
Strukturierte Daten
Strukturierte Daten sind standardisiertes Markup, das Suchmaschinen hilft, Webseiteninhalte zu verstehen. Erfahren Sie, wie JSON-LD, schema.org und microdata SE...
9 Min. Lesezeit

Schema-Markup, das speziell entwickelt wurde, um KI-Systemen zu helfen, Inhalte genau zu verstehen und zu zitieren. Strukturierte Daten verwenden standardisierte Formate wie JSON-LD, um expliziten Kontext zu Seiteninhalten bereitzustellen. So können große Sprachmodelle Informationen zuverlässiger analysieren und Quellen mit größerer Sicherheit zitieren.
Schema-Markup, das speziell entwickelt wurde, um KI-Systemen zu helfen, Inhalte genau zu verstehen und zu zitieren. Strukturierte Daten verwenden standardisierte Formate wie JSON-LD, um expliziten Kontext zu Seiteninhalten bereitzustellen. So können große Sprachmodelle Informationen zuverlässiger analysieren und Quellen mit größerer Sicherheit zitieren.
Strukturierte Daten für KI bezeichnen organisierte, maschinenlesbare Informationen, die nach standardisierten Schemata formatiert sind und es künstlichen Intelligenzsystemen ermöglichen, Inhalte präzise zu verstehen, zu interpretieren und zu nutzen. Im Gegensatz zu unstrukturiertem Text, der komplexe Sprachverarbeitung zur Sinnentnahme erfordert, liefern strukturierte Daten expliziten Kontext darüber, welche Informationen dargestellt werden. Diese Klarheit ist entscheidend, da KI-Systeme – insbesondere große Sprachmodelle und Suchmaschinen – täglich Milliarden von Datenpunkten verarbeiten. Wenn Inhalte nach Standards wie schema.org, JSON-LD oder Microdata strukturiert werden, kann KI sofort Entitäten, Beziehungen und Attribute eindeutig erkennen. Dieser strukturierte Ansatz liefert eine um 300 % höhere Genauigkeit beim KI-Verständnis im Vergleich zu unstrukturierten Alternativen. Für Organisationen, die Sichtbarkeit in AI Overviews und anderen KI-generierten Ergebnissen anstreben, sind strukturierte Daten zur unverzichtbaren Infrastruktur geworden. Sie verwandeln rohe Inhalte in eine Intelligenz, die KI-Systeme selbstbewusst zitieren, referenzieren und in ihre Antworten einbinden können – und verändern grundlegend, wie digitale Inhalte im KI-getriebenen Umfeld auffindbar werden.

KI-Systeme verarbeiten strukturierte Daten über eine ausgefeilte Pipeline, die markierte Inhalte in umsetzbare Intelligenz umwandelt. Wenn eine KI auf korrekt formatierte strukturierte Daten trifft, kann sie Schlüsselinformationen sofort extrahieren – ohne den rechnerischen Aufwand, der für natürliche Sprachinterpretation notwendig wäre. Der technische Mechanismus umfasst diese wesentlichen Schritte:
Dieser Prozess ermöglicht KIs, bei korrekt strukturierten Inhalten eine über 30 % höhere Sichtbarkeit in AI Overviews zu erzielen. Der strukturierte Ansatz senkt das Risiko von Halluzinationen, da KI-Antworten auf expliziten, überprüfbaren Daten statt auf probabilistischer Textgenerierung basieren. Organisationen mit umfassender Strategie für strukturierte Daten verzeichnen messbare Verbesserungen darin, wie KI-Systeme ihre Inhalte über verschiedene Plattformen und Anwendungen hinweg entdecken, verstehen und fördern.
