Cómo la IA comprende las entidades: Análisis técnico en profundidad
Explora cómo los sistemas de IA reconocen y procesan entidades en el texto. Aprende sobre modelos NER, arquitecturas de transformers y aplicaciones reales de la comprensión de entidades.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
La comprensión de entidades se ha convertido en una capacidad fundamental en los sistemas modernos de inteligencia artificial, permitiendo que las máquinas identifiquen y comprendan los actores clave, lugares y conceptos dentro de texto no estructurado. Desde impulsar motores de búsqueda que comprenden la intención del usuario hasta habilitar chatbots capaces de responder preguntas complejas sobre personas y organizaciones específicas, el reconocimiento de entidades constituye la base de una interacción significativa entre humanos y computadoras. Esta capacidad técnica es crítica en todas las industrias: las instituciones financieras la utilizan para el monitoreo de cumplimiento, los sistemas de salud la aprovechan para la gestión de registros de pacientes y las plataformas de comercio electrónico dependen de ella para entender menciones de productos y opiniones de clientes. Comprender cómo los sistemas de IA extraen e interpretan entidades es esencial para cualquiera que construya o implemente aplicaciones de PLN en entornos de producción.
Conceptos fundamentales: ¿Qué son las entidades?
El Reconocimiento de Entidades Nombradas (NER) es la tarea de PLN que identifica y clasifica entidades nombradas—unidades específicas y significativas de información—dentro del texto en categorías predefinidas. Estas entidades representan los sujetos concretos que cargan el peso semántico en el lenguaje: personas que realizan acciones, organizaciones que toman decisiones, ubicaciones donde ocurren eventos, expresiones temporales que anclan los eventos en el tiempo, valores monetarios que cuantifican transacciones y productos que se compran y venden. La clasificación de entidades es importante porque transforma texto sin procesar en conocimiento estructurado sobre el que las máquinas pueden razonar y actuar; sin ella, un sistema no puede distinguir entre “Apple la empresa” y “apple la fruta”, ni entender que “John Smith” y “J. Smith” se refieren a la misma persona. La capacidad de clasificar entidades con precisión habilita aplicaciones posteriores como la construcción de gráficos de conocimiento, extracción de información, respuesta a preguntas y detección de relaciones.
Tipo de entidad
Definición
Ejemplo
PERSONA
Seres humanos individuales
“Steve Jobs”, “Marie Curie”
ORGANIZACIÓN
Empresas, instituciones, grupos
“Microsoft”, “Naciones Unidas”, “Universidad de Harvard”
UBICACIÓN
Lugares y regiones geográficas
“Nueva York”, “Río Amazonas”, “Silicon Valley”
FECHA
Expresiones temporales y períodos de tiempo
“15 de enero de 2024”, “el próximo martes”, “T3 2023”
DINERO
Valores monetarios y monedas
“$50 millones”, “€100”, “5000 yen”
PRODUCTO
Bienes, servicios y creaciones
“iPhone 15”, “Windows 11”, “ChatGPT”
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Arquitectura técnica: Cómo procesa entidades la IA
Los sistemas modernos de IA procesan entidades mediante un sofisticado pipeline de múltiples etapas que comienza con la tokenización, dividiendo el texto en bruto en tokens discretos que sirven como unidades fundamentales para el procesamiento posterior. Cada token se convierte en una representación numérica mediante embeddings de palabras—vectores densos que capturan significado semántico—que se introducen en arquitecturas de redes neuronales diseñadas para comprender contexto y relaciones. Los modelos basados en transformers, que se han convertido en la arquitectura dominante en PLN contemporáneo, procesan secuencias completas en paralelo en lugar de secuencialmente, permitiendo capturar dependencias de largo alcance y relaciones contextuales complejas cruciales para una comprensión precisa de entidades. El mecanismo de self-attention dentro de los Transformers permite que cada token valore dinámicamente la importancia de todos los demás tokens en la secuencia, creando representaciones contextuales ricas donde el significado de una palabra se ve influenciado por su contexto; por eso “banco” se entiende de forma diferente en “banco del río” frente a “banco de ahorros”. Los modelos de lenguaje preentrenados como BERT y GPT aprenden patrones lingüísticos generales a partir de enormes corpus de texto antes de ser ajustados para tareas de reconocimiento de entidades, lo que les permite aprovechar representaciones aprendidas de sintaxis, semántica y conocimiento del mundo. La capa final de los sistemas de reconocimiento de entidades suele emplear un enfoque de etiquetado de secuencia—a menudo implementado como un Conditional Random Field (CRF) o una simple cabeza de clasificación—que asigna etiquetas de entidad a cada token en base a las representaciones contextuales aprendidas por la red neuronal. Esta arquitectura permite a los sistemas de IA comprender no solo qué entidades están presentes, sino cómo se relacionan entre sí y qué roles juegan dentro del contexto más amplio del texto.
