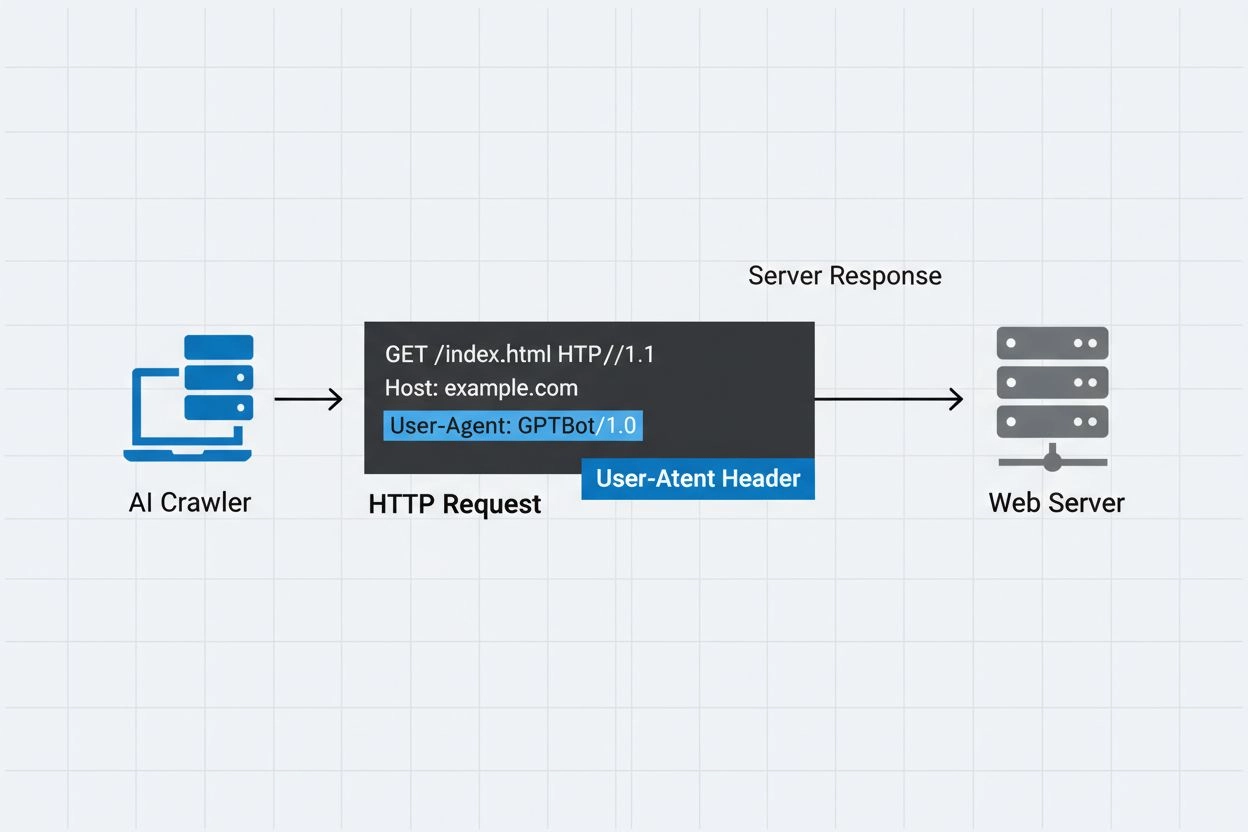
Die Identifikationszeichenfolge, die AI-Crawler in HTTP-Headern an Webserver senden. Sie wird für Zugriffskontrolle, Analyse-Tracking und zur Unterscheidung legitimer AI-Bots von bösartigen Scraper verwendet. Sie identifiziert Zweck, Version und Herkunft des Crawlers.
AI-Crawler User-Agent
Die Identifikationszeichenfolge, die AI-Crawler in HTTP-Headern an Webserver senden. Sie wird für Zugriffskontrolle, Analyse-Tracking und zur Unterscheidung legitimer AI-Bots von bösartigen Scraper verwendet. Sie identifiziert Zweck, Version und Herkunft des Crawlers.
Definition von AI-Crawler User-Agent
Ein AI-Crawler User-Agent ist eine HTTP-Header-Zeichenfolge, die automatisierte Bots identifiziert, die auf Webinhalte zum Zweck des Trainings, der Indexierung oder der Forschung im Bereich künstlicher Intelligenz zugreifen. Diese Zeichenfolge dient als digitale Identität des Crawlers und kommuniziert dem Webserver, wer die Anfrage stellt und mit welcher Absicht. Der User-Agent ist für AI-Crawler entscheidend, da er Websitebetreibern ermöglicht zu erkennen, nachzuverfolgen und zu kontrollieren, wie ihre Inhalte von verschiedenen AI-Systemen abgerufen werden. Ohne ordentliche User-Agent-Identifikation wird es deutlich schwieriger, legitime AI-Crawler von bösartigen Bots zu unterscheiden – sie ist somit ein essenzieller Bestandteil verantwortungsvoller Web-Scraping- und Datensammlungspraktiken.
