten- oder ressourcenspezifische Kontrolle, die schwerer zu umgehen ist als robots.txt
Rate Limiting: Strenge Zugriffsbeschränkungen für Crawler, um umfangreiche Datensammlung wirtschaftlich unattraktiv zu machen
Bot-Fingerprinting: Analyse von Anfrage-Mustern, Headern und Verhalten zur Identifikation von Crawlern, die ihre Identität verschleiern
Schutz und Sichtbarkeit abwägen
Die Entscheidung, KI-Crawler zu blockieren, beinhaltet einen Abwägungsprozess zwischen Content-Schutz und Auffindbarkeit. Das Blockieren aller KI-Crawler verhindert, dass Ihre Inhalte in KI-Suchergebnissen, Zusammenfassungen oder als Quellen in KI-Tools erscheinen – das kann die Sichtbarkeit für Nutzer verringern, die Inhalte über diese neuen Kanäle entdecken. Erlauben Sie hingegen uneingeschränkten Zugriff, werden Ihre Inhalte ohne Gegenleistung für KI-Training genutzt und es kann zu weniger Empfehlungs-Traffic kommen, da Nutzer Antworten direkt von KI-Systemen erhalten. Ein strategischer Ansatz ist das selektive Blockieren: Zulassen von zitationsbasierten Crawlern wie OAI-SearchBot und PerplexityBot, die Empfehlungs-Traffic liefern, während Trainingscrawler wie GPTBot und ClaudeBot, die Daten ohne Attribution verbrauchen, blockiert werden. Sie könnten auch Google-Extended zulassen, um die Sichtbarkeit in Google AI Overviews zu wahren, während Trainingscrawler von Wettbewerbern ausgeschlossen werden. Die optimale Strategie hängt von Inhaltstyp, Geschäftsmodell und Zielgruppe ab – Nachrichtenportale und Publisher setzen eher auf Blockaden, während Anbieter von Lerninhalten von breiterer KI-Sichtbarkeit profitieren könnten.
Überwachung und Durchsetzung
Crawler-Kontrollen wirken nur, wenn Sie überprüfen, ob Crawler Ihre Anweisungen tatsächlich befolgen. Server-Log-Analyseist die wichtigste Methode zur Überwachung von Crawler-Aktivitäten – untersuchen Sie Ihre Zugriffsprotokolle auf User-Agent-Strings und Anfrage-Muster, um festzustellen, welche Crawler Ihre Seite besuchen und ob sie robots.txt-Anweisungen einhalten. Viele Crawler geben vor, compliant zu sein, greifen aber weiterhin auf gesperrte Pfade zu – laufende Überwachung ist daher unerlässlich. Tools wie Cloudflare Radar bieten Echtzeit-Einblicke in Traffic-Muster und helfen, verdächtiges oder non-konformes Crawler-Verhalten zu erkennen. Richten Sie automatisierte Alarme für Zugriffsversuche auf gesperrte Ressourcen ein und prüfen Sie Ihre Logs regelmäßig, um neue Crawler oder sich ändernde Muster, die auf Umgehungsversuche hindeuten, zu entdecken.
