
Feinabstimmung
Definition Feinabstimmung: Anpassung vortrainierter KI-Modelle für spezifische Aufgaben durch domänenspezifisches Training. Erfahren Sie, wie Feinabstimmung die...
12 Min. Lesezeit

Die Feinabstimmung von KI-Modellen ist der Prozess, bei dem vortrainierte künstliche Intelligenzmodelle an spezifische Aufgaben oder den Umgang mit spezialisierten Daten angepasst werden, indem ihre Parameter durch zusätzliches Training an domänenspezifischen Datensätzen angepasst werden. Dieser Ansatz nutzt vorhandenes Basiswissen und ermöglicht gleichzeitig die Anpassung der Modelle an besondere geschäftliche Anforderungen, sodass Unternehmen hochspezialisierte KI-Systeme erstellen können, ohne den rechnerischen Aufwand eines Trainings von Grund auf.
Die Feinabstimmung von KI-Modellen ist der Prozess, bei dem vortrainierte künstliche Intelligenzmodelle an spezifische Aufgaben oder den Umgang mit spezialisierten Daten angepasst werden, indem ihre Parameter durch zusätzliches Training an domänenspezifischen Datensätzen angepasst werden. Dieser Ansatz nutzt vorhandenes Basiswissen und ermöglicht gleichzeitig die Anpassung der Modelle an besondere geschäftliche Anforderungen, sodass Unternehmen hochspezialisierte KI-Systeme erstellen können, ohne den rechnerischen Aufwand eines Trainings von Grund auf.
Die Feinabstimmung von KI-Modellen ist der Prozess, bei dem ein vortrainiertes künstliches Intelligenzmodell genommen und so angepasst wird, dass es spezifische Aufgaben erfüllen oder mit spezialisierten Daten arbeiten kann. Anstatt ein Modell von Grund auf zu trainieren, nutzt die Feinabstimmung das bereits in einem vortrainierten Modell enthaltene Basiswissen und passt dessen Parameter durch zusätzliches Training an domänenspezifischen