Sonar-Algorithmus in Perplexity: Echtzeit-Suchmodell erklärt
Erfahren Sie, wie Perplexitys Sonar-Algorithmus die Echtzeit-KI-Suche mit kostengünstigen Modellen antreibt. Entdecken Sie die Varianten Sonar, Sonar Pro und So...
8 Min. Lesezeit
Der Sonar-Algorithmus ist das proprietäre retrieval-augmented generation (RAG) Ranking-System von Perplexity, das hybride semantische und Keyword-Suche mit neuronalem Re-Ranking kombiniert, um Webquellen in KI-generierten Antworten in Echtzeit abzurufen, zu bewerten und zu zitieren. Er priorisiert Aktualität, semantische Relevanz und Zitierfähigkeit, um fundierte, quellengestützte Antworten zu liefern und Halluzinationen zu minimieren.
Der Sonar-Algorithmus ist das proprietäre retrieval-augmented generation (RAG) Ranking-System von Perplexity, das hybride semantische und Keyword-Suche mit neuronalem Re-Ranking kombiniert, um Webquellen in KI-generierten Antworten in Echtzeit abzurufen, zu bewerten und zu zitieren. Er priorisiert Aktualität, semantische Relevanz und Zitierfähigkeit, um fundierte, quellengestützte Antworten zu liefern und Halluzinationen zu minimieren.
Sonar-Algorithmus ist Perplexitys proprietäres retrieval-augmented generation (RAG) Rankingsystem, das seine Antwortmaschine antreibt, indem es hybride semantische und Keyword-Suche, neuronales Re-Ranking und Echtzeit-Zitierung kombiniert. Im Gegensatz zu traditionellen Suchmaschinen, die Seiten für die Anzeige in einer Ergebnisliste ranken, bewertet Sonar Inhaltsschnipsel zur Synthese einer einzigen, einheitlichen Antwort mit Inline-Zitaten auf Quelldokumente. Der Algorithmus priorisiert Aktualität, semantische Relevanz und Zitierfähigkeit, um fundierte, quellengestützte Antworten zu liefern und Halluzinationen zu minimieren. Sonar stellt einen grundlegenden Wandel darin dar, wie KI-Systeme Informationen abrufen und bewerten – weg von linkbasierten Autoritätssignalen hin zu nutzungsorientierten Metriken, die darauf abzielen, ob Inhalte direkt die Nutzerintention erfüllen und sauber in synthetisierten Antworten zitiert werden können. Dieser Unterschied ist entscheidend, um zu verstehen, wie Sichtbarkeit in KI-Antwortmaschinen sich grundlegend von klassischem SEO unterscheidet, da Sonar Inhalte nicht für Listenrankings, sondern für Extraktion, Synthese und Attribution in einer KI-generierten Antwort bewertet.
Das Aufkommen des Sonar-Algorithmus spiegelt einen breiteren Branchentrend hin zu retrieval-augmented generation als dominanter Architektur für KI-Antwortmaschinen wider. Als Perplexity Ende 2022 startete, erkannte das Unternehmen eine kritische Lücke in der KI-Landschaft: Während ChatGPT leistungsstarke Konversationsfähigkeiten bot, fehlten Echtzeit-Informationszugriff und Quellenangabe, was zu Halluzinationen und veralteten Antworten führte. Das Gründungsteam von Perplexity, das ursprünglich an einem Datenbank-Übersetzungstool arbeitete, verschrieb sich ganz dem Aufbau einer Antwortmaschine, die Live-Websuche mit LLM-Synthese verbindet. Diese strategische Entscheidung prägte Sonars Architektur von Anfang an – der Algorithmus wurde nicht dafür konzipiert, Seiten für menschliches Browsen zu ranken, sondern Inhaltsschnipsel für maschinelle Synthese und Zitierung abzurufen und zu bewerten. In den letzten zwei Jahren hat sich Sonar zu einem der ausgereiftesten Rankingsysteme im KI-Ökosystem entwickelt, wobei Perplexitys Sonar-Modelle die Ränge 1 bis 4 in der Search Arena Evaluation belegen und damit Wettbewerber wie Google und OpenAI deutlich übertreffen. Der Algorithmus verarbeitet inzwischen monatlich über 400 Millionen Suchanfragen, indiziert über 200 Milliarden einzigartige URLs und hält Aktualität durch zehntausende Index-Updates pro Sekunde in Echtzeit aufrecht. Diese Größenordnung und Raffinesse unterstreichen die Bedeutung von Sonar als prägendes Ranking-Paradigma im KI-Suchzeitalter.
