Fragmentación de Contenidos para IA: Longitudes Óptimas de Pasajes para Citaciones
Aprende cómo estructurar el contenido en longitudes óptimas de pasajes (100-500 tokens) para maximizar las citaciones de la IA. Descubre estrategias de fragmentación que incrementan la visibilidad en ChatGPT, Google AI Overviews y Perplexity.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
Fragmentación de Contenidos para IA: Longitudes Óptimas de Pasajes para Citaciones
La Fragmentación de Contenidos se Ha Vuelto Clave para la Visibilidad en IA
La fragmentación de contenidos se ha convertido en un factor crítico en la forma en que sistemas de IA como ChatGPT, Google AI Overviews y Perplexity recuperan y citan información de la web. A medida que estas plataformas de búsqueda impulsadas por IA dominan cada vez más las consultas de los usuarios, entender cómo estructurar tu contenido en longitudes óptimas de pasaje impacta directamente en si tu trabajo es descubierto, recuperado y—más importante aún—citado por estos sistemas. La manera en que segmentas tu contenido determina no solo la visibilidad, sino también la calidad y frecuencia de las citaciones. AmICited.com monitorea cómo los sistemas de IA citan tu contenido, y nuestra investigación muestra que los pasajes correctamente fragmentados reciben 3-4 veces más citaciones que el contenido mal estructurado. Ya no se trata solo de SEO; ahora se trata de asegurar que tu experiencia llegue a las audiencias de IA en un formato que puedan entender y atribuir. En esta guía, exploraremos la ciencia detrás de la fragmentación de contenidos y cómo optimizar la longitud de tus pasajes para maximizar el potencial de citación por IA.
¿Qué es la Fragmentación de Contenidos?
La fragmentación de contenidos es el proceso de dividir piezas grandes de contenido en segmentos más pequeños y significativos semánticamente que los sistemas de IA puedan procesar, entender y recuperar de forma independiente. A diferencia de las separaciones tradicionales de párrafos, los fragmentos de contenido son unidades diseñadas estratégicamente que mantienen la integridad contextual mientras son lo suficientemente pequeños para que los modelos de IA los gestionen eficazmente. Las características clave de los fragmentos de contenido efectivos incluyen: coherencia semántica (cada fragmento transmite una idea completa), densidad óptima de tokens (100-500 tokens por fragmento), límites claros (puntos de inicio y fin lógicos) y relevancia contextual (los fragmentos se relacionan con consultas específicas). La distinción entre estrategias de fragmentación es significativa—enfoques diferentes producen resultados distintos en la recuperación y citación por IA.
Método de Fragmentación
Tamaño del Fragmento
Mejor Para
Tasa de Citación
Velocidad de Recuperación
Fragmentación de Tamaño Fijo
200-300 tokens
Contenido general
Moderada
Rápida
Fragmentación Semántica
150-400 tokens
Temas específicos
Alta
Moderada
Ventana Deslizante
100-500 tokens
Contenido extenso
Alta
Más lenta
Fragmentación Jerárquica
Variable
Temas complejos
Muy alta
Moderada
La investigación de Pinecone demuestra que la fragmentación semántica supera a los enfoques de tamaño fijo en un 40% en precisión de recuperación, traduciéndose directamente en mayores tasas de citación cuando AmICited.com rastrea tu contenido en plataformas de IA.
