La guía completa para bloquear (o permitir) rastreadores de IA
Aprende a bloquear o permitir rastreadores de IA como GPTBot y ClaudeBot usando robots.txt, bloqueo a nivel de servidor y métodos avanzados de protección. Guía técnica completa con ejemplos.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
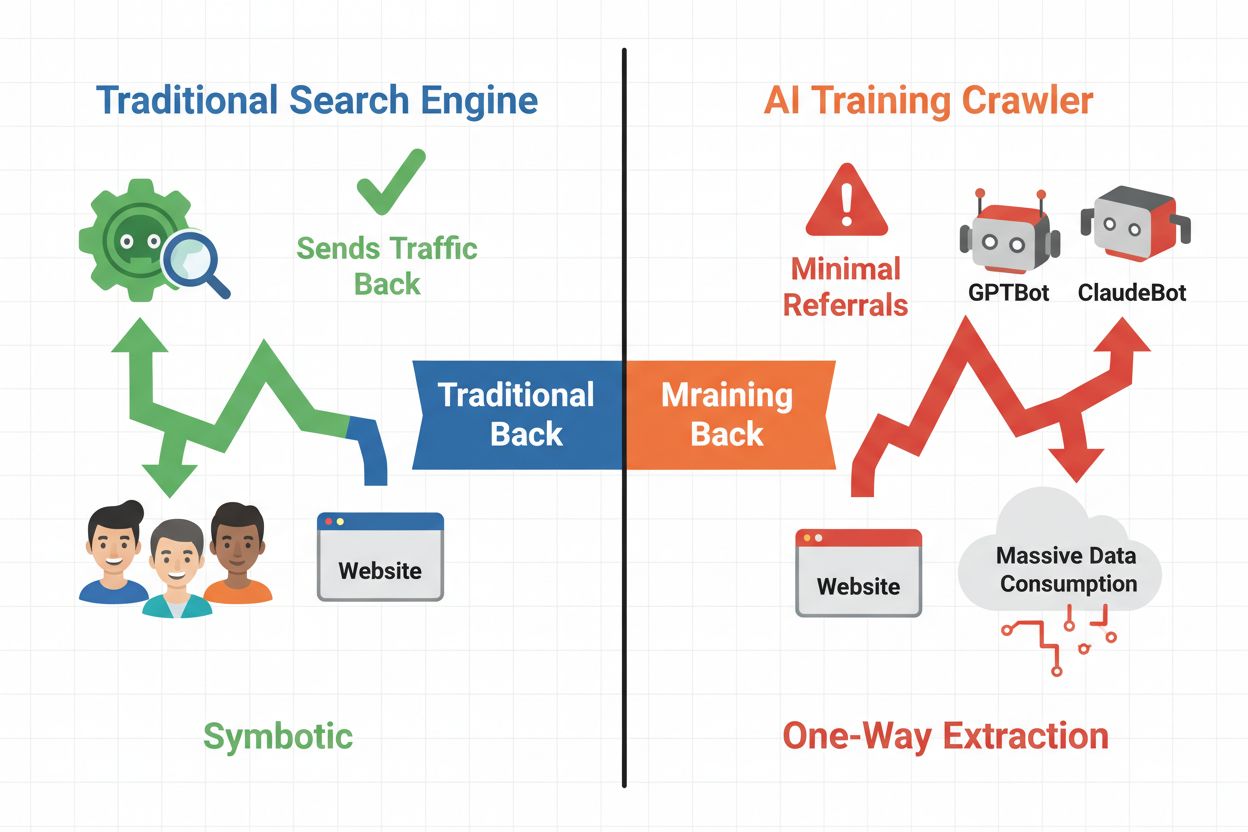
El panorama digital ha cambiado fundamentalmente, pasando de la optimización tradicional para motores de búsqueda a la gestión de una categoría completamente nueva de visitantes automatizados: los rastreadores de IA. A diferencia de los bots de búsqueda convencionales que llevan tráfico a tu sitio mediante resultados de búsqueda, los rastreadores de entrenamiento de IA consumen tu contenido para construir grandes modelos de lenguaje sin necesariamente enviar tráfico de referencia a cambio. Esta distinción tiene profundas implicaciones para editores, creadores de contenido y empresas que dependen del tráfico web como fuente de ingresos. Las apuestas son altas: controlar qué sistemas de IA acceden a tu contenido impacta directamente en tu ventaja competitiva, la privacidad de tus datos y tus resultados financieros.
