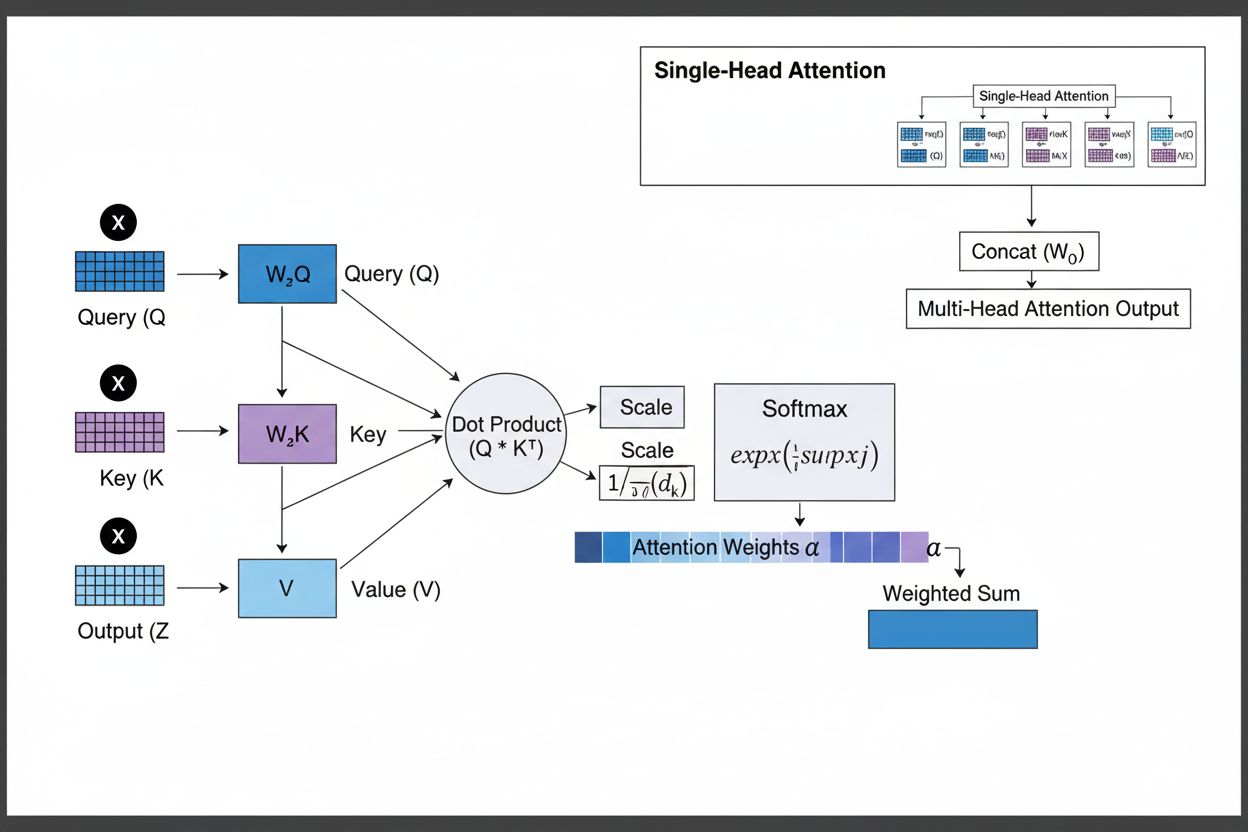
Definition des Aufmerksamkeitsmechanismus
Aufmerksamkeitsmechanismus ist eine Machine-Learning-Technik, die Deep-Learning-Modelle dazu anleitet, bei Vorhersagen die relevantesten Teile der Eingangsdaten zu priorisieren (oder ihnen „Aufmerksamkeit zu schenken“). Anstatt alle Eingabeelemente gleich zu behandeln, berechnen Aufmerksamkeitsmechanismen Aufmerksamkeitsgewichte, die die relative Bedeutung jedes Elements für die jeweilige Aufgabe widerspiegeln, und wenden diese Gewichte dann an, um bestimmte Eingaben dynamisch zu betonen oder abzuschwächen. Diese grundlegende Innovation ist zum Eckpfeiler moderner Transformer-Architekturen und großer Sprachmodelle (LLMs) wie ChatGPT, Claude und Perplexity geworden und ermöglicht es ihnen, sequenzielle Daten mit beispielloser Effizienz und Genauigkeit zu verarbeiten. Der Mechanismus ist von der menschlichen kognitiven Aufmerksamkeit inspiriert – der Fähigkeit, sich selektiv auf auffällige Details zu konzentrieren und irrelevante Informationen herauszufiltern – und überträgt dieses biologische Prinzip auf eine mathematisch rigorose und lernbare Komponente neuronaler Netzwerke.
