Definition von Wissensgraph
Ein Wissensgraph ist eine Datenbank aus miteinander verknüpften Informationen, die reale Entitäten – wie Personen, Orte, Organisationen und Konzepte – abbildet und ihre semantischen Beziehungen zueinander illustriert. Im Gegensatz zu traditionellen Datenbanken, die Informationen in starren, tabellarischen Formaten organisieren, strukturieren Wissensgraphen Daten als Netzwerke von Knoten (Entitäten) und Kanten (Beziehungen) und ermöglichen es Systemen, Bedeutung und Kontext zu erfassen, anstatt lediglich Schlüsselwörter abzugleichen. Googles Wissensgraph, der 2012 eingeführt wurde, revolutionierte die Suche durch ein entitätsbasiertes Verständnis. Dadurch konnte die Suchmaschine faktische Fragen wie „Wie hoch ist der Eiffelturm?“ oder „Wo fanden die Olympischen Sommerspiele 2016 statt?“ beantworten, indem sie verstand, wonach Nutzer tatsächlich suchten, und nicht nur, welche Wörter sie verwendeten. Im Mai 2024 enthielt Googles Wissensgraph über 1,6 Billionen Fakten zu 54 Milliarden Entitäten, was einen enormen Zuwachs gegenüber 500 Milliarden Fakten zu 5 Milliarden Entitäten im Jahr 2020 darstellt. Dieses Wachstum spiegelt die zunehmende Bedeutung von strukturiertem, semantischem Wissen für moderne Suche, KI-Systeme und intelligente Anwendungen in allen Branchen wider.
Kontext und historische Entwicklung
Das Konzept der Wissensgraphen entstand aus jahrzehntelanger Forschung in Künstlicher Intelligenz, Semantic-Web-Technologien und Wissensrepräsentation. Verbreite Bekanntheit erlangte der Begriff jedoch erst, als Google 2012 seinen Wissensgraphen einführte und damit grundlegend veränderte, wie Suchmaschinen Ergebnisse liefern. Vor dem Wissensgraphen arbeiteten Suchmaschinen hauptsächlich mit Schlüsselwortabgleich – wer nach „seal“ suchte, erhielt Ergebnisse zu allen möglichen Bedeutungen des Wortes, ohne dass verstanden wurde, welche Entität tatsächlich gemeint war. Der Wissensgraph veränderte dieses Paradigma, indem er Prinzipien der Ontologie – ein formaler Rahmen zur Definition von Entitäten, deren Attributen und Beziehungen – im großen Maßstab anwendete. Dieser Wandel von „Strings zu Things“ stellte einen grundlegenden Fortschritt der Suchtechnologie dar, denn Algorithmen konnten nun verstehen, dass „seal“ sich auf ein Meeressäugetier, einen Musiker, eine Militäreinheit oder ein Sicherheitsgerät beziehen kann, und anhand des Kontexts entscheiden, welche Bedeutung am relevantesten ist. Die globale Wissensgraph-Markt spiegelt diese Bedeutung wider: Prognosen zeigen ein Wachstum von 1,49 Milliarden US-Dollar im Jahr 2024 auf 6,94 Milliarden US-Dollar bis 2030, was einer durchschnittlichen jährlichen Wachstumsrate von etwa 35 % entspricht. Dieses explosive Wachstum wird durch die Einführung in Unternehmen aus Bereichen wie Finanzen, Gesundheitswesen, Einzelhandel und Lieferkettenmanagement vorangetrieben, da Organisationen zunehmend erkennen, dass das Verständnis von Entitätenbeziehungen entscheidend für Entscheidungsfindung, Betrugserkennung und operative Effizienz ist.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Wie Wissensgraphen funktionieren: Technische Architektur
