Rastreadores de entrenamiento de IA vs rastreadores de búsqueda: Entendiendo la diferencia
Descubre las diferencias críticas entre los rastreadores de entrenamiento de IA y los rastreadores de búsqueda. Aprende cómo impactan la visibilidad de tu contenido, las estrategias de optimización y las citas de IA.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Los rastreadores de motores de búsqueda como Googlebot y Bingbot son la columna vertebral de las operaciones tradicionales de los motores de búsqueda. Estos bots automatizados navegan sistemáticamente por la web, descubriendo e indexando contenido para determinar qué aparece en las páginas de resultados de los motores de búsqueda (SERPs). Googlebot, operado por Google, es el rastreador de búsqueda más conocido y activo, seguido por Bingbot de Microsoft y YandexBot de Yandex. Estos rastreadores poseen capacidades sofisticadas que les permiten ejecutar JavaScript, renderizar contenido dinámico y comprender estructuras web complejas. Visitan sitios web frecuentemente en función de factores como la autoridad del sitio, la frescura del contenido y el historial de actualizaciones, siendo los sitios de alta autoridad rastreados con mayor frecuencia. El objetivo principal de los rastreadores de búsqueda es indexar contenido con fines de clasificación, lo que significa que evalúan las páginas según relevancia, calidad y señales de experiencia de usuario.
Tipo de rastreador
Propósito principal
Soporte de JavaScript
Frecuencia de rastreo
Objetivo
Googlebot
Indexar para rankings de búsqueda
Sí (con limitaciones)
Frecuente, según autoridad
Ranking y visibilidad
Bingbot
Indexar para rankings de búsqueda
Sí (con limitaciones)
Regular, según actualizaciones de contenido
Ranking y visibilidad
YandexBot
Indexar para rankings de búsqueda
Sí (con limitaciones)
Regular, según señales del sitio
Ranking y visibilidad
¿Qué son los rastreadores de entrenamiento de IA?
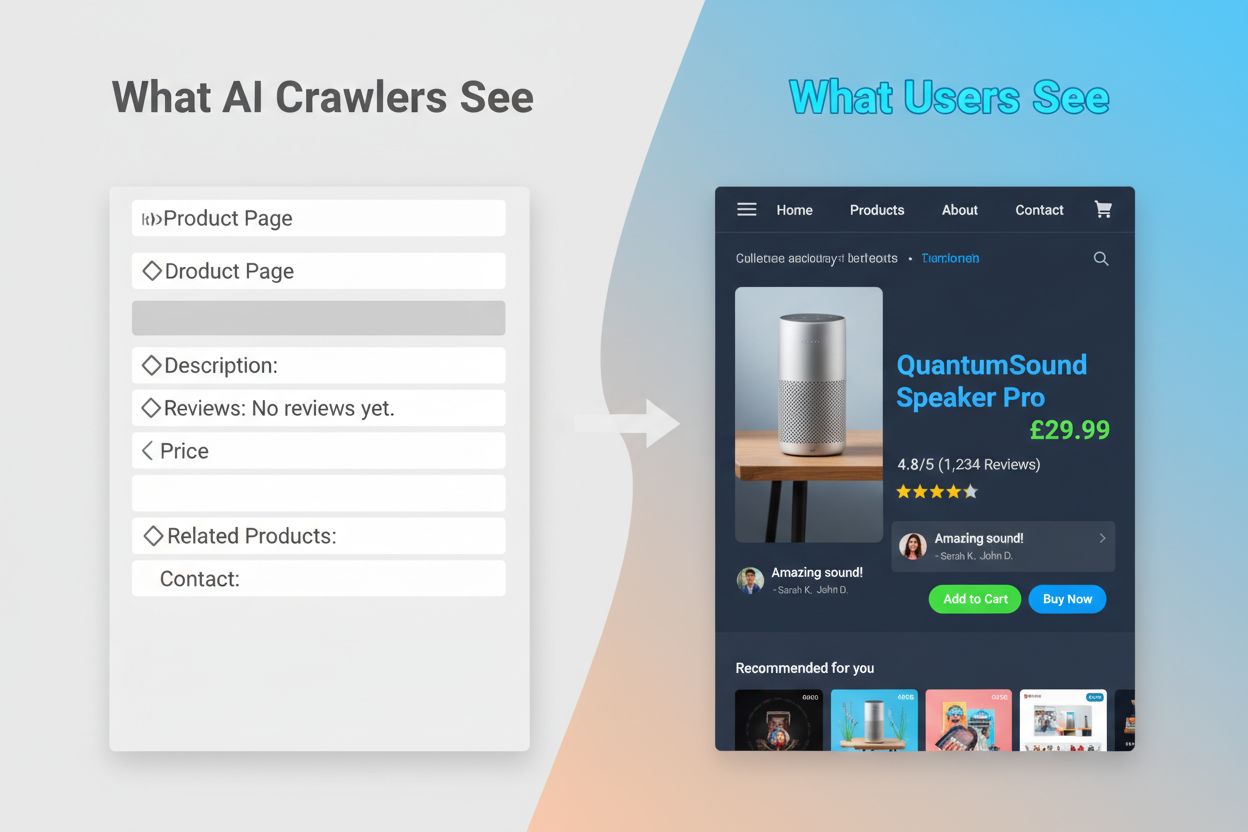
Los rastreadores de entrenamiento de IA representan una categoría fundamentalmente diferente de bots web diseñados para recolectar datos para entrenar grandes modelos de lenguaje (LLMs) en lugar de indexar para búsqueda. GPTBot, operado por OpenAI, es el rastreador de entrenamiento de IA más destacado, junto con ClaudeBot de Anthropic, PetalBot de Huawei y CCBot de Common Crawl. A diferencia