Fuentes de Citas de ChatGPT: ¿De Dónde Obtiene ChatGPT Su Información?
Descubre de dónde obtiene ChatGPT sus datos de entrenamiento, cómo cita fuentes, las fechas de corte de conocimiento y por qué monitorear las citas de la IA es importante para tu marca.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Comprendiendo las Fuentes de Datos de Entrenamiento de ChatGPT
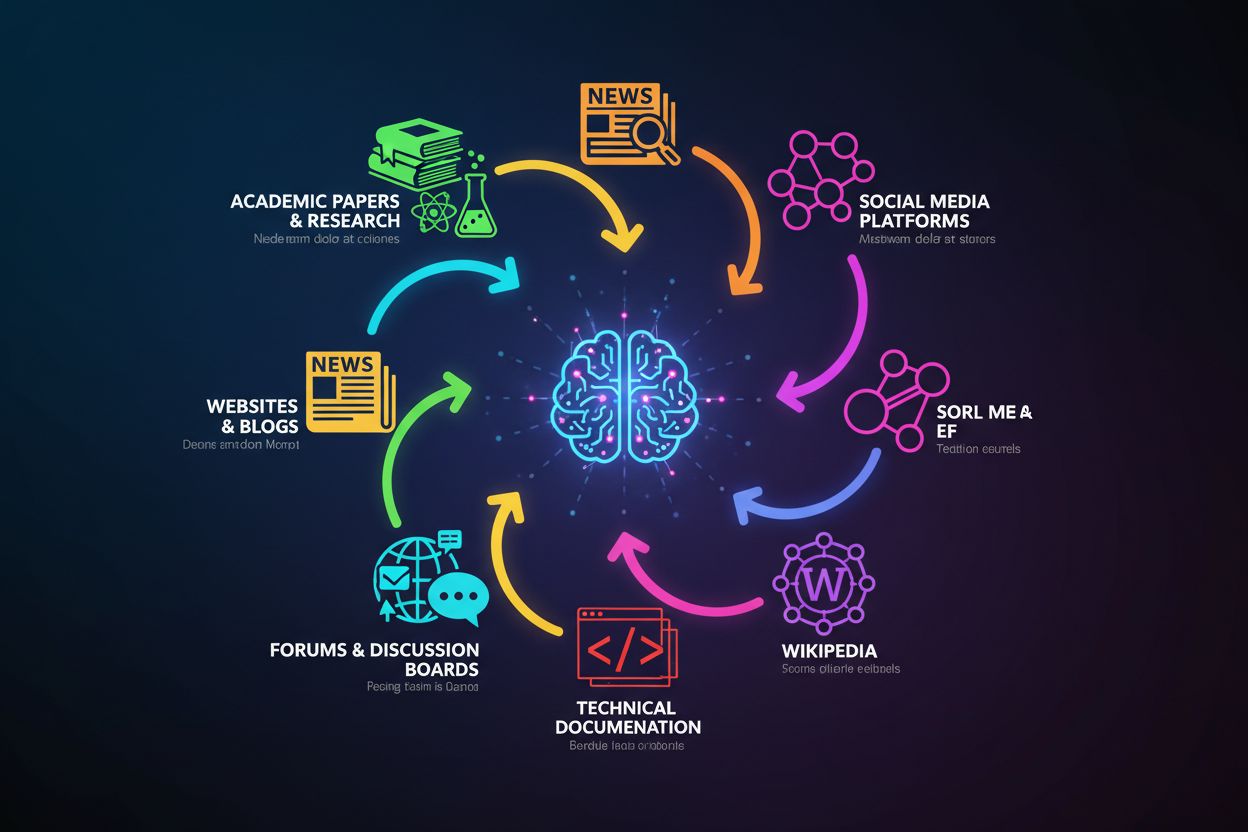
La base de conocimientos de ChatGPT se construye a partir de una colección diversa de datos públicos disponibles en internet, combinados con conjuntos de datos con licencia y retroalimentación humana. El modelo fue entrenado con tres fuentes principales: datos públicos disponibles en internet (sitios web, artículos y contenido en línea), conjuntos de datos licenciados (incluyendo libros y publicaciones académicas) y retroalimentación humana de entrenadores que ayudaron a refinar sus respuestas. Estos datos de entrenamiento abarcan una variedad extraordinaria de fuentes, entre ellas sitios de noticias, revistas académicas, libros, documentación técnica, foros como Reddit y Stack Overflow, artículos de Wikipedia y muchísimas otras páginas web de acceso público. El enorme volumen y diversidad de estas fuentes—que abarcan múltiples idiomas, dominios y perspectivas—crea una base de conocimientos integral que permite a ChatGPT tratar temas que van desde la física cuántica hasta la historia medieval o la cultura pop contemporánea. Sin embargo, es fundamental entender que ChatGPT no tiene acceso a información en tiempo real ni a bases de datos propietarias; solo puede extraer de lo que estaba disponible durante su periodo de entrenamiento.