Wissensgraphen arbeiten mit einer ausgefeilten Kombination aus Datenstrukturen, semantischen Technologien und maschinellen Lernalgorithmen. Im Kern verwenden Wissensgraphen ein graphbasiertes Datenmodell mit drei Grundbausteinen: Knoten (repräsentieren Entitäten wie Personen, Organisationen oder Konzepte), Kanten (repräsentieren Beziehungen zwischen Entitäten) und Labels (beschreiben die Art der Beziehung). In einem einfachen Wissensgraphen könnte „Seal“ ein Knoten sein, „ist-ein“ als Kanten-Label und „Musiker“ ein weiterer Knoten, was die semantische Beziehung „Seal ist ein Musiker“ ergibt. Diese Struktur unterscheidet sich grundlegend von relationalen Datenbanken, die Daten in Zeilen und Spalten mit festen Schemata pressen. Wissensgraphen werden entweder als Labeled Property Graphs (Eigenschaften werden direkt an Knoten und Kanten gespeichert) oder als RDF (Resource Description Framework) Triple Stores (alle Informationen als Subjekt-Prädikat-Objekt-Tripel) umgesetzt. Die Stärke von Wissensgraphen liegt in ihrer Fähigkeit, Daten aus verschiedenen Quellen und Strukturen zusammenzuführen. Beim Einlesen der Daten sorgen semantische Anreicherungsprozesse mithilfe von NLP und maschinellem Lernen dafür, Entitäten zu erkennen, Beziehungen zu extrahieren und den Kontext zu verstehen. So erkennt ein Wissensgraph automatisch, dass „IBM“, „International Business Machines“ und „Big Blue“ dieselbe Entität meinen, und wie diese mit anderen wie „Watson“, „Cloud Computing“ und „Künstliche Intelligenz“ verbunden ist. Das daraus entstehende Netzwerk ermöglicht anspruchsvolle Abfragen und Schlussfolgerungen, die in traditionellen Datenbanken nicht möglich wären: Systeme können komplexe Fragen beantworten, indem sie Beziehungen verfolgen und neues Wissen aus bestehenden Verknüpfungen ableiten.
Wissensgraph vs. traditionelle Datenbanken: Vergleichstabelle
| Aspekt | Wissensgraph | Traditionelle relationale Datenbank | Graphdatenbank |
|---|
| Datenstruktur | Knoten, Kanten und Labels für Entitäten und Beziehungen | Tabellen, Zeilen, Spalten mit festen Schemata | Knoten und Kanten, optimiert für Beziehungspflege |
| Schema-Flexibilität | Sehr flexibel; entwickelt sich mit neuen Erkenntnissen weiter | Starr; erfordert Schemadefinition vor Dateneingabe | Flexibel; unterstützt dynamische Schemata |
| Beziehungsmanagement | Native Unterstützung komplexer, mehrstufiger Beziehungen | Benötigt Joins über mehrere Tabellen; rechenintensiv | Für effiziente Beziehungsabfragen optimiert |
| Abfragesprache | SPARQL (für RDF), Cypher (für Property Graphs), eigene APIs | SQL | Cypher, Gremlin oder SPARQL |
| Semantisches Verständnis | Bedeutungs- und kontextorientiert durch Ontologien | Fokus auf Datenspeicherung und -abfrage | Fokus auf effiziente Navigation und Mustererkennung |