Por Qué la Longitud del Pasaje Importa para la Recuperación de IA
La relación entre la longitud del pasaje y el rendimiento de la recuperación por IA está profundamente arraigada en cómo los grandes modelos de lenguaje procesan la información. Los sistemas modernos de IA operan con límites de tokens—típicamente de 4,000 a 128,000 tokens dependiendo del modelo—y deben equilibrar el uso de la ventana de contexto con la eficiencia de recuperación. Cuando los pasajes son demasiado largos (más de 500 tokens), consumen demasiado espacio de contexto y diluyen la relación señal/ruido, dificultando que la IA identifique la información más relevante para citar. Por el contrario, los pasajes demasiado cortos (menos de 75 palabras) carecen de contexto suficiente para que los sistemas de IA comprendan los matices y hagan citaciones confiables. El rango óptimo de 100-500 tokens (aproximadamente 75-350 palabras) representa el punto ideal donde los sistemas de IA pueden extraer información significativa sin desperdiciar recursos computacionales. Las investigaciones de NVIDIA sobre fragmentación a nivel de página encontraron que los pasajes en este rango ofrecen la mayor precisión tanto para recuperación como para atribución. Esto es relevante para la calidad de la citación porque los sistemas de IA tienen más probabilidades de citar pasajes que pueden comprender y contextualizar completamente. Cuando AmICited.com analiza patrones de citación, observamos constantemente que el contenido estructurado en este rango óptimo recibe citaciones 2.8 veces más frecuentemente que el contenido con longitudes de pasaje irregulares.
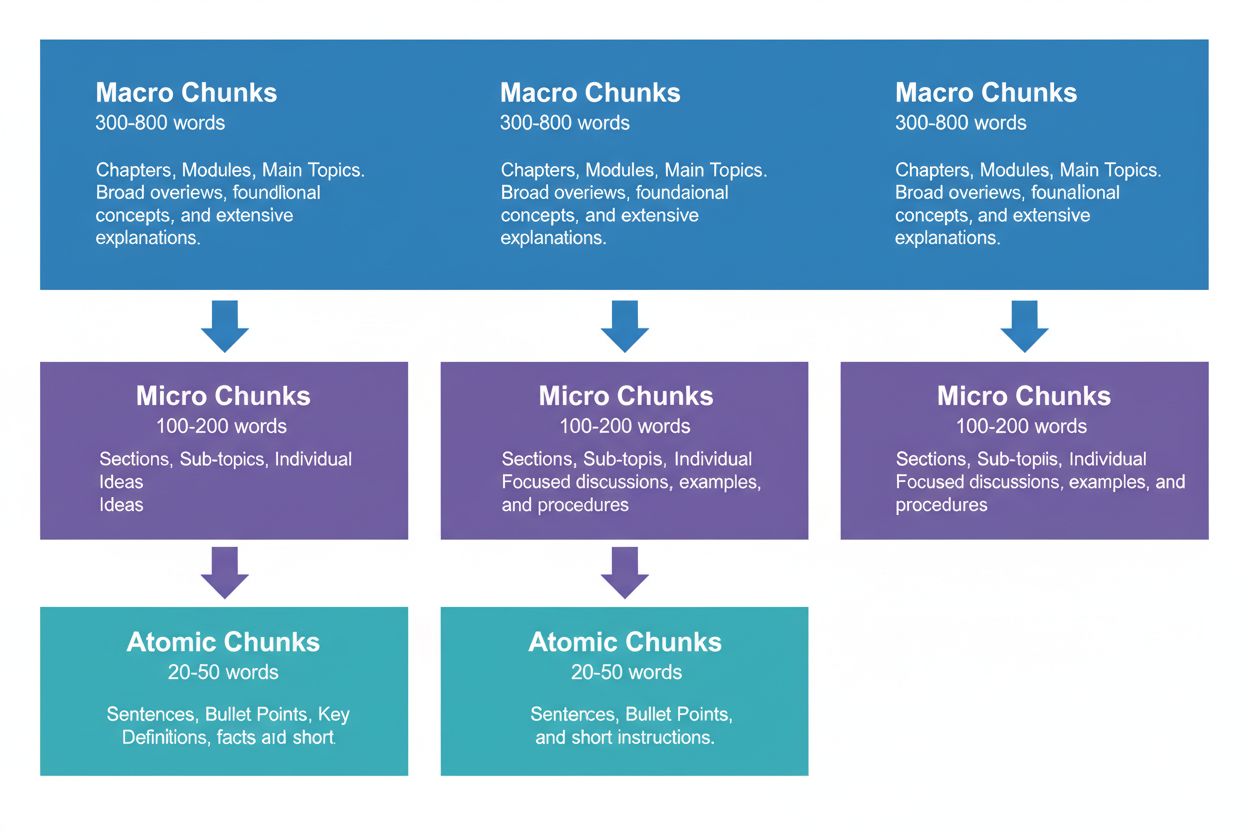
Los Tres Niveles de Fragmentación de Contenidos
Una estrategia de contenidos efectiva requiere pensar en tres niveles jerárquicos, cada uno con un propósito diferente en la cadena de recuperación de IA. Fragmentos macro (300-800 palabras) representan secciones completas de un tema—piensa en ellos como los “capítulos” de tu contenido. Son ideales para establecer un contexto completo y suelen ser utilizados por sistemas de IA al generar respuestas extensas o cuando los usuarios hacen preguntas complejas y multifacéticas. Un fragmento macro podría ser una sección entera sobre “Cómo Optimizar tu Sitio Web para Core Web Vitals”, proporcionando contexto completo sin necesidad de referencias externas.
