
PerplexityBot
Descubre qué es PerplexityBot, el rastreador web de Perplexity que indexa contenido para su motor de respuestas de IA. Comprende cómo funciona, su cumplimiento ...
9 min de lectura

Guía completa sobre el rastreador PerplexityBot: entiende cómo funciona, gestiona el acceso, monitorea citas y optimiza para la visibilidad en Perplexity AI. Aprende sobre las preocupaciones de rastreo sigiloso y mejores prácticas.
PerplexityBot es el rastreador web oficial desarrollado por Perplexity AI, diseñado para indexar y mostrar sitios web en los resultados de búsqueda impulsados por IA de Perplexity. A diferencia de algunos rastreadores de IA que recopilan datos para entrenar grandes modelos de lenguaje, PerplexityBot cumple un propósito específico: descubrir, rastrear y enlazar sitios web que proporcionan respuestas relevantes a las consultas de los usuarios. El rastreador opera usando una cadena de agente de usuario claramente definida (Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)) y publica públicamente sus rangos de direcciones IP, permitiendo a los propietarios de sitios web identificar y gestionar el tráfico del rastreador. Comprender lo que hace PerplexityBot es esencial para los propietarios de sitios que desean controlar la visibilidad de su contenido en el motor de respuestas de Perplexity y mantener la transparencia sobre cómo se accede a sus sitios.

PerplexityBot opera como un rastreador web estándar, escaneando continuamente Internet para descubrir e indexar páginas web. Cuando encuentra un sitio, lee el archivo robots.txt para entender a qué contenido se le permite acceder y luego rastrea sistemáticamente las páginas para extraer e indexar su contenido. Esta información indexada alimenta el algoritmo de búsqueda de Perplexity, que la utiliza para proporcionar respuestas citadas a las consultas de los usuarios. Sin embargo, Perplexity en realidad opera dos rastreadores distintos con diferentes propósitos, cada uno con su propio agente de usuario y patrones de comportamiento. Comprender la diferencia entre estos rastreadores es crucial para los propietarios de sitios web que deseen afinar sus políticas de acceso.
| Característica | PerplexityBot | Perplexity-User |
|---|---|---|
| Propósito | Indexa sitios web para resultados de búsqueda y citas | Obtiene páginas específicas en tiempo real al responder consultas de usuarios |
| Cadena de agente de usuario | PerplexityBot/1.0 | Perplexity-User/1.0 |
| Cumplimiento de robots.txt | Respeta las directivas de disallow en robots.txt | Generalmente ignora robots.txt (solicitudes iniciadas por usuarios) |
| Rangos de IP | Publicados en perplexity.com/perplexitybot.json | Publicados en perplexity.com/perplexity-user.json |
| Frecuencia | Rastreo continuo y programado | Bajo demanda, activado por consultas de usuarios |
| Caso de uso | Construcción del índice de búsqueda | Recuperación de información actual para respuestas |
La distinción entre estos dos rastreadores es importante porque pueden gestionarse por separado mediante reglas en robots.txt y configuraciones de firewall. El rastreo regular de PerplexityBot respeta tus directivas en robots.txt, mientras que Perplexity-User puede ignorarlas ya que obtiene contenido en respuesta a una solicitud específica de usuario. Ambos rastreadores publican sus rangos de IP, lo que permite a los propietarios de sitios implementar reglas de firewall precisas si deciden bloquear o permitir tráfico específico de rastreadores.
En 2025, Cloudflare publicó una investigación detallada que revelaba que Perplexity estaba utilizando rastreadores no declarados para eludir las restricciones de los sitios web. Según sus hallazgos, cuando los rastreadores declarados de Perplexity (PerplexityBot y Perplexity-User) eran bloqueados mediante robots.txt o reglas de firewall, la empresa desplegaba rastreadores adicionales utilizando agentes de usuario genéricos de navegador (como Chrome en macOS) y direcciones IP rotativas de diferentes ASNs (Números de Sistemas Autónomos) para seguir accediendo a contenido restringido. Este comportamiento contradice directamente los estándares de rastreo web descritos en RFC 9309, que enfatizan la transparencia y el respeto a las preferencias de los propietarios de sitios web. La investigación probó esto creando dominios completamente nuevos con reglas explícitas de disallow en robots.txt, y aun así Perplexity proporcionó información detallada sobre su contenido, lo que sugiere el uso de fuentes de datos no declaradas o técnicas de rastreo sigiloso.
