
Acceso Diferencial de Rastreador
Aprende cómo permitir o bloquear selectivamente rastreadores de IA según los objetivos comerciales. Implementa acceso diferencial de rastreadores para proteger ...
10 min de lectura

Aprende a usar robots.txt para controlar qué bots de IA acceden a tu contenido. Guía completa para bloquear GPTBot, ClaudeBot y otros crawlers de IA con ejemplos prácticos y estrategias de configuración.
El panorama del rastreo web ha cambiado fundamentalmente en los últimos dos años, yendo más allá del conocido territorio del indexado de motores de búsqueda hacia el complejo mundo del entrenamiento de modelos de IA. Mientras que Googlebot de Google ha sido durante mucho tiempo un visitante predecible en los sitios de los editores, una nueva generación de crawlers llega ahora con intenciones y patrones de consumo dramáticamente diferentes. GPTBot de OpenAI exhibe una proporción de rastreo a referencia de aproximadamente 1,700:1, lo que significa que rastrea 1,700 páginas para generar solo una referencia de vuelta a tu sitio, mientras que ClaudeBot de Anthropic opera en una proporción aún más extrema de 73,000:1, muy diferente de la proporción de Google de 14:1 donde la actividad de rastreo se traduce en tráfico significativo. Esta diferencia fundamental crea una decisión empresarial urgente para los creadores de contenido: permitir el acceso irrestricto de estos bots significa que tu contenido entrena modelos de IA que compiten con tu tráfico e ingresos, mientras que tu sitio recibe una compensación o tráfico mínimo a cambio. Los editores ahora deben decidir activamente si la propuesta de valor del acceso de bots de IA se alinea con su modelo de negocio, haciendo que la configuración de robots.txt no sea solo una cuestión técnica sino una imperativa estratégica empresarial.
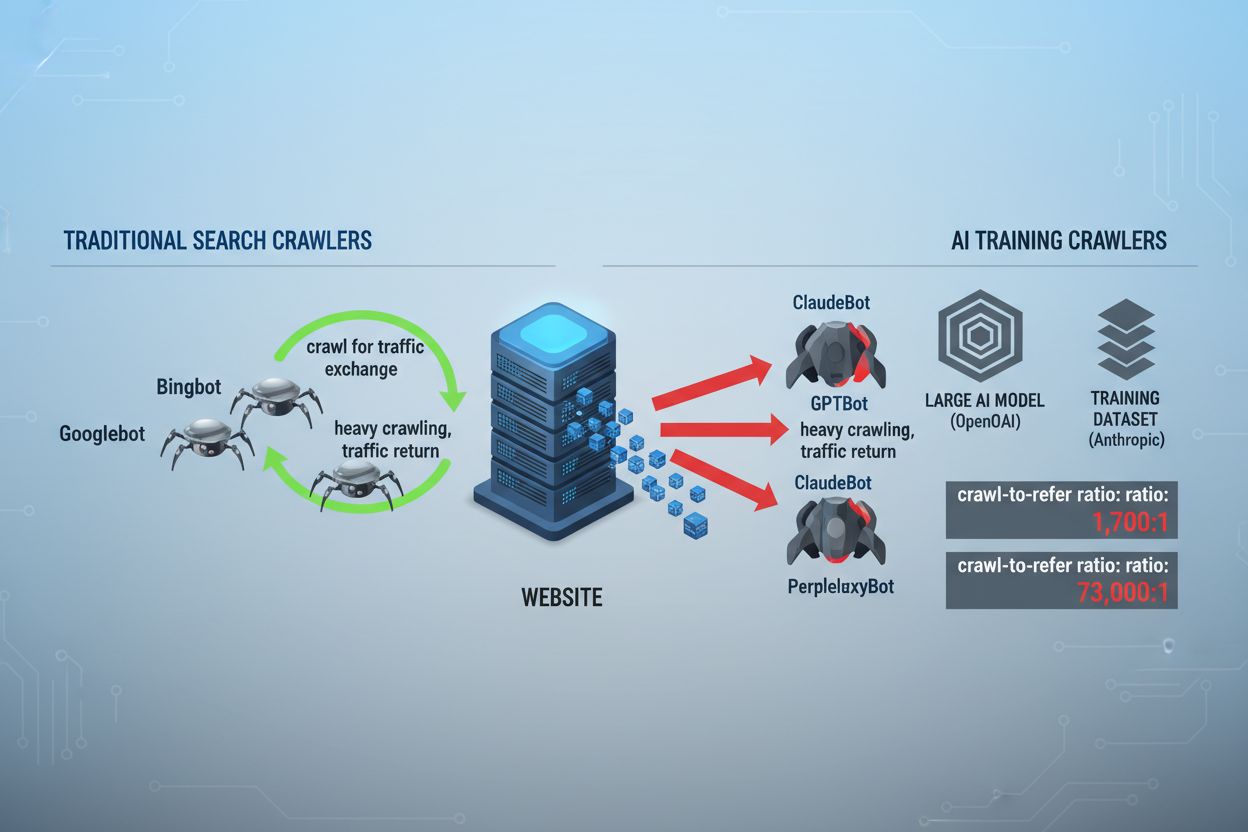
Los crawlers de IA operan en tres categorías distintas, cada una con diferentes propósitos y estrategias de bloqueo. Los crawlers de entrenamiento están diseñados para ingerir grandes volúmenes de contenido y entrenar modelos fundamentales de IA—estos incluyen GPTBot de OpenAI, ClaudeBot de Anthropic, Google-Extended de Google, PerplexityBot de Perplexity, Meta-ExternalAgent de Meta, Applebot-Extended de Apple y nuevos actores como Amazonbot, Bytespider y cohere-ai. Los crawlers de búsqueda, por el contrario, están diseñados para impulsar experiencias de búsqueda con IA y suelen devolver tráfico a los editores; estos incluyen OAI-SearchBot de OpenAI, Claude-Web de Anthropic y la funcionalidad de búsqueda de Perplexity. Los agentes activados por usuario representan una tercera categoría