
La guía completa para bloquear (o permitir) rastreadores de IA
Aprende a bloquear o permitir rastreadores de IA como GPTBot y ClaudeBot usando robots.txt, bloqueo a nivel de servidor y métodos avanzados de protección. Guía ...
8 min de lectura
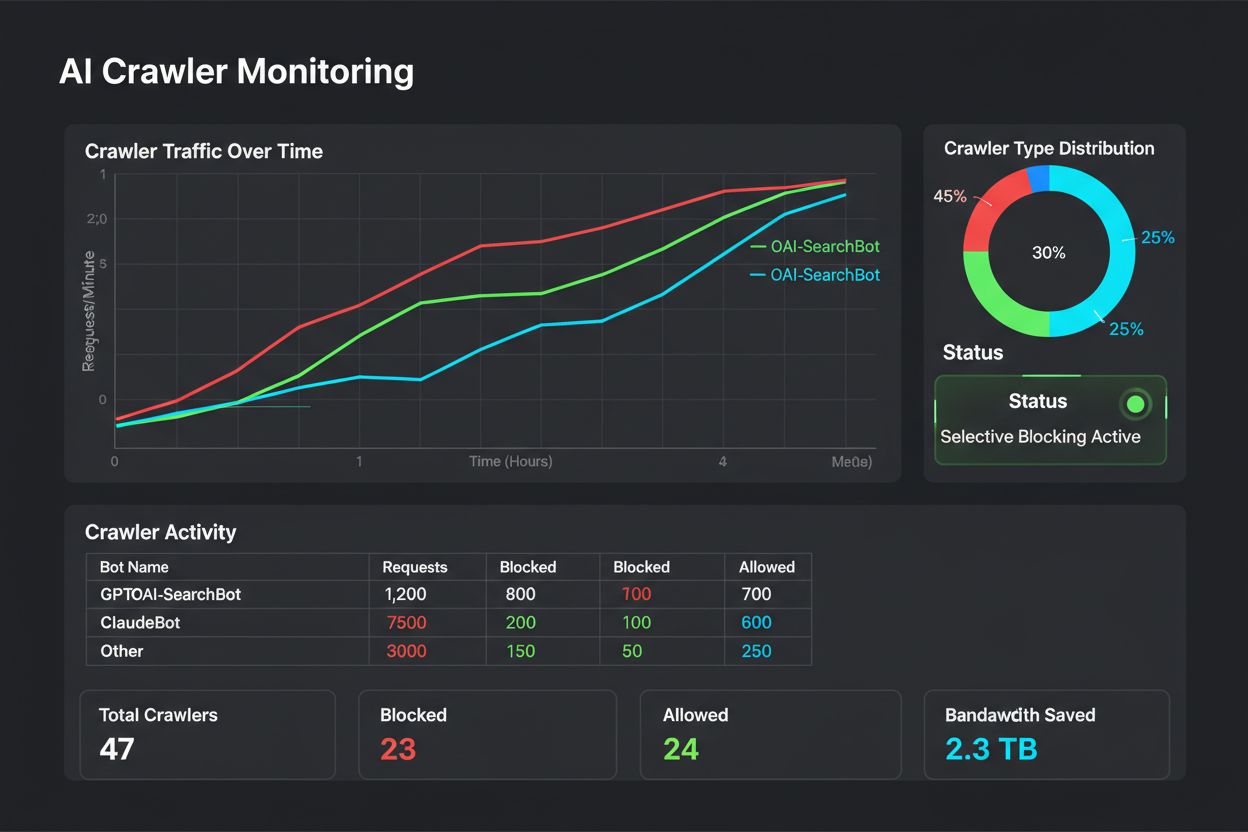
Aprende cómo implementar el bloqueo selectivo de rastreadores de IA para proteger tu contenido de bots de entrenamiento y mantener la visibilidad en resultados de búsqueda de IA. Estrategias técnicas para editores.