Historischer Kontext und Entwicklung
Das Konzept der Aufmerksamkeitsmechanismen wurde 2014 erstmals von Bahdanau und Kollegen eingeführt, um kritische Einschränkungen von rekurrenten neuronalen Netzwerken (RNNs) bei der maschinellen Übersetzung zu adressieren. Vor der Einführung von Aufmerksamkeit stützten sich Seq2Seq-Modelle auf einen einzigen Kontextvektor, um ganze Quellsätze zu kodieren, wodurch ein Informationsengpass entstand, der die Leistung bei längeren Sequenzen stark einschränkte. Der ursprüngliche Aufmerksamkeitsmechanismus ermöglichte es dem Decoder, auf alle verborgenen Zustände des Encoders statt nur auf den letzten zuzugreifen und so bei jedem Decodierschritt dynamisch die relevantesten Teile der Eingabe auszuwählen. Dieser Durchbruch verbesserte die Übersetzungsqualität dramatisch, insbesondere bei längeren Sätzen. 2015 führten Luong und Kollegen die Dot-Product-Attention ein, die die rechenintensive additive Aufmerksamkeit durch effiziente Matrixmultiplikation ersetzte. Der Wendepunkt kam 2017 mit der Veröffentlichung von „Attention is All You Need“, das die Transformer-Architektur einführte, die vollständig auf Rekurrenz verzichtete und stattdessen ausschließlich auf Aufmerksamkeitsmechanismen setzte. Dieses Paper revolutionierte das Deep Learning und ermöglichte die Entwicklung von BERT, GPT-Modellen und dem gesamten modernen generativen KI-Ökosystem. Heute sind Aufmerksamkeitsmechanismen allgegenwärtig in der Verarbeitung natürlicher Sprache, Computer Vision und multimodalen KI-Systemen, wobei über 85 % der State-of-the-Art-Modelle irgendeine Form von auf Aufmerksamkeit basierender Architektur einbeziehen.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technische Architektur und Komponenten
Der Aufmerksamkeitsmechanismus funktioniert durch ein raffiniertes Zusammenspiel von drei zentralen mathematischen Komponenten: Abfragen (Q), Schlüssel (K) und Werte (V). Jedes Eingabeelement wird durch gelernte lineare Projektionen in diese drei Repräsentationen überführt und bildet so eine strukturähnliche Datenbank, in der Schlüssel als Identifikatoren und Werte den eigentlichen Informationsinhalt darstellen. Der Mechanismus berechnet Ausrichtungswerte, indem er die Ähnlichkeit zwischen einer Abfrage und allen Schlüsseln misst, typischerweise mithilfe der skalierten Punktprodukt-Aufmerksamkeit, wobei der Wert als QK^T/√d_k berechnet wird. Diese Rohwerte werden anschließend mit der Softmax-Funktion normalisiert, die sie in eine Wahrscheinlichkeitsverteilung umwandelt, bei der alle Gewichte zusammen 1 ergeben, sodass jedes Element ein Gewicht zwischen 0 und 1 erhält. Im letzten Schritt wird eine gewichtete Summe der Wertvektoren unter Verwendung dieser Aufmerksamkeitsgewichte berechnet, was einen Kontextvektor ergibt, der die relevantesten Informationen der gesamten Eingabesequenz repräsentiert. Dieser Kontextvektor wird dann über Residualverbindungen mit der ursprünglichen Eingabe kombiniert und durch Feedforward-Schichten weiterverarbeitet, wodurch das Modell seine Interpretation der Eingabe iterativ verfeinern kann. Die mathematische Eleganz dieses Designs – die Verbindung aus lernbaren Transformationen, Ähnlichkeitsberechnungen und probabilistischer Gewichtung – ermöglicht es Aufmerksamkeitsmechanismen, komplexe Abhängigkeiten zu erfassen und gleichzeitig vollständig differenzierbar für gradientenbasierte Optimierung zu bleiben.
