
Was ist ein Kontextfenster in KI-Modellen
Erfahren Sie, was Kontextfenster in KI-Sprachmodellen sind, wie sie funktionieren, welchen Einfluss sie auf die Modellleistung haben und warum sie für KI-gestüt...
9 Min. Lesezeit
Kontextuelles Einfassen ist eine Technik zur Inhaltsoptimierung, die klare Grenzen um Informationen setzt, um Fehlinterpretationen und Halluzinationen durch KI zu verhindern. Sie verwendet explizite Trennzeichen und Kontextmarkierungen, damit KI-Modelle genau verstehen, wo relevante Informationen beginnen und enden, und verhindert so, dass Antworten auf Annahmen oder erfundenen Details basieren.
Kontextuelles Einfassen ist eine Technik zur Inhaltsoptimierung, die klare Grenzen um Informationen setzt, um Fehlinterpretationen und Halluzinationen durch KI zu verhindern. Sie verwendet explizite Trennzeichen und Kontextmarkierungen, damit KI-Modelle genau verstehen, wo relevante Informationen beginnen und enden, und verhindert so, dass Antworten auf Annahmen oder erfundenen Details basieren.
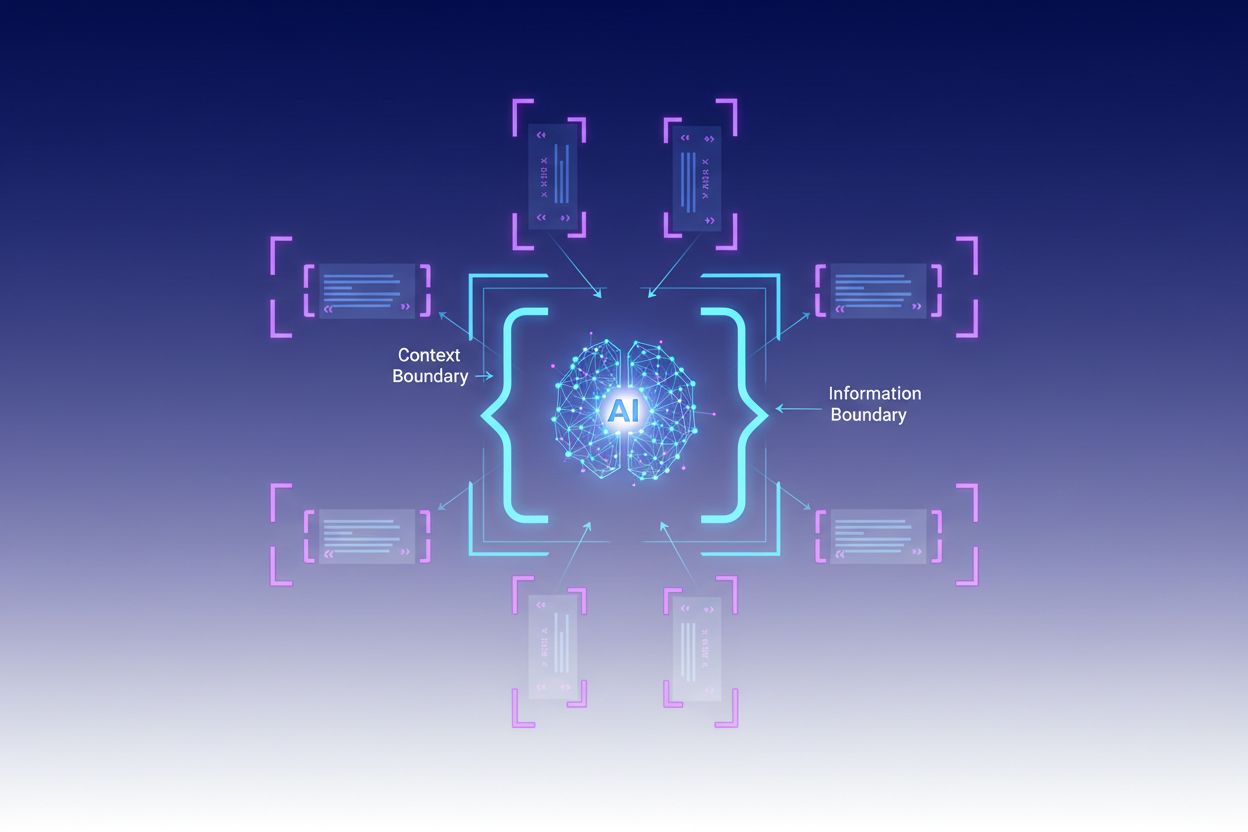
Kontextuelles Einfassen ist eine Technik zur Inhaltsoptimierung, die klare Grenzen um Informationen setzt, um Fehlinterpretationen und Halluzinationen durch KI zu verhindern. Diese Methode verwendet explizite Trennzeichen – wie XML-Tags, Markdown-Überschriften oder Sonderzeichen – um den Anfang und das Ende bestimmter Informationsblöcke zu markieren, was von Experten als „Kontextgrenze“ bezeichnet wird. Durch die Strukturierung von Prompts und Daten mit diesen klaren Markierungen stellen Entwickler sicher, dass KI-Modelle genau verstehen, wo relevante Informationen beginnen und enden, und verhindern, dass das Modell Antworten auf Grundlage von Annahmen oder erfundenen Details generiert. Kontextuelles Einfassen stellt eine Weiterentwicklung des klassischen Prompt Engineerings dar und geht in die umfassendere Disziplin des