Explicación de los rastreadores de IA: GPTBot, ClaudeBot y más
Comprende cómo funcionan los rastreadores de IA como GPTBot y ClaudeBot, sus diferencias con los rastreadores de búsqueda tradicionales y cómo optimizar tu sitio para la visibilidad en búsquedas de IA.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Los rastreadores de IA son programas automatizados diseñados para navegar sistemáticamente por Internet y recopilar datos de sitios web, específicamente para entrenar y mejorar modelos de inteligencia artificial. A diferencia de los rastreadores de motores de búsqueda tradicionales como Googlebot, que indexan contenido para los resultados de búsqueda, los rastreadores de IA recopilan datos web en bruto para alimentar grandes modelos de lenguaje (LLM) como ChatGPT, Claude y otros sistemas de IA. Estos bots operan continuamente en millones de sitios web, descargando páginas, analizando contenido y extrayendo información que ayuda a las plataformas de IA a comprender patrones lingüísticos, información fáctica y estilos de escritura diversos. Los principales actores en este ámbito incluyen GPTBot de OpenAI, ClaudeBot de Anthropic, Meta-ExternalAgent de Meta, Amazonbot de Amazon y PerplexityBot de Perplexity.ai, cada uno sirviendo a las necesidades de entrenamiento y operación de sus respectivas plataformas de IA. Comprender cómo funcionan estos rastreadores se ha vuelto esencial para los propietarios de sitios web y creadores de contenido, ya que la visibilidad en IA ahora impacta directamente en cómo aparece tu marca en los resultados de búsqueda y recomendaciones potenciados por inteligencia artificial.
El auge de los rastreadores de IA
El panorama del rastreo web ha experimentado una transformación dramática en el último año, con los rastreadores de IA creciendo explosivamente mientras los rastreadores de búsqueda tradicionales mantienen patrones estables. Entre mayo de 2024 y mayo de 2025, el tráfico total de rastreadores creció un 18%, pero la distribución cambió significativamente: GPTBot aumentó un 305% en solicitudes, mientras que otros rastreadores como ClaudeBot cayeron un 46% y Bytespider se desplomó un 85%. Esta reorganización refleja la competencia cada vez más intensa entre las empresas de IA para asegurar datos de entrenamiento y mejorar sus modelos. Aquí tienes un desglose detallado de los principales rastreadores y su posición actual en el mercado:
Nombre del rastreador
Empresa
Solicitudes mensuales
Crecimiento interanual
Propósito principal
Googlebot
Google
4.5 mil millones
96%
Indexación de búsqueda y AI Overviews
GPTBot
OpenAI
569 millones
305%
Entrenamiento de modelos ChatGPT y búsqueda
Claude
Anthropic
370 millones
-46%
Entrenamiento de Claude y búsqueda
Bingbot
Microsoft
~450 millones
2%
Indexación de búsqueda
PerplexityBot
Perplexity.ai
24.4 millones
157,490%
Indexación de búsqueda de IA
Meta-ExternalAgent
Meta
~380 millones
Nuevo ingreso
Entrenamiento de Meta AI
Amazonbot
Amazon
~210 millones
-35%
Búsqueda y aplicaciones de IA
Los datos revelan que, aunque Googlebot mantiene su dominio con 4.5 mil millones de solicitudes mensuales, los rastreadores de IA representan colectivamente aproximadamente el 28% del volumen de Googlebot, convirtiéndose en una fuerza significativa en el tráfico web. El crecimiento explosivo de PerplexityBot (aumento del 157,490%) demuestra la rapidez con la que las nuevas plataformas de IA están ampliando sus operaciones de rastreo, mientras que el declive de algunos rastreadores de IA consolidados sugiere una consolidación de mercado en torno a las plataformas de IA más exitosas.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
GPTBot es el rastreador web de OpenAI, diseñado específicamente para recopilar datos para entrenar y mejorar ChatGPT y otros modelos de OpenAI. Lanzado como un actor relativamente menor con solo un 5% de cuota de mercado en mayo de 2024, GPTBot se ha convertido en el rastreador de IA dominante, capturando el 30% de todo el tráfico de rastreadores de IA para mayo de 2025—un notable aumento del 305% en solicitudes. Este crecimiento explosivo refleja la estrategia agresiva de OpenAI para garantizar que ChatGPT tenga acceso a contenido web fresco y diverso tanto para el entrenamiento de modelos como para las capacidades de búsqueda en tiempo real a través de ChatGPT Search. GPTBot opera con un patrón de rastreo distintivo, priorizando el contenido HTML (57.70% de las solicitudes) y también descargando archivos JavaScript e imágenes, aunque no ejecuta JavaScript para renderizar contenido dinámico. El comportamiento del rastreador muestra que frecuentemente encuentra errores 404 (34.82% de las solicitudes), lo que sugiere que puede estar siguiendo enlaces desactualizados o intentando acceder a recursos que ya no existen. Para los propietarios de sitios web, el dominio de GPTBot significa que asegurar que tu contenido sea accesible para este rastreador se ha vuelto fundamental para la visibilidad en las funciones de búsqueda de ChatGPT y para una posible inclusión en futuras iteraciones de entrenamiento de modelos.
