Techniken, um sicherzustellen, dass KI-Crawler innerhalb ihrer Crawling-Grenzen effizient auf die wichtigsten Inhalte einer Website zugreifen und diese indexieren. Die Optimierung des Crawl-Budgets steuert das Gleichgewicht zwischen Crawling-Kapazität (Serverressourcen) und Crawling-Nachfrage (Bot-Anfragen), um die Sichtbarkeit in KI-generierten Antworten zu maximieren und gleichzeitig die Betriebskosten und Serverbelastung zu kontrollieren.
Crawl-Budget-Optimierung für KI
Techniken, um sicherzustellen, dass KI-Crawler innerhalb ihrer Crawling-Grenzen effizient auf die wichtigsten Inhalte einer Website zugreifen und diese indexieren. Die Optimierung des Crawl-Budgets steuert das Gleichgewicht zwischen Crawling-Kapazität (Serverressourcen) und Crawling-Nachfrage (Bot-Anfragen), um die Sichtbarkeit in KI-generierten Antworten zu maximieren und gleichzeitig die Betriebskosten und Serverbelastung zu kontrollieren.
Was ist das Crawl-Budget im KI-Zeitalter
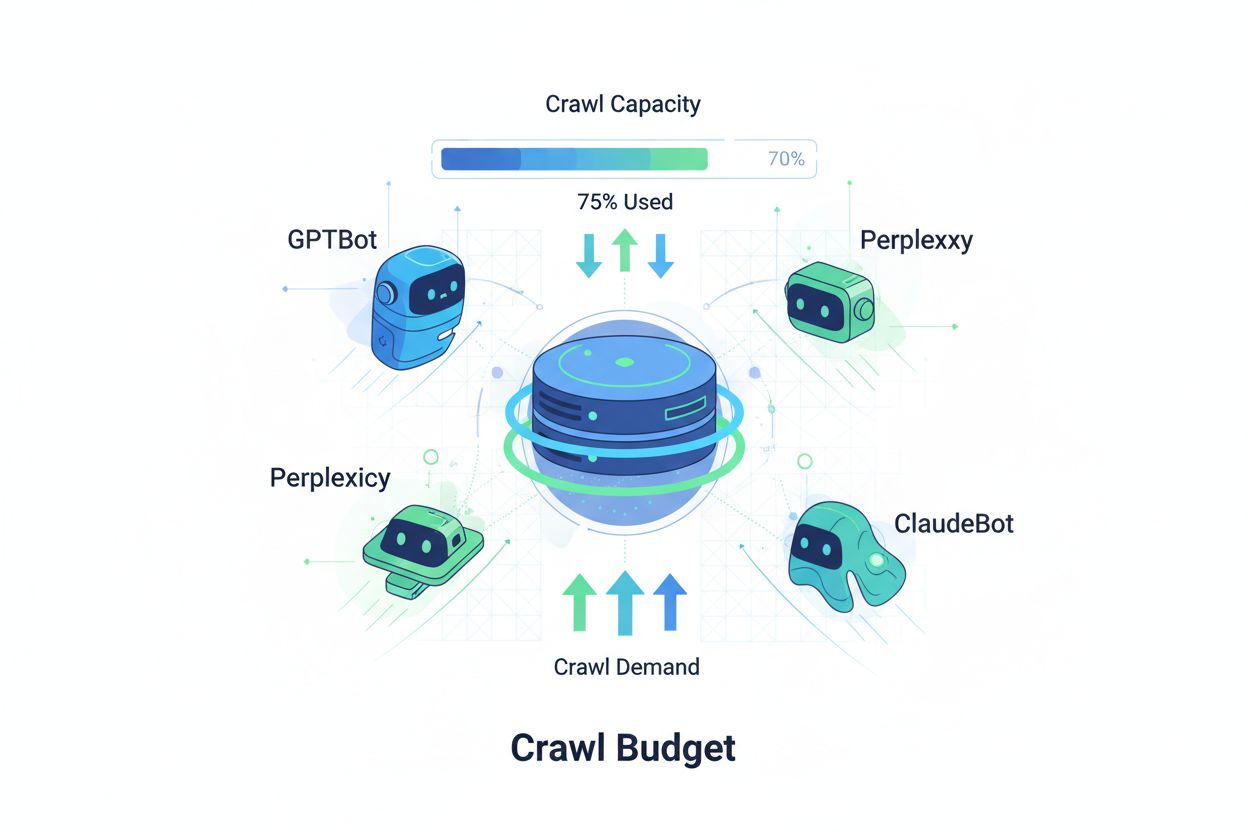
Crawl-Budget bezeichnet die Menge an Ressourcen – gemessen in Anfragen und Bandbreite – die Suchmaschinen und KI-Bots für das Crawlen Ihrer Website bereitstellen. Traditionell bezog sich dieses Konzept vor allem auf das Crawling-Verhalten von Google, doch das Aufkommen KI-gestützter Bots hat die Anforderungen an das Crawl-Budget-Management grundlegend verändert. Die Crawl-Budget-Gleichung besteht aus zwei zentralen Variablen: Crawl-Kapazität (die maximale Anzahl Seiten, die ein Bot crawlen kann) und Crawl-Nachfrage (die tatsächliche Anzahl Seiten, die der Bot crawlen möchte). Im KI-Zeitalter ist diese Dynamik exponentiell komplexer geworden, da Bots wie GPTBot (OpenAI), Perplexity Bot und ClaudeBot (Anthropic) nun neben traditionellen Suchmaschinen-Crawlern um