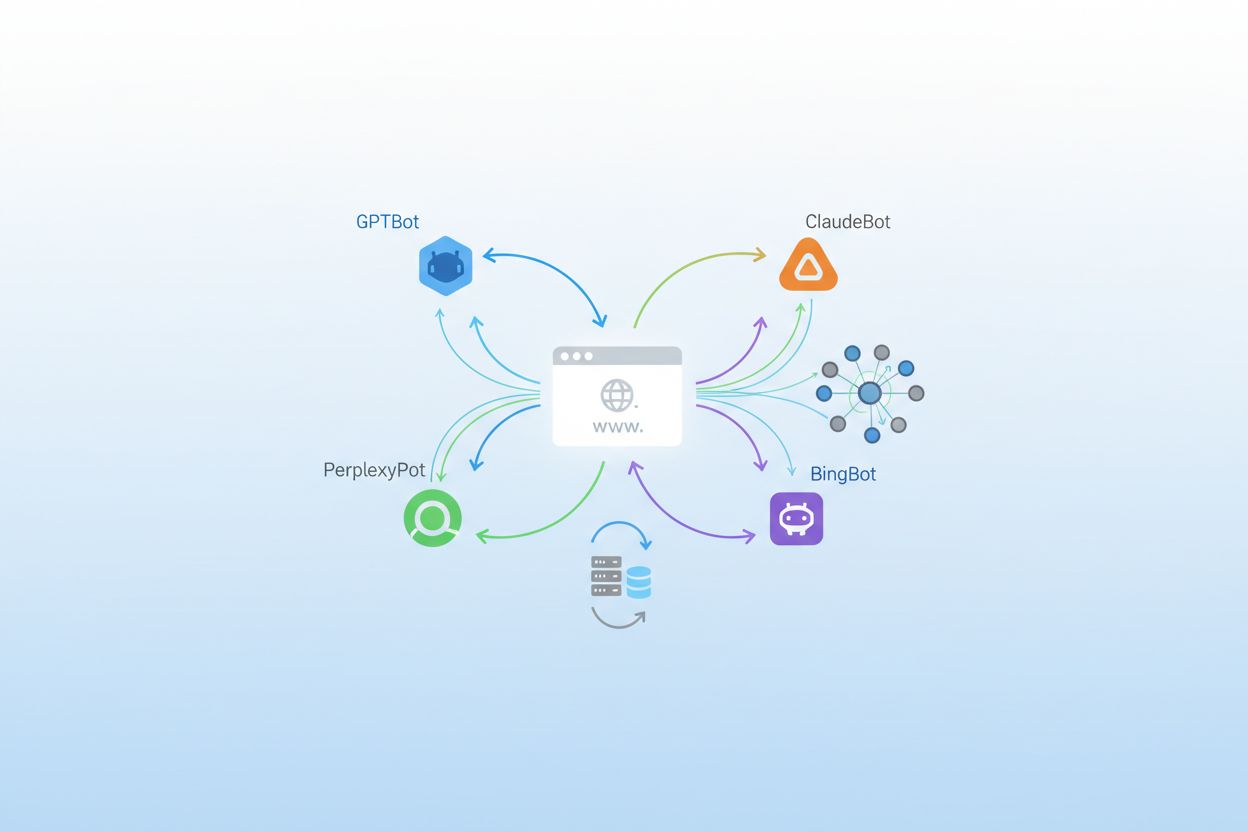
Lista completa de rastreadores de IA en 2025: Todos los bots que debes conocer
Guía completa de rastreadores de IA en 2025. Identifica GPTBot, ClaudeBot, PerplexityBot y más de 20 bots de IA. Aprende cómo bloquear, permitir o monitorear rastreadores con robots.txt y técnicas avanzadas.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Los rastreadores de IA son bots automatizados diseñados para navegar y recopilar sistemáticamente datos de sitios web, pero su propósito ha cambiado fundamentalmente en los últimos años. Mientras que los rastreadores tradicionales de motores de búsqueda como Googlebot se centran en indexar contenido para resultados de búsqueda, los rastreadores modernos de IA priorizan la recopilación de datos de entrenamiento para grandes modelos de lenguaje y sistemas de IA generativa. Según datos recientes de Playwire, los rastreadores de IA ahora representan aproximadamente el 80% de todo el tráfico de bots de IA, lo que supone un aumento drástico en el volumen y la diversidad de visitantes automatizados a los sitios web. Este cambio refleja la transformación general en cómo se desarrollan y entrenan los sistemas de inteligencia artificial, alejándose de conjuntos de datos públicos hacia la recopilación de contenido web en tiempo real. Comprender estos rastreadores se ha vuelto esencial para propietarios de sitios, editores y creadores de contenido que necesitan tomar decisiones informadas sobre su presencia digital.