ClaudeBot y el enfoque de Anthropic
ClaudeBot, desarrollado por Anthropic, sirve como el rastreador principal para entrenar y actualizar el asistente de IA Claude, así como para soportar las capacidades de búsqueda y grounding de Claude. Siendo una vez el segundo rastreador de IA más grande con un 27% de cuota de mercado en mayo de 2024, ClaudeBot ha experimentado una notable disminución hasta el 21% para mayo de 2025, con una caída del 46% interanual en solicitudes. Este descenso no indica necesariamente un problema con la estrategia de Anthropic, sino que refleja el cambio general del mercado hacia el dominio de OpenAI y la aparición de nuevos competidores como Meta-ExternalAgent. ClaudeBot muestra un comportamiento similar a GPTBot, priorizando el contenido HTML pero dedicando un mayor porcentaje de solicitudes a imágenes (35.17%), lo que sugiere que Anthropic podría estar entrenando a Claude para comprender mejor el contenido visual junto al texto. Como otros rastreadores de IA, ClaudeBot no procesa JavaScript, lo que significa que solo ve el HTML bruto de las páginas sin ningún contenido cargado dinámicamente. Para los creadores de contenido, mantener la visibilidad con ClaudeBot sigue siendo importante para asegurar que Claude pueda acceder y citar tu contenido, especialmente a medida que Anthropic desarrolla las capacidades de búsqueda y razonamiento de Claude.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Otros rastreadores de IA importantes
Más allá de GPTBot y ClaudeBot, otros rastreadores de IA significativos recopilan activamente datos web para sus respectivas plataformas:
Meta-ExternalAgent (Meta): El rastreador de Meta hizo una entrada dramática en las principales posiciones, capturando el 19% de cuota de mercado para mayo de 2025 como nuevo participante. Este bot recopila datos para las iniciativas de IA de Meta, incluyendo posible entrenamiento para Meta AI e integración con las funciones de IA de Instagram y Facebook. El rápido ascenso de Meta sugiere que la empresa está apostando en serio por la búsqueda y recomendaciones potenciadas por IA.
PerplexityBot (Perplexity.ai): A pesar de tener solo el 0.2% de cuota de mercado, PerplexityBot experimentó la tasa de crecimiento más explosiva con 157,490% interanual. Esto refleja la rápida expansión de Perplexity como un motor de respuestas de IA que depende de la búsqueda web en tiempo real para fundamentar sus respuestas. Para los sitios web, las visitas de PerplexityBot representan oportunidades directas de ser citados en las respuestas generadas por IA de Perplexity.
Amazonbot (Amazon): El rastreador de Amazon pasó del 21% al 11% de cuota de mercado, con una caída del 35% interanual en solicitudes. Amazonbot recopila datos para la funcionalidad de búsqueda de Amazon y aplicaciones de IA, aunque su cuota decreciente sugiere que Amazon podría estar cambiando su estrategia de IA o consolidando sus operaciones de rastreo.
Applebot (Apple): El rastreador de Apple experimentó una disminución del 26% en solicitudes, cayendo del 1.9% al 1.2% de cuota de mercado. Applebot sirve principalmente a Siri y Spotlight Search de Apple, aunque también podría apoyar las nuevas iniciativas de IA de la compañía. A diferencia de la mayoría de los rastreadores de IA, Applebot puede renderizar JavaScript, dándole capacidades similares a Googlebot.