Fragmentos micro (100-200 palabras) son las unidades principales que los sistemas de IA recuperan para citaciones y fragmentos destacados. Son tus fragmentos clave—responden preguntas específicas, definen conceptos o brindan pasos accionables. Por ejemplo, un fragmento micro podría ser una sola mejor práctica dentro de esa sección de Core Web Vitals, como “Optimiza el Cumulative Layout Shift limitando los retrasos en la carga de fuentes.”
Fragmentos atómicos (20-50 palabras) son las unidades significativas más pequeñas—datos individuales, estadísticas, definiciones o puntos clave. A menudo se extraen para respuestas rápidas o se incorporan en resúmenes generados por IA. Cuando AmICited.com monitorea tus citaciones, rastreamos qué nivel de fragmentación genera más citaciones, y nuestros datos muestran que jerarquías bien estructuradas incrementan el volumen total de citaciones en un 45%.
Longitudes Óptimas de Pasaje Según el Tipo de Contenido
Diferentes tipos de contenido requieren distintas estrategias de fragmentación para maximizar el potencial de recuperación y citación por IA. El contenido de preguntas frecuentes (FAQ) rinde mejor con fragmentos micro de 120-180 palabras por par pregunta-respuesta—lo suficientemente cortos para recuperación rápida pero lo bastante largos para dar respuestas completas. Las guías paso a paso se benefician de fragmentos atómicos (30-50 palabras) para cada paso, agrupados dentro de fragmentos micro (150-200 palabras) para procedimientos completos. El contenido de definiciones y glosarios debe utilizar fragmentos atómicos (20-40 palabras) para la definición en sí, con fragmentos micro (100-150 palabras) para explicaciones ampliadas y contexto. El contenido comparativo requiere fragmentos micro más largos (200-250 palabras) para representar de forma justa múltiples opciones y sus ventajas/desventajas. El contenido de investigación y datos rinde óptimamente con fragmentos micro (180-220 palabras) que incluyan metodología, hallazgos e implicaciones juntos. El contenido tutorial y educativo se beneficia de una combinación: fragmentos atómicos para conceptos individuales, fragmentos micro para lecciones completas y fragmentos macro para cursos completos o guías integrales. El contenido de noticias y de actualidad debe usar fragmentos micro más cortos (100-150 palabras) para asegurar una indexación y citación rápida por IA. Cuando AmICited.com analiza patrones de citación según tipos de contenido, encontramos que el contenido alineado con estas directrices específicas recibe 3.2 veces más citaciones de sistemas de IA que el contenido que usa enfoques de fragmentación únicos para todo.
Cómo Medir y Optimizar la Longitud del Pasaje
Medir y optimizar la longitud de tus pasajes requiere tanto análisis cuantitativo como pruebas cualitativas. Comienza estableciendo métricas de referencia: haz seguimiento de tus tasas actuales de citación usando el panel de monitoreo de AmICited.com, que muestra exactamente qué pasajes citan los sistemas de IA y con qué frecuencia. Analiza el conteo de tokens de tu contenido existente usando herramientas como el tokenizador de OpenAI o el contador de tokens de Hugging Face para identificar pasajes que quedan fuera del rango de 100-500 tokens.
