Impacto de los Crawlers de IA en los Recursos del Servidor: Qué Esperar
Descubre cómo los crawlers de IA impactan los recursos del servidor, el ancho de banda y el rendimiento. Conoce estadísticas reales, estrategias de mitigación y soluciones de infraestructura para gestionar eficazmente la carga de bots.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Comprendiendo el Comportamiento y la Escala de los Crawlers de IA
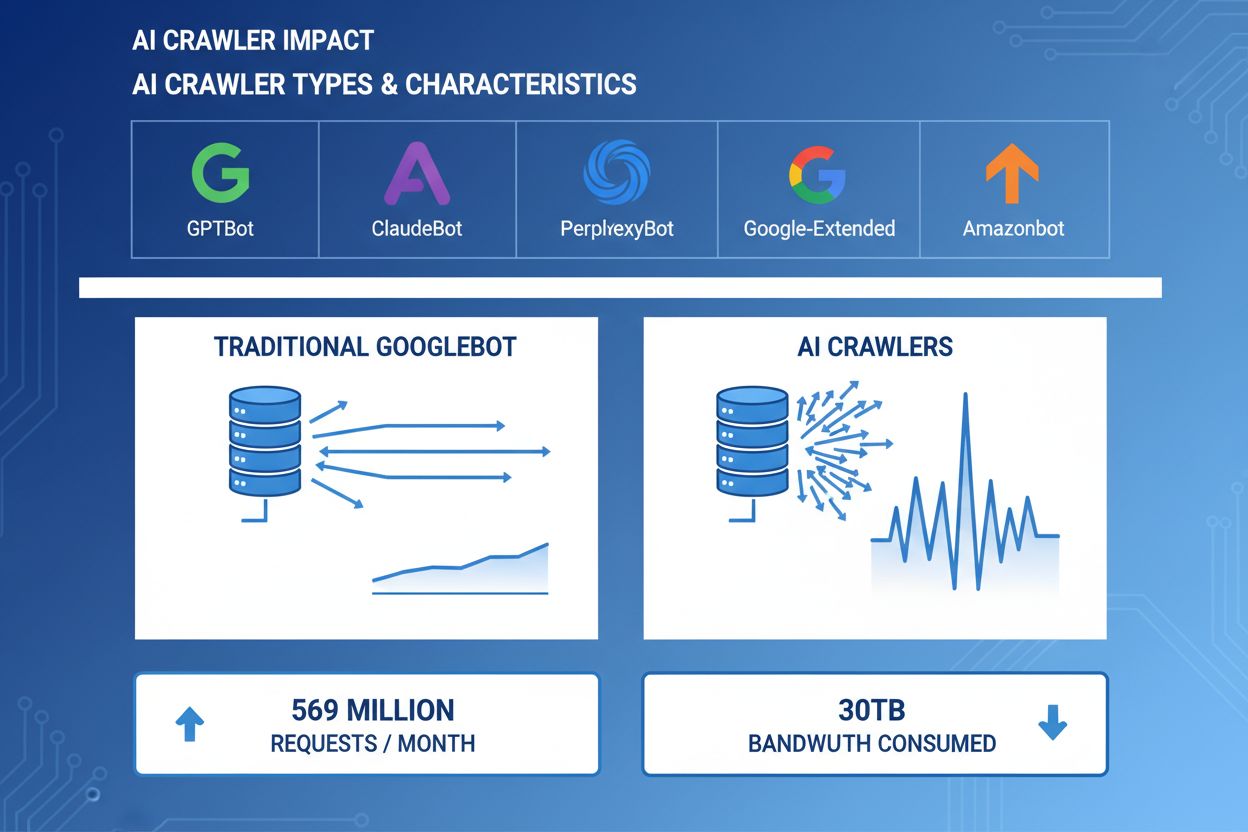
Los crawlers de IA se han convertido en una fuerza significativa en el tráfico web, con grandes empresas de IA desplegando bots sofisticados para indexar contenido con fines de entrenamiento y recuperación. Estos crawlers operan a una escala masiva, generando aproximadamente 569 millones de solicitudes por mes en la web y consumiendo más de 30TB de ancho de banda globalmente. Los principales crawlers de IA incluyen GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) y Amazonbot (Amazon), cada uno con patrones de rastreo y demandas de recursos distintos. Comprender el comportamiento y las características de estos crawlers es esencial para los administradores de sitios web, para gestionar adecuadamente los recursos del servidor y tomar decisiones informadas sobre las políticas de acceso.