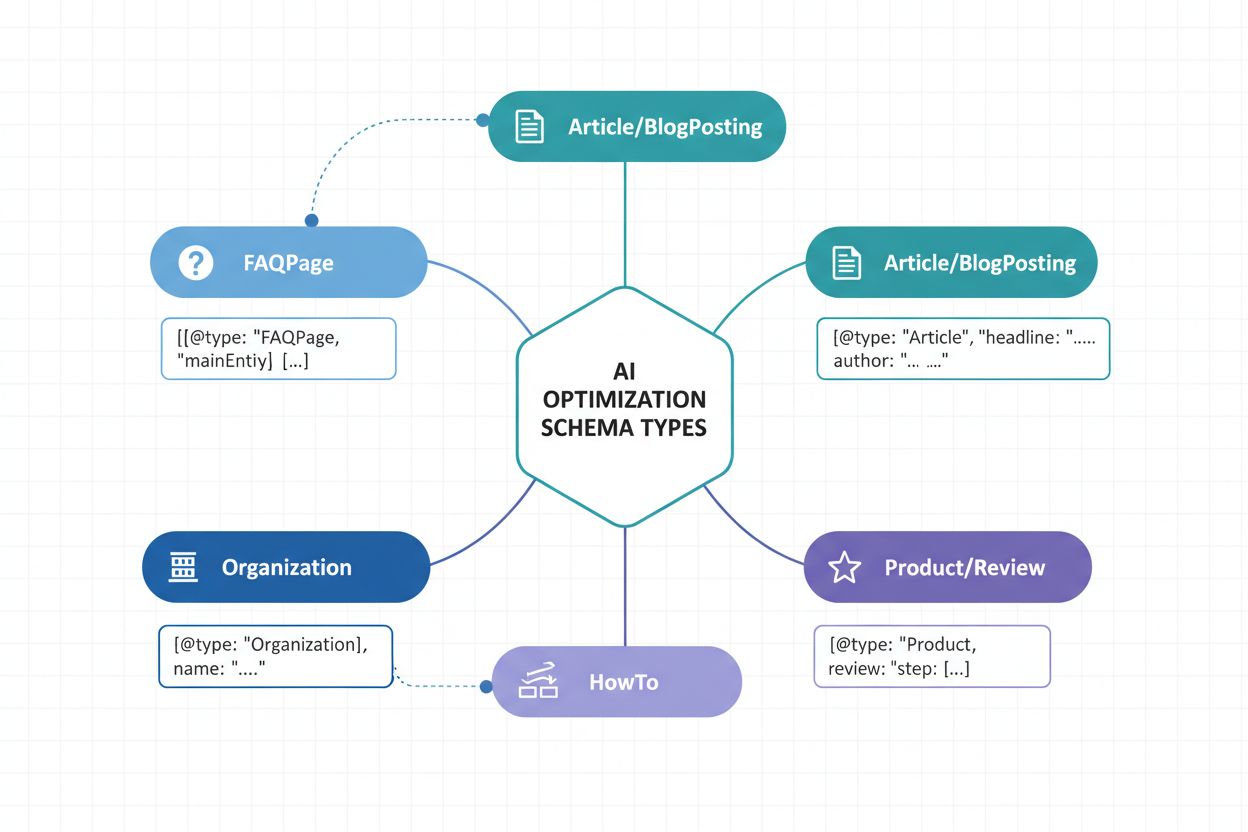
Die Implementierung der richtigen Schema-Typen ist grundlegend für jede KI-Sichtbarkeitsstrategie. Verschiedene Inhaltstypen benötigen spezifisches strukturiertes Markup, um KI-Systemen ihre Art und ihren Wert zu vermitteln. Hier die wichtigsten Schema-Typen zur Maximierung der KI-Erkennung:
Article Schema – Markiert Nachrichtenartikel, Blogposts und Longform-Inhalte mit Überschrift, Autor, Veröffentlichungsdatum und Text. Kritisch für KI-Systeme, um autoritative Inhaltsquellen zu identifizieren und Publikationsglaubwürdigkeit herzustellen.
Organization Schema – Definiert die Unternehmensidentität, inklusive Name, Logo, Kontaktinformationen und Social-Media-Profile. Ermöglicht KI, organisatorische Inhalte korrekt zu erkennen und zuzuordnen.
Product Schema – Strukturiert Produktinformationen wie Name, Beschreibung, Preis, Verfügbarkeit und Bewertungen. Essenziell für E-Commerce-Sichtbarkeit in KI-Shopping-Assistenten und Produktempfehlungssystemen.
LocalBusiness Schema – Markiert Geschäftsstandort, Öffnungszeiten, Kontaktdaten und Dienstleistungen. Unverzichtbar für lokale KI-Anfragen und standortbasierte AI Overviews, die die Suchergebnisse zunehmend dominieren.