Esto contrasta fuertemente con la forma en que OpenAI gestiona sus rastreadores. GPTBot de OpenAI se identifica claramente, respeta las directivas de robots.txt y deja de rastrear cuando se le bloquea, demostrando que es posible y práctico un comportamiento transparente y ético por parte de los rastreadores. Los hallazgos de Cloudflare generaron preocupaciones importantes sobre si el compromiso declarado de Perplexity con el respeto a las preferencias de los propietarios de sitios es genuino, especialmente para quienes desean evitar que su contenido sea indexado o citado por sistemas de IA. Para los propietarios preocupados por el control del contenido y la transparencia, esta controversia destaca la importancia de monitorear el comportamiento de los rastreadores y usar múltiples capas de protección (robots.txt, reglas WAF y bloqueo de IP) para hacer cumplir sus preferencias.
Decidir si permitir o no a PerplexityBot en tu sitio web implica sopesar varios factores importantes. Por un lado, permitir el rastreador ofrece beneficios relevantes: tu contenido puede ser citado en las respuestas de Perplexity, lo que potencialmente genera tráfico de referencia de usuarios que ven tu sitio mencionado en respuestas generadas por IA. Por otro lado, existen preocupaciones legítimas sobre el consumo de ancho de banda, el scraping de contenido y la pérdida de control sobre cómo se utiliza tu información. La decisión depende en última instancia de tus objetivos de negocio, estrategia de contenidos y nivel de comodidad con los sistemas de IA accediendo a tus datos.
Consideraciones clave para permitir a PerplexityBot:
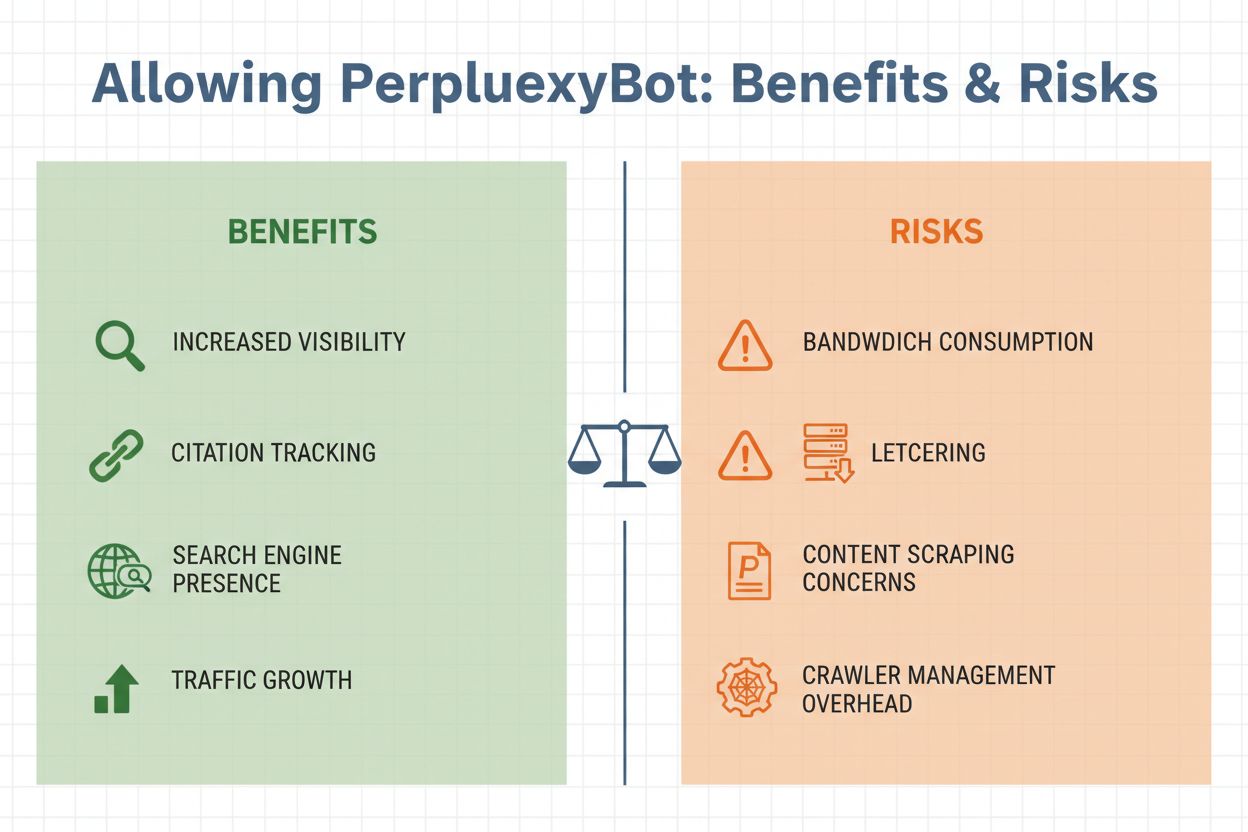
Gestionar el acceso de PerplexityBot es sencillo y puede lograrse mediante varios métodos, según tu infraestructura técnica y requisitos específicos. El método más común es usar el archivo robots.txt, que proporciona directivas claras a todos los rastreadores respetuosos sobre qué contenido pueden acceder.
