
Dirigiendo Sitios Fuente de LLM para Backlinks
Aprende cómo identificar y dirigir sitios fuente de LLM para backlinks estratégicos. Descubre qué plataformas de IA citan más fuentes y optimiza tu estrategia d...
12 min de lectura

Descubre cómo los Modelos de Lenguaje Grande seleccionan y citan fuentes mediante la ponderación de evidencia, el reconocimiento de entidades y los datos estructurados. Conoce el proceso de decisión de citación en 7 fases y optimiza tu contenido para la visibilidad en IA.
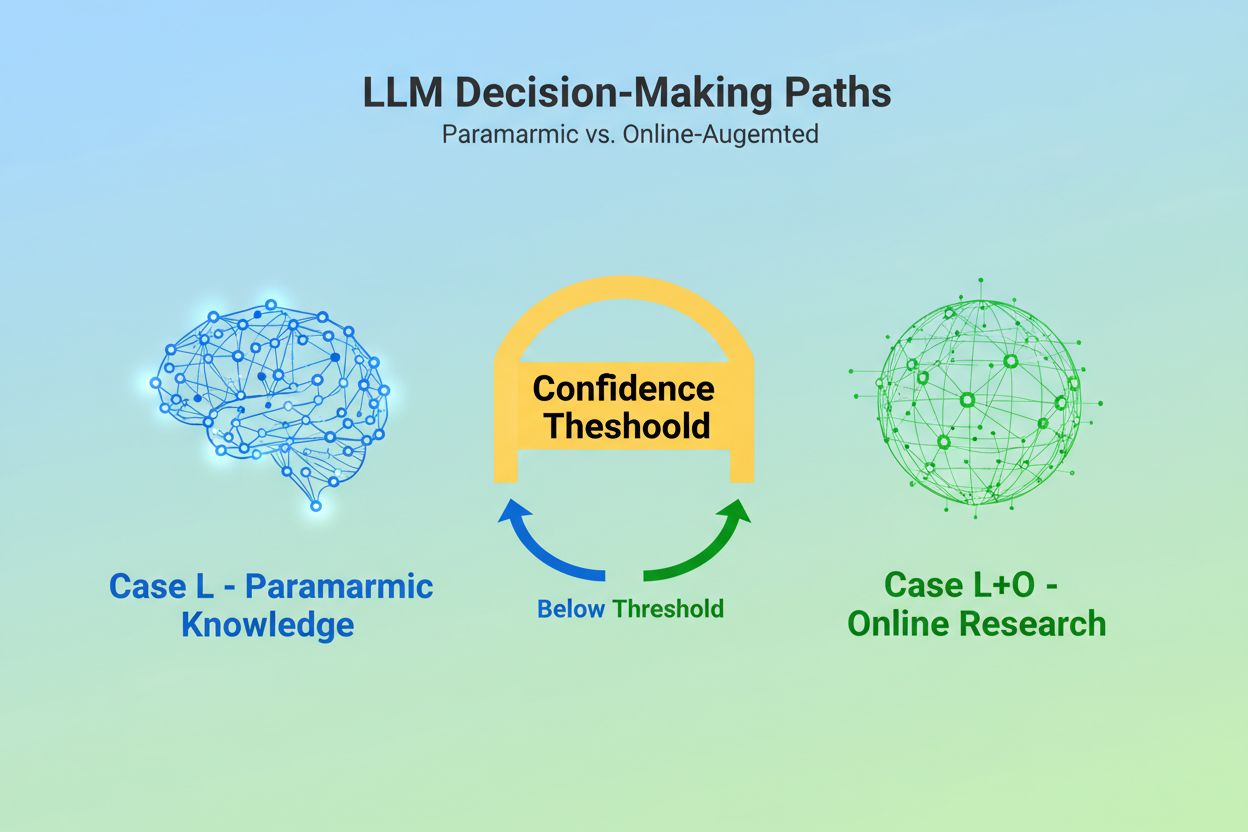
Cuando un Modelo de Lenguaje Grande recibe una consulta, enfrenta una decisión fundamental: ¿debe confiar únicamente en el conocimiento incrustado durante el entrenamiento, o debe buscar información actual en la web? Esta elección binaria—lo que los investigadores llaman Caso L (solo datos de aprendizaje) versus Caso L+O (datos de aprendizaje más investigación en línea)—determina si un LLM citará fuentes o no. En el modo Caso L, el modelo se basa exclusivamente en su base de conocimiento paramétrica, una representación condensada de patrones aprendidos durante el entrenamiento que normalmente refleja información de varios meses hasta más de un año antes del lanzamiento del modelo. En el modo Caso L+O, el modelo activa un umbral de confianza que dispara la investigación externa, abriendo lo que los investigadores llaman el “espacio candidato” de URLs y fuentes. Este punto de decisión es invisible para la mayoría de las herramientas de monitoreo, pero es donde comienza todo el mecanismo de citación—ya que sin activar la fase de búsqueda, no pueden evaluarse ni citarse fuentes externas.
