
NoAI-Meta-Tags: Steuerung des KI-Zugriffs über Header
Erfahren Sie, wie Sie noai- und noimageai-Meta-Tags implementieren, um den KI-Crawler-Zugriff auf Ihre Website-Inhalte zu steuern. Umfassender Leitfaden zu KI-Z...
6 Min. Lesezeit
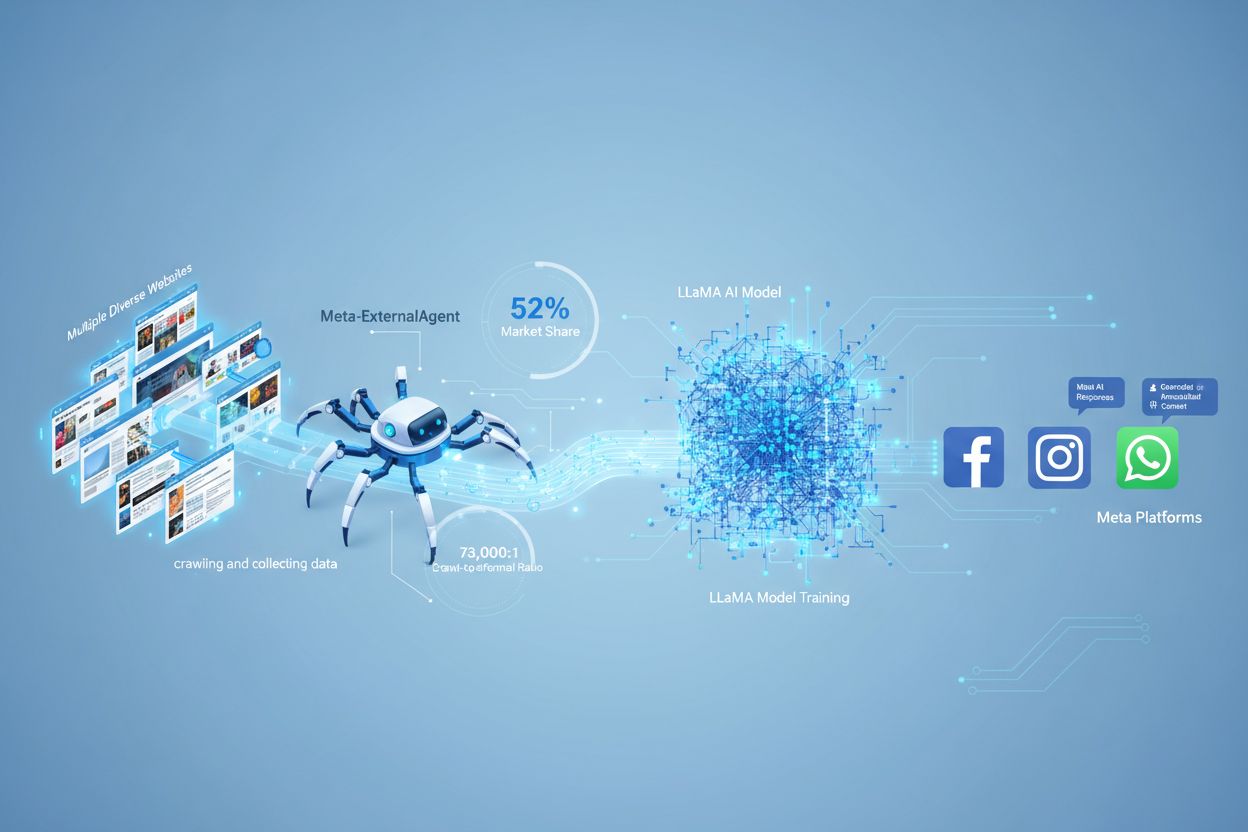
Meta-ExternalAgent ist Metas Web-Crawler-Bot, der im Juli 2024 gestartet wurde, um öffentlich verfügbare Inhalte für das Training von KI-Modellen wie LLaMA zu sammeln. Er identifiziert sich mit dem User-Agent-String meta-externalagent/1.1 und steuert, ob Inhalte in Meta-AI-Antworten auf Facebook, Instagram und WhatsApp erscheinen. Publisher können ihn über robots.txt oder serverseitige Konfigurationen blockieren, wobei die Einhaltung freiwillig und rechtlich nicht bindend ist.