oder aufgabenspezifischen Datensätzen an. Dieser Ansatz kombiniert die Effizienz des Transferlernens mit der erforderlichen Anpassung für spezielle geschäftliche Anwendungen. Die Feinabstimmung ermöglicht es Organisationen, hochspezialisierte KI-Modelle zu erstellen, ohne den rechnerischen Aufwand und Zeitaufwand, der für ein Training von Grund auf erforderlich wäre. Sie ist daher eine entscheidende Technik in der modernen Entwicklung des maschinellen Lernens.
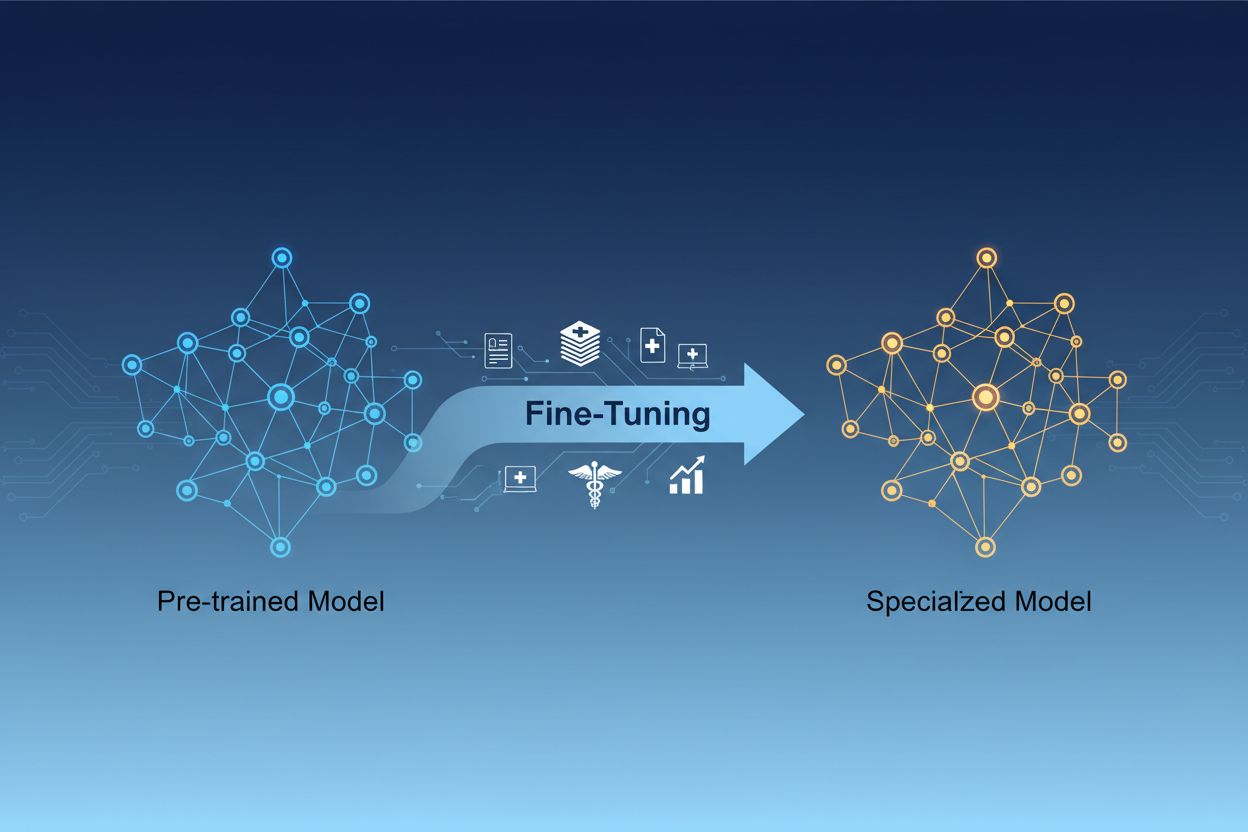
Die Unterscheidung zwischen Feinabstimmung und Training von Grund auf ist eine der wichtigsten Entscheidungen in der Entwicklung maschineller Lernsysteme. Beim Training von Grund auf beginnt man mit zufällig initialisierten Gewichten und muss dem Modell alles über Sprachmuster, visuelle Merkmale oder domänenspezifisches Wissen mithilfe riesiger Datensätze und erheblicher Rechenressourcen beibringen. Dieser Ansatz kann Wochen oder Monate in Anspruch nehmen und erfordert Zugang zu spezieller Hardware wie GPUs oder TPUs. Die Feinabstimmung hingegen startet mit einem Modell, das bereits grundlegende Muster und Konzepte versteht und benötigt nur einen Bruchteil der Daten und Rechenleistung, um es an die eigenen Anforderungen anzupassen. Das vortrainierte Modell hat während seiner initialen Trainingsphase bereits allgemeine Merkmale gelernt, sodass sich die Feinabstimmung darauf konzentriert, diese Merkmale an den konkreten Anwendungsfall anzupassen. Dieser Effizienzgewinn macht die Feinabstimmung für die meisten Organisationen zur bevorzugten Methode, da sie sowohl die Markteinführungszeit als auch die Infrastrukturkosten reduziert und dabei oft bessere Leistungen erzielt als das Training kleinerer Modelle von Grund auf.