Para permitir a PerplexityBot en tu archivo robots.txt:
User-agent: PerplexityBot
Allow: /
Para bloquear a PerplexityBot en tu archivo robots.txt:
User-agent: PerplexityBot
Disallow: /
Si deseas bloquear a PerplexityBot en directorios específicos y permitir el acceso a otros, puedes usar reglas más granulares:
User-agent: PerplexityBot
Disallow: /admin/
Disallow: /private/
Allow: /public/
Para una protección más robusta, especialmente si te preocupa el rastreo sigiloso, implementa reglas de firewall a nivel de Web Application Firewall (WAF). Los usuarios de Cloudflare WAF pueden crear reglas personalizadas para bloquear a PerplexityBot combinando coincidencias de agente de usuario y direcciones IP:
Los usuarios de AWS WAF deben crear conjuntos de IP usando los rangos publicados de PerplexityBot desde https://www.perplexity.com/perplexitybot.json, luego crear reglas que coincidan tanto con el conjunto de IP como con la cadena de agente de usuario PerplexityBot. Utiliza siempre los rangos oficiales publicados por Perplexity, ya que se actualizan regularmente y son la fuente autorizada para el tráfico legítimo del rastreador.
Una vez que has decidido tu política respecto a PerplexityBot, monitorear la actividad real del rastreador te ayuda a verificar que tus reglas funcionen correctamente y a entender el impacto en tu infraestructura. Puedes identificar las solicitudes de PerplexityBot en los registros de tu servidor buscando la distintiva cadena de agente de usuario: PerplexityBot/1.0 o el agente de usuario genérico de navegador si se produce rastreo sigiloso. La mayoría de las plataformas de análisis web y herramientas de análisis de registros permiten filtrar el tráfico por agente de usuario, lo que facilita aislar las solicitudes de PerplexityBot y analizar sus patrones.