Kontext Engineerings über, die darauf abzielt, alle einem LLM zur Verfügung gestellten Informationen zu optimieren, um gewünschte Ergebnisse zu erzielen. Die Technik ist besonders wertvoll in Produktionsumgebungen, in denen Genauigkeit und Konsistenz entscheidend sind, da sie mathematische und strukturelle Leitplanken bietet, die das KI-Verhalten lenken, ohne komplexe bedingte Logik zu erfordern.
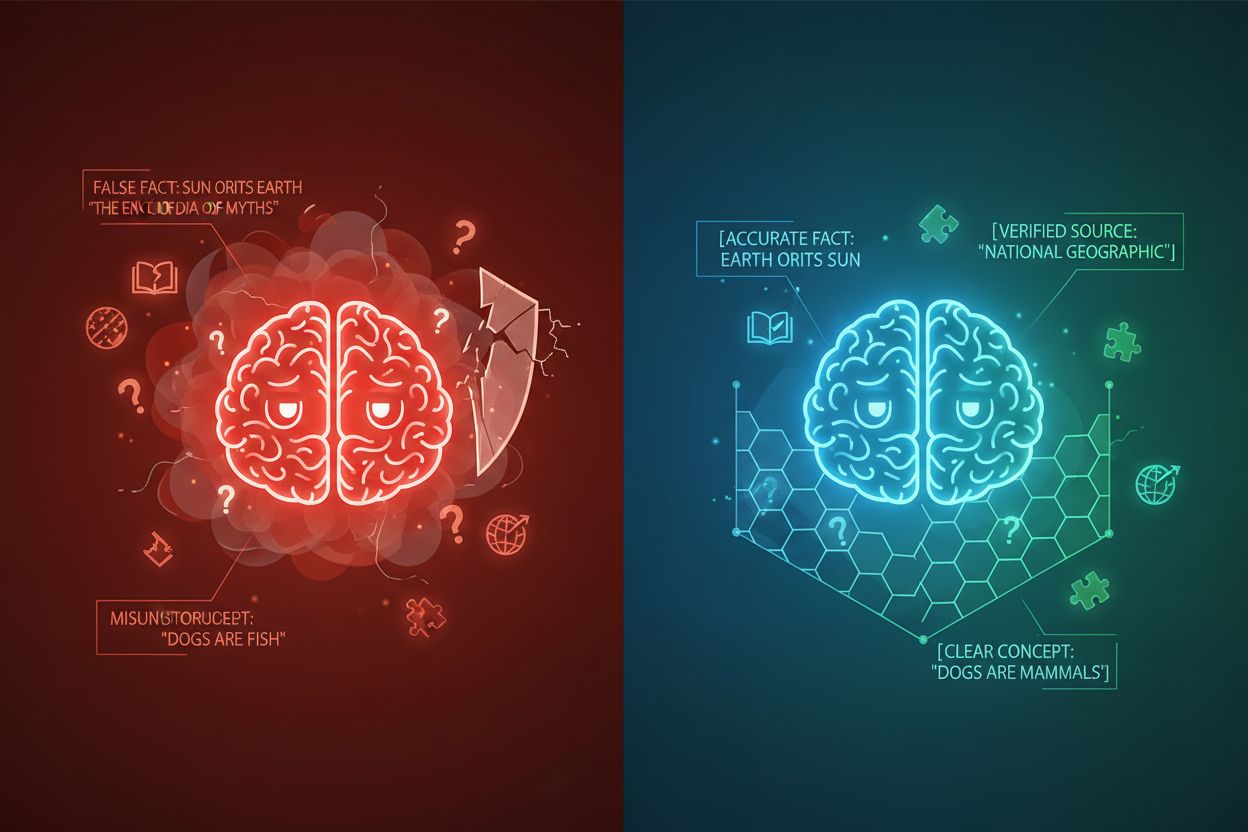
KI-Halluzinationen treten auf, wenn Sprachmodelle Antworten generieren, die nicht auf Fakten oder dem bereitgestellten spezifischen Kontext beruhen, was zu falschen Fakten, irreführenden Aussagen oder Verweisen auf nicht existierende Quellen führt. Untersuchungen zeigen, dass Chatbots etwa 27 % der Zeit Fakten erfinden und 46 % ihrer Texte sachliche Fehler enthalten, während die Journalismus-Zitate von ChatGPT zu 76 % falsch waren. Diese Halluzinationen entstehen aus verschiedenen Gründen: Modelle lernen möglicherweise Muster aus voreingenommenen oder unvollständigen Trainingsdaten, verstehen die Beziehung zwischen Tokens falsch oder haben nicht genügend Einschränkungen, die mögliche Ausgaben begrenzen. Die Folgen sind branchenübergreifend gravierend – im Gesundheitswesen können Halluzinationen zu Fehldiagnosen und unnötigen medizinischen Eingriffen führen; im Rechtsbereich zu erfundenen Fallzitaten (wie im Fall Mata v. Avianca, bei dem ein Anwalt wegen der Verwendung gefälschter ChatGPT-Zitate sanktioniert wurde); in Unternehmen werden Ressourcen durch fehlerhafte Analysen und Prognosen verschwendet. Das Grundproblem ist, dass KI-Modelle ohne klare Kontextgrenzen in einem Informationsvakuum arbeiten, in dem sie eher dazu neigen, „die Lücken zu füllen“ – mit plausibel klingenden, aber ungenauen Informationen, und Halluzinationen als Feature statt als Bug behandeln.
| Halluzinationstyp | Häufigkeit | Auswirkung | Beispiel |
|---|---|---|---|