Tres categorías de rastreadores de IA
Los rastreadores de IA pueden clasificarse en tres categorías distintas según su función, comportamiento e impacto en tu sitio web. Los rastreadores de entrenamiento representan el segmento más grande, con aproximadamente el 80% del tráfico de bots de IA, y están diseñados para recopilar contenido para el entrenamiento de modelos de aprendizaje automático; estos rastreadores suelen operar con alto volumen y mínimo tráfico de referencia, por lo que consumen mucho ancho de banda pero es poco probable que generen visitantes a tu sitio. Los rastreadores de búsqueda y citación operan a volúmenes moderados y están diseñados específicamente para encontrar y referenciar contenido en resultados y aplicaciones de búsqueda impulsadas por IA; a diferencia de los rastreadores de entrenamiento, estos bots pueden enviar tráfico a tu sitio cuando los usuarios hacen clic desde respuestas generadas por IA. Los rastreadores activados por el usuario representan la categoría más pequeña y operan bajo demanda cuando los usuarios solicitan explícitamente la recuperación de contenido a través de aplicaciones de IA como la función de navegación de ChatGPT; estos rastreadores tienen bajo volumen pero alta relevancia para consultas individuales de usuarios.
Categoría
Propósito
Ejemplos
Rastreadores de entrenamiento
Recopilar datos para entrenamiento de modelos de IA
GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider
Rastreadores de búsqueda/citación
Encontrar y referenciar contenido en respuestas de IA
OpenAI opera el ecosistema de rastreadores más diverso y agresivo en el panorama de la IA, con múltiples bots que cumplen diferentes propósitos en su suite de productos. GPTBot es su rastreador de entrenamiento principal, encargado de recopilar contenido para mejorar GPT-4 y futuros modelos, y ha experimentado un asombroso 305% de crecimiento en el tráfico de rastreadores según datos de Cloudflare; este bot opera con una relación de 400:1 entre rastreo y referencia, es decir, descarga contenido 400 veces por cada visitante que devuelve a tu sitio. OAI-SearchBot cumple una función completamente diferente, centrada en buscar y citar contenido para la función de búsqueda de ChatGPT sin usar el contenido para el entrenamiento de modelos. ChatGPT-User representa la categoría de mayor crecimiento explosivo, con un notable 2,825% de aumento en el tráfico, y opera cada vez que los usuarios habilitan la función “Navegar con Bing” para obtener contenido en tiempo real bajo demanda. Puedes identificar estos rastreadores por sus cadenas de user agent: GPTBot/1.0, OAI-SearchBot/1.0 y ChatGPT-User/1.0, y OpenAI proporciona métodos de verificación de IP para confirmar el tráfico legítimo de rastreadores desde su infraestructura.