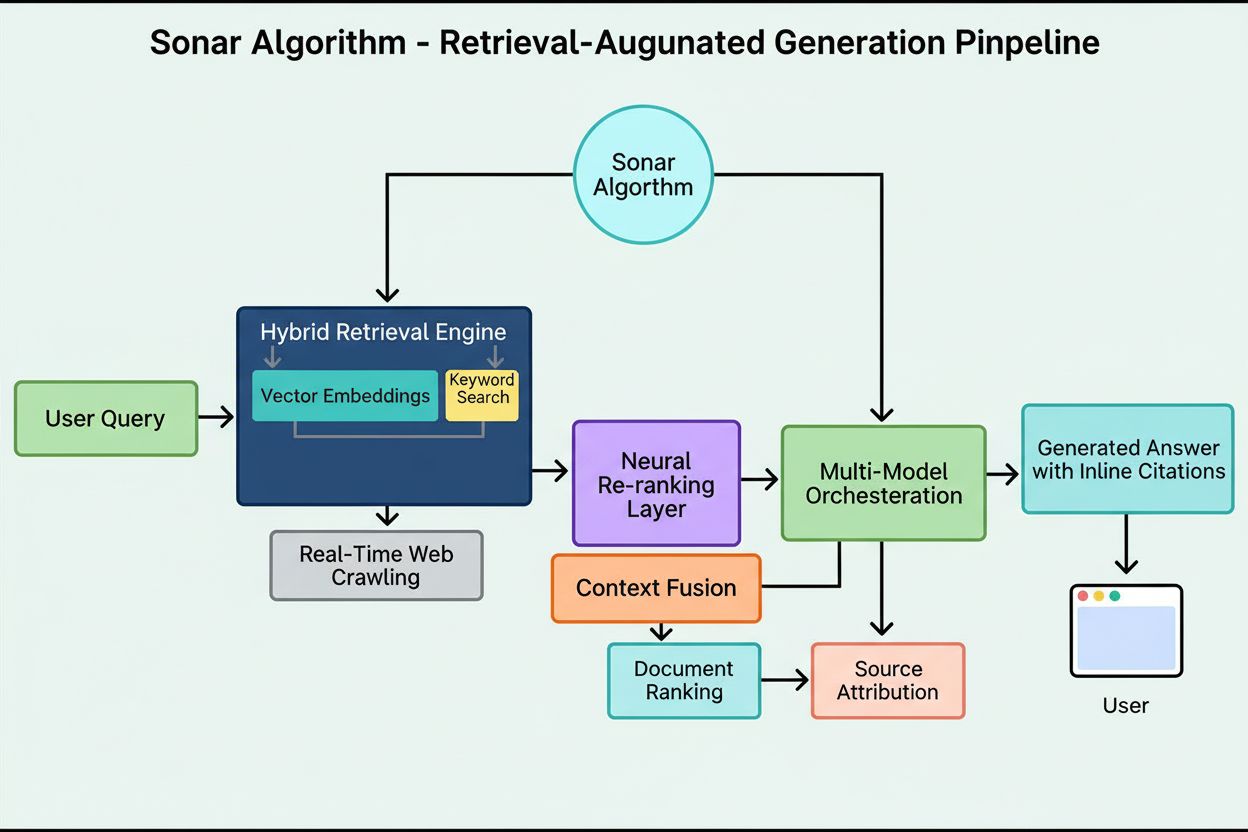
Sonars Rankingsystem arbeitet mit einer präzise orchestrierten fünfstufigen retrieval-augmented generation Pipeline, die Nutzeranfragen in fundierte, zitierte Antworten verwandelt. Die erste Stufe, Query Intent Parsing, nutzt ein LLM, um über simples Keyword-Matching hinauszugehen und die wahre Absicht des Nutzers semantisch zu erfassen, einschließlich Kontext, Nuancen und zugrunde liegender Intention. In der zweiten Stufe, Live Web Retrieval, wird die geparste Anfrage an Perplexitys massiven, verteilten Index auf Basis von Vespa AI gesendet, der das Web in Echtzeit nach relevanten Seiten und Dokumenten durchsucht. Dieses Retrievalsystem kombiniert Dense Retrieval (Vektorsuche mit semantischen Einbettungen) und Sparse Retrieval (lexikalische/keyword-basierte Suche) und verschmilzt die Ergebnisse zu etwa 50 vielfältigen Kandidatendokumenten. In der dritten Stufe, Snippet Extraction and Contextualization, wird nicht der volle Seitentext an das generative Modell übergeben, sondern Algorithmen extrahieren die relevantesten Schnipsel, Absätze oder Chunks, die sich direkt auf die Anfrage beziehen, und bündeln sie zu einem fokussierten Kontextfenster. Die vierte Stufe, Synthesized Answer Generation with Citations, übergibt diesen kuratierten Kontext an ein gewähltes LLM (aus Perplexitys proprietärer Sonar-Familie oder Fremdmodellen wie GPT-4 oder Claude), das eine natürliche Antwort ausschließlich auf Basis der abgerufenen Informationen generiert. Entscheidende Behauptungen werden mit Inline-Zitaten auf Quelldokumente verknüpft, was Transparenz und Überprüfbarkeit sicherstellt. Die fünfte Stufe, Conversational Refinement, hält den Konversationskontext über mehrere Runden hinweg, damit Folgefragen die Antworten durch wiederholte Websuchen verfeinern. Das Leitprinzip dieser Pipeline – “Du sollst nichts sagen, was du nicht abgerufen hast” – sorgt dafür, dass Sonar-Antworten stets in überprüfbaren Quellen verankert werden und Halluzinationen deutlich reduziert werden im Vergleich zu rein auf Trainingsdaten basierenden Modellen.