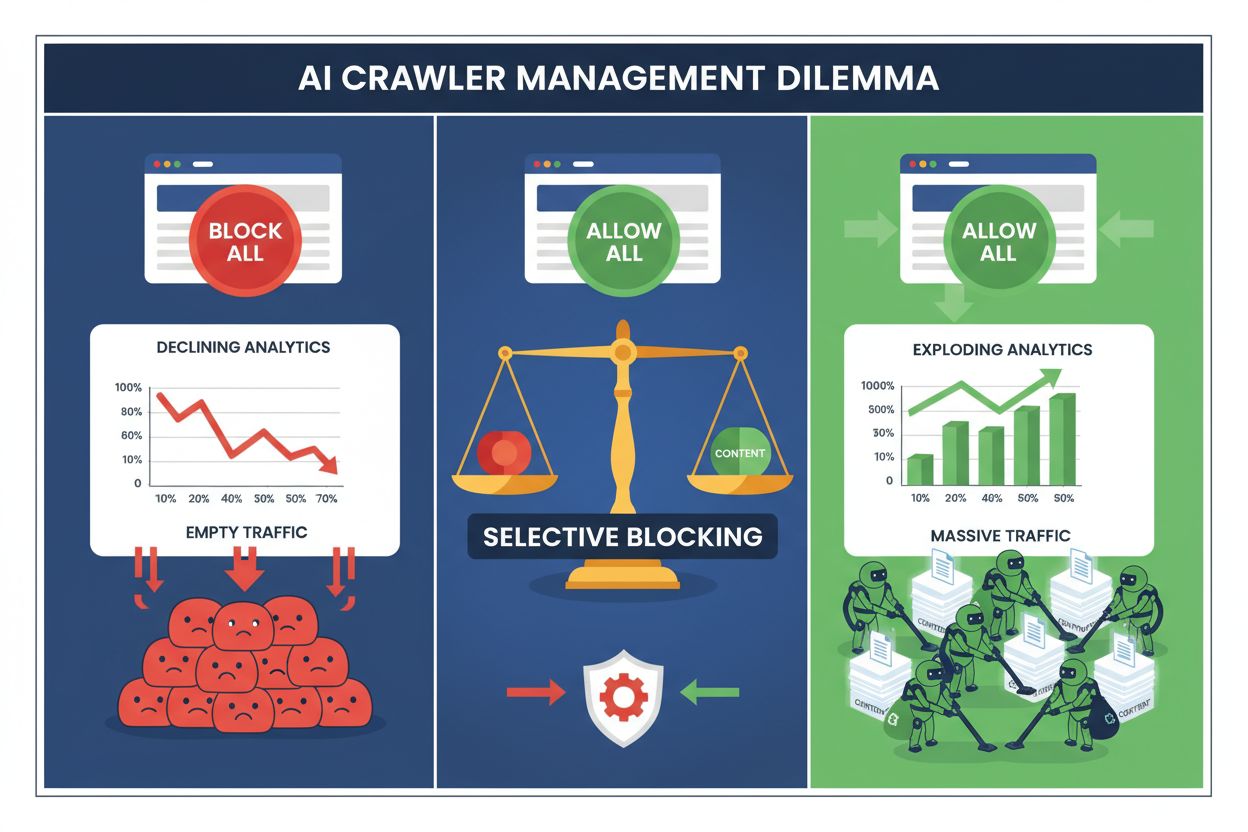
Hoy los editores enfrentan una elección imposible: bloquear todos los rastreadores de IA y perder valioso tráfico de motores de búsqueda, o permitirlos todos y ver cómo su contenido alimenta conjuntos de datos de entrenamiento sin compensación. El auge de la IA generativa ha creado un ecosistema de rastreadores bifurcado donde las mismas reglas de robots.txt se aplican indiscriminadamente tanto a motores de búsqueda que generan ingresos como a rastreadores de entrenamiento que extraen valor. Esta paradoja ha obligado a los editores más innovadores a desarrollar estrategias de control selectivo de rastreadores que distinguen entre diferentes tipos de bots de IA según su impacto real en los indicadores de negocio.