Rastreadores de IA de Anthropic y Google
Anthropic, la empresa detrás de Claude, opera una de las operaciones de rastreo más selectivas pero intensivas de la industria. ClaudeBot es su rastreador de entrenamiento principal y opera con una extraordinaria relación 38,000:1 de rastreo a referencia, lo que significa que descarga contenido de manera mucho más agresiva que los bots de OpenAI en proporción al tráfico devuelto; esta relación extrema refleja el enfoque de Anthropic en la recopilación exhaustiva de datos para el entrenamiento de modelos. Claude-Web y Claude-SearchBot cumplen diferentes propósitos, el primero maneja la recuperación de contenido activado por el usuario y el segundo se enfoca en la funcionalidad de búsqueda y citación. Google ha adaptado su estrategia de rastreadores para la era de la IA introduciendo Google-Extended, un token especial que permite a los sitios web optar por el entrenamiento de IA mientras bloquean la indexación tradicional de Googlebot, y Gemini-Deep-Research, que realiza consultas de investigación a fondo para usuarios de los productos de IA de Google. Muchos propietarios de sitios debaten si bloquear Google-Extended ya que proviene de la misma empresa que controla el tráfico de búsqueda, haciendo que la decisión sea más compleja que con rastreadores de IA de terceros.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meta, Apple, Amazon y Perplexity
Meta se ha convertido en un actor importante en el espacio de rastreadores de IA con Meta-ExternalAgent, que representa aproximadamente el 19% del tráfico de rastreadores de IA y se utiliza para entrenar sus modelos de IA y potenciar funciones en Facebook, Instagram y WhatsApp. Meta-WebIndexer cumple una función complementaria, enfocándose en la indexación web para sus funciones y recomendaciones potenciadas por IA. Apple introdujo Applebot-Extended para apoyar Apple Intelligence, sus funciones de IA en el dispositivo, y este rastreador ha crecido de forma constante a medida que la empresa expande sus capacidades de IA en dispositivos iPhone, iPad y Mac. Amazon opera Amazonbot para potenciar Alexa y Rufus, su asistente de compras con IA, haciéndolo relevante para sitios de comercio electrónico y contenido orientado a productos. PerplexityBot representa una de las historias de crecimiento más dramáticas en el panorama de rastreadores, con un asombroso 157,490% de aumento en el tráfico, reflejando el crecimiento explosivo de Perplexity AI como alternativa de búsqueda; a pesar de este crecimiento masivo, Perplexity sigue representando un volumen absoluto menor en comparación con OpenAI y Google, pero la tendencia indica una importancia creciente rápidamente.
Rastreadores emergentes y especializados
Más allá de los grandes actores, numerosos rastreadores de IA emergentes y especializados están recopilando activamente datos de sitios web en toda la red. Bytespider, operado por ByteDance (la empresa matriz de TikTok), experimentó una dramática caída del 85% en el tráfico de rastreadores, lo que sugiere un cambio de estrategia o una reducción en la necesidad de recopilación de datos de entrenamiento. Cohere, Diffbot y CCBot de Common Crawl representan rastreadores especializados enfocados en casos de uso específicos, desde el entrenamiento de modelos de lenguaje hasta la extracción de datos estructurados. You.com, Mistral y DuckDuckGo operan sus propios rastreadores para soportar funciones de búsqueda y asistentes potenciadas por IA, sumando complejidad al panorama de rastreadores. La aparición de nuevos rastreadores sucede regularmente, con startups y empresas consolidadas lanzando continuamente productos de IA que requieren recopilación de datos web. Mantenerse informado sobre estos rastreadores emergentes es crucial porque bloquearlos o permitirlos puede impactar significativamente tu visibilidad en nuevas plataformas de descubrimiento y aplicaciones impulsadas por IA.