donde el contenido se accede bajo demanda cuando un usuario solicita información explícitamente, como ChatGPT-User o interacciones de Claude-Web iniciadas directamente por usuarios finales. Comprender esta taxonomía es fundamental porque tu estrategia de bloqueo debe reflejar tus prioridades empresariales—puedes acoger a los crawlers de búsqueda que generan tráfico de referencia mientras bloqueas los de entrenamiento que consumen contenido sin compensación. Cada gran empresa de IA mantiene su propia flota de crawlers especializados, y la distinción entre ellos suele estar en la cadena user agent que emplean, por lo que una identificación precisa y un bloqueo dirigido son esenciales para una configuración eficaz de robots.txt.
| Empresa | Crawler de entrenamiento | Crawler de búsqueda | Agente activado por usuario |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (Utiliza Googlebot estándar) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
Mantener una lista precisa y actualizada de los user agents de bots de IA es esencial para una configuración efectiva de robots.txt, pero este panorama evoluciona rápidamente a medida que aparecen nuevos modelos y las empresas ajustan sus estrategias de rastreo. Los principales crawlers de entrenamiento que debes conocer incluyen GPTBot (crawler principal de OpenAI), ClaudeBot (de Anthropic), anthropic-ai (identificador alternativo de Anthropic), Google-Extended (token de entrenamiento de IA de Google), PerplexityBot (de Perplexity), Meta-ExternalAgent (de Meta), Applebot-Extended (variante de IA de Apple), CCBot (de Common Crawl), Amazonbot (de Amazon), Bytespider (de ByteDance), cohere-ai (de Cohere), DuckAssistBot (asistente de IA de DuckDuckGo) y YouBot (de You.com). Los crawlers enfocados en búsqueda suelen devolver tráfico e incluyen OAI-SearchBot, Claude-Web y PerplexityBot cuando operan en modo búsqueda. El desafío crítico es que esta lista no es estática—nuevas empresas de IA emergen regularmente, las existentes lanzan nuevos crawlers para nuevos productos y las cadenas user agent cambian o se amplían ocasionalmente. Los editores deben tratar la configuración de robots.txt como un documento vivo que requiere revisión y actualización trimestral, suscribiéndose a recursos de seguimiento de la industria o monitoreando los logs de servidor para identificar user agents desconocidos que puedan indicar la llegada de nuevos crawlers de IA. No mantener actualizada tu lista de user agents significa permitir accidentalmente nuevos crawlers de entrenamiento que querías bloquear, o bloquear innecesariamente crawlers de búsqueda legítimos que podrían generar tráfico valioso.