Las métricas clave a monitorear incluyen la frecuencia de las visitas del rastreador, las páginas accedidas y el ancho de banda consumido. Si observas patrones inusuales—como rastreo rápido de páginas sensibles o solicitudes desde direcciones IP que no están en los rangos publicados por Perplexity—esto puede indicar actividad de rastreo sigiloso. Más allá del monitoreo básico de tráfico, el uso de herramientas especializadas como AmICited.com proporciona una visión más profunda sobre cómo tu contenido es citado realmente en plataformas de IA incluyendo Perplexity. AmICited rastrea menciones de tu marca y contenido en respuestas generadas por IA, permitiéndote medir el impacto real de permitir a PerplexityBot y entender cuáles de tus páginas son más valiosas para los sistemas de IA. Estos datos te ayudan a tomar decisiones informadas sobre futuras políticas de gestión de rastreadores y estrategias de optimización de contenido.
Gestionar PerplexityBot de manera efectiva requiere un enfoque equilibrado que proteja tus intereses y reconozca el valor de la visibilidad impulsada por IA. Primero, establece una política clara basada en tus objetivos de negocio: decide si el tráfico potencial y la exposición de marca que brinda Perplexity superan tus preocupaciones sobre el ancho de banda y el control del contenido. Documenta esta decisión en tu archivo robots.txt y comunícalo a tu equipo para que todos comprendan tu estrategia de gestión de rastreadores.
En segundo lugar, implementa protección en capas si decides bloquear a PerplexityBot. No te bases únicamente en robots.txt, ya que la controversia del rastreo sigiloso demuestra que algunos rastreadores pueden ignorar estas directivas. Combina reglas en robots.txt con reglas WAF y bloqueo de IP para una protección en profundidad. En tercer lugar, mantente informado sobre el comportamiento de los rastreadores monitoreando regularmente tus registros y siguiendo las discusiones del sector sobre la ética y transparencia de los rastreadores de IA. El panorama evoluciona rápidamente, y pueden surgir nuevos rastreadores o tácticas que requieran ajustes de política.
Finalmente, utiliza herramientas de monitoreo estratégicamente para medir el impacto real de tus decisiones. Herramientas como AmICited.com te dan visibilidad sobre cómo los sistemas de IA citan tu contenido, ayudándote a entender si permitir a PerplexityBot te está proporcionando los beneficios de visibilidad que esperabas. Si permites el rastreador, estos datos te ayudan a optimizar tu contenido para la citación por IA. Si lo bloqueas, el monitoreo confirma que tus bloqueos son efectivos y que tu contenido no aparece en los resultados de Perplexity por otros medios.
PerplexityBot opera en un panorama lleno de rastreadores de IA, cada uno con diferentes propósitos y estándares de transparencia. GPTBot, operado por OpenAI, es ampliamente reconocido como un modelo de comportamiento transparente de rastreador: se identifica claramente, respeta las directivas de robots.txt y deja de rastrear cuando se le bloquea. Los rastreadores de Google para AI Overviews y otras funciones de IA también mantienen la transparencia y respetan las preferencias de los sitios web. En contraste, el comportamiento de rastreo sigiloso de Perplexity, documentado por Cloudflare, representa una desviación preocupante de estos estándares.
La diferencia clave radica en la transparencia y el respeto por las preferencias de los propietarios de sitios web. Rastreadores bien comportados como GPTBot facilitan a los propietarios entender lo que hacen y ofrecen mecanismos claros de control. El uso por parte de Perplexity de rastreadores no declarados y rotación de IPs para eludir restricciones mina esta confianza. Para los propietarios de sitios web, esto significa que deben ser más cautelosos respecto a las políticas declaradas por Perplexity e implementar controles técnicos más fuertes si desean asegurarse de que sus preferencias sean realmente respetadas. A medida que el ecosistema de rastreadores de IA madura, se espera una mayor presión sobre empresas como Perplexity para adoptar prácticas más transparentes y éticas que se alineen con los estándares web establecidos y respeten la autonomía de los propietarios de sitios.