| Anwendungsfälle | Semantische Suche, Wissensentdeckung, KI-Systeme, Entitätenabgleich | Geschäftstransaktionen, Reporting, OLTP-Systeme | Empfehlungssysteme, Betrugserkennung, Netzwerk-Analyse |
| Datenintegration | Überlegen bei heterogenen Datenquellen | Erfordert aufwändige ETL- und Transformation | Gut für vernetzte Daten, weniger semantischer Fokus |
| Skalierbarkeit | Skaliert auf Milliarden Entitäten und Billionen Fakten | Skaliert gut für strukturierte, transaktionale Daten | Skaliert gut für beziehungsreiche Abfragen |
| Schlussfolgerungen | Fortschrittliche Inferenz durch Ontologien | Eingeschränkt; benötigt explizite Programmierung | Eingeschränkt; Fokus auf Mustererkennung |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Die Rolle von Wissensgraphen in SEO und KI-Sichtbarkeit
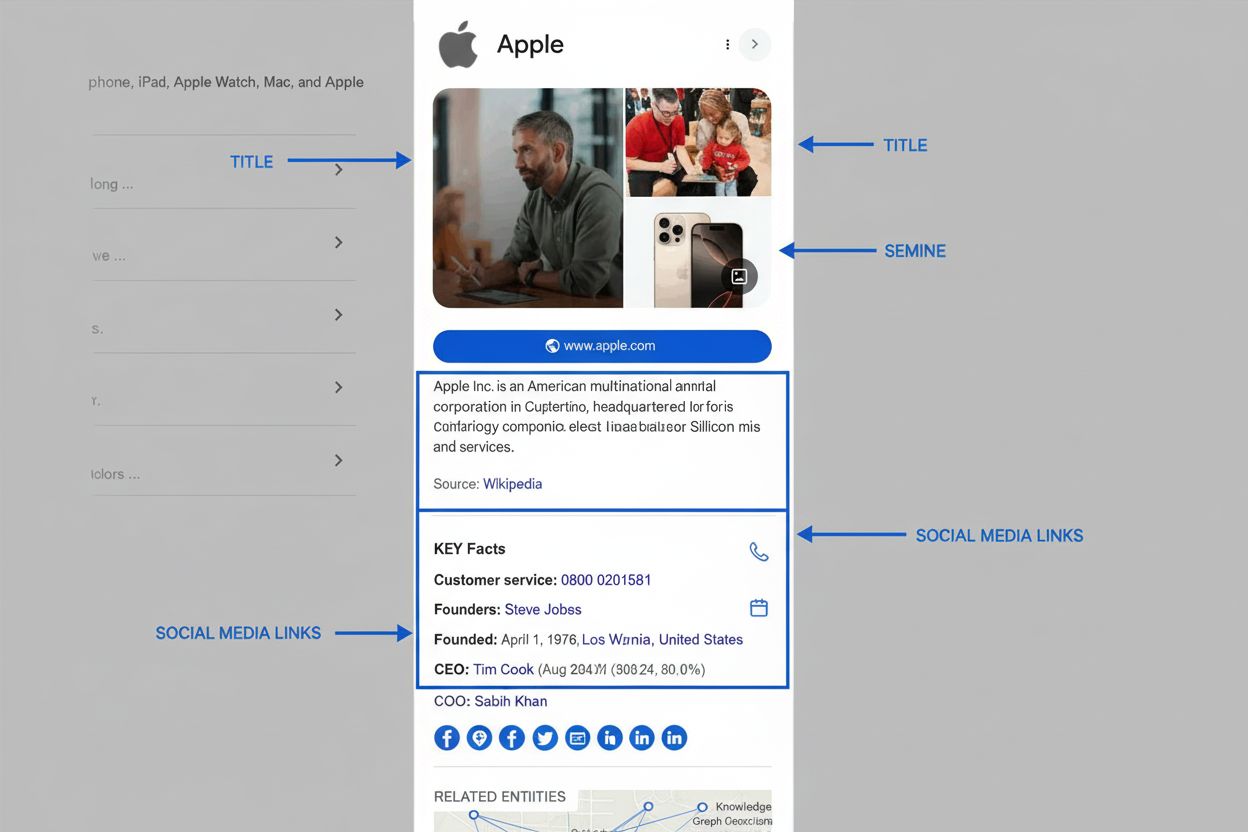
Wissensgraphen sind heute ein zentrales Element moderner SEO- und KI-Visibility-Strategien, da sie maßgeblich bestimmen, wie Informationen in Suchergebnissen und KI-generierten Antworten erscheinen. Wenn Google eine Suchanfrage verarbeitet, ist eine der Hauptaufgaben die Identifikation der gesuchten Entität, um anschließend relevante Informationen aus dem Wissensgraphen für SERP-Features bereitzustellen. Dieser entitätsbasierte Ansatz hat zur semantischen Suche geführt – Googles Fähigkeit, Bedeutung und Kontext von Anfragen zu verstehen, anstatt nur Schlüsselwörter abzugleichen. Der Wissensgraph treibt mehrere prominente SERP-Features an, die direkte Auswirkungen auf Klickrate und Markenpräsenz haben. Knowledge Panels werden auf Desktop und Mobilgeräten prominent angezeigt und zeigen kuratierte Fakten zur gesuchten Entität aus dem Wissensgraphen. AI Overviews (ehemals Search Generative Experience) fassen Informationen aus mehreren Quellen zusammen, die durch Wissensgraph-Beziehungen identifiziert wurden, und liefern umfassende Antworten, die klassische organische Treffer oft nach unten verschieben. People Also Ask-Boxen nutzen Entitätenbeziehungen, um verwandte Suchen und Themen vorzuschlagen. Das Verständnis dieser Features ist entscheidend für Marken, da sie eine erstklassige Platzierung in den Suchergebnissen darstellen und häufig noch vor den klassischen Treffern erscheinen. Für Unternehmen, die ihre Präsenz in KI-Systemen wie Perplexity, ChatGPT, Claude und Google AI Overviews überwachen, ist die Optimierung für den Wissensgraphen essenziell. Diese KI-Systeme verlassen sich zunehmend auf strukturierte Entitätsinformationen und semantische Beziehungen, um präzise, kontextuelle Antworten zu generieren. Eine Marke, die ihre Entitätenpräsenz im Wissensgraphen optimiert hat – durch strukturierte Daten, beanspruchte Knowledge Panels und konsistente Informationen über alle Quellen –, hat eine höhere Wahrscheinlichkeit, in KI-generierten Antworten zu relevanten Themen zu erscheinen. Umgekehrt können Marken mit unvollständigen oder inkonsistenten Entitätsinformationen übersehen oder falsch dargestellt werden, was sich direkt auf Sichtbarkeit und Reputation auswirkt.
