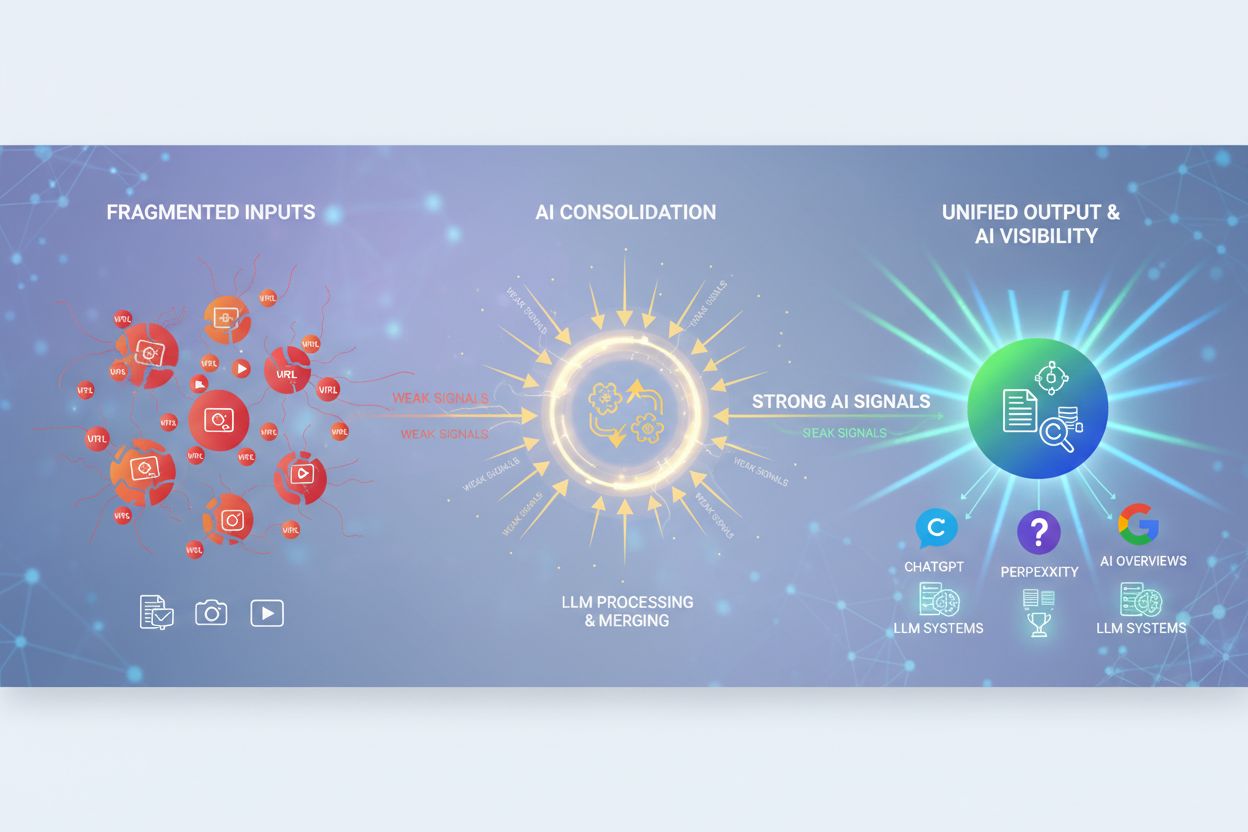
KI-Inhaltskonsolidierung
Erfahren Sie, was KI-Inhaltskonsolidierung ist und wie das Zusammenführen ähnlicher Inhalte die Sichtbarkeitssignale für ChatGPT, Perplexity und Google AI Overv...
10 Min. Lesezeit
KI-Deduplizierungslogik bezeichnet die automatisierten Prozesse und Algorithmen, die KI-Systeme verwenden, um redundante oder doppelte Informationen aus mehreren Quellen zu identifizieren, zu analysieren und zu eliminieren. Diese Systeme setzen Techniken wie maschinelles Lernen, natürliche Sprachverarbeitung und Ähnlichkeitsabgleiche ein, um identische oder sehr ähnliche Inhalte über verschiedene Datenbestände hinweg zu erkennen. Dadurch wird die Datenqualität sichergestellt, Speicherplatzkosten werden reduziert und die Genauigkeit von Entscheidungsprozessen verbessert.
