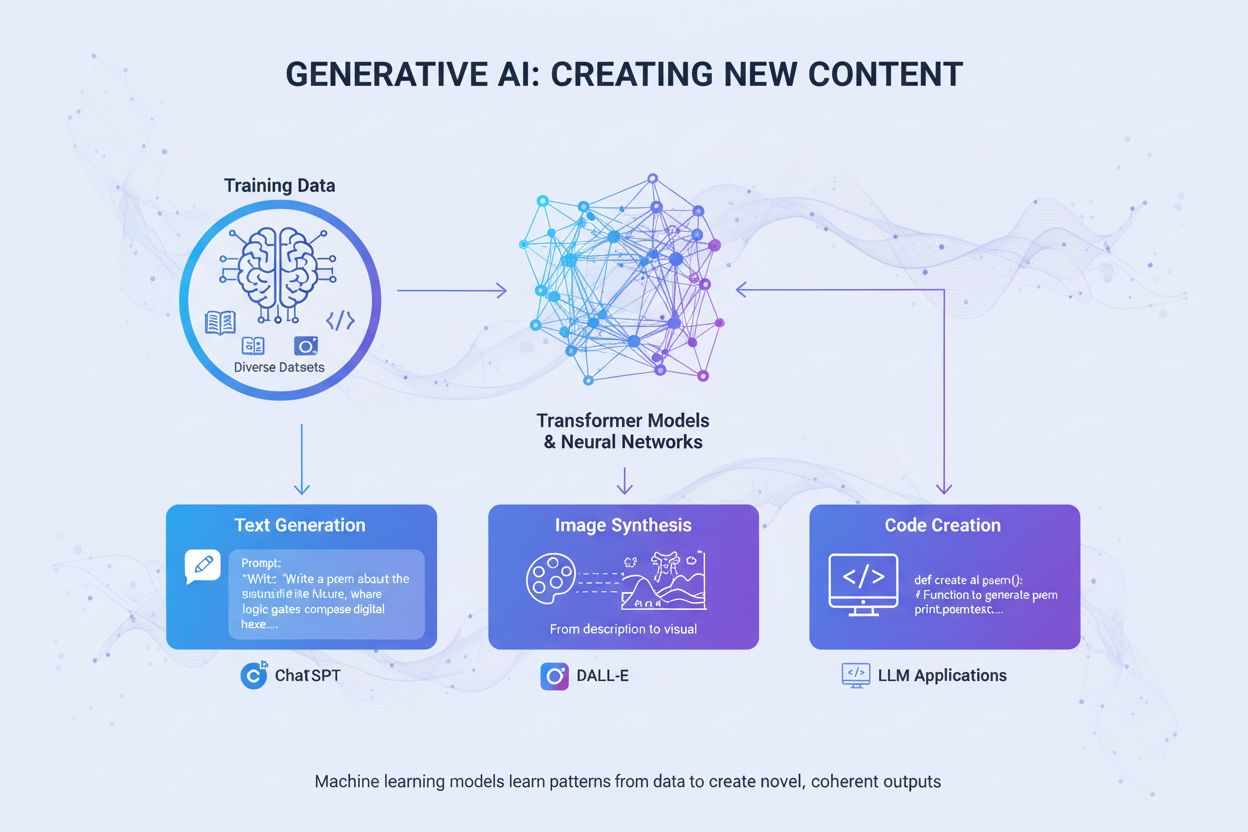
Generative KI
Generative KI erstellt mit neuronalen Netzwerken neue Inhalte aus Trainingsdaten. Erfahren Sie, wie sie funktioniert, ihre Anwendungen in ChatGPT und DALL-E und...
11 Min. Lesezeit
Ein KI-generiertes Bild ist ein digitales Bild, das von Algorithmen der künstlichen Intelligenz und maschinellen Lernmodellen erstellt wird, anstatt von menschlichen Künstlern oder Fotografen. Diese Bilder entstehen durch das Trainieren neuronaler Netzwerke mit umfangreichen Datensätzen beschrifteter Bilder, sodass die KI visuelle Muster erlernt und aus Texteingaben, Skizzen oder anderen Eingangsdaten originelle, realistische Visualisierungen erzeugen kann.