| Aspekt | Traditionelle Suche (Google) | Sonar-Algorithmus (Perplexity) | ChatGPT-Ranking | Gemini-Ranking | Claude-Ranking |
|---|---|---|---|---|---|
| Primäre Einheit | Gerankte Linkliste | Einzelne, synthetisierte Antwort mit Zitaten | Konsensbasierte Entitäten | E-E-A-T-ausgerichtete Inhalte | Neutrale, faktenbasierte Quellen |
| Suchfokus | Keywords, Links, ML-Signale | Hybride semantische + Keyword-Suche | Trainingsdaten + Web-Browsing | Wissensgraph-Integration | Konstitutionelle Sicherheitsfilter |
| Aktualitäts-Priorität | Query-deserves-freshness (QDF) | Echtzeit-Web-Abruf, 37 % Boost in 48h | Geringere Priorität, abhängig von Trainingsdaten | Moderat, in Google-Suche integriert | Geringere Priorität, Fokus auf Stabilität |
| Ranking-Signale | Backlinks, Domain-Autorität, CTR | Inhaltsaktualität, semantische Relevanz, Zitierfähigkeit, Autoritäts-Boosts | Entitätserkennung, Konsensnennungen | E-E-A-T, Konversationsausrichtung, strukturierte Daten | Transparenz, überprüfbare Zitate, Neutralität |
| Zitationsmechanismus | URL-Schnipsel in Ergebnissen | Inline-Zitate mit Quell-Links | Implizit, meist ohne Zitate | AI Overviews mit Attributierung | Explizite Quell-Attribution |
| Inhaltsdiversität | Mehrere Ergebnisse über Sites | Auswahl weniger Quellen für Synthese | Synthetisiert aus mehreren Quellen | Mehrere Quellen in Übersicht | Ausgewogene, neutrale Quellen |
| Personalisierung | Subtil, meist implizit | Explizite Fokussierungsmodi (Web, Akademisch, Finanzen, Schreiben, Social) | Implizit, konversationsbasiert | Implizit, abhängig vom Fragetyp | Minimal, Fokus auf Konsistenz |
| PDF-Handling | Standard-Indexierung | 22 % Zitationsvorteil gegenüber HTML | Standard-Indexierung | Standard-Indexierung | Standard-Indexierung |
| Schema-Markup-Effekt | FAQ-Schema in Featured Snippets | FAQ-Schema steigert Zitate um 41 %, reduziert Zeit-bis-Zitat um 6h | Minimaler direkter Einfluss | Moderater Einfluss auf Wissensgraph | Minimaler direkter Einfluss |
| Latenz-Optimierung | Millisekunden fürs Ranking | Sub-Sekunden-Retrieval + Generierung | Sekunden für Synthese | Sekunden für Synthese | Sekunden für Synthese |
Die technische Basis des Sonar-Algorithmus ist eine hybride Retrieval-Engine, die verschiedene Suchstrategien kombiniert, um sowohl Recall als auch Präzision zu maximieren. Dense Retrieval (Vektorsuche) nutzt semantische Einbettungen, um die konzeptionelle Bedeutung von Anfragen zu erfassen und kontextuell ähnliche Dokumente auch ohne exakte Keyword-Übereinstimmung zu finden. Hierzu werden transformerbasierte Einbettungen verwendet, die Anfragen und Dokumente in hochdimensionale Vektorräume abbilden, wo semantisch ähnliche Inhalte gruppiert sind. Sparse Retrieval (lexikalische Suche) ergänzt Dense Retrieval durch Präzision bei seltenen Begriffen, Produktnamen, internen IDs und spezifischen Entitäten, bei denen semantische Mehrdeutigkeit unerwünscht ist. Es kommen Ranking-Funktionen wie BM25 zum Einsatz, um diese kritischen Begriffe exakt abzugleichen. Beide Methoden werden zusammengeführt und dedupliziert, sodass etwa 50 vielfältige Kandidatendokumente entstehen, was Domain-Overfitting verhindert und breite Abdeckung über mehrere vertrauenswürdige Quellen sichert. Nach der ersten Auswahl bewertet Sonars neuronale Re-Ranking-Schicht die Kandidaten mittels fortschrittlicher ML-Modelle (wie DeBERTa-v3 Cross-Encoder) und berücksichtigt eine Vielzahl von Features: lexikalische Relevanz, Vektorsimilarität, Dokumentautorität, Aktualitätssignale, Nutzerinteraktion und Metadaten. Diese mehrphasige Architektur ermöglicht eine fortlaufende Verfeinerung der Ergebnisse unter engen Latenzbudgets und stellt sicher, dass das finale Ranking die qualitativ besten, relevantesten Quellen für die Synthese enthält. Die gesamte Retrieval-Infrastruktur basiert auf Vespa AI, einer verteilten Suchplattform, die Web-Indexierung im Milliardenmaßstab (200+ Mrd. URLs), Echtzeit-Updates (zehntausende pro Sekunde) und feingranulares Inhaltsverständnis durch Chunking unterstützt. Diese Architektur erlaubt es Perplexitys kleinem Engineering-Team, sich auf differenzierende Komponenten zu konzentrieren – RAG-Orchestrierung, Sonar-Modell-Finetuning und Inferenzoptimierung – statt Such-Infrastruktur neu zu erfinden.