Cómo difieren los rastreadores de IA de Googlebot
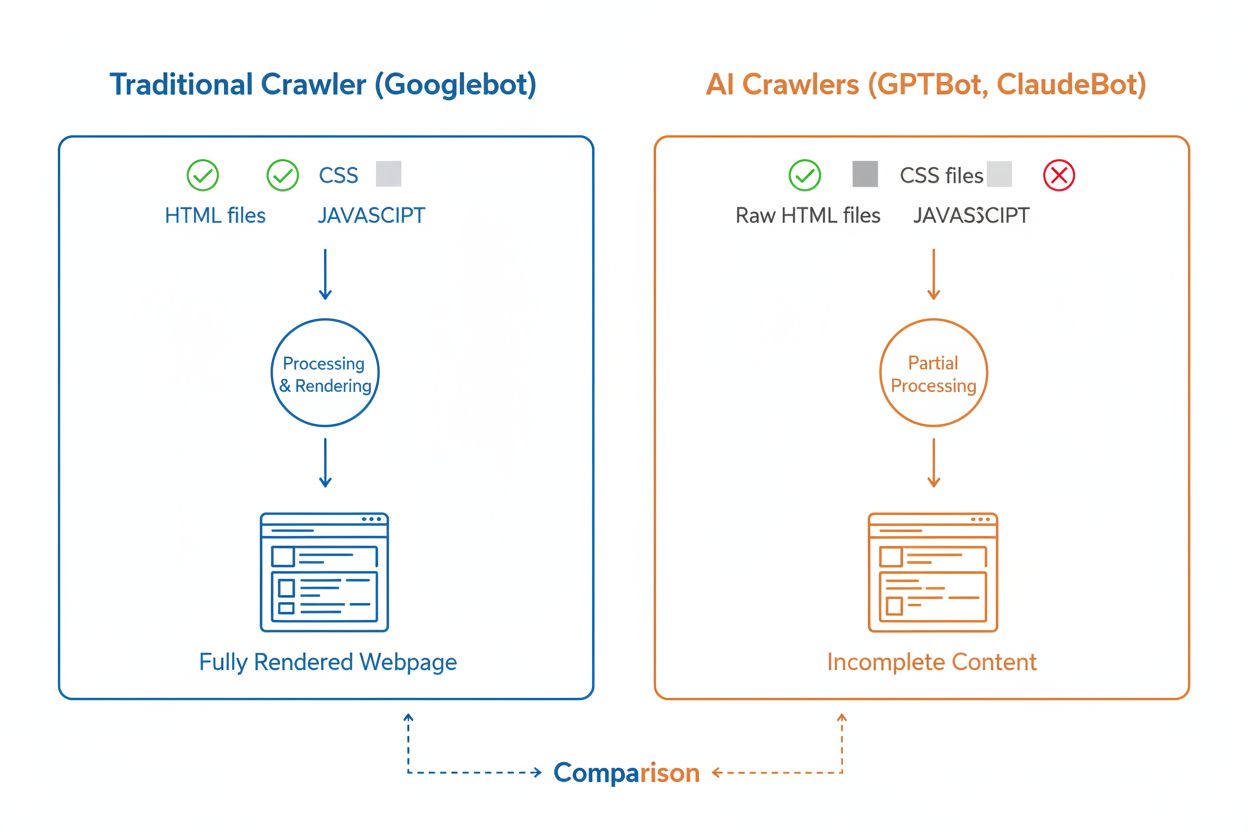
Aunque los rastreadores de IA y los rastreadores tradicionales como Googlebot navegan sistemáticamente por la web, sus capacidades técnicas y comportamientos difieren significativamente de maneras que impactan directamente en cómo se descubre y comprende tu contenido. La diferencia más crítica es el renderizado de JavaScript: Googlebot puede ejecutar JavaScript después de descargar una página, permitiéndole ver contenido cargado dinámicamente, mientras que la mayoría de los rastreadores de IA (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) solo leen el HTML bruto e ignoran cualquier contenido dependiente de JavaScript. Esto significa que si tu sitio depende del renderizado del lado del cliente para mostrar información clave, los rastreadores de IA verán una versión incompleta de tus páginas. Además, los rastreadores de IA muestran patrones de rastreo menos predecibles en comparación con el enfoque sistemático de Googlebot: pasan el 34.82% de las solicitudes en páginas 404 y el 14.36% siguiendo redirecciones, frente al más eficiente 8.22% de Googlebot en 404 y 1.49% en redirecciones. La frecuencia de rastreo también difiere: mientras Googlebot visita páginas según un sofisticado sistema de presupuesto de rastreo, los rastreadores de IA parecen rastrear más a menudo pero menos sistemáticamente, con investigaciones que muestran que algunos rastreadores de IA visitan páginas más de 100 veces más que Google en ciertos casos. Estas diferencias significan que las estrategias tradicionales de SEO pueden no abordar completamente la rastreabilidad para IA, requiriendo un enfoque distinto enfocado en el renderizado del lado del servidor y estructuras de URL limpias.
