
Cross-Platform AI Publishing
Erfahren Sie, wie Cross-Platform AI Publishing Inhalte über mehrere Kanäle hinweg für die KI-Entdeckung optimiert verteilt. Verstehen Sie PESO-Kanäle, Automatis...
8 Min. Lesezeit
Cross-Origin AI Access bezeichnet die Fähigkeit von künstlichen Intelligenzsystemen und Webcrawlern, Inhalte von Domains anzufordern und abzurufen, die sich von ihrer eigenen Herkunft unterscheiden, wobei Sicherheitsmechanismen wie CORS gelten. Es umfasst, wie KI-Unternehmen die Datensammlung für das Training großer Sprachmodelle skalieren und dabei plattformübergreifende Beschränkungen umgehen. Das Verständnis dieses Konzepts ist für Content-Ersteller und Website-Betreiber entscheidend, um geistiges Eigentum zu schützen und die Kontrolle darüber zu behalten, wie ihre Inhalte von KI-Systemen genutzt werden. Transparenz über plattformübergreifende KI-Aktivitäten hilft dabei, legitimen KI-Zugriff von unbefugtem Scraping zu unterscheiden.
Cross-Origin AI Access bezeichnet die Fähigkeit von künstlichen Intelligenzsystemen und Webcrawlern, Inhalte von Domains anzufordern und abzurufen, die sich von ihrer eigenen Herkunft unterscheiden, wobei Sicherheitsmechanismen wie CORS gelten. Es umfasst, wie KI-Unternehmen die Datensammlung für das Training großer Sprachmodelle skalieren und dabei plattformübergreifende Beschränkungen umgehen. Das Verständnis dieses Konzepts ist für Content-Ersteller und Website-Betreiber entscheidend, um geistiges Eigentum zu schützen und die Kontrolle darüber zu behalten, wie ihre Inhalte von KI-Systemen genutzt werden. Transparenz über plattformübergreifende KI-Aktivitäten hilft dabei, legitimen KI-Zugriff von unbefugtem Scraping zu unterscheiden.
Cross-Origin AI Access bezeichnet die Fähigkeit von künstlichen Intelligenzsystemen und Webcrawlern, Inhalte von Domains anzufordern und abzurufen, die sich von ihrer eigenen Herkunft unterscheiden, wobei Sicherheitsmechanismen wie Cross-Origin Resource Sharing (CORS) gelten. Während KI-Unternehmen ihre Datensammlungsbemühungen ausweiten, um große Sprachmodelle und andere KI-Systeme zu trainieren, ist das Verständnis, wie diese Systeme plattformübergreifende Beschränkungen umgehen, für Content-Ersteller und Website-Betreiber von entscheidender Bedeutung geworden. Die Herausforderung besteht darin, zwischen legitimen KI-Zugriffen für Suchindexierung und unbefugtem Scraping zum Modelltraining zu unterscheiden – eine Transparenz über plattformübergreifende KI-Aktivitäten ist unerlässlich, um geistiges Eigentum zu schützen und die Kontrolle über die Nutzung von Inhalten zu behalten.