Inhaltsaktualität ist eines der stärksten Rankingsignale von Sonar, wobei empirische Forschung zeigt, dass kürzlich aktualisierte Seiten deutlich höhere Zitierquoten erreichen. In kontrollierten A/B-Tests über 24 Wochen mit 120 URLs wurden Artikel, die innerhalb der letzten 48 Stunden aktualisiert waren, 37 % häufiger zitiert als identische Inhalte mit älterem Zeitstempel. Der Vorteil hielt nach zwei Wochen mit rund 14 % an, was einen anhaltenden, aber allmählich abnehmenden Boost zeigt. Der Mechanismus hinter dieser Priorisierung liegt in Sonars Designphilosophie: Der Algorithmus betrachtet veraltete Inhalte als höheres Halluzinationsrisiko und geht davon aus, dass überholte Informationen durch neue Entwicklungen ersetzt wurden. Die Infrastruktur von Perplexity verarbeitet zehntausende Index-Update-Anfragen pro Sekunde und ermöglicht so Echtzeit-Aktualitätssignale. Ein ML-Modell prognostiziert, ob eine URL neu indexiert werden sollte und plant Updates nach Seitenbedeutung und historischer Änderungsfrequenz, sodass hochwertige Inhalte aggressiver aktualisiert werden. Selbst kleine kosmetische Änderungen setzen die Aktualitätsuhr zurück, sofern das CMS den Zeitstempel neu veröffentlicht. Für Publisher schafft das einen strategischen Imperativ: Entweder einen Newsroom-Rhythmus mit wöchentlichen oder täglichen Updates etablieren – oder zusehen, wie Evergreen-Inhalte in der Sichtbarkeit allmählich abfallen. Das ist tiefgreifend – im Sonar-Zeitalter ist Content Velocity kein Eitelkeitswert, sondern ein Überlebensmechanismus. Marken, die wöchentliche Mikro-Updates automatisieren, Live-Changelogs führen oder kontinuierliche Optimierungs-Workflows pflegen, sichern sich einen überproportionalen Zitationsanteil gegenüber Wettbewerbern mit statischen, selten gepflegten Seiten.
Sonar priorisiert semantische Relevanz gegenüber Keyword-Dichte und belohnt Inhalte, die Nutzerfragen direkt und in natürlicher Sprache beantworten. Das Retrievalsystem verwendet dichte Vektoreinbettungen zur konzeptionellen Abgleichung von Anfragen und Inhalten, sodass Seiten mit Synonymen, verwandten Begriffen oder kontextreicheren Formulierungen Keyword-stuffed-Seiten ohne Tiefgang übertreffen können. Dieser Wandel hin zu bedeutungszentriertem Ranking hat große Auswirkungen auf Content-Strategien. Erfolgreiche Sonar-Inhalte haben eine typische Struktur: Sie beginnen mit einer kurzen, faktenbasierten Zusammenfassung, nutzen aussagekräftige H2/H3-Überschriften und kurze Absätze für einfache Extraktion, enthalten klare Zitate und Links zu Primärquellen und zeigen sichtbare Zeitstempel und Versionshinweise für Aktualitätssignale. Jeder Absatz ist eine atomare semantische Einheit, optimiert für Copy-Paste-Klarheit und LLM-Verständnis. Tabellen, Aufzählungen und beschriftete Diagramme sind besonders wertvoll, da sie Informationen strukturiert und leicht zitierbar präsentieren. Der Algorithmus belohnt zudem eigene Analysen und originäre Daten statt bloßer Aggregation, da Sonars Synthese-Engine nach Quellen sucht, die neue Blickwinkel, Primärdokumente oder proprietäre Einblicke bieten. Dieses Bekenntnis zu semantischem Reichtum und Answer-First-Struktur markiert einen fundamentalen Bruch mit klassischem SEO, wo Keyword-Platzierung und Linkautorität dominierten. Im Sonar-Zeitalter muss Inhalt für maschinellen Abruf und Synthese statt menschliches Browsen entwickelt werden.
