
Token
Descubre qué son los tokens en los modelos de lenguaje. Los tokens son unidades fundamentales de procesamiento de texto en sistemas de IA, representando palabra...
13 min de lectura

Explora cómo los límites de tokens afectan el rendimiento de la IA y aprende estrategias prácticas para la optimización de contenidos, incluyendo RAG, fragmentación y técnicas de resumen.
Los tokens son los bloques fundamentales que los modelos de IA utilizan para procesar y comprender la información. En lugar de trabajar con palabras o frases completas, los grandes modelos de lenguaje descomponen el texto en unidades más pequeñas llamadas tokens, que pueden ser caracteres individuales, subpalabras o palabras completas según el algoritmo de tokenización. A cada token se le asigna un identificador numérico único que el modelo utiliza internamente para el cálculo. Este proceso de tokenización es esencial porque permite a los sistemas de IA manejar entradas de longitud variable de manera eficiente y mantener un procesamiento consistente en diferentes tipos de contenido. Comprender los tokens es crucial para cualquiera que trabaje con sistemas de IA, ya que impactan directamente en el rendimiento, el costo y la calidad de los resultados que puedes lograr.
Diferentes modelos de IA tienen límites de tokens muy variados, que definen la cantidad máxima de información que pueden procesar en una sola solicitud. Estos límites han evolucionado dramáticamente en los últimos años, con modelos más nuevos que soportan ventanas de contexto significativamente más grandes. El límite de tokens abarca tanto los tokens de entrada (tu mensaje y datos) como los de salida (la respuesta del modelo), generando un presupuesto compartido que debe gestionarse cuidadosamente. Entender estos límites es esencial para escoger el modelo adecuado para tu caso de uso y planificar la arquitectura de tu aplicación en consecuencia.
| Modelo | Límite de Tokens | Caso de Uso Principal | Nivel de Costo |
|---|---|---|---|
| GPT-3.5 Turbo | 4,096 | Conversaciones cortas, tareas rápidas | Bajo |
| GPT-4 | 8,192 | Aplicaciones estándar, complejidad moderada | Medio |
| GPT-4 Turbo | 128,000 | Documentos largos, análisis complejo | Alto |
| Claude 3.5 Sonnet | 200,000 | Documentos extendidos, análisis integral | Alto |
| Gemini 1.5 Pro | 1,000,000 | Conjuntos de datos masivos, libros completos, análisis de video | Muy alto |
Consideraciones clave al evaluar límites de tokens:
Los límites de tokens crean restricciones significativas que afectan directamente la precisión, confiabilidad y rentabilidad de las aplicaciones de IA. Cuando excedes el límite de tokens de un modelo, la aplicación falla por completo—no hay degradación gradual ni procesamiento parcial. Incluso al permanecer dentro de los límites, enfoques ingenuos como una simple truncación pueden degradar gravemente el rendimiento al eliminar contexto crítico que el modelo necesita para generar respuestas precisas. Esto es especialmente problemático en dominios como análisis legal, investigación médica e ingeniería de software, donde perder incluso un solo detalle importante puede llevar a conclusiones incorrectas. El reto se vuelve aún más complejo si consideras que diferentes tipos de contenido consumen tokens a diferentes tasas—los datos estructurados como código o JSON requieren significativamente más tokens que el texto en inglés simple debido a los símbolos y el formato.
La truncación es el método más sencillo para manejar los límites de tokens—simplemente cortas el contenido excedente cuando supera la capacidad del modelo. Aunque es fácil de implementar, este enfoque conlleva riesgos significativos. Cuando trunques texto, inevitablemente pierdes información y el modelo no tiene forma de saber qué se eliminó. Esto puede llevar a análisis incompletos, contexto perdido y alucinaciones en las que el modelo genera información plausible pero incorrecta para rellenar los vacíos en su comprensión.
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# Example: Truncating to 4000 tokens
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
Una estrategia de truncación más sofisticada distingue entre contenido esencial y opcional. Puedes priorizar elementos imprescindibles como la consulta actual del usuario e instrucciones centrales, y luego añadir contexto opcional como el historial de conversación solo si el espacio lo permite. Este enfoque preserva la información crítica mientras sigue respetando los límites de tokens.