El panorama de rastreadores de IA se divide en dos categorías distintas con propósitos y repercusiones empresariales muy diferentes. Los rastreadores de entrenamiento—operados por empresas como OpenAI, Anthropic y Google—están diseñados para ingerir grandes volúmenes de texto y construir o mejorar modelos de lenguaje extensos, mientras que los rastreadores de búsqueda indexan contenido para su recuperación y descubrimiento. Los bots de entrenamiento representan aproximadamente el 80% de toda la actividad relacionada con bots de IA, pero no generan ingresos directos para los editores, mientras que rastreadores de búsqueda como Googlebot y Bingbot generan millones de visitas e impresiones publicitarias cada año. La distinción es importante porque un solo rastreador de entrenamiento puede consumir un ancho de banda equivalente al de miles de usuarios humanos, mientras que los rastreadores de búsqueda están optimizados para la eficiencia y suelen respetar los límites de velocidad.
| Nombre del bot | Operador | Propósito principal | Potencial de tráfico |
|---|---|---|---|
| GPTBot | OpenAI | Entrenamiento de modelos | Ninguno (extracción de datos) |
| Claude Web Crawler | Anthropic | Entrenamiento de modelos | Ninguno (extracción de datos) |
| Googlebot | Indexación de búsqueda | 243,8M visitas (abril 2025) | |
| Bingbot | Microsoft | Indexación de búsqueda | 45,2M visitas (abril 2025) |
| Perplexity Bot | Perplexity AI | Búsqueda + entrenamiento | 12,1M visitas (abril 2025) |
Los datos son contundentes: solo el rastreador de ChatGPT envió 243,8 millones de visitas a editores en abril de 2025, pero estas visitas generaron cero clics, cero impresiones publicitarias y cero ingresos. Mientras tanto, el tráfico de Googlebot se tradujo en interacción real de usuarios y oportunidades de monetización. Entender esta distinción es el primer paso para implementar una estrategia de bloqueo selectivo que proteja tu contenido y conserve tu visibilidad en buscadores.
Bloquear todos los rastreadores de IA indiscriminadamente es económicamente autodestructivo para la mayoría de los editores. Mientras que los rastreadores de entrenamiento extraen valor sin compensación, los rastreadores de búsqueda siguen siendo una de las fuentes de tráfico más confiables en un entorno digital cada vez más fragmentado. El argumento financiero para el bloqueo selectivo se basa en varios factores clave:
Los editores que implementan estrategias de bloqueo selectivo reportan mantener o incluso mejorar su tráfico de búsqueda mientras reducen la extracción no autorizada de contenido hasta en un 85%. Este enfoque estratégico reconoce que no todos los rastreadores de IA son iguales y que una política matizada sirve mejor a los intereses comerciales que una táctica de tierra quemada.
El archivo robots.txt sigue siendo el principal mecanismo para comunicar permisos a los rastreadores y es sorprendentemente efectivo para distinguir entre diferentes tipos de bots cuando está bien configurado. Este sencillo archivo de texto, ubicado en el directorio raíz de tu sitio web, usa directivas de user-agent para especificar qué rastreadores pueden acceder a qué contenido. Para el control selectivo de rastreadores de IA, puedes permitir motores de búsqueda y bloquear rastreadores de entrenamiento con precisión quirúrgica.
Aquí tienes un ejemplo práctico que bloquea rastreadores de entrenamiento y permite motores de búsqueda:
# Bloquear GPTBot de OpenAI
User-agent: GPTBot
Disallow: /
# Bloquear el rastreador Claude de Anthropic
User-agent: Claude-Web
Disallow: /
# Bloquear otros rastreadores de entrenamiento
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Permitir motores de búsqueda
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Este enfoque da instrucciones claras a los rastreadores bien comportados y mantiene la capacidad de descubrimiento de tu sitio en los resultados de búsqueda. Sin embargo, robots.txt es fundamentalmente un estándar voluntario: depende de que los operadores de rastreadores respeten tus directivas. Para editores preocupados por el cumplimiento, se requieren capas adicionales de control.
