
So lehnen Sie das KI-Training auf großen Plattformen ab
Vollständiger Leitfaden zum Ablehnen der Datensammlung für KI-Training auf ChatGPT, Perplexity, LinkedIn und anderen Plattformen. Erfahren Sie Schritt-für-Schri...
8 Min. Lesezeit

Das Training mit synthetischen Daten ist der Prozess, bei dem KI-Modelle mit künstlich generierten Daten anstelle von realen, von Menschen erstellten Informationen trainiert werden. Dieser Ansatz begegnet dem Mangel an Daten, beschleunigt die Modellentwicklung und schützt die Privatsphäre, bringt jedoch Herausforderungen wie Modellkollaps und Halluzinationen mit sich, die sorgfältiges Management und Validierung erfordern.
Das Training mit synthetischen Daten ist der Prozess, bei dem KI-Modelle mit künstlich generierten Daten anstelle von realen, von Menschen erstellten Informationen trainiert werden. Dieser Ansatz begegnet dem Mangel an Daten, beschleunigt die Modellentwicklung und schützt die Privatsphäre, bringt jedoch Herausforderungen wie Modellkollaps und Halluzinationen mit sich, die sorgfältiges Management und Validierung erfordern.
Unter Training mit synthetischen Daten versteht man den Prozess, bei dem künstliche Intelligenz mit künstlich generierten Daten anstelle von realen, von Menschen erstellten Informationen trainiert wird. Im Gegensatz zum traditionellen KI-Training, das auf authentische Datensätze aus Umfragen, Beobachtungen oder Web-Mining setzt, werden synthetische Daten durch Algorithmen und rechnergestützte Methoden erzeugt, die statistische Muster aus bestehenden Daten lernen oder völlig neue Daten von Grund auf generieren. Dieser grundlegende Wandel in der Trainingsmethodik adressiert eine zentrale Herausforderung der modernen KI-Entwicklung: Das exponentielle Wachstum des Rechenbedarfs übersteigt die Fähigkeit der Menschheit, ausreichend reale Daten zu erzeugen – Untersuchungen zeigen, dass von Menschen erzeugte Trainingsdaten in den nächsten Jahren erschöpft sein könnten. Das Training mit synthetischen Daten bietet eine skalierbare, kosteneffiziente Alternative, die unendlich erzeugt werden kann, ohne die zeitaufwendigen Prozesse der Datensammlung, -kennzeichnung und -bereinigung, die bis zu 80% der Entwicklungszeit traditioneller KI-Projekte ausmachen.
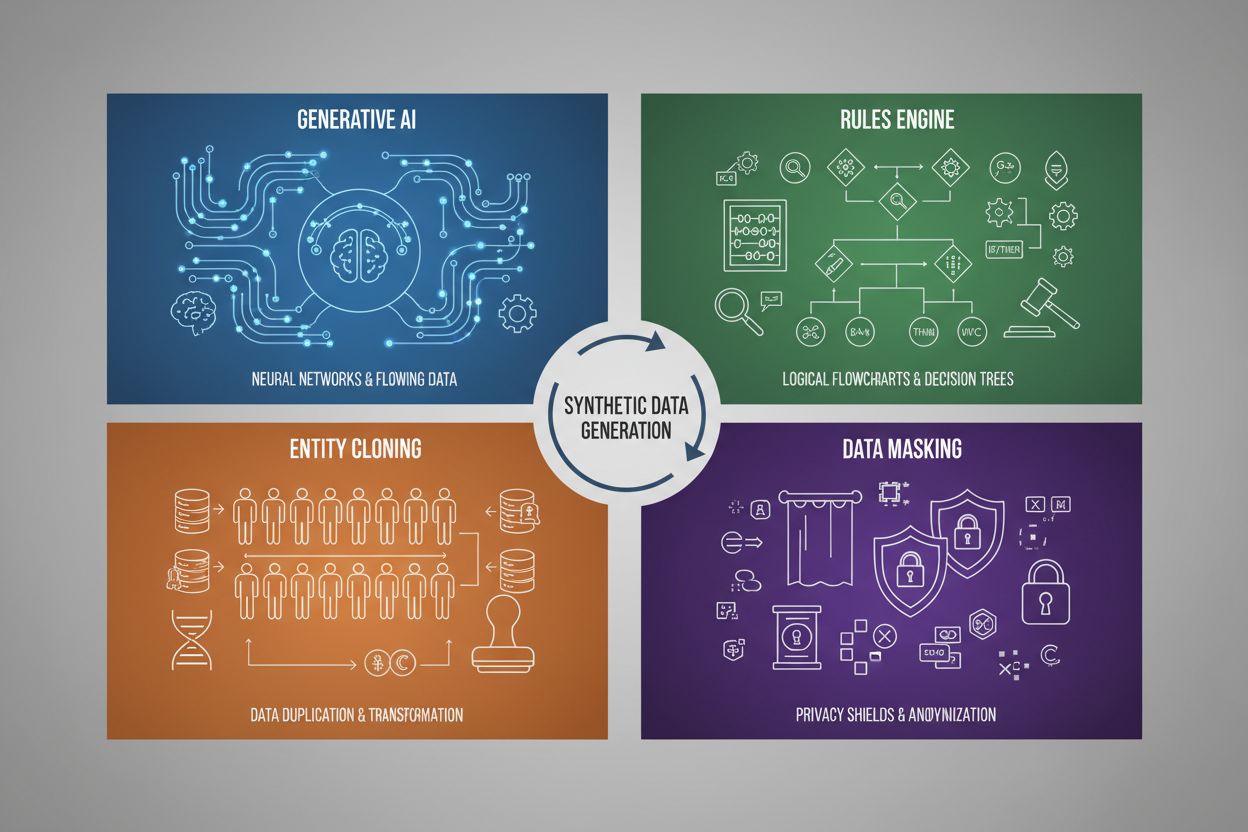
Die Generierung synthetischer Daten erfolgt durch vier Haupttechniken, die jeweils eigene Mechanismen und Anwendungsgebiete haben:
| Technik | Funktionsweise | Anwendungsfall |