Nombre del Crawler
Empresa
Propósito
Patrón de Solicitud
GPTBot
OpenAI
Datos de entrenamiento para ChatGPT y modelos GPT
Solicitudes agresivas y de alta frecuencia
ClaudeBot
Anthropic
Datos de entrenamiento para modelos Claude AI
Frecuencia moderada, rastreo respetuoso
PerplexityBot
Perplexity AI
Búsqueda en tiempo real y generación de respuestas
Frecuencia moderada a alta
Google-Extended
Google
Indexación extendida para funciones de IA
Controlado, sigue robots.txt
Amazonbot
Amazon
Indexación de productos y contenidos
Variable, enfocado en comercio
Métricas de Consumo de Recursos del Servidor
Los crawlers de IA consumen recursos del servidor en varias dimensiones, generando impactos medibles en el rendimiento de la infraestructura. El uso de CPU puede incrementarse en un 300% o más durante picos de actividad de crawlers, ya que los servidores procesan miles de solicitudes concurrentes y analizan contenido HTML. El consumo de ancho de banda representa uno de los costos más visibles, con un sitio web popular llegando a servir gigabytes de datos a crawlers diariamente. El uso de memoria aumenta significativamente a medida que los servidores mantienen pools de conexiones y almacenan en búfer grandes cantidades de datos para procesamiento. Las consultas a la base de datos se multiplican cuando los crawlers solicitan páginas que generan contenido dinámico, creando presión adicional de E/S. La E/S de disco puede convertirse en cuello de botella cuando los servidores deben leer del almacenamiento para atender solicitudes de crawlers, especialmente en sitios con grandes bibliotecas de contenido.
Recurso
Impacto
Ejemplo Real
CPU
Picos de 200-300% durante rastreo intenso
La carga promedio del servidor aumenta de 2.0 a 8.0
Ancho de banda
15-40% del uso mensual total
Sitio de 500GB sirviendo 150GB a crawlers mensualmente
Memoria
Aumento del 20-30% en consumo de RAM
Servidor de 8GB requiere 10GB durante actividad de crawlers
Base de datos
Incremento de 2-5x en carga de consultas
Tiempos de respuesta de consultas pasan de 50ms a 250ms
E/S de disco
Operaciones de lectura sostenidas altas
Utilización de disco sube de 30% a 85%
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
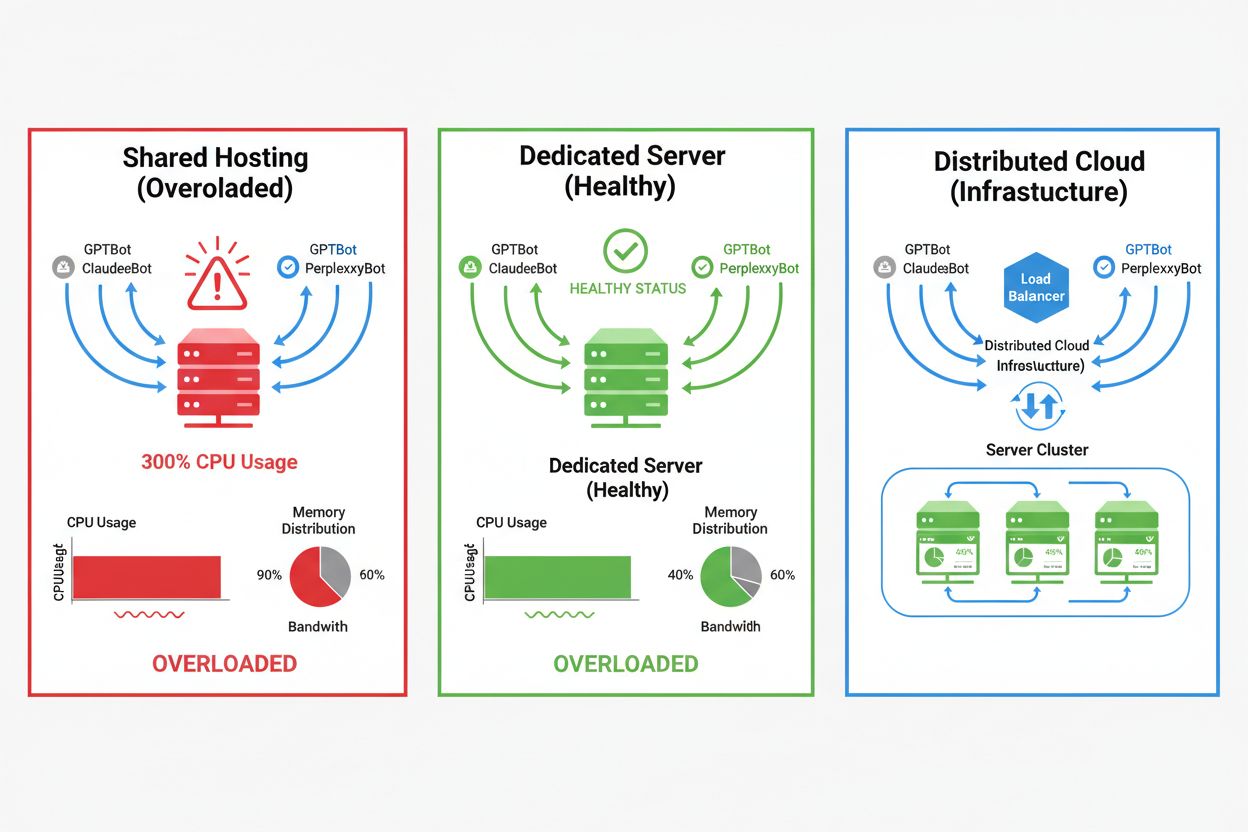
El impacto de los crawlers de IA varía drásticamente según el entorno de hosting, siendo el hosting compartido el que experimenta las consecuencias más severas. En escenarios de hosting compartido, el “síndrome del vecino ruidoso” es especialmente problemático: cuando un sitio web atrae tráfico intenso de crawlers, consume recursos que de otro modo estarían disponibles para otros sitios alojados, degradando el rendimiento para todos. Los servidores dedicados y la infraestructura en la nube brindan mejor aislamiento y garantías de recursos, permitiendo absorber el tráfico de crawlers sin afectar otros servicios. Sin embargo, incluso la infraestructura dedicada requiere monitoreo cuidadoso y escalado para manejar la carga acumulada de múltiples crawlers de IA operando simultáneamente.