| Sachliche Fehler | 27–46 % | Verbreitung von Fehlinformationen | Falsche Produkteigenschaften |
| Quellenfälschung | 76 % (Zitate) | Vertrauensverlust | Nicht existierende Zitate |
| Missverstandene Konzepte | Variabel | Falsche Analysen | Falsche Rechtsgrundlagen |
| Voreingenommene Muster | Laufend | Diskriminierende Ausgaben | Stereotype Antworten |
Die Wirksamkeit des kontextuellen Einfassens beruht auf fünf grundlegenden Prinzipien:
Verwendung von Trennzeichen: Nutzen Sie konsistente, eindeutige Markierungen (XML-Tags wie <context>, Markdown-Überschriften oder Sonderzeichen), um Informationsblöcke klar abzugrenzen und zu verhindern, dass das Modell Grenzen zwischen unterschiedlichen Datenquellen oder Anweisungstypen verwechselt.
Verwaltung des Kontextfensters: Vergeben Sie Tokens strategisch zwischen Systemanweisungen, Nutzereingaben und abgerufenen Informationen, sodass die relevantesten Informationen das begrenzte Aufmerksamkeitsbudget des Modells belegen und weniger wichtige Details gefiltert oder just-in-time abgerufen werden.
Informationshierarchie: Legen Sie klare Prioritätsstufen für verschiedene Informationstypen fest und signalisieren Sie dem Modell, welche Daten als autoritative Quelle und welche als ergänzender Kontext behandelt werden sollen, um eine Gleichgewichtung von primären und sekundären Informationen zu verhindern.
Grenzdefinition: Geben Sie explizit an, welche Informationen das Modell berücksichtigen und welche es ignorieren soll, und schaffen Sie so harte Stopps, die verhindern, dass das Modell über bereitgestellte Daten hinaus extrapoliert oder Annahmen über nicht explizite Informationen trifft.
Scope-Marker: Verwenden Sie Strukturelemente, um den Geltungsbereich von Anweisungen, Beispielen und Daten anzuzeigen, und machen Sie deutlich, ob Vorgaben global, nur für bestimmte Abschnitte oder nur für spezielle Fragetypen gelten.