Öffentlich gehostete PDFs sind ein bedeutender, oft unterschätzter Vorteil im Sonar-Rankingsystem, wie empirische Tests zeigen: PDF-Versionen werden etwa 22 % häufiger zitiert als HTML-Äquivalente. Dieser Vorteil entsteht, weil Sonars Crawler PDFs bevorzugt gegenüber HTML-Seiten behandelt. PDFs haben keine Cookie-Banner, benötigen kein JavaScript-Rendering, umgehen Paywalls und andere HTML-Komplikationen, die den Zugriff verzögern oder erschweren. Sonars Crawler kann PDFs klar und vorhersagbar auslesen, ohne die Parsing-Probleme komplexer HTML-Strukturen. Publisher können diesen Vorteil nutzen, indem sie PDFs in öffentlich zugänglichen Verzeichnissen hosten, semantische Dateinamen wählen und mittels <link rel="alternate" type="application/pdf">-Tag im HTML-Head als kanonisch auszeichnen. Das schafft, was Forscher als “LLM honey-trap” bezeichnen – ein hochsichtbares Asset, das von Konkurrenz-Tracking-Skripten kaum erkannt oder überwacht werden kann. Für B2B-Unternehmen, SaaS-Anbieter und forschungsgetriebene Organisationen ist diese Strategie besonders wirksam: Whitepaper, Studien, Fallbeispiele oder technische Dokumentation als PDF zu veröffentlichen, steigert Sonar-Zitationsraten erheblich. Entscheidend ist, das PDF nicht als nachrangigen Download zu behandeln, sondern als kanonische Kopie, die mindestens gleichwertig (oder besser) optimiert wird wie die HTML-Version. Besonders im Enterprise-Bereich hat sich dieser Ansatz bewährt, da PDFs oft strukturiertere, autoritativere Informationen enthalten als Webseiten.
JSON-LD-FAQ-Schema-Markup verstärkt die Sonar-Zitierhäufigkeit signifikant, mit Seiten, die drei oder mehr FAQ-Blöcke enthalten, werden 41 % häufiger zitiert als Kontrollseiten ohne Schema. Dieser deutliche Anstieg spiegelt Sonars Präferenz für strukturierte, chunk-basierte Inhalte wider, die zu seiner Retrieval- und Syntheselogik passen. FAQ-Schema präsentiert diskrete, eigenständige Q&A-Einheiten, die der Algorithmus leicht extrahieren, ranken und als atomare semantische Blöcke zitieren kann. Anders als im klassischen SEO, wo FAQ-Schema ein „Nice-to-have“ war, ist es bei Sonar ein zentraler Ranking-Hebel. Zudem zitiert Sonar häufig FAQ-Fragen als Ankertext, wodurch das Risiko von Kontextverlust sinkt, das bei der LLM-Zusammenfassung zufälliger Satzteile auftreten kann. Das Schema beschleunigt außerdem die Zeit bis zur ersten Zitierung um etwa sechs Stunden, was nahelegt, dass Sonars Parser strukturierte Q&A-Blöcke im Rankingprozess frühzeitig priorisiert. Für Publisher ist die Strategie klar: Drei bis fünf gezielte FAQ-Blöcke unterhalb des Folds einbetten, die mit Konversations-Trigger-Phrasen echte Nutzerfragen spiegeln. Die Fragen sollten Longtail-Suchphrasen und semantische Symmetrie mit wahrscheinlichen Sonar-Anfragen aufweisen. Jede Antwort sollte prägnant, faktenbasiert und direkt beantwortend sein – ohne Floskeln oder Marketingtexte. Besonders effektiv ist dieser Ansatz für SaaS-Anbieter, Gesundheitsdienstleister und beratende Unternehmen, wo FAQ-Inhalte natürlich auf Nutzerintention und Sonars Synthesebedarf einzahlen.