HTTP-Kommunikation und User-Agent-Header
Der User-Agent-Header ist ein zentrales Element von HTTP-Anfragen und taucht in den Request-Headern auf, die jeder Browser und Bot beim Zugriff auf eine Webressource sendet. Wenn ein Crawler eine Anfrage an einen Webserver stellt, gibt er Metadaten über sich selbst in den HTTP-Headern an – wobei die User-Agent-Zeichenfolge einer der wichtigsten Identifikatoren ist. Diese enthält typischerweise Informationen über den Namen des Crawlers, die Version, die betreibende Organisation und oft eine Kontakt-URL oder E-Mail zur Verifizierung. Der User-Agent ermöglicht es Servern, den anfragenden Client zu identifizieren und zu entscheiden, ob Inhalte ausgeliefert, Anfragen limitiert oder der Zugriff komplett blockiert wird. Nachfolgend Beispiele von User-Agent-Zeichenfolgen bedeutender AI-Crawler:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Crawler-Name
Zweck
Beispiel User-Agent
IP-Verifizierung
GPTBot
Trainingsdatensammlung
Mozilla/5.0…compatible; GPTBot/1.3
OpenAI-IP-Bereiche
ClaudeBot
Modelltraining
Mozilla/5.0…compatible; ClaudeBot/1.0
Anthropic-IP-Bereiche
OAI-SearchBot
Suchindizierung
Mozilla/5.0…compatible; OAI-SearchBot/1.3
OpenAI-IP-Bereiche
PerplexityBot
Suchindizierung
Mozilla/5.0…compatible; PerplexityBot/1.0
Perplexity-IP-Bereiche
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Mehrere namhafte AI-Unternehmen betreiben eigene Crawler mit unterschiedlichen User-Agent-Kennungen und Einsatzbereichen. Diese Crawler repräsentieren verschiedene Anwendungsfälle im AI-Ökosystem:
GPTBot (OpenAI): Sammelt Trainingsdaten für ChatGPT und andere OpenAI-Modelle, beachtet robots.txt-Anweisungen
ClaudeBot (Anthropic): Sammelt Inhalte für das Training von Claude-Modellen, kann via robots.txt gesperrt werden
OAI-SearchBot (OpenAI): Indiziert Webinhalte speziell für Suchfunktionen und AI-gestützte Suche
PerplexityBot (Perplexity AI): Durchsucht das Web für Suchergebnisse und Recherchefunktionen auf der eigenen Plattform
Gemini-Deep-Research (Google): Führt Deep-Research-Aufgaben für Googles Gemini-AI-Modell durch
Meta-ExternalAgent (Meta): Sammelt Daten für Metas AI-Trainings- und Forschungsinitiativen
Bingbot (Microsoft): Dient sowohl der klassischen Suchindizierung als auch der AI-gestützten Antwortgenerierung
Jeder Crawler hat spezifische IP-Bereiche und offizielle Dokumentationen, die Websitebetreiber zur Verifizierung der Legitimität und Steuerung des Zugriffs heranziehen können.