Entendiendo los tipos de rastreadores de IA
Los rastreadores de IA se dividen en tres categorías distintas, cada una con diferentes propósitos e implicaciones de tráfico. Los rastreadores de entrenamiento son utilizados por empresas de IA para construir y mejorar sus modelos de lenguaje, operando normalmente a gran escala con un retorno de tráfico mínimo. Los rastreadores de búsqueda y citación indexan contenido para motores de búsqueda de IA y sistemas de citación, a menudo generando algo de tráfico de referencia para los editores. Los rastreadores activados por el usuario obtienen contenido bajo demanda cuando los usuarios interactúan con aplicaciones de IA, representando un segmento pequeño pero en crecimiento. Comprender estas categorías te ayuda a tomar decisiones informadas sobre qué rastreadores permitir o bloquear según tu modelo de negocio.
Tipo de rastreador
Propósito
Impacto en el tráfico
Ejemplos
Entrenamiento
Construir/mejorar LLMs
Mínimo o ninguno
GPTBot, ClaudeBot, Bytespider
Búsqueda/Citación
Indexar para búsqueda y citaciones IA
Tráfico de referencia moderado
Googlebot-Extended, Perplexity
Activado por usuario
Obtener bajo demanda para usuarios
Bajo pero constante
Plugins de ChatGPT, navegación de Claude
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Los principales rastreadores de IA que debes conocer
El ecosistema de rastreadores de IA incluye rastreadores de las mayores empresas tecnológicas del mundo, cada uno con user agents y propósitos distintos. GPTBot de OpenAI (user agent: GPTBot/1.0) rastrea para entrenar ChatGPT y otros modelos, mientras que ClaudeBot de Anthropic (user agent: Claude-Web/1.0) cumple funciones similares para Claude. Googlebot-Extended de Google (user agent: Mozilla/5.0 ... Googlebot-Extended) indexa contenido para AI Overviews y Bard, mientras que Meta-ExternalFetcher de Meta rastrea para sus iniciativas de IA. Otros actores principales incluyen:
Bytespider (ByteDance) - Uno de los rastreadores más agresivos, usado para entrenar modelos chinos de IA
Amazonbot (Amazon) - Rastrea para Alexa y servicios de IA de AWS
Applebot-Extended (Apple) - Indexa contenido para Siri y funciones de Apple Intelligence
Perplexity Bot - Rastrea para su motor de búsqueda de IA (conocido por ignorar robots.txt)