Serverressourcen konkurrieren. Diese KI-Bots agieren mit anderen Prioritäten und Mustern als Googlebot und verbrauchen dabei oft deutlich mehr Bandbreite, während sie andere Indexierungsziele verfolgen. Daher ist die Crawl-Budget-Optimierung nicht mehr optional, sondern unerlässlich, um die Seitenleistung zu sichern und Betriebskosten zu kontrollieren.
Warum KI-Crawler alles verändert haben
KI-Crawler unterscheiden sich grundlegend von traditionellen Suchmaschinen-Bots hinsichtlich ihres Crawling-Musters, ihrer Frequenz und ihres Ressourcenverbrauchs. Während Googlebot Crawl-Budget-Grenzen respektiert und ausgefeilte Drosselungsmechanismen einsetzt, zeigen KI-Bots oft aggressivere Crawling-Verhaltensweisen, fordern dieselben Inhalte mehrfach an und reagieren weniger auf Signale zur Serverbelastung. Untersuchungen zeigen, dass OpenAIs GPTBot auf bestimmten Websites 12- bis 15-mal mehr Bandbreite verbrauchen kann als Googles Crawler, insbesondere bei großen Inhaltsbibliotheken oder häufig aktualisierten Seiten. Dieser aggressive Ansatz resultiert aus den Anforderungen des KI-Trainings: Diese Bots müssen kontinuierlich neue Inhalte aufnehmen, um die Modellleistung zu verbessern – ein grundlegend anderes Crawling-Paradigma als Suchmaschinen, die auf Indexierung für die Suche fokussiert sind. Die Serverbelastung ist erheblich: Organisationen berichten über deutliche Steigerungen bei Bandbreitenkosten, CPU-Auslastung und Serverlast, die direkt auf KI-Bot-Traffic zurückzuführen sind. Außerdem kann das gleichzeitige Crawlen mehrerer KI-Bots die Nutzererfahrung beeinträchtigen, Ladezeiten verlängern und Hosting-Kosten erhöhen – die Unterscheidung zwischen traditionellen und KI-Crawlern ist damit eine geschäftskritische Entscheidung und keine technische Kuriosität.
