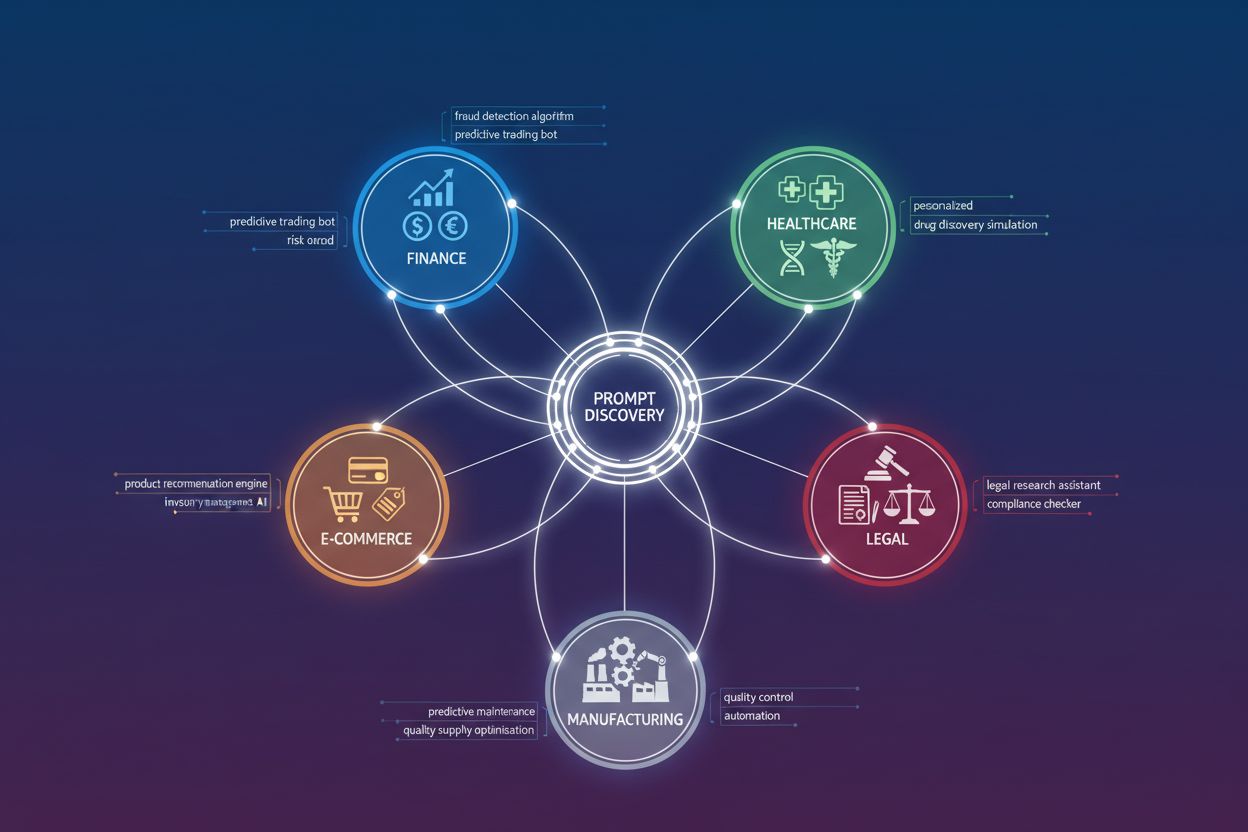
Hochwertige KI-Prompts in Ihrer Branche finden
Erfahren Sie systematische Methoden zur Entdeckung und Optimierung hochwertiger KI-Prompts für Ihre Branche. Praktische Techniken, Tools und reale Fallstudien f...