Limitaciones en el renderizado de JavaScript
Uno de los desafíos técnicos más significativos para los rastreadores de IA es su incapacidad para renderizar JavaScript, limitación que surge del alto costo computacional de ejecutar JavaScript a la escala masiva requerida para entrenar grandes modelos de lenguaje. Cuando un rastreador descarga tu página web, recibe la respuesta HTML inicial, pero cualquier contenido cargado o modificado por JavaScript—como detalles de productos, precios, reseñas de usuarios o elementos de navegación dinámica—permanece invisible para los rastreadores de IA. Esto crea un problema crítico para sitios web modernos que dependen en gran medida de frameworks de renderizado del lado del cliente como React, Vue o Angular sin renderizado del lado del servidor (SSR) o generación de sitio estático (SSG). Por ejemplo, un sitio de e-commerce que carga información de productos mediante JavaScript aparecerá para los rastreadores de IA como una página vacía sin detalles de productos, haciendo imposible que los sistemas de IA comprendan o citen ese contenido. La solución es asegurarse de que todo el contenido crítico se sirva en la respuesta HTML inicial mediante renderizado del lado del servidor, que genera el HTML completo en el servidor antes de enviarlo al navegador. Este enfoque asegura que tanto los visitantes humanos como los rastreadores de IA reciban la misma experiencia rica en contenido. Los sitios que utilizan frameworks modernos como Next.js con SSR, generadores estáticos como Hugo o Gatsby, o plataformas tradicionales como WordPress, son naturalmente amigables para los rastreadores de IA, mientras que aquellos que dependen solo del renderizado del lado del cliente enfrentan grandes retos de visibilidad en la búsqueda de IA.
Frecuencia y patrones de rastreo
Los rastreadores de IA muestran patrones de frecuencia de rastreo distintos a los de Googlebot, con implicaciones importantes sobre la rapidez con la que tu contenido es recogido por los sistemas de IA. Las investigaciones muestran que rastreadores de IA como ChatGPT y Perplexity suelen visitar las páginas más a menudo que Google en el corto plazo tras la publicación—en algunos casos, visitando las páginas 8 veces más que Googlebot en los primeros días. Este rápido rastreo inicial sugiere que las plataformas de IA priorizan descubrir e indexar contenido nuevo rápidamente, probablemente para garantizar que sus modelos y funciones de búsqueda tengan acceso a la información más reciente. Sin embargo, este rastreo agresivo inicial es seguido por un patrón en el que los rastreadores de IA pueden no volver si el contenido no cumple con los estándares de calidad, haciendo que esa primera impresión sea crucial. A diferencia de Googlebot, que tiene un sofisticado sistema de presupuesto de rastreo y volverá a las páginas regularmente según la frecuencia de actualización e importancia, los rastreadores de IA parecen tomar decisiones rápidas sobre si vale la pena volver al contenido. Esto significa que si un rastreador de IA visita tu página y encuentra contenido pobre, errores técnicos o señales negativas de experiencia de usuario, puede pasar mucho tiempo antes de que regrese—si es que regresa. La implicación para los creadores de contenido es clara: no puedes confiar en una segunda oportunidad para optimizar el contenido para los rastreadores de IA como podría ocurrir con los motores de búsqueda tradicionales, por lo que la garantía de calidad antes de publicar es esencial.