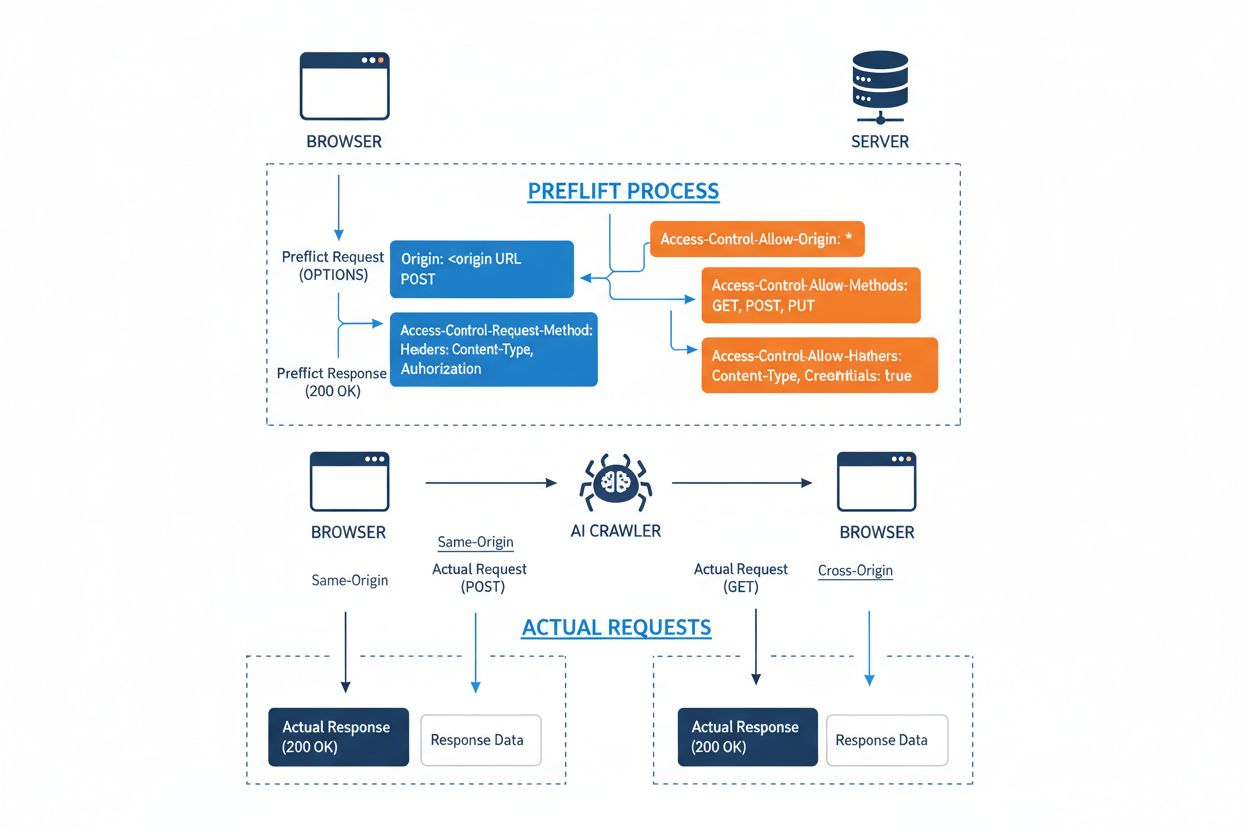
Cross-Origin Resource Sharing (CORS) ist ein auf HTTP-Headern basierender Sicherheitsmechanismus, mit dem Server festlegen können, welche Ursprünge (Domains, Protokolle oder Ports) auf ihre Ressourcen zugreifen dürfen. Wenn ein KI-Crawler oder ein anderer Client versucht, auf eine Ressource von einem anderen Ursprung aus zuzugreifen, initiiert der Browser oder Client eine Vorab-Anfrage mit der HTTP-Methode OPTIONS, um zu prüfen, ob der Server die eigentliche Anfrage zulässt. Der Server antwortet mit spezifischen CORS-Headern, die Zugriffsberechtigungen regeln – darunter, welche Ursprünge erlaubt sind, welche HTTP-Methoden gestattet werden, welche Header enthalten sein dürfen und ob Anmeldeinformationen wie Cookies oder Authentifizierungs-Token mitgesendet werden dürfen.