Ein KI-generiertes Bild ist ein digitales Bild, das von Algorithmen der künstlichen Intelligenz und maschinellen Lernmodellen erstellt wird, anstatt von menschlichen Künstlern oder Fotografen. Diese Bilder entstehen durch das Trainieren neuronaler Netzwerke mit umfangreichen Datensätzen beschrifteter Bilder, sodass die KI visuelle Muster erlernt und aus Texteingaben, Skizzen oder anderen Eingangsdaten originelle, realistische Visualisierungen erzeugen kann.
Ein KI-generiertes Bild ist ein digitales Bild, das von Algorithmen der künstlichen Intelligenz und maschinellen Lernmodellen erstellt wird – und nicht von menschlichen Künstlern oder Fotografen. Diese Bilder entstehen durch fortschrittliche neuronale Netzwerke, die mit riesigen Datensätzen beschrifteter Bilder trainiert wurden, sodass die KI visuelle Muster, Stile und Beziehungen zwischen Konzepten erlernt. Die Technologie ermöglicht es KI-Systemen, originelle, realistische Visualisierungen aus verschiedenen Inputs zu erzeugen – am häufigsten aus Texteingaben, aber auch aus Skizzen, Referenzbildern oder anderen Datenquellen. Im Gegensatz zu traditioneller Fotografie oder manueller Kunst können KI-generierte Bilder alles Vorstellbare abbilden, darunter unmögliche Szenarien, fantastische Welten und abstrakte Konzepte, die in der physischen Realität nie existiert haben. Der Prozess ist bemerkenswert schnell und liefert oft hochwertige Bilder in Sekunden – eine transformative Technologie für Kreativbranchen, Marketing, Produktdesign und Content-Erstellung.
Die Entwicklung der KI-Bildgenerierung begann mit grundlegender Forschung im Bereich Deep Learning und neuronaler Netzwerke, doch erst Anfang der 2020er Jahre wurde die Technologie zum Mainstream. Generative Adversarial Networks (GANs), eingeführt von Ian Goodfellow im Jahr 2014, waren einer der ersten erfolgreichen Ansätze und nutzten zwei konkurrierende neuronale Netzwerke zur Erstellung realistischer Bilder. Der eigentliche Durchbruch erfolgte jedoch mit dem Aufkommen von Diffusionsmodellen und auf Transformern basierenden Architekturen, die stabiler waren und qualitativ hochwertigere Ergebnisse lieferten. 