Meta-ExternalAgent ist Metas Web-Crawler-Bot, der im Juli 2024 gestartet wurde, um öffentlich verfügbare Inhalte für das Training von KI-Modellen wie LLaMA zu sammeln. Er identifiziert sich mit dem User-Agent-String meta-externalagent/1.1 und steuert, ob Inhalte in Meta-AI-Antworten auf Facebook, Instagram und WhatsApp erscheinen. Publisher können ihn über robots.txt oder serverseitige Konfigurationen blockieren, wobei die Einhaltung freiwillig und rechtlich nicht bindend ist.
Meta-ExternalAgent ist ein von Meta Platforms betriebener Web-Crawler, der im Juli 2024 gestartet wurde, um Daten für das Training von KI-Modellen zu sammeln. Der Crawler identifiziert sich durch den User-Agent-String meta-externalagent/1.1 und unterscheidet sich damit deutlich vom älteren facebookexternalhit-Crawler von Meta, der primär für Linkvorschauen und Social-Media-Sharing-Funktionen genutzt wurde. Meta-ExternalAgent markiert einen bedeutsamen Wandel in der Art und Weise, wie Meta Trainingsdaten für KI-Initiativen wie die LLaMA-Sprachmodelle und den Meta-AI-Chatbot auf Facebook, Instagram und WhatsApp sammelt. Im Gegensatz zu früheren Meta-Crawlern agiert dieser Agent mit minimaler Transparenz und wurde ohne formelle öffentliche Ankündigung eingeführt.

Meta-ExternalAgent arbeitet als automatisierter Bot, der systematisch Websites im gesamten Internet durchsucht, um Text und Inhalte für das Training von KI-Modellen zu extrahieren. Der Crawler sendet HTTP-Anfragen an Webserver, identifiziert sich über seinen einzigartigen User-Agent-Header und lädt Seiteninhalte zur Verarbeitung herunter. Nach der Sammlung analysieren Metas Systeme die Inhalte und tokenisieren den Text, um daraus Trainingsdaten für die Verbesserung der großen Sprachmodelle zu gewinnen. Der Crawler respektiert die robots.txt-Datei auf freiwilliger Basis, wobei dies eher einem Ehrenkodex als einer rechtlichen Verpflichtung entspricht. Laut Cloudflare-Daten entfallen etwa 52 % des gesamten KI-Crawler-Traffics im Internet auf Meta-ExternalAgent, was ihn zu einer der aggressivsten Datensammlungsoperationen in der KI-Branche macht. Der Crawler arbeitet kontinuierlich; einige Publisher berichten von Crawling-Frequenzen, die darauf hindeuten, dass Meta eine umfassende Abdeckung von Webinhalten gegenüber selektiver Sammlung priorisiert.
| Crawler-Name | User-Agent-String | Hauptzweck | Einführungsdatum | Datennutzung |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | KI-Modelltraining (LLaMA, Meta AI) | Juli 2024 | Trainingsdaten für generative KI |
| facebookexternalhit | facebookexternalhit/1.1 | Linkvorschauen und Social Sharing | ~2010 | Open Graph-Metadaten, Thumbnails |
| Facebot | facebot/1.0 | Inhaltsüberprüfung für Facebook-Apps | ~2015 | Inhaltsvalidierung für mobile Apps |
| Applebot | Applebot/0.1 | Apple Siri und Suchindexierung | ~2015 | Suchindexierung und Sprachassistent |
| Googlebot | Googlebot/2.1 | Google-Suchindexierung | ~1998 | Aufbau des Suchmaschinenindex |
Meta-ExternalAgent stellt für Content-Ersteller und Publisher ein zentrales Anliegen dar, da er in beispiellosem Umfang operiert und nur minimale Transparenz darüber bietet, wie Inhalte verwendet werden. Gemäß Cloudflare-Forschung entfallen 52 % des gesamten KI-Crawler-Traffics auf Meta-ExternalAgent – deutlich mehr als bei Konkurrenten wie GPTBot von OpenAI oder Googles KI-Crawlern. Diese Dominanz bedeutet, dass Meta mehr Trainingsdaten sammelt als jedes andere KI-Unternehmen, während Publisher weder Vergütung noch Attribution erhalten, wenn ihre Inhalte zum Training von Metas KI-Modellen genutzt werden. Das 73.000:1 Crawl-zu-Referral-Verhältnis verdeutlicht, dass Meta enorme Mengen an Inhalten extrahiert, aber praktisch keinen Traffic an die Ursprung-Websites zurückgibt – ein grundlegendes Ungleichgewicht im Wertetausch. Trotz dieser Problematik blockieren nur 2 % der Websites aktiv Meta-ExternalAgent, während 25 % GPTBot blockieren – viele Publisher sind sich der Existenz oder Bedeutung des Crawlers also nicht bewusst. Mit Metas Investitionen von 40 Milliarden US-Dollar in KI-Infrastruktur dürfte sich die aggressive Datensammlung weiter verstärken, wodurch es für Publisher unerlässlich wird, ihren Umgang mit diesem Crawler aktiv zu steuern.