9 Min. Lesezeit
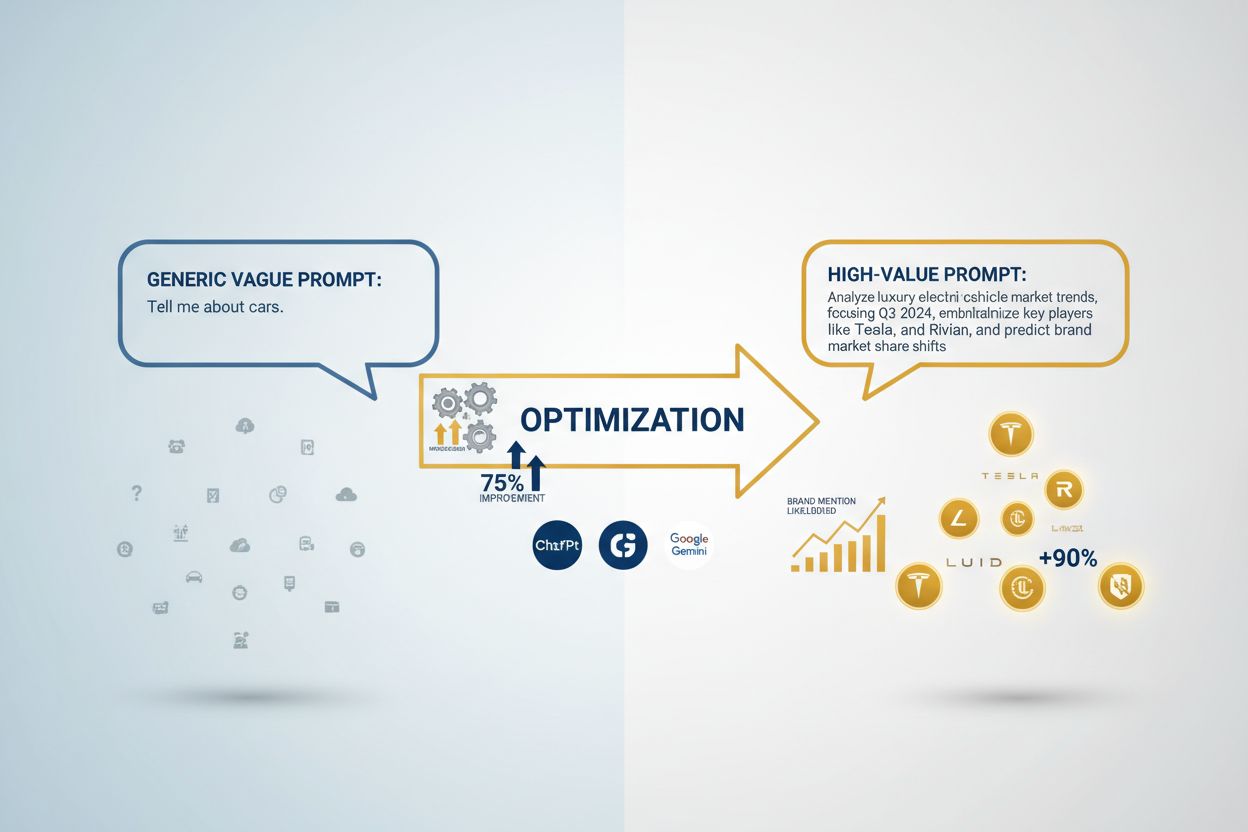
Spezifische Formulierungen von Anfragen, die strategisch darauf ausgelegt sind, relevante Markennennungen in KI-generierten Antworten auszulösen. Diese Prompts verbinden Spezifität, Kontext und eine klare Struktur, um die Wahrscheinlichkeit von Markenzitierungen in KI-Systemen wie ChatGPT, Perplexity und Google Gemini zu erhöhen.
Spezifische Formulierungen von Anfragen, die strategisch darauf ausgelegt sind, relevante Markennennungen in KI-generierten Antworten auszulösen. Diese Prompts verbinden Spezifität, Kontext und eine klare Struktur, um die Wahrscheinlichkeit von Markenzitierungen in KI-Systemen wie ChatGPT, Perplexity und Google Gemini zu erhöhen.
Hochwertige KI-Eingabeaufforderungen sind spezifische Anfrageformulierungen, die strategisch darauf ausgelegt sind, relevante Markennennungen in KI-generierten Antworten auszulösen. Im Gegensatz zu generischen Prompts, die breite und unscharfe Antworten liefern, sind hochwertige Prompts darauf ausgelegt, kontextuell passende Verweise auf bestimmte Marken, Produkte oder Dienstleistungen zu erhalten. Diese Prompts sind für die Markensichtbarkeit von großer Bedeutung, da sie bestimmen, ob Ihr Unternehmen in KI-Overviews, ChatGPT-Antworten, Perplexity-Antworten und anderen KI-generierten Inhalten erscheint, die täglich von Millionen Menschen genutzt werden. Der Unterschied zwischen einem generischen und einem hochwertigen Prompt kann den Unterschied zwischen Markenunsichtbarkeit und prominenter Platzierung in KI-Systemen bedeuten. Zu wissen, wie man hochwertige Prompts erkennt und einsetzt, ist für jede Marke, die im Zeitalter der KI-gestützten Suche und Content-Generierung sichtbar bleiben will, essenziell.
