
Query Refinement
Query Refinement ist der iterative Prozess der Optimierung von Suchanfragen für bessere Ergebnisse in KI-Suchmaschinen. Erfahren Sie, wie es bei ChatGPT, Perple...
13 Min. Lesezeit
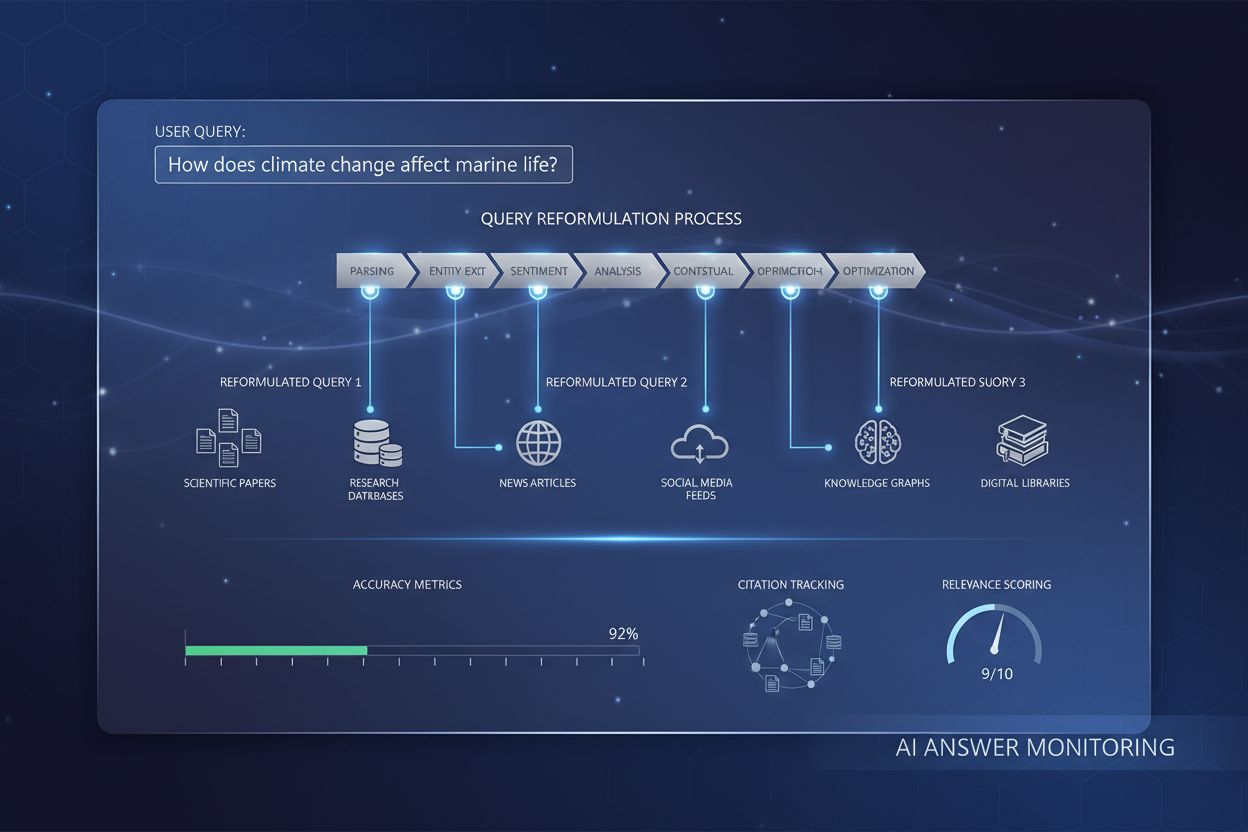
Query-Reformulierung ist der Prozess, bei dem KI-Systeme Benutzeranfragen interpretieren, umstrukturieren und erweitern, um die Genauigkeit und Relevanz der Informationsbeschaffung zu verbessern. Sie verwandelt einfache oder mehrdeutige Benutzereingaben in detailliertere, kontextuell angereicherte Versionen, die mit dem Verständnis des KI-Systems übereinstimmen und präzisere sowie umfassendere Antworten ermöglichen.
Query-Reformulierung ist der Prozess, bei dem KI-Systeme Benutzeranfragen interpretieren, umstrukturieren und erweitern, um die Genauigkeit und Relevanz der Informationsbeschaffung zu verbessern. Sie verwandelt einfache oder mehrdeutige Benutzereingaben in detailliertere, kontextuell angereicherte Versionen, die mit dem Verständnis des KI-Systems übereinstimmen und präzisere sowie umfassendere Antworten ermöglichen.