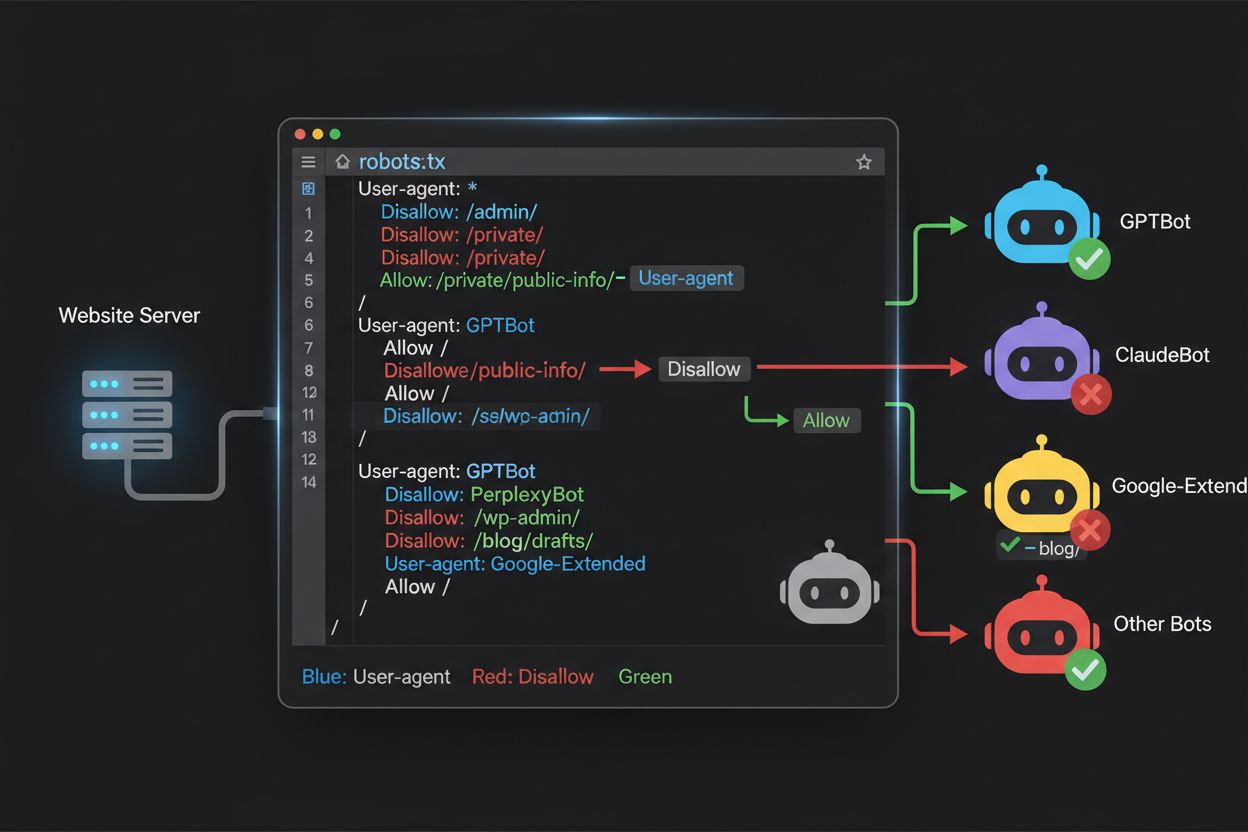
El archivo robots.txt, ubicado en la raíz de tu dominio (tudominio.com/robots.txt), utiliza una sintaxis sencilla para comunicar preferencias de rastreo a los bots que respetan el protocolo. Cada regla comienza con una directiva User-Agent que especifica a qué bot aplica, seguida de una o más directivas Disallow que indican qué rutas el bot no puede acceder. Para bloquear todos los principales crawlers de entrenamiento de IA mientras permites el acceso a motores de búsqueda tradicionales, deberías crear bloques User-Agent separados para cada crawler de entrenamiento que desees excluir: GPTBot, ClaudeBot, anthropic-ai, Google-Extended, PerplexityBot, Meta-ExternalAgent, Applebot-Extended y otros, cada uno con una directiva “Disallow: /” que les impide rastrear cualquier contenido de tu sitio. Al mismo tiempo, asegúrate de que crawlers legítimos como Googlebot, Bingbot y variantes enfocadas en búsqueda como OAI-SearchBot no estén bloqueados, permitiendo que sigan indexando tu contenido y generando tráfico. Un archivo robots.txt correctamente configurado también debe incluir una referencia al Sitemap señalando tu sitemap XML, lo que ayuda a los motores de búsqueda a descubrir e indexar tu contenido eficientemente. La importancia de una configuración correcta no puede subestimarse—un simple error de sintaxis, un carácter fuera de lugar o un user agent incorrecto puede hacer ineficaz toda tu estrategia de bloqueo, permitiendo el acceso a crawlers no deseados mientras potencialmente bloqueas fuentes legítimas de tráfico. Por ello, probar tu configuración antes de implementarla no es opcional, sino esencial para asegurar que tu robots.txt logre su efecto deseado.
