KI-generiertes Bild
Erfahren Sie, was KI-generierte Bilder sind, wie sie mithilfe von Diffusionsmodellen und neuronalen Netzwerken erstellt werden, ihre Anwendungen im Marketing un...
11 Min. Lesezeit
Generative KI ist künstliche Intelligenz, die neue, originelle Inhalte wie Texte, Bilder, Videos, Code und Audio basierend auf Mustern aus Trainingsdaten erstellt. Sie nutzt Deep-Learning-Modelle wie Transformer und Diffusionsmodelle, um vielfältige Ausgaben als Reaktion auf Nutzeranfragen zu generieren.
Generative KI ist künstliche Intelligenz, die neue, originelle Inhalte wie Texte, Bilder, Videos, Code und Audio basierend auf Mustern aus Trainingsdaten erstellt. Sie nutzt Deep-Learning-Modelle wie Transformer und Diffusionsmodelle, um vielfältige Ausgaben als Reaktion auf Nutzeranfragen zu generieren.
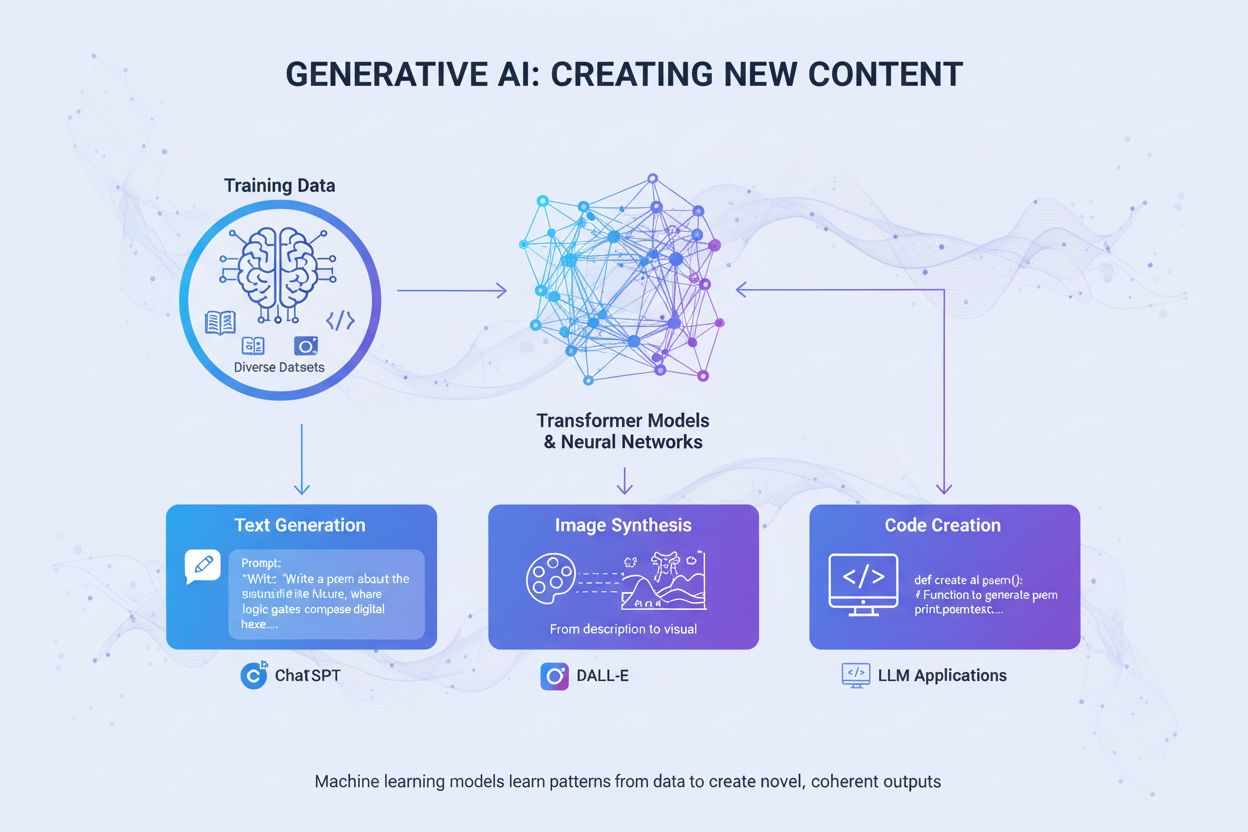
Generative KI ist eine Kategorie künstlicher Intelligenz, die neue, originelle Inhalte auf Basis von Mustern erstellt, die aus Trainingsdaten gelernt wurden. Im Gegensatz zu traditionellen KI-Systemen, die Informationen klassifizieren oder vorhersagen, erzeugen generative KI-Modelle eigenständig neue Ausgaben wie Texte, Bilder, Videos, Audio, Code und andere Datentypen als Antwort auf Benutzereingaben oder -anfragen. Diese Systeme nutzen fortschrittliche Deep-Learning-Modelle und neuronale Netze, um komplexe Muster und Beziehungen in riesigen Datensätzen zu erkennen und dieses erlernte Wissen zu verwenden, um Inhalte zu generieren, die den Trainingsdaten ähneln, aber dennoch neu sind. Der Begriff „generativ“ betont die Fähigkeit des Modells, etwas Neues zu schaffen, anstatt lediglich bestehende Informationen zu analysieren oder zu klassifizieren. Seit der öffentlichen Einführung von ChatGPT im November 2022 zählt generative KI zu den transformativsten Technologien der Informatik und verändert grundlegend, wie Organisationen Inhalte erstellen, Probleme lösen und Entscheidungen in nahezu jeder Branche treffen.