Vergleich von Aufmerksamkeitsmechanismus-Varianten
| Aufmerksamkeitstyp | Rechenmethode | Rechenkomplexität | Bester Anwendungsfall | Hauptvorteil |
|---|
| Additive Aufmerksamkeit | Feed-Forward-Netzwerk + tanh-Aktivierung | O(n·d) pro Abfrage | Kürzere Sequenzen, variable Dimensionen | Unterstützt unterschiedliche Query/Key-Dimensionen |
| Dot-Product-Attention | Einfache Matrixmultiplikation | O(n·d) pro Abfrage | Standardsequenzen | Rechnerisch effizient |
| Skalierte Punktprodukt | QK^T/√d_k + softmax | O(n·d) pro Abfrage | Moderne Transformer | Verhindert Gradientenauslöschung |
| Multi-Head-Attention | Mehrere parallele Aufmerksamkeitsköpfe | O(h·n·d) mit h=Köpfe | Komplexe Beziehungen | Erfasst vielfältige semantische Aspekte |
| Selbstaufmerksamkeit | Abfragen, Schlüssel, Werte aus derselben Sequenz | O(n²·d) | Intra-Sequenz-Beziehungen | Ermöglicht parallele Verarbeitung |
| Kreuzaufmerksamkeit | Abfragen aus einer Sequenz, Schlüssel/Werte aus einer anderen | O(n·m·d) | Encoder-Decoder, multimodal | Richtet verschiedene Modalitäten aus |
| Grouped Query Attention | Teilt Schlüssel/Werte über Abfrageköpfe hinweg | O(n·d) | Effizientes Inferenz | Reduziert Speicher und Berechnung |
| Sparse Attention | Begrenzte Aufmerksamkeit auf lokale/abgestufte Positionen | O(n·√n·d) | Sehr lange Sequenzen | Bewältigt extrem lange Sequenzen |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Wie Aufmerksamkeitsmechanismen in der Praxis funktionieren
Der Aufmerksamkeitsmechanismus arbeitet durch eine präzise abgestimmte Abfolge mathematischer Transformationen, die es neuronalen Netzwerken ermöglichen, sich dynamisch auf relevante Informationen zu konzentrieren. Beim Verarbeiten einer Eingabesequenz wird jedes Element zunächst in einen hochdimensionalen Vektorraum eingebettet, der semantische und syntaktische Informationen erfasst. Diese Einbettungen werden dann durch gelernte Gewichtsmatrizen in drei separate Räume projiziert: den Abfrage-Raum (welche Information gesucht wird), den Schlüssel-Raum (welche Information jedes Element enthält) und den Werte-Raum (die eigentlichen zu aggregierenden Informationen). Für jede Abfrageposition berechnet der Mechanismus einen Ähnlichkeitswert mit jedem Schlüssel durch deren Punktprodukt und erzeugt so einen Vektor roher Ausrichtungswerte. Diese Werte werden durch Division durch die Quadratwurzel der Schlüsseldimension (√d_k) skaliert – ein wichtiger Schritt, der verhindert, dass Punktprodukte bei hohen Dimensionen zu groß werden und dadurch Gradienten beim Backpropagation-Prozess verschwinden. Die skalierten Werte werden durch eine Softmax-Funktion geführt, die jeden Wert exponentiert und so normalisiert, dass alle zusammen 1 ergeben – das ergibt eine Wahrscheinlichkeitsverteilung über alle Positionen. Schließlich werden diese Aufmerksamkeitsgewichte verwendet, um einen gewichteten Durchschnitt der Wertevektoren zu berechnen, wobei Positionen mit höheren Gewichten stärker zum endgültigen Kontextvektor beitragen. Dieser Kontextvektor wird über Residualverbindungen mit der ursprünglichen Eingabe kombiniert und durch Feedforward-Schichten weiterverarbeitet, sodass das Modell seine Repräsentationen iterativ verfeinert. Der gesamte Prozess ist differenzierbar, sodass das Modell optimale Aufmerksamkeitsmuster während des Trainings per Gradientenabstieg lernen kann.