Sonars Rankingsystem integriert viele Signale in ein einheitliches Zitations-Framework, wobei Forschung acht Hauptfaktoren identifiziert, die Quellenauswahl und Zitierfrequenz beeinflussen. Erstens dominiert semantische Relevanz zur Frage das Retrieval, mit Priorisierung von Inhalten, die die Anfrage in natürlicher Sprache klar beantworten. Zweitens sind Autorität und Glaubwürdigkeit maßgeblich, wobei Partnerschaften mit Publishern und algorithmische Boosts etablierte Nachrichtenquellen, akademische Institutionen und Experten bevorzugen. Drittens erhält Aktualität besonderes Gewicht – wie beschrieben, mit 37 % Zitat-Plus bei jüngsten Updates. Viertens werden Diversität und Abdeckung geschätzt, da Sonar mehrere hochwertige Quellen für Kreuzvalidierung bevorzugt und so Halluzinationsrisiken senkt. Fünftens bestimmen Modus und Scope, welche Indizes Sonar durchsucht – Fokusmodi wie Academic, Finance, Writing und Social schränken Quelltypen ein, während Source-Selectoren (Web, Org Files, Web + Org Files, None) festlegen, ob offen aus dem Web, aus internen Dokumenten oder beiden abgerufen wird. Sechstens sind Zitierfähigkeit und Zugänglichkeit entscheidend: Kann PerplexityBot crawlen und indexieren, ist Zitation leichter – robots.txt-Konformität und Pagespeed sind daher wichtig. Siebtens ermöglichen Custom-Source-Filter via API in Enterprise-Setups, bestimmte Domains zu bevorzugen oder zu beschränken, was das Ranking in Whitelist-Collections beeinflusst. Achtens beeinflusst der Gesprächskontext Folgefragen: Seiten, die die sich wandelnde Intention besser treffen, überragen generische Referenzen. Zusammengenommen entsteht so ein multidimensionaler Rankingraum, der Optimierung auf mehreren Ebenen erfordert – nicht nur an einer Stellschraube wie Backlinks oder Keyword-Dichte.
Der Sonar-Algorithmus entwickelt sich rasant weiter – angetrieben durch Fortschritte in LLM-Inferenz und Retrieval-Technologie. Im Engineering-Blog von Perplexity wurde kürzlich über spekulatives Decoding berichtet, eine Technik, die Token-Latenz halbiert, indem mehrere Folgetoken gleichzeitig vorausgesagt werden. Schnellere Generierungsschleifen erlauben frischere Retrieval-Sets bei jeder Anfrage, wodurch das Zeitfenster für veraltete Seiten schrumpft. Ein angeblich bereits existierendes Sonar-Reasoning-Pro-Modell übertrifft Gemini 2.0 Flash und GPT-4o Search in Arena-Tests, was auf einen weiteren Sprung in der Rankingsophistikation hindeutet. Je näher die Latenz menschlicher Denkgeschwindigkeit kommt, wird Zitationswettbewerb zum Hochfrequenzspiel, bei dem Content Velocity zum ultimativen Differenzierungsmerkmal wird. Zu erwarten sind neue Infrastruktur-Innovationen wie „LLM Freshness APIs“, die Zeitstempel so automatisch anpassen, wie Adtech einst Gebotspreise automatisierte – mit neuen Wettbewerbsdynamiken rund um Echtzeit-Updates. Auch rechtliche und ethische Herausforderungen zeichnen sich ab, wenn PDF-Piraten Sonars PDF-Präferenz ausnutzen, um Autorität von geschützten E-Books und Forschungsarbeiten abzugreifen, was zu neuen Zugangskontrollen oder Authentifizierungsanforderungen führen kann. Die größere Implikation ist klar: Das Sonar-Zeitalter belohnt Publisher, die jede Absatz als atomare, schema-umhüllte, gestempelte Manifestation für maschinellen Konsum verstehen. Marken, die nur auf Google-Rankings achten, aber Sonar-Sichtbarkeit ignorieren, hängen Plakate in einer Stadt auf, deren Bewohner gerade VR-Brillen bekommen haben. Die Zukunft gehört denen, die für den „Prozentsatz unserer URL in Antwortboxen“ statt für klassische CTR-Metriken optimieren.
Der Sonar-Algorithmus stellt eine grundlegende Neuerfindung dar, wie Rankingsysteme im Zeitalter KI-gestützter Antwortmaschinen Inhalte bewerten und priorisieren. Durch die Kombination aus hybrider Suche, neuronaler Neubewertung, Echtzeit-Aktualitätssignalen und strengen Zitationsanforderungen schafft Sonar ein Ranking-Umfeld, in dem klassische SEO-Signale wie Backlinks und Keyword-Dichte weit weniger zählen als semantische Relevanz, Aktualität und Zitierfähigkeit. Der Fokus des Algorithmus auf die Fundierung von Antworten in überprüfbaren Quellen adressiert eines der zentralen Probleme generativer KI – Halluzinationen – durch das strikte Prinzip, dass LLMs nichts behaupten dürfen, was sie nicht abgerufen haben. Für Publisher und Marken ist das Verständnis von Sonars Rankingfaktoren nicht mehr optional, sondern unverzichtbar, um Sichtbarkeit in einer zunehmend KI-vermittelten Informationslandschaft zu sichern. Der Wandel von linkbasierter Autorität zu nutzungsorientierten Metriken erfordert ein Umdenken bei Content-Strategien: weg von Keyword-Optimierung hin zu semantischem Reichtum, von statischen Seiten hin zu kontinuierlich aktualisierten Assets und von menschzentriertem Design hin zu maschinenlesbarer Struktur. Mit wachsendem Marktanteil von Perplexity und der Einführung ähnlicher RAG-Architekturen durch konkurrierende KI-Antwortsysteme wird Sonars Einfluss weiter zunehmen. Erfolgreich werden die Marken sein, die Sonar nicht als Bedrohung für klassisches SEO, sondern als ergänzendes Rankingsystem mit eigenen Optimierungsstrategien begreifen. Wer Inhalte als atomare, gestempelte, schema-konforme Einheiten für maschinelles Retrieval und Synthese behandelt, sichert sich seinen Platz in den KI-Antwortboxen, die zunehmend bestimmen, wie Nutzer Informationen online finden und konsumieren.