2022 wurde Stable Diffusion als Open-Source-Modell veröffentlicht, wodurch der Zugang zu KI-Bildgenerierung demokratisiert und die breite Nutzung ausgelöst wurde. Kurz darauf sorgten DALL-E 2 von OpenAI und Midjourney für große Aufmerksamkeit und brachten KI-generierte Bilder ins öffentliche Bewusstsein. Laut aktuellen Statistiken sind 71% der Social-Media-Bilder inzwischen KI-generiert, und der globale Markt für KI-Bildgeneratoren wurde 2023 auf 299,2 Millionen US-Dollar geschätzt – mit einer Wachstumsprognose von 17,4% jährlich bis 2030. Dieses explosive Wachstum spiegelt die technologische Reife und breite geschäftliche Nutzung in verschiedensten Branchen wider.
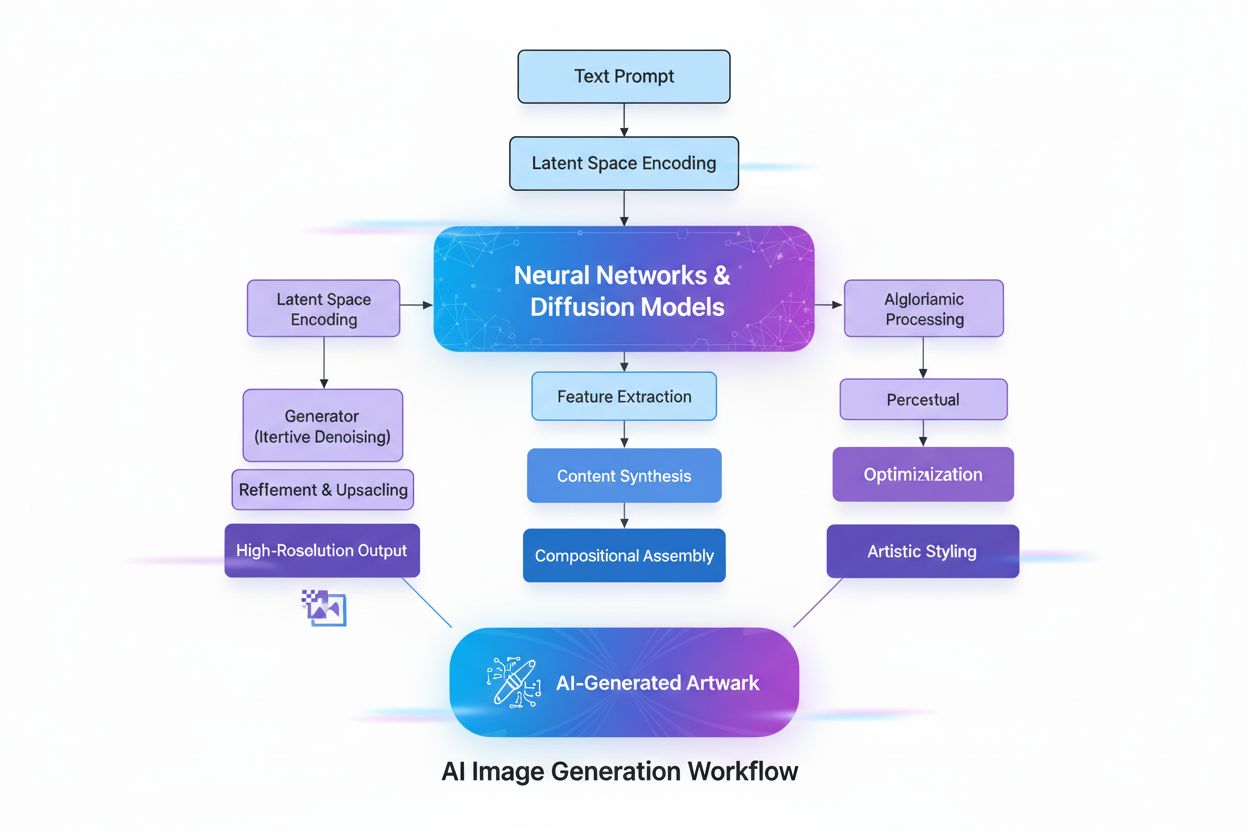
Die Erstellung von KI-generierten Bildern umfasst mehrere hochentwickelte technische Prozesse, die zusammenspielen, um abstrakte Konzepte visuell umzusetzen. Der Prozess beginnt mit dem Textverständnis durch Natural Language Processing (NLP), bei dem die KI menschliche Sprache in numerische Repräsentationen, sogenannte Einbettungen, umwandelt. Modelle wie CLIP (Contrastive Language-Image Pre-training) verschlüsseln Texteingaben in hochdimensionale Vektoren, die semantische Bedeutung und Kontext erfassen. Gibt ein Nutzer beispielsweise „ein roter Apfel auf einem Baum“ ein, zerlegt das NLP-Modell dies in numerische Koordinaten für „rot“, „Apfel“, „Baum“ und deren räumliche Beziehungen. Diese numerische Karte steuert anschließend den Bildgenerierungsprozess und dient der KI als Regelwerk, welche Komponenten enthalten sein und wie sie zusammenwirken sollen.
Diffusionsmodelle, die viele moderne KI-Bildgeneratoren wie DALL-E 2 und Stable Diffusion antreiben, arbeiten mit einem eleganten iterativen Verfahren. Das Modell beginnt mit reinem Zufallsrauschen – einem chaotischen Pixelmuster – und verfeinert dieses schrittweise durch mehrfache Entrauschungs-Iterationen. Während des Trainings lernt das Modell, den Prozess des Hinzufügens von Rauschen zu Bildern umzukehren, es lernt also, „verrauschte“ Versionen wieder in ihre Ursprungsform zu bringen. Bei der Generierung neuer Bilder wendet das Modell diesen gelernten Entrauschungsprozess in umgekehrter Richtung an, startet mit Rauschen und formt daraus schrittweise ein kohärentes Bild. Die Texteingabe steuert diese Transformation in jedem Schritt, sodass das Endergebnis mit der Nutzerbeschreibung übereinstimmt. Diese schrittweise Verfeinerung ermöglicht außergewöhnliche Kontrolle und liefert detaillierte, qualitativ hochwertige Bilder.