# Bloquear crawlers de entrenamiento de IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# Permitir motores de búsqueda tradicionales
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Referencia al Sitemap
Sitemap: https://yoursite.com/sitemap.xml
Muchos editores se enfrentan a una decisión matizada: quieren mantener la visibilidad en resultados de búsqueda impulsados por IA y recibir el tráfico de referencia que generan esas plataformas, pero desean evitar que su contenido sea usado para entrenar modelos de IA que compiten con su negocio. Esta estrategia de bloqueo selectivo requiere distinguir entre crawlers de búsqueda y de entrenamiento de la misma empresa—por ejemplo, permitiendo el acceso de OAI-SearchBot de OpenAI (que impulsa la función de búsqueda de ChatGPT y devuelve tráfico) mientras se bloquea a GPTBot (que entrena el modelo subyacente). De manera similar, puedes permitir el crawler de búsqueda de PerplexityBot mientras bloqueas sus operaciones de entrenamiento, o permitir Claude-Web para búsquedas activadas por usuario y bloquear las actividades de entrenamiento de ClaudeBot. La razón empresarial es contundente: los crawlers de búsqueda operan con ratios mucho más bajos de rastreo a referencia porque están diseñados para dirigir tráfico de vuelta a tu sitio, mientras que los de entrenamiento consumen contenido a gran escala con un beneficio recíproco mínimo. Este enfoque requiere una configuración cuidadosa y monitoreo constante, ya que las empresas ocasionalmente cambian sus estrategias de rastreo o introducen nuevos user agents que difuminan la línea entre búsqueda y entrenamiento. Los editores que implementen esta estrategia deben auditar regularmente sus logs de servidor para verificar que los crawlers deseados acceden a su contenido mientras los bloqueados son excluidos exitosamente, ajustando su robots.txt conforme evoluciona el panorama de IA y entran nuevos actores al mercado.