Datenquellen und Aufbau von Wissensgraphen
Googles Wissensgraph bezieht seine Daten aus einem vielfältigen Ökosystem von Quellen, die jeweils unterschiedliche Informationen liefern und verschiedene Zwecke erfüllen. Offene Daten und Community-Projekte wie Wikipedia und Wikidata bilden die Basis vieler Inhalte im Wissensgraphen. Wikipedia liefert narrative Beschreibungen und Zusammenfassungen, die oft in Knowledge Panels erscheinen; Wikidata – eine strukturierte Wissensdatenbank, die Wikipedia unterstützt – stellt maschinenlesbare Entitätsdaten und Beziehungen bereit. Google verwendete früher Freebase, eine Community-edited Datenbank, wechselte aber nach deren Einstellung 2016 zu Wikidata. Behördliche Datenquellen liefern autoritative Informationen, insbesondere für faktische Anfragen. Das CIA World Factbook stellt Informationen zu Ländern, Regionen und Organisationen bereit. Data Commons, Googles Projekt für strukturierte öffentliche Daten, aggregiert Daten von Regierungs- und Multi-Regierungs-Organisationen wie den Vereinten Nationen und der EU und stellt Statistiken und demographische Daten bereit. Wetter- und Luftqualitätsdaten stammen von nationalen und internationalen Wetterdiensten und ermöglichen Googles „Nowcast“-Wetterfunktionen. Lizenzierte private Daten ergänzen den Wissensgraphen mit Informationen, die sich häufig ändern oder spezielles Fachwissen erfordern. Google lizenziert Finanzmarktdaten von Anbietern wie Morningstar, S&P Global und Intercontinental Exchange für Aktien- und Marktdaten. Sportdaten kommen aus Partnerschaften mit Ligen, Teams und Aggregatoren wie Stats Perform und bieten Echtzeit-Ergebnisse und Statistiken. Strukturierte Daten von Websites tragen wesentlich zur Anreicherung des Wissensgraphen bei. Wenn Websites Schema.org-Markup verwenden, stellen sie explizite semantische Informationen bereit, die Google extrahieren und integrieren kann. Daher ist die Implementierung von strukturierten Daten – etwa Organization-, LocalBusiness-, oder FAQPage-Schema – für Unternehmen, die ihr Wissensgraphen-Erscheinungsbild beeinflussen wollen, entscheidend. Google Books-Daten aus über 40 Millionen digitalisierten Büchern liefern historischen Kontext, biografische Informationen und detaillierte Beschreibungen zur Erweiterung des Entitätenwissens. Nutzerfeedback und beanspruchte Knowledge Panels ermöglichen es Einzelpersonen und Organisationen, den Informationsgehalt des Wissensgraphen direkt zu beeinflussen. Wer Rückmeldungen zu Knowledge Panels gibt oder als autorisierter Vertreter Panels beansprucht und aktualisiert, kann Änderungen anstoßen. Dieser Human-in-the-Loop-Ansatz sorgt für Genauigkeit und Repräsentativität, wobei Googles automatische Systeme letztlich entscheiden, was angezeigt wird.