Aufmerksamkeitsmechanismen bilden den grundlegenden Baustein der Transformer-Architekturen, die sich zum dominanten Ansatz im Deep Learning entwickelt haben. Im Gegensatz zu RNNs, die Sequenzen sequenziell verarbeiten, und CNNs, die auf festen lokalen Fenstern operieren, nutzen Transformer Selbstaufmerksamkeit, sodass jede Position direkt auf alle anderen Positionen gleichzeitig achten kann, was massive Parallelisierung auf GPUs und TPUs ermöglicht. Die Transformer-Architektur besteht aus abwechselnden Schichten von Multi-Head-Selbstaufmerksamkeit und Feedforward-Netzwerken, wobei jede Aufmerksamkeitslage das Modell befähigt, die Eingabe selektiv auf verschiedene Aspekte hin zu analysieren. Multi-Head-Attention führt mehrere Aufmerksamkeitsmechanismen parallel aus, wobei jeder Kopf lernt, sich auf unterschiedliche Beziehungstypen zu fokussieren – ein Kopf kann sich auf grammatische Abhängigkeiten spezialisieren, ein anderer auf semantische Beziehungen und ein dritter auf Langstrecken-Koreferenz. Die Ausgaben aller Köpfe werden zusammengefügt und projiziert, sodass das Modell mehrere linguistische Phänomene gleichzeitig erfassen kann. Diese Architektur hat sich als äußerst effektiv für große Sprachmodelle wie GPT-4, Claude 3 und Gemini erwiesen, die ausschließlich Decoder-basierte Transformer-Architekturen einsetzen, wobei jedes Token nur auf vorherige Token achten darf (kausales Maskieren), um die autoregressive Generierungseigenschaft zu bewahren. Die Fähigkeit des Aufmerksamkeitsmechanismus, Langstreckenabhängigkeiten ohne die von RNNs bekannten vanishing gradients zu erfassen, war entscheidend, um Kontextfenster von über 100.000 Token zu ermöglichen und dabei Kohärenz und Konsistenz über große Textmengen aufrechtzuerhalten. Forschungen zeigen, dass etwa 92 % der modernen NLP-Modelle auf Transformer-Architekturen mit Aufmerksamkeitsmechanismen basieren, was ihre fundamentale Bedeutung für heutige KI-Systeme unterstreicht.