# Permitir crawlers de búsqueda de IA
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# Bloquear crawlers de entrenamiento
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
Incluso webmasters experimentados cometen errores de configuración que minan por completo su estrategia robots.txt, dejando el contenido vulnerable ante los crawlers que pretendían bloquear. El primer error común es crear líneas User-Agent independientes sin directivas Disallow correspondientes—por ejemplo, escribir “User-Agent: GPTBot” en una línea y luego empezar una nueva regla sin especificar qué debe negarse a GPTBot, lo que deja al bot totalmente desbloqueado. El segundo error implica la ubicación incorrecta del archivo, el nombre o la sensibilidad a mayúsculas; el archivo debe llamarse exactamente “robots.txt” (en minúsculas), estar en la raíz del dominio y devolverse con un código HTTP 200—ponerlo en un subdirectorio o llamarlo “Robots.txt” o “robots.TXT” lo hace invisible para los crawlers. El tercer error es insertar líneas en blanco dentro de un bloque de reglas, ya que muchos analizadores de robots.txt interpretan esto como el final de la regla, haciendo que directivas posteriores sean ignoradas o mal aplicadas. El cuarto error implica la sensibilidad a mayúsculas en las rutas URL; aunque los nombres de user agent no distinguen mayúsculas, las rutas en Disallow sí, así que “Disallow: /Admin” no bloqueará “/admin” ni “/ADMIN”. El quinto error es el uso incorrecto de comodines: el asterisco (*) coincide con cualquier secuencia de caracteres, pero muchos editores lo usan mal escribiendo patrones como “Disallow: .pdf” cuando deberían escribir “Disallow: /.pdf” o “Disallow: /*pdf” para coincidir adecuadamente con extensiones de archivo. Además, algunos editores crean reglas demasiado complejas con múltiples directivas Disallow que se contradicen, o no consideran parámetros de URL y cadenas de consulta, lo que puede hacer que contenido legítimo se bloquee o permanezca accesible contenido no deseado. Probar tu configuración con validadores dedicados antes de implementarla puede detectar estos errores antes de que afecten la rastreabilidad de tu sitio.
Errores comunes a evitar:
Google-Extended representa un caso único en la configuración de robots.txt porque funciona como un token de control en vez de un crawler tradicional, y entender esta distinción es crítico para tomar decisiones informadas de bloqueo. A diferencia de Googlebot, que rastrea tu sitio para indexar contenido en Google Search, Google-Extended es una señal que controla si tu contenido puede usarse para entrenar los modelos de IA Gemini de Google y alimentar la función AI Overviews de Google en los resultados de búsqueda. Bloquear Google-Extended evita que tu contenido se use en el entrenamiento de Gemini y la generación de AI Overviews, pero no afecta tu visibilidad en los resultados tradicionales de Google Search—Googlebot seguirá indexando tu contenido normalmente. El intercambio es significativo: bloquear Google-Extended significa que tu contenido no aparecerá en AI Overviews, que son cada vez más prominentes y pueden generar tráfico relevante, pero protege tu contenido de ser usado para entrenar un modelo de IA competidor. Por el contrario, permitir Google-Extended hace que tu contenido pueda aparecer en AI Overviews (potencialmente generando tráfico) pero también contribuye a los datos de entrenamiento de Gemini, que eventualmente podría competir con tu propio contenido o modelo de negocio. Los editores deben considerar cuidadosamente su situación específica—organizaciones de noticias y creadores de contenido cuyo modelo depende del tráfico directo pueden beneficiarse de bloquear Google-Extended, mientras que otros pueden acoger la visibilidad y el potencial de tráfico de AI Overviews. Esta decisión debe tomarse intencionadamente y no por defecto, ya que tiene implicaciones importantes para tu visibilidad y tráfico a largo plazo en el ecosistema de búsqueda de Google.