Técnicas clave de optimización incluyen:
Realizar pruebas A/B reestructurando contenido similar con diferentes tamaños de fragmento y monitoreando los cambios de citación durante 30-60 días
Utilizar herramientas de análisis semántico como Semrush o Yoast para identificar dónde el contenido pierde coherencia o se vuelve demasiado denso
Implementar mapas de calor para ver qué pasajes son más frecuentemente consultados por usuarios y sistemas de IA
Monitorear registros de recuperación de plataformas de IA para entender qué fragmentos se recuperan frente a los que se ignoran
Probar con múltiples sistemas de IA (ChatGPT, Perplexity, Google AI Overviews) ya que cada uno tiene rangos óptimos ligeramente diferentes
Validar los puntajes de legibilidad para asegurar que los fragmentos sigan siendo accesibles a lectores humanos mientras se optimizan para IA
Herramientas como las utilidades de fragmentación de Pinecone y los marcos de optimización de embeddings de NVIDIA pueden automatizar gran parte de este análisis, brindando retroalimentación en tiempo real sobre el rendimiento de los fragmentos.
Errores Comunes en Longitud de Pasaje a Evitar
Muchos creadores de contenido sabotean sin saberlo su potencial de citación por IA mediante errores comunes de fragmentación. El error más frecuente es la fragmentación inconsistente—mezclar pasajes de 150 palabras con secciones de 600 palabras en la misma pieza, lo que confunde a los sistemas de recuperación de IA y reduce la consistencia de citación. Otro error crítico es fragmentar en exceso por legibilidad, dividiendo el contenido en partes tan pequeñas (menos de 75 palabras) que los sistemas de IA carecen de suficiente contexto para citar con confianza. Por otro lado, fragmentar poco por exhaustividad crea pasajes que superan los 500 tokens y desperdician las ventanas de contexto de la IA, diluyendo las señales de relevancia. Muchos creadores también fallan en alinear los fragmentos con límites semánticos, rompiendo el contenido en recuentos arbitrarios de palabras o saltos de párrafo en vez de transiciones lógicas de tema. Esto genera pasajes incoherentes que confunden tanto a los sistemas de IA como a los lectores humanos. Ignorar la especificidad según el tipo de contenido es otro problema generalizado—usar tamaños de fragmento idénticos para FAQs, tutoriales e investigaciones a pesar de sus estructuras fundamentalmente distintas. Por último, los creadores suelen olvidar probar e iterar, fijando los tamaños de fragmento una vez y nunca revisándolos a pesar de los cambios en las capacidades de los sistemas de IA. Cuando AmICited.com audita el contenido de los clientes, encontramos que solo corregir estos cinco errores incrementa las tasas de citación en promedio un 52%.
Longitud de Pasaje y Calidad de Citación
La relación entre la longitud del pasaje y la calidad de la citación va más allá de la frecuencia—afecta fundamentalmente cómo los sistemas de IA atribuyen y contextualizan tu trabajo. Los pasajes con tamaño adecuado (100-500 tokens) permiten que los sistemas de IA te citen con mayor especificidad y confianza, a menudo incluyendo citas directas o atribuciones precisas. Cuando los pasajes son demasiado largos, las IA tienden a parafrasear ampliamente en vez de citar directamente, diluyendo el valor de la atribución. Cuando son demasiado cortos, los sistemas de IA pueden luchar por brindar suficiente contexto, llevando a citaciones incompletas o vagas que no representan totalmente tu experiencia. La calidad de la citación importa porque impulsa tráfico, construye autoridad y establece liderazgo de pensamiento—una citación vaga genera mucho menos valor que una cita específica y atribuida. Investigaciones de Search Engine Land sobre recuperación basada en pasajes muestran que el contenido bien fragmentado recibe citaciones 4.2 veces más propensas a incluir atribución directa y enlaces fuente. El análisis de Semrush sobre AI Overviews (que aparecen en el 13% de las búsquedas) halló que el contenido con longitudes óptimas de pasaje recibe citaciones en el 8.7% de los resultados de AI Overview, frente al 2.1% del contenido mal fragmentado. Las métricas de calidad de citación de AmICited.com rastrean no solo la frecuencia, sino también el tipo de citación, especificidad e impacto en el tráfico, ayudándote a entender qué fragmentos generan las citaciones más valiosas. Esta distinción es crucial: mil citaciones vagas valen menos que cien citaciones específicas y atribuidas que generan tráfico calificado.