Best Practices und Umsetzung
Effektives KI-Crawler-Management erfordert einen systematischen Ansatz, der Schutz und strategische Sichtbarkeit ins Gleichgewicht bringt. Befolgen Sie diese acht Schritte, um eine umfassende Crawler-Management-Strategie zu etablieren:
Zugriffe prüfen: Analysieren Sie Ihre Serverlogs, um festzustellen, welche KI-Crawler Ihre Seite aktuell besuchen, wie häufig und auf welche Ressourcen sie zugreifen
Policy definieren: Entscheiden Sie, welche Crawler zu Ihren Zielen passen – berücksichtigen Sie Trainings- vs. Suchcrawler, Traffic-Einflüsse und den Wert Ihrer Inhalte
Entscheidungen dokumentieren: Halten Sie Ihre Crawler-Policy und die Begründungen dafür klar fest, um Referenzen und Team-Alignment zu sichern
Kontrollen umsetzen: Setzen Sie robots.txt-Regeln, HTTP-Header und erweiterte Maßnahmen wie Rate Limiting oder IP-Blockaden entsprechend Ihrer Policy um
Compliance überwachen: Prüfen Sie regelmäßig Serverlogs und nutzen Sie Monitoring-Tools, um das Einhalten Ihrer Vorgaben zu verifizieren
Alarme einrichten: Konfigurieren Sie automatische Alarme für non-konformes Crawler-Verhalten oder Umgehungsversuche
Vierteljährlich überprüfen: Bewerten Sie Ihre Crawler-Management-Strategie mindestens vierteljährlich neu, da neue Crawler auftauchen und sich Geschäftsanforderungen ändern können
Bei neuen Crawlern aktualisieren: Bleiben Sie über neue KI-Crawler informiert und aktualisieren Sie Ihre Kontrollen proaktiv
AmICited.com: Ihre KI-Verweise überwachen
AmICited.com bietet eine spezialisierte Plattform, um zu überwachen, wie KI-Systeme Ihre Inhalte über verschiedene Modelle und Anwendungen hinweg referenzieren und nutzen. Der Dienst ermöglicht die Echtzeit-Analyse Ihrer Zitationen in KI-generierten Antworten, sodass Sie erkennen, welche Crawler Ihre Inhalte am aktivsten verwenden und wie häufig Ihre Arbeit in KI-Ausgaben erscheint. Durch die Auswertung von Crawler-Mustern und Zitationsdaten ermöglicht AmICited.com datenbasierte Entscheidungen für Ihre Crawler-Management-Strategie – Sie sehen genau, welche Crawler durch Zitate und Empfehlungen Mehrwert schaffen und welche Inhalte ohne Attribution konsumieren. Diese Informationen machen aus dem Crawler-Management ein strategisches Werkzeug, um die Sichtbarkeit und Wirkung Ihrer Inhalte im KI-getriebenen Web zu optimieren.
Häufig gestellte Fragen
Was ist der Unterschied zwischen dem Blockieren von KI-Trainingscrawlern und Suchcrawlern?
Trainingscrawler wie GPTBot und ClaudeBot sammeln Inhalte, um Datensätze für die Entwicklung großer Sprachmodelle zu erstellen, wobei Ihre Inhalte genutzt werden, ohne dass Sie Empfehlungs-Traffic erhalten. Suchcrawler wie OAI-SearchBot und PerplexityBot indexieren Inhalte für KI-gestützte Suchergebnisse und können Besucher über Zitate zurück auf Ihre Website führen. Das Blockieren von Trainingscrawlern schützt Ihre Inhalte davor, in KI-Modelle aufgenommen zu werden, während das Blockieren von Suchcrawlern Ihre Sichtbarkeit auf KI-gestützten Plattformen verringern kann.
Beeinträchtigt das Blockieren von KI-Crawlern mein SEO-Ranking?
Nein. Das Blockieren von KI-Trainingscrawlern wie GPTBot, ClaudeBot und CCBot hat keinen Einfluss auf Ihr Google- oder Bing-Ranking. Traditionelle Suchmaschinen verwenden andere Crawler (Googlebot, Bingbot), die unabhängig von KI-Trainingsbots arbeiten. Blockieren Sie traditionelle Suchcrawler nur, wenn Sie vollständig aus den Suchergebnissen verschwinden möchten – das würde Ihrem SEO schaden.
Wie erkenne ich, welche Crawler auf meine Seite zugreifen?
Analysieren Sie Ihre Serverzugriffsprotokolle, um User-Agent-Strings von Crawlern zu identifizieren. Suchen Sie nach Einträgen, die 'bot', 'crawler' oder 'spider' im User-Agent-Feld enthalten. Tools wie Cloudflare Radar bieten Echtzeit-Einblicke, welche KI-Crawler auf Ihre Seite zugreifen und wie deren Traffic-Muster aussehen. Sie können auch Analyseplattformen nutzen, die Bot-Traffic von menschlichen Besuchern unterscheiden.
Können KI-Crawler robots.txt-Anweisungen ignorieren?