Publisher können den Zugriff von Meta-ExternalAgent über die robots.txt-Datei kontrollieren, wobei zu beachten ist, dass diese Methode freiwillig ist und keine rechtliche Bindung besitzt. Um Meta-ExternalAgent zu blockieren, fügen Sie Ihrer robots.txt-Datei folgende Anweisung hinzu:
User-agent: meta-externalagent
Disallow: /
Alternativ können Sie, wenn Sie den Crawler zulassen, aber auf bestimmte Verzeichnisse beschränken möchten, folgendes nutzen:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Einige Publisher berichten jedoch, dass Meta-ExternalAgent ihre Seiten trotz robots.txt-Sperren weiterhin crawlt. Dies deutet darauf hin, dass Meta diese Vorgaben nicht immer konsequent einhält. Für umfassenderen Schutz können Publisher HTTP-Header-basierte Blockierungen oder CDN-Regeln einsetzen, um Anfragen anhand des User-Agent-Strings zu identifizieren und abzulehnen. Darüber hinaus können Server-Logs auf das Auftreten des User-Agent-Strings meta-externalagent/1.1 überprüft werden, um festzustellen, ob der Crawler auf eigene Inhalte zugreift. Tools wie AmICited.com helfen Publishern dabei, zu verfolgen, ob ihre Inhalte in Meta-AI-Antworten zitiert oder referenziert werden und gewähren so Einblick in die Nutzung ihrer Arbeit durch Metas KI-Systeme.

Wenn Nutzer mit Meta-AI-Chatbots auf Facebook, Instagram oder WhatsApp interagieren, basieren die generierten Antworten teilweise auf Inhalten, die von Meta-ExternalAgent gesammelt wurden. Meta-AI-Antworten enthalten jedoch in der Regel keine sichtbaren Zitate oder Attributionen zu den Quell-Websites, sodass Nutzer nicht erkennen können, welche Publisher-Inhalte zur erhaltenen Antwort beigetragen haben. Dieser Mangel an Transparenz stellt eine große Herausforderung für Content-Ersteller dar, die den Wert ihrer Arbeit für Metas KI-Systeme nachvollziehen möchten. Im Unterschied zu manchen Wettbewerbern, die Zitate in KI-generierte Antworten einbinden, stellt Meta das Nutzererlebnis über die Attribution der Publisher. Das Fehlen sichtbarer Zitate erschwert es Publishern, die Häufigkeit der Nutzung ihrer Inhalte in Meta-AI-Antworten zu verfolgen und so den geschäftlichen Einfluss der KI-Nutzung ihrer Inhalte einzuschätzen. Diese Sichtbarkeitslücke ist ein Hauptgrund dafür, dass Monitoring-Lösungen für Publisher im KI-Ökosystem immer wichtiger werden.
Publisher können Aktivitäten des Meta-ExternalAgent durch Analyse der Server-Logs überprüfen, die die IP-Adressen des Crawlers, Anfragemuster und Zugriffshäufigkeit auf Inhalte offenlegen. Durch Auswertung der Access-Logs lassen sich Anfragen mit dem User-Agent-String meta-externalagent/1.1 identifizieren und feststellen, welche Seiten besonders häufig gecrawlt werden. Fortgeschrittene Monitoring-Tools können Crawl-Muster über die Zeit verfolgen und aufzeigen, ob Meta bestimmte Inhaltstypen oder Website-Bereiche priorisiert. Publisher sollten auch ihre Bandbreitennutzung überwachen, da aggressives Crawling von Meta-ExternalAgent erhebliche Server-Ressourcen beanspruchen kann – insbesondere bei umfangreichen Content-Archiven. Zusätzlich können Tools wie AmICited.com genutzt werden, um zu überwachen, ob eigene Inhalte in Meta-AI-Antworten erscheinen und wie sich Zitatmuster über Metas Plattformen hinweg entwickeln. Das Einrichten von Alerts für ungewöhnliche Crawling-Aktivitäten hilft Publishern, Veränderungen im Datensammlungsverhalten von Meta frühzeitig zu erkennen und entsprechend zu reagieren. Regelmäßige Audits der Server-Logs sollten Teil jeder KI-Crawler-Management-Strategie für Publisher sein, um sich kontinuierlich über den Zugriff und die Nutzung ihrer Inhalte zu informieren.