KI-Modelle verarbeiten Prompts über eine ausgefeilte, mehrstufige Pipeline, die mit der Tokenisierung beginnt – also dem Zerlegen Ihres Textes in einzelne Einheiten – gefolgt von Mustererkennung in Milliarden von Trainingsbeispielen und schließlich der Vorhersage und Generierung der wahrscheinlichsten Antwort. Die Struktur Ihres Prompts beeinflusst direkt, wie das Modell Ihre Intention interpretiert und welche Informationen es in seiner Antwort priorisiert. Ein gut strukturiertes Prompt mit klarem Kontext und spezifischen Anforderungen führt das Modell zu relevanteren Ergebnissen, während ein vages Prompt oft zu generischen Antworten führt, die wichtige Markenaspekte außer Acht lassen. Unterschiedliche KI-Plattformen gehen diesen Prozess mit verschiedenen Architekturen an: ChatGPT setzt auf transformerbasierte Attention-Mechanismen, Perplexity optimiert für suchähnliche Anfragen mit Echtzeit-Informationsabruf, und Google Gemini integriert multimodales Verständnis. Die zentrale Erkenntnis: Die Prompt-Struktur wirkt als Steuermechanismus – sie beeinflusst den Entscheidungsprozess des Modells in jedem Schritt der Generierung.
| Aspekt | Generisches Prompt | Hochwertiges Prompt |
|---|---|---|
| Spezifität | Breit, offen | Detailliert, zielgerichtet |
| Kontext | Minimale Hintergründe | Reichhaltige Kontextinformation |
| Erwartetes Ergebnis | Allgemeine Übersicht | Konkrete Empfehlungen |
| Wahrscheinlichkeit für Markennennung | Gering (5–15 %) | Hoch (60–85 %) |
Spezifität und Kontext sind die beiden Säulen der Prompt-Effektivität und bestimmen direkt, ob KI-Systeme Ihre Marke in ihren Antworten berücksichtigen. Wenn Sie spezifische Details zu Ihren Anforderungen angeben – Branche, Anwendungsfall, Budget, technische Anforderungen – hat das KI-Modell konkrete Anhaltspunkte, um mit seinen Trainingsdaten abzugleichen, was die Wahrscheinlichkeit für Markennennungen deutlich erhöht. Kontext verstärkt diesen Effekt, indem er den Rahmen liefert, in dem das Modell Informationen bewertet; ein Prompt, das erklärt, dass Sie B2B-SaaS-Käufer sind, führt zu völlig anderen Markenvorschlägen als eines für Endverbraucher. Hier einige Beispiele, wie Spezifität die Effektivität von Prompts verändert:
Diese Spezifität wirkt sich direkt auf die Markensichtbarkeit aus, denn KI-Modelle sind darauf trainiert, die Suchintention mit relevanten Entitäten zu verbinden; je präziser Sie Ihre Anforderungen definieren, desto sicherer kann das Modell Marken nennen, die diesen Kriterien entsprechen.