Die Grundlagen der generativen KI reichen mehrere Jahrzehnte zurück, doch die Technologie hat sich in den letzten Jahren dramatisch weiterentwickelt. Frühe statistische Modelle des 20. Jahrhunderts legten das Fundament für das Verständnis von Datenverteilungen, aber echte generative KI entstand erst mit Fortschritten im Deep Learning und bei neuronalen Netzen in den 2010er Jahren. Die Einführung von Variational Autoencoders (VAEs) im Jahr 2013 war ein bedeutender Durchbruch, da sie es ermöglichten, realistische Variationen von Daten wie Bildern und Sprache zu erzeugen. 2014 folgten Generative Adversarial Networks (GANs) und Diffusionsmodelle, die die Qualität und Realitätsnähe generierter Inhalte weiter verbesserten. Ein Wendepunkt war 2017 die Veröffentlichung von „Attention is All You Need“, in der die Transformer-Architektur vorgestellt wurde – ein Durchbruch, der die Verarbeitung und Generierung von Sequenzdaten durch generative KI-Modelle grundlegend veränderte. Diese Innovation ermöglichte die Entwicklung von Large Language Models (LLMs) wie OpenAIs GPT-Serie, die beispiellose Fähigkeiten im Verständnis und in der Generierung menschlicher Sprache zeigten. Laut McKinsey nutzten 2023 bereits ein Drittel der Unternehmen generative KI regelmäßig in mindestens einer Unternehmensfunktion, und Gartner prognostiziert, dass bis 2026 mehr als 80 % der Unternehmen generative KI-Anwendungen oder APIs eingesetzt haben werden. Die rasante Entwicklung von einer Forschungsneuheit zur unternehmerischen Notwendigkeit stellt einen der schnellsten Technologieadoptionszyklen der Geschichte dar.