Der rechtliche Status von Meta-ExternalAgent ist umstritten; laufende Klagen von Content-Erstellern, Künstlern und Publishern stellen Metas Recht infrage, deren Werke ohne ausdrückliche Zustimmung oder Vergütung für das KI-Training zu nutzen. Während Meta argumentiert, dass Web-Crawling unter das Fair-Use-Prinzip fällt, vertreten Kritiker die Ansicht, dass Umfang und kommerzielle Nutzung der Datensammlung – kombiniert mit mangelnder Attribution – Urheberrechtsverletzungen darstellen. Die robots.txt-Datei gilt zwar branchenweit als Standard, besitzt jedoch keine Rechtskraft, sodass Meta nicht verpflichtet ist, die Blockierung zu respektieren. In mehreren Rechtsgebieten werden derzeit Regulierungen für das Sammeln von KI-Trainingsdaten entwickelt; der EU AI Act und Gesetzesvorschläge in anderen Regionen könnten künftig strengere Auflagen für Unternehmen wie Meta mit sich bringen. Aus ethischer Sicht stellt sich die grundlegende Frage, ob Content-Ersteller das Recht haben sollten, die Nutzung ihrer Werke für kommerzielles KI-Training zu steuern und ob das aktuelle System eine angemessene Vergütung für den Wert ihrer Inhalte bietet. Publisher sollten sich über die Entwicklung rechtlicher Rahmenbedingungen informieren und ggf. juristischen Rat bezüglich ihrer Rechte und Pflichten in Bezug auf KI-Crawler einholen. Das Gleichgewicht zwischen Innovationsförderung durch KI und dem Schutz der Rechte von Urhebern ist weiterhin offen und unterliegt laufenden gesetzlichen und regulatorischen Entwicklungen.
Die Landschaft des KI-Crawler-Managements entwickelt sich rasant, während Publisher, Regulierungsbehörden und KI-Unternehmen die Bedingungen für Datensammlung und -nutzung neu verhandeln. Metas aggressiver Einsatz von Meta-ExternalAgent zeigt, dass große Technologieunternehmen Webinhalte als essenzielles Trainingsmaterial für wettbewerbsfähige KI-Systeme betrachten – ein Trend, der sich mit dem wachsenden Einfluss von KI auf Geschäftsstrategien weiter beschleunigen dürfte. Zukünftige Entwicklungen könnten stärkeren rechtlichen Schutz für Ersteller, verpflichtende Lizenzierungsmodelle für KI-Trainingsdaten und technische Standards bringen, die es Publishern erleichtern, die Nutzung ihrer Inhalte in KI-Systemen zu steuern und zu monetarisieren. Das Aufkommen von Tools wie AmICited.com verdeutlicht die steigende Nachfrage nach Transparenz und Verantwortlichkeit bei der KI-Nutzung veröffentlichter Inhalte und macht Monitoring und Verifizierung zum Standard für Content-Ersteller. Mit zunehmender Reife der KI-Branche sind ausgefeiltere Verhandlungen zwischen Content-Erstellern und KI-Unternehmen zu erwarten – möglicherweise entstehen neue Geschäftsmodelle, die Publisher für ihren Beitrag zur KI-Entwicklung fair entlohnen.
Meta-ExternalAgent ist Metas dedizierter KI-Trainingscrawler, der im Juli 2024 eingeführt wurde und sich durch den User-Agent-String meta-externalagent/1.1 identifiziert. Er unterscheidet sich von facebookexternalhit, der Linkvorschauen für das soziale Teilen generiert. Meta-ExternalAgent sammelt gezielt Inhalte für das Training von LLaMA-Modellen und Meta AI, während facebookexternalhit seit etwa 2010 für soziale Funktionen verwendet wird.