Solo con robots.txt no se puede garantizar el cumplimiento, ya que aproximadamente el 13% de los rastreadores de IA ignoran completamente las directivas de robots.txt, ya sea por negligencia o por evasión deliberada. El control a nivel de servidor, usando tu servidor web o la capa de aplicación, proporciona una defensa técnica que impide el acceso no autorizado independientemente del comportamiento del rastreador. Este enfoque bloquea las solicitudes a nivel HTTP antes de que consuman recursos o ancho de banda significativos.
Implementar el bloqueo a nivel de servidor con Nginx es sencillo y muy efectivo:
# En tu bloque de servidor Nginx
location / {
# Bloquear rastreadores de entrenamiento a nivel de servidor
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Bloquear por rangos de IP si es necesario (para rastreadores que suplantan user-agent)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Continuar con el procesamiento normal de la solicitud
proxy_pass http://backend;
}
Esta configuración devuelve una respuesta 403 Forbidden a los rastreadores bloqueados, consumiendo mínimos recursos del servidor y comunicando claramente que el acceso está denegado. Combinado con robots.txt, el control a nivel de servidor crea una defensa de dos capas que detiene tanto a rastreadores cumplidores como no cumplidores. La tasa de evasión del 13% cae a casi cero cuando las reglas en el servidor se implementan correctamente.
Las redes de entrega de contenido (CDN) y los cortafuegos de aplicaciones web (WAF) ofrecen una capa adicional de control que opera antes de que las solicitudes lleguen a tus servidores de origen. Servicios como Cloudflare, Akamai y AWS WAF te permiten crear reglas que bloquean agentes de usuario o rangos de IP específicos en el edge, previniendo que rastreadores maliciosos o no deseados consuman recursos de tu infraestructura. Estos servicios mantienen listas actualizadas de IPs y agentes de usuario de rastreadores de entrenamiento conocidos, bloqueándolos automáticamente sin necesidad de configuración manual.
Los controles a nivel de CDN ofrecen varias ventajas frente a la aplicación en el servidor: reducen la carga sobre el servidor de origen, permiten bloqueos geográficos y ofrecen análisis en tiempo real sobre solicitudes bloqueadas. Muchos proveedores de CDN ahora ofrecen reglas de bloqueo específicas para IA como características estándar, reconociendo la preocupación generalizada de los editores por la extracción no autorizada de datos de entrenamiento. Para editores que usan Cloudflare, habilitar la opción “Block AI Crawlers” en la configuración de seguridad brinda protección con un solo clic contra los principales rastreadores de entrenamiento sin afectar el acceso de los motores de búsqueda.
Un bloqueo selectivo efectivo requiere un enfoque sistemático para clasificar rastreadores según su impacto en el negocio y su nivel de confianza. En lugar de tratar a todos los rastreadores de IA por igual, los editores deben implementar un marco de tres niveles que refleje el valor real y el riesgo que cada rastreador presenta. Este marco permite tomar decisiones matizadas que equilibran la protección del contenido con las oportunidades comerciales.