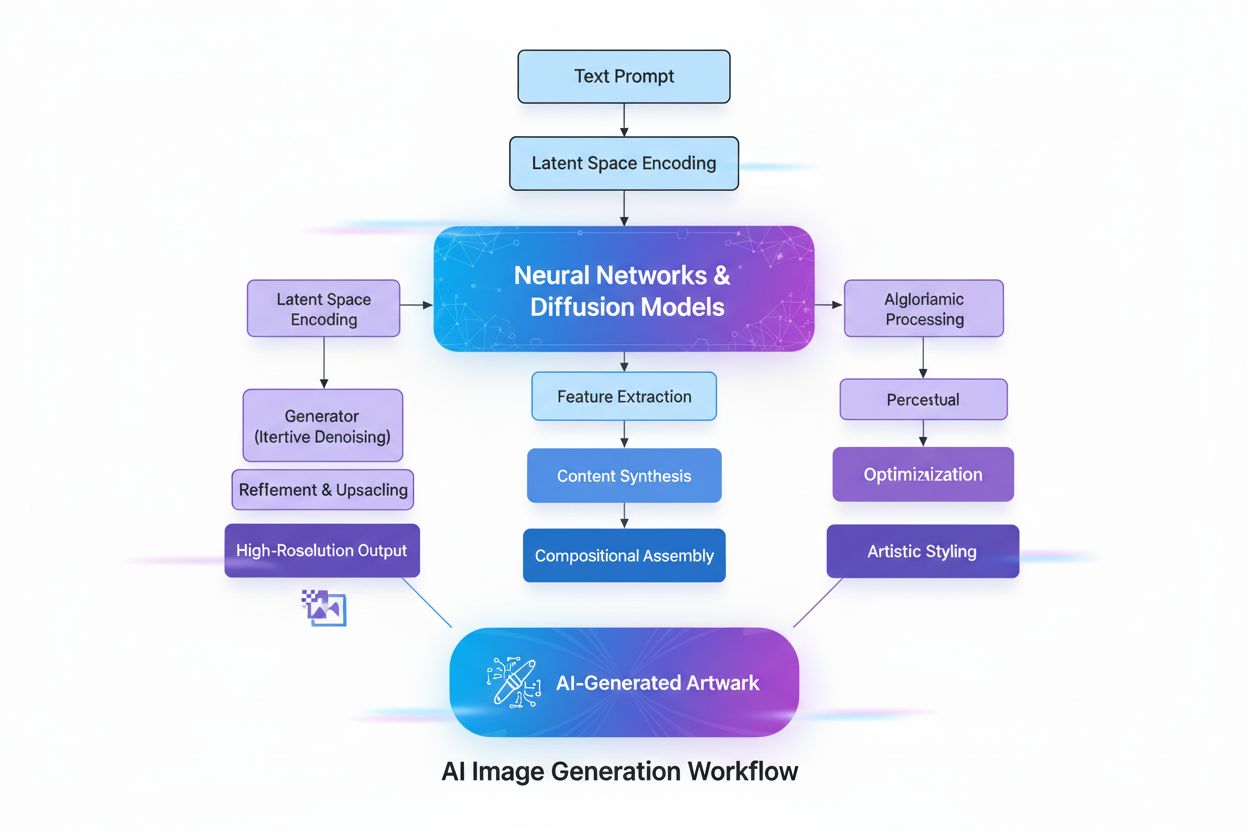
Generative KI arbeitet in einem mehrphasigen Prozess, der mit dem Training an riesigen Datensätzen beginnt, gefolgt von Tuning für spezifische Anwendungen und kontinuierlichen Zyklen von Generierung, Bewertung und Retuning. Während der Trainingsphase füttern Fachleute Deep-Learning-Algorithmen mit Terabytes an Rohdaten – etwa Internettexten, Bildern oder Code-Repositories – und der Algorithmus führt Millionen von „Lückentext“-Übungen durch, indem er das nächste Element in einer Sequenz vorhersagt und sich selbst zur Fehlerminimierung anpasst. So entsteht ein neuronales Netz aus Parametern, die die erkannten Muster, Entitäten und Beziehungen aus den Trainingsdaten kodieren. Das Ergebnis ist ein Foundation Model – ein großes, vortrainiertes Modell, das mehrere Aufgaben in unterschiedlichen Domänen ausführen kann. Foundation Models wie GPT-3, GPT-4 und Stable Diffusion bilden die Basis für zahlreiche spezialisierte Anwendungen. Das Tuning umfasst Feinabstimmung (Fine-Tuning) des Foundation Models mit beschrifteten Daten für eine bestimmte Aufgabe oder den Einsatz von Reinforcement Learning with Human Feedback (RLHF), bei dem menschliche Bewerter verschiedene Ausgaben bewerten, um das Modell auf mehr Genauigkeit und Relevanz zu trimmen. Entwickler und Anwender bewerten die Ausgaben kontinuierlich und stimmen die Modelle – manchmal wöchentlich – weiter ab, um die Leistung zu verbessern. Eine weitere Optimierungsmethode ist Retrieval Augmented Generation (RAG), bei der das Foundation Model Zugriff auf relevante externe Quellen erhält, damit das Modell immer aktuelle Informationen nutzen und dabei die Herkunft transparent machen kann.