Wissensgraphen und E-E-A-T: Autorität und Vertrauen aufbauen
Google hat explizit betont, dass Informationen aus Quellen mit hoher E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) beim Aufbau und der Aktualisierung des Wissensgraphen bevorzugt werden. Die Verbindung zwischen E-E-A-T und Aufnahme in den Wissensgraphen ist kein Zufall, sondern Ausdruck des Ziels, vertrauenswürdige und autoritative Inhalte zu priorisieren. Erscheint der Inhalt Ihrer Website in SERP-Features, die vom Wissensgraphen gesteuert werden, ist das oft ein starkes Signal dafür, dass Google Ihre Seite als maßgeblich für das Thema erkennt. Umgekehrt kann das Ausbleiben in Wissensgraph-gesteuerten Features auf E-E-A-T-Probleme hindeuten. E-E-A-T für Sichtbarkeit im Wissensgraphen aufzubauen, erfordert eine vielseitige Strategie. Experience bedeutet, dass Sie oder Ihre Autoren nachweislich praktische Erfahrung mit dem Thema haben. Im Gesundheitsbereich etwa sollten lizenzierte Mediziner mit klinischer Erfahrung Inhalte beisteuern; in der Technologiebranche sollten die Entwickler oder Forscher vorgestellt werden, die die Produkte gebaut haben. Expertise erfordert tiefgehende, fachkundige Inhalte, die Themen umfassend und präzise behandeln – über oberflächliche Erklärungen hinaus und mit Verständnis für Details und Spezialfälle. Authoritativeness verlangt Anerkennung in Ihrer Branche, etwa durch Auszeichnungen, Zertifikate, Medienberichte, Vorträge oder Zitate durch andere Autoritäten. Für Organisationen bedeutet das, die eigene Marke als Branchenführer zu etablieren. Trustworthiness baut auf den anderen drei Elementen auf und zeigt sich in Transparenz, Genauigkeit, korrekter Quellenangabe, klarer Urheberschaft und gutem Kundenservice. Organisationen, die E-E-A-T-Signale liefern, werden eher im Wissensgraphen aufgenommen und in KI-Antworten genannt – ein Kreislauf, in dem Autorität zu Sichtbarkeit führt und diese wiederum die Autorität stärkt.
Wissensgraphen in KI-Systemen und generativer Suche
Mit dem Aufkommen großer Sprachmodelle (LLMs) und generativer KI erhalten Wissensgraphen eine neue Bedeutung im KI-Ökosystem. Auch wenn LLMs wie ChatGPT, Claude und Perplexity nicht direkt auf Googles proprietärem Wissensgraphen trainiert werden, stützen sie sich immer häufiger auf ähnlich strukturierte Wissensquellen und semantisches Verständnis. Viele KI-Systeme setzen Retrieval-Augmented Generation (RAG) ein, wobei das Modell zur Antwortgenerierung Wissensgraphen oder strukturierte Datenbanken abfragt, um Fakten zu verankern und Halluzinationen zu reduzieren. Öffentlich verfügbare Wissensgraphen wie Wikidata werden genutzt, um Modelle zu feintunen oder strukturierte Wissenselemente einzubringen, wodurch diese Entitätenbeziehungen besser verstehen und akkuratere Informationen liefern können. Für Marken und Organisationen bedeutet das, dass Wissensgraph-Optimierung über die klassische Google-Suche hinausgeht. Wenn Nutzer KI-Systeme zu Ihrer Branche, Ihren Produkten oder Ihrem Unternehmen befragen, hängt die Genauigkeit der Antwort auch davon ab, wie gut Ihre Entität in strukturierten Wissensquellen präsent ist. Wer einen gepflegten Wikidata-Eintrag, ein beanspruchtes Google Knowledge Panel und konsistente strukturierte Daten auf der Website hat, wird wahrscheinlicher korrekt von KI-Systemen repräsentiert. Organisationen mit unvollständigen oder widersprüchlichen Angaben laufen hingegen Gefahr, fehlerhaft oder gar nicht in KI-Antworten aufzutauchen. Das eröffnet eine neue Dimension des KI-Visibility-Monitorings – es geht nicht mehr nur um das Ranking in klassischen Suchergebnissen, sondern auch um das Markenbild in KI-generierten Antworten auf verschiedenen Plattformen. Tools und Plattformen zur Überwachung der Markenpräsenz in KI-Systemen fokussieren zunehmend auf Entitätenbeziehungen und Wissensgraph-Repräsentation, da diese Faktoren die KI-Sichtbarkeit direkt beeinflussen.