robots.txt y control de rastreadores de IA
Los propietarios de sitios web pueden utilizar el archivo robots.txt para comunicar sus preferencias sobre el acceso de rastreadores de IA, aunque la efectividad y aplicación de estas reglas varía considerablemente entre distintos rastreadores. Según datos recientes, aproximadamente el 14% de los 10,000 principales sitios web han implementado reglas específicas de permiso o bloqueo para bots de IA en sus archivos robots.txt. GPTBot es el rastreador más bloqueado, con 312 dominios (250 totalmente, 62 parcialmente) que lo prohíben explícitamente, aunque también es el más permitido explícitamente con 61 dominios otorgando acceso. Otros rastreadores comúnmente bloqueados incluyen CCBot (Common Crawl) y Google-Extended (el token de entrenamiento de IA de Google). El reto de robots.txt es que el cumplimiento es voluntario—los rastreadores respetan estas reglas solo si sus operadores deciden implementarlas, y algunos rastreadores nuevos o menos transparentes pueden no respetar las directivas de robots.txt. Además, los tokens de robots.txt como “Google-Extended” no corresponden directamente a cadenas de agente de usuario en las solicitudes HTTP; en cambio, indican el propósito del rastreo, por lo que no siempre puedes verificar el cumplimiento mediante registros del servidor. Para una aplicación más fuerte, los propietarios de sitios recurren cada vez más a reglas de firewall y cortafuegos de aplicaciones web (WAF) que pueden bloquear activamente agentes de usuario de rastreadores específicos, proporcionando un control más confiable que solo robots.txt. Este cambio hacia mecanismos de bloqueo activos refleja la creciente preocupación por los derechos sobre el contenido y el deseo de controles más exigibles sobre el acceso de rastreadores de IA.
Monitorización de la actividad de rastreadores de IA
Rastrear la actividad de rastreadores de IA en tu sitio web es esencial para comprender tu visibilidad en la búsqueda de IA, pero presenta desafíos únicos en comparación con el monitoreo de rastreadores de motores de búsqueda tradicionales. Las herramientas de análisis tradicionales como Google Analytics dependen del seguimiento con JavaScript, que los rastreadores de IA no ejecutan, por lo que estas herramientas no ofrecen visibilidad sobre las visitas de bots de IA. De igual manera, el seguimiento mediante píxeles no funciona porque la mayoría de los rastreadores de IA solo procesan texto e ignoran las imágenes. La única forma confiable de rastrear la actividad de rastreadores de IA es a través de la monitorización del lado del servidor—analizando los encabezados de solicitudes HTTP y los registros del servidor para identificar los agentes de usuario de los rastreadores antes de que la página sea entregada. Esto requiere análisis manual de registros o herramientas especializadas diseñadas específicamente para identificar y rastrear el tráfico de rastreadores de IA. El monitoreo en tiempo real es especialmente crucial porque los rastreadores de IA operan en horarios impredecibles y pueden no regresar a las páginas si encuentran problemas, por lo que una auditoría semanal o mensual puede perder problemas importantes. Si un rastreador de IA visita tu sitio y encuentra un error técnico o mala calidad de contenido, puede que no tengas otra oportunidad para causar una buena impresión. Implementar soluciones de monitorización 24/7 que te alerten de inmediato cuando los rastreadores de IA encuentren problemas—como errores 404, tiempos de carga lentos o ausencia de marcado schema—te permite solucionar los problemas antes de que afecten tu visibilidad en la búsqueda de IA. Este enfoque en tiempo real representa un cambio fundamental respecto a las prácticas tradicionales de monitoreo SEO, reflejando la velocidad e imprevisibilidad del comportamiento de los rastreadores de IA.