| Aspekt | Feinabstimmung | Training von Grund auf |
|---|---|---|
| Trainingsdauer | Tage bis Wochen | Wochen bis Monate |
| Datenbedarf | Tausende bis Millionen Beispiele | Millionen bis Milliarden Beispiele |
| Rechenaufwand | Moderat (oft reicht eine GPU) | Extrem hoch (mehrere GPUs/TPUs erforderlich) |
| Anfangswissen | Nutzt vortrainierte Gewichte | Start mit Zufallsinitialisierung |
| Leistung | Oft überlegen bei wenig Daten | Besser bei riesigen Datensätzen |
| Erforderliche Expertise | Mittel | Fortgeschritten |
| Anpassungsgrad | Hoch für spezifische Aufgaben | Maximale Flexibilität |
| Infrastruktur | Standard Cloud-Ressourcen | Spezialisierte Hardware-Cluster |
Die Feinabstimmung ist für Unternehmen, die KI-Lösungen mit Wettbewerbsvorteilen einsetzen wollen, zu einer Schlüsselkompetenz geworden. Durch die Anpassung vortrainierter Modelle an den eigenen Geschäftskontext können KI-Systeme entwickelt werden, die branchenspezifische Terminologie, Kundenpräferenzen und betriebliche Anforderungen mit hoher Genauigkeit verstehen. Diese Individualisierung ermöglicht Leistungen, die generische, von der Stange verfügbare Modelle nicht erreichen – besonders in spezialisierten Bereichen wie Gesundheitswesen, juristische Dienstleistungen oder technischer Support. Dank der Kosteneffizienz der Feinabstimmung können auch kleinere Unternehmen nun auf KI-Funktionen im Enterprise-Format zugreifen, ohne große Infrastrukturausgaben tätigen zu müssen. Darüber hinaus können feinabgestimmte Modelle schneller bereitgestellt werden, sodass Unternehmen rasch auf Marktchancen und Konkurrenzdruck reagieren können. Die Möglichkeit, Modelle kontinuierlich durch Feinabstimmung mit neuen Daten zu verbessern, stellt sicher, dass Ihre KI-Systeme stets relevant und wirksam bleiben, während sich die Geschäftsbedingungen ändern.
Zentrale geschäftliche Vorteile der Feinabstimmung:
Im Bereich der Feinabstimmung haben sich mehrere bewährte Techniken herausgebildet, die je nach Anforderung unterschiedliche Vorteile bieten. Vollständige Feinabstimmung bedeutet, dass alle Parameter des vortrainierten Modells aktualisiert werden. Dies bietet maximale Flexibilität und häufig die beste Leistung, erfordert aber erhebliche Rechenressourcen und größere Datensätze, um Überanpassung zu vermeiden. Parameter-effiziente Feinabstimmungsmethoden wie LoRA (Low-Rank Adaptation) und QLoRA haben das Feld revolutioniert, indem sie eine effektive Modellanpassung ermöglichen, während nur ein kleiner Teil der Parameter aktualisiert wird. Dadurch werden der Speicherbedarf und die Trainingszeit drastisch reduziert. Diese Techniken fügen trainierbare Low-Rank-Matrizen zu den Gewichtsmatrizen des Modells hinzu und erfassen aufgabenspezifische Anpassungen, ohne die ursprünglichen vortrainierten Gewichte zu verändern. Adaptermodule stellen einen weiteren Ansatz dar, indem kleine trainierbare Netzwerke zwischen die Schichten des eingefrorenen vortrainierten Modells eingefügt werden. So ist eine effiziente Feinabstimmung mit minimalen zusätzlichen Parametern möglich. Prompt-basierte Feinabstimmung konzentriert sich darauf, Eingabeaufforderungen statt Modellgewichte zu optimieren – nützlich für Modelle, bei denen kein Zugriff auf die Parameter besteht. Instruktions-Feinabstimmung trainiert Modelle darauf, bestimmten Anweisungen und Befehlen zu folgen, was besonders bei großen Sprachmodellen wichtig ist, die unterschiedlichste Nutzeranfragen korrekt beantworten müssen. Die Wahl der jeweiligen Technik hängt von Ihren Rechenressourcen, der Datensatzgröße, den Leistungsanforderungen und der spezifischen Modellarchitektur ab.