Cómo identificar rastreadores de IA
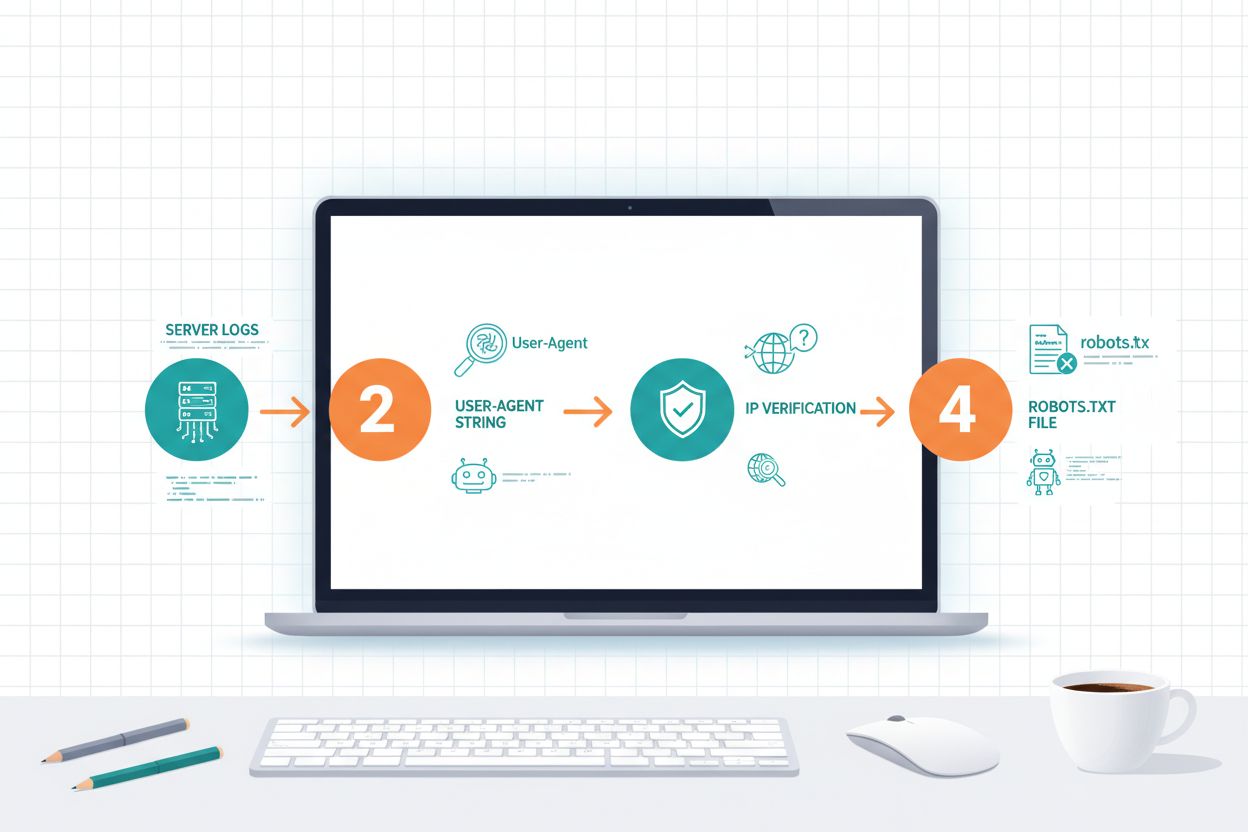
Identificar rastreadores de IA requiere comprender cómo se identifican y analizar los patrones de tráfico de tu servidor. Las cadenas de user-agent son el principal método de identificación, ya que cada rastreador se anuncia con un identificador específico en las solicitudes HTTP; por ejemplo, GPTBot usa GPTBot/1.0, ClaudeBot usa Claude-Web/1.0 y PerplexityBot usa PerplexityBot/1.0. Analizar tus registros del servidor (normalmente en /var/log/apache2/access.log en servidores Linux o registros IIS en Windows) te permite ver qué rastreadores acceden a tu sitio y con qué frecuencia. La verificación de IP es otra técnica crítica, donde puedes verificar que un rastreador que afirma ser de OpenAI o Anthropic realmente provenga de sus rangos de IP legítimos, los cuales estas empresas publican por motivos de seguridad. Revisar tu archivo robots.txt revela qué rastreadores has permitido o bloqueado explícitamente, y comparar esto con tu tráfico real muestra si los rastreadores están respetando tus directivas. Herramientas como Cloudflare Radar brindan visibilidad en tiempo real sobre los patrones de tráfico de rastreadores y pueden ayudarte a identificar qué bots están más activos en tu sitio. Los pasos prácticos de identificación incluyen: revisar tu plataforma de analítica para tráfico de bots, analizar los registros brutos del servidor en busca de patrones de user-agent, cruzar direcciones IP con los rangos publicados de IP de rastreadores y usar herramientas de verificación en línea para confirmar fuentes de tráfico sospechosas.