| Modelltyp | Trainingsansatz | Generierungsgeschwindigkeit | Ausgabequalität | Diversität | Beste Anwendungsfälle |
|---|---|---|---|---|---|
| Diffusionsmodelle | Iteratives Entfernen von Rauschen aus Zufallsdaten | Langsam (mehrere Iterationen) | Sehr hoch (fotorealistisch) | Hoch | Bilderzeugung, High-Fidelity-Synthese |
| Generative Adversarial Networks (GANs) | Wettbewerb Generator vs. Diskriminator | Schnell | Hoch | Geringer | Domänenspezifische Generierung, Stiltransfer |
| Variational Autoencoders (VAEs) | Encoder-Decoder mit latenten Raum | Mittel | Mittel | Mittel | Datenkompression, Anomalieerkennung |
| Transformer-Modelle | Self-Attention auf sequenziellen Daten | Mittel bis schnell | Sehr hoch (Text/Code) | Sehr hoch | Sprachgenerierung, Code-Synthese, LLMs |
| Hybride Ansätze | Kombination mehrerer Architekturen | Variabel | Sehr hoch | Sehr hoch | Multimodale Generierung, komplexe Aufgaben |
Die Transformer-Architektur ist die einflussreichste Technologie für moderne generative KI. Transformer nutzen Self-Attention-Mechanismen, um zu bestimmen, welche Teile der Eingabedaten bei der Verarbeitung jedes Elements am wichtigsten sind. Dadurch kann das Modell langfristige Abhängigkeiten und Kontext erfassen. Positionskodierung bildet die Reihenfolge der Eingabeelemente ab, sodass Transformer die Sequenzstruktur ohne sequentielle Verarbeitung verstehen. Diese parallele Verarbeitungsfähigkeit beschleunigt das Training im Vergleich zu früheren rekurrenten neuronalen Netzen (RNNs) erheblich. Die Encoder-Decoder-Struktur des Transformers, kombiniert mit mehreren Schichten von Attention-Heads, ermöglicht es dem Modell, verschiedene Aspekte der Daten gleichzeitig zu berücksichtigen und kontextuelle Einbettungen auf jeder Ebene zu verfeinern. Diese Einbettungen erfassen alles von Grammatik und Syntax bis zu komplexen semantischen Bedeutungen. Large Language Models (LLMs) wie ChatGPT, Claude und Gemini basieren auf Transformer-Architekturen und enthalten Milliarden von Parametern – kodierte Repräsentationen gelernter Muster. Die Größe dieser Modelle, kombiniert mit Training an internetgroßen Datenmengen, ermöglicht vielseitige Aufgaben von Übersetzung und Zusammenfassung bis zu kreativem Schreiben und Codegenerierung. Diffusionsmodelle, eine weitere zentrale Architektur, fügen zunächst Rauschen zu Trainingsdaten hinzu, bis diese zufällig werden, und trainieren dann den Algorithmus darauf, dieses Rauschen iterativ zu entfernen, um die gewünschten Ausgaben zu erzeugen. Obwohl Diffusionsmodelle mehr Trainingszeit als VAEs oder GANs benötigen, bieten sie überlegene Kontrolle über die Ausgabequalität, insbesondere für hochwertige Bildgeneratoren wie DALL-E und Stable Diffusion.