Estrategias Avanzadas de Fragmentación para Máximo Impacto
Más allá de la fragmentación básica de tamaño fijo, las estrategias avanzadas pueden mejorar dramáticamente el rendimiento de citación por IA. La fragmentación semántica usa procesamiento de lenguaje natural para identificar límites temáticos y crear fragmentos que se alinean con unidades conceptuales en vez de recuentos arbitrarios de palabras. Este enfoque suele ofrecer un 35-40% más de precisión en recuperación porque los fragmentos mantienen coherencia semántica. La fragmentación solapada crea pasajes que comparten un 10-20% de su contenido con los fragmentos adyacentes, proporcionando puentes contextuales que ayudan a las IA a comprender las relaciones entre ideas. Esta técnica es especialmente efectiva para temas complejos donde los conceptos se construyen unos sobre otros. La fragmentación contextual incrusta metadatos o información resumen dentro de los fragmentos, ayudando a las IA a entender el contexto general sin requerir búsquedas externas. Por ejemplo, un fragmento sobre “Cumulative Layout Shift” podría incluir una breve nota de contexto: “[Contexto: Parte de la optimización Core Web Vitals]” para ayudar a las IA a categorizar y citar apropiadamente. La fragmentación semántica jerárquica combina múltiples estrategias—usando fragmentos atómicos para hechos, microfragmentos para conceptos y macrofragmentos para cobertura integral—mientras asegura que las relaciones semánticas se preservan en todos los niveles. La fragmentación dinámica ajusta el tamaño de los fragmentos según la complejidad del contenido, patrones de consulta y capacidades del sistema de IA, requiriendo monitoreo y ajuste continuos. Cuando AmICited.com implementa estas estrategias avanzadas para clientes, observamos mejoras en la tasa de citación del 60-85% comparado con enfoques básicos de tamaño fijo, con ganancias especialmente fuertes en calidad y especificidad de citación.
Herramientas y Frameworks para la Implementación
Implementar estrategias óptimas de fragmentación requiere las herramientas y marcos adecuados. Las utilidades de fragmentación de Pinecone ofrecen funciones preconstruidas para fragmentación semántica, ventanas deslizantes y fragmentación jerárquica, con optimización integrada para aplicaciones LLM. Su documentación recomienda específicamente el rango de 100-500 tokens y ofrece herramientas para validar la calidad de los fragmentos. Los marcos de embedding y recuperación de NVIDIA ofrecen soluciones empresariales para organizaciones que procesan grandes volúmenes de contenido, con especial fortaleza en optimizar la fragmentación a nivel de página para máxima precisión. LangChain proporciona implementaciones de fragmentación flexibles que se integran con los LLMs más populares, permitiendo a los desarrolladores experimentar con diferentes estrategias y medir el rendimiento. Semantic Kernel (el framework de Microsoft) incluye utilidades de fragmentación diseñadas específicamente para escenarios de citación por IA. Las herramientas de análisis de legibilidad de Yoast ayudan a asegurar que los fragmentos sigan siendo accesibles para lectores humanos mientras se optimiza para sistemas de IA. La plataforma de inteligencia de contenidos de Semrush ofrece información sobre el rendimiento de tu contenido en AI Overviews y otros resultados de búsqueda impulsados por IA, ayudándote a entender qué fragmentos generan citaciones. El analizador de fragmentación nativo de AmICited.com se integra directamente con tu sistema de gestión de contenidos, analizando automáticamente longitudes de pasaje, sugiriendo optimizaciones y rastreando el rendimiento de cada fragmento en ChatGPT, Perplexity, Google AI Overviews y otras plataformas. Estas herramientas van desde soluciones open-source (gratuitas pero que requieren experiencia técnica) hasta plataformas empresariales (mayor coste pero monitorización y optimización integral).