Eigenschaft
Traditionelle Crawler (Googlebot)
KI-Crawler (GPTBot, ClaudeBot)
Crawl-Frequenz
Anpassungsfähig, respektiert Crawl-Budget
Aggressiv, kontinuierlich
Bandbreitenverbrauch
Moderat, optimiert
Hoch, ressourcenintensiv
Respekt vor Robots.txt
Strikte Einhaltung
Unterschiedliche Einhaltung
Caching-Verhalten
Ausgereiftes Caching
Häufige Neu-Anfragen
User-Agent-Kennung
Klar, konsistent
Teilweise verschleiert
Geschäftsziel
Suchindexierung
Modelltraining/Datenakquise
Kosten-Auswirkung
Gering
Signifikant (12-15x höher)
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Das Verständnis des Crawl-Budgets erfordert die Kenntnis seiner beiden Grundkomponenten: Crawl-Kapazität und Crawl-Nachfrage. Crawl-Kapazität steht für die maximale Anzahl von URLs, die Ihr Server innerhalb eines bestimmten Zeitraums verarbeiten kann, bestimmt durch verschiedene, miteinander verknüpfte Faktoren. Diese Kapazität wird beeinflusst durch:
Geografische Verteilung (Multi-Region-Hosting steigert die Kapazität)
Crawl-Nachfrage hingegen beschreibt, wie viele Seiten Bots tatsächlich crawlen wollen, getrieben durch Inhaltsmerkmale und Bot-Prioritäten. Faktoren, die die Crawl-Nachfrage beeinflussen, sind:
Aktualität der Inhalte (häufig aktualisierte Seiten werden öfter gecrawlt)
Inhaltsqualität und Autorität (hochwertige Seiten erhalten höhere Crawl-Priorität)
Aktualisierungshäufigkeit (täglich aktualisierte Seiten ziehen mehr Aufmerksamkeit auf sich)
Interne Verlinkungsstruktur (gut verlinkte Seiten werden öfter gecrawlt)
Sitemap-Aufnahme (Seiten in Sitemaps erhalten höhere Crawl-Priorität)
Historische Crawl-Muster (Bots lernen, welche Seiten sich häufig ändern)
Die Optimierungsherausforderung entsteht, wenn die Crawl-Nachfrage die Crawl-Kapazität übersteigt – Bots müssen dann Seiten auswählen und verpassen womöglich wichtige Updates. Umgekehrt verschwenden Sie Ressourcen, wenn die Kapazität die Nachfrage deutlich übersteigt. Ziel ist Crawl-Effizienz: Das Crawling wichtiger Seiten maximieren und unnötige Crawls auf wenig wertvolle Inhalte minimieren. Dieses Gleichgewicht wird im KI-Zeitalter immer komplexer, da verschiedene Bot-Typen mit unterschiedlichen Prioritäten um dieselben Ressourcen konkurrieren und ausgefeilte Strategien zur effektiven Verteilung des Crawl-Budgets erfordern.