Ja. robots.txt ist ein freiwilliger Standard, der auf die Einhaltung durch Crawler angewiesen ist – er ist nicht durchsetzbar. Gut programmierte Crawler großer Unternehmen wie OpenAI, Anthropic und Google respektieren robots.txt in der Regel, aber manche Crawler ignorieren sie vollständig. Für stärkeren Schutz nutzen Sie serverseitige Sperren über .htaccess, Firewall-Regeln oder IP-basierte Einschränkungen.
Sollte ich alle KI-Crawler blockieren oder selektiv vorgehen?
Das hängt von Ihren geschäftlichen Prioritäten ab. Das Blockieren aller Trainingscrawler schützt Ihre Inhalte davor, in KI-Modelle aufgenommen zu werden, während Sie Suchcrawler möglicherweise zulassen, die Empfehlungs-Traffic liefern. Viele Publisher setzen auf selektives Blockieren und sperren gezielt Trainingscrawler, während Such- und Zitationscrawler zugelassen werden. Berücksichtigen Sie Inhaltstyp, Traffic-Quellen und Monetarisierungsmodell bei Ihrer Strategie.
Wie oft sollte ich meine Crawler-Management-Policy aktualisieren?
Überprüfen und aktualisieren Sie Ihre Crawler-Management-Policy mindestens vierteljährlich. Neue KI-Crawler entstehen regelmäßig, und bestehende Crawler ändern ihre User-Agents ohne Vorwarnung. Verfolgen Sie Ressourcen wie das ai.robots.txt-Projekt auf GitHub für community-gepflegte Listen und kontrollieren Sie Ihre Serverlogs monatlich, um neue Crawler auf Ihrer Seite zu erkennen.
Wie wirken sich KI-Crawler auf meinen Website-Traffic und Umsatz aus?
KI-Crawler können Ihren Traffic und Umsatz erheblich beeinflussen. Wenn Nutzer Antworten direkt von KI-Systemen erhalten, anstatt Ihre Website zu besuchen, verlieren Sie Empfehlungs-Traffic und damit verbundene Werbeeinblendungen. Studien zeigen Crawl-to-Refer-Verhältnisse von bis zu 73.000:1 bei manchen KI-Plattformen – sie greifen Ihre Inhalte tausendfach ab, bevor ein Besucher zurückgeführt wird. Das Blockieren von Trainingscrawlern kann Ihren Traffic schützen, während das Zulassen von Suchcrawlern potenziell Vorteile durch Empfehlungen bietet.
Wie kann ich überprüfen, ob meine robots.txt-Konfiguration funktioniert?
Überprüfen Sie Ihre Serverlogs, ob gesperrte Crawler weiterhin in Ihren Zugriffsprotokollen auftauchen. Nutzen Sie Testtools wie den robots.txt-Tester der Google Search Console oder den Robots.txt Tester von Merkle, um Ihre Konfiguration zu validieren. Rufen Sie Ihre robots.txt direkt unter yoursite.com/robots.txt auf, um den Inhalt zu prüfen. Überwachen Sie Ihre Logs regelmäßig, um Crawler zu erkennen, die trotz Sperre auftauchen.
Überwachen Sie, wie KI-Systeme auf Ihre Inhalte verweisen
AmICited.com verfolgt in Echtzeit, wie KI-Systeme wie ChatGPT, Perplexity, Google AI Overviews und andere auf Ihre Marke Bezug nehmen. Treffen Sie datenbasierte Entscheidungen für Ihre Crawler-Management-Strategie.
So erkennen Sie KI-Crawler in Server-Logs: Vollständiger Leitfaden zur Erkennung
Erfahren Sie, wie Sie KI-Crawler wie GPTBot, PerplexityBot und ClaudeBot in Ihren Server-Logs identifizieren und überwachen. Entdecken Sie User-Agent-Strings, M...
Auswirkungen von KI-Crawlern auf Serverressourcen: Was Sie erwarten können
Erfahren Sie, wie KI-Crawler Serverressourcen, Bandbreite und Leistung beeinflussen. Entdecken Sie echte Statistiken, Strategien zur Abschwächung und Infrastruk...
Verstehen Sie, wie KI-Crawler wie GPTBot und ClaudeBot funktionieren, wo sie sich von traditionellen Such-Crawlern unterscheiden und wie Sie Ihre Website für Si...
12 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.