Die Implementierung des kontextuellen Einfassens erfordert sorgfältige Beachtung der Strukturierung und Präsentation von Informationen für KI-Modelle. Strukturierte Eingabeformate mit JSON- oder XML-Schemas bieten explizite Felddefinitionen, die das Modellverhalten lenken – etwa indem Nutzeranfragen in <user_query>-Tags und erwartete Ausgaben in <expected_output>-Tags eingeschlossen werden, wodurch eindeutige Grenzen entstehen. Systemprompts sollten in verschiedene Abschnitte mit Markdown-Überschriften oder XML-Tags gegliedert werden: <background_information>, <instructions>, <tool_guidance> und <output_description> erfüllen jeweils spezifische Zwecke und helfen dem Modell, die Hierarchie der Informationen zu erfassen. Few-Shot-Beispiele sollten eingefasste Kontexte enthalten, die dem Modell genau zeigen, wie es seine Antworten strukturieren soll, mit klaren Trennzeichen um Eingaben und Ausgaben. Tool-Definitionen profitieren von expliziten Parameterbeschreibungen und Nutzungseinschränkungen, damit das Modell Werkzeuge nicht missbraucht oder außerhalb des vorgesehenen Rahmens einsetzt. Retrieval-Augmented Generation (RAG)-Systeme können kontextuelles Einfassen implementieren, indem abgerufene Dokumente mit Quellmarkierungen (<source>Dokumentname</source>) versehen und Grounding-Scores genutzt werden, um zu überprüfen, ob generierte Antworten innerhalb der abgerufenen Informationen bleiben. Beispielsweise arbeitet die Kontextgrenzen-Funktion von CustomGPT so, dass Modelle ausschließlich auf hochgeladene Datensätze trainiert werden und Antworten niemals über die bereitgestellte Wissensbasis hinausgehen – eine praktische Umsetzung des kontextuellen Einfassens auf architektonischer Ebene.
Obwohl kontextuelles Einfassen Ähnlichkeiten mit verwandten Techniken aufweist, nimmt es eine eigene Position in der KI-Entwicklung ein. Klassisches Prompt Engineering konzentriert sich vor allem auf das Erstellen effektiver Anweisungen und Beispiele, verfolgt jedoch keinen systematischen Ansatz zur Verwaltung aller Kontextelemente, wie es das kontextuelle Einfassen tut. Kontext Engineering als breitere Disziplin umfasst das kontextuelle Einfassen als eine von mehreren Komponenten – dazu gehören Prompt-Optimierung, Tool-Design, Speichermanagement und dynamische Kontextabrufe, was Kontextuelles Einfassen zu einem Teilbereich dieses umfassenderen Ansatzes macht. Einfaches Befolgen von Anweisungen verlässt sich darauf, dass das Modell natürliche Sprachanweisungen ohne explizite Strukturgrenzen versteht, was oft fehlschlägt, wenn Anweisungen komplex sind oder das Modell auf mehrdeutige Situationen trifft. Guardrails und Validierungssysteme arbeiten auf Ausgabeseite und prüfen Antworten nach der Generierung, während kontextuelles Einfassen bereits auf Eingabeseite Halluzinationen verhindert. Der entscheidende Unterschied ist, dass kontextuelles Einfassen präventiv und strukturell wirkt – es gestaltet die Informationslandschaft, in der das Modell arbeitet, statt nur nachträglich zu korrigieren, und ist daher für die Wahrung von Genauigkeit in Produktionssystemen effizienter und zuverlässiger.
Kontextuelles Einfassen liefert messbaren Mehrwert in verschiedensten Anwendungen. Kundenservice-Chatbots nutzen Kontextgrenzen, um Antworten auf firmeninterne Wissensdatenbanken zu beschränken und verhindern so, dass Agenten Produkteigenschaften erfinden oder unautorisierte Zusagen machen. Systeme zur Analyse juristischer Dokumente fassen relevante Gesetze, Präzedenzfälle und Statuten ein, sodass die KI nur verifizierte Quellen referenziert und keine Rechtszitate erfindet. Medizinische KI-Systeme setzen strikte Kontextgrenzen um klinische Leitlinien, Patientendaten und genehmigte Behandlungsprotokolle und verhindern so gefährliche Halluzinationen, die Patienten schaden könnten. Content-Generation-Plattformen verwenden kontextuelles Einfassen, um Markenvorgaben, Tonalitätsanforderungen und Faktenbeschränkungen durchzusetzen, sodass generierte Inhalte den Unternehmensstandards entsprechen. Forschungs- und Analysetools fassen Primärquellen, Datensätze und verifizierte Informationen ein und ermöglichen der KI, Erkenntnisse zu synthetisieren, während sie Quellen klar zuordnet und keine Statistiken oder Studien erfindet. AmICited.com veranschaulicht dieses Prinzip, indem überwacht wird, wie KI-Systeme Marken in GPTs, Perplexity und Google AI Overviews zitieren und referenzieren – und so nachverfolgt wird, ob KI-Modelle die passenden Kontextgrenzen bei der Diskussion bestimmter Unternehmen oder Produkte einhalten oder die Informationen korrekt wiedergeben.