So messen Sie die aktuelle Crawl-Budget-Performance
Die Messung der Crawl-Budget-Performance beginnt mit derGoogle Search Console, die unter „Einstellungen“ Crawl-Statistiken wie tägliche Anfragen, heruntergeladene Bytes und Antwortzeiten anzeigt. Um das Crawl-Effizienz-Verhältnis zu berechnen, teilen Sie die Anzahl erfolgreicher Crawls (HTTP 200) durch die Gesamtzahl der Crawl-Anfragen. Gesunde Seiten erreichen meist 85-95 % Effizienz. Die Formel für die Crawl-Effizienz lautet: (Erfolgreiche Crawls ÷ Gesamtanzahl der Crawl-Anfragen) × 100 = Crawl-Effizienz %. Darüber hinaus ist für die Praxis wichtig:
Server-Log-Analyse mit Tools wie Splunk oder ELK Stack, um sämtlichen Bot-Traffic einschließlich KI-Crawler zu identifizieren
Überwachung der 4xx- und 5xx-Fehlerraten, um zu erkennen, wo das Budget auf Fehlerseiten verschwendet wird
Monitoring der Crawltiefe (wie tief Bots in Ihre Seitenstruktur vordringen)
Messung der Antwortzeit-Trends, um Leistungseinbußen durch Crawling zu identifizieren
Traffic-Segmentierung nach User-Agent, um zu erkennen, welche Bots die meisten Ressourcen verbrauchen
Für die gezielte Überwachung von KI-Crawlern bieten Tools wie AmICited.com spezielles Tracking für GPTBot, ClaudeBot und Perplexity Bot und geben Einblicke, welche Seiten priorisiert und wie häufig sie besucht werden. Das Einrichten individueller Alarme bei ungewöhnlichen Crawl-Spikes – insbesondere durch KI-Bots – ermöglicht eine schnelle Reaktion auf unerwarteten Ressourcenverbrauch. Die zentrale Metrik ist Crawl-Kosten pro Seite: Teilen Sie die insgesamt durch Crawls verbrauchten Serverressourcen durch die Zahl der eindeutig gecrawlten Seiten, um zu erkennen, ob Sie Ihr Budget effizient oder auf wenig wertvolle Seiten verschwenden.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Optimierungsstrategien für KI-Crawler
Die Optimierung des Crawl-Budgets für KI-Bots erfordert einen mehrschichtigen Ansatz aus technischer Umsetzung und strategischer Entscheidung. Die wichtigsten Optimierungstaktiken umfassen:
Verfeinerung der robots.txt: Blockieren Sie KI-Bots beim Crawlen von Seiten mit geringem Wert (Archive, Duplikate, Admin-Bereiche) und erlauben Sie den Zugriff auf Kerninhalte
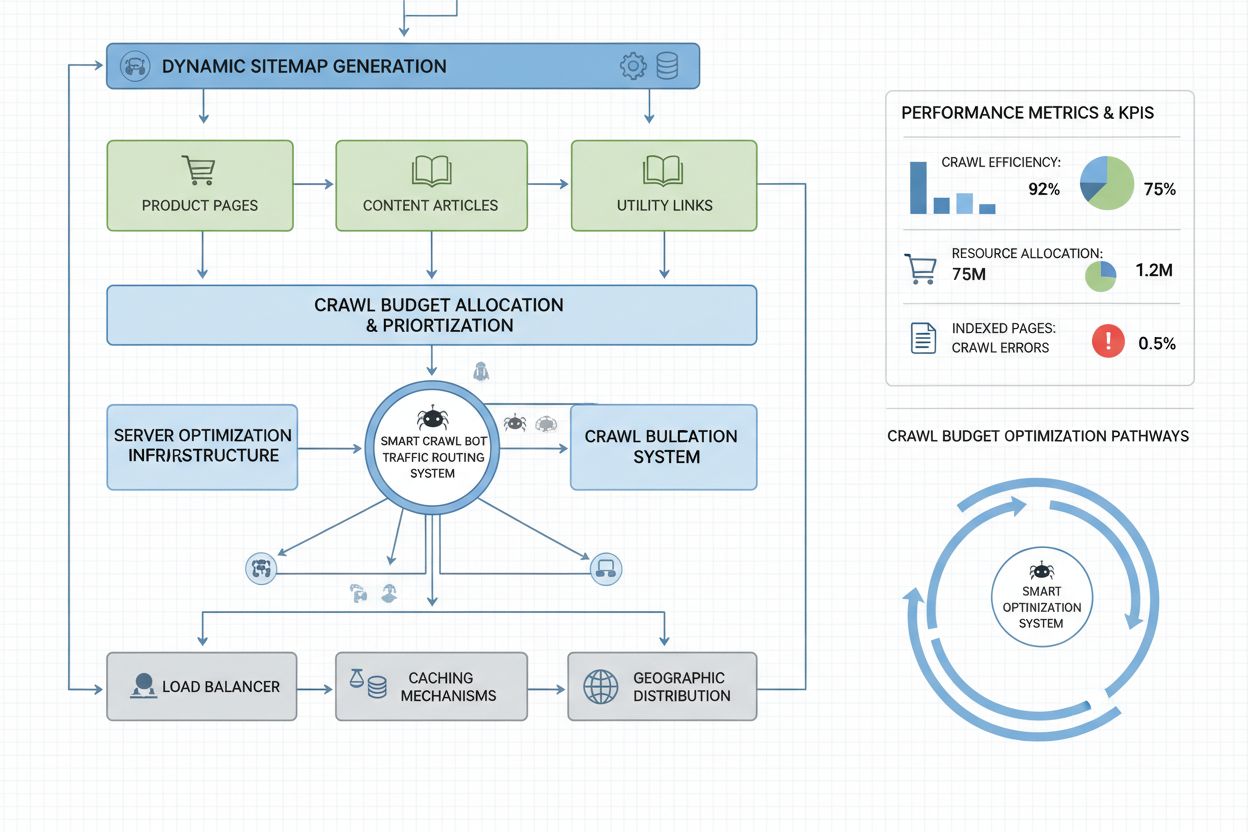
Dynamische Sitemaps: Erstellen Sie separate Sitemaps für unterschiedliche Inhaltstypen und priorisieren Sie regelmäßig aktualisierte und wertvolle Seiten