Explicación de la Fecha de Corte de Conocimiento
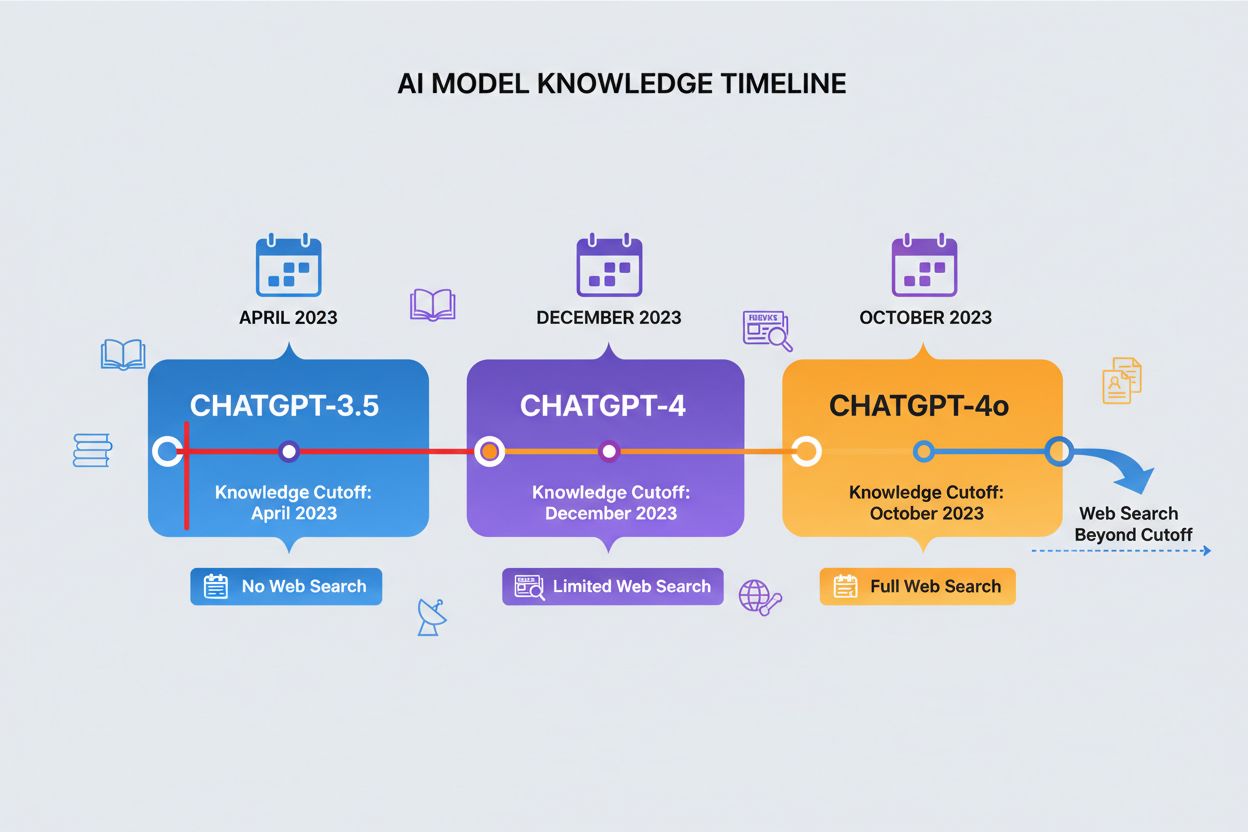
Una fecha de corte de conocimiento representa el momento a partir del cual ChatGPT ya no tiene datos de entrenamiento, creando un límite estricto para la información a la que puede acceder. Las distintas versiones de ChatGPT tienen diferentes fechas de corte: ChatGPT-4 fue entrenado con datos hasta diciembre de 2023, mientras que ChatGPT-4o (la versión optimizada) tiene un corte de conocimiento en octubre de 2023. Estas fechas de corte impactan significativamente en la precisión y relevancia de las respuestas, especialmente para eventos recientes, investigaciones nuevas o estadísticas actuales que puedan haber cambiado desde que se recopilaron los datos de entrenamiento. Algunas versiones más recientes de ChatGPT pueden realizar búsquedas web para obtener información actual más allá de sus fechas de corte, aunque esta función no está disponible en todas las versiones o contextos. Entender la fecha de corte de tu modelo es esencial para quienes necesitan información actual, ya que ChatGPT no puede proporcionar respuestas precisas sobre eventos o desarrollos ocurridos después de su periodo de entrenamiento. Esta limitación es uno de los factores más importantes a considerar al evaluar la fiabilidad de ChatGPT para consultas sensibles al tiempo.
Versión de ChatGPT
Fecha de Corte de Conocimiento
Capacidad de Búsqueda Web
Caso de Uso Principal
ChatGPT-4
Diciembre 2023
Limitada
Conocimiento general, análisis, razonamiento
ChatGPT-4o
Octubre 2023
Disponible
Rendimiento optimizado, tareas multimodales