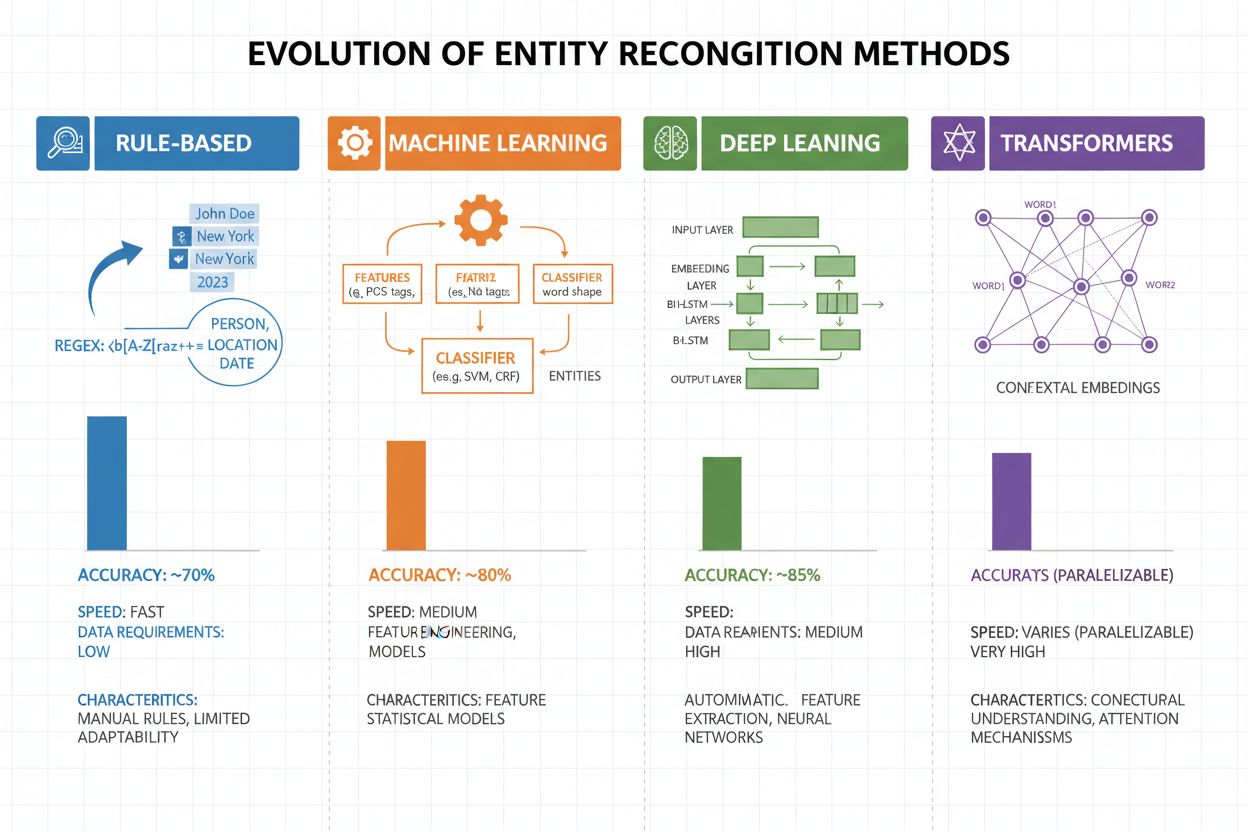
Evolución de los métodos de reconocimiento de entidades
El reconocimiento de entidades ha evolucionado drásticamente en las dos últimas décadas, pasando de enfoques sencillos basados en reglas a sofisticadas arquitecturas neuronales. Los primeros sistemas dependían de reglas y diccionarios hechos a mano, usando expresiones regulares y coincidencia de patrones para identificar entidades—métodos interpretables y que requerían pocos datos de entrenamiento, pero con baja capacidad de generalización y alto coste de mantenimiento. Con la llegada del aprendizaje automático surgieron enfoques supervisados como Support Vector Machines (SVM) y Conditional Random Fields (CRF), que aprendían a partir de datos etiquetados mediante ingeniería de características, mejorando significativamente la precisión aunque seguían requiriendo expertos para diseñar características significativas. Los métodos de deep learning, especialmente LSTM y BiLSTM, automatizaron la extracción de características aprendiendo representaciones directamente del texto, logrando una precisión mucho mayor sin ingeniería manual pero demandando conjuntos de datos etiquetados más grandes. Los modelos basados en transformers como BERT y RoBERTa revolucionaron el campo aprovechando el self-attention para capturar dependencias de largo alcance y matices contextuales, alcanzando resultados de vanguardia (BERT logró un 90,9% F1 en CoNLL-2003) y permitiendo el aprendizaje por transferencia desde modelos preentrenados masivos. El equilibrio entre complejidad y precisión ha cambiado drásticamente: aunque los sistemas basados en reglas todavía son valiosos para entornos con recursos limitados o dominios muy especializados, los transformers dominan cuando hay recursos computacionales y datos etiquetados suficientes, con alternativas ligeras como DistilBERT como opción intermedia para sistemas en producción con restricciones de latencia.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Modelos transformer y enfoques modernos
Los modelos basados en transformers han transformado fundamentalmente el reconocimiento de entidades al reemplazar el procesamiento secuencial por mecanismos de self-attention paralelos que consideran simultáneamente todos los tokens de una oración, permitiendo una comprensión contextual mucho más rica que las arquitecturas anteriores. BERT y sus variantes (RoBERTa, DistilBERT, ALBERT) aprovechan el preentrenamiento bidireccional en grandes corpus no etiquetados, aprendiendo representaciones universales del lenguaje que capturan información sintáctica y semántica antes de ser ajustados para tareas NER con conjuntos pequeños de datos etiquetados. El paradigma de preentrenamiento y ajuste fino es especialmente potente para el reconocimiento de entidades: los modelos preentrenados en miles de millones de tokens desarrollan representaciones robustas de la estructura del lenguaje y patrones de entidades, que luego pueden adaptarse a dominios específicos con solo miles de ejemplos etiquetados, reduciendo drásticamente la