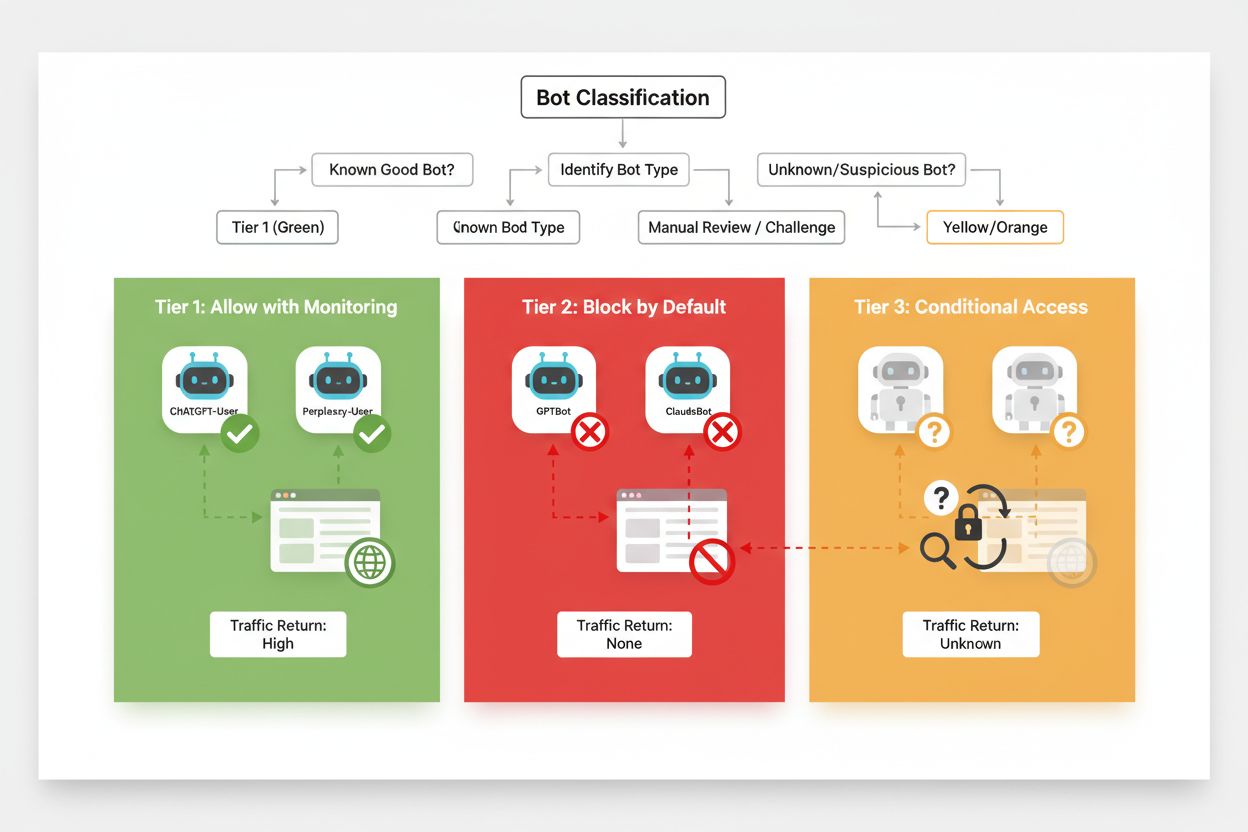
| Nivel | Clasificación | Ejemplos | Acción |
|---|---|---|---|
| Nivel 1: Generadores de ingresos | Motores de búsqueda y fuentes de referencia de alto tráfico | Googlebot, Bingbot, Perplexity Bot | Permitir todo el acceso; optimizar para rastreabilidad |
| Nivel 2: Neutros/No probados | Rastreadores nuevos o emergentes con intención poco clara | Startups de IA pequeñas, bots de investigación | Monitorear de cerca; permitir con limitación de velocidad |
| Nivel 3: Extractores de valor | Rastreadores de entrenamiento sin beneficio directo | GPTBot, Claude-Web, CCBot | Bloquear completamente; aplicar en múltiples capas |
Implementar este marco requiere investigación continua sobre nuevos rastreadores y sus modelos de negocio. Los editores deben auditar periódicamente sus registros de acceso para identificar nuevos bots, investigar los términos de servicio y políticas de compensación de sus operadores y ajustar las clasificaciones según corresponda. Un rastreador que comienza en el nivel 3 puede pasar al 2 si su operador empieza a ofrecer acuerdos de reparto de ingresos, mientras que un rastreador previamente confiable puede caer al nivel 3 si comienza a violar límites de velocidad o directivas de robots.txt.