CCBot (Common Crawl) - Construye conjuntos de datos abiertos usados por muchas empresas de IA
Cada rastreador opera a diferentes escalas y respeta las directivas de bloqueo en distintos grados de cumplimiento.
Cómo bloquear rastreadores de IA con robots.txt
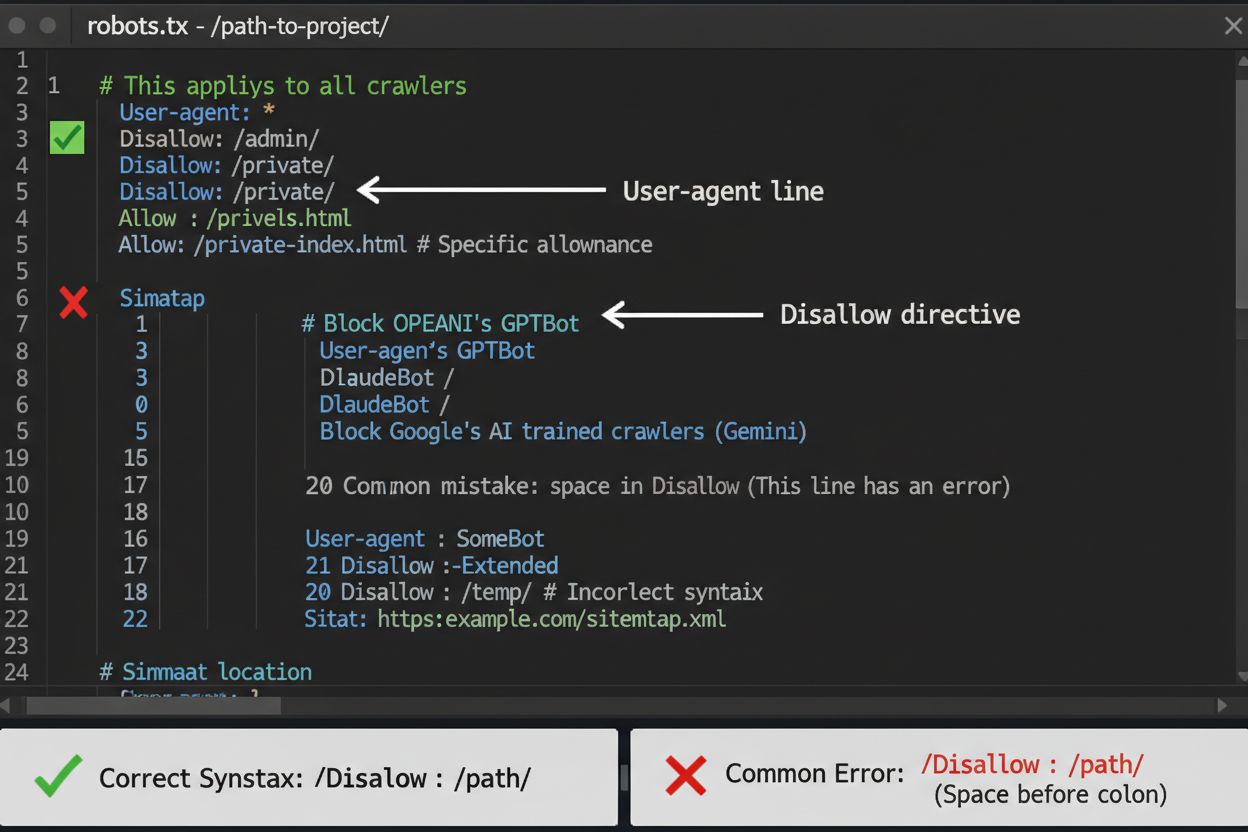
El archivo robots.txt es tu primera línea de defensa para controlar el acceso de los rastreadores de IA, aunque es importante entender que es solo una sugerencia y no tiene fuerza legal. Ubicado en la raíz de tu dominio (por ejemplo, tusitio.com/robots.txt), este archivo usa sintaxis simple para indicar a los rastreadores qué áreas deben evitar. Para bloquear todos los rastreadores de IA de manera integral, agrega las siguientes reglas:
Un error común es usar reglas demasiado generales como Disallow: *, lo que puede confundir a los parsers, o olvidar especificar rastreadores individuales cuando solo deseas bloquear algunos. Grandes empresas como OpenAI, Anthropic y Google generalmente respetan las directivas de robots.txt, aunque algunos rastreadores como Perplexity han sido documentados ignorando estas reglas por completo.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Más allá de robots.txt - Métodos de protección más fuertes
Cuando robots.txt no es suficiente, varios métodos de protección más robustos ofrecen control adicional sobre el acceso de rastreadores de IA. El bloqueo por IP implica identificar rangos de IP de rastreadores de IA y bloquearlos a nivel de firewall o servidor; esto es muy efectivo pero requiere mantenimiento continuo, ya que los rangos de IP cambian. El bloqueo a nivel de servidor mediante archivos .htaccess (Apache) o archivos de configuración de Nginx proporciona un control más granular y es más difícil de eludir que robots.txt. Para servidores Apache, implementa esta regla de bloqueo:
El bloqueo con metaetiquetas usando <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> previene la indexación pero no detiene a los rastreadores de entrenamiento. La verificación de cabeceras de solicitud comprueba si los rastreadores provienen realmente de sus fuentes declaradas mediante la verificación de DNS inversa y certificados SSL. Utiliza el bloqueo a nivel de servidor cuando necesites la certeza absoluta de que los rastreadores no accederán a tu contenido y combina varios métodos para una protección máxima.