Für eine erfolgreiche Implementierung des kontextuellen Einfassens sollten bewährte Methoden beachtet werden:
Mit minimalem Kontext starten: Beginnen Sie mit dem kleinsten Informationsumfang, der für genaue Antworten erforderlich ist, und erweitern Sie diesen nur, wenn Tests Lücken aufzeigen – so vermeiden Sie Kontextverschmutzung und erhalten den Fokus des Modells.
Konsistente Trennmuster nutzen: Legen Sie einheitliche Trennzeichen im gesamten System fest und halten Sie diese aufrecht, damit das Modell Grenzen leichter erkennt und Verwirrung durch inkonsistente Formatierungen vermieden wird.
Grenzen testen und validieren: Überprüfen Sie systematisch, ob das Modell die definierten Grenzen respektiert, indem Sie versuchen, es zum Überschreiten zu verleiten, um Lücken vor der Produktivsetzung zu identifizieren und zu schließen.
Kontextdrift überwachen: Verfolgen Sie kontinuierlich, ob die Modellantworten im Zeitverlauf innerhalb der gewünschten Grenzen bleiben, da sich das Verhalten des Modells mit unterschiedlichen Eingabemustern oder sich entwickelnder Wissensbasis verändern kann.
Feedback-Schleifen implementieren: Erstellen Sie Mechanismen, damit Nutzer oder menschliche Prüfer Fälle melden können, in denen das Modell die Grenzen überschritten hat, und nutzen Sie dieses Feedback zur Verfeinerung der Kontextdefinitionen und zur Leistungsverbesserung.
Kontextdefinitionen versionieren: Behandeln Sie Kontextgrenzen wie Code, führen Sie Versionshistorien und Dokumentation von Änderungen, um bei Verschlechterung der Ergebnisse auf vorherige Definitionen zurückgreifen zu können.
Verschiedene Plattformen haben kontextuelles Einfassen fest in ihr Angebot integriert. CustomGPT.ai setzt Kontextgrenzen durch das „Kontextgrenzen“-Feature um, das als Schutzwall dient und sicherstellt, dass die KI nur vom Nutzer bereitgestellte Daten verwendet und niemals Allgemeinwissen oder erfundene Informationen einbezieht – dieser Ansatz hat sich für Organisationen wie das MIT, die absolute Genauigkeit benötigen, bewährt. Anthropics Claude legt Wert auf die Prinzipien des Kontext Engineerings, bietet ausführliche Dokumentation zur Promptstrukturierung, Verwaltung von Kontextfenstern und Implementierung von Guardrails, die Antworten innerhalb definierter Grenzen halten. AWS Bedrock Guardrails bietet automatisierte Reasoning-Prüfungen, die generierte Inhalte anhand mathematischer und logischer Regeln validieren, wobei Grounding-Scores anzeigen, ob Antworten innerhalb des Ausgangsmaterials bleiben (für Finanzanwendungen sind Scores über 0,85 erforderlich). Shelf.io stellt RAG-Lösungen mit Kontextmanagement bereit und ermöglicht es Organisationen, Retrieval-Augmented Generation zu implementieren, während strikte Grenzen um zugängliche und referenzierbare Informationen eingehalten werden. AmICited.com ergänzt dieses Angebot, indem überwacht wird, wie KI-Systeme Ihre Marke über verschiedene KI-Plattformen hinweg zitieren und referenzieren – so erhalten Sie Einblick, ob KI-Modelle angemessene Kontextgrenzen bei der Diskussion Ihrer Organisation respektieren oder sich innerhalb genauer, verifizierter Informationen über Ihre Marke bewegen und somit sichtbar machen, ob kontextuelles Einfassen „in freier Wildbahn“ wirksam ist.