Query-Reformulierung ist der Prozess, bei dem die ursprüngliche Suchanfrage eines Nutzers transformiert, erweitert oder umgeschrieben wird, um sie besser an die Fähigkeiten des zugrundeliegenden Informationsbeschaffungssystems und an die tatsächliche Absicht des Nutzers anzupassen. Im Kontext von Künstlicher Intelligenz und Natural Language Processing (NLP) überbrückt die Query-Reformulierung die entscheidende Lücke zwischen der natürlichen Ausdrucksweise der Nutzer und der Interpretation sowie Verarbeitung dieser Anfragen durch KI-Systeme. Diese Technik ist in modernen KI-Systemen unerlässlich, da Nutzer Anfragen häufig ungenau formulieren, domänenspezifische Begriffe inkonsistent verwenden oder es versäumen, Kontextinformationen anzugeben, die die Genauigkeit der Informationsbeschaffung verbessern würden. Die Query-Reformulierung liegt an der Schnittstelle von Informationsbeschaffung, semantischem Verständnis und maschinellem Lernen und ermöglicht es Systemen, relevantere Ergebnisse zu generieren, indem sie Anfragen aus verschiedenen Blickwinkeln neu interpretiert—sei es durch Synonym-Expansion, kontextuelle Anreicherung oder strukturelle Umorganisation. Durch intelligente Reformulierung von Anfragen können KI-Systeme die Antwortqualität erheblich steigern, Mehrdeutigkeiten reduzieren und sicherstellen, dass abgerufene Informationen die Nutzerabsicht genauer widerspiegeln.
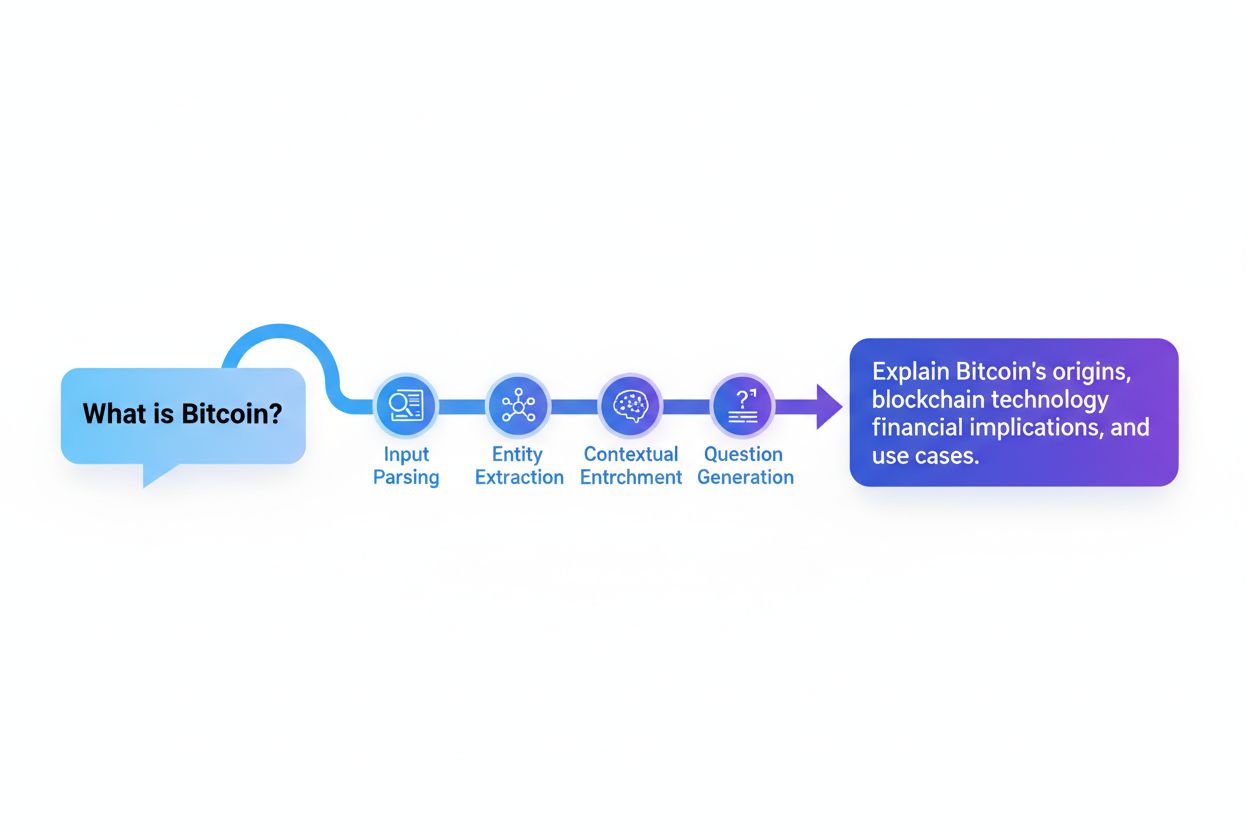
Query-Reformulierungssysteme arbeiten typischerweise durch fünf miteinander verbundene Komponenten, die zusammenarbeiten, um rohe Benutzereingaben in optimierte Suchanfragen umzuwandeln. Input Parsing zerlegt die ursprüngliche Anfrage in ihre Bestandteile und identifiziert Schlüsselwörter, Phrasen und Strukturelemente. Entity Extraction erkennt benannte Entitäten (Personen, Orte, Organisationen, Produkte) und domänenspezifische Konzepte mit semantischer Bedeutung. Sentiment-Analyse bewahrt den emotionalen Tonfall oder die Bewertungshaltung der ursprünglichen Anfrage, sodass reformulierte Versionen die Perspektive des Nutzers erhalten. Kontextanalyse bezieht Sitzungsverlauf, Nutzerprofilinformationen und Domänenwissen ein, um die Anfrage mit impliziter Bedeutung anzureichern. Fragegenerierung wandelt deklarative Aussagen oder Fragmente in wohlgeformte Fragen um, die von Abrufsystemen effektiver verarbeitet werden können.