Diferencias clave entre entornos de hosting:
Hosting Compartido: Recursos limitados, sin aislamiento, el tráfico de crawlers impacta directamente otros sitios, control mínimo sobre el acceso de crawlers
VPS/Nube: Recursos dedicados, mejor aislamiento, capacidad escalable, control granular sobre la gestión del tráfico
Servidor Dedicado: Asignación total de recursos, control completo, mayor costo, requiere decisiones manuales de escalado
CDN + Origen: Carga distribuida, caché en el edge, tráfico de crawlers absorbido en el edge, servidor de origen protegido
Implicaciones de Ancho de Banda y Costos
El impacto financiero del tráfico de crawlers de IA va más allá de los costos simples de ancho de banda, abarcando tanto gastos directos como ocultos que pueden afectar significativamente tu rentabilidad. Los costos directos incluyen cargos incrementados de ancho de banda por parte de tu proveedor de hosting, que pueden sumar cientos o miles de dólares mensualmente según el volumen de tráfico y la intensidad de los crawlers. Los costos ocultos surgen del aumento en requerimientos de infraestructura: puede que necesites actualizar a planes de hosting de mayor nivel, implementar capas adicionales de caché o invertir en servicios CDN específicamente para manejar el tráfico de crawlers. El cálculo del ROI se vuelve complejo al considerar que los crawlers de IA ofrecen un valor directo mínimo a tu negocio mientras consumen recursos que podrían atender a clientes reales o mejorar la experiencia del usuario. Muchos propietarios de sitios web encuentran que el costo de acomodar el tráfico de crawlers supera cualquier posible beneficio del entrenamiento de modelos de IA o la visibilidad en resultados de búsqueda impulsados por IA.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Impacto en el Rendimiento y la Experiencia del Usuario
El tráfico de crawlers de IA degrada directamente la experiencia de los visitantes legítimos al consumir recursos del servidor que, de otro modo, servirían más rápido a los usuarios humanos. Las métricas Core Web Vitals se ven afectadas de manera medible, con Largest Contentful Paint (LCP) aumentando entre 200-500ms y Time to First Byte (TTFB) deteriorándose entre 100-300ms durante periodos de intensa actividad de crawlers. Estas degradaciones de rendimiento desencadenan efectos negativos en cascada: cargas de página más lentas reducen el engagement, aumentan el bounce rate y, en último término, disminuyen las tasas de conversión en sitios de comercio electrónico o generación de leads. El posicionamiento en motores de búsqueda también se ve afectado, ya que el algoritmo de Google incorpora las Core Web Vitals como factor de ranking, creando un ciclo vicioso en el que el tráfico de crawlers perjudica indirectamente tu SEO. Los usuarios que experimentan tiempos de carga lentos son más propensos a abandonar tu sitio y visitar a la competencia, impactando directamente en ingresos y percepción de marca.