BreadcrumbList Schema – Definiert die Navigationshierarchie der Website und hilft KI, die Struktur und Beziehungen zwischen Seiten innerhalb Ihrer Informationsarchitektur zu verstehen.
FAQPage Schema – Strukturiert häufig gestellte Fragen mit Antworten und ermöglicht KI-Systemen, spezifische Q&A-Inhalte direkt zu extrahieren und zu zitieren.
NewsArticle und BlogPosting Schemata – Spezialisierte Artikel-Typen, die KI-Systemen die Inhaltskategorie signalisieren und die Kategorisierungsgenauigkeit sowie das Relevanz-Matching verbessern.
Event Schema – Markiert Veranstaltungsdetails wie Datum, Ort, Beschreibung und Anmeldeinformationen – essenziell für KI-Event-Discovery und Kalenderintegration.
Derzeit nutzen 45 Millionen Domains schema.org-Markup, was 12,4 % aller Domains weltweit entspricht. Organisationen, die mehrere Schema-Typen gleichzeitig implementieren, profitieren von einer kumulierten Sichtbarkeit, da KI-Systeme einen reicheren Kontext zu ihrem Content-Ökosystem erhalten.
Erfolgreiche Implementierung strukturierter Daten erfordert strategische Planung und technische Präzision. Organisationen sollten diese bewährten Praktiken befolgen, um die KI-Sichtbarkeit zu maximieren und die Datenqualität zu sichern:
Hier ein praktisches JSON-LD-Beispiel für einen Artikel:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Strukturierte Daten für KI: Strategischer Implementierungsleitfaden",
"author": {
"@type": "Person",
"name": "Content Author"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Full article text here...",
"publisher": {
"@type": "Organization",
"name": "Your Organization",
"logo": "https://example.com/logo.png"
}
}
Korrekte Implementierung liefert eine 35%ige Steigerung der Klickrate durch Rich Results in der klassischen Suche, mit weiteren Vorteilen, sobald AI Overviews zum primären Discovery-Kanal werden. Unternehmen, die ihre Performance strukturierter Daten mit Lösungen wie AmICited.com überwachen, erhalten einen Wettbewerbsvorteil, indem sie erkennen, welche Inhaltstypen und Schema-Implementierungen die höchste KI-Sichtbarkeit bringen.
Sowohl strukturierte Daten als auch llms.txt dienen der KI-Auffindbarkeit, funktionieren jedoch grundlegend unterschiedlich. Strukturierte Daten verwenden standardisierte Schemata (schema.org, JSON-LD), die im HTML eingebettet sind und einzelne Inhaltselemente mit expliziter semantischer Bedeutung auszeichnen. Dieser Ansatz integriert sich direkt in Webseiten und macht Informationen sofort für Suchmaschinen und KI-Systeme während des Crawlings verfügbar. Strukturierte Daten ermöglichen eine granulare Auszeichnung einzelner Artikel, Produkte, Events und Organisationen, sodass KI Beziehungen und Attribute präzise versteht.
llms.txt hingegen ist eine Textdatei im Root-Verzeichnis der Website mit Anweisungen und Richtlinien für große Sprachmodelle. Sie fungiert als Manifestdatei und vermittelt Präferenzen darüber, wie KI-Systeme Ihre Inhalte nutzen und zitieren dürfen. Während llms.txt grundlegende Hinweise zu Nutzungsrechten und Zitationspräferenzen gibt, fehlt ihr die semantische Präzision strukturierter Daten. Strukturierte Daten beantworten „Was ist dieser Inhalt?“ mit expliziten, maschinenlesbaren Informationen, während llms.txt „Wie sollst du diesen Inhalt nutzen?“ als Richtlinie beantwortet.
Am effektivsten ist die Kombination beider Ansätze: Strukturierte Daten sorgen dafür, dass KI-Systeme Ihre Inhalte korrekt verstehen und zitieren können, während llms.txt klare Nutzungs- und Zitationsregeln definiert. Organisationen, die beides einsetzen, erscheinen 36 % häufiger in KI-generierten Zusammenfassungen als solche, die keinen dieser Ansätze nutzen. Strukturierte Daten bilden das Fundament für das KI-Verständnis, llms.txt bietet das Governance-Framework für korrekte Attribution und Nutzungs-Compliance.