Praktische Umsetzung: Optimierung für Wissensgraphen
Organisationen, die ihre Präsenz in Wissensgraphen optimieren möchten, sollten systematisch vorgehen und SEO-Grundlagen mit entitätsspezifischen Strategien kombinieren. Schritt eins ist die Implementierung von strukturiertem Daten-Markup mit Schema.org-Vokabular. Das bedeutet, der Website JSON-LD-, Microdata- oder RDFa-Markup hinzuzufügen, das Organisation, Produkte, Personen und andere relevante Entitäten explizit beschreibt. Zentrale Schema-Typen sind Organization (Firmeninformationen), LocalBusiness (standortbezogene Infos), Person (Personenprofile), Product (Produktinfos) und FAQPage (häufig gestellte Fragen). Nach der Implementierung ist es wichtig, das Markup mit Googles Structured Data Testing Tool zu testen und zu validieren. Schritt zwei ist die Überprüfung und Optimierung von Wikidata- und Wikipedia-Informationen. Falls Ihr Unternehmen oder Ihre Schlüsselpersonen Wikipedia-Seiten haben, sollten diese korrekt, umfassend und gut belegt sein. Bei Wikidata gilt es, die Existenz und die korrekte Darstellung von Eigenschaften und Beziehungen zu prüfen. Allerdings erfordert das Bearbeiten von Wikipedia oder Wikidata genaue Beachtung der Richtlinien und Community-Normen – Eigenwerbung oder nicht deklarierte Interessenkonflikte führen zu Reverts und können dem Ruf schaden. Schritt drei ist das Beanspruchen und Optimieren Ihres Google-Unternehmensprofils (bei lokalen Unternehmen) und der Knowledge Panels (für Personen und Organisationen). Ein beanspruchtes Panel gibt Ihnen mehr Kontrolle über die Darstellung Ihrer Entität und ermöglicht schnellere Änderungsvorschläge. Schritt vier ist die Konsistenz über alle Kanäle hinweg – Website, Google-Unternehmensprofil, Social Media und Branchenverzeichnisse sollten identische Angaben machen. Widersprüchliche Informationen verwirren Googles Systeme und behindern eine korrekte Wissensgraph-Darstellung. Schritt fünf ist die Erstellung von entitätsbasierten Inhalten statt klassisch keywordfokussierten Artikeln. Statt einzelne Artikel zu „bestes CRM“, „Salesforce Funktionen“ und „HubSpot Preise“ zu schreiben, sollten Sie einen umfassenden Content-Cluster mit klaren Entitätenbeziehungen aufbauen: Salesforce ist eine CRM-Plattform, Wettbewerber von HubSpot, integriert mit Slack usw. Dieser Ansatz hilft Wissensgraphen, die semantische Bedeutung und Beziehungen Ihrer Inhalte zu verstehen.
Zentrale Aspekte der Wissensgraph-Optimierung und Umsetzung
- Implementierung strukturierter Daten: Fügen Sie Schema.org-Markup auf allen relevanten Seiten ein, inklusive Organization-, LocalBusiness-, Product-, Person- und FAQPage-Schemas, und validieren Sie es mit Googles Testing-Tools
- Entitätenkonsistenz: Pflegen Sie identische Unternehmensdaten (Name, Adresse, Telefon, Beschreibung) auf Ihrer Website, im Google-Unternehmensprofil, in sozialen Medien und in Branchenverzeichnissen, um widersprüchliche Signale zu vermeiden
- Knowledge Panel beanspruchen: Beanspruchen Sie Ihr Knowledge Panel, um direkten Einfluss auf Entitäteninformationen zu haben und Änderungsvorschläge schneller einzureichen
- Wikidata-Optimierung: Stellen Sie sicher, dass Ihr Unternehmen oder Ihre Schlüsselfiguren korrekte, umfassende Wikidata-Einträge mit passenden Eigenschaften und Beziehungen haben und halten Sie sich an Community-Richtlinien
- E-E-A-T-Signale: Bauen Sie Autorität durch Experteninhalte, Autorenprofile, Branchenanerkennung, Auszeichnungen, Medienberichte und transparente Quellen auf, um die Aufnahme in den Wissensgraphen zu fördern
- Entitätsbasierte Content-Strategie: Organisieren Sie Inhalte um Entitäten und deren Beziehungen, nicht um Keywords, und schaffen Sie umfassende Content-Cluster mit semantischen Verbindungen