User-Agent-Spoofing und Verifizierungsprobleme
User-Agent-Zeichenfolgen können von jedem Client, der eine HTTP-Anfrage stellt, leicht gefälscht werden und sind daher als alleiniger Authentifizierungsmechanismus für die Identifikation legitimer AI-Crawler unzureichend. Bösartige Bots verwenden oft beliebte User-Agent-Kennungen, um ihre wahre Identität zu verschleiern und Sicherheitsmechanismen oder robots.txt-Beschränkungen zu umgehen. Um diese Schwachstelle zu adressieren, empfehlen Sicherheitsexperten die zusätzliche Nutzung von IP-Verifizierung: Es wird geprüft, ob Anfragen aus den offiziellen von AI-Unternehmen veröffentlichten IP-Bereichen stammen. Der neue Standard RFC 9421 HTTP Message Signatures ermöglicht kryptografische Verifizierung – Crawler signieren ihre Anfragen digital, Server können die Echtheit prüfen. Dennoch bleibt die Unterscheidung zwischen echten und gefälschten Crawlern herausfordernd, da entschlossene Angreifer auch IP-Adressen über Proxies oder kompromittierte Infrastruktur spoofen können. Dieses Katz-und-Maus-Spiel zwischen Crawler-Betreibern und sicherheitsbewussten Websitebetreibern entwickelt sich laufend mit neuen Verifikationsmethoden weiter.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Einsatz von robots.txt mit User-Agent-Direktiven
Websitebetreiber können den Crawlerzugriff steuern, indem sie in ihrer robots.txt gezielte User-Agent-Direktiven festlegen. Damit lässt sich granular bestimmen, welche Crawler auf welche Bereiche der Site zugreifen dürfen. Die robots.txt nutzt User-Agent-Kennungen, um einzelnen Crawlern spezifische Regeln zuzuweisen – so können einige Crawler zugelassen, andere ausgesperrt werden. Beispielkonfiguration:
Web Application Firewall (WAF) kann Anfragen aus nicht autorisierten IP-Bereichen blockieren
Die Kombination aus robots.txt und IP-Verifizierung schafft eine robustere Zugriffskontrolle
Analyse von Crawler-Aktivitäten durch Server-Logs
Websitebetreiber können Server-Logs auswerten, um AI-Crawler-Aktivitäten zu verfolgen und so zu erkennen, welche AI-Systeme auf ihre Inhalte zugreifen und wie häufig. Durch die Analyse von HTTP-Request-Logs und das Filtern nach bekannten AI-Crawler-User-Agents gewinnen Administratoren Einblick in Bandbreitenbelastung und Datenzugriffsverhalten verschiedener AI-Unternehmen. Tools wie Log-Analysetools, Web-Analytics-Dienste oder eigene Skripte können Server-Logs nach Crawler-Traffic durchsuchen, Anfrageraten messen und Datenvolumen berechnen. Diese Transparenz ist besonders wichtig für Content-Ersteller und Publisher, die wissen möchten, wie ihre Inhalte für AI-Training genutzt werden und ob sie Zugriffsrestriktionen erwägen sollten. Dienste wie AmICited.com spielen hier eine entscheidende Rolle, indem sie überwachen, wie AI-Systeme Inhalte aus dem Web zitieren und referenzieren – so erhalten Ersteller Transparenz über die Nutzung ihrer Inhalte im AI-Training. Das Verständnis der Crawler-Aktivitäten unterstützt Websitebetreiber dabei, fundierte Entscheidungen zu Content-Richtlinien zu treffen und mit AI-Unternehmen über Nutzungsrechte zu verhandeln.
Best Practices zur Verwaltung von AI-Crawler-Zugriffen
Für ein effektives Management des AI-Crawler-Zugriffs empfiehlt sich ein mehrschichtiger Ansatz, der mehrere Prüf- und Überwachungstechniken kombiniert:
User-Agent-Prüfung mit IP-Verifizierung kombinieren – Verlassen Sie sich nie allein auf User-Agent-Zeichenfolgen; prüfen Sie immer gegen die offiziellen von AI-Anbietern veröffentlichten IP-Bereiche
Aktuelle IP-Whitelists pflegen – Überprüfen und aktualisieren Sie regelmäßig Ihre Firewall-Regeln mit den neuesten IP-Bereichen von OpenAI, Anthropic, Google und anderen AI-Providern
Regelmäßige Analyse der Server-Logs implementieren – Planen Sie regelmäßige Auswertungen der Server-Logs, um verdächtige Crawler-Aktivitäten und unbefugte Zugriffsversuche zu erkennen
Zwischen Crawler-Typen unterscheiden – Unterscheiden Sie zwischen Trainings-Crawlern (GPTBot, ClaudeBot) und Such-Crawlern (OAI-SearchBot, PerplexityBot), um gezielte Zugriffsrichtlinien anzuwenden
Ethische Implikationen berücksichtigen – Balancieren Sie Zugangsbeschränkungen mit dem Wissen, dass AI-Training von vielfältigen, hochwertigen Content-Quellen profitiert
Monitoring-Services nutzen – Verwenden Sie Plattformen wie AmICited.com, um nachzuvollziehen, wie Ihre Inhalte von AI-Systemen genutzt und zitiert werden – für korrekte Attribution und mehr Verständnis über die Wirkung Ihrer Inhalte
Mit diesen Maßnahmen behalten Websitebetreiber die Kontrolle über ihre Inhalte und unterstützen gleichzeitig die verantwortungsvolle Entwicklung von AI-Systemen.
Häufig gestellte Fragen
Was ist eine User-Agent-Zeichenfolge?
Ein User-Agent ist eine HTTP-Header-Zeichenfolge, die den Client identifiziert, der eine Webanfrage stellt. Sie enthält Informationen über die Software, das Betriebssystem und die Version der anfragenden Anwendung, egal ob Browser, Crawler oder Bot. Diese Zeichenfolge ermöglicht es Webservern, verschiedene Typen von Clients zu identifizieren und deren Zugriff auf Inhalte nachzuverfolgen.