KI-Deduplizierungslogik bezeichnet die automatisierten Prozesse und Algorithmen, die KI-Systeme verwenden, um redundante oder doppelte Informationen aus mehreren Quellen zu identifizieren, zu analysieren und zu eliminieren. Diese Systeme setzen Techniken wie maschinelles Lernen, natürliche Sprachverarbeitung und Ähnlichkeitsabgleiche ein, um identische oder sehr ähnliche Inhalte über verschiedene Datenbestände hinweg zu erkennen. Dadurch wird die Datenqualität sichergestellt, Speicherplatzkosten werden reduziert und die Genauigkeit von Entscheidungsprozessen verbessert.
KI-Deduplizierungslogik ist ein ausgeklügeltes algorithmisches Verfahren, das mit Hilfe von Künstlicher Intelligenz und maschinellem Lernen doppelte oder nahezu doppelte Datensätze in umfangreichen Datenbeständen erkennt und entfernt. Diese Technologie erkennt automatisch, wenn mehrere Einträge dieselbe Entität repräsentieren – unabhängig davon, ob es sich um eine Person, ein Produkt, ein Dokument oder eine Information handelt – selbst bei Unterschieden in Formatierung, Schreibweise oder Darstellung. Das Hauptziel der Deduplizierung ist die Sicherung der Datenintegrität und die Vermeidung von Redundanzen, die Analysen verfälschen, Speicherplatzkosten erhöhen und die Genauigkeit von Entscheidungen beeinträchtigen können. In der heutigen datengetriebenen Welt, in der Organisationen täglich Millionen von Datensätzen verarbeiten, ist eine effektive Deduplizierung unerlässlich für effiziente Abläufe und zuverlässige Erkenntnisse.
KI-Deduplizierung nutzt mehrere sich ergänzende Techniken, um ähnliche Datensätze mit bemerkenswerter Präzision zu identifizieren und zu gruppieren. Der Prozess beginnt mit der Analyse von Datenattributen – wie Namen, Adressen, E-Mail-Adressen und anderen Identifikatoren – und deren Vergleich mit festgelegten Ähnlichkeitsschwellen. Moderne Deduplizierungssysteme kombinieren phonetische Abgleiche, Zeichenfolgen-Ähnlichkeitsalgorithmen und semantische Analysen, um Duplikate zu erkennen, die traditionelle regelbasierte Systeme übersehen würden. Das System vergibt Ähnlichkeitswerte an potenzielle Übereinstimmungen und gruppiert Datensätze, die den eingestellten Schwellenwert überschreiten, zu Einheiten, die dieselbe Entität repräsentieren. Nutzer behalten die Kontrolle über das Inklusionsniveau der Deduplizierung und können die Sensitivität an ihren Anwendungsfall und die Toleranz für Fehlalarme anpassen.
| Methode | Beschreibung | Am besten geeignet für |
|---|---|---|
| Phonetische Ähnlichkeit | Gruppiert Zeichenfolgen, die ähnlich klingen (z. B. “Smith” vs “Smyth”) | Namensvariationen, phonetische Verwechslungen |
| Rechtschreibähnlichkeit | Gruppiert Zeichenfolgen mit ähnlicher Schreibweise | Tippfehler, kleine Schreibvarianten |
| TFIDF-Ähnlichkeit | Nutzt den Termfrequenz-Inverse-Dokumentfrequenz-Algorithmus | Allgemeines Textmatching, Dokumentähnlichkeit |
Die Deduplizierungs-Engine verarbeitet Datensätze in mehreren Durchgängen: Zunächst werden offensichtliche Übereinstimmungen erkannt, danach zunehmend subtilere Varianten überprüft. Dieser gestufte Ansatz gewährleistet eine umfassende Abdeckung bei gleichzeitiger Effizienz – auch bei der Verarbeitung von Datenbeständen mit Millionen von Einträgen.
Moderne KI-Deduplizierung nutzt Vektor-Embeddings und semantische Analysen, um die Bedeutung hinter Daten zu verstehen, anstatt nur oberflächliche Merkmale zu vergleichen. Natürliche Sprachverarbeitung (NLP) ermöglicht es Systemen, Kontext und Absicht zu erfassen – so erkennt das System beispielsweise, dass „Robert“, „Bob“ und „Rob“ dieselbe Person meinen, obwohl die Formen unterschiedlich sind. Fuzzy-Matching-Algorithmen ermitteln die Editierdistanz zwischen Zeichenfolgen und identifizieren Datensätze, die sich nur um wenige Zeichen unterscheiden – entscheidend, um Tipp- und Übertragungsfehler zu erfassen. Das System analysiert außerdem Metadaten wie Zeitstempel, Erstellungsdaten und Änderungshistorien, um bei der Bewertung von Duplikaten zusätzliche Sicherheit zu gewinnen. Fortgeschrittene Implementierungen integrieren maschinelle Lernmodelle, die auf gelabelten Datensätzen trainiert wurden, und steigern ihre Genauigkeit kontinuierlich, je mehr Daten verarbeitet und Rückmeldungen zu Deduplizierungsentscheidungen gesammelt werden.