Der **Sonar-Algorithmus** ist Perplexitys proprietäres Rankingsystem, das seine Antwortmaschine antreibt und sich grundlegend von traditionellen Suchmaschinen wie Google unterscheidet. Während Google Seiten für die Anzeige in einer Liste von blauen Links einstuft, bewertet Sonar Inhaltsschnipsel zur Synthese einer einzigen, einheitlichen Antwort mit Inline-Zitaten. Sonar verwendet retrieval-augmented generation (RAG), das hybride Suche (Vektoreinbettungen plus Keyword-Matching), neuronales Re-Ranking und Echtzeit-Webabruf kombiniert, um Antworten auf überprüfbare Quellen zu stützen. Dieser Ansatz priorisiert semantische Relevanz und Aktualität gegenüber klassischen SEO-Signalen wie Backlinks und ist somit ein eigenständiges Ranking-Paradigma, das auf KI-generierte Synthese statt auf linkbasierte Autorität optimiert ist.
Sonar implementiert eine **hybride Retrieval-Engine**, die zwei komplementäre Suchstrategien kombiniert: Dense Retrieval (Vektorsuche mit semantischen Einbettungen) und Sparse Retrieval (lexikalische/keyword-basierte Suche mit BM25). Dense Retrieval erfasst konzeptionelle Bedeutung und Kontext, sodass das System semantisch ähnliche Inhalte auch ohne exakte Keyword-Übereinstimmung findet. Sparse Retrieval bietet Präzision für seltene Begriffe, Produktnamen und spezifische Kennungen, bei denen semantische Mehrdeutigkeiten unerwünscht sind. Diese beiden Methoden werden zusammengeführt und dedupliziert, sodass etwa 50 vielfältige Kandidatendokumente entstehen, was Domain-Overfitting verhindert und für breite Abdeckung sorgt. Dieser hybride Ansatz übertrifft Einzelmethodensysteme sowohl bei Recall als auch bei Relevanzgenauigkeit.
Die wichtigsten Rankingfaktoren für Sonar sind: (1) **Inhaltsaktualität** – kürzlich aktualisierte oder veröffentlichte Seiten erhalten innerhalb von 48 Stunden nach dem Update 37 % mehr Zitate; (2) **Semantische Relevanz** – Inhalte müssen die Anfrage in natürlicher Sprache direkt beantworten und Klarheit über Keyword-Dichte stellen; (3) **Autorität und Glaubwürdigkeit** – Quellen etablierter Verlage, akademischer Institutionen und Nachrichtenorganisationen erhalten algorithmische Vorteile; (4) **Zitierfähigkeit** – Inhalte müssen leicht zitierbar und mit klaren Überschriften, Tabellen und Absätzen strukturiert sein; (5) **Diversität** – Sonar bevorzugt mehrere hochwertige Quellen gegenüber Ein-Quellen-Antworten; und (6) **Technische Zugänglichkeit** – Seiten müssen für den PerplexityBot crawlbar und für On-Demand-Browsing schnell ladbar sein.
**Aktualität ist eines der wichtigsten Ranking-Signale von Sonar**, insbesondere bei zeitkritischen Themen. Die Infrastruktur von Perplexity verarbeitet zehntausende Index-Update-Anfragen pro Sekunde, um den Index stets auf dem neuesten Stand zu halten. Ein ML-Modell prognostiziert, ob eine URL neu indexiert werden muss, und plant Updates basierend auf Bedeutung und Änderungsfrequenz der Seite. In empirischen Tests erhielten Inhalte, die innerhalb der letzten 48 Stunden aktualisiert wurden, 37 % mehr Zitate als identische Inhalte mit älteren Zeitstempeln; dieser Vorteil hielt auch nach zwei Wochen mit 14 % an. Selbst kleinere Anpassungen setzen die Aktualitätsuhr zurück, wodurch kontinuierliche Inhaltsoptimierung entscheidend ist, um Sichtbarkeit in Sonar-gesteuerten Antworten zu erhalten.