|---|---|---|
| Generative KI (GANs, VAEs, GPT) | Nutzt Deep-Learning-Modelle, um statistische Muster und Verteilungen aus realen Daten zu lernen und erzeugt dann neue synthetische Proben, die die gleichen statistischen Eigenschaften und Beziehungen aufweisen. GANs verwenden gegnerische Netzwerke, bei denen ein Generator gefälschte Daten erstellt und ein Diskriminator deren Authentizität bewertet, wodurch zunehmend realistische Ausgaben entstehen. | Training großer Sprachmodelle wie ChatGPT, Generierung synthetischer Bilder mit DALL-E, Erstellung vielfältiger Textdatensätze für Aufgaben der natürlichen Sprachverarbeitung |
| Regel-Engine | Anwenden vordefinierter logischer Regeln und Einschränkungen, um Daten zu generieren, die bestimmter Geschäftslogik, Domänenwissen oder regulatorischen Anforderungen entsprechen. Dieser deterministische Ansatz garantiert, dass die erzeugten Daten bekannten Mustern und Beziehungen folgen, ohne maschinelles Lernen einzusetzen. | Finanztransaktionsdaten, Gesundheitsdaten mit spezifischen Compliance-Anforderungen, Sensordaten aus der Fertigung mit bekannten Betriebsparametern |
| Entitätsklonierung | Dupliziert und verändert vorhandene reale Datensätze durch Transformationen, Störungen oder Variationen, um neue Instanzen zu erzeugen und dabei statistische Eigenschaften und Beziehungen zu bewahren. Diese Technik erhält die Authentizität der Daten und erweitert gleichzeitig den Datensatz. | Erweiterung begrenzter Datensätze in regulierten Branchen, Erzeugung von Trainingsdaten für seltene Krankheitsdiagnosen, Ergänzung von Datensätzen mit zu wenigen Minderheitenklassen |
| Datenmaskierung & Anonymisierung | Verschleiert sensible, personenbezogene Informationen (PII) unter Erhalt der Datenstruktur und statistischer Beziehungen durch Techniken wie Tokenisierung, Verschlüsselung oder Wertsubstitution. So entstehen datenschutzfreundliche synthetische Versionen realer Daten. | Gesundheits- und Finanzdatensätze, Kundenverhaltensdaten, personenbezogene sensible Informationen in Forschungsumgebungen |
Das Training mit synthetischen Daten bringt erhebliche Kostensenkungen, indem teure Prozesse der Datensammlung, -annotation und -bereinigung entfallen, die traditionell viel Zeit und Ressourcen binden. Organisationen können unbegrenzt viele Trainingsmuster auf Abruf generieren, wodurch die Modellentwicklung erheblich beschleunigt und schnelle Iteration und Experimentieren ermöglicht werden – ohne auf reale Datensammlung warten zu müssen. Die Technik bietet starke Möglichkeiten zur Datenaugmentation, mit denen Entwickler begrenzte Datensätze erweitern und ausgewogene Trainingssets zur Behebung von Klassenungleichgewichten erstellen können – ein zentrales Problem, wenn bestimmte Kategorien in echten Daten unterrepräsentiert sind. Besonders wertvoll sind synthetische Daten zur Überwindung von Datenmangel in spezialisierten Bereichen wie medizinischer Bildgebung, seltener Krankheitsdiagnose oder autonomem Fahrzeugtest, wo die Sammlung ausreichender realer Beispiele entweder extrem teuer oder ethisch schwierig ist. Ein großer Vorteil liegt im Datenschutz: Synthetische Daten können erzeugt werden, ohne sensible persönliche Informationen offenzulegen, was sie ideal macht für das Training von Modellen mit Gesundheitsakten, Finanzdaten oder anderen regulierten Informationen. Darüber hinaus ermöglichen synthetische Daten die gezielte Reduzierung von Verzerrungen, indem Entwickler ausgewogene, vielfältige Datensätze erstellen können, die diskriminierende Muster in echten Daten ausgleichen – beispielsweise durch die Generierung vielfältiger demografischer Darstellungen in Trainingsbildern, um zu verhindern, dass KI-Modelle Geschlechter- oder Rassestereotype in Bereichen wie Personalwesen, Kreditvergabe oder Strafjustiz fortschreiben.
Trotz ihres Potenzials bringt das Training mit synthetischen Daten erhebliche technische und praktische Herausforderungen mit sich, die die Modellleistung beeinträchtigen können, wenn sie nicht sorgfältig kontrolliert werden. Das größte Risiko ist der Modellkollaps – ein Phänomen, bei dem KI-Modelle, die überwiegend mit synthetischen Daten trainiert werden, eine starke Verschlechterung der Ausgabequalität, Genauigkeit und Kohärenz erfahren. Das liegt daran, dass synthetische Daten zwar statistisch echten Daten ähneln, aber die feinen Nuancen und Grenzfälle authentischer, von Menschen generierter Informationen fehlen – trainieren Modelle auf KI-generierten Inhalten, verstärken sich Fehler und Artefakte, was zu einer Kettenreaktion führt, bei der jede Generation synthetischer Daten zunehmend an Qualität verliert.
Zentrale Herausforderungen sind:
Diese Herausforderungen zeigen, warum synthetische Daten reale Daten nicht ersetzen können – sie müssen als Ergänzung zu authentischen Datensätzen mit strenger Qualitätskontrolle und menschlicher Aufsicht in den Trainingsprozess integriert werden.