ChatGPT-3.5
Abril 2023
No
Consultas básicas, opción rentable
ChatGPT con Navegación
Tiempo real
Sí
Eventos actuales, investigación reciente
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
A diferencia de los motores de búsqueda que recuperan documentos o páginas web específicas en respuesta a consultas, ChatGPT genera respuestas sintetizando patrones aprendidos durante el entrenamiento—un proceso fundamentalmente diferente. Cuando haces una pregunta a ChatGPT, no busca en una base de datos o índice; en cambio, utiliza patrones estadísticos de sus datos de entrenamiento para predecir la secuencia de palabras más probable que constituya una respuesta útil. Este enfoque basado en generación significa que ChatGPT combina información de múltiples fuentes de sus datos de entrenamiento para crear respuestas novedosas que pueden no existir literalmente en ningún material original. El modelo aprende esencialmente las relaciones entre conceptos, hechos e ideas, y luego reconstruye este conocimiento según tu consulta específica. Sin embargo, este proceso tiene una desventaja importante: cuando el modelo no está seguro sobre cierta información o cuando los patrones en sus datos son contradictorios o escasos, puede generar información que suena plausible pero es falsa, fenómeno conocido como “alucinación”. Las versiones más recientes de ChatGPT que integran búsqueda web pueden complementar este proceso de generación recuperando información actual de internet, aunque esta función requiere activación explícita y no está disponible en todas las plataformas.