| CORS-Header | Zweck |
|---|---|
Access-Control-Allow-Origin | Legt fest, welche Ursprünge auf die Ressource zugreifen dürfen (* für alle oder bestimmte Domains) |
Access-Control-Allow-Methods | Listet zulässige HTTP-Methoden auf (GET, POST, PUT, DELETE, usw.) |
Access-Control-Allow-Headers | Definiert, welche Anfrage-Header erlaubt sind (Authorization, Content-Type, usw.) |
Access-Control-Allow-Credentials | Bestimmt, ob Anmeldeinformationen (Cookies, Authentifizierungstoken) mitgesendet werden dürfen |
Access-Control-Max-Age | Gibt an, wie lange Vorab-Antworten zwischengespeichert werden können (in Sekunden) |
Access-Control-Expose-Headers | Listet Antwort-Header auf, auf die Clients zugreifen dürfen |
KI-Crawler interagieren mit CORS, indem sie diese Header respektieren, wenn sie korrekt konfiguriert sind – viele ausgeklügelte Bots versuchen jedoch, diese Beschränkungen zu umgehen, indem sie User-Agents fälschen oder Proxy-Netzwerke nutzen. Die Wirksamkeit von CORS als Verteidigung gegen unbefugten KI-Zugriff hängt vollständig von der richtigen Serverkonfiguration und der Bereitschaft des Crawlers ab, die Beschränkungen einzuhalten – ein entscheidender Unterschied, der angesichts des Wettbewerbs um Trainingsdaten zwischen KI-Unternehmen immer wichtiger wird.
Das Feld der KI-Crawler, die auf das Web zugreifen, hat sich dramatisch ausgeweitet, wobei mehrere große Akteure die plattformübergreifenden Zugriffsmuster dominieren. Laut Cloudflares Analyse des Netzwerkverkehrs gehören zu den häufigsten KI-Crawlern:
Diese Crawler generieren jeden Monat Milliarden von Anfragen, wobei einige wie Bytespider und GPTBot auf den Großteil der öffentlich verfügbaren Internetinhalte zugreifen. Das enorme Volumen und die aggressive Natur dieser Aktivitäten haben dazu geführt, dass große Plattformen wie Reddit, Twitter/X, Stack Overflow und zahlreiche Nachrichtenorganisationen Blockiermaßnahmen umgesetzt haben.
Fehlkonfigurierte CORS-Richtlinien schaffen erhebliche Sicherheitslücken, die KI-Crawler ausnutzen können, um ohne Autorisierung auf sensible Daten zuzugreifen. Wenn Server Access-Control-Allow-Origin: * ohne korrekte Validierung setzen, erlauben sie versehentlich jedem Ursprung – einschließlich böswilliger KI-Scraper – den Zugriff auf eigentlich geschützte Ressourcen. Besonders gefährlich ist die Kombination aus Access-Control-Allow-Credentials: true und Platzhalter-Ursprüngen, wodurch Angreifer authentifizierte Nutzerdaten stehlen können, indem sie plattformübergreifende Anfragen inklusive Session-Cookies oder Authentifizierungs-Token absenden.
Häufige CORS-Fehlkonfigurationen umfassen das dynamische Spiegeln des Origin-Headers direkt in die Access-Control-Allow-Origin-Antwort ohne Validierung, was praktisch jedem Ursprung Zugriff gewährt. Zu großzügige Allow-Listen, die die Domain-Grenzen nicht korrekt prüfen, können durch Subdomain-Angriffe oder Präfix-Manipulation ausgenutzt werden. Außerdem versäumen es viele Organisationen, den Origin-Header selbst richtig zu prüfen, was sie für gefälschte Anfragen anfällig macht. Die Konsequenzen reichen über Datendiebstahl hinaus und umfassen unbefugtes KI-Modelltraining mit proprietären Inhalten, Wettbewerbsbeobachtung und Verletzung von Urheberrechten – Risiken, deren Monitoring und Quantifizierung durch Tools wie AmICited.com unterstützt wird.