de los rastreadores de búsqueda que buscan clasificar contenido, los rastreadores de entrenamiento de IA se centran en recopilar información de alta calidad y contexto rico para mejorar la base de conocimientos y la generación de respuestas de los modelos de IA. Estos rastreadores suelen operar con menos frecuencia que los de búsqueda, visitando un sitio web solo una vez cada pocas semanas o meses, y priorizan la calidad del contenido sobre el volumen. La distinción es crucial: mientras que tu contenido puede estar completamente indexado por Googlebot para la visibilidad en búsqueda, puede ser rastreado solo parcialmente o con poca frecuencia por GPTBot para el entrenamiento de modelos de IA.
Las diferencias técnicas entre los rastreadores de búsqueda y los de entrenamiento de IA crean implicaciones significativas para la visibilidad del contenido. La diferencia más crítica es la ejecución de JavaScript: los rastreadores de búsqueda como Googlebot pueden ejecutar JavaScript (aunque con algunas limitaciones), lo que les permite ver contenido renderizado dinámicamente. Por el contrario, los rastreadores de entrenamiento de IA no ejecutan JavaScript en absoluto: solo analizan el HTML puro disponible en la carga inicial de la página. Esta diferencia fundamental significa que el contenido cargado dinámicamente mediante scripts del lado del cliente permanece completamente invisible para los rastreadores de IA. Además, los rastreadores de búsqueda respetan los presupuestos de rastreo y priorizan páginas según la arquitectura del sitio y el enlazado interno, mientras que los de IA emplean patrones de rastreo más selectivos y enfocados en la calidad. Los rastreadores de búsqueda generalmente siguen estrictamente las directrices de robots.txt, mientras que algunos rastreadores de IA históricamente han sido menos transparentes sobre su cumplimiento. La frecuencia de rastreo difiere drásticamente: los rastreadores de búsqueda visitan sitios activos varias veces por semana o incluso diariamente, mientras que los de entrenamiento de IA pueden visitar solo una vez cada pocas semanas o meses. Además, los rastreadores de búsqueda están diseñados para entender señales de clasificación y métricas de experiencia de usuario, mientras que los de IA se centran en extraer texto limpio y bien estructurado para el entrenamiento del modelo.