Fuentes de Datos Específicas y Su Importancia
Los datos de entrenamiento de ChatGPT provienen de varias categorías principales de fuentes, cada una aportando un valor único a su base de conocimientos:
Artículos y Publicaciones Académicas: Revistas revisadas por pares y publicaciones de investigación proporcionan información autorizada y verificada sobre temas científicos y técnicos
Artículos de Noticias: Importantes medios de comunicación aportan conocimiento de actualidad y perspectivas diversas sobre temas contemporáneos
Libros: Los libros publicados ofrecen una cobertura profunda y exhaustiva de temas y representan contenido curado y editado
Sitios Web y Blogs: El contenido general de la web brinda información práctica, tutoriales y puntos de vista diversos
Foros y Tableros de Discusión: Los debates comunitarios como Reddit y Stack Overflow aportan soluciones a problemas reales y conocimientos de expertos
Documentación Técnica: Documentación de software, APIs y guías técnicas proporcionan información precisa y especializada
Wikipedia: La enciclopedia colaborativa contribuye información estructurada en prácticamente todos los ámbitos
La importancia de estas fuentes diversas radica en sus fortalezas complementarias: los artículos académicos aportan rigor, las noticias actualidad, los libros profundidad y los foros aplicación práctica. Sin embargo, la calidad de las fuentes varía significativamente—un artículo académico revisado por pares tiene más peso que una entrada aleatoria de blog, pero el proceso de entrenamiento de ChatGPT no distingue explícitamente entre ellas. Esto significa que el conocimiento de ChatGPT refleja tanto fuentes autorizadas de alta calidad como contenido de menor calidad o potencialmente engañoso, por lo que la verificación sigue siendo esencial al usar el modelo para decisiones importantes.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
El Papel de la Retroalimentación Humana en el Entrenamiento
Después del entrenamiento inicial con grandes cantidades de texto, OpenAI empleó una técnica llamada aprendizaje por refuerzo con retroalimentación humana (RLHF) para refinar las respuestas de ChatGPT. En este proceso, entrenadores humanos evaluaron las salidas del modelo y brindaron retroalimentación, ayudando al sistema a aprender qué respuestas eran más útiles, precisas y alineadas con los valores humanos. Estos entrenadores no verificaron cada afirmación; más bien, evaluaron la calidad general, utilidad y seguridad de las respuestas, lo que indirectamente influyó en cómo el modelo prioriza y presenta la información. El proceso RLHF influye significativamente en qué información se enfatiza en las respuestas y cómo se abordan los diferentes temas, introduciendo juicio humano en lo que de otro modo sería un modelo puramente estadístico. Sin embargo, este proceso de retroalimentación humana tiene limitaciones inherentes: los entrenadores tienen sus propios sesgos, lagunas de conocimiento y limitaciones, y no pueden evaluar la precisión de cada afirmación en todos los ámbitos. Además, el proceso requiere muchos recursos y solo puede aplicarse a una fracción de las posibles salidas del modelo, lo que significa que gran parte del comportamiento de ChatGPT sigue reflejando los patrones en sus datos de entrenamiento en vez de una curación humana explícita.
Cómo Citar Correctamente a ChatGPT
Citar a ChatGPT es importante para la integridad académica y la transparencia, permitiendo a los lectores saber de dónde proviene la información y potencialmente reproducir o verificar tus hallazgos. El formato de cita depende de la guía de estilo requerida, pero aquí tienes los enfoques más comunes:
Ejemplo en formato MLA:
OpenAI. "ChatGPT." Accedido el [Fecha], https://chat.openai.com.
En estilo MLA, se cita a ChatGPT como un sitio web, incluyendo la fecha de acceso ya que el contenido es dinámico y puede cambiar. Si citas una respuesta específica, deberías indicar la fecha de acceso e idealmente el prompt o pregunta que hiciste.
Ejemplo en formato APA:
OpenAI. (2024). ChatGPT (Versión 4) [Gran modelo de lenguaje].
Recuperado de https://chat.openai.com
El formato APA trata a ChatGPT como una herramienta de software o aplicación, incluyendo el número de versión y la fecha de recuperación. Algunas guías APA recomiendan incluir el prompt específico en la cita o en una nota complementaria.
Cuándo citar a ChatGPT: Debes citar la herramienta siempre que utilices su salida en trabajos académicos, informes profesionales o cualquier contexto donde la atribución sea relevante. Documenta el prompt exacto que utilizaste, la fecha de acceso y, de ser posible, la versión de ChatGPT, ya que estos detalles afectan la reproducibilidad. La principal diferencia entre citar a ChatGPT y a fuentes tradicionales es que las respuestas de ChatGPT se generan dinámicamente—el mismo prompt puede producir salidas ligeramente diferentes en distintas ocasiones—por lo que incluir el prompt es parte de una cita adecuada. Muchas instituciones aún están desarrollando lineamientos formales para citar IA, así que consulta con tu organización o publicación por su formato preferido.