Probar tu configuración robots.txt antes de desplegarla a producción es absolutamente crítico, ya que los errores pueden tener consecuencias de gran alcance tanto para tu visibilidad en buscadores como para tu estrategia de protección de contenido. Google Search Console ofrece un probador incorporado de robots.txt que permite verificar si agentes específicos pueden acceder a URLs de tu sitio—puedes introducir una cadena de user agent como “GPTBot” y una ruta URL, y Google te dirá si ese bot estaría permitido o bloqueado según tu configuración. Merkle Robots.txt Tester ofrece una funcionalidad similar con una interfaz amigable y explicaciones detalladas de cómo se interpretan tus reglas. TechnicalSEO.com proporciona otra herramienta gratuita que valida tu sintaxis y muestra exactamente cómo serían tratados los distintos bots. Para un monitoreo más completo, Knowatoa AI Search Console ofrece herramientas especializadas para rastrear la actividad de crawlers de IA y validar tu configuración contra los bots específicos que intentas bloquear. Tu flujo de validación debe incluir subir tu robots.txt a un entorno de pruebas primero, verificar que las páginas críticas que deseas mantener accesibles no estén bloqueadas accidentalmente, confirmar que los bots de IA que querías bloquear estén realmente excluidos y monitorear los logs de tu servidor para detectar actividad inesperada de crawlers. Esta fase de pruebas también debe incluir verificar que tu referencia al Sitemap es correcta y que los motores de búsqueda aún pueden acceder normalmente a tu contenido—quieres bloquear crawlers de entrenamiento de IA sin bloquear accidentalmente el tráfico legítimo de búsqueda. Solo después de pruebas exhaustivas debes desplegar tu configuración en producción y aún así monitorear los logs la primera semana para detectar cualquier problema inesperado.
Herramientas de prueba:
Aunque robots.txt es una útil primera línea de defensa, es importante entender que opera bajo un sistema de honor—los bots que respetan el protocolo seguirán tus directivas, pero crawlers maliciosos o mal diseñados pueden ignorarlo y acceder igualmente a tu contenido. Los datos sugieren que robots.txt detiene aproximadamente el 40-60% del tráfico no deseado de crawlers, lo que significa que el 40-60% de los bots ignoran el protocolo o están diseñados para eludirlo. Para editores que requieren protección más robusta, se necesitan capas adicionales de defensa. El firewall de aplicaciones web (WAF) de Cloudflare permite crear reglas que bloquean el tráfico basado en cadenas user agent, direcciones IP o patrones de comportamiento, protegiendo contra bots que ignoran robots.txt. Herramientas a nivel de servidor como .htaccess (en servidores Apache) o configuraciones equivalentes en Nginx pueden bloquear user agents o rangos de IP antes de que las solicitudes lleguen a tu aplicación. El bloqueo por IP puede ser efectivo si identificas los rangos usados por crawlers específicos, aunque requiere mantenimiento continuo a medida que cambia la infraestructura de los crawlers. Herramientas como Fail2ban pueden bloquear automáticamente IPs que muestran patrones sospechosos, como hacer solicitudes a velocidades inhumanas o acceder a rutas sensibles. Sin embargo, implementar estas protecciones adicionales requiere una configuración cuidadosa—un bloqueo demasiado agresivo puede excluir accidentalmente tráfico legítimo, incluidos usuarios reales que navegan a través de VPNs o proxies corporativos que comparten rangos de IP con crawlers conocidos. El enfoque más efectivo combina robots.txt como primera solicitud cortés, bloqueo por user agent a nivel de servidor para bots que ignoran robots.txt y monitoreo de comportamiento para detectar crawlers sofisticados que falsifican user agents o usan IPs distribuidas. Los editores deben implementar estas capas de manera incremental, probando cada una para asegurarse de no bloquear tráfico legítimo mientras logran sus objetivos de protección de contenido.
Entender qué está accediendo realmente a tu sitio es esencial para validar que tu configuración de robots.txt funciona como esperabas y para identificar nuevos crawlers que puedan requerir bloqueo. El análisis de logs de servidor es el método principal para este monitoreo—los logs de tu servidor web (logs de acceso de Apache, logs de Nginx o equivalentes) contienen registros detallados de cada solicitud, incluyendo la cadena de user agent, dirección IP, marca de tiempo y recurso solicitado. Puedes usar herramientas de línea de comandos como grep para buscar en tus logs user agents específicos; por ejemplo, “grep ‘GPTBot’ /var/log/apache2/access.log” te mostrará cada solicitud de GPTBot, permitiéndote verificar si tus reglas de bloqueo funcionan. Un análisis más sofisticado podría implicar analizar la tasa de rastreo de diferentes bots, las páginas específicas a las que acceden y si respetan tus directivas de robots.txt. Soluciones de monitoreo automatizado pueden analizar continuamente tus logs y alertarte cuando aparecen crawlers nuevos o inesperados, lo cual es especialmente valioso dado lo rápido que evoluciona el panorama de los crawlers de IA. Algunos editores usan plataformas de agregación de logs como ELK Stack, Splunk o soluciones en la nube para centralizar y analizar la actividad de crawlers en múltiples servidores. El panorama cambiante de crawlers de IA significa que monitorear no es una tarea puntual sino una responsabilidad continua—nuevos bots emergen regularmente, los existentes cambian sus cadenas user agent y el comportamiento de los crawlers evoluciona a medida que las empresas ajustan sus estrategias. Establecer una rutina de monitoreo regular (revisiones semanales o mensuales de logs) te ayuda a anticiparte a los cambios y ajustar proactivamente tu configuración de robots.txt en vez de descubrir problemas después de que hayan impactado tu sitio.