Der Business Case für generative KI ist überzeugend: Unternehmen verzeichnen messbare Produktivitätsgewinne und Kostensenkungen. Laut OpenAIs Enterprise-AI-Report 2025 sparen Nutzer mit generativen KI-Anwendungen 40–60 Minuten pro Tag, was zu deutlichen Produktivitätssteigerungen in Organisationen führt. Der Markt für generative KI wurde 2024 auf 16,87 Milliarden USD geschätzt und soll bis 2030 auf 109,37 Milliarden USD wachsen – mit einer CAGR von 37,6 %, einer der höchsten Wachstumsraten in der Geschichte der Unternehmenssoftware. Die Unternehmensausgaben für generative KI erreichten 2025 37 Milliarden USD, gegenüber 11,5 Milliarden USD 2024, was einem 3,2-fachen Anstieg entspricht. Diese Entwicklung spiegelt das wachsende Vertrauen in die Rendite wider: KI-Käufer konvertieren mit 47 % im Vergleich zu den traditionellen 25 % bei SaaS, was zeigt, dass generative KI sofortigen Mehrwert liefert und daher schnell eingeführt wird. Unternehmen setzen generative KI in vielen Bereichen ein: Kundendienstteams nutzen KI-Chatbots für personalisierte Antworten und Erstkontaktlösungen; Marketingabteilungen setzen Content-Generierung für Blogs, E-Mails und Social Media ein; Softwareentwicklungsteams verwenden Codegenerierungstools, um Entwicklungszyklen zu beschleunigen; Forschungsteams analysieren komplexe Datensätze und schlagen neuartige Lösungen vor. Finanzdienstleister verwenden generative KI zur Betrugserkennung und für personalisierte Finanzberatung, während Gesundheitsorganisationen sie für Medikamentenentwicklung und medizinische Bildanalyse einsetzen. Die Vielseitigkeit der Technologie in verschiedenen Branchen zeigt ihr transformatives Potenzial für Geschäftsprozesse.
Die Anwendungen generativer KI erstrecken sich über nahezu jeden Sektor und jede Funktion. Bei der Textgenerierung erstellen Modelle kohärente, kontextbezogene Inhalte wie Dokumentationen, Marketingtexte, Blogartikel, wissenschaftliche Arbeiten und kreative Texte. Sie automatisieren lästige Schreibaufgaben wie Zusammenfassungen und Metadatenerstellung, sodass Autoren sich auf wertschöpfende kreative Arbeit konzentrieren können. Bilderzeugungstools wie DALL-E, Midjourney und Stable Diffusion erstellen fotorealistische Bilder, Originalkunstwerke und übernehmen Stiltransfer sowie Bildbearbeitung. Videogenerierung ermöglicht die Animationserstellung aus Textvorgaben und die Anwendung von Spezialeffekten schneller als auf herkömmlichem Wege. Audio- und Musikgenerierung synthetisiert natürlich klingende Sprache für Chatbots und digitale Assistenten, erstellt Hörbuch-Narrationen und generiert Musik, die professionellen Kompositionen ähnelt. Codegenerierung ermöglicht Entwicklern, Originalcode zu schreiben, Snippets zu vervollständigen, zwischen Programmiersprachen zu übersetzen und Anwendungen zu debuggen. Im Gesundheitswesen beschleunigt generative KI die Arzneimittelentwicklung, indem sie neue Proteinsequenzen und Molekülstrukturen mit gewünschten Eigenschaften generiert. Generierung synthetischer Daten schafft beschriftete Trainingsdaten für maschinelles Lernen, besonders wertvoll, wenn reale Daten eingeschränkt, nicht verfügbar oder für Randfälle unzureichend sind. In der Automobilindustrie erzeugt generative KI 3D-Simulationen für die Fahrzeugentwicklung und generiert synthetische Daten für das Training autonomer Fahrzeuge. Medien- und Unterhaltungsunternehmen setzen generative KI zur Erstellung von Animationen, Drehbüchern, Spielumgebungen und personalisierten Empfehlungen ein. Energieunternehmen verwenden generative Modelle für Netzmanagement, Optimierung der Betriebssicherheit und Energieprognosen. Die breite Anwendung zeigt, dass generative KI eine Basistechnologie ist, die die Art und Weise, wie Organisationen kreieren, analysieren und innovieren, grundlegend verändert.