Die KI-Deduplizierungslogik ist heute in praktisch jedem Sektor, der umfangreiche Datenbestände verwaltet, unverzichtbar. Organisationen setzen diese Technologie ein, um saubere, zuverlässige Datensätze zu erhalten, die präzise Analysen und fundierte Entscheidungen ermöglichen. Die praktischen Einsatzbereiche erstrecken sich über zahlreiche wichtige Geschäftsprozesse:

Diese Anwendungsfälle zeigen, wie Deduplizierung Compliance, Betrugsprävention und operative Integrität in verschiedensten Branchen direkt beeinflusst.
Die finanziellen und betrieblichen Vorteile der KI-Deduplizierung sind erheblich und messbar. Organisationen können durch das Entfernen redundanter Daten die Speicherkosten deutlich senken – manche Umsetzungen erreichen Reduzierungen des Speicherbedarfs um 20-40 %. Verbesserte Datenqualität führt direkt zu besseren Analysen und Entscheidungen, da Auswertungen auf sauberen Daten zuverlässigere Erkenntnisse und Prognosen liefern. Untersuchungen zeigen, dass Datenwissenschaftler rund 80 % ihrer Zeit für die Datenaufbereitung aufwenden, wobei doppelte Datensätze einen wesentlichen Teil dieser Arbeit ausmachen – automatisierte Deduplizierung gibt Analysten Zeit für wertschöpfende Aufgaben zurück. Studien haben ergeben, dass 10-30 % der Datensätze in typischen Datenbanken Duplikate enthalten – eine erhebliche Quelle für Ineffizienz und Fehler. Neben Kostensenkungen stärkt Deduplizierung auch Compliance und regulatorische Anforderungen, da sie eine korrekte Dokumentation sicherstellt und Mehrfacheinreichungen vermeidet, die Prüfungen oder Strafen auslösen könnten. Die Effizienzvorteile erstrecken sich auf schnellere Abfragen, geringere Rechenlast und verbesserte Systemstabilität.
Trotz ihrer Leistungsfähigkeit birgt die KI-Deduplizierung Herausforderungen und Einschränkungen, die von Organisationen sorgfältig beachtet werden müssen. Fehlalarme – also das fälschliche Zusammenführen unterschiedlicher Datensätze – können zu Datenverlust oder vermischten Informationen führen, die eigentlich getrennt bleiben sollten, während Fehlverpassungen dazu führen, dass echte Duplikate übersehen werden. Die Komplexität der Deduplizierung steigt exponentiell, wenn mehrformatige Daten aus verschiedenen Systemen, Sprachen und Datenstrukturen mit unterschiedlichen Formatierungs- und Kodierungsstandards verarbeitet werden müssen. Datenschutz- und Sicherheitsaspekte werden relevant, wenn für die Deduplizierung sensible Informationen analysiert werden – hier sind starke Verschlüsselung und Zugriffskontrollen während des Abgleichs unerlässlich. Die Genauigkeit von Deduplizierungssystemen hängt zudem grundlegend von der Qualität der Eingangsdaten ab: Schlechte oder unvollständige Daten können auch die besten Algorithmen in die Irre führen.