La configuración de robots.txt para crawlers de IA es fundamentalmente una decisión de ingresos y merece la misma consideración estratégica que aplicarías a cualquier elección empresarial con implicaciones financieras importantes. Permitir el acceso irrestricto de crawlers de entrenamiento a tu contenido significa que modelos de IA entrenados con tus datos pueden eventualmente competir con tu tráfico e ingresos—si tu modelo de negocio depende de tráfico directo, visibilidad en buscadores o ingresos publicitarios, esencialmente estás proporcionando datos de entrenamiento gratis a empresas que construyen productos competidores. Por el contrario, bloquear todos los crawlers de IA significa perder visibilidad potencial en resultados de búsqueda impulsados por IA y tráfico de referencia de asistentes de IA, que representan una porción creciente de cómo los usuarios descubren contenido. La estrategia óptima depende de tu modelo de negocio específico: editores apoyados en publicidad pueden beneficiarse permitiendo crawlers de búsqueda (que generan tráfico e impresiones) y bloqueando los de entrenamiento (que no generan tráfico). Los editores por suscripción pueden optar por una postura más agresiva, bloqueando la mayoría de los crawlers de IA para proteger su contenido de ser resumido o replicado por sistemas de IA. Los editores enfocados en visibilidad de marca pueden acoger la visibilidad en búsqueda de IA como un canal de distribución. La clave es tomar esta decisión de forma intencionada y no por defecto—muchos editores nunca han configurado robots.txt para crawlers de IA, permitiendo todos los bots por defecto, lo que equivale a tomar una decisión pasiva de contribuir su contenido al entrenamiento de IA sin elegirlo activamente. Además, considera implementar marcado schema que ofrezca atribución adecuada cuando tu contenido sea usado por sistemas de IA, lo que puede ayudar a asegurar que el tráfico y el crédito lleguen a tu sitio incluso cuando el contenido sea referenciado por asistentes de IA. Tu configuración robots.txt debe reflejar tu estrategia empresarial deliberada, revisada y actualizada regularmente a medida que el panorama de IA evoluciona y cambian tus prioridades empresariales.
El panorama de los crawlers de IA evoluciona a un ritmo sin precedentes, con nuevas empresas lanzando productos de IA, compañías existentes introduciendo nuevos crawlers y cadenas user agent cambiando o ampliándose regularmente. Tu configuración de robots.txt no debe ser un archivo de “configura y olvida”, sino un documento vivo que revises y actualices al menos cada trimestre. Establece un proceso para monitorear anuncios de la industria sobre nuevos crawlers de IA, suscríbete a boletines o blogs que rastreen estos desarrollos y audita regularmente tus logs de servidor para identificar user agents desconocidos que puedan indicar la llegada de nuevos crawlers. Cuando descubras nuevos crawlers, investiga su propósito y modelo de negocio para determinar si se alinean con tu estrategia de protección de contenido, y luego actualiza tu robots.txt en consecuencia. Además, monitorea la efectividad de tu configuración rastreando métricas como el volumen de tráfico de crawlers, la proporción de solicitudes de crawler respecto al tráfico de usuario y cualquier cambio en tu visibilidad orgánica o tráfico de referencia desde resultados de búsqueda impulsados por IA. Algunos editores descubren que su estrategia inicial de bloqueo necesita ajustes tras algunos meses de datos reales—quizá descubren que bloquear cierto crawler tuvo consecuencias no deseadas, o que permitir ciertos crawlers genera tráfico más valioso de lo esperado. Prepárate para iterar en tu estrategia basándote en resultados reales y no en suposiciones. Finalmente, comunica tu estrategia robots.txt a los interesados relevantes de tu organización—tu equipo SEO, de contenido y dirección deben entender por qué se bloquean o permiten ciertos crawlers, para que las decisiones permanezcan consistentes e intencionadas conforme evoluciona tu organización. Esta atención continua a la gestión de crawlers asegura que tu estrategia de protección de contenido siga siendo efectiva y alineada con tus objetivos empresariales a medida que el panorama de la IA continúa transformándose.