El bloqueo selectivo no es una configuración que se define una vez y se olvida: requiere monitoreo y ajuste continuo a medida que evoluciona el ecosistema de rastreadores. Los editores deben implementar un registro y análisis exhaustivo para rastrear qué rastreadores acceden a su contenido, cuánto ancho de banda consumen y si cumplen con las restricciones configuradas. Estos datos informan decisiones estratégicas sobre qué rastreadores permitir, bloquear o limitar.
Analizar tus registros de acceso revela patrones de comportamiento de rastreadores que guían los ajustes de políticas:
# Identificar todos los rastreadores de IA que acceden a tu sitio
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Calcular el ancho de banda consumido por rastreadores específicos
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot bandwidth: " sum/1024/1024 " MB"}'
# Monitorear respuestas 403 a rastreadores bloqueados
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
El análisis regular de estos datos—idealmente de forma semanal o mensual—revela si tu estrategia de bloqueo está funcionando como se espera, si han aparecido nuevos rastreadores o si algún rastreador previamente bloqueado ha cambiado su comportamiento. Esta información retroalimenta tu marco de clasificación, asegurando que tus políticas sigan alineadas con los objetivos de negocio y la realidad técnica.
Los editores que implementan el bloqueo selectivo de rastreadores frecuentemente cometen errores que socavan su estrategia o crean consecuencias no deseadas. Entender estos errores te ayuda a evitar costos y a implementar una política más efectiva desde el principio.
Bloquear todos los rastreadores indiscriminadamente: El error más común es usar reglas demasiado amplias que bloquean motores de búsqueda junto con rastreadores de entrenamiento, destruyendo la visibilidad en buscadores al intentar proteger el contenido.
Depender solo de robots.txt: Suponer que solo robots.txt evitará el acceso no autorizado ignora al 13% de rastreadores que lo ignoran completamente, dejando tu contenido vulnerable a la extracción de datos.
No monitorear ni ajustar: Implementar una política de bloqueo estática y no revisarla significa perderse nuevos rastreadores, no adaptarse a cambios de modelos de negocio y potencialmente bloquear rastreadores beneficiosos que han mejorado sus prácticas.
Bloquear solo por user agent: Rastreadores sofisticados suplantan o rotan su user agent frecuentemente, haciendo que el bloqueo basado únicamente en user agent sea ineficaz sin reglas complementarias basadas en IP y limitación de velocidad.
Ignorar la limitación de velocidad: Incluso los rastreadores permitidos pueden consumir ancho de banda excesivo si no se les limita la velocidad, degradando la experiencia de los usuarios humanos y consumiendo recursos innecesariamente.
El futuro de la relación entre editores y rastreadores de IA probablemente implicará negociaciones y modelos de compensación más sofisticados en lugar de simples bloqueos. Sin embargo, hasta que surjan estándares de la industria, el control selectivo de rastreadores sigue siendo el enfoque más práctico para proteger el contenido y mantener la visibilidad en buscadores. Los editores deben ver su estrategia de bloqueo como una política dinámica que evoluciona junto con el ecosistema de rastreadores, reevaluando regularmente qué rastreadores merecen acceso según su impacto en el negocio y su confiabilidad.
Los editores más exitosos serán aquellos que implementen defensas en capas—combinando directivas de robots.txt, controles a nivel de servidor, reglas de CDN y monitoreo continuo en una estrategia integral. Este enfoque protege tanto de rastreadores cumplidores como no cumplidores y mantiene el tráfico de motores de búsqueda que impulsa los ingresos y la interacción del usuario. A medida que las empresas de IA reconozcan cada vez más el valor del contenido de los editores y comiencen a ofrecer arreglos de compensación o licencias, el marco que construyas hoy se adaptará fácilmente a nuevos modelos de negocio mientras mantienes el control sobre tus activos digitales.