En el momento en que un LLM decide buscar fuentes externas, entra en la fase más crítica para la selección de citaciones: la ponderación de evidencia. Aquí es donde se decide la diferencia entre una simple mención y una recomendación autoritativa. El modelo no simplemente cuenta cuántas veces aparece una fuente o qué tan alto aparece en los resultados de búsqueda; evalúa la integridad estructural de la propia evidencia. Examina la arquitectura del documento—si las fuentes contienen relaciones de datos claras, identificadores recurrentes y enlaces referenciados—interpretando estos elementos como signos de confiabilidad. El modelo construye lo que los investigadores llaman un “grafo de evidencia”, donde los nodos representan entidades y las aristas representan relaciones entre documentos. Cada fuente se pondera no solo por la relevancia del contenido sino también por la consistencia con la que los hechos son confirmados en múltiples documentos, la relevancia temática de la información y la autoridad aparente del dominio. Esta evaluación multidimensional crea lo que se conoce como matriz de evidencia, una valoración integral que determina qué fuentes son lo suficientemente confiables como para ser citadas. De forma crítica, esta fase opera en la capa de razonamiento del LLM, haciéndola invisible para las herramientas tradicionales de monitoreo SEO que solo miden señales de recuperación.
Los datos estructurados—especialmente JSON-LD, el marcado Schema.org y RDFa—actúan como un multiplicador en el proceso de ponderación de evidencia. Las fuentes que implementan datos estructurados correctamente reciben un peso de 2 a 3 veces mayor en la matriz de evidencia en comparación con contenido no estructurado. Esto no es porque los LLM prefieran datos formateados estéticamente; es porque los datos estructurados permiten el enlace de entidades, el proceso de conectar menciones entre documentos mediante identificadores legibles por máquina como @id, sameAs y Q-IDs (identificadores de Wikidata). Cuando un LLM encuentra una fuente con un Q-ID para una organización, puede verificar esa entidad de inmediato en múltiples documentos, creando lo que los investigadores llaman “correferencia de entidad entre documentos”. Este proceso de verificación incrementa drásticamente la confianza en la fiabilidad de la fuente.
| Formato de datos | Precisión de citación | Enlace de entidades | Verificación entre documentos |
|---|---|---|---|
| Texto no estructurado | 62% | Ninguno | Inferencia manual |
| Marcado HTML básico | 71% | Limitado | Coincidencia parcial |
| RDFa/Microdatos | 81% | Bueno | Basado en patrones |
| JSON-LD con Q-IDs | 94% | Excelente | Enlaces verificados |
| Formato de grafo de conocimiento | 97% | Perfecto | Verificación automática |
El impacto de los datos estructurados opera en dos ejes temporales. Transitoriamente, cuando un LLM busca en línea, lee JSON-LD y el marcado Schema.org en tiempo real, incorporando de inmediato esta información estructurada en la ponderación de evidencia para la respuesta actual. De manera persistente, los datos estructurados que se mantienen consistentes con el tiempo se integran en la base de conocimiento paramétrica del modelo en futuros ciclos de entrenamiento, moldeando cómo el modelo reconoce y evalúa entidades incluso sin investigación en línea. Este doble mecanismo implica que las marcas que implementan datos estructurados adecuados aseguran tanto visibilidad inmediata en citaciones como autoridad a largo plazo en el espacio de conocimiento interno del modelo.