Trotz beeindruckender Fähigkeiten bringt generative KI erhebliche Herausforderungen mit sich, die Unternehmen adressieren müssen. KI-Halluzinationen – plausibel klingende, aber inhaltlich falsche Ausgaben – entstehen, weil generative Modelle das nächste Element auf Basis von Mustern vorhersagen, ohne Fakten zu prüfen. Ein Anwalt nutzte ChatGPT für juristische Recherchen und erhielt komplett erfundene Fallzitate samt angeblicher Zitate und Quellen. Vorurteile und Fairness-Probleme treten auf, wenn Trainingsdaten gesellschaftliche Verzerrungen enthalten, was zu voreingenannten, unfairen oder beleidigenden Inhalten führen kann. Inkonsistente Ausgaben resultieren aus der probabilistischen Natur generativer Modelle, sodass identische Eingaben verschiedene Ausgaben erzeugen – problematisch etwa im Kundenservice. Fehlende Erklärbarkeit erschwert das Nachvollziehen, wie Modelle zu bestimmten Ergebnissen kommen; selbst Ingenieure können die Entscheidungsfindung dieser „Black Box“-Modelle oft nicht erklären. Sicherheits- und Datenschutzrisiken entstehen, wenn proprietäre Daten für das Training genutzt oder Inhalte generiert werden, die geistiges Eigentum offenlegen oder das IP anderer verletzen. Deepfakes – KI-generierte oder manipulierte Bilder, Videos oder Audios zur Täuschung – zählen zu den besorgniserregendsten Anwendungen, etwa im Voice-Phishing oder Finanzbetrug. Hohe Rechenkosten bleiben, da das Training großer Foundation Models tausende GPUs, Wochen an Rechenzeit und Millionen an Kosten erfordert. Unternehmen begegnen diesen Risiken mit Schutzmechanismen, die Modelle auf vertrauenswürdige Datenquellen beschränken, kontinuierlicher Bewertung und Feinabstimmung zur Minimierung von Halluzinationen, vielfältigen Trainingsdaten zur Reduzierung von Vorurteilen, Prompt Engineering zur Erzielung konsistenter Ausgaben und Sicherheitsprotokollen zum Schutz von Geschäftsgeheimnissen. Transparenz beim KI-Einsatz und menschliche Kontrolle bei kritischen Entscheidungen bleiben unverzichtbare Best Practices.
Da generative KI-Systeme für Millionen von Nutzern zu primären Informationsquellen werden, müssen Unternehmen verstehen, wie ihre Marken, Produkte und Inhalte in KI-generierten Antworten erscheinen. Monitoring der KI-Sichtbarkeit bedeutet, systematisch zu verfolgen, wie große generative KI-Plattformen wie ChatGPT, Perplexity, Google AI Overviews und Claude Marken, Produkte und Wettbewerber beschreiben. Dieses Monitoring ist entscheidend, da KI-Systeme oft Quellen zitieren und Informationen referenzieren, ohne traditionelle SEO-Metriken zu verwenden. Marken, die nicht in KI-Antworten erscheinen, verpassen Sichtbarkeits- und Einflusschancen im KI-gesteuerten Suchumfeld. Tools wie AmICited ermöglichen es Unternehmen, Markenerwähnungen zu verfolgen, die Zitiergenauigkeit zu überwachen, zu analysieren, welche Domains und URLs in KI-Antworten referenziert werden, und zu verstehen, wie KI-Systeme ihre Wettbewerbsposition darstellen. Diese Daten helfen, Inhalte für KI-Zitate zu optimieren, Fehlinformationen oder falsche Darstellungen zu erkennen und die Sichtbarkeit im neuen KI-Informationsökosystem zu sichern. Die Praxis des GEO (Generative Engine Optimization) konzentriert sich darauf, Inhalte gezielt für KI-Zitate und -Sichtbarkeit zu optimieren und ergänzt klassische SEO-Strategien. Organisationen, die ihre KI-Sichtbarkeit überwachen und optimieren, sichern sich Wettbewerbsvorteile im entstehenden KI-basierten Informationsmarkt.