Aufmerksamkeitsmechanismen in KI-Suche und Monitoring
Im Kontext von KI-Suchplattformen wie ChatGPT, Perplexity, Claude und Google AI Overviews spielen Aufmerksamkeitsmechanismen eine entscheidende Rolle dabei, welche Teile abgerufener Dokumente und Wissensbasen für Nutzeranfragen am relevantesten sind. Wenn diese Systeme Antworten generieren, gewichten ihre Aufmerksamkeitsmechanismen verschiedene Quellen und Passagen dynamisch nach Relevanz und ermöglichen es ihnen, kohärente Antworten aus mehreren Quellen zu synthetisieren, während die faktische Genauigkeit erhalten bleibt. Die während der Generierung berechneten Aufmerksamkeitsgewichte können analysiert werden, um zu verstehen, welche Informationen das Modell priorisiert hat, und geben Aufschluss darüber, wie KI-Systeme Anfragen interpretieren und beantworten. Für das Brand Monitoring und GEO (Generative Engine Optimization) ist das Verständnis von Aufmerksamkeitsmechanismen essenziell, weil sie bestimmen, welchen Inhalten und Quellen in KI-generierten Antworten Gewicht verliehen wird. Inhalte, die so strukturiert sind, dass sie mit der Gewichtung der Aufmerksamkeitsmechanismen harmonieren – etwa durch klare Entitätsdefinitionen, autoritative Quellen und kontextuelle Relevanz – werden mit höherer Wahrscheinlichkeit prominent in KI-Antworten genannt und zitiert. AmICited nutzt Erkenntnisse über Aufmerksamkeitsmechanismen, um zu verfolgen, wie Marken und Domains in KI-Plattformen erscheinen, und erkennt, dass durch Aufmerksamkeitsgewichte gewichtete Zitate die einflussreichsten Erwähnungen in KI-generierten Inhalten darstellen. Während Unternehmen verstärkt ihre Präsenz in KI-Antworten überwachen, ist das Verständnis, dass Aufmerksamkeitsmechanismen die Zitiermuster steuern, entscheidend für die Optimierung der Content-Strategie und die Sicherung der Markenpräsenz im Zeitalter generativer KI.
Wichtige Aspekte und Implementierungsüberlegungen
- Rechen-Effizienz: Skalierte Punktprodukt-Aufmerksamkeit ermöglicht O(n²)-Komplexität mit massiver Parallelisierung, wodurch Sequenzen von Tausenden Tokens auf modernen GPUs praktikabel verarbeitet werden können
- Gradientenfluss: Der Skalierungsfaktor (1/√d_k) verhindert das Verschwinden von Gradienten und ermöglicht stabiles Training sehr tiefer Netzwerke mit vielen Aufmerksamkeitslagen
- Interpretierbarkeit: Aufmerksamkeitsgewichte ermöglichen interpretierbare Visualisierungen, die zeigen, welche Eingabeelemente spezifische Vorhersagen beeinflusst haben, und steigern so die Transparenz des Modells
- Positionale Codierung: Transformer benötigen explizite Positionsinformationen, z. B. durch sinusförmige oder rotatorische Encodierungen, da Aufmerksamkeit die Reihenfolge nicht inhärent abbildet
- Kausales Maskieren: Autoregressive Modelle wie GPT nutzen kausales Maskieren, um zu verhindern, dass Tokens auf zukünftige Positionen achten, und erhalten so die Generierungseigenschaft
- Speichereffizienz: Varianten wie Grouped Query Attention und Sparse Attention reduzieren den Speicherbedarf von O(n²) auf O(n·√n) bei sehr langen Sequenzen
- Multi-Skalen-Aufmerksamkeit: Verschiedene Aufmerksamkeitsköpfe lernen, sich auf unterschiedliche Kontextbereiche zu konzentrieren – von lokalen Wortbeziehungen bis hin zu dokumentweiten Themen
- Cross-Modal Alignment: Kreuzaufmerksamkeit ermöglicht es Modellen wie Stable Diffusion, Textprompts mit der Bildgenerierung abzugleichen und Sprachmodelle an visuelle Informationen zu koppeln
Entwicklung und zukünftige Richtungen