Los dilemas: Bloquear vs. Permitir
Decidir si permitir o bloquear rastreadores de IA implica sopesar varios factores de negocio que no tienen una respuesta universal. Los principales dilemas incluyen:
Visibilidad en aplicaciones de IA: Permitir rastreadores asegura que tu contenido aparezca en resultados de búsqueda, plataformas de descubrimiento y respuestas de asistentes de IA, potencialmente generando tráfico de nuevas fuentes
Ancho de banda y carga del servidor: Los rastreadores de entrenamiento consumen mucho ancho de banda y recursos del servidor, con algunos sitios reportando aumentos del 10-30% en el tráfico solo por bots de IA, lo que puede elevar los costos de alojamiento
Protección de contenido vs. tráfico: Bloquear rastreadores protege tu contenido de ser usado en el entrenamiento de IA pero elimina la posibilidad de referencias de tráfico desde plataformas de descubrimiento potenciadas por IA
Potencial de tráfico de referencia: Rastreadores de búsqueda y citación como PerplexityBot y OAI-SearchBot pueden enviar tráfico a tu sitio, mientras que rastreadores de entrenamiento como GPTBot y ClaudeBot normalmente no lo hacen
Posicionamiento competitivo: Competidores que permiten rastreadores pueden ganar visibilidad en aplicaciones de IA mientras tú permaneces invisible, afectando tu posición en el mercado de descubrimiento por IA
Dado que el 80% del tráfico de bots de IA proviene de rastreadores de entrenamiento con mínimo potencial de referencia, muchos editores eligen bloquear rastreadores de entrenamiento y permitir rastreadores de búsqueda y citación. Esta decisión depende en última instancia de tu modelo de negocio, tipo de contenido y prioridades estratégicas respecto a la visibilidad en IA frente al consumo de recursos.
Configuración de Robots.txt para rastreadores de IA
El archivo robots.txt es tu principal herramienta para comunicar políticas a los bots de IA, aunque es importante entender que el cumplimiento es voluntario y no técnicamente exigible. Robots.txt utiliza coincidencias de user-agent para dirigir reglas a rastreadores específicos, permitiéndote crear reglas diferentes para distintos bots; por ejemplo, puedes bloquear GPTBot mientras permites OAI-SearchBot, o bloquear todos los rastreadores de entrenamiento mientras permites los de búsqueda. Según investigaciones recientes, solo el 14% de los 10,000 dominios principales han implementado reglas específicas de robots.txt para IA, lo que indica que la mayoría de los sitios aún no han optimizado sus políticas de rastreadores para la era de la IA. El archivo utiliza una sintaxis simple donde especificas un nombre de user-agent seguido de directivas de disallow o allow, y puedes usar comodines para coincidir con varios rastreadores con nombres similares.
Aquí tienes tres escenarios prácticos de configuración de robots.txt:
# Escenario 1: Bloquear todos los rastreadores de entrenamiento de IA, permitir los de búsqueda
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
# Escenario 2: Bloquear completamente todos los rastreadores de IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Applebot-Extended
Disallow: /
# Escenario 3: Bloqueo selectivo por directorio
User-agent: GPTBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
User-agent: ClaudeBot
Disallow: /
User-agent: OAI-SearchBot
Allow: /
Recuerda que robots.txt es solo una recomendación, y los rastreadores maliciosos o no conformes pueden ignorar tus directivas por completo. La coincidencia de user-agent no distingue mayúsculas de minúsculas, así que gptbot, GPTBot y GPTBOT se refieren al mismo rastreador, y puedes usar User-agent: * para crear reglas que apliquen a todos los rastreadores.
Métodos avanzados de protección
Más allá de robots.txt, existen varios métodos avanzados que brindan mayor protección contra rastreadores de IA no deseados, aunque cada uno tiene distintos niveles de efectividad y complejidad de implementación. La verificación de IP y las reglas de firewall te permiten bloquear tráfico de rangos de IP específicos asociados a rastreadores de IA; puedes obtener estos rangos de la documentación de los operadores de rastreadores y configurar tu firewall o Web Application Firewall (WAF) para rechazar solicitudes de esas IPs, aunque esto requiere mantenimiento continuo porque los rangos de IP cambian. El bloqueo a nivel de servidor con .htaccess proporciona protección en servidores Apache revisando cadenas de user-agent y direcciones IP antes de servir el contenido, ofreciendo una aplicación más confiable que robots.txt ya que opera a nivel de servidor y no depende del cumplimiento del rastreador.