| Komponente | Zweck | Beispiel |
|---|---|---|
| Input Parsing | Zerlegt und segmentiert die Anfrage in sinnvolle Einheiten | “beste Python-Bibliotheken” → [“beste”, “Python”, “Bibliotheken”] |
| Entity Extraction | Erkennt benannte Entitäten und Domänenkonzepte | “Apples neuestes iPhone” → Entität: Apple (Unternehmen), iPhone (Produkt) |
| Sentiment-Analyse | Bewahrt Bewertungston und Nutzerperspektive | “schlechter Kundenservice” → Negative Stimmung bleibt in der Reformulierung erhalten |
| Kontextanalyse | Bezieht Sitzungsverlauf und Domänenwissen ein | Frühere Anfrage zu “Maschinelles Lernen” beeinflusst aktuelle Anfrage zu “Neuronale Netze” |
| Fragegenerierung | Wandelt Fragmente in strukturierte Fragen um | “Python-Debugging” → “Wie debugge ich Python-Code?” |
Der Prozess der Query-Reformulierung folgt einer systematischen sechsstufigen Methodik, die darauf ausgelegt ist, die Qualität und Relevanz der Anfragen schrittweise zu steigern:
Input Parsing und Normalisierung
Entitäts- und Konzeptextraktion
Bewahrung von Sentiment und Absicht
Kontextuelle Anreicherung
Query-Expansion und Synonym-Generierung
Optimierung und Evaluation
Die Query-Reformulierung nutzt verschiedene Techniken, von klassischen lexikalischen Ansätzen bis hin zu modernen neuronalen Methoden. Synonymbasierte Expansion nutzt etablierte Ressourcen wie WordNet, Wort-Embeddings wie Word2Vec und GloVe und kontextuelle Modelle wie BERT, um semantisch ähnliche Begriffe zu ermitteln. Query Relaxation lockert die Anfrage schrittweise, um die Trefferquote zu erhöhen, wenn die ursprünglichen Ergebnisse unzureichend sind—z. B. Entfernen seltener Begriffe oder Erweitern von Datumsbereichen. Integration von Nutzerfeedback und Sitzungskontext ermöglicht es Systemen, aus Nutzerinteraktionen zu lernen und Reformulierungen anhand tatsächlich als relevant empfundener Ergebnisse zu verfeinern. Transformer-basierte Rewriter wie T5 (Text-to-Text Transfer Transformer) und GPT-Modelle generieren völlig neue Anfrageformulierungen, indem sie Muster aus großen Trainingsdatensätzen von Anfragenpaaren lernen. Hybride Ansätze kombinieren mehrere Techniken—etwa regelbasierte Synonym-Expansion für Begriffe mit hoher Sicherheit und neuronale Modelle für mehrdeutige Phrasen. In der Praxis werden oft Ensemble-Methoden verwendet, die mehrere Reformulierungen erzeugen und diese mittels gelernten Relevanzmodellen bewerten. E-Commerce-Plattformen kombinieren zum Beispiel domänenspezifische Synonymwörterbücher mit BERT-Embeddings, um sowohl standardisierte Produktterminologien als auch umgangssprachliche Nutzersprache zu verarbeiten, während medizinische Suchsysteme spezialisierte Ontologien in Verbindung mit Transformermodellen einsetzen, um klinische Genauigkeit zu gewährleisten.