No. Bloquear crawlers de entrenamiento de IA como GPTBot, ClaudeBot y CCBot no afecta tu posicionamiento en Google o Bing. Los motores de búsqueda tradicionales usan crawlers diferentes (Googlebot, Bingbot) que funcionan de manera independiente. Solo bloquéalos si quieres desaparecer por completo de los resultados de búsqueda.
Los principales crawlers de OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) y Perplexity (PerplexityBot) afirman oficialmente que respetan las directivas de robots.txt. Sin embargo, bots más pequeños o menos transparentes pueden ignorar tu configuración, por lo cual existen estrategias de protección por capas.
Depende de tu estrategia. Bloquear solo los crawlers de entrenamiento (GPTBot, ClaudeBot, CCBot) protege tu contenido del entrenamiento de modelos, pero permite que los crawlers enfocados en búsqueda te ayuden a aparecer en resultados de búsqueda de IA. Bloquear por completo te excluye de los ecosistemas de IA.
Revisa tu configuración al menos trimestralmente. Las empresas de IA introducen nuevos crawlers con regularidad. Anthropic fusionó sus bots 'anthropic-ai' y 'Claude-Web' en 'ClaudeBot', dándole acceso temporal irrestricto a sitios que no actualizaron sus reglas.
Robots.txt es un archivo en la raíz de tu dominio que aplica a todas las páginas, mientras que las etiquetas meta robots son directivas HTML en páginas individuales. Robots.txt se consulta primero y puede evitar que los crawlers accedan a una página, mientras que las meta solo se leen si la página es accedida. Usa ambos para un control integral.
Sí. Puedes usar reglas Disallow específicas por ruta en robots.txt (por ejemplo, 'Disallow: /premium/' para bloquear solo contenido premium) o utilizar meta robots en páginas individuales. Así puedes proteger contenido sensible y permitir el acceso a otras áreas.
Si un bot ignora robots.txt, necesitarás métodos de protección adicionales como bloqueo a nivel de servidor (.htaccess), bloqueo por IP o reglas WAF. Robots.txt detiene aproximadamente el 40-60% de los crawlers no deseados, por lo que la protección por capas es importante para una defensa integral.
Utiliza herramientas como el probador de robots.txt de Google Search Console, Merkle Robots.txt Tester o TechnicalSEO.com para validar tu configuración. Monitorea los logs de tu servidor para ver la actividad de los crawlers y verifica que los bots bloqueados estén siendo excluidos y los permitidos accedan a tu contenido.
Robots.txt es solo el primer paso. Usa AmICited para rastrear qué sistemas de IA citan tu contenido, con qué frecuencia te mencionan y asegurar la atribución adecuada en GPTs, Perplexity, Google AI Overviews y más.
Aprende cómo permitir o bloquear selectivamente rastreadores de IA según los objetivos comerciales. Implementa acceso diferencial de rastreadores para proteger ...

Aprende cómo los cortafuegos de aplicaciones web proporcionan un control avanzado sobre los rastreadores de IA más allá de robots.txt. Implementa reglas WAF par...

Aprende cómo los rastreadores de búsqueda por IA determinan la frecuencia de rastreo de tu sitio web. Descubre cómo ChatGPT, Perplexity y otros motores de IA ra...