En lugar de truncar, la fragmentación divide tu contenido en piezas más pequeñas y manejables que pueden procesarse de forma independiente o selectiva. La fragmentación de tamaño fijo divide el texto en segmentos uniformes, mientras que la fragmentación semántica utiliza embeddings para identificar puntos de corte naturales basados en significado en vez de contar tokens arbitrariamente. Las ventanas deslizantes con solapamiento preservan el contexto entre fragmentos, asegurando que la información importante que abarca varios fragmentos no se pierda.
La fragmentación jerárquica crea varios niveles de abstracción—párrafos individuales en el nivel más fino, secciones en el siguiente nivel y capítulos en el nivel más alto. Este enfoque permite estrategias de recuperación sofisticadas donde puedes identificar rápidamente las secciones relevantes sin procesar el documento completo. Combinada con bases de datos vectoriales y búsqueda semántica, la fragmentación se convierte en una herramienta poderosa para gestionar grandes bases de conocimiento manteniendo la relevancia y precisión.
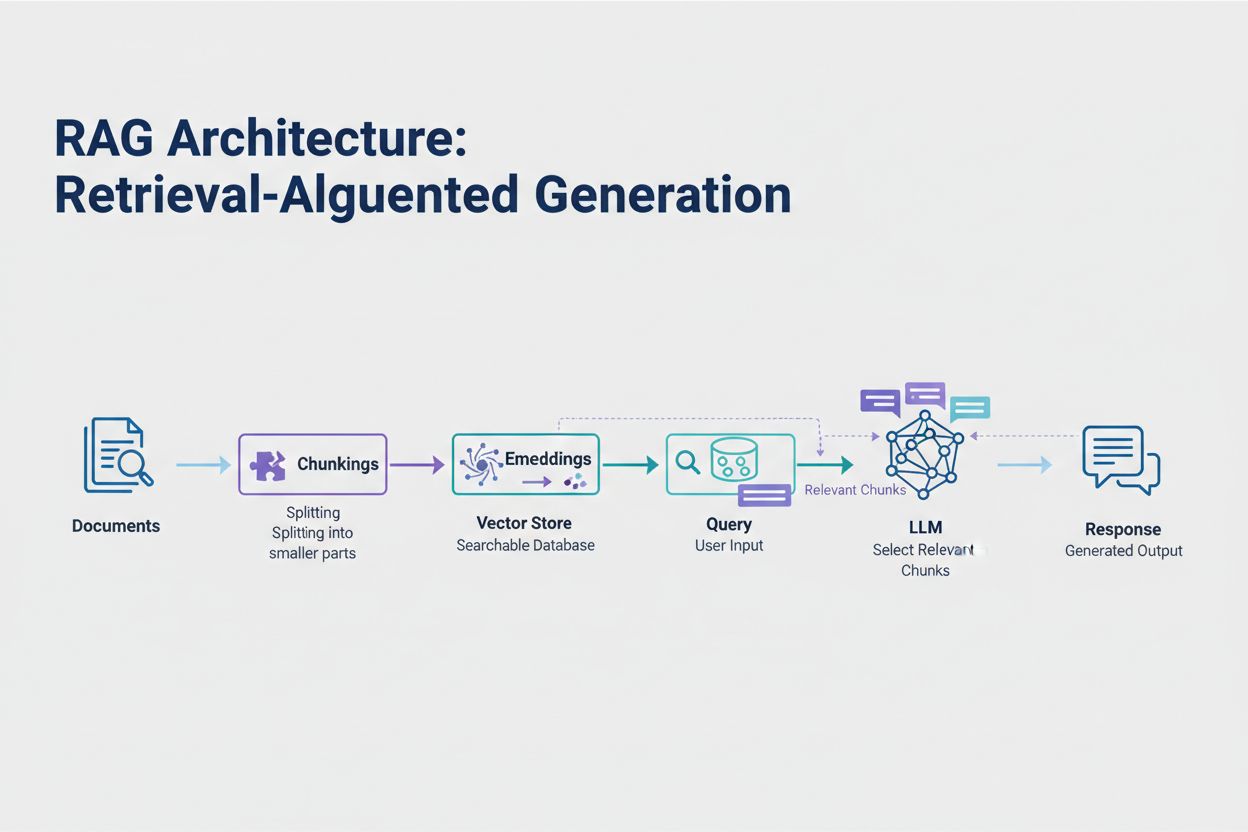
La Generación Aumentada por Recuperación (RAG) representa el enfoque moderno más efectivo para manejar los límites de tokens. En lugar de intentar incluir todos tus datos en la ventana de contexto del modelo, RAG recupera solo la información más relevante en el momento de la consulta. El proceso comienza convirtiendo tus documentos en embeddings—representaciones numéricas que capturan el significado semántico. Estos embeddings se almacenan en una base de datos vectorial, lo que permite búsquedas de similitud rápidas.