Optimierung der URL-Struktur: Implementieren Sie saubere, hierarchische URLs, um die Crawltiefe zu reduzieren und wichtige Seiten besser auffindbar zu machen
Selektives Blockieren: Nutzen Sie agentenspezifische Regeln, um Googlebot zuzulassen, aber aggressive KI-Bots zu beschränken, falls diese zu viele Ressourcen verbrauchen
Crawl-Delay-Direktiven: Setzen Sie in robots.txt angemessene Crawl-Delay-Werte, um Bot-Anfragen zu drosseln (auch wenn nicht alle KI-Bots dies beachten)
Kanonisierung: Nutzen Sie Canonical-Tags konsequent, um Duplikate zu konsolidieren und Crawl-Verschwendung auf Varianten zu vermeiden
Welche Taktik die richtige ist, hängt vom Geschäftsmodell und der Content-Strategie ab. E-Commerce-Seiten könnten KI-Crawler auf Produktseiten blockieren, um das Training von Wettbewerbern zu verhindern, während Publisher das Crawling zulassen, um Sichtbarkeit in KI-generierten Antworten zu erhalten. Bei echter Serverüberlastung durch KI-Bot-Traffic ist das agentenspezifische Blockieren per robots.txt die direkteste Lösung: User-agent: GPTBot gefolgt von Disallow: / verhindert, dass OpenAIs Crawler überhaupt auf Ihre Website zugreift. Allerdings verzichten Sie damit auf potenzielle Sichtbarkeit in ChatGPT-Antworten und anderen KI-Anwendungen. Eine differenziertere Strategie ist selektives Blockieren: Erlauben Sie KI-Crawlern den Zugriff auf öffentliche Inhalte, blockieren Sie aber sensible Bereiche, Archive oder Duplikate, die das Crawl-Budget ohne Mehrwert für Nutzer oder Bot verschwenden.
Fortgeschrittene Techniken für große Websites
Websites im Unternehmensmaßstab mit Millionen von Seiten benötigen weitergehende Crawl-Budget-Optimierung als eine reine robots.txt-Konfiguration. Dynamische Sitemaps sind ein entscheidender Fortschritt, da sie in Echtzeit basierend auf Aktualität, Wichtigkeit und Crawl-Historie generiert werden. Statt statischer XML-Sitemaps mit allen Seiten priorisieren dynamische Sitemaps kürzlich aktualisierte, stark besuchte und konversionsstarke Seiten, damit Bots ihr Budget auf relevante Inhalte konzentrieren. URL-Segmentierung teilt Ihre Website in logische Crawl-Zonen mit je eigenen Optimierungsstrategien – etwa häufige Sitemap-Updates für News-Bereiche und selteneres für Evergreen-Inhalte.