Antes de que un LLM pueda citar una fuente, primero debe entender de qué trata esa fuente y a quién representa. Este es el trabajo del reconocimiento de entidades, un proceso que transforma el lenguaje humano impreciso en entidades legibles por máquinas. Cuando un documento menciona “Apple”, el LLM debe determinar si se refiere a Apple Inc., la fruta u otra cosa completamente distinta. El modelo logra esto mediante patrones de entidades entrenados a partir de Wikipedia, Wikidata y Common Crawl, junto con análisis contextual del texto circundante. En modo Caso L+O, este proceso se vuelve más sofisticado: el modelo verifica entidades contra datos estructurados externos, buscando atributos @id, enlaces sameAs y Q-IDs que brindan identificación definitiva. Este paso de verificación es crucial porque referencias ambiguas o inconsistentes de entidades se pierden en el ruido del proceso de razonamiento del modelo. Una marca que utiliza convenciones de nombre inconsistentes, no establece identificadores de entidad claros o no implementa el marcado Schema.org se vuelve semánticamente confusa para la máquina—apareciendo como múltiples entidades diferentes en lugar de una sola fuente coherente. Por el contrario, organizaciones con entidades estables y referenciadas consistentemente en múltiples documentos son reconocidas como nodos confiables en el grafo de conocimiento del LLM, incrementando significativamente su probabilidad de citación.
El trayecto desde la consulta hasta la citación sigue un proceso estructurado de siete fases que los investigadores han mapeado mediante el análisis del comportamiento de los LLM. Fase 0: Análisis de intención comienza cuando el modelo tokeniza la entrada del usuario, realiza análisis semántico y crea un vector de intención—una representación abstracta de lo que realmente está pidiendo el usuario. Esta fase determina qué temas, entidades y relaciones son siquiera relevantes a considerar. Fase 1: Recuperación de conocimiento interno accede al conocimiento paramétrico del modelo y calcula un puntaje de confianza. Si este puntaje supera un umbral, el modelo permanece en modo Caso L; si no, procede a la investigación externa. Fase 2: Generación de consultas expansivas (solo en Caso L+O) crea múltiples consultas de búsqueda semánticamente variadas—normalmente de 1 a 6 tokens cada una—diseñadas para abrir al máximo el espacio candidato. Fase 3: Extracción de evidencia recupera URLs y fragmentos de los resultados de búsqueda, analiza HTML y extrae JSON-LD, RDFa y microdatos. Aquí es donde los datos estructurados se vuelven visibles para el mecanismo de citación. Fase 4: Enlace de entidades identifica entidades en los documentos recuperados y las verifica contra identificadores externos, creando un grafo de conocimiento temporal de relaciones. Fase 5: Ponderación de evidencia evalúa la fuerza de la evidencia de todas las fuentes, considerando la arquitectura del documento, la diversidad de fuentes, la frecuencia de confirmación y la coherencia entre fuentes. Fase 6: Razonamiento y síntesis combina evidencia interna y externa, resuelve contradicciones y determina si cada fuente merece una mención o una recomendación. Fase 7: Construcción de la respuesta final traduce la evidencia ponderada a lenguaje natural, integrando citaciones donde corresponda. Cada fase alimenta la siguiente, con bucles de retroalimentación que permiten al modelo refinar su búsqueda o reevaluar evidencia si surgen inconsistencias.
Los LLM modernos emplean cada vez más la Generación Aumentada por Recuperación (RAG), una técnica que cambia fundamentalmente cómo se seleccionan y justifican las citaciones. En lugar de depender únicamente del conocimiento paramétrico, los sistemas RAG recuperan activamente documentos relevantes, extraen evidencia y fundamentan las respuestas en fuentes específicas. Este enfoque transforma la citación de un subproducto implícito del entrenamiento a un proceso explícito y rastreable. Las implementaciones RAG suelen utilizar búsqueda híbrida, combinando recuperación basada en palabras clave con búsqueda por similitud vectorial para maximizar el alcance. Una vez recuperados los documentos candidatos, el ranking semántico reordena los resultados en función del significado y no solo de la coincidencia de palabras clave, asegurando que las fuentes más relevantes lleguen a la cima. Este mecanismo explícito de recuperación hace que el proceso de citación sea más transparente y auditable—cada fuente citada puede rastrearse hasta los pasajes específicos que justificaron su inclusión. Para las organizaciones que monitorean su visibilidad en IA, los sistemas basados en RAG son especialmente importantes porque crean patrones de citación medibles. Herramientas como AmICited rastrean cómo los sistemas RAG hacen referencia a tu marca entre distintas plataformas de IA, proporcionando información sobre si apareces como fuente citada o solo como material de contexto en la fase de recuperación de evidencia.