Query-Reformulierung bringt bedeutende Verbesserungen in mehreren Bereichen der KI-Systemleistung und Benutzererfahrung:
Verbesserte Retrieval-Genauigkeit: Reformulierte Anfragen erfassen die Nutzerabsicht präziser, was zu hochwertigeren abgerufenen Dokumenten und relevanteren KI-generierten Antworten führt. Durch die Erweiterung von Anfragen mit Synonymen und verwandten Konzepten finden Systeme auch Dokumente mit abweichender Terminologie, was die Wahrscheinlichkeit erhöht, wirklich relevante Informationen zu finden.
Erhöhte Recall und Abdeckung: Query-Expansion steigert die Anzahl relevanter Dokumente, indem sie semantische Varianten und verwandte Konzepte einbezieht. Dies ist besonders wertvoll in Spezialgebieten mit stark variierender Terminologie, damit Nutzer keine relevanten Informationen aufgrund unterschiedlicher Wortwahl verpassen.
Reduzierte Mehrdeutigkeit und Klarstellung: Reformulierungsprozesse entschärfen vage oder mehrdeutige Anfragen, indem sie Kontext einbeziehen und mehrere Interpretationen generieren. So können Systeme beispielsweise die Anfrage “Apple” (Frucht vs. Unternehmen) durch kontextspezifische Reformulierungen präzisieren.
Bessere Nutzererfahrung und Zufriedenheit: Nutzer erhalten schneller relevantere Ergebnisse und müssen weniger Anfragen nachbessern. Weniger fehlgeschlagene Suchen und mehr Treffer beim ersten Versuch führen zu höherer Zufriedenheit und geringerer kognitiver Belastung.
Skalierbarkeit und Effizienz: Reformulierung ermöglicht es Systemen, vielfältige Nutzergruppen mit unterschiedlichen Wortschätzen, Kenntnisständen und sprachlichen Hintergründen zu bedienen. Eine einzige Reformulierungs-Engine kann Nutzer verschiedenster Domänen und Sprachen unterstützen, wodurch die Skalierbarkeit ohne proportionalen Infrastrukturaufwand steigt.
Kontinuierliche Verbesserung und Lernen: Query-Reformulierungssysteme können auf Basis von Nutzungsdaten trainiert werden und verbessern kontinuierlich ihre Strategien, je nachdem, welche Reformulierungen zu erfolgreichen Ergebnissen führen. Dadurch entsteht ein positiver Kreislauf, in dem sich die Systemleistung mit wachsender Datenbasis verbessert.
Domänenanpassung und Spezialisierung: Reformulierungstechniken lassen sich auf bestimmte Domänen (medizinisch, juristisch, technisch) zuschneiden, indem sie auf domänenspezifischen Anfragepaaren trainiert und Domänenontologien integriert werden. So können spezialisierte Systeme die Fachterminologie präziser behandeln als generische Ansätze.
Robustheit gegenüber Anfragevariationen: Systeme werden widerstandsfähig gegen Tippfehler, Grammatikfehler und Umgangssprache, indem sie Anfragen in standardisierte Formen reformulieren. Diese Robustheit ist besonders für sprachbasierte Interfaces und mobile Suche wertvoll, bei denen die Eingabequalität stark variiert.
Die Query-Reformulierung spielt eine entscheidende Rolle für die Genauigkeit und Zuverlässigkeit von KI-generierten Antworten und ist damit unverzichtbar für KI-Antwort-Monitoring-Plattformen wie AmICited.com. Wenn KI-Systeme Anfragen vor der Generierung von Antworten reformulieren, beeinflusst die Qualität dieser Reformulierungen direkt, ob die KI geeignete Quellenmaterialien abruft und korrekte, gut belegte Antworten liefert. Schlecht reformulierte Anfragen können dazu führen, dass KI-Systeme irrelevante Dokumente abrufen und Antworten generieren, die unzureichend fundiert sind oder unangemessene Quellen zitieren. Im Kontext von KI-Monitoring und Zitations-Tracking ist das Verständnis der Reformulierung entscheidend, um zu überprüfen, ob KI-Systeme tatsächlich die vom Nutzer gestellte Frage beantworten und nicht eine verzerrte Interpretation davon. AmICited.com verfolgt, wie KI-Systeme Anfragen reformulieren, um sicherzustellen, dass die in KI-generierten Antworten zitierten Quellen wirklich zur ursprünglichen Nutzerfrage passen und nicht nur zu einer fehlinterpretierten Reformulierung. Diese Monitoring-Fähigkeit ist besonders wichtig, weil die Query-Reformulierung für Endnutzer unsichtbar bleibt—sie sehen nur die endgültige Antwort und Zitate, ohne zu wissen, wie die zugrunde liegende Anfrage transformiert wurde. Durch die Analyse von Reformulierungsmustern können KI-Monitoring-Plattformen erkennen, wann KI-Systeme Antworten auf Basis von Reformulierungen generieren, die stark von der Nutzerabsicht abweichen, und potenzielle Genauigkeitsprobleme frühzeitig identifizieren. Darüber hinaus hilft das Verständnis der Reformulierung den Plattformen zu beurteilen, ob KI-Systeme mehrdeutige Anfragen angemessen behandeln, indem sie mehrere Reformulierungen generieren und Informationen daraus zusammenführen, oder ob sie unbegründete Annahmen über die Nutzerabsicht treffen.