Estrategias de Monitoreo y Detección
La gestión efectiva del tráfico de crawlers de IA comienza con un monitoreo y detección exhaustivos, permitiéndote comprender el alcance del problema antes de implementar soluciones. La mayoría de los servidores web registran cadenas de user-agent que identifican el crawler detrás de cada solicitud, proporcionando la base para el análisis de tráfico y decisiones de filtrado. Los registros del servidor, las plataformas analíticas y las herramientas especializadas de monitoreo pueden analizar estas cadenas de user-agent para identificar y cuantificar patrones de tráfico de crawlers.
Métodos y herramientas clave de detección:
Análisis de Registros: Analiza los registros del servidor en busca de user-agents (GPTBot, ClaudeBot, Google-Extended, CCBot) para identificar solicitudes de crawlers
Plataformas Analíticas: Google Analytics, Matomo y herramientas similares pueden segmentar el tráfico de crawlers separado de los usuarios humanos
Monitoreo en Tiempo Real: Herramientas como New Relic y Datadog brindan visibilidad en tiempo real sobre la actividad de crawlers y el consumo de recursos
DNS Reverse Lookup: Verifica direcciones IP de crawlers contra rangos publicados por OpenAI, Anthropic y otras empresas de IA
Análisis de Comportamiento: Identifica patrones sospechosos como solicitudes rápidas secuenciales, combinaciones inusuales de user-agent o solicitudes a áreas sensibles
Estrategias de Mitigación - robots.txt y Limitación de Tasa
La primera línea de defensa contra el tráfico excesivo de crawlers de IA es implementar un archivo robots.txt bien configurado que controle explícitamente el acceso de crawlers a tu sitio web. Este sencillo archivo de texto, ubicado en el directorio raíz de tu sitio, te permite desautorizar crawlers específicos, limitar la frecuencia de rastreo y dirigir a los crawlers a un sitemap que contenga solo el contenido que deseas indexar. La limitación de tasa a nivel de aplicación o servidor añade una capa adicional de protección, estrangulando solicitudes desde direcciones IP o user-agents específicos para evitar el agotamiento de recursos. Estas estrategias no son bloqueantes y son reversibles, lo que las hace ideales como punto de partida antes de implementar medidas más agresivas.
# robots.txt - Bloquear crawlers de IA permitiendo motores de búsqueda legítimos
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Permitir Google y Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Retraso de rastreo para otros bots
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Protección Avanzada - Soluciones WAF y CDN
Los Firewalls de Aplicaciones Web (WAF) y las Redes de Entrega de Contenidos (CDN) ofrecen protección sofisticada de nivel empresarial contra el tráfico indeseado de crawlers mediante análisis de comportamiento y filtrado inteligente. Cloudflare y proveedores CDN similares ofrecen funciones de gestión de bots integradas que pueden identificar y bloquear crawlers de IA en función de patrones de comportamiento, reputación de IP y características de las solicitudes sin requerir configuración manual. Las reglas de WAF pueden configurarse para desafiar solicitudes sospechosas, limitar la tasa de user-agents específicos o bloquear completamente el tráfico desde rangos de IP conocidos de crawlers. Estas soluciones operan en el edge, filtrando el tráfico malicioso antes de que alcance tu servidor de origen, reduciendo drásticamente la carga sobre tu infraestructura. La ventaja de las soluciones WAF y CDN es su capacidad de adaptarse a nuevos crawlers y patrones de ataque en evolución sin requerir actualizaciones manuales en tu configuración.