Die Wirksamkeit strukturierter Daten lässt sich durch spezifische Metriken messen, die zeigen, wie KI-Systeme Ihre Inhalte entdecken, verstehen und zitieren. Organisationen sollten diese Key Performance Indicators überwachen:
AmICited.com bietet spezialisiertes Monitoring für die KI-Zitations-Performance und ermöglicht es Unternehmen, nachzuvollziehen, wie sich ihre Investitionen in strukturierte Daten in tatsächliche KI-Sichtbarkeit und Attribution umsetzen. Die Plattform zeigt, welche Inhalte KI-Zitationen erhalten, welche Queries Ihre Inhalte auslösen und wie Ihre Zitationshäufigkeit im Branchenvergleich steht. Dieser datengetriebene Ansatz macht aus der Implementierung strukturierter Daten einen messbaren Geschäftsvorteil.
Organisationen mit einer umfassenden Strategie für strukturierte Daten berichten, dass 93 % der durch KI beantworteten Suchanfragen ohne Klicks ablaufen – Zitationssichtbarkeit wird damit zum entscheidenden Faktor für Traffic. Die Messung der Zitations-Performance stellt sicher, dass Investitionen in strukturierte Daten messbare Rendite durch bessere KI-Auffindbarkeit und Markenattribution bringen.
Erfolgreiche Implementierung strukturierter Daten folgt einem gestuften Ansatz, der die Fähigkeiten schrittweise aufbaut und in jeder Phase messbaren Mehrwert liefert. Organisationen sollten ihren Implementierungszeitplan wie folgt strukturieren:
Phase 1: Fundament (Monate 1–2)
Phase 2: Ausbau (Monate 3–4)
Phase 3: Optimierung (Monate 5–6)
Phase 4: Strategische Integration (Monat 7+)
Dieser Zeitplan ermöglicht es Unternehmen, bereits innerhalb von 2–3 Monaten spürbare Verbesserungen bei der KI-Sichtbarkeit zu erzielen und langfristig eine umfassende, skalierbare Infrastruktur für strukturierte Daten aufzubauen. Frühe Anwender dieses Ansatzes sichern sich Wettbewerbsvorteile, wenn AI Overviews zur wichtigsten Traffic-Quelle werden.
Strukturierte Daten haben sich von einer optionalen SEO-Maßnahme zu einer essenziellen strategischen Infrastruktur in einer KI-getriebenen digitalen Welt entwickelt. Da KI-Systeme zunehmend vermitteln, wie Nutzer Informationen entdecken, sind Organisationen ohne umfassendes strukturiertes Markup systematisch im Nachteil. Der Wandel spiegelt grundlegende Veränderungen im Informationsfluss wider: Früher mussten Nutzer für Informationen auf Websites klicken, heute beantworten AI Overviews Fragen direkt – Zitationssichtbarkeit ist das neue Wettbewerbsfeld.
Organisationen, die strukturierte Daten strategisch implementieren, positionieren sich langfristig erfolgreich auf mehreren KI-Plattformen und neuen Discovery-Kanälen. Die Infrastrukturinvestition zahlt sich weit über die unmittelbare KI-Sichtbarkeit hinaus aus: Strukturierte Daten verbessern das interne Content-Management, ermöglichen bessere Personalisierung, unterstützen Voice Search-Optimierung und schaffen Daten-Assets für zukünftige KI-Anwendungen. Frühzeitige, umfassende Implementierung bringt kumulative Vorteile, da KI-Systeme künftig immer stärker auf gut markierte Inhalte setzen.
Der Wettbewerbsvorteil des frühen Handelns ist nicht zu unterschätzen. Je mehr Organisationen die Bedeutung strukturierter Daten erkennen, desto mehr wird ihre Implementierung zur Grundvoraussetzung für Sichtbarkeit. Wer jetzt eine solide Infrastruktur schafft, wird KI-generierte Ergebnisse dominieren, wenn diese Kanäle ausgereift sind. Wer zögert, wird es zunehmend schwer haben, Sichtbarkeit zu erreichen, denn KI-Systeme bevorzugen umfassend markierte Inhalte. Strukturierte Daten sind nicht bloß eine technische Umsetzung, sondern ein grundlegendes strategisches Bekenntnis zur Auffindbarkeit und Zitierbarkeit im KI-geprägten Informations-Ökosystem.