Prompt Engineering konzentriert sich hauptsächlich auf das Erstellen effektiver Anweisungen und Beispiele, während kontextuelles Einfassen einen systematischen Ansatz zur Verwaltung aller Kontextelemente durch explizite Trennzeichen und Grenzen darstellt. Kontextuelles Einfassen ist strukturierter und präventiver, indem es auf Eingabeebene Halluzinationen verhindert, bevor sie entstehen, während Prompt Engineering breiter gefasst ist und verschiedene Optimierungstechniken umfasst.
Kontextuelles Einfassen verhindert Halluzinationen, indem klare Informationsgrenzen mit Trennzeichen wie XML-Tags oder Markdown-Überschriften gesetzt werden. Das teilt dem KI-Modell genau mit, welche Informationen es berücksichtigen und welche es ignorieren soll, wodurch es daran gehindert wird, Details zu erfinden oder Annahmen über nicht explizit genannte Informationen zu treffen. Durch die Begrenzung der Modellaufmerksamkeit auf definierte Grenzen wird die Wahrscheinlichkeit der Generierung falscher Fakten oder nicht existierender Quellen reduziert.
Übliche Trennzeichen sind XML-Tags (wie
Die Prinzipien des kontextuellen Einfassens lassen sich auf die meisten modernen Sprachmodelle anwenden, wobei die Wirksamkeit variiert. Modelle, die besser auf Anweisungen trainiert wurden (wie Claude, GPT-4 und Gemini), respektieren Grenzen in der Regel zuverlässiger. Die Technik funktioniert am besten in Kombination mit Modellen, die strukturierte Ausgaben unterstützen und auf vielfältigen, gut formatierten Daten trainiert wurden.
Beginnen Sie damit, Ihre Systemprompts mit klaren Trennzeichen in unterschiedliche Abschnitte zu gliedern. Strukturieren Sie Eingaben und Ausgaben mit JSON- oder XML-Schemas. Verwenden Sie durchgehend einheitliche Trennmuster. Implementieren Sie Few-Shot-Beispiele, die dem Modell genau zeigen, wie es Grenzen respektieren soll. Testen Sie ausführlich, ob das Modell die definierten Grenzen einhält, und überwachen Sie die Leistung im Zeitverlauf, um Kontextdrift zu erkennen.
Kontextuelles Einfassen kann durch zusätzliche Trennzeichen und Strukturmarker den Tokenverbrauch leicht erhöhen, was jedoch in der Regel durch verbesserte Genauigkeit und geringere Halluzinationen ausgeglichen wird. Die Technik steigert tatsächlich die Effizienz, da das Modell keine Tokens für erfundene Informationen verschwendet. In Produktionssystemen überwiegen die Genauigkeitsgewinne den minimalen Token-Overhead deutlich.
Kontextuelles Einfassen und RAG sind komplementäre Techniken. RAG ruft relevante Informationen aus externen Quellen ab, während kontextuelles Einfassen sicherstellt, dass das Modell innerhalb der Grenzen dieser abgerufenen Informationen bleibt. Zusammen entsteht so ein leistungsfähiges System, in dem das Modell auf externes Wissen zugreifen kann, aber nur verifizierte, abgerufene Quellen referenziert.
Mehrere Plattformen bieten integrierte Unterstützung: CustomGPT.ai verfügt über Funktionen für Kontextgrenzen, Anthropics Claude bietet Dokumentation zum Kontext-Engineering und strukturierte Ausgabemöglichkeiten, AWS Bedrock Guardrails beinhaltet automatisierte Reasoning-Prüfungen, und Shelf.io stellt RAG-Lösungen mit Kontextmanagement bereit. AmICited.com überwacht, wie KI-Systeme Ihre Marke zitieren, und hilft dabei zu prüfen, ob das kontextuelle Einfassen effektiv funktioniert.
Kontextuelles Einfassen stellt sicher, dass KI-Systeme genaue Informationen über Ihre Marke liefern. Nutzen Sie AmICited, um zu verfolgen, wie KI-Modelle Ihre Inhalte in GPTs, Perplexity und Google AI Overviews zitieren und referenzieren.
Erfahren Sie, was Kontextfenster in KI-Sprachmodellen sind, wie sie funktionieren, welchen Einfluss sie auf die Modellleistung haben und warum sie für KI-gestüt...

Kontextfenster erklärt: die maximale Anzahl an Tokens, die ein LLM auf einmal verarbeiten kann. Erfahren Sie, wie Kontextfenster die KI-Genauigkeit, Halluzinati...

Erfahren Sie, was ein konversationelles Kontextfenster ist, wie es KI-Antworten beeinflusst und warum es für effektive KI-Interaktionen wichtig ist. Verstehen S...