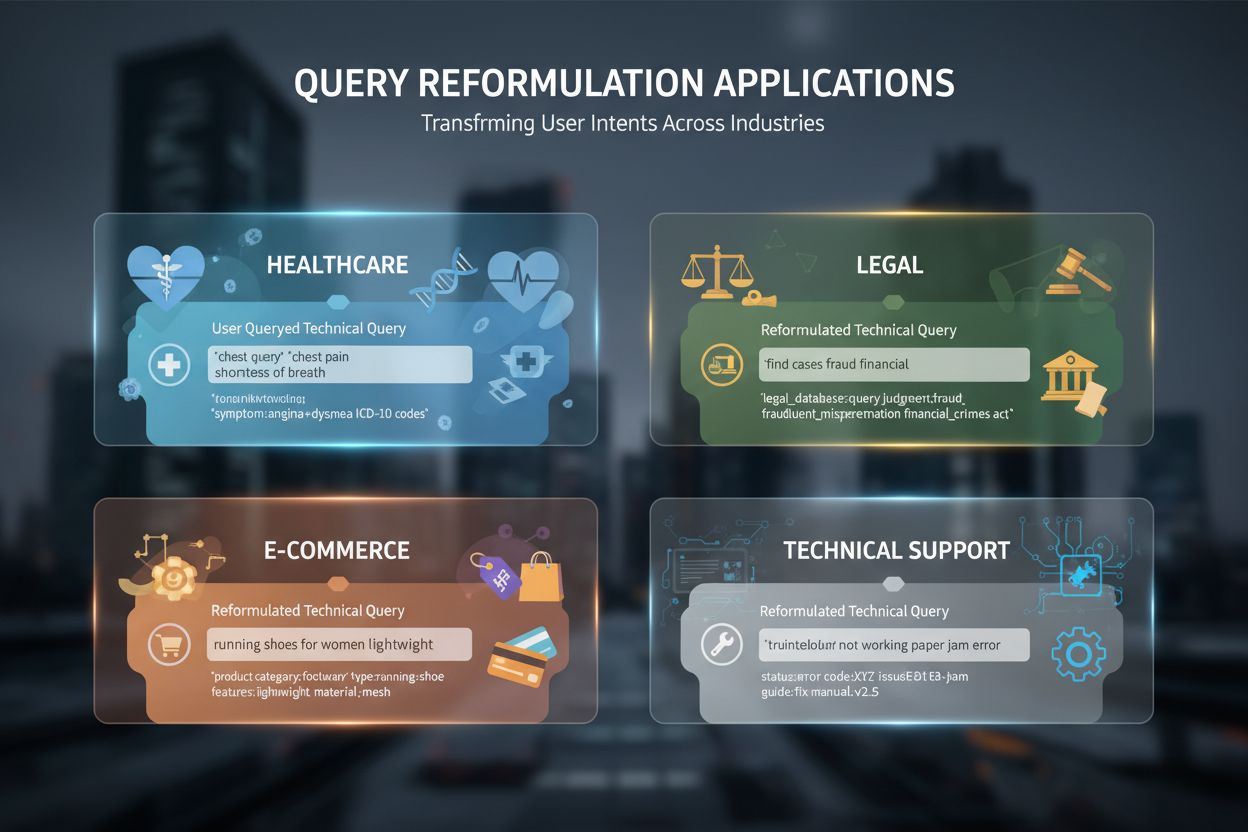
Die Query-Reformulierung ist in zahlreichen KI-gestützten Anwendungen und Branchen unverzichtbar geworden. Im Gesundheitswesen und der medizinischen Forschung bewältigt sie die Komplexität medizinischer Terminologie, bei der Patienten etwa nach “Herzinfarkt” suchen, während die Fachliteratur “Myokardinfarkt” verwendet—Reformulierung überbrückt diese Wortschatzlücke und fördert klinische Genauigkeit. Juristische Dokumentenanalyse nutzt Query-Reformulierung, um die präzise, altertümliche Sprache von Rechtstexten mit modernen Suchbegriffen zu verbinden, damit Juristen relevante Präzedenzfälle unabhängig von der Formulierung finden. Technische Supportsysteme reformulieren Nutzeranfragen, um sie mit Artikeln in Wissensdatenbanken abzugleichen, indem umgangssprachliche Problembeschreibungen (“mein Computer ist langsam”) in technische Begriffe (“Systemleistungsabfall”) übersetzt werden, um passende Hilfestellungen zu finden. E-Commerce-Suchoptimierung verwendet Query-Reformulierung, um Produktsuchen zu bewältigen, bei denen Nutzer nach “Laufschuhen” suchen, der Katalog aber “Sportschuhe” oder Markennamen führt—so finden Kunden Produkte trotz unterschiedlicher Begriffe. Konversationelle KI und Chatbots nutzen Query-Reformulierung, um Kontext über mehrere Gesprächsrunden hinweg zu erhalten und Folgefragen mit implizitem Kontext aus vorherigen Interaktionen zu reformulieren. Retrieval-Augmented Generation (RAG)-Systeme sind stark auf Query-Reformulierung angewiesen, um sicherzustellen, dass die abgerufenen Kontextdokumente tatsächlich zur Nutzerfrage passen—was die Qualität der generierten Antworten direkt beeinflusst. Beispielsweise kann ein RAG-System auf die Frage “Wie optimiere ich Datenbankabfragen?” mehrere Varianten wie “Leistungsoptimierung von Datenbankabfragen”, “SQL-Optimierungstechniken” und “Query Execution Plans” reformulieren, um möglichst umfassenden Kontext zu beschaffen und eine fundierte Antwort zu generieren.
Trotz aller Vorteile bringt die Query-Reformulierung mehrere Herausforderungen mit sich, die Praktiker sorgfältig abwägen müssen. Rechenkomplexität steigt erheblich, wenn mehrere Reformulierungen erzeugt und nach Relevanz bewertet werden müssen—jede Reformulierung erfordert Verarbeitung, und Systeme müssen Qualitätsgewinne gegen Latenzanforderungen insbesondere bei Echtzeitanwendungen abwägen. Qualität der Trainingsdaten bestimmt direkt die Effektivität der Reformulierung; Systeme, die auf schlechten Anfragepaaren oder voreingenommenen Datensätzen trainiert wurden, perpetuieren diese Verzerrungen und verschärfen Probleme möglicherweise noch. Risiko der Über-Reformulierung besteht, wenn Systeme so viele