Generative Adversarial Networks (GANs) verfolgen einen grundlegend anderen Ansatz, der auf Spieltheorie basiert. Ein GAN besteht aus zwei konkurrierenden neuronalen Netzwerken: einem Generator, der aus Zufallseingaben künstliche Bilder erzeugt, und einem Diskriminator, der echte von gefälschten Bildern zu unterscheiden versucht. Diese Netzwerke liefern sich ein adversariales Spiel, wobei der Generator immer besser darin wird, den Diskriminator zu täuschen, während dieser immer besser echte von künstlichen Bildern unterscheidet. Diese Wettbewerbssituation treibt beide Netzwerke zu Höchstleistungen an und führt letztlich zu Bildern, die echten Fotos nahezu nicht mehr zu unterscheiden sind. GANs sind besonders effektiv zur Erzeugung fotorealistischer menschlicher Gesichter und für Stiltransfers, sind in der Praxis aber oft weniger stabil als Diffusionsmodelle.
Transformer-basierte Modelle bilden eine weitere Hauptarchitektur und adaptieren die ursprünglich für NLP entwickelte Transformer-Technologie. Sie sind besonders geschickt darin, komplexe Beziehungen innerhalb von Texteingaben zu verstehen und Sprach-Token in visuelle Merkmale zu übersetzen. Mithilfe von Self-Attention-Mechanismen erfassen sie Kontext und Relevanz und können so auch nuancierte, mehrteilige Prompts mit hoher Genauigkeit umsetzen. Transformer erzeugen Bilder, die detaillierten Textbeschreibungen sehr genau entsprechen, was sie ideal für Anwendungen macht, die präzise Kontrolle über die Bildausgabe erfordern.
| Technologie | Funktionsweise | Stärken | Schwächen | Beste Anwendungsfälle | Beispiel-Tools |
|---|---|---|---|---|---|
| Diffusionsmodelle | Iteratives Entrauschen von Zufallsrauschen zu strukturierten Bildern, gesteuert durch Texteingaben | Hochwertige, detailreiche Ergebnisse, exzellente Textausrichtung, stabiles Training, feine Kontrolle | Langsamerer Generierungsprozess, benötigt mehr Rechenleistung | Text-zu-Bild-Generierung, hochauflösende Kunst, wissenschaftliche Visualisierung | Stable Diffusion, DALL-E 2, Midjourney |
| GANs | Zwei konkurrierende neuronale Netzwerke (Generator und Diskriminator) erzeugen durch adversariales Training realistische Bilder | Schnelle Generierung, sehr gut für Fotorealismus, geeignet für Stiltransfer und Bildverbesserung | Instabiles Training, Mode Collapse, weniger präzise Textsteuerung | Fotorealistische Gesichter, Stiltransfer, Bildhochskalierung | StyleGAN, Progressive GAN, ArtSmart.ai |
| Transformer | Wandeln Texteingaben mittels Self-Attention und Token-Einbettungen in Bilder um | Herausragende Text-zu-Bild-Synthese, bewältigt komplexe Prompts, starke semantische Erfassung | Benötigt viel Rechenleistung, neuere Technologie mit weniger Optimierung | Kreative Bildgenerierung aus detailliertem Text, Design und Werbung, konzeptionelle Kunst | DALL-E 2, Runway ML, Imagen |
| Neural Style Transfer | Verschmilzt den Inhalt eines Bildes mit dem künstlerischen Stil eines anderen | Künstlerische Kontrolle, erhält den Inhalt bei Stilübernahme, nachvollziehbarer Prozess | Auf Stiltransfer beschränkt, benötigt Referenzbilder, weniger flexibel | Künstlerische Bildgestaltung, Stilübertragung, kreative Nachbearbeitung | DeepDream, Prisma, Artbreeder |
Die Einführung KI-generierter Bilder in geschäftlichen Bereichen erfolgt rasant und ist äußerst transformativ. Im E-Commerce und Einzelhandel nutzen Unternehmen KI-Bildgenerierung, um Produktfotos in großem Maßstab zu erstellen und teure Fotoshootings zu vermeiden. Laut aktuellen Daten erwarten 80% der Einzelhandelsverantwortlichen den Einsatz von KI-Automatisierung bis 2025, und Einzelhandelsunternehmen investierten 2023 rund 19,71 Milliarden US-Dollar in KI-Tools, wobei die Bildgenerierung einen bedeutenden Anteil ausmacht. Der Markt für KI-Bildbearbeitung wird 2025 auf 88,7 Milliarden US-Dollar geschätzt und soll bis 2034 auf 8,9 Milliarden US-Dollar wachsen, wobei Unternehmenskunden rund 42% der Ausgaben ausmachen.