Das Feld der generativen KI entwickelt sich rasant mit mehreren prägenden Trends. Multimodale KI-Systeme, die Text, Bilder, Video und Audio nahtlos integrieren, werden immer ausgefeilter und ermöglichen komplexere, nuanciertere Generierungen. Agentische KI – autonome KI-Systeme, die Aufgaben und Ziele ohne menschliches Eingreifen erledigen können – bildet die nächste Entwicklungsstufe, in der KI-Agenten generierte Inhalte nutzen, um mit Tools zu interagieren und Entscheidungen zu treffen. Kleinere, effizientere Modelle entstehen als Alternativen zu riesigen Foundation Models und erlauben den Einsatz generativer KI mit geringeren Kosten und schnelleren Antwortzeiten. Retrieval Augmented Generation (RAG) entwickelt sich weiter und erlaubt Modellen den Zugriff auf aktuelle Informationen und externes Wissen – ein wichtiger Schritt gegen Halluzinationen und zur Verbesserung der Genauigkeit. Regulatorische Rahmenwerke entstehen weltweit, mit Richtlinien für verantwortungsvolle KI-Entwicklung und -Einsatz. Unternehmensspezifische Anpassungen durch Fine-Tuning und domänenspezifische Modelle nehmen zu, da Unternehmen generative KI auf ihre Geschäftsprozesse zuschneiden. Ethische KI-Praktiken werden zum Wettbewerbsfaktor, mit Fokus auf Transparenz, Fairness und verantwortungsvolle Einführung. Die Konvergenz dieser Trends lässt erwarten, dass generative KI immer stärker in Unternehmensabläufe integriert, effizienter und für Unternehmen jeder Größe zugänglich sowie von klaren Governance- und Ethik-Standards begleitet wird. Organisationen, die generative KI verstehen, ihre KI-Sichtbarkeit überwachen und verantwortungsvoll implementieren, sind am besten positioniert, den Mehrwert dieser Technologie zu nutzen und Risiken zu managen.
Generative KI erstellt neue Inhalte, indem sie die Verteilung von Daten erlernt und neuartige Ausgaben generiert, während diskriminierende KI sich auf Klassifizierungs- und Vorhersageaufgaben konzentriert, indem sie Entscheidungsgrenzen zwischen Kategorien erlernt. Generative Modelle wie GPT-3 und DALL-E produzieren kreative Inhalte, wohingegen diskriminierende Modelle besser für Aufgaben wie Bilderkennung oder Spam-Erkennung geeignet sind. Beide Ansätze haben unterschiedliche Anwendungen, je nachdem, ob das Ziel Inhaltserstellung oder Datenklassifikation ist.
Transformer-Modelle nutzen Self-Attention-Mechanismen und Positionskodierung, um sequenzielle Daten wie Text zu verarbeiten, ohne eine sequentielle Verarbeitung zu benötigen. Diese Architektur ermöglicht es den Transformern, langfristige Abhängigkeiten zwischen Wörtern zu erfassen und den Kontext effektiver zu verstehen als frühere Modelle. Die Fähigkeit des Transformers, ganze Sequenzen gleichzeitig zu verarbeiten und komplexe Beziehungen zu erlernen, hat ihn zur Grundlage der meisten modernen generativen KI-Systeme gemacht, einschließlich ChatGPT und GPT-4.
Foundation Models sind groß angelegte Deep-Learning-Modelle, die auf riesigen Mengen unbeschrifteter Daten vortrainiert werden und mehrere Aufgaben in verschiedenen Domänen ausführen können. Beispiele sind GPT-3, GPT-4 und Stable Diffusion. Diese Modelle dienen als Basis für verschiedene Anwendungen der generativen KI und können für spezifische Anwendungsfälle feinjustiert werden, was sie im Vergleich zum Training von Grund auf sehr vielseitig und kosteneffizient macht.