necesidad de datos en comparación con entrenar desde cero. Los transformers sobresalen en la comprensión de entidades gracias a su mecanismo de atención multi-cabeza, donde diferentes cabezas de atención se especializan en distintos tipos de relaciones entre entidades—algunas se centran en los límites sintácticos y otras capturan asociaciones semánticas entre entidades y sus contextos. El reconocimiento de entidades multilingüe ha sido revolucionado por modelos como mBERT y XLM-RoBERTa, preentrenados en más de 100 idiomas, permitiendo transferencias zero-shot y few-shot a lenguas con pocos recursos y vinculación cruzada de entidades. Modelos emergentes como GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) llevan los límites aún más lejos permitiendo el reconocimiento de entidades basado en instrucciones, donde los modelos pueden identificar cualquier tipo de entidad especificado en prompts de lenguaje natural sin ajuste específico para cada tarea, representando un cambio hacia sistemas de comprensión de entidades más flexibles y generalizables.
Desafíos en la comprensión de entidades
A pesar del avance notable, los sistemas de reconocimiento de entidades enfrentan desafíos persistentes en el mundo real que limitan su despliegue práctico, siendo la ambigüedad y la sensibilidad al contexto de los más difíciles de abordar: la palabra “Apple” requiere comprender si se refiere a la fruta o a la empresa tecnológica según el contexto, y hasta los modelos más avanzados fallan en la desambiguación semántica en textos ruidosos o ambiguos. Las entidades fuera de vocabulario (OOV) suponen otro desafío fundamental: los modelos entrenados en conjuntos estándar pueden no encontrar nunca entidades raras, nombres propios emergentes o variantes mal escritas, haciendo que las clasifiquen mal o no las reconozcan. La adaptación al dominio sigue siendo problemática porque los modelos entrenados en corpus de noticias (como CoNLL-2003) suelen funcionar mal en textos biomédicos, legales o de redes sociales, donde la distribución de entidades y los patrones lingüísticos difieren mucho, requiriendo costosa re-rotulación y ajuste en cada nuevo dominio. Los errores de detección de límites—cuando el sistema identifica que existe una entidad pero determina mal su inicio o fin—son especialmente frecuentes en entidades de varias palabras y estructuras anidadas, como distinguir “Ciudad de Nueva York” de “Nueva York” o manejar entidades como “Director Ejecutivo de Apple Inc.” Las complejidades multilingües agravan estos desafíos, pues cada idioma tiene convenciones de mayúsculas, estructuras morfológicas y patrones de nombramiento distintos, haciendo que los modelos entrenados en inglés fallen al aplicarse en lenguas con propiedades diferentes. La escasez de datos en dominios especializados como nombres de enfermedades raras, tecnologías emergentes o terminología empresarial crea un cuello de botella donde el coste de la anotación manual es prohibitivo, forzando a elegir entre aceptar menor precisión o invertir mucho en recolección de datos específicos.