Chain-of-Thought Prompting regt KI-Modelle dazu an, ihre Überlegungen Schritt für Schritt darzulegen, was zu gründlicheren Markenevaluationen und Nennungen führt. Beispielsweise löst der Prompt „Erklären Sie Ihren Entscheidungsprozess für die Empfehlung einer Data-Warehouse-Lösung für ein Healthcare-Startup“ beim Modell explizit die Abwägung mehrerer Marken und die Begründung aus, warum welche (nicht) geeignet ist. Few-Shot Prompting gibt dem Modell Beispiele für das gewünschte Format und die erwartete Tiefe, was die Antwortqualität und Präzision der Markennennungen stark verbessert. Ein Prompt wie „Hier sind zwei Beispiele für detaillierte Tool-Vergleiche: [Beispiel 1] [Beispiel 2]. Vergleichen Sie nun diese drei Marketing-Automation-Plattformen …“ setzt klare Erwartungen an umfassende Markenabdeckung. Rollenbasiertes Prompting weist dem Modell eine bestimmte Perspektive zu, etwa „Als CTO, der Enterprise-Software bewertet, vergleichen Sie diese Datenbanklösungen …“, wodurch sich die Empfehlungen auf branchenspezifisches Markenwissen stützen. Diese Techniken sind für die Markensichtbarkeit relevant, weil sie vage KI-Antworten in strukturierte, fundierte Analysen verwandeln, bei denen Marken nach objektiven Kriterien bewertet und explizit genannt werden. Im Kern signalisieren Sie dem KI-Modell damit: „Ich möchte detaillierte, spezifische und gut begründete Antworten mit relevanten Markenempfehlungen.“
Um hochwertige Prompts zu erstellen, die Markennennungen fördern, muss man die Beziehung zwischen Prompt-Qualität und Zitierwahrscheinlichkeit – also der Chance, dass Ihre Marke in der KI-Antwort erwähnt wird – verstehen. Die effektivsten hochwertigen Prompts vereinen Spezifität (detaillierte Anforderungen), Kontext (Branche/Anwendungsfall) und Struktur (klare Formatvorgaben), sodass Markennennungen selbstverständlich und unausweichlich werden. Statt etwa „Was ist ein gutes E-Mail-Marketing-Tool?“ zu fragen, sollte ein hochwertiger Prompt lauten: „Ich bin ein B2B-SaaS-Unternehmen mit 10.000 Kunden. Ich suche eine E-Mail-Marketing-Plattform, die sich in Salesforce integriert, fortgeschrittene Segmentierung unterstützt und eine hohe Zustellrate bietet. Was sind meine besten Optionen und warum?“ Diese Struktur erhöht die Wahrscheinlichkeit, dass relevante Marken von KI-Systemen genannt werden, erheblich, da sie klare Bewertungskriterien vorgibt. AmICited überwacht genau solche hochwertigen Prompts in ChatGPT, Perplexity, Google AI Overviews und anderen Plattformen und verfolgt, welche Anfragen Ihre Markennennungen am häufigsten auslösen. Indem Sie verstehen, welche Prompts Zitierungen generieren, können Marken ihre Content-Strategie und SEO optimal darauf abstimmen, wie Nutzer tatsächlich mit KI-Systemen interagieren.
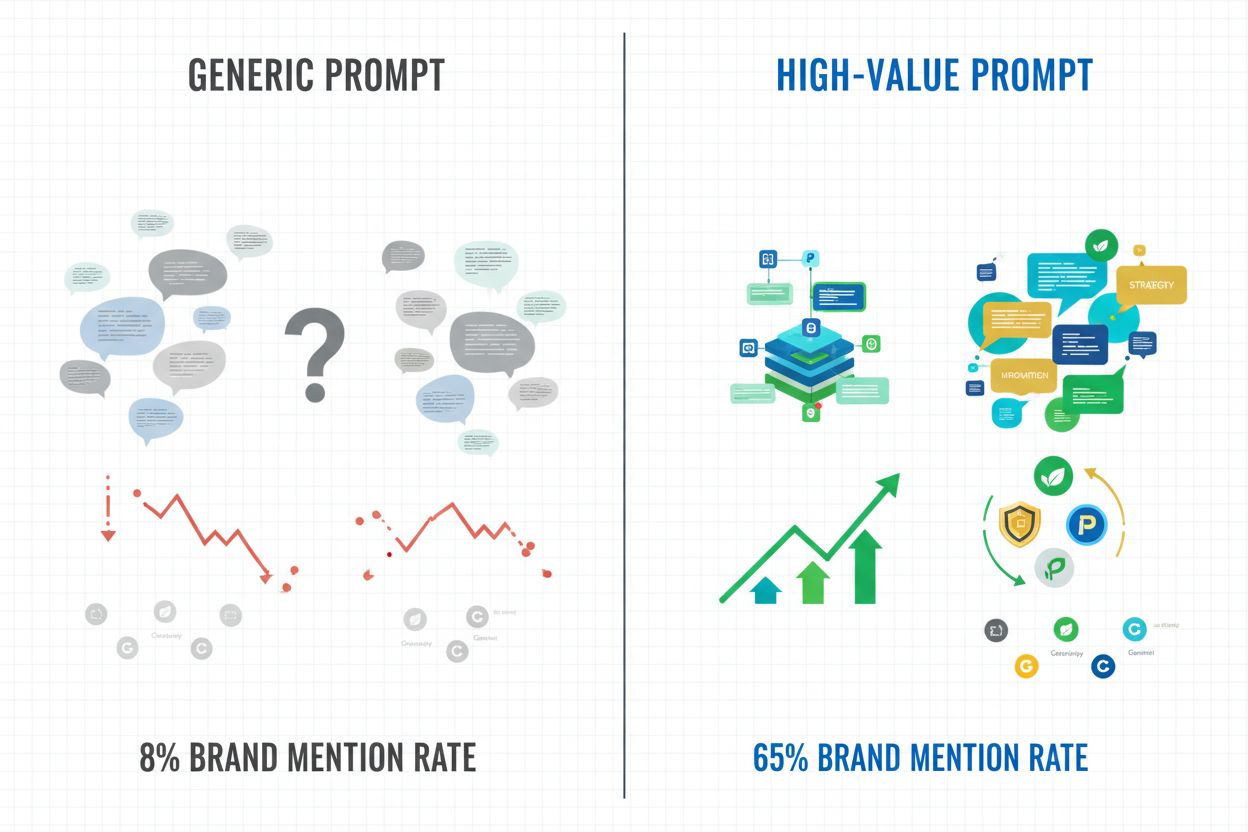