Im Marketing und in der Werbung nutzen 62% der Marketer KI, um neue Bildinhalte zu erstellen, und Unternehmen, die KI für Social-Media-Content einsetzen, berichten von 15–25% höheren Engagement-Raten. Die Fähigkeit, schnell zahlreiche kreative Varianten zu generieren, ermöglicht A/B-Tests in nie dagewesenem Umfang und erlaubt Marketern eine datengestützte Optimierung ihrer Kampagnen. Das Cosmopolitan-Magazin sorgte im Juni 2022 für Schlagzeilen, als es erstmals ein Titelbild präsentierte, das vollständig von DALL-E 2 generiert wurde. Der verwendete Prompt lautete: „A wide angle shot from below of a female astronaut with an athletic female body walking with swagger on Mars in an infinite universe, synthwave, digital art.“
In der medizinischen Bildgebung werden KI-generierte Bilder zu Diagnosezwecken und zur Erzeugung synthetischer Daten eingesetzt. Studien zeigen, dass DALL-E 2 realistische Röntgenbilder aus Texteingaben generieren und sogar fehlende Elemente in radiologischen Aufnahmen rekonstruieren kann. Dies hat große Bedeutung für die medizinische Ausbildung, den datenschutzkonformen Austausch zwischen Institutionen und die Entwicklung neuer Diagnosetools. Der KI-getriebene Social-Media-Markt soll bis 2031 auf 12 Milliarden US-Dollar wachsen, gegenüber 2,1 Milliarden US-Dollar in 2021 – ein Zeichen für die zentrale Rolle der Technologie in der digitalen Inhaltserstellung.
Die schnelle Verbreitung KI-generierter Bilder wirft erhebliche ethische und rechtliche Fragen auf, mit denen sich Branche und Regulierungsbehörden weiterhin auseinandersetzen. Urheberrechts- und Eigentumsfragen sind dabei besonders umstritten. Die meisten KI-Bildgeneratoren werden mit riesigen Datensätzen trainiert, die Bilder aus dem Internet enthalten – viele davon sind urheberrechtlich geschützte Werke von Künstlern und Fotografen. Im Januar 2023 reichten drei Künstler eine wegweisende Klage gegen Stability AI, Midjourney und DeviantArt ein, da die Unternehmen urheberrechtlich geschützte Bilder ohne Zustimmung oder Vergütung zur KI-Trainierung nutzten. Dieser Fall steht exemplarisch für den breiteren Konflikt zwischen technischer Innovation und Künstlerrechten.
Die Frage nach Eigentum und Nutzungsrechten an KI-generierten Bildern ist rechtlich weiterhin ungeklärt. Als 2022 ein KI-generiertes Kunstwerk, eingereicht von Jason Allen mithilfe von Midjourney, den ersten Platz beim Kunstwettbewerb der Colorado State Fair gewann, entbrannte eine kontroverse Debatte. Viele argumentierten, dass ein von KI erschaffenes Werk nicht als originär menschliche Schöpfung qualifiziert. Das US Copyright Office hat angedeutet, dass Werke, die vollständig von KI ohne menschliche Kreativität geschaffen wurden, möglicherweise nicht urheberrechtlich geschützt werden – ein sich weiter entwickelndes Rechtsgebiet mit laufenden Verfahren und Regulierungsinitiativen.
Deepfakes und Desinformation sind eine weitere kritische Herausforderung. KI-Bildgeneratoren können täuschend echte Bilder von Ereignissen erstellen, die nie stattgefunden haben, und so die Verbreitung falscher Informationen ermöglichen. Im März 2023 kursierten KI-generierte Deepfake-Bilder einer angeblichen Verhaftung von Ex-Präsident Donald Trump auf Social Media, erzeugt mit Midjourney. Einige Nutzer hielten diese Bilder zunächst für echt, was das Missbrauchspotenzial der Technologie verdeutlicht. Die Raffinesse moderner KI-generierter Bilder erschwert deren Erkennung zunehmend, was Plattformen und Medien vor große Herausforderungen bei der Authentizitätsprüfung stellt.