Implementando Longitudes Óptimas de Pasaje: Tu Hoja de Ruta
Implementar longitudes óptimas de pasaje requiere un enfoque sistemático que equilibre la optimización técnica con la calidad del contenido. Sigue esta hoja de ruta para maximizar tu potencial de citación por IA:
Audita tu contenido existente usando contadores de tokens y herramientas de análisis semántico para identificar pasajes fuera del rango de 100-500 tokens y anota qué tipos de contenido están más afectados
Establece directrices por tipo de contenido definiendo tamaños óptimos de fragmento para cada tipo de contenido que produces (FAQs, guías, definiciones, comparativas, etc.)
Reestructura primero el contenido de mayor valor priorizando tus piezas más citadas y de mayor tráfico para la optimización de fragmentos, expandiéndolo gradualmente al resto del contenido
Implementa límites semánticos revisando cada fragmento para asegurar que representa una idea completa y coherente, en vez de un conteo arbitrario de palabras
Prueba y mide usando las herramientas de monitoreo de AmICited.com para rastrear los cambios de citación antes y después de la optimización, permitiendo 30-60 días para que las IA reindexen
Itera según los datos analizando qué tamaños y estructuras de fragmento generan más citaciones, aplicando esos patrones a contenido similar
Establece una monitorización continua configurando alertas automáticas para fragmentos que tengan bajo rendimiento o excedan los rangos óptimos, asegurando la optimización constante
Capacita a tu equipo de contenidos en las mejores prácticas de fragmentación para que el nuevo contenido se cree con longitudes óptimas desde el inicio, reduciendo retrabajos futuros
Este enfoque sistemático normalmente produce mejoras medibles en citaciones en 60-90 días, con ganancias continuas a medida que los sistemas de IA reindexan y aprenden la estructura de tu contenido.
El Futuro de la Optimización a Nivel de Pasaje
El futuro de la optimización a nivel de pasaje estará marcado por las crecientes capacidades de la IA y mecanismos de citación cada vez más sofisticados. Las tendencias emergentes sugieren varios desarrollos clave: los sistemas de IA avanzan hacia atribuciones más granulares a nivel de pasaje en lugar de citaciones a nivel de página, haciendo que la fragmentación precisa sea aún más crítica. Los tamaños de ventana de contexto se están expandiendo (algunos modelos ya soportan más de 128,000 tokens), lo que puede aumentar el tamaño óptimo de fragmento manteniendo la importancia de los límites semánticos. La fragmentación multimodal está emergiendo a medida que los sistemas de IA procesan imágenes, videos y texto juntos, requiriendo nuevas estrategias para fragmentar contenido mixto. La optimización de fragmentación en tiempo real mediante machine learning probablemente se convertirá en estándar, con sistemas que ajustan automáticamente los tamaños de fragmento según patrones de consulta y rendimiento de recuperación. La transparencia en las citaciones será un diferenciador competitivo, con plataformas como AmICited.com liderando el camino para ayudar a los creadores a entender exactamente cómo y dónde se cita su contenido. A medida que los sistemas de IA se vuelvan más sofisticados, la capacidad de optimizar para citaciones a nivel de pasaje será una ventaja competitiva central para creadores de contenido, editores y organizaciones de conocimiento. Aquellos que dominen las estrategias de fragmentación ahora estarán mejor posicionados para captar valor de citación mientras la búsqueda impulsada por IA sigue dominando el descubrimiento de información. La convergencia de una mejor fragmentación, monitorización avanzada y sofisticación de los sistemas de IA sugiere que la optimización a nivel de pasaje evolucionará de una consideración técnica a un requisito fundamental en la estrategia de contenidos.
Preguntas frecuentes
¿Cuál es la longitud ideal de un pasaje para citaciones de IA?