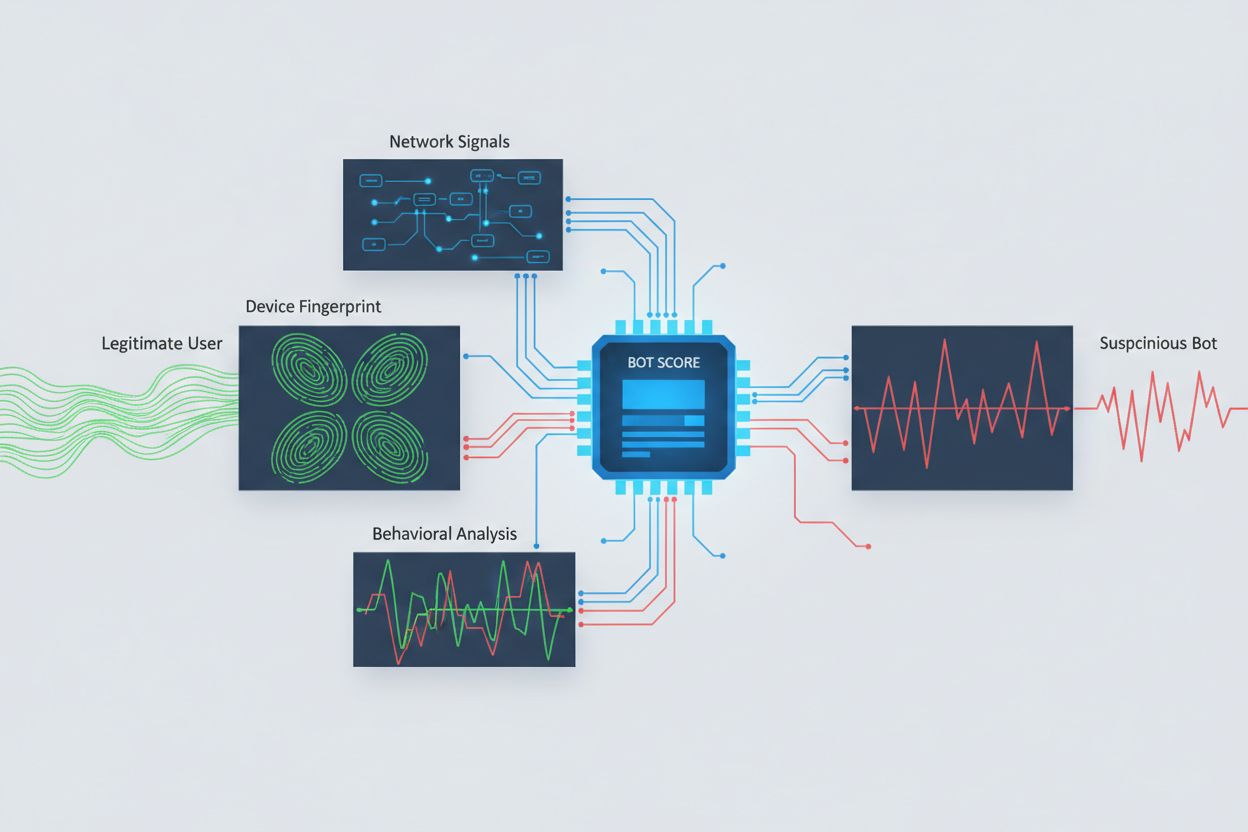
Um KI-Crawler zu identifizieren, die plattformübergreifenden Zugriff versuchen, müssen mehrere Signale analysiert werden – einfache User-Agent-Strings lassen sich leicht fälschen. Die Analyse von User-Agents bleibt eine erste Verteidigungslinie, da viele KI-Crawler sich durch spezifische User-Agent-Strings wie “GPTBot/1.0” oder “ClaudeBot/1.0” zu erkennen geben, während ausgeklügelte Crawler gezielt ihre Identität verschleiern, indem sie legitime Browser imitieren. Verhaltens-Fingerprinting analysiert, wie Anfragen gestellt werden – etwa Muster bei der Anfragesequenz, Zugriffszeiten, ob JavaScript ausgeführt wird und Interaktionsmuster, die sich grundlegend vom menschlichen Surfverhalten unterscheiden.