Serverseitige Optimierung umfasst Crawl-bewusstes Caching, das Bots gecachte Antworten liefert, während Nutzer frische Inhalte erhalten, und so die Serverlast durch wiederholte Bot-Anfragen reduziert. Content Delivery Networks (CDNs) mit bot-spezifischem Routing können Bot-Traffic vom Nutzer-Traffic abkoppeln und verhindern, dass Crawler die für Besucher notwendige Bandbreite verbrauchen. Ratenbegrenzung nach User-Agent ermöglicht es, KI-Bot-Anfragen zu drosseln und gleichzeitig Googlebot und Nutzern normale Geschwindigkeit zu bieten. Für sehr große Websites sorgt verteiltes Crawl-Budget-Management über mehrere Serverregionen dafür, dass es keinen Single Point of Failure gibt und Bot-Traffic geografisch ausbalanciert wird. Machine-Learning-basierte Crawl-Vorhersagen analysieren historische Muster, um vorherzusagen, welche Seiten Bots als nächstes anfordern – so können diese Seiten proaktiv optimiert und gecacht werden. Diese Enterprise-Strategien machen das Crawl-Budget von einer Einschränkung zu einer steuerbaren Ressource und ermöglichen es großen Organisationen, Milliarden Seiten performant für Bots und Nutzer bereitzustellen.
Die strategische Entscheidung – KI-Crawler blockieren oder zulassen?
Die Entscheidung, KI-Crawler zu blockieren oder zuzulassen, ist eine grundlegende geschäftsstrategische Wahl mit weitreichenden Folgen für Sichtbarkeit, Wettbewerbsfähigkeit und Betriebskosten. Das Zulassen von KI-Crawlern bringt erhebliche Vorteile: Ihre Inhalte können in KI-generierten Antworten erscheinen und so Traffic von ChatGPT, Claude, Perplexity und anderen KI-Anwendungen generieren; Ihre Marke gewinnt Sichtbarkeit in einem neuen Distributionskanal; und Sie profitieren von den SEO-Signalen, die aus KI-Zitierungen resultieren. Allerdings entstehen auch Kosten: höhere Serverlast und Bandbreitenverbrauch, mögliches Training von Wettbewerber-KI-Modellen auf Ihren Inhalten und Kontrollverlust darüber, wie Ihre Informationen in KI-Antworten dargestellt und attribuiert werden.
Das Blockieren von KI-Crawlern eliminiert diese Kosten, aber Sie verzichten auf Sichtbarkeitsvorteile und geben unter Umständen Marktanteile an Wettbewerber ab, die das Crawling zulassen. Die optimale Strategie hängt vom Geschäftsmodell ab: Content-Publisher und Nachrichtenportale profitieren meist vom Zulassen, um über KI-Zusammenfassungen verteilt zu werden; SaaS-Firmen und E-Commerce blockieren oft, um Wettbewerber am Training auf Produktdaten zu hindern; Bildungs- und Forschungsinstitutionen erlauben Crawling meist, um Wissen maximal zu verbreiten. Ein hybrider Ansatz bietet einen Mittelweg: Erlauben Sie das Crawling öffentlicher Inhalte, blockieren Sie sensible Bereiche, User-Generated Content oder proprietäre Informationen. So maximieren Sie die Sichtbarkeit und schützen gleichzeitig wertvolle Assets. Das Monitoring mit AmICited.com und ähnlichen Tools zeigt außerdem, ob Ihre Inhalte tatsächlich von KI-Systemen zitiert werden – erscheint Ihre Seite trotz Zulassung nicht in KI-Antworten, wird das Blockieren attraktiver, da Sie die Kosten tragen, aber keinen Sichtbarkeitsvorteil haben.
Tools und Monitoring für das Crawl-Budget-Management
Effektives Crawl-Budget-Management erfordert spezialisierte Tools, die Einblick in das Bot-Verhalten geben und datenbasierte Optimierungsentscheidungen ermöglichen. Conductor und Sitebulb bieten Enterprise-Crawl-Analysen, simulieren Suchmaschinen-Crawling, identifizieren Ineffizienzen, verschwendete Crawls auf Fehlerseiten und Optimierungsmöglichkeiten bei der Budgetzuweisung. Cloudflare ermöglicht Bot-Management auf Netzwerkebene, granular gesteuert nach Bot-Typ, inklusive Ratenbegrenzung für KI-Crawler. Für KI-Crawler-spezifisches Monitoring ist AmICited.com die umfassendste Lösung: Tracking von GPTBot, ClaudeBot, Perplexity Bot und anderen KI-Crawlern mit detaillierten Analysen, welche Seiten besucht und wie häufig sie zurückkehren – sowie, ob Ihre Inhalte in KI-Antworten erscheinen.