Aplicaciones y casos de uso en el mundo real
La comprensión de entidades se ha vuelto indispensable en todas las industrias, transformando cómo las organizaciones extraen valor del texto no estructurado. En extracción de información y construcción de gráficos de conocimiento, el reconocimiento de entidades permite poblar automáticamente bases de datos estructuradas a partir de documentos, impulsando motores de búsqueda y sistemas de recomendación que comprenden relaciones entre personas, lugares y conceptos. Las organizaciones de salud aprovechan la comprensión de entidades para identificar nombres de medicamentos, dosis, síntomas y datos demográficos de pacientes en notas clínicas, mejorando la toma de decisiones clínicas y permitiendo sistemas de farmacovigilancia que detectan interacciones adversas a gran escala. Las instituciones financieras utilizan el reconocimiento de entidades para extraer símbolos bursátiles, valores monetarios y eventos de mercado de fuentes de noticias e informes de resultados, permitiendo que sistemas de trading algorítmico y plataformas de gestión de riesgos reaccionen a información relevante en tiempo real. Las firmas de tecnología legal aplican la comprensión de entidades para identificar automáticamente partes, fechas, obligaciones y cláusulas de responsabilidad en contratos, reduciendo de semanas a horas el tiempo de revisión documental. Las plataformas de atención al cliente y chatbots emplean el reconocimiento de entidades para extraer intenciones del usuario y contexto relevante—como números de pedido, nombres de productos y tipos de incidencias—permitiendo una mejor asignación y resolución más rápida. Las plataformas de comercio electrónico usan la comprensión de entidades para identificar nombres de productos, marcas, características y especificaciones en reseñas y búsquedas, mejorando el descubrimiento de productos y la personalización. Los sistemas de recomendación de contenido utilizan el reconocimiento de entidades para entender con qué entidades interactúan los usuarios, permitiendo recomendaciones colaborativas y basadas en contenido más sofisticadas que impulsan la participación y los ingresos.
Implementación de sistemas de comprensión de entidades
Implementar un sistema de comprensión de entidades de calidad productiva requiere especial atención a la preparación de los datos, selección de modelo y evaluación. Comienza con datos anotados de alta calidad: establece definiciones claras de tipos de entidad, usa métricas de acuerdo entre anotadores para asegurar consistencia y apunta a al menos 500-1000 ejemplos etiquetados por tipo de entidad, aunque las aplicaciones de dominio específico pueden requerir más. La selección del modelo depende de tus restricciones: los sistemas basados en reglas ofrecen interpretabilidad y baja latencia en dominios bien definidos, los modelos tradicionales de machine learning (CRF, SVM) brindan buen rendimiento con datos moderados, mientras que los modelos basados en transformers (BERT, RoBERTa) logran precisión de vanguardia pero requieren más recursos computacionales y datos. Las estrategias de entrenamiento y ajuste fino deben incluir técnicas de aumento de datos para manejar el desbalance de clases, validación cruzada para prevenir sobreajuste y un ajuste cuidadoso de hiperparámetros como tasa de aprendizaje y tamaño de lote. Evalúa tu sistema usando precisión (entidades correctas identificadas), recall (entidades encontradas sobre el total existente) y F1-score (media armónica que equilibra ambas), con métricas separadas por tipo de entidad para identificar debilidades. Las consideraciones de despliegue incluyen requisitos de latencia (procesamiento por lotes vs. en tiempo real), necesidades de escalabilidad e integración con pipelines de datos existentes, mientras que el monitoreo post-despliegue debe rastrear deriva de rendimiento, tasas de falsos positivos y feedback de usuarios para activar ciclos de re-entrenamiento.