Aquí tienes un ejemplo práctico de .htaccess para bloqueo avanzado de rastreadores:
# Bloquear rastreadores de entrenamiento de IA a nivel de servidor<IfModulemod_rewrite.c> RewriteEngine On# Bloquear por cadena de user-agent RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|Meta-ExternalAgent|Amazonbot|Bytespider) [NC]
RewriteRule ^.*$ - [F,L]
# Bloquear por dirección IP (IPs de ejemplo - reemplazar por IPs reales de rastreadores) RewriteCond %{REMOTE_ADDR} ^192\.0\.2\.0$ [OR]
RewriteCond %{REMOTE_ADDR} ^198\.51\.100\.0$
RewriteRule ^.*$ - [F,L]
# Permitir rastreadores específicos bloqueando otros RewriteCond %{HTTP_USER_AGENT} !OAI-SearchBot [NC]
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule># Enfoque con metaetiquetas HTML (agregar a los encabezados de página)# <meta name="robots" content="noarchive, noimageindex"># <meta name="googlebot" content="noindex, nofollow">
Las metaetiquetas HTML como <meta name="robots" content="noarchive"> y <meta name="googlebot" content="noindex"> ofrecen control a nivel de página, aunque son menos confiables que el bloqueo a nivel de servidor ya que los rastreadores deben analizar el HTML para verlas. Es importante tener en cuenta que la suplantación de IP es técnicamente posible, lo que significa que actores sofisticados podrían hacerse pasar por IPs legítimas de rastreadores, por lo que combinar varios métodos brinda mejor protección que confiar en uno solo. Cada método tiene ventajas: robots.txt es fácil de implementar pero no se hace cumplir, el bloqueo por IP es confiable pero requiere mantenimiento, .htaccess brinda aplicación a nivel de servidor y las metaetiquetas permiten granularidad a nivel de página.
Monitoreo y verificación
Implementar políticas de rastreadores es solo la mitad del trabajo; debes monitorear activamente si los rastreadores respetan tus directivas y ajustar tu estrategia según los patrones de tráfico reales. Los registros del servidor son tu principal fuente de datos, normalmente ubicados en /var/log/apache2/access.log en servidores Linux o en el directorio de registros IIS en servidores Windows, donde puedes buscar cadenas de user-agent específicas para ver qué rastreadores acceden a tu sitio y con qué frecuencia. Plataformas de analítica como Google Analytics, Matomo o Plausible pueden configurarse para rastrear el tráfico de bots por separado de los visitantes humanos, permitiéndote ver el volumen y comportamiento de diferentes rastreadores a lo largo del tiempo. Cloudflare Radar brinda visibilidad en tiempo real sobre patrones de tráfico de rastreadores en toda la red y puede mostrarte cómo el tráfico de rastreadores de tu sitio se compara con los promedios del sector. Para verificar que los rastreadores respeten tus bloqueos, puedes usar herramientas en línea para revisar tu archivo robots.txt, revisar los registros del servidor en busca de user-agents bloqueados y cruzar direcciones IP con los rangos publicados de rastreadores para confirmar que el tráfico proviene realmente de fuentes legítimas. Los pasos prácticos de monitoreo incluyen: configurar análisis semanal de registros para rastrear el volumen de rastreadores, configurar alertas por actividad inusual de rastreadores, revisar tu panel de analítica mensualmente para detectar tendencias de tráfico de bots y realizar revisiones trimestrales de tus políticas de rastreadores para asegurar que sigan alineadas con tus objetivos de negocio. El monitoreo regular te ayuda a identificar nuevos rastreadores, detectar violaciones de políticas y tomar decisiones basadas en datos sobre qué rastreadores permitir o bloquear.