- Social-Media-Profile: Erstellen und optimieren Sie Profile auf von Google anerkannten Plattformen (Facebook, Instagram, LinkedIn, YouTube, TikTok, X, Pinterest, Snapchat) und verknüpfen Sie diese mit dem „sameAs“-Schema
- Externe Unternehmensprofile: Pflegen Sie Profile auf maßgeblichen Verzeichnissen wie Crunchbase, Forbes und Fortune, die von Google für den Wissensgraphen genutzt werden
- Überwachung der Datenkonsistenz: Prüfen Sie regelmäßig Ihre Entitäteninformationen auf allen Quellen und korrigieren Sie veraltete oder fehlerhafte Angaben, ggf. auch durch Kontakt zu Drittanbietern
- Feedback einreichen: Nutzen Sie die Feedback-Mechanismen in Knowledge Panels und Suchergebnissen, um Fehler zu melden und Verbesserungen an Wissensgraph-Informationen vorzuschlagen
- KI-Sichtbarkeit überwachen: Verfolgen Sie, wie Ihre Marke in KI-generierten Antworten auf Perplexity, ChatGPT, Claude und Google AI Overviews erscheint, um Ihre Entitätenrepräsentation in KI-Systemen zu verstehen
Die Zukunft der Wissensgraphen: Entwicklung und strategische Bedeutung
Wissensgraphen entwickeln sich rasant weiter – durch Fortschritte in Künstlicher Intelligenz, verändertes Suchverhalten und neue Plattformen und Technologien. Ein wichtiger Trend ist die Ausweitung auf multimodale Wissensgraphen, die Text, Bilder, Audio und Video integrieren. Mit dem Aufstieg von Sprach- und visueller Suche passen sich Wissensgraphen an, um Informationen über verschiedene Modalitäten hinweg zu verstehen und zu repräsentieren. Googles Arbeit an multimodaler Suche mit Produkten wie Google Lens zeigt diese Entwicklung: Das System muss nicht nur Text, sondern auch visuelle Eingaben verstehen, wofür Wissensgraphen nötig sind, die Informationen medienübergreifend verbinden. Ein weiterer Fortschritt ist die zunehmende semantische Anreicherung und Verbesserung der Verarbeitung natürlicher Sprache beim Aufbau von Wissensgraphen. Mit besseren NLP-Technologien lassen sich immer mehr semantische Beziehungen aus unstrukturiertem Text extrahieren, sodass weniger manuell gepflegte oder eindeutig markierte Daten nötig sind. Damit können Organisationen mit hochwertigen, gut geschriebenen Inhalten auch ohne explizites strukturiertes Daten-Markup in Wissensgraphen aufgenommen werden, wobei Markup weiterhin für eine präzise Darstellung wichtig bleibt. Die Integration von Wissensgraphen mit großen Sprachmodellen und generativer KI ist vielleicht die bedeutendste Entwicklung. Da KI-Systeme immer zentraler für die Informationssuche werden, reicht Wissensgraph-Optimierung über die klassische Suche hinaus und betrifft auch die KI-Sichtbarkeit auf vielen Plattformen. Unternehmen, die Wissensgraphen verstehen und für sich nutzen, haben Vorteile sowohl in der klassischen Suche als auch in KI-generierten Antworten. Hinzu kommt der Trend zu Enterprise Knowledge Graphs, da immer mehr Unternehmen Wissensgraphen intern einsetzen, um Datensilos aufzubrechen, Entscheidungen zu verbessern und KI-Anwendungen zu ermöglichen – Wissensgraph-Kompetenz wird so für Führungskräfte, Data Scientists und Marketingexperten immer wichtiger. Schließlich rücken auch die regulatorischen und ethischen Fragen rund um Wissensgraphen stärker in den Fokus. Da Wissensgraphen beeinflussen, wie Milliarden Menschen Informationen präsentiert bekommen, werden Themen wie Richtigkeit, Bias, Repräsentation und Kontrolle der Wissensgraph-Informationen wichtiger. Unternehmen sollten sich bewusst sein, dass ihre Entitätenpräsenz im Wissensgraph reale Auswirkungen auf Sichtbarkeit, Ruf und Geschäftserfolg hat, und die Optimierung mit derselben Sorgfalt und Ethik angehen wie andere Aspekte der digitalen Präsenz.