Die Analyse von Netzwerksignalen bietet tiefere Erkennungsmöglichkeiten, indem TLS-Handshake-Signaturen, IP-Reputation, DNS-Auflösungsmuster und Verbindungsmerkmale untersucht werden, die Bot-Aktivität selbst bei gefälschten User-Agents verraten. Geräte-Fingerprinting aggregiert Dutzende von Signalen wie Browserversion, Bildschirmauflösung, installierte Schriftarten, Betriebssystemdetails und JA3-TLS-Fingerprints, um eindeutige Identifizierer für jede Anfragequelle zu erstellen. Fortgeschrittene Erkennungssysteme können erkennen, wenn mehrere Sitzungen von demselben Gerät oder Skript ausgehen, und so verteilte Scraping-Versuche identifizieren, die versuchen, Rate-Limiting durch die Verteilung auf viele IP-Adressen zu umgehen. Organisationen können diese Methoden über Sicherheitsplattformen und Überwachungsdienste nutzen, um Transparenz darüber zu erhalten, welche KI-Systeme auf ihre Inhalte zugreifen und wie sie versuchen, Beschränkungen zu umgehen.
Organisationen setzen mehrere sich ergänzende Strategien ein, um plattformübergreifenden KI-Zugriff zu blockieren oder zu kontrollieren, da keine einzelne Methode vollständigen Schutz bietet:
User-agent: GPTBot gefolgt von Disallow: /) bietet einen höflichen, aber freiwilligen Mechanismus; wirksam bei gutartigen Crawlern, aber von entschlossenen Scraper leicht zu ignorierenDie effektivste Verteidigung kombiniert mehrere Ebenen, da entschlossene Angreifer jede Schwäche eines Einzelansatzes ausnutzen. Organisationen müssen kontinuierlich überwachen, welche Blockiermethoden wirken, und sich anpassen, sobald Crawler ihre Umgehungstechniken weiterentwickeln.
Ein effektives Management von plattformübergreifendem KI-Zugriff erfordert einen umfassenden, mehrschichtigen Ansatz, der Sicherheit und betriebliche Anforderungen ausbalanciert. Organisationen sollten eine gestufte Strategie umsetzen, die mit Grundkontrollen wie robots.txt und User-Agent-Filterung beginnt und dann je nach Bedrohungslage fortschrittlichere Erkennungs- und Blockiermechanismen ergänzt. Kontinuierliche Überwachung ist entscheidend – das Nachverfolgen, welche KI-Systeme auf Ihre Inhalte zugreifen, wie häufig sie Anfragen stellen und ob sie Ihre Beschränkungen respektieren, liefert die notwendige Transparenz für fundierte Entscheidungen zu Zugriffspolitiken.
Die Dokumentation von Zugriffspolitiken sollte klar und durchsetzbar sein, mit expliziten Nutzungsbedingungen, die unbefugtes Scraping verbieten und Konsequenzen bei Verstößen festlegen. Regelmäßige Prüfungen der CORS-Konfiguration helfen dabei, Fehlkonfigurationen zu erkennen, bevor sie ausgenutzt werden, während eine stets aktualisierte Liste bekannter KI-Crawler-User-Agents und IP-Bereiche eine schnelle Reaktion auf neue Bedrohungen ermöglicht. Organisationen sollten auch die geschäftlichen Auswirkungen der KI-Blockierung bedenken – einige KI-Crawler liefern Mehrwert durch Suchindexierung oder legitime Partnerschaften, daher sollten Richtlinien zwischen nützlichem und schädlichem Zugriff unterscheiden. Die Umsetzung dieser Praktiken erfordert Abstimmung zwischen Sicherheits-, Rechts- und Business-Teams, um sicherzustellen, dass Richtlinien mit den Unternehmenszielen und regulatorischen Anforderungen übereinstimmen.