No todas las citaciones son iguales. Un LLM puede mencionar una fuente como contexto de fondo mientras recomienda otra como evidencia autoritativa—y esta distinción depende enteramente de la ponderación de evidencia, no del éxito en la recuperación. Una fuente puede aparecer en el espacio candidato (Fases 2-3) pero no alcanzar el estatus de recomendación si su puntaje de evidencia es insuficiente. Esta separación entre mención y recomendación es donde las métricas GEO tradicionales fallan. Las herramientas estándar de monitoreo miden la expansión—si tu contenido aparece en los resultados de búsqueda—pero no pueden medir si el LLM realmente considera tu contenido lo suficientemente confiable como para recomendarlo. Una mención puede leerse como “Algunas fuentes sugieren…” mientras que una recomendación sería “Según [Fuente], la evidencia muestra…”. La diferencia radica en el puntaje de la matriz de evidencia de la Fase 5. Las fuentes con Q-IDs consistentes, arquitectura documental bien estructurada y confirmación en múltiples fuentes independientes logran el estatus de recomendación. Las fuentes con referencias ambiguas de entidades, pobre coherencia estructural o afirmaciones aisladas permanecen como menciones. Para las marcas, esta distinción es crítica: ser recuperado no es lo mismo que ser citado como autoridad. El camino de la recuperación a la recomendación requiere claridad semántica, integridad estructural y densidad de evidencia—factores que la optimización SEO tradicional no aborda.
Comprender cómo los LLM seleccionan fuentes tiene implicaciones inmediatas y accionables para la estrategia de contenido. Primero, implementa el marcado Schema.org de manera consistente en tu sitio web, especialmente para información organizacional, artículos y entidades clave. Usa el formato JSON-LD con atributos @id adecuados y enlaces sameAs a Wikidata, Wikipedia u otras fuentes autorizadas. Estos datos estructurados incrementan directamente tu peso de evidencia en la Fase 5. Segundo, establece identificadores de entidad claros para tu organización, productos y conceptos clave. Usa convenciones de nombre consistentes, evita abreviaturas que generen ambigüedad y enlaza entidades relacionadas mediante relaciones jerárquicas (isPartOf, about, mentions). Tercero, crea evidencia legible por máquina publicando datos estructurados sobre tus afirmaciones, credenciales y relaciones. No solo escribas “Somos el proveedor líder de X”—estructura esa afirmación con datos de soporte, citaciones y relaciones verificables. Cuarto, mantén la consistencia de contenido en múltiples plataformas y períodos de tiempo. Los LLM evalúan la densidad de evidencia revisando si las afirmaciones se confirman en fuentes independientes; afirmaciones aisladas en una sola plataforma tienen menos peso. Quinto, entiende que las métricas SEO tradicionales no predicen la citación en IA. Un alto ranking en búsquedas no garantiza recomendaciones de LLM; en cambio, enfócate en la claridad semántica y la integridad estructural. Sexto, monitorea tus patrones de citación con herramientas como AmICited, que rastrean cómo distintos sistemas de IA hacen referencia a tu marca. Esto revela si logras el estatus de mención o recomendación y qué tipos de contenido disparan citaciones. Finalmente, reconoce que la visibilidad en IA es una inversión a largo plazo. Los datos estructurados que implementes hoy influyen tanto en la probabilidad inmediata de citación (efecto transitorio) como en la base de conocimiento interna del modelo en futuros ciclos de entrenamiento (efecto persistente).