Mit der zunehmenden Verbreitung synthetischer Daten im KI-Training stehen Marken vor einer neuen Herausforderung: die Sicherstellung einer genauen und positiven Darstellung in KI-generierten Ausgaben und Zitaten. Wenn große Sprachmodelle und generative KI-Systeme mit synthetischen Daten trainiert werden, beeinflussen die Qualität und Eigenschaften dieser Daten direkt, wie Marken in KI-Suchergebnissen, Chatbot-Antworten und automatisierter Inhaltserstellung beschrieben, empfohlen und zitiert werden. Dies stellt ein ernstzunehmendes Markensicherheitsproblem dar, da synthetische Daten mit veralteten Informationen, Wettbewerbsverzerrung oder fehlerhaften Markenbeschreibungen sich in KI-Modellen festsetzen und so zu dauerhafter Fehlrepräsentation in Millionen von Nutzerinteraktionen führen können. Für Unternehmen, die Plattformen wie AmICited.com zur Überwachung ihrer Markenpräsenz in KI-Systemen nutzen, wird das Verständnis der Rolle synthetischer Daten im Modelltraining entscheidend – Marken müssen wissen, ob KI-Zitate und -Nennungen aus echten Trainingsdaten oder synthetischen Quellen stammen, da dies Glaubwürdigkeit und Genauigkeit beeinflusst. Die fehlende Transparenz beim Einsatz synthetischer Daten im KI-Training erschwert die Verantwortlichkeit: Unternehmen können oft nicht nachvollziehen, ob und wie ihre Marke in synthetischen Datensätzen repräsentiert ist, die zur Schulung von Modellen verwendet werden, welche die Verbraucherwahrnehmung prägen. Vorausschauende Marken sollten daher KI-Monitoring und Zitatverfolgung priorisieren, auf Transparenzstandards bestehen, die den Einsatz synthetischer Daten im KI-Training offenlegen, und mit Plattformen zusammenarbeiten, die Einblicke geben, wie ihre Marke in KI-Systemen auf Basis echter und synthetischer Daten erscheint. Da synthetische Daten bis 2030 zum dominierenden Trainingsparadigma werden, verlagert sich das Markenmonitoring vom klassischen Medientracking hin zu umfassender KI-Zitationsintelligenz – Plattformen, die die Markenrepräsentation in generativen KI-Systemen verfolgen, werden unverzichtbar, um Markenintegrität zu schützen und eine korrekte Markenstimme im KI-getriebenen Informationsökosystem sicherzustellen.
Traditionelles KI-Training basiert auf realen Daten, die von Menschen durch Umfragen, Beobachtungen oder Web-Mining gesammelt werden, was zeitaufwendig ist und zunehmend unter Datenknappheit leidet. Beim Training mit synthetischen Daten werden künstlich generierte Daten verwendet, die von Algorithmen erstellt werden, die statistische Muster aus vorhandenen Daten lernen oder völlig neue Daten von Grund auf generieren. Synthetische Daten können unbegrenzt auf Abruf erzeugt werden, was Entwicklungszeit und Kosten drastisch reduziert und gleichzeitig Datenschutzprobleme adressiert.
Die vier wichtigsten Techniken sind: 1) Generative KI (unter Verwendung von GANs, VAEs oder GPT-Modellen, um Datenmuster zu lernen und zu replizieren), 2) Regel-Engine (Anwendung vordefinierter Geschäftslogik und Einschränkungen), 3) Entitätsklonierung (Duplizieren und Modifizieren vorhandener Datensätze unter Beibehaltung statistischer Eigenschaften) und 4) Datenmaskierung (Anonymisierung sensibler Informationen bei Erhalt der Datenstruktur). Jede Technik dient unterschiedlichen Anwendungsfällen und hat spezifische Vorteile.
Modellkollaps tritt auf, wenn KI-Modelle, die umfangreich mit synthetischen Daten trainiert wurden, eine starke Verschlechterung der Ausgabequalität und Genauigkeit erfahren. Dies geschieht, weil synthetische Daten zwar statistisch echten Daten ähneln, aber die nuancierte Komplexität und die Grenzfälle authentischer Informationen fehlen. Beim Training auf KI-generierten Inhalten verstärken sich Fehler und Artefakte, was zu einer Kettenreaktion führt, bei der jede Generation von synthetischen Daten zunehmend an Qualität verliert, bis schließlich unbrauchbare Ausgaben entstehen.