Característica
Rastreadores de búsqueda
Rastreadores de entrenamiento de IA
Ejecución de JavaScript
Sí (con limitaciones)
No
Frecuencia de rastreo
Alta (varias veces por semana)
Baja (una vez cada pocas semanas)
Análisis de contenido
Renderizado de página completo
Solo HTML puro
Cumplimiento de robots.txt
Estricto
Variable
Enfoque de presupuesto de rastreo
Priorización según autoridad
Selección basada en calidad
Manejo de contenido dinámico
Puede renderizar e indexar
Lo omite completamente
Objetivo principal
Ranking y visibilidad en búsqueda
Recolección de datos de entrenamiento
Tolerancia al tiempo de espera
Mayor (permite renderizado complejo)
Estricta (1-5 segundos)
El problema de JavaScript
La incapacidad de los rastreadores de IA para ejecutar JavaScript crea una brecha crítica de visibilidad que afecta a muchos sitios web modernos. Cuando un sitio depende de JavaScript para cargar contenido dinámicamente—como descripciones de productos, reseñas de clientes, información de precios o imágenes—ese contenido se vuelve invisible para los rastreadores de IA. Esto es especialmente problemático para aplicaciones de una sola página (SPA) construidas con React, Vue o Angular, donde la mayor parte del contenido se carga del lado del cliente después del HTML inicial. Por ejemplo, un sitio de ecommerce puede mostrar la disponibilidad y el precio de los productos mediante JavaScript, lo que significa que GPTBot solo ve una página en blanco o un esqueleto básico de HTML. Del mismo modo, los sitios que usan carga diferida para imágenes o scroll infinito para contenido harán que esos elementos sean completamente omitidos por los rastreadores de IA. El impacto comercial es sustancial: si los detalles de tus productos, testimonios de clientes o contenido clave están ocultos detrás de JavaScript, los sistemas de IA como ChatGPT y Perplexity no tendrán acceso a esa información al generar respuestas. Esto crea una situación donde tu contenido puede posicionarse bien en Google pero estar completamente ausente de las respuestas generadas por IA, haciéndote efectivamente invisible para un segmento creciente de usuarios que dependen de la IA para descubrir información.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Rastreador de búsqueda vs Rastreador de IA: Implicaciones prácticas
Las consecuencias prácticas de estas diferencias técnicas son profundas y a menudo mal entendidas por los propietarios de sitios web. Tu sitio podría lograr excelentes posiciones en Google y al mismo tiempo ser casi invisible para ChatGPT, Perplexity y otros sistemas de IA. Esto crea una situación paradójica donde el éxito tradicional de SEO no garantiza la visibilidad en IA. Cuando los usuarios preguntan a ChatGPT sobre tu industria o producto, el sistema de IA puede citar a tus competidores en vez de a ti, simplemente porque su contenido fue más accesible para los rastreadores de IA. La relación entre los datos de entrenamiento y las citas en los resultados de búsqueda añade otra capa de complejidad: el contenido utilizado para entrenar un modelo de IA puede recibir trato preferencial en los resultados de búsqueda de ese modelo, lo que significa que bloquear rastreadores de entrenamiento de IA puede reducir tu visibilidad en respuestas impulsadas por IA. Para editores y creadores de contenido, esto significa que la decisión estratégica de permitir o bloquear rastreadores de IA tiene consecuencias reales para el tráfico futuro. Un sitio que bloquea GPTBot para proteger su contenido del entrenamiento puede reducir a la vez sus posibilidades de aparecer en los resultados de búsqueda de ChatGPT. Por el contrario, permitir el acceso de rastreadores de IA proporciona datos de entrenamiento pero no garantiza citas ni tráfico, creando un verdadero dilema estratégico sin una solución perfecta.
Monitoreo e identificación de la actividad de los rastreadores
Entender qué rastreadores acceden a tu sitio web y con qué frecuencia lo visitan es esencial para optimizar tu estrategia de contenido. El análisis de archivos de registro es el método principal para identificar la actividad de los rastreadores, permitiéndote segmentar y analizar los registros del servidor para ver qué bots accedieron a tu sitio, con qué frecuencia y qué páginas priorizaron. Al examinar las cadenas User-Agent en tus registros de servidor, puedes distinguir entre Googlebot, GPTBot, OAI-SearchBot y otros rastreadores, revelando patrones en su comportamiento. Las métricas clave a monitorear incluyen frecuencia de rastreo (con qué regularidad visita cada rastreador), profundidad de rastreo (cuántos niveles de la estructura de tu sitio están siendo rastreados) y presupuesto de rastreo (el número total de páginas rastreadas en un periodo determinado). Herramientas como Google Search Console y Bing Webmaster Tools ofrecen información sobre la actividad de rastreadores de búsqueda, mientras que soluciones especializadas como AmICited.com ofrecen monitoreo integral del comportamiento de rastreadores de IA en múltiples plataformas incluyendo ChatGPT, Perplexity y Google AI Overviews. AmICited.com rastrea específicamente cómo los sistemas de IA hacen referencia a tu marca y contenido, brindando visibilidad sobre en qué plataformas de IA eres citado y con qué frecuencia. Entender estos patrones te ayuda a identificar problemas técnicos temprano, optimizar la asignación de presupuesto de rastreo y tomar decisiones informadas sobre el acceso de rastreadores y la optimización de contenido.