KI-Deduplizierung ist heute ein zentraler Bestandteil moderner KI-Antwortüberwachungsplattformen und Suchsysteme, die Informationen aus vielen Quellen aggregieren. Wenn KI-Systeme Antworten aus zahlreichen Dokumenten und Quellen zusammenstellen, sorgt die Deduplizierung dafür, dass identische Informationen nicht mehrfach gezählt werden – so werden Vertrauenswerte und Relevanzrankings nicht künstlich erhöht oder verfälscht. Quellenzuordnung wird aussagekräftiger, wenn die Deduplizierung redundante Quellen entfernt und Nutzern die tatsächliche Vielfalt der Evidenz hinter einer Antwort zeigt. Plattformen wie AmICited.com nutzen Deduplizierungslogik, um eine transparente und genaue Quellenverfolgung zu ermöglichen – sie erkennen, wenn mehrere Quellen im Grunde identische Informationen enthalten, und fassen diese angemessen zusammen. So wird verhindert, dass KI-Antworten den Eindruck erwecken, breiter abgestützt zu sein, als sie tatsächlich sind, und die Integrität der Quellenzuordnung sowie die Glaubwürdigkeit der Antwort bleiben erhalten. Durch das Herausfiltern doppelter Quellen verbessert Deduplizierung die Qualität von KI-Suchergebnissen und stellt sicher, dass Nutzer tatsächlich unterschiedliche Perspektiven erhalten – statt mehrfach wiederholter Varianten derselben Information aus verschiedenen Quellen. Die Technologie stärkt letztlich das Vertrauen in KI-Systeme, indem sie eine klarere und ehrlichere Darstellung der Evidenz für KI-generierte Antworten bietet.
KI-Deduplizierung und Datenkomprimierung reduzieren beide das Datenvolumen, arbeiten jedoch unterschiedlich. Deduplizierung identifiziert und entfernt exakte oder nahezu doppelte Datensätze, behält nur eine Instanz und ersetzt andere durch Verweise. Datenkomprimierung hingegen codiert Daten effizienter, ohne Duplikate zu entfernen. Deduplizierung arbeitet auf Makroebene (gesamte Dateien oder Datensätze), während Komprimierung auf Mikroebene (einzelne Bits und Bytes) wirkt. Für Organisationen mit vielen doppelten Daten bietet die Deduplizierung typischerweise größere Einsparungen beim Speicherplatz.
KI verwendet mehrere ausgeklügelte Techniken, um nicht-exakte Duplikate zu erkennen. Phonetische Algorithmen erkennen Namen, die ähnlich klingen (z. B. 'Smith' vs 'Smyth'). Fuzzy Matching berechnet die Editierdistanz, um Datensätze zu finden, die sich nur durch wenige Zeichen unterscheiden. Vektor-Embeddings wandeln Text in mathematische Repräsentationen um, die semantische Bedeutung erfassen, sodass das System umformulierte Inhalte erkennt. Maschinelle Lernmodelle, die mit gelabelten Datensätzen trainiert wurden, lernen Muster, was in bestimmten Kontexten ein Duplikat ausmacht. Diese Techniken arbeiten zusammen, um Duplikate trotz Varianten in Rechtschreibung, Formatierung oder Darstellung zu identifizieren.
Deduplizierung kann die Speicherkosten erheblich senken, indem redundante Daten entfernt werden. Organisationen erreichen typischerweise eine Reduzierung des Speicherbedarfs um 20-40 % nach der Einführung effektiver Deduplizierung. Diese Einsparungen summieren sich im Laufe der Zeit, da neue Daten kontinuierlich dedupliziert werden. Neben der direkten Kostensenkung für Speicher reduziert Deduplizierung auch Aufwendungen für Datenmanagement, Backup-Prozesse und Systemwartung. Für große Unternehmen mit Millionen von Datensätzen können diese Einsparungen jährlich Hunderttausende Dollar betragen, was Deduplizierung zu einer Investition mit hoher Rendite macht.
Ja, moderne KI-Deduplizierungssysteme können mit unterschiedlichen Dateiformaten arbeiten, auch wenn dies eine anspruchsvollere Verarbeitung erfordert. Das System muss zunächst Daten aus verschiedenen Formaten (PDFs, Word-Dokumente, Tabellen, Datenbanken usw.) in eine vergleichbare Struktur bringen. Fortgeschrittene Implementierungen nutzen optische Zeichenerkennung (OCR) für gescannte Dokumente und formatspezifische Parser zur Extraktion relevanter Inhalte. Die Deduplizierungsgenauigkeit kann jedoch je nach Formatkomplexität und Datenqualität variieren. Die besten Ergebnisse erzielen Organisationen, wenn sie Deduplizierung auf strukturierte Daten in konsistenten Formaten anwenden, doch auch formatübergreifende Deduplizierung ist mit modernen KI-Techniken zunehmend möglich.