Unterschiedliche Branchen nutzen hochwertige Prompts auf jeweils eigene Weise, um die Markensichtbarkeit in KI-Antworten zu maximieren. Technologieunternehmen setzen Prompts wie „Vergleichen Sie Enterprise-SaaS-Lösungen für [spezifischen Anwendungsfall] mit diesen Anforderungen: [detaillierte Spezifikationen]“ ein, um sicherzustellen, dass ihre Produkte in KI-Empfehlungen erscheinen. Gesundheitsdienstleister formulieren Prompts um Behandlungsergebnisse und Compliance-Anforderungen, um relevante Zitierungen auszulösen. E-Commerce-Marken optimieren für Prompts, die Produktkategorien, Preisspannen und spezielle Features beinhalten, um die Wahrscheinlichkeit zu erhöhen, in KI-Shopping-Empfehlungen aufzutauchen. Finanzdienstleister fokussieren auf Prompts, die regulatorische Anforderungen, Anlageziele und Risikotoleranz spezifizieren, wodurch ihre Marken in KI-generierter Finanzberatung erscheinen. Studien zeigen: Hochwertige Prompts steigern die Wahrscheinlichkeit für Markennennungen im Vergleich zu generischen Anfragen um 400–600 %, in manchen Branchen steigt die Zitierquote von 8 % auf 45 %, wenn Prompts von vage zu spezifisch wechseln. Der praktische Effekt ist messbar: Marken, die hochwertige Prompts überwachen und optimieren, erhalten mehr Traffic aus KI-Overviews, höhere Interaktionen von Perplexity-Nutzern und mehr Sichtbarkeit in ChatGPT-Gesprächen. Deshalb ist Prompt-Monitoring heute essenzieller Bestandteil moderner Markenstrategien – zu wissen, welche Anfrageformulierungen Zitierungen auslösen, ermöglicht es, Content, Produktpositionierung und SEO optimal mit der tatsächlichen Funktionsweise von KI-Systemen abzustimmen.
Ein hochwertiger Prompt vereint drei Schlüsselelemente: Spezifität (detaillierte Anforderungen), Kontext (Branchen- oder Anwendungsfallinformationen) und klare Struktur (explizite Formatvorgaben). Diese Elemente führen KI-Modelle zu fokussierten, relevanten Antworten, die natürlicherweise Markennennungen enthalten. Zum Beispiel ist 'Was ist ein gutes CRM?' allgemein gehalten, während 'Was ist das beste CRM für ein B2B-SaaS-Unternehmen mit 50 Mitarbeitern und einem Budget von 5.000 $/Monat?' ein hochwertiger Prompt ist, da er spezifische Bewertungskriterien liefert.
Hochwertige Prompts erhöhen die Wahrscheinlichkeit für Markennennungen um 400–600 % im Vergleich zu generischen Anfragen. Wenn Prompts spezifische Anforderungen und Kontext enthalten, haben KI-Modelle konkrete Kriterien, mit denen sie ihre Trainingsdaten abgleichen können, wodurch relevante Marken viel häufiger genannt werden. Studien zeigen, dass Marken, die in hochwertigen Prompts genannt werden, Zitierquoten von 8 % auf 45 % oder mehr erreichen – mit direkter Auswirkung auf die Sichtbarkeit in KI-Overviews, ChatGPT-Gesprächen und Perplexity-Antworten.