Server-Log-Analyse bleibt das Fundament der Crawl-Budget-Optimierung: Tools wie Splunk, Datadog oder der Open-Source-ELK Stack ermöglichen das Parsen von Zugriffsdaten, die Segmentierung nach User-Agent und die Identifikation der ressourcenintensivsten Bots und am meisten gecrawlten Seiten. Individuelle Dashboards mit Crawl-Trends zeigen, ob Optimierungsmaßnahmen greifen und ob neue Bot-Typen auftreten. Google Search Console liefert weiterhin essenzielle Daten zum Google-Crawling, Bing Webmaster Tools für Microsofts Crawler. Die fortschrittlichsten Organisationen implementieren Multi-Tool-Monitoring: Google Search Console für traditionelle Suchdaten, AmICited.com für KI-Crawler-Tracking, Server-Log-Analyse für umfassende Bot-Sichtbarkeit und Spezialtools wie Conductor für Simulation und Effizienzbewertung. Dieser gestufte Ansatz schafft vollständige Transparenz über das Zusammenspiel aller Bot-Typen mit Ihrer Website und ermöglicht eine Optimierung auf Basis vollständiger Daten statt Vermutungen. Regelmäßiges Monitoring – idealerweise wöchentliche Überprüfung der Crawl-Metriken – erlaubt eine schnelle Identifikation von Problemen wie unerwarteten Crawling-Spitzen, steigenden Fehlerquoten oder neuen aggressiven Bots, sodass Sie reagieren können, bevor Crawl-Budget-Probleme die Seitenleistung oder Kosten beeinflussen.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Crawl-Budget für KI-Bots und Googlebot?
KI-Bots wie GPTBot und ClaudeBot arbeiten mit anderen Prioritäten als Googlebot. Während Googlebot Crawl-Budget-Grenzen respektiert und ausgefeiltes Throttling implementiert, zeigen KI-Bots oft aggressivere Crawling-Muster und verbrauchen 12- bis 15-mal mehr Bandbreite. KI-Bots priorisieren die kontinuierliche Inhaltsaufnahme für das Modelltraining statt für die Suchindexierung, wodurch ihr Crawl-Verhalten grundlegend verschieden ist und eigene Optimierungsstrategien erfordert.
Wie viel Crawl-Budget verbrauchen KI-Bots typischerweise?
Untersuchungen zeigen, dass OpenAIs GPTBot auf bestimmten Websites – insbesondere mit großen Inhaltsbibliotheken – 12- bis 15-mal mehr Bandbreite verbrauchen kann als Googles Crawler. Der genaue Verbrauch hängt von der Größe Ihrer Website, der Aktualisierungshäufigkeit der Inhalte und der Anzahl der gleichzeitig crawlenden KI-Bots ab. Mehrere KI-Bots, die gleichzeitig crawlen, können die Serverbelastung und die Hosting-Kosten erheblich steigern.
Kann ich bestimmte KI-Crawler blockieren, ohne das SEO zu beeinflussen?
Ja, Sie können bestimmte KI-Crawler mit robots.txt blockieren, ohne das traditionelle SEO zu beeinträchtigen. Das Blockieren von KI-Crawlern bedeutet jedoch, dass Sie auf Sichtbarkeit in KI-generierten Antworten von ChatGPT, Claude, Perplexity und anderen KI-Anwendungen verzichten. Die Entscheidung hängt von Ihrem Geschäftsmodell ab – Content-Publisher profitieren in der Regel vom Zulassen, während E-Commerce-Seiten eher blockieren, um das Training von Wettbewerbern zu verhindern.
Welche Auswirkungen hat ein schlechtes Crawl-Budget-Management auf meine Website?