Estrategias de optimización para rastreadores de búsqueda
Optimizar para rastreadores de búsqueda tradicionales requiere enfocarse en fundamentos técnicos de SEO que aseguren que tu contenido sea descubrible e indexable. Las siguientes estrategias siguen siendo esenciales para mantener una fuerte visibilidad en búsqueda:
Mejora la rastreabilidad creando estructuras de enlaces internos claras, eliminando enlaces rotos y evitando páginas huérfanas que los rastreadores no pueden alcanzar
Envía sitemaps XML a los motores de búsqueda para guiar a los rastreadores hacia tu contenido más valioso y asegurar una indexación completa
Implementa datos estructurados usando marcado de esquema para ayudar a los motores de búsqueda a comprender mejor el contexto y significado de tu contenido
Optimiza la velocidad de la página para asegurar que los rastreadores puedan procesar tu sitio eficientemente sin agotar el tiempo de espera o saltarse páginas
Prioriza el contenido importante en la arquitectura de tu sitio para que los rastreadores encuentren y rastreen primero tus páginas más valiosas
Utiliza robots.txt estratégicamente para bloquear páginas de poco valor y conservar el presupuesto de rastreo para contenido prioritario
Mantén contenido fresco y de alta calidad que indique a los rastreadores que tu sitio está activo y merece visitas frecuentes
Motores de búsqueda como Google están cada vez más enfocados en la eficiencia del rastreo, y representantes de Google han indicado que Googlebot rastreará menos en el futuro. Esto significa que tu sitio debe ser lo más optimizado y fácil de entender posible, con jerarquías claras y enlaces internos eficientes que guíen a los rastreadores directamente a tus páginas más importantes.
Estrategias de optimización para rastreadores de entrenamiento de IA
Optimizar para rastreadores de entrenamiento de IA requiere un enfoque diferente enfocado en la calidad, claridad y accesibilidad del contenido más que en señales de clasificación. Dado que los rastreadores de IA priorizan contenido bien estructurado y con contexto rico, tu estrategia de optimización debe enfatizar la exhaustividad y legibilidad. Evita contenido crítico dependiente de JavaScript: asegúrate de que los detalles de productos, precios, reseñas y datos clave estén presentes en el HTML puro donde los rastreadores de IA puedan acceder a ellos. Crea contenido completo y profundo que cubra los temas a fondo y brinde contexto valioso para los modelos de IA. Usa un formato claro con encabezados, viñetas y listas numeradas que dividan el texto y faciliten el análisis del contenido. Escribe con claridad semántica usando lenguaje sencillo sin excesivo tecnicismo que pueda confundir a los modelos de IA. Implementa una jerarquía adecuada de encabezados (H1, H2, H3) para ayudar a los rastreadores de IA a comprender la estructura y relaciones del contenido. Incluye metadatos relevantes y marcado de esquema que aporte contexto sobre tu contenido. Asegura tiempos de carga rápidos, ya que los rastreadores de IA tienen tiempos de espera muy ajustados (típicamente 1-5 segundos) y pueden saltar páginas lentas.
La diferencia clave respecto a la optimización para la búsqueda es que a los rastreadores de IA no les importan las señales de ranking, los backlinks ni la densidad de palabras clave. Valoran, en cambio, el contenido claro, bien organizado y rico en información. Una página que tal vez no posicione bien en Google podría ser muy valiosa para los modelos de IA si contiene información completa y bien estructurada sobre un tema.
El futuro de la gestión de rastreadores
El panorama del rastreo web está evolucionando rápidamente, con los rastreadores de IA volviéndose cada vez más importantes para la visibilidad de contenido y el reconocimiento de marca. A medida que herramientas de búsqueda impulsadas por IA como ChatGPT, Perplexity y Google AI Overviews siguen ganando usuarios, la posibilidad de ser descubierto y citado por estos sistemas será tan crítica como los rankings de búsqueda tradicionales. La distinción entre rastreadores de entrenamiento y de búsqueda probablemente se volverá más matizada, y las empresas podrían ofrecer una separación más clara entre la recopilación de datos y la recuperación de búsqueda, similar al enfoque de OpenAI con GPTBot y OAI-SearchBot. Los propietarios de sitios deberán desarrollar estrategias que equilibren la optimización SEO tradicional con la visibilidad en IA, reconociendo que son objetivos complementarios y no competidores. El surgimiento de herramientas y soluciones especializadas de monitoreo facilitará el seguimiento de la actividad de rastreadores tanto en plataformas tradicionales como de IA, permitiendo decisiones basadas en datos sobre el acceso de rastreadores y la optimización de contenido. Quienes adopten pronto la optimización para ambos tipos de rastreadores obtendrán ventaja competitiva, posicionando su contenido para ser descubierto a través de múltiples canales a medida que el panorama de búsqueda evoluciona. El futuro de la visibilidad de contenido depende de comprender y optimizar para todo el espectro de rastreadores que descubren y utilizan tu contenido.
Preguntas frecuentes
¿Cuál es la principal diferencia entre los rastreadores de búsqueda y los rastreadores de entrenamiento de IA?