La decisión estratégica - Bloquear vs. Permitir
Decidir si bloquear rastreadores de IA requiere sopesar varios intereses contrapuestos. Bloquear rastreadores de entrenamiento (GPTBot, ClaudeBot, Bytespider) impide que tu contenido sea utilizado para entrenar modelos de IA, protegiendo tu propiedad intelectual y tu ventaja competitiva. Sin embargo, permitir rastreadores de búsqueda (Googlebot-Extended, Perplexity) puede generar tráfico de referencia e incrementar la visibilidad en resultados de búsqueda impulsados por IA—un canal de descubrimiento en crecimiento. El dilema se complica cuando se considera que algunas empresas de IA tienen una pobre proporción de rastreo frente a referencias: los rastreadores de Anthropic generan aproximadamente 38,000 solicitudes de rastreo por cada referencia, mientras que la relación de OpenAI es de alrededor de 400:1. La carga del servidor y el ancho de banda son otra consideración: los rastreadores de IA consumen recursos significativos, y bloquearlos puede reducir los costos de infraestructura. Tu decisión debe alinearse con tu modelo de negocio: las organizaciones de noticias y editores pueden beneficiarse del tráfico de referencia, mientras que las empresas SaaS y creadores de contenido propietario suelen preferir bloquear.
Monitoreo y verificación
Implementar bloqueos de rastreadores es solo la mitad de la batalla: debes verificar que realmente respeten tus directivas. El análisis de registros de servidor es tu principal herramienta de verificación; examina tus registros de acceso en busca de cadenas de user agent e IPs de rastreadores que intentan acceder a tu sitio tras el bloqueo. Usa grep para buscar en tus registros:
Este comando cuenta cuántas veces estos rastreadores han accedido a tu sitio. Las herramientas de prueba como curl pueden simular solicitudes de rastreadores para verificar que tus reglas de bloqueo funcionen correctamente:
curl -A "GPTBot/1.0" https://tusitio.com/robots.txt
Monitorea tus registros semanalmente durante el primer mes tras implementar los bloqueos y luego cada trimestre. Si detectas rastreadores que ignoran tu robots.txt, escala a bloqueo a nivel de servidor o contacta al equipo de abuso del operador del rastreador.
Manteniendo tu lista de bloqueos actualizada
El panorama de rastreadores de IA evoluciona rápidamente a medida que nuevas empresas lanzan productos de IA y los rastreadores existentes cambian sus cadenas de user agent y rangos de IP. Las revisiones trimestrales de tu lista de bloqueos aseguran que no te pierdas nuevos rastreadores ni bloquees accidentalmente tráfico legítimo. El ecosistema de rastreadores es fragmentado y descentralizado, lo que hace imposible crear una lista de bloqueos verdaderamente permanente. Monitorea estos recursos para actualizaciones:
Documentación oficial de OpenAI para cambios en GPTBot
Comunicados públicos de Anthropic sobre el comportamiento de ClaudeBot
Foros comunitarios y discusiones en Reddit donde los desarrolladores comparten nuevos rastreadores descubiertos
Tus propios registros de servidor para user agents desconocidos que podrían ser nuevos rastreadores de IA
Publicaciones de la industria y blogs de seguridad que rastrean la actividad emergente de rastreadores de IA
Configura recordatorios en tu calendario para revisar tu robots.txt y las reglas a nivel de servidor cada 90 días y suscríbete a listas de correo de seguridad que informan sobre nuevos despliegues de rastreadores.
Cómo AmICited ayuda a monitorear referencias de IA
Mientras que bloquear rastreadores de IA impide que accedan a tu contenido, AmICited aborda el desafío complementario: monitorear si los sistemas de IA citan y mencionan tu marca y contenido en sus resultados. AmICited rastrea menciones de tu organización en respuestas generadas por IA, proporcionando visibilidad sobre cómo tu contenido influye en las salidas de los modelos de IA y dónde aparece tu marca en resultados de búsqueda de IA. Esto genera una estrategia de IA integral: controlas qué rastreadores pueden acceder mediante robots.txt y bloqueos a nivel de servidor, mientras AmICited garantiza que comprendas el impacto posterior de tu contenido en los sistemas de IA. Juntas, estas herramientas te ofrecen visibilidad y control total sobre tu presencia en el ecosistema de IA: desde prevenir el uso no deseado de tus datos para entrenamiento hasta medir las citas y referencias reales que genera tu contenido en plataformas de IA.
Preguntas frecuentes
¿Bloquear bots de IA perjudica mi posicionamiento SEO?