Das Feld der Aufmerksamkeitsmechanismen entwickelt sich rasant weiter: Forscher entwickeln immer ausgefeiltere Varianten, um Rechenbeschränkungen zu adressieren und die Leistung zu steigern. Sparse-Attention-Muster beschränken die Aufmerksamkeit auf lokale Nachbarschaften oder abgestufte Positionen, reduzieren die Komplexität von O(n²) auf O(n·√n) und ermöglichen dennoch gute Leistungen bei sehr langen Sequenzen. Effiziente Aufmerksamkeitsmechanismen wie FlashAttention optimieren die Speicherzugriffsmuster der Berechnung und erreichen durch bessere GPU-Auslastung Beschleunigungen um den Faktor 2-4. Grouped Query Attention und Multi-Query Attention verringern die Anzahl der Key-Value-Köpfe bei gleichbleibender Leistung und senken so den Speicherbedarf im Inferenzbetrieb – ein wichtiger Aspekt für den produktiven Einsatz großer Modelle. Mixture-of-Experts-Architekturen kombinieren Aufmerksamkeit mit sparsamen Routen und ermöglichen es Modellen, auf Billionen von Parametern zu skalieren, ohne die Recheneffizienz zu beeinträchtigen. Neue Forschungen untersuchen gelernte Aufmerksamkeitsmuster, die sich dynamisch an die Eingabe anpassen, sowie hierarchische Aufmerksamkeit, die auf mehreren Abstraktionsebenen arbeitet. Die Integration von Aufmerksamkeitsmechanismen mit Retrieval-Augmented Generation (RAG) ermöglicht es Modellen, dynamisch auf relevantes externes Wissen zu achten, was die Faktentreue steigert und Halluzinationen reduziert. Da KI-Systeme zunehmend in kritischen Anwendungen eingesetzt werden, werden Aufmerksamkeitsmechanismen mit Erklärbarkeitsfunktionen erweitert, die klarere Einblicke in die Entscheidungsfindung liefern. Die Zukunft dürfte hybride Architekturen beinhalten, die Aufmerksamkeit mit alternativen Mechanismen wie State-Space-Modellen (wie bei Mamba) kombinieren, die lineare Komplexität bei wettbewerbsfähiger Leistung bieten. Das Verständnis dieser sich weiterentwickelnden Aufmerksamkeitsmechanismen ist essenziell für Praktiker, die nächste KI-Systeme entwickeln, sowie für Organisationen, die ihre Präsenz in KI-generierten Inhalten überwachen, da die Mechanismen, die Zitiermuster und Inhaltsgewichtung bestimmen, sich stetig weiterentwickeln.
Aufmerksamkeitsmechanismen und KI-Zitiermuster
Für Organisationen, die AmICited zur Überwachung der Markenpräsenz in KI-Antworten nutzen, liefert das Verständnis von Aufmerksamkeitsmechanismen entscheidenden Kontext zur Interpretation von Zitiermustern. Wenn ChatGPT, Claude oder Perplexity Ihre Domain in ihren Antworten zitieren, haben die während der Generierung berechneten Aufmerksamkeitsgewichte bestimmt, dass Ihre Inhalte für die Nutzeranfrage am relevantesten waren. Hochwertige, gut strukturierte Inhalte, die Entitäten klar definieren und autoritative Informationen bieten, erhalten von Natur aus höhere Aufmerksamkeitsgewichte und werden so mit größerer Wahrscheinlichkeit für Zitate ausgewählt. Die Visualisierungsfunktionen für Aufmerksamkeit in einigen KI-Plattformen zeigen, welche Quellen während der Antwortgenerierung den größten Fokus erhalten haben und machen so sichtbar, welche Zitate am einflussreichsten waren. Diese Erkenntnis ermöglicht es Organisationen, ihre Content-Strategie gezielt zu optimieren, denn Aufmerksamkeitsmechanismen belohnen Klarheit, Relevanz und autoritative Quellen. Mit dem Wachstum der KI-Suche – über 60 % der Unternehmen investieren inzwischen in generative KI-Initiativen – wird die Fähigkeit, Aufmerksamkeitsmechanismen zu verstehen und zu optimieren, immer wertvoller für die Markenpräsenz und eine korrekte Darstellung in KI-generierten Inhalten. Der Schnittpunkt von Aufmerksamkeitsmechanismen und Markenüberwachung bildet eine neue Grenze im GEO, bei der das Verständnis der mathematischen Grundlagen, wie KI-Systeme Informationen gewichten und zitieren, direkt zu verbesserter Sichtbarkeit und Einfluss im generativen KI-Ökosystem führt.