Die Feinabstimmung großer Sprachmodelle (LLMs) bietet im Vergleich zur Feinabstimmung kleinerer Modelle oder anderer neuronaler Netzwerke besondere Chancen und Herausforderungen. Moderne LLMs wie GPT-Modelle enthalten Milliarden von Parametern, sodass eine vollständige Feinabstimmung für die meisten Organisationen rechnerisch nicht praktikabel ist. Das hat zum Einsatz parameter-effizienter Techniken geführt, mit denen LLMs effektiv angepasst werden können, ohne dass eine Infrastruktur im Unternehmensmaßstab nötig ist. Instruktions-Feinabstimmung ist für LLMs besonders wichtig: Modelle werden dabei mit Beispielen von Anweisungen und hochwertigen Antworten trainiert, um Nutzeranweisungen besser Folge zu leisten. Reinforcement Learning from Human Feedback (RLHF) ist ein fortgeschrittener Ansatz, bei dem Modelle durch menschliche Bewertungen weiter optimiert und besser auf menschliche Werte und Erwartungen abgestimmt werden. Für die Feinabstimmung von LLMs werden oft nur Hunderte oder Tausende von Beispielen benötigt, was diese Methode auch für Organisationen ohne riesige Label-Datensätze zugänglich macht. Dennoch erfordert die Feinabstimmung von LLMs sorgfältige Auswahl von Hyperparametern, Learning-Rate-Scheduling und die Vermeidung von katastrophalem Vergessen, bei dem das Modell zuvor erlernte Fähigkeiten beim Anpassen an neue Aufgaben verliert.

Unternehmen aller Branchen haben leistungsstarke Anwendungen für feinabgestimmte KI-Modelle gefunden, die messbaren geschäftlichen Nutzen bringen. Automatisierung des Kundenservice ist einer der häufigsten Anwendungsfälle: Modelle werden auf unternehmenseigenen Support-Tickets, Produktinformationen und Kommunikationsstilen feinabgestimmt, um Chatbots zu schaffen, die Kundenanfragen mit Fachwissen und Markenkonsistenz bearbeiten. Analyse medizinischer und juristischer Dokumente nutzt Feinabstimmung, um allgemeine Sprachmodelle auf die Interpretation von Fachterminologie, regulatorischen Vorgaben und branchenspezifischen Formaten auszurichten, sodass Informationen präzise extrahiert und klassifiziert werden können. Sentiment-Analyse und Inhaltsmoderation lassen sich durch Feinabstimmung auf Beispiele aus Ihrer spezifischen Branche oder Community deutlich verbessern, da nuancierte Sprachmuster und Kontexte erkannt werden, die generische Modelle übersehen. Code-Generierung und Unterstützung bei der Softwareentwicklung profitieren von der Feinabstimmung auf den eigenen Codebestand, Programmierkonventionen und Architekturmustern – so entstehen KI-Tools, die Code nach Ihren Standards generieren. Empfehlungssysteme werden häufig auf Nutzerdaten und Produktkataloge feinabgestimmt, um personalisierte Vorschläge zu machen, die Engagement und Umsatz steigern. Named Entity Recognition und Informationsextraktion aus branchenspezifischen Dokumenten – wie Finanzberichte, wissenschaftliche Publikationen oder technische Spezifikationen – lassen sich durch Feinabstimmung auf relevante Beispiele erheblich verbessern. Diese vielfältigen Anwendungen zeigen, dass Feinabstimmung nicht auf eine Branche oder einen Use Case beschränkt ist, sondern eine grundlegende Fähigkeit zur Entwicklung von KI-Systemen mit Wettbewerbsvorteil in praktisch jedem Geschäftsfeld darstellt.