Optimización para rastreadores de IA
Optimizar tu sitio web para los rastreadores de IA requiere un enfoque distinto al SEO tradicional, enfocándose en factores técnicos que impactan directamente en cómo los sistemas de IA pueden acceder y comprender tu contenido. La primera prioridad es el renderizado del lado del servidor: asegúrate de que todo el contenido crítico—títulos, cuerpo de texto, metadatos, datos estructurados—esté incluido en la respuesta HTML inicial en vez de cargarse dinámicamente mediante JavaScript. Esto aplica a tu página principal, páginas de destino clave y cualquier contenido que quieras que los sistemas de IA citen o referencien. En segundo lugar, implementa marcado de datos estructurados (Schema.org) en tus páginas de mayor impacto, incluyendo schema de artículo para blogs, schema de producto para e-commerce y schema de autor para establecer experiencia y autoridad. Los rastreadores de IA usan los datos estructurados para comprender rápidamente la jerarquía y contexto del contenido, facilitando su análisis y citación. En tercer lugar, mantén altos estándares de calidad de contenido en todas las páginas, ya que los rastreadores de IA parecen tomar decisiones rápidas sobre si vale la pena indexar y citar tu contenido. Esto significa asegurar que tu contenido sea original, bien investigado, preciso y aporte verdadero valor al lector. En cuarto lugar, monitoriza y optimiza los Core Web Vitals y el rendimiento general de la página, ya que los tiempos de carga lentos indican mala experiencia de usuario y pueden desincentivar que los rastreadores de IA regresen. Finalmente, mantén una estructura de URL limpia y consistente, un sitemap XML actualizado y asegúrate de que tu archivo robots.txt esté correctamente configurado para guiar a los rastreadores hacia tu contenido más importante. Estas optimizaciones técnicas crean una base que hace que tu contenido sea descubrible, comprensible y citable por sistemas de IA.
El futuro de los rastreadores de IA
El panorama de los rastreadores de IA seguirá evolucionando rápidamente a medida que la competencia se intensifique entre empresas de IA y la tecnología madure. Una tendencia clara es la concentración de cuota de mercado en torno a las plataformas más exitosas—GPTBot de OpenAI ha surgido como la fuerza dominante, mientras que nuevos participantes como Meta-ExternalAgent están escalando rápidamente, lo que sugiere que el mercado probablemente se estabilizará alrededor de unos pocos actores principales. A medida que los rastreadores de IA maduren, podemos esperar mejoras en sus capacidades técnicas, particularmente en el renderizado de JavaScript y patrones de rastreo más eficientes que reduzcan solicitudes desperdiciadas en páginas 404 y contenido desactualizado. La industria también avanza hacia protocolos de comunicación más estandarizados, como la emergente especificación llms.txt, que permite a los sitios web comunicar explícitamente su estructura de contenido y preferencias de rastreo a los sistemas de IA. Además, los mecanismos de control para el acceso de rastreadores de IA se están volviendo más sofisticados, con plataformas como Cloudflare que ahora ofrecen bloqueo automático de bots de entrenamiento de IA por defecto, dando a los propietarios de sitios un control más granular sobre su contenido. Para los creadores de contenido y propietarios de sitios web, mantenerse a la vanguardia de estos cambios implica monitorizar continuamente la actividad de los rastreadores de IA, mantener la infraestructura técnica optimizada para la accesibilidad de IA y adaptar la estrategia de contenido considerando que los sistemas de IA representan ahora una porción significativa del tráfico de tu sitio y un canal crítico para la visibilidad de tu marca. El futuro pertenece a quienes comprendan y optimicen para este nuevo ecosistema de rastreadores.
Preguntas frecuentes
¿Qué es un rastreador de IA y en qué se diferencia de un rastreador de motores de búsqueda?
Los rastreadores de IA son programas automatizados que recopilan datos web específicamente para entrenar y mejorar modelos de inteligencia artificial como ChatGPT y Claude. A diferencia de los rastreadores de motores de búsqueda tradicionales como Googlebot, que indexan contenido para los resultados de búsqueda, los rastreadores de IA recopilan datos web en bruto para alimentar grandes modelos de lenguaje. Ambos tipos de rastreadores navegan sistemáticamente por Internet, pero cumplen diferentes propósitos y tienen diferentes capacidades técnicas.
¿Por qué los rastreadores de IA necesitan acceder a mi sitio web?
Los rastreadores de IA acceden a tu sitio web para recopilar datos que permitan entrenar modelos de IA, mejorar funciones de búsqueda y fundamentar las respuestas de IA con información actual. Cuando sistemas de IA como ChatGPT o Perplexity responden preguntas de usuarios, a menudo necesitan obtener tu contenido en tiempo real para proporcionar información precisa y citada. Permitir el acceso de los rastreadores de IA a tu sitio aumenta las posibilidades de que tu marca sea mencionada y citada en respuestas generadas por IA.
¿Puedo bloquear a los rastreadores de IA para que no accedan a mi sitio?