Los rastreadores de búsqueda como Googlebot indexan contenido para los rankings de búsqueda y pueden ejecutar JavaScript para ver contenido dinámico. Los rastreadores de entrenamiento de IA como GPTBot recopilan datos para entrenar LLMs y normalmente no pueden ejecutar JavaScript, lo que les hace perder contenido cargado dinámicamente. Esta diferencia fundamental significa que tu sitio web podría posicionarse bien en Google mientras es casi invisible para ChatGPT.
¿Puedo bloquear los rastreadores de entrenamiento de IA sin afectar mis rankings de búsqueda?
Sí, puedes usar robots.txt para bloquear rastreadores de IA específicos como GPTBot mientras permites los rastreadores de búsqueda. Sin embargo, esto puede reducir tu visibilidad en respuestas y resúmenes generados por IA. El intercambio estratégico depende de si priorizas la protección de contenido sobre el posible tráfico de referencia de IA.
¿Por qué los rastreadores de IA no pueden ver mi contenido en JavaScript?
Los rastreadores de IA como GPTBot solo analizan el HTML puro en la carga inicial de la página y no ejecutan JavaScript. El contenido cargado dinámicamente mediante scripts, como detalles de productos, reseñas o imágenes, les resulta completamente invisible. Esta es una limitación crítica para los sitios modernos que dependen mucho del renderizado del lado del cliente.
¿Con qué frecuencia visitan los rastreadores de entrenamiento de IA mi sitio web?
Los rastreadores de entrenamiento de IA suelen visitar con menos frecuencia que los rastreadores de búsqueda, con intervalos más largos entre visitas. Priorizan contenido de alta autoridad y pueden rastrear una página solo una vez cada pocas semanas o meses. Este patrón de rastreo poco frecuente refleja su enfoque en la calidad sobre el volumen.
¿Qué contenido está más en riesgo de ser invisible para los rastreadores de IA?
Los detalles de productos, reseñas de clientes, imágenes cargadas de forma diferida, elementos interactivos (pestañas, carruseles, modales), información de precios y cualquier contenido oculto detrás de JavaScript son los más vulnerables. Para sitios de ecommerce y páginas basadas en SPA, esto puede representar una parte significativa del contenido crítico.
¿Cómo puedo optimizar mi sitio web para ambos rastreadores, de búsqueda y de IA?
Asegura que el contenido clave esté presente en el HTML puro, mejora la velocidad del sitio, utiliza una estructura y formato claros con jerarquía adecuada de encabezados, implementa marcado de esquema y evita contenido crítico dependiente de JavaScript. El objetivo es que tu contenido sea accesible tanto para rastreadores tradicionales como de IA.
¿Qué herramientas pueden ayudarme a monitorear la actividad de rastreadores en mi sitio?
Las herramientas de análisis de archivos de registro, Google Search Console, Bing Webmaster Tools y soluciones especializadas de monitoreo de rastreadores como AmICited.com pueden ayudar a rastrear el comportamiento de los rastreadores. AmICited.com monitorea específicamente cómo los sistemas de IA hacen referencia a tu marca en ChatGPT, Perplexity y Google AI Overviews.
¿Bloquear rastreadores de IA afectará mi tráfico de referencia de IA?
Potencialmente sí. Aunque bloquear rastreadores de entrenamiento puede proteger tu contenido, podría reducir tu visibilidad en resultados y resúmenes impulsados por IA. Además, el contenido que ya fue rastreado antes de bloquearlo permanece en los modelos entrenados. La decisión requiere equilibrar la protección del contenido frente a la posible pérdida de descubrimiento mediante IA.
Monitorea la actividad de rastreadores de IA con AmICited
Rastrea cómo los sistemas de IA hacen referencia a tu marca en ChatGPT, Perplexity y Google AI Overviews. Obtén información en tiempo real sobre tu visibilidad en IA y optimiza tu estrategia de contenido.
Cómo Permitir que los Bots de IA Rastreen tu Sitio Web: Guía Completa de robots.txt y llms.txt
Aprende cómo permitir que bots de IA como GPTBot, PerplexityBot y ClaudeBot rastreen tu sitio. Configura robots.txt, crea llms.txt y optimiza para la visibilida...
Etiquetas Meta NoAI: Controlando el Acceso de la IA a Través de Encabezados
Aprende cómo implementar las etiquetas meta noai y noimageai para controlar el acceso de rastreadores de IA al contenido de tu sitio web. Guía completa sobre en...
Explicación de los rastreadores de IA: GPTBot, ClaudeBot y más
Comprende cómo funcionan los rastreadores de IA como GPTBot y ClaudeBot, sus diferencias con los rastreadores de búsqueda tradicionales y cómo optimizar tu siti...
16 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.