Sie können Meta-ExternalAgent blockieren, indem Sie Anweisungen in Ihrer robots.txt-Datei hinzufügen. Fügen Sie 'User-agent: meta-externalagent' gefolgt von 'Disallow: /' hinzu, um ihn vollständig zu blockieren. Für einen umfassenderen Schutz implementieren Sie serverseitige Sperren mittels .htaccess (Apache) oder Nginx-Konfigurationsregeln. Beachten Sie jedoch, dass robots.txt freiwillig und nicht rechtlich bindend ist, sodass einige Publisher trotz Sperre weiterhin Crawling-Aktivitäten melden.
Nein, das Blockieren von Meta-ExternalAgent wirkt sich nicht auf Facebook-Linkvorschauen aus. Der facebookexternalhit-Crawler ist für Linkvorschauen und soziale Sharing-Funktionen zuständig. Sie können meta-externalagent blockieren und gleichzeitig facebookexternalhit erlauben, weiterhin ansprechende Vorschauen zu generieren, wenn Ihre Inhalte auf Meta-Plattformen geteilt werden.
Meta-ExternalAgent weist ein Crawl-zu-Referral-Verhältnis von etwa 73.000:1 auf, das heißt, Meta extrahiert Inhalte in enormem Umfang, während nahezu kein Traffic an die Quell-Websites zurückgesendet wird. Dies stellt ein grundlegendes Ungleichgewicht im Vergleich zu traditionellen Suchmaschinen dar, die Inhalte crawlen, um Verweis-Traffic zu liefern.
robots.txt ist ein Ehrenkodex und rechtlich nicht bindend. Während viele Crawler robots.txt-Anweisungen respektieren, haben einige Publisher berichtet, dass Meta-ExternalAgent ihre Seiten trotz expliziter robots.txt-Sperren weiterhin crawlt. Für garantierten Schutz implementieren Sie serverseitige Blockierungen mittels HTTP-Headern, CDN-Regeln oder Firewall-Konfigurationen.
Prüfen Sie Ihre Server-Access-Logs auf Anfragen mit dem User-Agent-String 'meta-externalagent/1.1'. Sie können auch Überwachungstools wie AmICited.com verwenden, um zu verfolgen, ob Ihre Inhalte in Meta-AI-Antworten erscheinen. Tools wie Dark Visitors und Cloudflare Analytics bieten zusätzliche Einblicke in die Aktivitäten von KI-Crawlern auf Ihrer Website.
Laut Cloudflare-Daten macht Meta-ExternalAgent etwa 52 % des gesamten KI-Crawler-Traffics im Internet aus und ist damit die aggressivste KI-Datensammlungsoperation. Dies übertrifft Konkurrenten wie OpenAIs GPTBot und Googles KI-Crawler deutlich und zeigt Metas dominierende Position bei der Sammlung von Webinhalten für das KI-Training.
Die Entscheidung hängt von Ihren geschäftlichen Prioritäten ab. Wenn Meta-AI-Traffic für Ihr Publikum wertvoll ist, könnten Sie ihn zulassen. Bedenken Sie jedoch, dass Meta für im KI-Training verwendete Inhalte weder Vergütung noch Attribution bietet. Viele Publisher setzen selektive Blockierstrategien ein, die das KI-Training stoppen, aber die Vorschau-Funktionalität für das soziale Teilen erhalten.
Verfolgen Sie, wie Ihre Inhalte in Meta-AI-Antworten auf Facebook, Instagram und WhatsApp erscheinen. Erhalten Sie Einblick in KI-Zitate und verstehen Sie die Präsenz Ihrer Marke in KI-generierten Antworten.
Erfahren Sie, wie Sie noai- und noimageai-Meta-Tags implementieren, um den KI-Crawler-Zugriff auf Ihre Website-Inhalte zu steuern. Umfassender Leitfaden zu KI-Z...

Entdecken Sie, wie Meta AI-Optimierung Facebook- und Instagram-Werbung mit KI-gestützter Automatisierung, Echtzeit-Gebotsabgabe und intelligenter Zielgruppenans...

Verstehen Sie, wie KI-Crawler wie GPTBot und ClaudeBot funktionieren, wo sie sich von traditionellen Such-Crawlern unterscheiden und wie Sie Ihre Website für Si...