Limitaciones y Consideraciones de Fiabilidad
Aunque ChatGPT es notablemente capaz, tiene limitaciones importantes que afectan la fiabilidad de su información. ChatGPT puede afirmar información falsa con confianza, un problema conocido como alucinación, particularmente cuando se le pregunta por temas poco comunes, eventos recientes posteriores a su fecha de corte o cuando hay información contradictoria en sus datos de entrenamiento. Los datos de entrenamiento del modelo contienen sesgos inherentes que reflejan las perspectivas, demografía y puntos de vista presentes en las fuentes, lo que significa que las respuestas pueden favorecer inadvertidamente ciertas posturas o contener estereotipos. La información en los datos de entrenamiento de ChatGPT se vuelve cada vez más desactualizada con el tiempo, por lo que no es fiable para estadísticas actuales, hallazgos recientes o situaciones en evolución. Por estas razones, verificar las afirmaciones de ChatGPT es esencial, especialmente para decisiones importantes; debes contrastar los datos clave con fuentes primarias, publicaciones recientes y bases de datos autorizadas. Para verificar las afirmaciones de ChatGPT, cruza sus declaraciones con múltiples fuentes independientes, revisa fechas y estadísticas con datos actuales y sé especialmente escéptico ante cifras, nombres o eventos recientes. Por último, recuerda que ChatGPT no es una fuente primaria; es una fuente secundaria que sintetiza información de otras fuentes, por lo que para trabajos académicos o profesionales deberías citar las fuentes originales referenciadas por ChatGPT en vez de ChatGPT mismo.
Monitoreo de Citas de IA con AmICited
A medida que ChatGPT y otros sistemas de IA se integran cada vez más en la manera en que las personas descubren información, monitorear cómo estos sistemas citan y hacen referencia a tu marca u organización se ha vuelto crucial. AmICited es una plataforma de monitoreo de respuestas de IA diseñada específicamente para rastrear cómo ChatGPT, Claude y otros grandes modelos de lenguaje mencionan, citan o hacen referencia a tu empresa, productos o marca en sus respuestas. La plataforma te ayuda a entender cuándo y cómo aparece tu marca en respuestas generadas por IA, brindando visibilidad sobre un canal nuevo y creciente de descubrimiento de información que las herramientas tradicionales de monitoreo web suelen pasar por alto. Esta capacidad de monitoreo es esencial porque las citas de IA funcionan de manera diferente a las citas web tradicionales—están integradas en respuestas conversacionales con las que millones de usuarios interactúan a diario, y la mayoría de las marcas no tiene visibilidad sobre cómo están siendo representadas. Al usar AmICited para rastrear menciones y citas de IA, obtienes información sobre la percepción de marca en los sistemas de IA, puedes identificar imprecisiones o información desactualizada que requiere corrección y entiendes cómo tu marca se compara con la competencia en respuestas generadas por IA. En una era en la que los sistemas de IA están convirtiéndose en fuentes primarias de información para muchos usuarios, monitorear tu presencia en estos sistemas es tan importante como monitorear los resultados de búsqueda tradicionales, haciendo que herramientas como AmICited sean esenciales para la gestión moderna de marcas y la transparencia en IA.
Preguntas frecuentes
¿De dónde obtiene exactamente ChatGPT sus datos de entrenamiento?
ChatGPT fue entrenado con tres fuentes principales: datos públicos disponibles en internet (sitios web, artículos, foros), conjuntos de datos con licencia (libros y publicaciones académicas) y retroalimentación humana de entrenadores. Los datos de entrenamiento abarcan sitios de noticias, revistas académicas, documentación técnica, Wikipedia, Reddit, Stack Overflow y muchísimas otras páginas web de acceso público recopiladas hasta su fecha de corte de conocimiento.
¿Qué es una fecha de corte de conocimiento y por qué es importante?