Wenn KI-Modelle mit synthetischen Daten trainiert werden, beeinflussen die Qualität und Eigenschaften dieser Daten direkt, wie Marken in KI-Ausgaben beschrieben, empfohlen und zitiert werden. Minderwertige synthetische Daten mit veralteten Informationen oder Wettbewerbsverzerrungen können sich in KI-Modellen festsetzen und zu dauerhafter Markenfehlrepräsentation in Millionen von Nutzerinteraktionen führen. Dies schafft ein Markensicherheitsproblem, das Überwachung und Transparenz bei der Verwendung synthetischer Daten im KI-Training erfordert.
Nein, synthetische Daten sollten echte Daten ergänzen, nicht ersetzen. Obwohl sie hinsichtlich Kosten, Geschwindigkeit und Datenschutz große Vorteile bieten, können sie die Komplexität, Vielfalt und Grenzfälle authentischer, von Menschen generierter Daten nicht vollständig nachbilden. Am effektivsten ist ein Ansatz, der synthetische und reale Daten kombiniert, mit strikter Qualitätskontrolle und menschlicher Aufsicht, um Modellgenauigkeit und Zuverlässigkeit sicherzustellen.
Synthetische Daten bieten einen überlegenen Datenschutz, da sie keine echten Werte aus Originaldatensätzen enthalten und keine Eins-zu-eins-Beziehungen zu realen Personen bestehen. Im Gegensatz zu herkömmlicher Datenmaskierung oder Anonymisierung, die immer noch Rückschlüsse auf Einzelpersonen ermöglichen kann, werden synthetische Daten vollständig von Grund auf auf Basis gelernter Muster erstellt. Sie sind daher ideal, um Modelle mit sensiblen Daten wie Gesundheitsakten, Finanzdaten oder persönlichem Verhalten zu trainieren, ohne reale Daten preiszugeben.
Synthetische Daten ermöglichen eine systematische Reduzierung von Verzerrungen, indem Entwickler gezielt ausgewogene, vielfältige Datensätze erzeugen können, die diskriminierende Muster in echten Daten ausgleichen. Zum Beispiel lassen sich im Training vielfältige demografische Repräsentationen generieren, um zu verhindern, dass KI-Modelle Geschlechter- oder Rassestereotype in Bereichen wie Personalwesen, Kreditvergabe oder Strafjustiz verstärken.
Da synthetische Daten bis 2030 zum dominierenden Trainingsparadigma werden, müssen Marken verstehen, wie ihre Informationen in KI-Systemen repräsentiert werden. Die Qualität synthetischer Daten beeinflusst direkt Markenzitate und -nennungen in KI-Ausgaben. Marken sollten ihre Präsenz in KI-Systemen überwachen, Transparenzstandards einfordern, die den Einsatz synthetischer Daten offenlegen, und Plattformen wie AmICited.com nutzen, um Markenrepräsentation zu verfolgen und Fehldarstellungen frühzeitig zu erkennen.
Erfahren Sie, wie Ihre Marke in KI-Systemen, die mit synthetischen Daten trainiert wurden, dargestellt wird. Verfolgen Sie Zitate, überwachen Sie die Genauigkeit und stellen Sie Markensicherheit im KI-getriebenen Informationsökosystem sicher.
Vollständiger Leitfaden zum Ablehnen der Datensammlung für KI-Training auf ChatGPT, Perplexity, LinkedIn und anderen Plattformen. Erfahren Sie Schritt-für-Schri...

Trainingsdaten sind der Datensatz, mit dem ML-Modelle Muster und Zusammenhänge erlernen. Erfahren Sie, wie qualitativ hochwertige Trainingsdaten die Leistung, G...

Vergleichen Sie Optimierungsstrategien für Trainingsdaten und Echtzeit-Abfrage für KI. Erfahren Sie, wann Feintuning und wann RAG sinnvoll ist, was die Kosten b...