Vorurteile in Trainingsdaten sind ein weiteres zentrales ethisches Problem. KI-Modelle lernen aus Datensätzen, die kulturelle, geschlechtliche oder rassistische Vorurteile enthalten können. Das Gender Shades Project von Joy Buolamwini am MIT Media Lab zeigte erhebliche Verzerrungen bei kommerziellen KI-Geschlechtsklassifikationssystemen, mit deutlich höheren Fehlerquoten bei dunkelhäutigen Frauen im Vergleich zu hellhäutigen Männern. Solche Verzerrungen können sich in der Bildgenerierung fortsetzen und schädliche Stereotype oder die Unterrepräsentation bestimmter Gruppen bewirken. Die Bekämpfung solcher Vorurteile erfordert sorgfältige Datenauswahl, vielfältige Trainingsdaten und kontinuierliche Überprüfung der Modellergebnisse.
Die Qualität KI-generierter Bilder hängt maßgeblich von der Qualität und Spezifität des Eingabe-Prompts ab. Prompt Engineering – die Kunst, effektive Texteingaben zu formulieren – ist zu einer zentralen Fähigkeit für Nutzer geworden, die optimale Ergebnisse erzielen möchten. Effektive Prompts zeichnen sich durch mehrere Merkmale aus: Sie sind spezifisch und detailliert statt vage, enthalten Stil- oder Medium-Beschreibungen (wie „digitale Malerei“, „Aquarell“ oder „fotorealistisch“), beinhalten Stimmungs- und Lichtinformationen (z.B. „goldene Stunde“, „filmisches Licht“ oder „dramatische Schatten“) und stellen klare Beziehungen zwischen den Elementen her.
Anstatt beispielsweise einfach „eine Katze“ zu verlangen, wäre ein effektiver Prompt: „eine flauschige orangefarbene Tabby-Katze sitzt auf einer Fensterbank bei Sonnenuntergang, warmes goldenes Licht fällt durch das Fenster, fotorealistisch, professionelle Fotografie“. Dieser Detaillierungsgrad liefert der KI klare Hinweise zu Aussehen, Umgebung, Licht und gewünschter Ästhetik. Untersuchungen zeigen, dass strukturierte Prompts mit klaren Informationshierarchien zu konsistenteren und zufriedenstellenderen Ergebnissen führen. Nutzer verwenden häufig Techniken wie die Angabe von Kunststilen, beschreibenden Adjektiven, technischen Fotobegriffen und sogar die Nennung bestimmter Künstler oder Kunstbewegungen, um die KI gezielt zu steuern.
Verschiedene KI-Bildgenerierungsplattformen haben eigene Besonderheiten, Stärken und Einsatzbereiche. DALL-E 2 von OpenAI erstellt detaillierte Bilder aus Texteingaben mit fortschrittlichen Inpainting- und Bearbeitungsfunktionen. Es basiert auf einem Credit-System, bei dem Nutzer Credits für einzelne Bildgenerierungen erwerben. DALL-E 2 ist für seine Vielseitigkeit und die Fähigkeit bekannt, komplexe, nuancierte Prompts zu verarbeiten, und daher besonders bei Profis und Kreativen beliebt.
Midjourney konzentriert sich auf künstlerische und stilisierte Bildkreationen und wird von Designern und Künstlern für seine besondere Ästhetik geschätzt. Die Plattform läuft über einen Discord-Bot, wobei Nutzer Prompts per /imagine-Kommando eingeben. Midjourney ist besonders bekannt für visuell ansprechende, malerische Bilder mit harmonischen Farben, ausgewogener Beleuchtung und scharfen Details. Die Abonnements reichen von 10 bis 120 US-Dollar pro Monat, wobei höhere Stufen mehr Bildgenerierungen pro Monat ermöglichen.
Stable Diffusion, entwickelt in Kooperation von Stability AI, EleutherAI und LAION, ist ein Open-Source-Modell, das die KI-Bildgenerierung demokratisiert. Die Open-Source-Natur erlaubt Entwicklern und Forschern individuelle Anpassung und Einsatz, ideal für experimentelle Projekte und Unternehmenslösungen. Stable Diffusion verwendet eine latente Diffusionsmodell-Architektur, sodass eine effiziente Generierung auch auf handelsüblichen Grafikkarten möglich ist. Die Plattform ist mit 0,0023 US-Dollar pro Bild preislich attraktiv, und für Neueinsteiger gibt es kostenlose Testphasen.