Der Feinabstimmungsprozess folgt einem strukturierten Workflow, der mit sorgfältiger Vorbereitung beginnt und sich über Bereitstellung und Überwachung erstreckt. Datenvorbereitung ist der kritische erste Schritt – Sie müssen Ihren domänenspezifischen Datensatz sammeln, bereinigen und so formatieren, dass er zur Ein-/Ausgabe-Struktur des vortrainierten Modells passt. Dieser Datensatz sollte repräsentativ für die Aufgaben sein, die Ihr feinabgestimmtes Modell später übernimmt. Hierbei zählt Qualität mehr als Quantität – ein kleiner, hochwertiger Beispieldatensatz schlägt meist einen größeren, aber inkonsistenten oder fehlerhaften Datensatz. Trainings-, Validierungs- und Testaufteilung stellt sicher, dass die Modellleistung korrekt bewertet wird; typisch sind 70-80% für das Training, 10-15% für die Validierung und 10-15% für den Test. Hyperparameterauswahl umfasst Lernraten, Batchgrößen, die Anzahl der Trainingsepochen und weitere Parameter, die die Feinabstimmung steuern – diese haben großen Einfluss auf Leistung und Effizienz. Modellinitialisierung nutzt die vortrainierten Gewichte als Ausgangspunkt, damit das Basiswissen erhalten bleibt, während die Parameter für Ihre Aufgabe angepasst werden. Training bedeutet, die Modellparameter iterativ an den Trainingsdaten zu aktualisieren und dabei die Validierungsleistung im Blick zu behalten, um Überanpassung zu erkennen. Evaluation und Iteration erfolgen auf dem Testdatensatz, um die Endleistung zu beurteilen und zu entscheiden, ob weitere Feinabstimmung, andere Hyperparameter oder mehr Trainingsdaten die Ergebnisse verbessern würden. Bereitstellungsvorbereitung umfasst die Optimierung des Modells für schnelle und ressourceneffiziente Inferenz, eventuell durch Quantisierung oder Distillation. Schließlich sorgt Überwachung und Wartung im Produktivbetrieb dafür, dass das Modell bei sich wandelnden Datenverteilungen weiterhin zuverlässig arbeitet – regelmäßiges Nachtrainieren mit neuen Daten erhält die Genauigkeit.
Auch wenn die Feinabstimmung effizienter ist als das Training von Grund auf, bringt sie spezifische Herausforderungen mit sich, die sorgfältig adressiert werden müssen. Überanpassung tritt auf, wenn Modelle Trainingsdaten auswendig lernen, statt generalisierbare Muster zu erkennen – besonders kritisch bei kleinen Datensätzen. Dagegen helfen frühzeitiges Stoppen, Regularisierung oder Datenaugmentation. Katastrophales Vergessen beschreibt den Verlust zuvor erlernter Fähigkeiten durch die Feinabstimmung, was vor allem bei der Spezialisierung allgemeiner Modelle problematisch ist. Eine vorsichtige Wahl der Lernrate und Methoden wie Wissensdistillation helfen, Basiswissen zu bewahren. Datenqualität und -kennzeichnung sind zentrale Herausforderungen; die Feinabstimmung verlangt hochwertige, korrekt gelabelte Beispiele, die Ihren Zielbereich und Anwendungsfälle gut abbilden. Management der Rechenressourcen ist notwendig, um den Gewinn an Performance gegen Trainingszeiten und Infrastrukturkosten abzuwägen – insbesondere bei großen Modellen. Hyperparametersensitivität bedeutet, dass die Feinabstimmungsleistung stark von Lernrate, Batchgröße und weiteren Einstellungen abhängt, was systematisches Experimentieren und Validieren erfordert.