**PDFs sind ein erheblicher Vorteil im Sonar-Rankingsystem** und übertreffen HTML-Versionen desselben Inhalts bei der Zitationshäufigkeit oft um 22 %. Der Crawler von Sonar behandelt PDFs bevorzugt, da sie keine Cookie-Banner, Paywalls, JavaScript-Rendering-Probleme und andere HTML-Komplikationen aufweisen, die Inhalte verdecken können. Publisher können die Sichtbarkeit von PDFs optimieren, indem sie sie in öffentlich zugänglichen Verzeichnissen hosten, semantische Dateinamen verwenden und die PDF als kanonisch mit ``-Tags im HTML-Head kennzeichnen. Das schafft, was Forscher als "LLM honey-trap" bezeichnen – eine Falle, die von Konkurrenz-Tracking-Skripten kaum erkannt wird, wodurch PDFs ein strategischer Vorteil zur Sicherung von Sonar-Zitaten sind.
**JSON-LD-FAQ-Schema steigert die Sonar-Zitathäufigkeit signifikant**, wobei Seiten mit drei oder mehr FAQ-Blöcken 41 % häufiger zitiert werden als Kontrollseiten ohne Schema. Das FAQ-Markup passt perfekt zur Chunk-basierten Retrieval-Logik von Sonar, weil es diskrete, eigenständige Q&A-Einheiten präsentiert, die der Algorithmus leicht extrahieren und zitieren kann. Zudem zitiert Sonar oft FAQ-Fragen als Ankertext, wodurch das Risiko von Kontextverlust reduziert wird, das auftreten kann, wenn das LLM zufällige Satzteile aus Absätzen zusammenfasst. Das Schema beschleunigt außerdem die Zeit bis zur ersten Zitierung um etwa sechs Stunden, was darauf hindeutet, dass Sonars Parser strukturierte Q&A-Blöcke frühzeitig im Rankingprozess priorisiert.
Sonar implementiert eine **dreistufige retrieval-augmented generation (RAG) Pipeline**, die Antworten in verifiziertem externem Wissen verankert. In Stufe eins werden relevante Dokumente mit hybrider Suche abgerufen; Stufe zwei extrahiert und kontextualisiert die relevantesten Schnipsel; Stufe drei synthetisiert eine Antwort ausschließlich aus dem bereitgestellten Kontext und erzwingt das strikte Prinzip: "Du sollst nichts sagen, was du nicht abgerufen hast." Diese Architektur koppelt Retrieval und Generierung eng, sodass jede Aussage auf eine Quelle zurückgeführt werden kann. Inline-Zitate verlinken den generierten Text zurück zu Quelldokumenten und ermöglichen Benutzerüberprüfung. Dieser Verankerungsansatz reduziert Halluzinationen deutlich im Vergleich zu Modellen, die sich ausschließlich auf Trainingsdaten stützen, und macht Sonars Antworten deutlich zuverlässiger und vertrauenswürdiger.
Während **ChatGPT Entitätserkennung und Konsens aus Trainingsdaten priorisiert**, **setzt Gemini auf E-E-A-T-Signale und Konversationsausrichtung**, und **Claude fokussiert sich auf konstitutionelle Sicherheit und Neutralität**, **legt Sonar einzigartig Wert auf Echtzeit-Aktualität und semantische Tiefe**. Sonars dreistufiger ML-Reranker legt strengere Qualitätsfilter an als traditionelle Suche und verwirft ganze Ergebnislisten, wenn Inhalte Qualitätsanforderungen nicht erfüllen. Anders als ChatGPT, das auf historische Trainingsdaten setzt, ruft Sonar für jede Anfrage live das Web ab, sodass Antworten stets aktuell sind. Sonar unterscheidet sich auch von Geminis Wissensgraph-Integration durch die Betonung semantischer Relevanz auf Absatzebene und von Claudes Neutralitätsfokus durch die Akzeptanz autoritativer Domain-Boosts etablierter Publisher.
Beginnen Sie zu verfolgen, wie KI-Chatbots Ihre Marke auf ChatGPT, Perplexity und anderen Plattformen erwähnen. Erhalten Sie umsetzbare Erkenntnisse zur Verbesserung Ihrer KI-Präsenz.
Erfahren Sie, wie Perplexitys Sonar-Algorithmus die Echtzeit-KI-Suche mit kostengünstigen Modellen antreibt. Entdecken Sie die Varianten Sonar, Sonar Pro und So...
RankBrain ist Googles KI-gestütztes System für maschinelles Lernen, das Suchintentionen interpretiert und Suchergebnisse platziert. Erfahren Sie, wie dieser zen...
Erfahren Sie, wie das RankBrain-KI-System von Google Suchrankings durch semantisches Verständnis, Interpretation der Nutzerintention und Algorithmen für maschin...