Googles Imagen ist ein weiteres bedeutendes Modell, das Text-zu-Bild-Diffusionsmodelle mit beispiellosem Fotorealismus und tiefem Sprachverständnis bietet. Diese Plattformen zeigen die Vielfalt der Ansätze und Geschäftsmodelle im Bereich der KI-Bildgenerierung und bedienen jeweils unterschiedliche Nutzerbedürfnisse und Anwendungsfälle.
Das Feld der KI-Bildgenerierung entwickelt sich rasant, wobei mehrere grundlegende Trends die Zukunft der Technologie bestimmen. Modellverbesserungen und Effizienzsteigerungen schreiten in hohem Tempo voran, neue Modelle liefern höhere Auflösungen, bessere Textausrichtung und schnellere Generierungszeiten. Der Markt für KI-Bildgeneratoren soll bis 2030 jährlich um 17,4% wachsen, was auf anhaltende Investitionen und Innovationen hindeutet. Zu den neuesten Entwicklungen zählen Videogenerierung aus Text, bei der KI-Modelle Bildgenerierungsfähigkeiten auf kurze Videoclips ausweiten; 3D-Modellgenerierung, mit der KI dreidimensionale Assets direkt erzeugen kann; und Echtzeit-Bildgenerierung, die Interaktivität und kreative Workflows ermöglicht.
Regulatorische Rahmenbedingungen entstehen weltweit, indem Regierungen und Branchenverbände Standards für Transparenz, Urheberrechtsschutz und ethische Nutzung entwickeln. Der NO FAKES Act und ähnliche Gesetzesinitiativen fordern etwa die Kennzeichnung KI-generierter Inhalte und die Offenlegung des KI-Einsatzes. 62% der globalen Marketer glauben, dass verpflichtende Labels für KI-generierte Inhalte positive Auswirkungen auf die Social-Media-Performance hätten, was die Bedeutung von Transparenz unterstreicht.
Die Integration mit anderen KI-Systemen beschleunigt sich, und Bildgenerierung wird zunehmend in übergeordnete Plattformen und Workflows eingebettet. Multimodale KI-Systeme, die Text, Bild, Audio und Video vereinen, werden immer leistungsfähiger. Auch die Personalisierung und Anpassung nimmt zu – KI-Modelle lassen sich auf bestimmte künstlerische Stile, Markenästhetik oder individuelle Vorlieben feinabstimmen. Mit der zunehmenden Verbreitung KI-generierter Bilder auf digitalen Plattformen wächst auch die Bedeutung von Markenüberwachung und Zitaten-Tracking in KI-Antworten. Tools, die verfolgen, wie Marken in KI-Inhalten erscheinen, werden für Unternehmen, die Sichtbarkeit und Autorität im Zeitalter generativer KI bewahren wollen, immer wichtiger.
KI-generierte Bilder werden vollständig von Algorithmen des maschinellen Lernens aus Texteingaben oder anderen Inputs erschaffen, während die traditionelle Fotografie reale Szenen durch eine Kamera einfängt. KI-Bilder können alles Vorstellbare darstellen, einschließlich unmöglicher Szenarien, wohingegen Fotografie auf das beschränkt ist, was existiert oder physisch inszeniert werden kann. Die Generierung durch KI ist in der Regel schneller und kostengünstiger als Fotoshootings zu organisieren und eignet sich daher ideal für schnelle Inhaltserstellung und Prototyping.
Diffusionsmodelle beginnen mit reinem Zufallsrauschen und verfeinern dieses schrittweise durch iterative Entrauschung. Die Texteingabe wird in numerische Einbettungen umgewandelt, die diesen Entrauschungsprozess steuern und das Rauschen allmählich in ein kohärentes Bild verwandeln, das der Beschreibung entspricht. Dieser schrittweise Ansatz ermöglicht präzise Kontrolle und liefert hochwertige, detailreiche Ergebnisse mit exzellenter Abstimmung auf den eingegebenen Text.
Die drei Haupttechnologien sind Generative Adversarial Networks (GANs), die konkurrierende neuronale Netzwerke zur Erstellung realistischer Bilder nutzen; Diffusionsmodelle, die schrittweise Rauschen in strukturierte Bilder entrauschen; und Transformer, die Texteingaben mittels Selbstaufmerksamkeits-Mechanismen in Bilder umwandeln. Jede Architektur hat eigene Stärken: GANs sind herausragend in Fotorealismus, Diffusionsmodelle liefern sehr detailreiche Ergebnisse, und Transformer meistern komplexe Text-zu-Bild-Synthese besonders gut.