Varianten erzeugen, dass der Bezug zur ursprünglichen Absicht verloren geht und zunehmend abwegige Ergebnisse abgerufen werden, die eher verwirren als klären. Domänenspezifische Anpassung erfordert erheblichen Aufwand—auf allgemeine Webanfragen trainierte Modelle liefern in Spezialgebieten wie Medizin oder Recht oft schlechte Ergebnisse ohne umfassendes Retraining und Domänentuning. Abwägung zwischen Präzision und Recall stellt einen fundamentalen Zielkonflikt dar: Aggressive Query-Expansion erhöht den Recall, verringert aber unter Umständen die Präzision durch irrelevante Ergebnisse; konservative Reformulierung erhält die Präzision, verpasst aber relevante Dokumente. Potenzielle Einführung von Vorurteilen kann auftreten, wenn Reformulierungssysteme gesellschaftliche Verzerrungen der Trainingsdaten übernehmen und so Diskriminierung in Suchergebnissen oder KI-Antworten verstärken—beispielsweise könnten reformulierte “Krankenschwester”-Anfragen überwiegend weiblich assoziierte Ergebnisse liefern, wenn die Trainingsdaten historische Geschlechterrollen widerspiegeln.
Die Query-Reformulierung entwickelt sich rasant weiter, da KI-Fähigkeiten wachsen und neue Techniken entstehen. Fortschritte in LLM-basierter Reformulierung ermöglichen kontextbewusstere und ausgefeiltere Anfrage-Transformationen, da große Sprachmodelle immer besser differenzierte Nutzerabsichten erkennen und natürlichere, semantisch reichhaltige Reformulierungen generieren können. Multimodale KI-Integration wird die Query-Reformulierung über Text hinaus erweitern und Bilder-, Audio- und Videoanfragen unterstützen, indem visuelle Suchanfragen in Textbeschreibungen umgewandelt werden, die von Retrieval-Systemen verarbeitet werden können. Personalisierung und Lernen erlauben es Reformulierungssystemen, sich an individuelle Nutzerpräferenzen, Wortschatz und Suchmuster anzupassen und zunehmend personalisierte Reformulierungen zu erzeugen, die dem Kommunikationsstil der einzelnen Nutzer entsprechen. Echtzeit-adaptive Reformulierung ermöglicht es Systemen, Anfragen dynamisch basierend auf Zwischenergebnissen der Informationsbeschaffung zu reformulieren und Feedbackschleifen zu schaffen, in denen erste Reformulierungen weitere Verfeinerungen anstoßen. Integration von Knowledge Graphs versetzt Reformulierungssysteme in die Lage, strukturiertes Wissen über Entitäten und Beziehungen zu nutzen und semantisch präzisere Reformulierungen auf Basis expliziter Wissensrepräsentationen zu erstellen. Neue Standards für die Evaluation und das Benchmarking von Query-Reformulierung werden Vergleiche zwischen Systemen ermöglichen und branchenweite Verbesserungen in Qualität und Konsistenz der Reformulierung vorantreiben.