Warum benötigen AI-Crawler User-Agent-Strings?
User-Agent-Zeichenfolgen ermöglichen es Webservern, zu erkennen, welcher Crawler auf ihre Inhalte zugreift. Dadurch können Websitebetreiber den Zugriff steuern, Crawler-Aktivitäten nachverfolgen und verschiedene Bot-Typen unterscheiden. Dies ist entscheidend für die Bandbreitenverwaltung, den Schutz von Inhalten und um zu verstehen, wie AI-Systeme Ihre Daten verwenden.
Können User-Agent-Zeichenfolgen gefälscht werden?
Ja, User-Agent-Zeichenfolgen können leicht gefälscht werden, da sie nur Textwerte in HTTP-Headern sind. Deshalb sind IP-Verifizierung und HTTP Message Signatures wichtige zusätzliche Prüfmöglichkeiten, um die wahre Identität eines Crawlers zu bestätigen und zu verhindern, dass bösartige Bots legitime Crawler imitieren.
Wie blockiere ich bestimmte AI-Crawler?
Sie können robots.txt mit User-Agent-Direktiven verwenden, um Crawler zu bitten, Ihre Seite nicht zu besuchen – dies ist jedoch nicht erzwingbar. Für stärkere Kontrolle nutzen Sie serverseitige Verifizierung, IP-Whitelisting/Blacklisting oder WAF-Regeln, die User-Agent und IP-Adresse gleichzeitig prüfen.
Was ist der Unterschied zwischen GPTBot und OAI-SearchBot?
GPTBot ist OpenAI's Crawler zur Sammlung von Trainingsdaten für AI-Modelle wie ChatGPT, während OAI-SearchBot für die Suchindizierung und Suche in ChatGPT entwickelt wurde. Sie haben unterschiedliche Zwecke, Crawling-Raten und IP-Bereiche, was verschiedene Zugangskontrollstrategien erfordert.
Wie kann ich überprüfen, ob ein Crawler legitim ist?
Prüfen Sie die IP-Adresse des Crawlers anhand der offiziellen IP-Liste des Crawler-Betreibers (z.B. openai.com/gptbot.json für GPTBot). Legitime Crawler veröffentlichen ihre IP-Bereiche, und Sie können überprüfen, ob Anfragen aus diesen Bereichen stammen – etwa mit Firewall- oder WAF-Konfigurationen.
Was ist HTTP Message Signature Verification?
HTTP Message Signatures (RFC 9421) ist eine kryptografische Methode, bei der Crawler ihre Anfragen mit einem privaten Schlüssel signieren. Server können die Signatur mit dem öffentlichen Schlüssel aus dem .well-known-Verzeichnis des Crawlers prüfen, wodurch die Echtheit der Anfrage bestätigt und Manipulation ausgeschlossen wird.
Wie unterstützt AmICited.com das Monitoring von AI-Crawlern?
AmICited.com überwacht, wie AI-Systeme Ihre Marke in GPTs, Perplexity, Google AI Overviews und anderen AI-Plattformen referenzieren und zitieren. Es verfolgt Crawler-Aktivitäten und AI-Nennungen, damit Sie Ihre Sichtbarkeit in AI-generierten Antworten verstehen und wissen, wie Ihre Inhalte genutzt werden.
Überwachen Sie Ihre Marke in AI-Systemen
Verfolgen Sie, wie AI-Crawler Ihre Inhalte in ChatGPT, Perplexity, Google AI Overviews und anderen AI-Plattformen mit AmICited referenzieren und zitieren.
So erkennen Sie KI-Crawler in Server-Logs: Vollständiger Leitfaden zur Erkennung
Erfahren Sie, wie Sie KI-Crawler wie GPTBot, PerplexityBot und ClaudeBot in Ihren Server-Logs identifizieren und überwachen. Entdecken Sie User-Agent-Strings, M...
Welche KI-Crawler sollte ich zulassen? Vollständiger Leitfaden für 2025
Erfahren Sie, welche KI-Crawler Sie in Ihrer robots.txt zulassen oder blockieren sollten. Umfassender Leitfaden zu GPTBot, ClaudeBot, PerplexityBot und 25+ KI-C...
So erlaubst du KI-Bots das Crawlen deiner Website: Umfassender robots.txt- & llms.txt-Leitfaden
Erfahre, wie du KI-Bots wie GPTBot, PerplexityBot und ClaudeBot das Crawlen deiner Website erlaubst. Konfiguriere robots.txt, richte llms.txt ein und optimiere ...
12 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.