Los rastreadores de entrenamiento como GPTBot y ClaudeBot recolectan datos para construir modelos de IA sin devolver tráfico a tu sitio. Los rastreadores de búsqueda como OAI-SearchBot y PerplexityBot indexan contenido para motores de búsqueda de IA y pueden generar tráfico de referencia significativo hacia tu sitio. Entender esta distinción es crucial para implementar una estrategia de bloqueo selectivo efectiva.
Sí, esta es la estrategia central del control selectivo de rastreadores. Puedes usar robots.txt para bloquear bots de entrenamiento y permitir bots de búsqueda, luego aplicar controles a nivel de servidor para bots que ignoran robots.txt. Este enfoque protege tu contenido del entrenamiento no autorizado y mantiene la visibilidad en los resultados de búsqueda de IA.
La mayoría de las grandes empresas de IA afirman respetar robots.txt, pero el cumplimiento es voluntario. Investigaciones muestran que aproximadamente el 13% de los bots de IA ignoran completamente las directivas de robots.txt. Por eso la aplicación a nivel de servidor es esencial para los editores que quieren proteger su contenido de rastreadores no conformes.
Significativo y en aumento. ChatGPT envió 243,8 millones de visitas a 250 sitios de noticias y medios en abril de 2025, un aumento del 98% respecto a enero. Bloquear estos rastreadores significa perder esta fuente emergente de tráfico. Para muchos editores, el tráfico de búsqueda de IA ahora representa entre el 5% y el 15% del tráfico de referencia total.
Analiza los registros de tu servidor regularmente usando comandos grep para identificar agentes de usuario de bots, rastrear la frecuencia de rastreo y monitorear el cumplimiento de tus reglas robots.txt. Revisa los registros al menos mensualmente para identificar nuevos bots, patrones de comportamiento inusuales y si los bots bloqueados realmente están fuera. Estos datos informan decisiones estratégicas sobre tu política de rastreadores.
Proteges tu contenido del entrenamiento no autorizado, pero pierdes visibilidad en los resultados de búsqueda de IA, te pierdes fuentes emergentes de tráfico y podrías reducir las menciones de tu marca en respuestas generadas por IA. Los editores que implementan bloqueos totales suelen ver reducciones del 40-60% en visibilidad de búsqueda y pierden oportunidades de descubrimiento de marca a través de plataformas de IA.
Al menos mensualmente, ya que constantemente surgen nuevos bots y los existentes evolucionan su comportamiento. El panorama de rastreadores de IA cambia rápidamente, con nuevos operadores lanzando rastreadores y jugadores existentes fusionando o renombrando sus bots. Revisiones regulares aseguran que tu política se mantenga alineada con los objetivos de negocio y la realidad técnica.
Es el número de páginas rastreadas versus los visitantes enviados de regreso a tu sitio. Anthropic rastrea 38.000 páginas por cada visitante referido, mientras que OpenAI mantiene una proporción de 1.091:1 y Perplexity se sitúa en 194:1. Proporciones más bajas indican mayor valor por permitir el rastreador. Esta métrica ayuda a decidir qué rastreadores merecen acceso según su impacto real en el negocio.
AmICited rastrea qué plataformas de IA citan tu marca y contenido. Obtén información sobre tu visibilidad en IA y asegúrate de la atribución adecuada en ChatGPT, Perplexity, Google AI Overviews y más.
Aprende a bloquear o permitir rastreadores de IA como GPTBot y ClaudeBot usando robots.txt, bloqueo a nivel de servidor y métodos avanzados de protección. Guía ...

Discusión de la comunidad sobre qué rastreadores de IA permitir o bloquear. Decisiones reales de webmasters sobre el acceso de GPTBot, PerplexityBot y otros ras...

Aprende cómo los cortafuegos de aplicaciones web proporcionan un control avanzado sobre los rastreadores de IA más allá de robots.txt. Implementa reglas WAF par...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.