Spezialisierte Tools und Plattformen helfen Organisationen dabei, plattformübergreifenden KI-Zugriff präziser und transparenter zu überwachen und zu kontrollieren. AmICited.com bietet umfassendes Monitoring, wie KI-Systeme Ihre Marke über GPTs, Perplexity, Google AI Overviews und andere KI-Plattformen hinweg referenzieren und darauf zugreifen, und gibt Einblick, welche KI-Modelle Ihre Inhalte verwenden und wie häufig Ihre Marke in KI-generierten Antworten erscheint. Diese Überwachungsfunktionen umfassen die Nachverfolgung plattformübergreifender Zugriffsmuster und das Verständnis des breiteren Ökosystems von KI-Systemen, die mit Ihren digitalen Assets interagieren.
Darüber hinaus bietet Cloudflare Bot-Management-Funktionen mit One-Click-Blockierung bekannter KI-Crawler, wobei maschinelles Lernen auf netzwerkweiten Verkehrsmustern beruht, um Bots auch bei gefälschten User-Agents zu erkennen. AWS WAF (Web Application Firewall) ermöglicht anpassbare Regeln zur Blockierung bestimmter User-Agents und IP-Bereiche, während Imperva fortschrittliche Bot-Erkennung mit Verhaltensanalyse und Threat Intelligence kombiniert. Bright Data ist spezialisiert auf das Verständnis von Bot-Traffic-Mustern und hilft Organisationen, verschiedene Crawler-Typen zu unterscheiden. Die Auswahl der Tools hängt von Größe, technischer Reife und Anforderungen der Organisation ab – vom einfachen robots.txt-Management für kleine Seiten bis hin zu Enterprise-Bot-Management-Plattformen für große Unternehmen mit sensiblen Daten. Unabhängig von der Toolwahl gilt: Transparenz über plattformübergreifenden KI-Zugriff ist die Grundlage für effektive Kontrolle und Schutz digitaler Assets.
CORS (Cross-Origin Resource Sharing) ist ein Sicherheitsmechanismus, der steuert, welche Ursprünge auf Ressourcen auf einem Server zugreifen dürfen. Cross-Origin AI Access bezieht sich speziell darauf, wie KI-Systeme und Crawler mit CORS interagieren, um Inhalte von verschiedenen Domains anzufordern. Während CORS den technischen Rahmen bildet, beschreibt Cross-Origin AI Access die praktische Herausforderung, das Verhalten von KI-Crawlern innerhalb dieses Rahmens zu managen, einschließlich Erkennung und Blockierung von unbefugtem KI-Zugriff.
Die meisten gutartigen KI-Crawler identifizieren sich über spezifische User-Agent-Strings wie 'GPTBot/1.0' oder 'ClaudeBot/1.0', die ihren Zweck klar angeben. Viele ausgeklügelte Crawler täuschen jedoch absichtlich User-Agents vor, indem sie legitime Browser wie Chrome oder Safari imitieren, um User-Agent-basierte Sperren zu umgehen. Daher sind fortschrittliche Erkennungsmethoden wie Verhaltens-Fingerprinting und Analyse von Netzwerksignalen notwendig, um Bots unabhängig von ihrer angegebenen Identität zu erkennen.
robots.txt bietet einen freiwilligen Mechanismus, um Crawler darum zu bitten, Zugriffsbeschränkungen zu respektieren, und gutartige KI-Crawler wie GPTBot halten sich in der Regel an diese Vorgaben. Allerdings ist robots.txt nicht durchsetzbar – entschlossene Scraper können diese einfach ignorieren. Viele KI-Unternehmen wurden dabei erwischt, robots.txt-Beschränkungen zu umgehen, was sie zu einer notwendigen, aber unzureichenden Verteidigung macht, die mit technischen Methoden wie User-Agent-Filterung, Rate-Limiting und Geräte-Fingerprinting kombiniert werden sollte.
Fehlkonfigurierte CORS-Richtlinien können unbefugten KI-Crawlern Zugriff auf sensible Daten ermöglichen, authentifizierte Nutzerinformationen durch Anfragen mit Anmeldeinformationen stehlen und proprietäre Inhalte für unbefugtes KI-Modelltraining auslesen. Die gefährlichsten Konfigurationen kombinieren Platzhalter-Ursprünge mit Anmeldeberechtigungen, sodass praktisch jeder Ursprung auf geschützte Ressourcen zugreifen kann. Diese Fehlkonfigurationen können zu Diebstahl geistigen Eigentums, Wettbewerbsbeobachtung und Verletzung von Inhaltslizenzvereinbarungen führen.