Da generative KI-Systeme wie ChatGPT, Perplexity und Google AI Overviews zu primären Informationsquellen werden, müssen Marken überwachen, wie sie in KI-generierten Antworten erscheinen. Das Monitoring der KI-Sichtbarkeit hilft Unternehmen, die Markenwahrnehmung zu verstehen, eine korrekte Informationsdarstellung zu gewährleisten und die Wettbewerbsposition im KI-gesteuerten Suchumfeld zu sichern. Tools wie AmICited ermöglichen es Marken, Erwähnungen und Zitate auf mehreren KI-Plattformen zu verfolgen.
Generative KI-Systeme können sogenannte 'Halluzinationen' erzeugen – plausibel klingende, aber inhaltlich falsche Ausgaben – aufgrund ihres musterbasierten Lernansatzes. Diese Modelle können auch Vorurteile aus den Trainingsdaten übernehmen, inkonsistente Ausgaben für identische Eingaben generieren und mangelnde Transparenz in ihren Entscheidungsprozessen aufweisen. Die Bewältigung dieser Herausforderungen erfordert vielfältige Trainingsdaten, kontinuierliche Bewertung und die Implementierung von Schutzmechanismen, um die Modelle auf vertrauenswürdige Datenquellen zu beschränken.
Diffusionsmodelle generieren Inhalte, indem sie iterativ Rauschen aus Zufallsdaten entfernen, was qualitativ hochwertige Ausgaben, aber langsamere Generierungsgeschwindigkeit bietet. GANs verwenden zwei konkurrierende neuronale Netze (Generator und Diskriminator), um realistische Inhalte schnell zu erzeugen, jedoch mit geringerer Vielfalt. Diffusionsmodelle werden derzeit für hochqualitative Bildgenerierung bevorzugt, während GANs bei domänenspezifischen Anwendungen, bei denen es auf Geschwindigkeit und Qualität ankommt, effektiv bleiben.
Der Markt für generative KI wurde 2024 auf 16,87 Milliarden USD geschätzt und soll bis 2030 auf 109,37 Milliarden USD wachsen, mit einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von 37,6 % von 2025 bis 2030. Die Ausgaben der Unternehmen für generative KI erreichten 2025 37 Milliarden USD, was einem 3,2-fachen Anstieg gegenüber 11,5 Milliarden USD im Jahr 2024 entspricht und die rasche Einführung in verschiedenen Branchen zeigt.
Eine verantwortungsvolle Implementierung generativer KI beginnt mit internen Anwendungen, um Ergebnisse in kontrollierten Umgebungen zu testen, stellt Transparenz durch klare Kommunikation des KI-Einsatzes sicher, implementiert Sicherheitsmechanismen zum Schutz vor unbefugtem Datenzugriff und führt umfangreiche Tests in unterschiedlichen Szenarien durch. Organisationen sollten zudem klare Governance-Rahmen schaffen, die Ausgaben auf Vorurteile und Genauigkeit überwachen und bei kritischen Entscheidungen menschliche Aufsicht beibehalten.
Beginnen Sie zu verfolgen, wie KI-Chatbots Ihre Marke auf ChatGPT, Perplexity und anderen Plattformen erwähnen. Erhalten Sie umsetzbare Erkenntnisse zur Verbesserung Ihrer KI-Präsenz.
Erfahren Sie, was KI-generierte Bilder sind, wie sie mithilfe von Diffusionsmodellen und neuronalen Netzwerken erstellt werden, ihre Anwendungen im Marketing un...

Community-Diskussion, die generative Engines erklärt. Klare Erklärungen, wie sich ChatGPT, Perplexity und andere KI-Systeme von der traditionellen Google-Suche ...
Erfahren Sie, was generative Engines sind, wie sie sich von traditionellen Suchmaschinen unterscheiden und welchen Einfluss sie auf ChatGPT, Perplexity, Google ...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.