Herramientas y frameworks para reconocimiento de entidades
El ecosistema de herramientas para la comprensión de entidades ofrece soluciones para todos los tamaños y casos de uso. Librerías open-source como spaCy ofrecen pipelines NER listos para producción con un rendimiento impresionante (89,22% F1-score en benchmarks estándar) y excelente documentación, lo que la hace ideal para equipos con experiencia en machine learning; NLTK aporta valor educativo y capacidades básicas de NER; y Hugging Face Transformers brinda acceso a modelos preentrenados de última generación que pueden ajustarse a dominios específicos con poco código. Servicios gestionados en la nube eliminan preocupaciones de infraestructura: Google Cloud Natural Language API, AWS Comprehend e IBM Watson NLP ofrecen reconocimiento de entidades preentrenado con soporte para múltiples idiomas y tipos de entidad, gestionando el escalado automáticamente e integrándose fácilmente con pipelines en la nube. Frameworks especializados como Flair (basado en PyTorch, con excelente soporte para etiquetado de secuencias) y DeepPavlov (con modelos preentrenados para múltiples idiomas y dominios) atienden a investigadores y equipos que necesitan mayor personalización que las librerías generalistas. La decisión entre soluciones personalizadas y herramientas preconstruidas depende de la sensibilidad de tus datos (on-premise vs. cloud), los niveles de precisión requeridos, la especificidad del dominio y la experiencia del equipo: usa APIs gestionadas para aplicaciones generales con tipos estándar de entidades, opta por librerías open-source para personalización en dominios internos y construye modelos propios solo cuando las soluciones existentes no alcancen tus requisitos de precisión o latencia.
Tendencias futuras en la comprensión de entidades
El futuro de la comprensión de entidades está siendo definido por grandes modelos de lenguaje que ofrecen una flexibilidad y rendimiento sin precedentes para esta tarea. Modelos como GPT-4 y Claude demuestran notables capacidades de reconocimiento de entidades con pocos o ningún ejemplo, permitiendo identificar tipos de entidad personalizados con solo unos pocos ejemplos o incluso descripciones en lenguaje natural, reduciendo drásticamente la carga de anotación y acelerando el retorno de valor. La comprensión multimodal de entidades emerge como una frontera, combinando texto, imágenes y datos estructurados para reconocer entidades en documentos, facturas y páginas web con mayor contexto, habilitando aplicaciones como procesamiento automático de documentos y búsqueda visual. Las mejoras en procesamiento en tiempo real impulsadas por la destilación de modelos y el despliegue en edge hacen que el reconocimiento de entidades sofisticado sea factible en dispositivos móviles y sistemas IoT, abriendo nuevas aplicaciones en realidad aumentada, traducción en tiempo real y sistemas autónomos. Los avances en fine-tuning específico de dominio están creando modelos especializados para los sectores biomédico, legal y financiero que superan en órdenes de magnitud a los modelos generalistas, con técnicas como preentrenamiento adaptativo por dominio y transfer learning haciendo esto cada vez más accesible. A medida que estas tecnologías maduren, la comprensión de entidades se convertirá en una capa fundamental invisible en los sistemas de IA, permitiendo que las máquinas comprendan el mundo con entendimiento semántico similar al humano y abriendo posibilidades que apenas comenzamos a imaginar.
Por qué la comprensión de entidades es clave para el monitoreo de IA
A medida que sistemas de IA como ChatGPT, Perplexity y Google AI Overviews se integran cada vez más en la forma en que se descubre y consume información, entender cómo estos sistemas reconocen y referencian entidades—including tu marca—se vuelve fundamental. La comprensión de entidades es el mecanismo por el cual los sistemas de IA identifican y procesan menciones de empresas, productos, personas y conceptos. Cuando monitoreas cómo los sistemas de IA comprenden y mencionan tu marca a través del reconocimiento de entidades, obtienes información sobre:
Cómo se categoriza tu marca en los sistemas de IA (como empresa, producto o concepto)
Qué contexto asocian los sistemas de IA con tu marca
Con qué precisión los sistemas de IA identifican tu marca entre los competidores
Qué entidades se mencionan frecuentemente junto a tu marca
Esto es precisamente lo que AmICited monitoriza: rastrear cómo los sistemas de IA reconocen y referencian tu marca como entidad en múltiples plataformas de IA. Al comprender el reconocimiento de entidades, puedes entender mejor cómo los sistemas de IA perciben y comunican información sobre tu negocio.
Preguntas frecuentes
¿Cuál es la diferencia entre reconocimiento de entidades y vinculación de entidades?