Best Practices für erfolgreiche Feinabstimmung:
Organisationen stehen oft vor der Wahl zwischen drei sich ergänzenden Ansätzen, um KI-Modelle für spezielle Aufgaben anzupassen: Feinabstimmung, Retrieval-Augmented Generation (RAG) und Prompt Engineering. Prompt Engineering bedeutet, mit sorgfältig formulierten Anweisungen und Beispielen das Modellverhalten zu steuern, ohne das Modell selbst zu verändern. Dieser Ansatz ist schnell und erfordert kein Training, ist aber bei komplexen Aufgaben begrenzt und kann dem Modell kein echtes neues Wissen vermitteln. RAG erweitert die Modellantworten, indem relevante Dokumente oder Daten aus externen Quellen vor der Antwortgenerierung abgerufen werden. So können Modelle auf aktuelle Informationen und domänenspezifisches Wissen zugreifen, ohne ihre Parameter zu verändern; dieser Ansatz eignet sich gut für wissensintensive Aufgaben, erhöht aber Komplexität und Latenz bei der Inferenz. Feinabstimmung hingegen verändert die Modellparameter und bettet aufgabenspezifisches Wissen und Muster tief ein. Sie liefert die beste Leistung für klar umrissene Aufgaben mit ausreichend Trainingsdaten, erfordert jedoch mehr Zeit und Rechenressourcen als die anderen Ansätze. Die optimale Lösung ist meist eine Kombination: Prompt Engineering für schnelles Prototyping, RAG für wissensintensive Anwendungen und Feinabstimmung für leistungsrelevante Systeme, bei denen sich der Trainingsaufwand lohnt. Feinabstimmung ist ideal, wenn konsistentes, leistungsstarkes Verhalten bei spezifischen Aufgaben gefordert ist, ausreichend Trainingsdaten vorliegen und der Leistungsgewinn den Entwicklungsaufwand rechtfertigt. RAG eignet sich am besten für Anwendungen, die Zugang zu aktuellen oder sich häufig ändernden proprietären Informationen benötigen. Prompt Engineering ist ein hervorragender Einstiegspunkt für Exploration und Prototyping, bevor man ressourcenintensivere Methoden wählt. Wer die Stärken und Grenzen jedes Ansatzes kennt, kann die passenden Techniken für die verschiedenen Komponenten seines KI-Systems gezielt einsetzen.
Transferlernen ist das übergeordnete Konzept, Wissen aus einer Aufgabe zu nutzen, um die Leistung bei einer anderen Aufgabe zu verbessern, während Feinabstimmung eine spezifische Umsetzung des Transferlernens ist. Bei der Feinabstimmung wird ein vortrainiertes Modell auf neue Daten angepasst, während Transferlernen auch die Merkmalsextraktion umfassen kann, bei der die vortrainierten Gewichte eingefroren und nur neue Schichten trainiert werden. Jede Feinabstimmung beinhaltet Transferlernen, aber nicht jedes Transferlernen erfordert Feinabstimmung.
Die Zeit für die Feinabstimmung variiert stark je nach Modellgröße, Datensatzgröße und verfügbarer Hardware. Mit parameter-effizienten Techniken wie LoRA kann ein Modell mit 13 Milliarden Parametern in etwa 5 Stunden auf einer einzelnen A100-GPU feinabgestimmt werden. Kleinere Modelle oder parameter-effiziente Methoden benötigen oft nur wenige Stunden, während eine vollständige Feinabstimmung größerer Modelle Tage oder Wochen in Anspruch nehmen kann. Der entscheidende Vorteil ist, dass die Feinabstimmung deutlich schneller ist als ein Training von Grund auf, das Monate dauern kann.
Ja, die Feinabstimmung ist speziell darauf ausgelegt, auch mit wenigen Daten effektiv zu funktionieren. Vortrainierte Modelle haben bereits allgemeine Muster gelernt, sodass in der Regel nur Hunderte bis Tausende von Beispielen für eine effektive Feinabstimmung benötigt werden – im Vergleich zu Millionen, die für ein Training von Grund auf erforderlich sind. Die Datenqualität ist jedoch wichtiger als die Quantität – ein kleiner, qualitativ hochwertiger und repräsentativer Datensatz übertrifft einen größeren Datensatz mit inkonsistenten oder fehlerhaften Labels.