El futuro de los rastreadores de IA
El panorama de los rastreadores de IA continúa evolucionando rápidamente, con nuevos actores ingresando al mercado y rastreadores existentes ampliando sus capacidades en direcciones inesperadas. Rastreadores emergentes de empresas como xAI (Grok), Mistral y DeepSeek están comenzando a recopilar datos web a escala, y cada nueva startup de IA que se lanza probablemente introducirá su propio rastreador para apoyar el entrenamiento de modelos y funciones de producto. Los navegadores agenticos representan una nueva frontera en la tecnología de rastreadores, con sistemas como ChatGPT Operator y Comet que pueden interactuar con sitios web como usuarios humanos, haciendo clic en botones, rellenando formularios y navegando por interfaces complejas; estos agentes basados en navegador presentan desafíos únicos porque son más difíciles de identificar y bloquear usando métodos tradicionales. El problema con los agentes basados en navegador es que pueden no identificarse claramente en las cadenas de user-agent y podrían eludir el bloqueo por IP usando proxies residenciales o infraestructura distribuida. Aparecen nuevos rastreadores regularmente, a veces sin previo aviso, por lo que es esencial mantenerse informado sobre los avances en el espacio de la IA y ajustar tus políticas en consecuencia. La tendencia sugiere que el tráfico de rastreadores seguirá creciendo, con Cloudflare reportando un 18% de aumento general en el tráfico de rastreadores de mayo de 2024 a mayo de 2025, y este crecimiento probablemente se acelere a medida que más aplicaciones de IA lleguen al público general. Los propietarios de sitios y editores deben permanecer atentos y adaptables, revisando regularmente sus políticas de rastreadores y monitoreando nuevos desarrollos para asegurar que sus estrategias sigan siendo efectivas en este panorama en rápida evolución.
Monitorea tu marca en respuestas de IA
Si bien gestionar el acceso de rastreadores a tu sitio es importante, igual de crítico es entender cómo se está usando y citando tu contenido en respuestas generadas por IA. AmICited.com es una plataforma especializada diseñada para resolver este problema al rastrear cómo los rastreadores de IA recopilan tu contenido y monitorear si tu marca y contenido están siendo citados correctamente en aplicaciones potenciadas por IA. La plataforma te ayuda a entender qué sistemas de IA usan tu contenido, con qué frecuencia aparece tu información en respuestas de IA y si se está brindando la atribución adecuada a tus fuentes originales. Para editores y creadores de contenido, AmICited.com proporciona información valiosa sobre tu visibilidad dentro del ecosistema de IA, ayudándote a medir el impacto de tu decisión de permitir o bloquear rastreadores y a comprender el valor real que recibes del descubrimiento por IA. Al monitorear tus citaciones a través de múltiples plataformas de IA, puedes tomar decisiones más informadas sobre tus políticas de rastreadores, identificar oportunidades para mejorar la visibilidad de tu contenido en respuestas de IA y garantizar que tu propiedad intelectual esté correctamente atribuida. Si te tomas en serio comprender la presencia de tu marca en la web impulsada por IA, AmICited.com ofrece la transparencia y las capacidades de monitoreo que necesitas para mantenerte informado y proteger el valor de tu contenido en esta nueva era de descubrimiento impulsado por IA.
Preguntas frecuentes
¿Cuál es la diferencia entre rastreadores de entrenamiento y rastreadores de búsqueda?
Los rastreadores de entrenamiento como GPTBot y ClaudeBot recopilan contenido para crear conjuntos de datos para el desarrollo de grandes modelos de lenguaje, formando parte de la base de conocimiento de la IA. Los rastreadores de búsqueda como OAI-SearchBot y PerplexityBot indexan contenido para experiencias de búsqueda potenciadas por IA y pueden enviar tráfico de referencia a los editores mediante citaciones.
¿Debería bloquear todos los rastreadores de IA o solo los de entrenamiento?
Esto depende de las prioridades de tu negocio. Bloquear rastreadores de entrenamiento protege tu contenido de ser incorporado en modelos de IA. Bloquear rastreadores de búsqueda puede reducir tu visibilidad en plataformas de descubrimiento impulsadas por IA como la búsqueda de ChatGPT o Perplexity. Muchos editores optan por un bloqueo selectivo que apunte a rastreadores de entrenamiento mientras permiten rastreadores de búsqueda y citación.