El reconocimiento de entidades (NER) identifica y clasifica entidades en el texto (por ejemplo, 'Apple' como ORGANIZACIÓN), mientras que la vinculación de entidades conecta esas entidades con bases de conocimiento o referencias canónicas (por ejemplo, vincular 'Apple' a la página de Wikipedia de Apple Inc.). El reconocimiento de entidades es el primer paso; la vinculación de entidades añade una base semántica.
¿Qué precisión tienen los sistemas modernos de reconocimiento de entidades?
Los modelos de última generación basados en transformers como BERT alcanzan un 90,9% de F1-score en benchmarks estándar como CoNLL-2003. Sin embargo, la precisión varía significativamente según el dominio: los modelos entrenados en noticias funcionan mal en textos biomédicos o de redes sociales. La precisión real depende en gran medida de la adaptación al dominio y la calidad de los datos.
¿Puede el reconocimiento de entidades funcionar en varios idiomas?
Sí, modelos multilingües como mBERT y XLM-RoBERTa soportan más de 100 idiomas simultáneamente. Sin embargo, el rendimiento varía según el idioma debido a las diferencias en mayúsculas, morfología y datos de entrenamiento disponibles. Los modelos específicos por idioma suelen superar a los multilingües en aplicaciones críticas.
¿Cuál es la diferencia entre el reconocimiento de entidades basado en reglas y en ML?
Los sistemas basados en reglas utilizan patrones y diccionarios hechos a mano (rápidos, interpretables, pero frágiles). Los sistemas basados en ML aprenden a partir de datos etiquetados (más flexibles, mejor generalización, pero requieren datos de entrenamiento e ingeniería de características). Los enfoques modernos de deep learning automatizan la extracción de características, logrando una precisión superior.
¿Cuántos datos de entrenamiento se necesitan para un reconocimiento de entidades personalizado?
Los sistemas basados en reglas solo necesitan definiciones de patrones. Los modelos tradicionales de ML requieren entre 300 y 500 ejemplos etiquetados. Los modelos basados en transformers funcionan con más de 800 ejemplos pero se benefician del aprendizaje por transferencia: los modelos preentrenados pueden lograr buenos resultados con solo 100-200 ejemplos específicos de dominio mediante fine-tuning.
¿Cuáles son los principales desafíos en la comprensión de entidades?
Los desafíos clave incluyen: ambigüedad (la misma palabra con diferentes significados), entidades fuera de vocabulario, adaptación al dominio (los modelos entrenados en un dominio fallan en otro), errores en la detección de límites, complejidades multilingües y escasez de datos para dominios especializados. Estos requieren un diseño cuidadoso del sistema y ajustes específicos por dominio.
¿Cómo afecta el contexto a la precisión del reconocimiento de entidades?
El contexto es crucial: 'banco' significa cosas diferentes en 'banco del río' vs. 'banco de ahorros'. Los transformers modernos usan self-attention para ponderar el contexto de todos los tokens circundantes, permitiéndoles desambiguar entidades en base al contexto lingüístico y semántico. Un manejo pobre del contexto es una fuente importante de errores en el reconocimiento de entidades.
¿Cuál es el futuro de la comprensión de entidades en IA?
Los desarrollos futuros incluyen: grandes modelos de lenguaje que permiten el reconocimiento de entidades sin ejemplos previos, comprensión multimodal combinando texto e imágenes, procesamiento en tiempo real en dispositivos edge y avances en fine-tuning específico de dominio. La comprensión de entidades se convertirá en una capa fundamental invisible que permitirá a las máquinas comprender el mundo con entendimiento semántico similar al humano.
Monitorea cómo la IA menciona tu marca
AmICited rastrea las menciones de entidades en sistemas de IA como ChatGPT, Perplexity y Google AI Overviews. Comprende cómo la IA entiende y referencia tu marca en tiempo real.
SEO de Entidades para Visibilidad en IA: Construyendo Presencia en Knowledge Graphs
Aprende cómo construir visibilidad de entidades en la búsqueda por IA. Domina la optimización de knowledge graphs, schema markup y estrategias de SEO de entidad...
¿Cómo entienden los sistemas de IA las relaciones entre entidades?
Descubre cómo los sistemas de IA identifican, extraen y comprenden las relaciones entre entidades en un texto. Conoce técnicas de extracción de relaciones entre...
Optimización de entidades para IA: haz que tu marca sea reconocible para los LLM
Aprende cómo la optimización de entidades ayuda a que tu marca sea reconocible para los LLM. Domina la optimización de gráficos de conocimiento, el marcado de e...
15 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.