Spezifität bedeutet, relevante Details zu liefern, die KI-Modellen helfen, Ihre Bedürfnisse zu verstehen (Budget, Branche, Anwendungsfall, technische Anforderungen). Eine Über-Spezifizierung fügt unnötige Einschränkungen hinzu, die die Fähigkeit des Modells, umfassende Empfehlungen zu geben, einschränken. Der optimale Bereich liegt bei 3–5 Hauptkriterien, die Ihre Bedürfnisse definieren, ohne das Prompt zu überladen. Zum Beispiel ist 'B2B SaaS, 50 Mitarbeiter, 5.000 $ Budget' spezifisch; 'muss vor 2015 gegründet sein, muss genau 47 Integrationen haben' ist über-spezifiziert.
Ja, hochwertige Prompts reduzieren Halluzinationen, indem sie KI-Modellen einen konkreten Kontext und klare Bewertungskriterien liefern. Wenn Modelle spezifische Anforderungen zur Bewertung haben, ist die Wahrscheinlichkeit geringer, dass sie Informationen erfinden oder unbegründete Aussagen machen. Zudem helfen hochwertige Prompts mit Anweisungen wie 'nennen Sie nur Lösungen, die diese spezifischen Kriterien erfüllen', das Modell auf faktenbasierte Vergleiche zu fokussieren, statt spekulative Inhalte zu erzeugen.
Testen Sie Ihre Prompts, indem Sie sie auf mehreren KI-Plattformen (ChatGPT, Perplexity, Google Gemini) ausführen und verfolgen, welche davon Markennennungen generieren. Nutzen Sie AmICited, um Zitiermuster zu überwachen und herauszufinden, welche Anfrageformulierungen Ihre Marke am häufigsten auslösen. Vergleichen Sie die Ergebnisse von generischen vs. spezifischen Versionen desselben Prompts, um den Effekt zu messen. Hochwertige Prompts sollten konsistent relevante Markennennungen auf verschiedenen KI-Systemen erzeugen.
Kontext ist entscheidend, da er den Rahmen schafft, in dem KI-Modelle Informationen bewerten. Ein Prompt über CRM-Tools für ein Healthcare-Startup liefert andere Markenvorschläge als einer für ein Einzelhandelsunternehmen, selbst wenn beide spezifisch sind. Kontext hilft KI-Modellen, Ihre Branche, Ihr Geschäftsmodell, regulatorische Anforderungen und Ihren Anwendungsfall zu verstehen, sodass sie die relevantesten Marken vorschlagen. Ohne Kontext könnten selbst spezifische Prompts wichtige Nuancen übersehen, die die Markeneignung beeinflussen.
AmICited verfolgt, welche Anfrageformulierungen Ihre Markennennungen auf ChatGPT, Perplexity, Google AI Overviews und anderen Plattformen auslösen. Durch die Analyse von Mustern in hochwertigen Prompts, die Ihre Marke nennen, können Sie verstehen, welche spezifischen Anforderungen, Branchen und Anwendungsfälle Zitierungen auslösen. Dieses Wissen hilft Ihnen, Ihre Content-Strategie, Produktpositionierung und SEO mit der tatsächlichen Nutzung von KI-Systemen abzustimmen und so Ihre Sichtbarkeit in KI-generierten Antworten zu erhöhen.
Während die Kernprinzipien Spezifität und Kontext für alle KI-Modelle gelten, reagieren verschiedene Plattformen unterschiedlich auf dasselbe Prompt. ChatGPT, Perplexity und Google Gemini verfügen über unterschiedliche Trainingsdaten, Architekturen und Optimierungsziele, weshalb ein hochwertiges Prompt für eine Plattform für eine andere angepasst werden muss. Die beste Herangehensweise ist, Ihre Prompts auf mehreren KI-Systemen zu testen und sie auf Basis der Ergebnisse, die die meisten relevanten Markennennungen für Ihre Ziele erzeugen, zu optimieren.
Verfolgen Sie, wie Ihre Marke in KI-generierten Antworten auf ChatGPT, Perplexity, Google AI Overviews und anderen Plattformen erscheint. Verstehen Sie, welche Prompts Ihre Zitierungen auslösen und optimieren Sie Ihre Sichtbarkeit.
Erfahren Sie systematische Methoden zur Entdeckung und Optimierung hochwertiger KI-Prompts für Ihre Branche. Praktische Techniken, Tools und reale Fallstudien f...

Erfahren Sie, wie die Formulierung, Klarheit und Spezifität von Prompts die Antwortqualität von KIs direkt beeinflussen. Lernen Sie Techniken des Prompt Enginee...
Erfahren Sie, was Prompt Engineering ist, wie es mit KI-Suchmaschinen wie ChatGPT und Perplexity funktioniert, und entdecken Sie wichtige Techniken, um Ihre KI-...