Balanceando Visibilidad y Protección
Decidir si bloquear o no los crawlers de IA requiere una cuidadosa consideración de los pros y contras entre proteger los recursos de tu servidor y mantener visibilidad en resultados y aplicaciones de búsqueda impulsadas por IA. Bloquear todos los crawlers de IA elimina la posibilidad de que tu contenido aparezca en resultados de búsqueda de ChatGPT, respuestas de Perplexity AI u otros mecanismos de descubrimiento basados en IA, lo que podría reducir el tráfico de referencia y la visibilidad de marca. Por el contrario, permitir el acceso irrestricto de crawlers consume recursos significativos y puede degradar la experiencia del usuario sin brindar beneficios medibles para tu negocio. La estrategia óptima depende de tu situación específica: los sitios de alto tráfico con recursos abundantes pueden optar por permitir crawlers, mientras que sitios con recursos limitados deben priorizar la experiencia del usuario bloqueando o limitando el acceso de crawlers. La toma de decisiones estratégica debe considerar tu industria, audiencia objetivo, tipo de contenido y objetivos de negocio en lugar de adoptar un enfoque único para todos.
Soluciones de Escalado de Infraestructura
Para los sitios web que deciden acomodar el tráfico de crawlers de IA, el escalado de infraestructura brinda una vía para mantener el rendimiento absorbiendo la carga extra. El escalado vertical—actualizar a servidores con más CPU, RAM y ancho de banda—ofrece una solución directa pero costosa que eventualmente alcanza límites físicos. El escalado horizontal—distribuir el tráfico entre varios servidores mediante balanceadores de carga—brinda mejor escalabilidad y resiliencia a largo plazo. Plataformas de infraestructura en la nube como AWS, Google Cloud y Azure ofrecen capacidades de autoescalado que aprovisionan recursos adicionales automáticamente durante picos de tráfico, reduciéndolos después para minimizar costos. Las CDN pueden almacenar contenido estático en ubicaciones edge, reduciendo la carga sobre tu servidor de origen y mejorando el rendimiento tanto para usuarios humanos como para crawlers. La optimización de la base de datos, el caching de consultas y mejoras a nivel de aplicación también pueden reducir el consumo de recursos por solicitud, mejorando la eficiencia sin requerir infraestructura adicional.
Herramientas de Monitoreo y Mejores Prácticas
El monitoreo y la optimización continuos son esenciales para mantener el rendimiento óptimo ante el tráfico persistente de crawlers de IA. Las herramientas especializadas ofrecen visibilidad sobre la actividad de crawlers, el consumo de recursos y las métricas de rendimiento, permitiendo la toma de decisiones basada en datos sobre las estrategias de gestión de crawlers. Implementar un monitoreo integral desde el principio permite establecer líneas base, identificar tendencias y medir la efectividad de las estrategias de mitigación a lo largo del tiempo.
Herramientas y prácticas esenciales de monitoreo:
Monitoreo del Servidor: New Relic, Datadog o Prometheus para métricas en tiempo real de CPU, memoria y E/S de disco
Análisis de Registros: ELK Stack, Splunk o Graylog para analizar y procesar registros del servidor e identificar patrones de crawlers
Soluciones Especializadas: AmICited.com provee monitoreo especializado para actividad de crawlers de IA, ofreciendo información detallada sobre qué modelos de IA acceden a tu contenido
Seguimiento de Rendimiento: Google PageSpeed Insights, WebPageTest y monitoreo de Core Web Vitals para medir el impacto en la experiencia del usuario
Alertas: Configura alertas para picos de recursos, patrones de tráfico inusuales y degradaciones de rendimiento para permitir una respuesta rápida
Estrategia a Largo Plazo y Consideraciones Futuras
El panorama de la gestión de crawlers de IA sigue evolucionando, con estándares emergentes e iniciativas de la industria que dan forma a cómo interactúan sitios web y empresas de IA. El estándar llms.txt representa un enfoque emergente para proporcionar a las empresas de IA información estructurada sobre derechos y preferencias de uso de contenido, ofreciendo potencialmente una alternativa más matizada al bloqueo o permiso total. Las discusiones en la industria sobre modelos de compensación sugieren que eventualmente las empresas de IA podrían pagar a los sitios web por el acceso a datos de entrenamiento, cambiando fundamentalmente la economía del tráfico de crawlers. Preparar tu infraestructura para el futuro requiere estar informado sobre estándares emergentes, monitorear desarrollos en la industria y mantener flexibilidad en tus políticas de gestión de crawlers. Construir relaciones con empresas de IA, participar en discusiones de la industria y abogar por modelos de compensación justos serán cada vez más importantes a medida que la IA se vuelva central en el descubrimiento web y el consumo de contenido. Los sitios web que prosperen en este entorno serán aquellos que equilibren la innovación con el pragmatismo, protegiendo sus recursos mientras permanecen abiertos a oportunidades legítimas de visibilidad y colaboración.