¿Cómo verifico si un rastreador es legítimo o falsificado?
El método de verificación más confiable es comprobar la IP de la solicitud con los rangos de IP publicados oficialmente por los operadores de los rastreadores. Grandes empresas como OpenAI, Anthropic y Amazon publican las direcciones IP de sus rastreadores. También puedes usar reglas de firewall para incluir en la lista blanca IPs verificadas y bloquear solicitudes de fuentes no verificadas que afirman ser rastreadores de IA.
¿Bloquear Google-Extended afectará mi posicionamiento en búsquedas?
Google afirma oficialmente que bloquear Google-Extended no impacta en los rankings de búsqueda ni en la inclusión en AI Overviews. Sin embargo, algunos webmasters han reportado inquietudes, así que monitorea tu rendimiento en búsquedas después de implementar los bloqueos. AI Overviews en Google Search siguen las reglas estándar de Googlebot, no las de Google-Extended.
¿Con qué frecuencia debo actualizar mi lista de bloqueo de rastreadores de IA?
Nuevos rastreadores de IA surgen regularmente, por lo que revisa y actualiza tu lista de bloqueo al menos trimestralmente. Consulta recursos como el proyecto ai.robots.txt en GitHub para listas mantenidas por la comunidad. Revisa los registros de tu servidor mensualmente para identificar nuevos rastreadores que visitan tu sitio y que no están en tu configuración actual.
¿Pueden los rastreadores de IA ignorar las directivas de robots.txt?
Sí, robots.txt es una recomendación más que una obligación. Los rastreadores bien comportados de grandes empresas generalmente respetan las directivas de robots.txt, pero algunos rastreadores las ignoran. Para mayor protección, implementa bloqueos a nivel de servidor mediante .htaccess o reglas de firewall, y verifica rastreadores legítimos usando los rangos de direcciones IP publicados.
¿Cuál es el impacto de los rastreadores de IA en el ancho de banda de mi sitio web?
Los rastreadores de IA pueden generar una carga significativa en el servidor y consumo de ancho de banda. Algunos proyectos de infraestructura reportaron que bloquear rastreadores de IA redujo el consumo de ancho de banda de 800GB a 200GB diarios, ahorrando aproximadamente $1,500 al mes. Los editores con alto tráfico pueden ver reducciones de costos significativas mediante bloqueos selectivos.
¿Cómo puedo monitorear qué rastreadores de IA están accediendo a mi sitio?
Revisa los registros de tu servidor (normalmente en /var/log/apache2/access.log en Linux) para encontrar cadenas de user-agent que coincidan con rastreadores conocidos. Utiliza plataformas de analítica como Google Analytics o Cloudflare Radar para rastrear el tráfico de bots por separado. Configura alertas por actividad inusual de rastreadores y realiza revisiones trimestrales de tus políticas sobre rastreadores.
Monitorea tu marca en respuestas de IA
Rastrea cómo plataformas de IA como ChatGPT, Perplexity y Google AI Overviews hacen referencia a tu contenido. Recibe alertas en tiempo real cuando tu marca sea mencionada en respuestas generadas por IA.
Tarjeta de Referencia de Rastreadores de IA: Todos los Bots de un Vistazo
Guía de referencia completa de rastreadores y bots de IA. Identifica GPTBot, ClaudeBot, Google-Extended y más de 20 rastreadores de IA con user agents, tasas de...
Explicación de los rastreadores de IA: GPTBot, ClaudeBot y más
Comprende cómo funcionan los rastreadores de IA como GPTBot y ClaudeBot, sus diferencias con los rastreadores de búsqueda tradicionales y cómo optimizar tu siti...
Cómo identificar rastreadores de IA en los registros del servidor: Guía completa de detección
Aprende a identificar y monitorear rastreadores de IA como GPTBot, PerplexityBot y ClaudeBot en los registros de tu servidor. Descubre cadenas de user-agent, mé...
10 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.