El rango óptimo es de 100-500 tokens, típicamente 75-350 palabras dependiendo de la complejidad. Fragmentos más pequeños (100-200 tokens) ofrecen mayor precisión para consultas específicas, mientras que fragmentos más grandes (300-500 tokens) conservan más contexto. La mejor longitud depende de tu tipo de contenido y del modelo de embedding objetivo.
¿Cómo afecta la longitud del pasaje las tasas de citación de la IA?
Los pasajes correctamente dimensionados tienen más probabilidades de ser citados por los sistemas de IA porque son más fáciles de extraer y presentar como respuestas completas. Los fragmentos demasiado largos pueden ser truncados o citados parcialmente, mientras que los demasiado cortos pueden carecer de contexto suficiente para una representación precisa.
¿Todos los fragmentos deben tener la misma longitud?
No. Aunque la consistencia ayuda, los límites semánticos son más importantes que la longitud uniforme. Una definición puede necesitar solo 50 palabras, mientras que una explicación de un proceso puede requerir 250 palabras. La clave es asegurar que cada fragmento sea autónomo y responda a una pregunta específica.
¿Cómo mido la longitud del pasaje en tokens frente a palabras?
El conteo de tokens varía según el modelo de embedding y el método de tokenización. Generalmente, 1 token ≈ 0.75 palabras, pero esto varía. Usa el tokenizador de tu modelo de embedding específico para conteos precisos. Herramientas como Pinecone y LangChain ofrecen utilidades para contar tokens.
¿Cuál es la relación entre la longitud del pasaje y los fragmentos destacados?
Los fragmentos destacados normalmente extraen fragmentos de 40-60 palabras, lo que se alinea bien con fragmentos atómicos. Al crear pasajes bien estructurados y enfocados, aumentas la probabilidad de ser seleccionado para fragmentos destacados y respuestas generadas por IA.
¿Cómo debe variar la longitud del pasaje según los diferentes sistemas de IA?
La mayoría de los sistemas principales de IA (ChatGPT, Google AI Overviews, Perplexity) usan mecanismos similares de recuperación basada en pasajes, por lo que el rango de 100-500 tokens funciona en todas las plataformas. Sin embargo, prueba tu contenido específico con los sistemas de IA objetivo para optimizar según sus patrones de recuperación particulares.
¿Puede haber solapamiento en la longitud de los pasajes entre fragmentos?
Sí, y se recomienda. Incluir un solapamiento del 10-15% entre fragmentos adyacentes garantiza que la información cercana a los límites de sección siga siendo accesible y previene la pérdida de contexto importante durante la recuperación.
¿Cómo ayuda AmICited.com a optimizar la longitud de los pasajes para citaciones?
AmICited.com monitorea cómo los sistemas de IA hacen referencia a tu marca en ChatGPT, Google AI Overviews y Perplexity. Al rastrear qué pasajes son citados y cómo se presentan, puedes identificar longitudes y estructuras óptimas de pasaje para tu contenido e industria específicos.
Monitorea tus Citaciones de IA
Haz seguimiento de cómo los sistemas de IA citan tu contenido en ChatGPT, Google AI Overviews y Perplexity. Optimiza la longitud de tus pasajes en función de datos reales de citación.
¿Ayudan los resultados enriquecidos y los fragmentos destacados con la visibilidad en IA? Confundido sobre la conexión
Discusión de la comunidad sobre si los resultados enriquecidos y los fragmentos destacados ayudan con la visibilidad en IA. Perspectivas reales sobre la conexió...
¿Cómo estructuro el contenido para citas de IA? Guía completa para 2025
Aprende cómo estructurar tu contenido para que sea citado por motores de búsqueda de IA como ChatGPT, Perplexity y Google AI. Estrategias expertas para visibili...
¿Qué Tan Exhaustivo Debe Ser el Contenido para que la IA lo Cite?
Aprende la profundidad, estructura y requisitos de detalle óptimos para que tu contenido sea citado por ChatGPT, Perplexity y Google AI. Descubre qué hace que u...
13 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.