PerplexityBot es el rastreador web oficial de Perplexity AI, diseñado para indexar sitios web y mostrarlos en los resultados de búsqueda impulsados por IA de Perplexity. A diferencia de algunos rastreadores de IA que recopilan datos para entrenamiento, PerplexityBot descubre y enlaza específicamente sitios web que proporcionan respuestas relevantes a las consultas de los usuarios. Opera de manera transparente con una cadena de agente de usuario publicada y rangos de direcciones IP.
No. Según la documentación oficial de Perplexity, PerplexityBot está diseñado para mostrar y enlazar sitios web en los resultados de búsqueda de Perplexity. No se utiliza para rastrear contenido con fines de entrenamiento de modelos fundacionales de IA. La única función del rastreador es indexar contenido para su inclusión en el motor de respuestas de Perplexity.
Puedes bloquear a PerplexityBot usando tu archivo robots.txt añadiendo 'User-agent: PerplexityBot' seguido de 'Disallow: /' para evitar todo acceso. Para una protección más fuerte, implementa reglas WAF en Cloudflare o AWS WAF que bloqueen solicitudes que coincidan con el agente de usuario e IPs de PerplexityBot. Sin embargo, ten en cuenta que el rastreo sigiloso puede eludir estos controles.
Perplexity publica los rangos de direcciones IP oficiales para PerplexityBot en https://www.perplexity.com/perplexitybot.json y para Perplexity-User en https://www.perplexity.com/perplexity-user.json. Estos rangos se actualizan regularmente y deben ser la fuente autorizada para la configuración de tu firewall y WAF. Utiliza siempre los endpoints oficiales en lugar de depender de listas de IPs obsoletas.
PerplexityBot afirma respetar las directivas de robots.txt, pero la investigación de Cloudflare en 2025 encontró evidencia de rastreo sigiloso utilizando agentes de usuario no declarados y direcciones IP rotativas para eludir las restricciones de robots.txt. Aunque el rastreador PerplexityBot declarado debería respetar tus reglas, se recomienda implementar protecciones adicionales con WAF si deseas asegurarte de que tus preferencias se apliquen.
El consumo de ancho de banda varía según el tamaño y volumen de contenido de tu sitio. PerplexityBot realiza un rastreo continuo y programado similar al de Google. Los sitios de alto tráfico pueden notar un consumo de ancho de banda considerable. Puedes monitorear el uso real filtrando los registros de tu servidor por solicitudes de PerplexityBot y analizando el volumen de transferencia de datos para determinar si afecta tu infraestructura.
Sí. Puedes buscar manualmente en Perplexity consultas relacionadas con tu contenido para ver si tu sitio es citado en las respuestas. Para un monitoreo más completo, utiliza herramientas como AmICited.com, que rastrea cómo tu marca y contenido aparecen en plataformas de IA incluyendo Perplexity, proporcionando información en tiempo real sobre tu visibilidad en IA y patrones de citación.
PerplexityBot es el rastreador programado que indexa continuamente sitios web para el índice de búsqueda de Perplexity. Perplexity-User se activa bajo demanda cuando los usuarios hacen preguntas y Perplexity necesita obtener páginas específicas en tiempo real. PerplexityBot respeta robots.txt, mientras que Perplexity-User generalmente lo ignora ya que responde a solicitudes de usuarios. Ambos tienen cadenas de agente de usuario y rangos de IP diferentes.
Haz seguimiento de cómo Perplexity y otras plataformas de IA citan tu marca. Obtén información en tiempo real sobre tu visibilidad en IA y optimiza tu estrategia de contenidos para lograr el máximo impacto en motores de búsqueda generativos.
Descubre qué es PerplexityBot, el rastreador web de Perplexity que indexa contenido para su motor de respuestas de IA. Comprende cómo funciona, su cumplimiento ...

Aprende cómo permitir que bots de IA como GPTBot, PerplexityBot y ClaudeBot rastreen tu sitio. Configura robots.txt, crea llms.txt y optimiza para la visibilida...
Perplexity AI es un motor de respuestas con IA que combina búsqueda web en tiempo real con LLM para entregar respuestas citadas y precisas. Descubre cómo funcio...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.