Strukturierte Daten haben keinen direkten Einfluss auf das Google-Ranking, verbessern aber das Erscheinungsbild in den Suchergebnissen durch Rich Snippets erheblich, was die Klickrate um bis zu 35 % steigert. Für KI-Systeme haben strukturierte Daten einen direkteren Einfluss darauf, ob Ihre Inhalte in KI-generierten Antworten zitiert werden.
Ja, KI-Systeme verarbeiten strukturierte Daten sowohl beim Training als auch bei Echtzeitanfragen. Während OpenAI keine öffentlichen Stellungnahmen gemacht hat, deutet vieles darauf hin, dass GPTBot und andere KI-Crawler JSON-LD-Markup parsen. Microsoft hat offiziell bestätigt, dass Bing's KI-Systeme Schema-Markup verwenden, um Inhalte besser zu verstehen.
JSON-LD ist das empfohlene Format, da es Schema vom HTML-Inhalt trennt und so die Implementierung und Wartung im großen Maßstab erleichtert. Google empfiehlt ausdrücklich JSON-LD, und es ist weniger fehleranfällig als Microdata oder RDFa.
Rich Snippets können innerhalb von 1–4 Wochen nach der Implementierung erscheinen. Verbesserungen der Klickrate sind oft schon nach 2 Wochen messbar. Für Verbesserungen bei KI-Zitationen sollten Sie 4–8 Wochen für die Grundarbeit einplanen, wobei sich Autoritätsvorteile über 3–6 Monate hinweg verstärken.
Priorisieren Sie zuerst Schema-Markup – es ist bewährt und wird weitgehend unterstützt. llms.txt ist noch ein aufkommender Standard mit begrenzter Akzeptanz bei KI-Crawlern. Wenn Sie ein entwicklerorientiertes Unternehmen mit umfangreicher Dokumentation sind, könnte der geringe Aufwand für llms.txt sinnvoll sein, um zukunftssicher zu sein.
Beginnen Sie mit dem Organization-Schema auf Ihrer Startseite (mit sameAs-Eigenschaften) und dann mit dem Article-Schema auf den wichtigsten Inhaltsseiten. FAQPage-Schema sollte als nächstes kommen – es ist am nützlichsten für die KI-Extraktion. Danach fügen Sie HowTo-Schema zu Anleitungen und SoftwareApplication-Schema zu Produktseiten hinzu.
Nur falsch implementiertes Markup schadet der Performance. Die Google-Richtlinien sind klar: Verwenden Sie relevante Schema-Typen, die mit sichtbarem Inhalt übereinstimmen, halten Sie Preise und Daten aktuell und markieren Sie keine Inhalte, die Nutzer nicht sehen. Validieren Sie immer mit dem Google Rich Results Test, bevor Sie veröffentlichen.
Strukturierte Daten liefern expliziten Kontext, der KI-Systemen hilft, Informationen hinsichtlich Entitäten, Beziehungen und Attributen zu verstehen. Diese Klarheit ermöglicht KI, Ihre Inhalte sicher zu extrahieren und zu zitieren. LLMs, die auf Knowledge Graphs basieren, erreichen eine um 300 % höhere Genauigkeit als solche, die nur auf unstrukturierten Daten basieren.
Verfolgen Sie, wie KI-Systeme Ihre Inhalte über ChatGPT, Perplexity, Google AI Overviews und andere Plattformen hinweg zitieren. Erhalten Sie Echtzeit-Einblick in Ihre KI-Präsenz.
Strukturierte Daten sind standardisiertes Markup, das Suchmaschinen hilft, Webseiteninhalte zu verstehen. Erfahren Sie, wie JSON-LD, schema.org und microdata SE...
Erfahren Sie, wie KI-Crawler strukturierte Daten verarbeiten. Entdecken Sie, warum die JSON-LD-Implementierungsmethode für die Sichtbarkeit in ChatGPT, Perplexi...
Entdecken Sie, warum KI-Modelle Listicles und nummerierte Listen bevorzugen. Lernen Sie, wie Sie Listen-Inhalte für ChatGPT-, Gemini- und Perplexity-Zitate mit ...