Schlechtes Crawl-Budget-Management kann dazu führen, dass wichtige Seiten nicht gecrawlt oder indexiert werden, neue Inhalte langsamer indexiert werden, die Serverlast und Bandbreitenkosten steigen, die Nutzererfahrung durch Bot-Traffic beeinträchtigt wird und Sichtbarkeitschancen in traditionellen Suchen und KI-generierten Antworten verpasst werden. Große Websites mit Millionen von Seiten sind dafür besonders anfällig.
Für optimale Ergebnisse überwachen Sie die Crawl-Budget-Metriken wöchentlich, bei großen Content-Launches oder unerwarteten Traffic-Spitzen täglich. Nutzen Sie die Google Search Console für traditionelle Crawling-Daten, AmICited.com zur Überwachung von KI-Crawlern und Server-Logs für umfassende Bot-Sichtbarkeit. Regelmäßiges Monitoring ermöglicht eine schnelle Problemerkennung, bevor die Seitenleistung beeinträchtigt wird.
Ist robots.txt wirksam, um das Crawling von KI-Bots zu steuern?
Die Wirksamkeit von robots.txt bei KI-Bots ist unterschiedlich. Während Googlebot robots.txt-Direktiven strikt befolgt, ist die Einhaltung bei KI-Bots inkonsistent – einige halten sich an die Regeln, andere ignorieren sie. Für mehr Kontrolle sollten Sie agentenspezifisches Blockieren, Ratenbegrenzungen auf Serverebene oder CDN-basierte Bot-Management-Tools wie Cloudflare einsetzen.
Wie hängt das Crawl-Budget mit der KI-Sichtbarkeit zusammen?
Das Crawl-Budget beeinflusst die KI-Sichtbarkeit direkt, denn KI-Bots können Inhalte, die sie nicht gecrawlt haben, weder zitieren noch referenzieren. Wenn wichtige Seiten aus Budgetgründen nicht gecrawlt werden, erscheinen sie nicht in KI-generierten Antworten. Die Optimierung des Crawl-Budgets stellt sicher, dass Ihre besten Inhalte von KI-Bots entdeckt werden und erhöht die Wahrscheinlichkeit, in ChatGPT-, Claude- oder Perplexity-Antworten zitiert zu werden.
Wie priorisiere ich, welche Seiten von KI-Bots gecrawlt werden sollen?
Priorisieren Sie Seiten mit dynamischen Sitemaps, die kürzlich aktualisierte Inhalte, Seiten mit hohem Traffic und solche mit Konversionspotenzial hervorheben. Blockieren Sie mit robots.txt Seiten mit geringem Wert wie Archive und Duplikate. Implementieren Sie saubere URL-Strukturen und strategisches internes Linking, um Bots zu wichtigen Inhalten zu führen. Überwachen Sie mit Tools wie AmICited.com, welche Seiten KI-Bots tatsächlich crawlen, um Ihre Strategie zu verfeinern.
Überwachen Sie Ihr KI-Crawl-Budget effizient
Verfolgen Sie, wie KI-Bots Ihre Website crawlen, und optimieren Sie Ihre Sichtbarkeit in KI-generierten Antworten mit der umfassenden KI-Crawler-Monitoring-Plattform von AmICited.com.
Was ist das Crawl-Budget für KI? Verständnis der Ressourcenallokation von KI-Bots
Erfahren Sie, was das Crawl-Budget für KI bedeutet, wie es sich von traditionellen Such-Crawl-Budgets unterscheidet und warum es für die Sichtbarkeit Ihrer Mark...
Das Crawl-Budget ist die Anzahl der Seiten, die Suchmaschinen innerhalb eines Zeitraums auf deiner Website crawlen. Erfahre, wie du dein Crawl-Budget für eine b...
Crawl-Frequenz beschreibt, wie oft Suchmaschinen und KI-Crawler Ihre Seite besuchen. Erfahren Sie, was die Crawl-Rate beeinflusst, warum sie für SEO und KI-Sich...
12 Min. Lesezeit
Cookie-Zustimmung Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.