Die Erkennung erfordert die Analyse mehrerer Signale über User-Agent-Strings hinaus. Sie können Server-Logs auf bekannte KI-Crawler-User-Agents prüfen, Verhaltens-Fingerprinting implementieren, um Bots anhand ihres Interaktionsmusters zu erkennen, Netzwerksignale wie TLS-Handshakes und DNS-Muster analysieren und Geräte-Fingerprinting einsetzen, um verteilte Scraping-Versuche zu identifizieren. Tools wie AmICited.com bieten umfassende Überwachung, wie KI-Systeme Ihre Marke referenzieren, während Plattformen wie Cloudflare maschinelles Lernen zur Bot-Erkennung einsetzen, das auch getarnte Crawler erkennt.
Keine einzelne Methode bietet vollständigen Schutz, daher ist ein mehrschichtiger Ansatz am effektivsten. Beginnen Sie mit robots.txt und User-Agent-Filterung als Basisschutz, fügen Sie Rate-Limiting hinzu, um den Impact zu verringern, implementieren Sie Geräte-Fingerprinting, um ausgeklügelte Bots zu erkennen, und erwägen Sie Authentifizierung oder Paywalls für sensible Inhalte. Die effektivsten Organisationen kombinieren mehrere Techniken und überwachen kontinuierlich, welche Methoden wirken, um sich an die sich entwickelnden Umgehungstechniken der Crawler anzupassen.
Nein. Während große Unternehmen wie OpenAI und Anthropic angeben, robots.txt und CORS-Beschränkungen zu respektieren, haben Untersuchungen gezeigt, dass viele KI-Crawler diese Beschränkungen umgehen. Perplexity AI wurde dabei erwischt, User-Agents zu fälschen, um Sperren zu umgehen, und Forschungen zeigen, dass OpenAI- und Anthropic-Crawler trotz expliziter robots.txt-Verbote auf Inhalte zugegriffen haben. Diese Inkonsistenz macht technische Blockiermethoden und rechtliche Durchsetzung zunehmend notwendig.
AmICited.com bietet umfassende Überwachung, wie KI-Systeme Ihre Marke über GPTs, Perplexity, Google AI Overviews und andere KI-Plattformen hinweg referenzieren und darauf zugreifen. Es verfolgt, welche KI-Modelle Ihre Inhalte verwenden, wie häufig Ihre Marke in KI-generierten Antworten erscheint, und gibt Einblick in das breitere Ökosystem der KI-Systeme, die mit Ihren digitalen Eigenschaften interagieren. Diese Überwachung hilft Ihnen, den Umfang des KI-Zugriffs zu verstehen und fundierte Entscheidungen zu Ihrer Content-Schutzstrategie zu treffen.
Erhalten Sie vollständige Transparenz darüber, welche KI-Systeme Ihre Marke über GPTs, Perplexity, Google AI Overviews und andere Plattformen hinweg ansteuern. Verfolgen Sie plattformübergreifende KI-Zugriffsmuster und verstehen Sie, wie Ihre Inhalte für KI-Training und -Inference genutzt werden.
Erfahren Sie, wie Cross-Platform AI Publishing Inhalte über mehrere Kanäle hinweg für die KI-Entdeckung optimiert verteilt. Verstehen Sie PESO-Kanäle, Automatis...

Erfahren Sie, was KI-Sichtbarkeits-Attribution ist, wie sie sich von traditioneller SEO unterscheidet und warum die Überwachung des Markenauftritts in KI-generi...

Erfahren Sie, was AI-Visibility-APIs sind, wie sie funktionieren und wie Sie sie für Echtzeit-Markenmonitoring über ChatGPT, Perplexity, Gemini und andere KI-Pl...