Query-Reformulierung ist der umfassendere Prozess der Umwandlung einer Anfrage, um die Informationsbeschaffung zu verbessern, während die Query-Expansion eine spezielle Technik innerhalb der Reformulierung ist, bei der Synonyme und verwandte Begriffe hinzugefügt werden. Die Query-Expansion konzentriert sich auf die Erweiterung des Suchbereichs, während die Reformulierung mehrere Techniken wie Parsing, Entitätsextraktion, Sentiment-Analyse und kontextuelle Anreicherung umfasst, um die Qualität der Anfrage grundsätzlich zu verbessern.
Die Query-Reformulierung hilft KI-Systemen, die Benutzerabsicht besser zu verstehen, indem sie mehrdeutige Begriffe klärt, Kontext hinzufügt und mehrere Interpretationen der ursprünglichen Anfrage erzeugt. Dies führt zur Beschaffung relevanterer Quelldokumente, wodurch die KI genauere, besser begründete Antworten mit korrekten Zitaten generieren kann.
Ja, die Query-Reformulierung kann als Sicherheitsschicht dienen, indem sie Benutzereingaben standardisiert und bereinigt, bevor sie das Haupt-KI-System erreichen. Ein spezialisierter Reformulierungsagent kann potenziell schädliche Eingaben erkennen und neutralisieren, verdächtige Muster filtern und Anfragen in sichere, standardisierte Formate umwandeln, um die Anfälligkeit für Prompt-Injection-Angriffe zu verringern.
In Retrieval-Augmented Generation (RAG)-Systemen ist die Query-Reformulierung entscheidend, um sicherzustellen, dass die abgerufenen Kontextdokumente tatsächlich relevant für die Benutzerfrage sind. Durch Reformulierung von Anfragen in mehrere Varianten können RAG-Systeme umfassenderen und vielfältigeren Kontext abrufen, was die Qualität und Genauigkeit der generierten Antworten direkt verbessert.
Die Implementierung umfasst in der Regel die Auswahl geeigneter Techniken für Ihren Anwendungsfall: Verwenden Sie synonymbasierte Expansion mit BERT oder Word2Vec für semantische Ähnlichkeit, setzen Sie Transformermodelle wie T5 oder GPT für neuronale Reformulierung ein, integrieren Sie domänenspezifische Ontologien für Spezialgebiete und implementieren Sie Feedbackschleifen, um Reformulierungen kontinuierlich anhand von Benutzerinteraktionen und Erfolgsmetriken bei der Informationsbeschaffung zu verbessern.
Die Rechenkosten variieren je nach Technik: Einfache Synonym-Expansion ist ressourcenschonend, während transformerbasierte Reformulierung erhebliche GPU-Ressourcen erfordert. Die Verwendung kleinerer spezialisierter Modelle für die Reformulierung und größerer Modelle nur für die endgültige Antwortgenerierung kann jedoch Kosten optimieren. Viele Systeme verwenden Caching und Batch-Processing, um die Rechenkosten auf mehrere Anfragen zu verteilen.
Die Query-Reformulierung wirkt sich direkt auf die Zitiergenauigkeit aus, da die reformulierte Anfrage bestimmt, welche Dokumente abgerufen und zitiert werden. Wenn die Reformulierung erheblich von der ursprünglichen Benutzerabsicht abweicht, kann es sein, dass die KI Quellen zitiert, die für die reformulierte Anfrage, nicht aber für die ursprüngliche Frage relevant sind. KI-Monitoring-Plattformen wie AmICited verfolgen diese Transformationen, um sicherzustellen, dass die Zitate tatsächlich für das relevant sind, was Benutzer tatsächlich gefragt haben.