Deduplizierung verbessert die Suchergebnisse von KI, indem sie sicherstellt, dass Relevanzrankings eine tatsächliche Vielfalt an Quellen widerspiegeln und nicht nur Varianten derselben Information. Wenn mehrere Quellen identische oder nahezu identische Inhalte enthalten, konsolidiert die Deduplizierung diese, um eine künstliche Erhöhung der Vertrauenswerte zu verhindern. So erhalten Nutzer eine klarere und ehrlichere Darstellung der Evidenz für KI-generierte Antworten. Deduplizierung steigert auch die Suchleistung, da das System weniger Daten verarbeiten muss und somit Anfragen schneller beantwortet werden. Durch das Herausfiltern redundanter Quellen können sich KI-Systeme auf tatsächlich unterschiedliche Perspektiven und Informationen konzentrieren und liefern letztlich hochwertigere und vertrauenswürdigere Ergebnisse.
Fehlalarme (False Positives) entstehen, wenn bei der Deduplizierung unterschiedliche Datensätze fälschlicherweise als Duplikate erkannt und zusammengeführt werden. Zum Beispiel werden Datensätze von 'John Smith' und 'Jane Smith', die unterschiedliche Personen sind, aber denselben Nachnamen tragen, zusammengeführt. Fehlalarme sind problematisch, weil sie zu dauerhaftem Datenverlust führen – einmal zusammengeführte Datensätze lassen sich nur schwer oder gar nicht wieder trennen. In kritischen Anwendungen wie dem Gesundheitswesen oder dem Finanzbereich können Fehlalarme schwerwiegende Folgen haben, etwa fehlerhafte Krankengeschichten oder betrügerische Transaktionen. Organisationen müssen die Empfindlichkeit der Deduplizierung sorgfältig kalibrieren, um Fehlalarme zu minimieren und akzeptieren oft einige Fehlverpassungen (False Negatives) als die sicherere Alternative.
Deduplizierung ist für KI-Content-Monitoring-Plattformen wie AmICited unerlässlich, die verfolgen, wie KI-Systeme auf Marken und Quellen verweisen. Bei der Überwachung von KI-Antworten über verschiedene Plattformen hinweg (GPTs, Perplexity, Google AI) verhindert die Deduplizierung, dass dieselbe Quelle mehrfach gezählt wird, wenn sie in unterschiedlichen KI-Systemen oder Formaten auftaucht. Das sorgt für eine genaue Zuordnung und verhindert verfälschte Sichtbarkeitsmetriken. Deduplizierung hilft zudem zu erkennen, wenn KI-Systeme trotz scheinbar vielfältiger Belege im Wesentlichen auf einen kleinen Quellensatz zurückgreifen. Durch die Zusammenführung doppelter Quellen liefern Monitoring-Plattformen klarere Einblicke, welche einzigartigen Quellen tatsächlich Einfluss auf KI-Antworten haben.
Metadaten – Informationen über Daten wie Erstellungsdatum, Änderungszeitpunkte, Autorendaten und Dateieigenschaften – spielen eine entscheidende Rolle bei der Duplikaterkennung. Metadaten helfen, den Lebenszyklus von Datensätzen zu bestimmen und zu erkennen, wann Dokumente erstellt, aktualisiert oder genutzt wurden. Diese zeitlichen Informationen helfen, legitime Versionen fortlaufend entwickelter Dokumente von echten Duplikaten zu unterscheiden. Angaben zu Autoren oder Abteilungen liefern Kontext zur Herkunft und zum Zweck eines Datensatzes. Zugriffsmuster zeigen, ob Dokumente aktiv genutzt oder veraltet sind. Fortgeschrittene Deduplizierungssysteme kombinieren Metadatenanalyse mit Inhaltsanalyse und nutzen beide Signale, um Duplikate genauer zu bestimmen und die maßgebliche Version als autoritative Quelle zu identifizieren.
AmICited verfolgt, wie KI-Systeme wie GPTs, Perplexity und Google AI auf Ihre Marke in verschiedenen Quellen verweisen. Sorgen Sie für eine korrekte Quellenzuordnung und verhindern Sie, dass doppelte Inhalte Ihre KI-Sichtbarkeit verfälschen.
Erfahren Sie, was KI-Inhaltskonsolidierung ist und wie das Zusammenführen ähnlicher Inhalte die Sichtbarkeitssignale für ChatGPT, Perplexity und Google AI Overv...

Erfahren Sie, wie kanonische URLs Duplicate-Content-Probleme in KI-Suchsystemen verhindern. Entdecken Sie Best Practices für die Implementierung von Canonicals,...

Erfahren Sie, wie Sie Ihre Inhalte für KI-Suchmaschinen wie ChatGPT, Perplexity und Gemini konsolidieren und optimieren. Entdecken Sie Best Practices für Strukt...