No. Bloquear rastreadores de entrenamiento de IA como GPTBot, ClaudeBot y Bytespider no afecta tu posicionamiento en Google o Bing. Los motores de búsqueda tradicionales usan diferentes rastreadores (Googlebot, Bingbot) que funcionan de forma independiente. Solo bloquea esos si deseas desaparecer completamente de los resultados de búsqueda.
¿Qué bots de IA realmente respetan robots.txt?
Los principales rastreadores de OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) y Perplexity (PerplexityBot) declaran oficialmente respetar las directivas de robots.txt. Sin embargo, rastreadores más pequeños o menos transparentes pueden ignorar tu configuración, por eso existen estrategias de protección en capas.
¿Debo bloquear todos los rastreadores de IA o solo los de entrenamiento?
Depende de tu estrategia. Bloquear solo los rastreadores de entrenamiento (GPTBot, ClaudeBot, Bytespider) protege tu contenido del entrenamiento de modelos, permitiendo que rastreadores enfocados en búsqueda te ayuden a aparecer en resultados de búsqueda de IA. El bloqueo completo te elimina del ecosistema de IA por completo.
¿Con qué frecuencia debo actualizar mi robots.txt para nuevos bots de IA?
Revisa tu configuración al menos trimestralmente. Las empresas de IA introducen nuevos rastreadores regularmente. Anthropic fusionó sus bots 'anthropic-ai' y 'Claude-Web' en 'ClaudeBot', lo que dio al nuevo bot acceso temporal sin restricciones a sitios que no habían actualizado sus reglas.
¿Cuál es la diferencia entre bloquear y permitir rastreadores de IA?
Bloquear impide que los rastreadores accedan a tu contenido completamente, protegiéndolo de la recolección de datos de entrenamiento o indexación. Permitir rastreadores les da acceso, pero puede resultar en que tu contenido se use para entrenar modelos o aparecer en resultados de búsqueda de IA con poco tráfico de referencia.
¿Pueden los rastreadores de IA ignorar las directivas de robots.txt?
Sí, robots.txt es una sugerencia y no tiene fuerza legal. Los rastreadores bien comportados de grandes empresas generalmente respetan robots.txt, pero algunos rastreadores lo ignoran. Para una protección más fuerte, implementa bloqueos a nivel de servidor vía .htaccess o reglas de firewall.
¿Cómo sé si mi robots.txt está funcionando?
Revisa los registros de tu servidor en busca de cadenas de user agent de rastreadores bloqueados. Si ves solicitudes de rastreadores que has bloqueado, es posible que no estén respetando robots.txt. Usa herramientas de prueba como el probador de robots.txt de Google Search Console o comandos curl para verificar tu configuración.
¿Cuál es el impacto en el tráfico de mi sitio si bloqueo rastreadores de IA?
Bloquear rastreadores de entrenamiento normalmente tiene un impacto mínimo en el tráfico directo, ya que apenas generan tráfico de referencia. Sin embargo, bloquear rastreadores de búsqueda puede reducir la visibilidad en plataformas de descubrimiento impulsadas por IA. Monitorea tus analíticas durante 30 días después de implementar los bloqueos para medir el impacto real.
Monitorea cómo los sistemas de IA mencionan tu marca
Aunque controlas el acceso de los rastreadores con robots.txt, AmICited te ayuda a rastrear cómo los sistemas de IA citan y mencionan tu contenido en sus resultados. Obtén visibilidad total sobre tu presencia en IA.
Cómo identificar rastreadores de IA en los registros de tu servidor
Aprende a identificar y monitorear rastreadores de IA como GPTBot, ClaudeBot y PerplexityBot en los registros de tu servidor. Guía completa con cadenas de user-...
Cómo identificar rastreadores de IA en los registros del servidor: Guía completa de detección
Aprende a identificar y monitorear rastreadores de IA como GPTBot, PerplexityBot y ClaudeBot en los registros de tu servidor. Descubre cadenas de user-agent, mé...
Tarjeta de Referencia de Rastreadores de IA: Todos los Bots de un Vistazo
Guía de referencia completa de rastreadores y bots de IA. Identifica GPTBot, ClaudeBot, Google-Extended y más de 20 rastreadores de IA con user agents, tasas de...
18 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.