Sí, puedes utilizar tu archivo robots.txt para bloquear rastreadores de IA específicos indicando sus nombres de agente de usuario. Sin embargo, cumplir con robots.txt es voluntario y no todos los rastreadores respetan estas reglas. Para una aplicación más estricta, puedes usar reglas de firewall y cortafuegos de aplicaciones web (WAF) para bloquear activamente agentes de usuario de rastreadores específicos. Esto te da un control más confiable sobre qué rastreadores de IA pueden acceder a tu contenido.
¿Los rastreadores de IA procesan JavaScript como lo hace Google?
No, la mayoría de los rastreadores de IA (GPTBot, ClaudeBot, Meta-ExternalAgent) no ejecutan JavaScript. Solo leen el HTML bruto de tus páginas, lo que significa que cualquier contenido cargado dinámicamente mediante JavaScript será invisible para ellos. Por eso el renderizado del lado del servidor es fundamental para la rastreabilidad por IA. Si tu sitio depende del renderizado del lado del cliente, los rastreadores de IA verán una versión incompleta de tus páginas.
¿Con qué frecuencia visitan los rastreadores de IA los sitios web?
Los rastreadores de IA visitan los sitios web con más frecuencia que los motores de búsqueda tradicionales en el corto plazo tras la publicación de contenido. La investigación muestra que pueden visitar páginas de 8 a 100 veces más que Google en los primeros días. Sin embargo, si el contenido no cumple con los estándares de calidad, puede que no vuelvan. Esto hace que la primera impresión sea crítica: puede que no tengas una segunda oportunidad para optimizar el contenido para los rastreadores de IA.
¿Cuál es la mejor manera de optimizar mi sitio para los rastreadores de IA?
Las optimizaciones clave son: (1) Utilizar renderizado del lado del servidor para asegurar que el contenido crítico esté en el HTML inicial, (2) Añadir marcado de datos estructurados (Schema) para ayudar a la IA a entender tu contenido, (3) Mantener alta calidad y actualidad del contenido, (4) Monitorizar los Core Web Vitals para una buena experiencia de usuario, y (5) Mantener una estructura de URL limpia y un sitemap actualizado. Estas optimizaciones técnicas crean una base que hace que tu contenido sea descubrible y citable por sistemas de IA.
¿Qué rastreador de IA es más importante para mi sitio web?
GPTBot de OpenAI es actualmente el rastreador de IA dominante, capturando el 30% de todo el tráfico de rastreadores de IA y creciendo un 305% año tras año. Sin embargo, deberías optimizar para todos los principales rastreadores, incluidos ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) y otros. Las distintas plataformas de IA tienen diferentes bases de usuarios, así que la visibilidad en varios rastreadores maximiza la presencia de tu marca en la búsqueda de IA.
¿Cómo puedo rastrear la actividad de rastreadores de IA en mi sitio web?
Las herramientas de análisis tradicionales como Google Analytics no capturan la actividad de rastreadores de IA porque dependen del seguimiento con JavaScript. En su lugar, necesitas monitorización del lado del servidor que analice los encabezados de las solicitudes HTTP y los registros del servidor para identificar los agentes de usuario de rastreadores. Herramientas especializadas diseñadas para el seguimiento de rastreadores de IA ofrecen visibilidad en tiempo real sobre qué páginas están siendo rastreadas, con qué frecuencia y si los rastreadores encuentran problemas técnicos.
Monitorea la visibilidad de tu marca en la búsqueda de IA
Rastrea cómo los rastreadores de IA como GPTBot y ClaudeBot acceden y citan tu contenido. Obtén información en tiempo real sobre tu visibilidad en búsquedas de IA con AmICited.
¿A qué rastreadores de IA debo permitir el acceso? Guía completa para 2025
Descubre qué rastreadores de IA permitir o bloquear en tu robots.txt. Guía completa que cubre GPTBot, ClaudeBot, PerplexityBot y más de 25 rastreadores de IA co...
¿Deberías Bloquear o Permitir Rastreadores de IA? Marco de Decisión
Aprende cómo tomar decisiones estratégicas sobre el bloqueo de rastreadores de IA. Evalúa el tipo de contenido, las fuentes de tráfico, los modelos de ingresos ...
Cómo identificar rastreadores de IA en los registros del servidor: Guía completa de detección
Aprende a identificar y monitorear rastreadores de IA como GPTBot, PerplexityBot y ClaudeBot en los registros de tu servidor. Descubre cadenas de user-agent, mé...
10 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.