A medida que evolucionan los LLM, los mecanismos de citación se vuelven cada vez más sofisticados y transparentes. Los modelos futuros probablemente implementarán grafos de citación—mapas explícitos que muestran no solo qué fuentes fueron citadas, sino cómo influyeron en afirmaciones específicas de la respuesta. Algunos sistemas avanzados ya experimentan con puntajes probabilísticos de confianza adjuntos a las citaciones, indicando cuán seguro está el modelo sobre la relevancia y confiabilidad de la fuente. Otra tendencia emergente es la verificación con intervención humana, donde los usuarios pueden cuestionar citaciones y aportar retroalimentación que refina la ponderación de evidencia del modelo para futuras consultas. La integración de datos estructurados en los ciclos de entrenamiento implica que las organizaciones que implementan infraestructura semántica adecuada hoy están construyendo, en esencia, su autoridad a largo plazo en los sistemas de IA. A diferencia de los rankings en buscadores, que pueden fluctuar por actualizaciones de algoritmos, el efecto persistente de los datos estructurados crea una base más estable para la visibilidad en IA. Este cambio de la visibilidad tradicional (ser encontrado) a la autoridad semántica (ser confiable) representa un cambio fundamental en cómo las marcas deben abordar la comunicación digital. Los ganadores en este nuevo panorama no serán quienes tengan más contenido o mejores rankings en búsquedas, sino quienes estructuren su información de forma que las máquinas puedan entender, verificar y recomendar de manera confiable.
El Caso L utiliza solo datos de entrenamiento de la base de conocimiento paramétrica del modelo, mientras que el Caso L+O lo complementa con investigación web en tiempo real. El umbral de confianza del modelo determina qué camino tomar. Esta distinción es crucial porque determina si se pueden evaluar y citar fuentes externas o no.
La ponderación de la evidencia determina esta distinción. Las fuentes con datos estructurados, identificadores consistentes y confirmación entre documentos se elevan a 'recomendaciones' en lugar de simples menciones. Una fuente puede aparecer en los resultados de búsqueda pero no lograr el estatus de recomendación si su puntaje de evidencia es insuficiente.
Los datos estructurados (JSON-LD, @id, sameAs, Q-IDs) reciben un peso 2-3 veces mayor en las matrices de evidencia. Este marcado permite el enlace de entidades y la verificación entre documentos, aumentando drásticamente el puntaje de confiabilidad de la fuente. Las fuentes con una implementación adecuada de Schema.org tienen una probabilidad significativamente mayor de ser citadas como autoritativas.
El reconocimiento de entidades es la forma en que los LLM identifican y distinguen entre diferentes entidades (organizaciones, personas, conceptos). Una identificación clara de la entidad mediante nombres consistentes e identificadores estructurados evita confusiones y aumenta la probabilidad de citación. Las referencias ambiguas de entidades se pierden en el proceso de razonamiento del modelo.
Los sistemas RAG recuperan y clasifican fuentes activamente en tiempo real, haciendo que la selección de citaciones sea más transparente y basada en evidencia que el puro conocimiento paramétrico. Este mecanismo explícito de recuperación crea patrones de citación medibles que pueden rastrearse y analizarse con herramientas de monitoreo como AmICited.
Sí. Implementa el marcado de Schema.org de forma consistente, establece identificadores de entidad claros, crea evidencia legible por máquinas, mantén consistencia de contenido en todas las plataformas y monitorea tus patrones de citación. Estos factores influyen directamente en si tu contenido logra el estatus de mención o de recomendación en las respuestas de los LLM.
La visibilidad tradicional mide el alcance y el ranking en los resultados de búsqueda. La visibilidad en IA mide si tu contenido es reconocido como evidencia autorizada en los procesos de razonamiento de los LLM. Ser recuperado no es lo mismo que ser citado como confiable: esto último requiere claridad semántica e integridad estructural.
AmICited rastrea cómo los sistemas de IA hacen referencia a tu marca en GPTs, Perplexity y Google AI Overviews. Revela si estás logrando estatus de mención o recomendación, qué tipos de contenido disparan citaciones y cómo se comparan tus patrones de citación entre distintas plataformas de IA.
Comprende cómo los LLM hacen referencia a tu marca en ChatGPT, Perplexity y Google AI Overviews. Rastrea patrones de citación y optimiza tu visibilidad en IA con AmICited.
Aprende cómo identificar y dirigir sitios fuente de LLM para backlinks estratégicos. Descubre qué plataformas de IA citan más fuentes y optimiza tu estrategia d...

Descubre cómo el grounding en LLMs y la búsqueda web permiten a los sistemas de IA acceder a información en tiempo real, reducir alucinaciones y proporcionar ci...

Descubre qué es LLMO, cómo funciona y por qué es importante para la visibilidad en IA. Conoce técnicas de optimización para lograr que tu marca sea mencionada e...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.