Una fecha de corte de conocimiento es el momento a partir del cual ChatGPT ya no tiene datos de entrenamiento. ChatGPT-4 tiene una fecha de corte en diciembre de 2023, mientras que ChatGPT-4o la tiene en octubre de 2023. Esto es importante porque ChatGPT no puede proporcionar información precisa sobre eventos, investigaciones o desarrollos ocurridos después de su periodo de entrenamiento, lo que lo hace poco fiable para consultas sensibles al tiempo.
¿Puede ChatGPT acceder a información en tiempo real?
ChatGPT no puede acceder a información en tiempo real solo con sus datos de entrenamiento. Sin embargo, versiones más recientes de ChatGPT pueden realizar búsquedas en la web para obtener información actual más allá de sus fechas de corte de conocimiento, aunque esta función no está disponible en todas las versiones o contextos y requiere activación explícita.
¿Cómo cito a ChatGPT en mi trabajo académico?
En formato MLA, cita a ChatGPT como un sitio web con la fecha de acceso. En formato APA, trátalo como un software e incluye el número de versión. Ambos formatos requieren documentar el prompt exacto que usaste, la fecha de acceso y, de ser posible, la versión de ChatGPT, ya que el mismo prompt puede producir salidas diferentes en distintas ocasiones.
¿La información de ChatGPT siempre es precisa?
No. ChatGPT puede afirmar información falsa con confianza (alucinación), especialmente respecto a temas poco comunes, eventos recientes posteriores a su fecha de corte o información contradictoria. Sus datos de entrenamiento contienen sesgos inherentes y la información se vuelve cada vez más desactualizada. Siempre verifica las afirmaciones importantes con fuentes primarias y bases de datos autorizadas.
¿Con qué frecuencia se actualizan los datos de entrenamiento de ChatGPT?
Los datos de entrenamiento de ChatGPT no se actualizan de forma continua. Se lanzan nuevas versiones periódicamente con fechas de corte de conocimiento actualizadas, pero no hay actualización en tiempo real del modelo base. OpenAI publica nuevas versiones (como GPT-4o) con datos de entrenamiento más recientes, pero el cronograma exacto de actualizaciones no es público.
¿Puede ChatGPT citar sus fuentes?
ChatGPT no cita fuentes específicas para afirmaciones individuales porque sintetiza información a partir de patrones en sus datos de entrenamiento en lugar de recuperar documentos concretos. No puede señalarte la fuente exacta de un hecho. Para trabajos académicos, debes verificar las afirmaciones de ChatGPT y citar las fuentes originales que encuentres, no a ChatGPT en sí.
¿Cómo ayuda AmICited a monitorear las citas de ChatGPT?
AmICited rastrea cómo ChatGPT, Claude y otros sistemas de IA mencionan, citan o hacen referencia a tu marca en sus respuestas. Ofrece visibilidad sobre cómo aparece tu empresa en respuestas generadas por IA, ayuda a identificar imprecisiones y muestra cómo tu marca se compara con competidores en los sistemas de IA—esencial para la gestión moderna de marcas en la era de la IA.
Monitorea Cómo ChatGPT Hace Referencia a Tu Marca
Rastrea en tiempo real las citas de ChatGPT y las menciones de IA con AmICited. Comprende cómo los sistemas de IA hacen referencia a tu marca y mantente a la vanguardia en el descubrimiento de información impulsado por IA.
Cómo excluirse del entrenamiento de IA en las principales plataformas
Guía completa para excluirse de la recopilación de datos para entrenamiento de IA en ChatGPT, Perplexity, LinkedIn y otras plataformas. Aprende instrucciones pa...
El papel de Wikipedia en los datos de entrenamiento de IA: calidad, impacto y licenciamiento
Descubre cómo Wikipedia sirve como un conjunto de datos crítico para el entrenamiento de IA, su impacto en la precisión de los modelos, acuerdos de licencia y p...
Descubre cómo ChatGPT selecciona y cita fuentes al navegar por la web. Conoce los factores de credibilidad, los algoritmos de búsqueda y cómo optimizar tu conte...
8 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.