Die Urheberrechtsfrage bei KI-generierten Bildern ist rechtlich weiterhin unklar und variiert je nach Rechtsraum. In vielen Fällen kann das Urheberrecht der Person gehören, die den Prompt erstellt hat, dem Entwickler des KI-Modells oder möglicherweise niemandem, wenn die KI autonom arbeitet. Das US Copyright Office hat angedeutet, dass Werke, die ausschließlich von KI ohne menschliche kreative Eingabe geschaffen wurden, möglicherweise nicht urheberrechtlich geschützt werden können, doch dieses Rechtsgebiet entwickelt sich weiter und steht im Mittelpunkt laufender Gerichtsverfahren und Regulierungsentwicklungen.
KI-generierte Bilder werden im E-Commerce für Produktfotografie, im Marketing für Kampagnenvisuals und Social Media Content, in der Spieleentwicklung für die Erstellung von Charakteren und Assets, in der medizinischen Bildgebung für diagnostische Visualisierung und in der Werbung für schnelles Konzept-Testing weit eingesetzt. Laut aktuellen Daten nutzen 62% der Marketer KI, um neue Bildressourcen zu erstellen, und der Markt für KI-Bildbearbeitung wird 2025 auf 88,7 Milliarden US-Dollar geschätzt – ein Zeichen für die breite Unternehmensadoption in verschiedensten Branchen.
Aktuelle KI-Bildgeneratoren haben Schwierigkeiten, anatomisch korrekte menschliche Hände und Gesichter zu erzeugen und produzieren oft unnatürliche Merkmale wie zusätzliche Finger oder asymmetrische Gesichtselemente. Sie sind zudem stark von der Qualität der Trainingsdaten abhängig, was Vorurteile einschleusen und die Vielfalt der generierten Ergebnisse einschränken kann. Außerdem erfordert das Erzielen spezifischer Details sorgfältiges Prompt-Engineering, und gelegentlich wirken die Resultate unnatürlich oder erfassen nicht die gewünschte kreative Nuance.
Die meisten KI-Bildgeneratoren werden mit riesigen Datensätzen aus Bildern trainiert, die aus dem Internet stammen – viele davon sind urheberrechtlich geschützt. Das hat zu erheblichen rechtlichen Auseinandersetzungen geführt, etwa durch Klagen von Künstlern gegen Unternehmen wie Stability AI und Midjourney, weil urheberrechtlich geschützte Bilder ohne Erlaubnis oder Vergütung verwendet wurden. Manche Plattformen wie Getty Images und Shutterstock haben KI-generierte Bild-Einreichungen aus diesen Gründen verboten, und regulatorische Rahmenbedingungen befinden sich noch in der Entwicklung, um Transparenz und faire Vergütung sicherzustellen.
Der globale Markt für KI-Bildgeneratoren wurde 2023 auf 299,2 Millionen US-Dollar geschätzt und soll mit einer jährlichen Wachstumsrate von 17,4% bis 2030 wachsen. Der breitere Markt für KI-Bildbearbeitung wird 2025 auf 88,7 Milliarden US-Dollar geschätzt und soll bis 2034 auf 8,9 Milliarden US-Dollar sinken. Zudem sind inzwischen 71% aller Social-Media-Bilder KI-generiert, und der KI-gesteuerte Social-Media-Markt soll bis 2031 auf 12 Milliarden US-Dollar wachsen – ein Zeichen für das explosive Wachstum und die breite Akzeptanz.
Beginnen Sie zu verfolgen, wie KI-Chatbots Ihre Marke auf ChatGPT, Perplexity und anderen Plattformen erwähnen. Erhalten Sie umsetzbare Erkenntnisse zur Verbesserung Ihrer KI-Präsenz.
Generative KI erstellt mit neuronalen Netzwerken neue Inhalte aus Trainingsdaten. Erfahren Sie, wie sie funktioniert, ihre Anwendungen in ChatGPT und DALL-E und...

Erfahren Sie, was individuelle Bilder und origineller visueller Inhalt sind, warum sie für Markenidentität, SEO und KI-Sichtbarkeit wichtig sind. Entdecken Sie,...

Erfahren Sie, was nutzergenerierte Inhalte für KI sind, wie sie zur Schulung von KI-Modellen verwendet werden, welche Anwendungen es branchenübergreifend gibt u...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.