LoRA (Low-Rank Adaptation) ist eine parameter-effiziente Feinabstimmungstechnik, die trainierbare Low-Rank-Matrizen zu den Gewichtsmatrizen eines Modells hinzufügt, anstatt alle Parameter zu aktualisieren. Dadurch wird die Anzahl der trainierbaren Parameter um ein Vielfaches reduziert, während eine vergleichbare Leistung zur vollständigen Feinabstimmung beibehalten wird. LoRA ist wichtig, weil es die Feinabstimmung auf Standardhardware zugänglich macht, den Speicherbedarf drastisch senkt und es Organisationen ermöglicht, große Modelle ohne teure Infrastruktur feinabzustimmen.
Überanpassung tritt auf, wenn der Trainingsverlust sinkt, aber der Validierungsverlust steigt – das Modell lernt dann das Training auswendig, anstatt generalisierbare Muster zu erkennen. Überwachen Sie beide Metriken während des Trainings – wenn die Validierungsleistung stagniert oder sich verschlechtert, während die Trainingsleistung weiter steigt, überanpasst Ihr Modell wahrscheinlich. Setzen Sie frühzeitiges Stoppen ein, um das Training zu beenden, wenn sich die Validierungsleistung nicht mehr verbessert, und nutzen Sie Techniken wie Regularisierung und Datenaugmentation, um Überanpassung zu vermeiden.
Zu den Kosten der Feinabstimmung zählen Rechenressourcen (GPU/TPU-Zeit), Datenvorbereitung und -kennzeichnung, Modell-Storage und Bereitstellungsinfrastruktur sowie laufende Überwachung und Wartung. Diese Kosten liegen jedoch typischerweise um den Faktor 10-100 niedriger als das Training von Modellen von Grund auf. Der Einsatz parameter-effizienter Techniken wie LoRA kann die Rechenkosten im Vergleich zur vollständigen Feinabstimmung um 80-90% senken, sodass Feinabstimmung für die meisten Unternehmen eine wirtschaftliche Lösung darstellt.
Ja, die Feinabstimmung verbessert die Modellgenauigkeit für spezifische Aufgaben in der Regel deutlich. Durch das Training mit domänenspezifischen Daten lernen Modelle aufgabenspezifische Muster und Terminologie, die generische Modelle übersehen. Studien zeigen, dass die Feinabstimmung die Genauigkeit je nach Aufgabe und Datensatzqualität um 10-30% oder mehr steigern kann. Der größte Zugewinn tritt auf, wenn die Feinabstimmungsaufgabe stark von der Vortrainingsaufgabe abweicht, da das Modell seine gelernten Merkmale an Ihre Anforderungen anpasst.
Die Feinabstimmung ermöglicht es Organisationen, sensible Daten auf der eigenen Infrastruktur zu halten, anstatt sie an externe APIs zu senden. Sie können Modelle lokal auf proprietären oder regulierten Daten feinabstimmen, ohne diese an externe Dienste weiterzugeben, und so die Einhaltung von Datenschutzvorschriften wie DSGVO, HIPAA oder branchenspezifischen Anforderungen sicherstellen. Dieser Ansatz bietet sowohl Sicherheits- als auch Compliance-Vorteile und erhält gleichzeitig die Leistungsfähigkeit vortrainierter Modelle.
Verfolgen Sie, wie KI-Systeme wie GPTs, Perplexity und Google AI Overviews Ihre Marke mit der KI-Überwachungsplattform von AmICited zitieren und referenzieren.
Definition Feinabstimmung: Anpassung vortrainierter KI-Modelle für spezifische Aufgaben durch domänenspezifisches Training. Erfahren Sie, wie Feinabstimmung die...
Erfahren Sie, was Erkennung von KI-Inhalten ist, wie Erkennungstools mit maschinellem Lernen und NLP funktionieren und warum sie für Markenüberwachung, Bildung ...
Erfahren Sie, was KI-Kaufzuordnung ist, wie sie Verkäufe aus KI-Empfehlungen misst und warum sie für den E-Commerce wichtig ist. Entdecken Sie wichtige Kennzahl...