Preguntas frecuentes
¿Cuál es la diferencia entre los crawlers de IA y los crawlers de motores de búsqueda?
Los crawlers de IA (GPTBot, ClaudeBot) extraen contenido para entrenamiento de LLM sin necesariamente enviar tráfico de regreso. Los crawlers de búsqueda (Googlebot) indexan contenido para visibilidad en la búsqueda y normalmente envían tráfico de referencia. Los crawlers de IA operan de forma más agresiva con solicitudes en lotes más grandes e ignoran las directrices de ahorro de ancho de banda.
¿Cuánto ancho de banda pueden consumir los crawlers de IA?
Ejemplos reales muestran más de 30TB al mes por un solo crawler. El consumo depende del tamaño del sitio, volumen de contenido y frecuencia del crawler. Solo GPTBot de OpenAI generó 569 millones de solicitudes en un solo mes en la red de Vercel.
¿Bloquear crawlers de IA perjudica mi SEO?
Bloquear crawlers de entrenamiento de IA (GPTBot, ClaudeBot) no afecta el posicionamiento en Google. Sin embargo, bloquear crawlers de búsqueda de IA podría reducir la visibilidad en resultados de búsqueda impulsados por IA como Perplexity o la búsqueda de ChatGPT.
¿Cuáles son las señales de que mi servidor está siendo sobrecargado por crawlers?
Busca picos inexplicables de CPU (300%+), aumento en el uso de ancho de banda sin más visitantes humanos, tiempos de carga de página más lentos y cadenas de user-agent inusuales en los registros del servidor. Las métricas Core Web Vitals también pueden degradarse significativamente.
¿Vale la pena migrar a hosting dedicado para gestionar crawlers?
Para sitios con tráfico significativo de crawlers, el hosting dedicado brinda mejor aislamiento de recursos, control y previsibilidad de costos. Los entornos de hosting compartido sufren el 'síndrome del vecino ruidoso', donde el tráfico de crawlers de un sitio afecta a todos los sitios alojados.
¿Qué herramientas debo usar para monitorear la actividad de crawlers de IA?
Utiliza Google Search Console para datos de Googlebot, registros de acceso del servidor para análisis de tráfico detallado, analítica de CDN (Cloudflare) y plataformas especializadas como AmICited.com para monitoreo y seguimiento integral de crawlers de IA.
¿Puedo permitir selectivamente algunos crawlers y bloquear otros?
Sí, mediante directivas en robots.txt, reglas de WAF y filtrado basado en IP. Puedes permitir crawlers beneficiosos como Googlebot mientras bloqueas crawlers de entrenamiento de IA que consumen muchos recursos usando reglas específicas de user-agent.
¿Cómo sé si los crawlers de IA están afectando el rendimiento de mi sitio?
Compara las métricas del servidor antes y después de implementar controles para crawlers. Monitorea Core Web Vitals (LCP, TTFB), tiempos de carga, uso de CPU y métricas de experiencia de usuario. Herramientas como Google PageSpeed Insights y plataformas de monitoreo del servidor brindan información detallada.
Monitorea el Impacto de los Crawlers de IA Hoy
Obtén información en tiempo real sobre cómo los modelos de IA acceden a tu contenido e impactan los recursos de tu servidor con la plataforma de monitoreo especializada de AmICited.
Rastrea la Actividad de Crawlers de IA: Guía Completa de Monitoreo
Aprende cómo rastrear y monitorear la actividad de crawlers de IA en tu sitio web utilizando logs de servidor, herramientas y mejores prácticas. Identifica GPTB...
¿Deberías Bloquear o Permitir Rastreadores de IA? Marco de Decisión
Aprende cómo tomar decisiones estratégicas sobre el bloqueo de rastreadores de IA. Evalúa el tipo de contenido, las fuentes de tráfico, los modelos de ingresos ...
Cómo identificar rastreadores de IA en los registros del servidor: Guía completa de detección
Aprende a identificar y monitorear rastreadores de IA como GPTBot, PerplexityBot y ClaudeBot en los registros de tu servidor. Descubre cadenas de user-agent, mé...
10 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.