Ja, die Query-Reformulierung kann bestehende Vorurteile verstärken, wenn Trainingsdaten gesellschaftliche Vorurteile widerspiegeln. Zum Beispiel könnte die Reformulierung bestimmter Anfragen überproportional Ergebnisse liefern, die mit bestimmten demografischen Gruppen assoziiert sind. Dies zu mildern erfordert sorgfältige Auswahl von Datensätzen, Mechanismen zur Erkennung von Verzerrungen, vielfältige Trainingsbeispiele und kontinuierliche Überwachung der Reformulierungsausgaben auf Fairness und Repräsentativität.
Die Query-Reformulierung beeinflusst, wie KI-Systeme Ihre Inhalte verstehen und zitieren. AmICited verfolgt diese Transformationen, um sicherzustellen, dass Ihre Marke in KI-generierten Antworten korrekt zugeordnet wird.
Query Refinement ist der iterative Prozess der Optimierung von Suchanfragen für bessere Ergebnisse in KI-Suchmaschinen. Erfahren Sie, wie es bei ChatGPT, Perple...
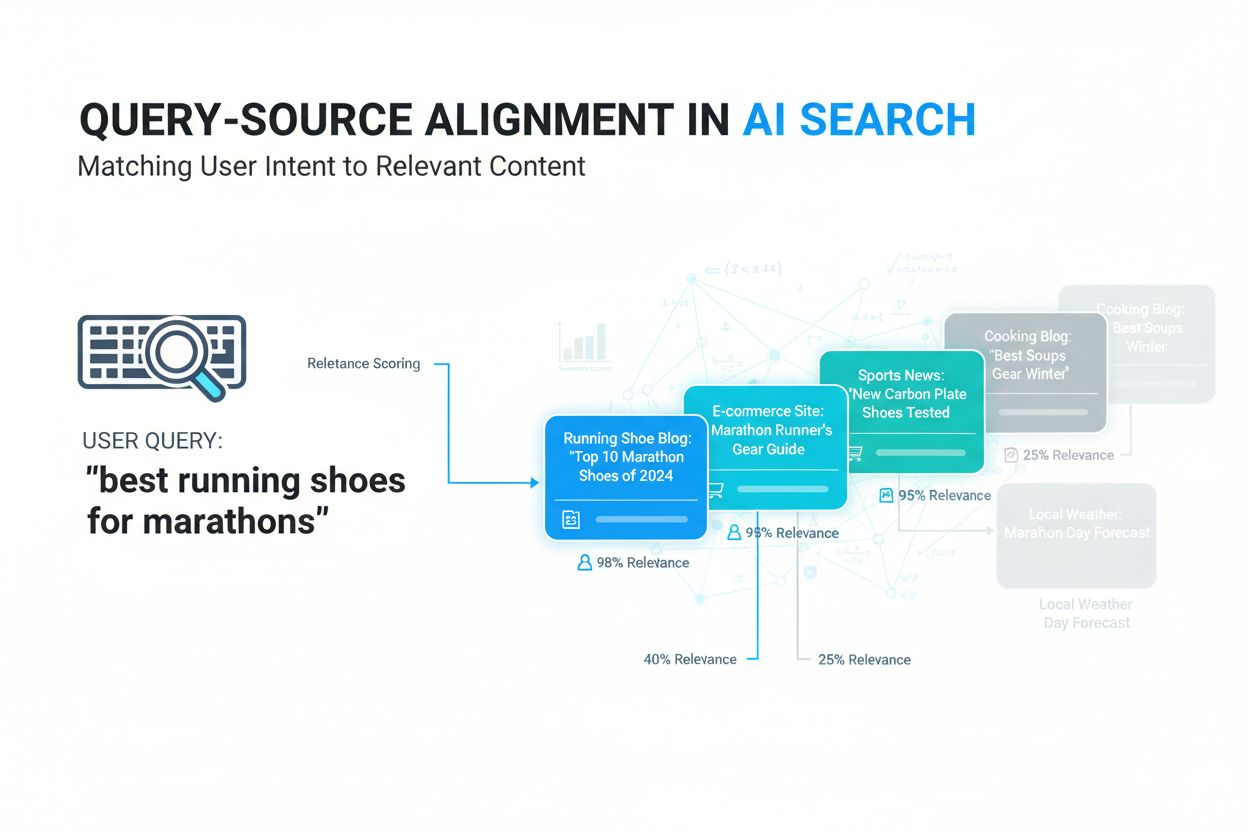
Erfahren Sie, was Query-Source-Alignment ist, wie KI-Systeme Benutzeranfragen mit relevanten Quellen abgleichen und warum das für die Sichtbarkeit von Inhalten ...
Erfahren Sie, wie die Optimierung der Abfrageerweiterung KI-Suchergebnisse verbessert, indem sie Wortschatzlücken überbrückt. Entdecken Sie Techniken, Herausfor...