Cuando un usuario envía una consulta, el sistema convierte la consulta en un embedding y recupera los fragmentos de documentos más relevantes del almacén vectorial. Solo estos fragmentos relevantes se inyectan en el mensaje junto con la pregunta del usuario, reduciendo drásticamente el consumo de tokens y mejorando la precisión. Por ejemplo, analizar un contrato legal de 100 páginas con RAG podría requerir solo 3-5 cláusulas clave en el mensaje, en comparación con los miles de tokens necesarios para incluir el documento completo.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Step 1: Load and chunk documents
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# Step 2: Create embeddings and vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# Step 3: Set up RAG chain
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# Step 4: Query the system
result = qa_chain.run("What are the key terms of this contract?")
El resumen condensa contenido extenso preservando la información esencial, reduciendo efectivamente el consumo de tokens. El resumen extractivo selecciona frases clave del texto original, mientras que el resumen abstractivo genera texto nuevo y conciso que capta las ideas principales. El resumen jerárquico crea varios niveles de resúmenes—primero resumiendo secciones individuales, luego combinando esos resúmenes en descripciones generales de alto nivel. Este enfoque funciona especialmente bien para documentos estructurados como artículos de investigación o informes técnicos.
La compresión de contexto adopta un enfoque diferente eliminando redundancia y contenido de relleno manteniendo la redacción original. Los enfoques de grafo de conocimiento extraen entidades y relaciones del texto, y luego reconstruyen el contexto usando solo los hechos más relevantes. Estas técnicas pueden lograr una reducción de tokens del 40-60% manteniendo la precisión semántica, por lo que son valiosas para la optimización de costos en sistemas de producción.
La gestión de tokens impacta directamente en los costos de tu aplicación de IA. Cada token consumido durante la inferencia implica un cargo, y los costos escalan linealmente con el uso de tokens. Monitorear el consumo de tokens es esencial para comprender tu estructura de costos e identificar oportunidades de optimización. Muchas plataformas de IA ofrecen ahora utilidades de conteo de tokens y tableros en tiempo real que rastrean patrones de uso, ayudándote a identificar qué consultas o funciones consumen más tokens.
Un monitoreo efectivo revela oportunidades de optimización—quizás ciertos tipos de consultas exceden consistentemente los límites de tokens, o funciones específicas consumen recursos desproporcionados. Al rastrear estos patrones, puedes tomar decisiones informadas sobre qué estrategia de optimización implementar. Algunas aplicaciones se benefician al enrutar solicitudes grandes a modelos más capaces (pero más costosos), mientras que otras se benefician más implementando RAG o resúmenes. La clave es medir el rendimiento y los costos reales para validar tus elecciones de optimización.
Elegir la estrategia de gestión de tokens adecuada depende de tu caso de uso específico, los requisitos de rendimiento y las limitaciones de costos. Las aplicaciones que requieren alta precisión con respuestas referenciadas se benefician más de RAG, que preserva la fidelidad de la información mientras administra el consumo de tokens. Las aplicaciones conversacionales de larga duración se benefician de técnicas de almacenamiento de memoria que resumen el historial de la conversación mientras preservan decisiones clave y contexto. Aplicaciones con muchos documentos, como análisis legal o herramientas de investigación, suelen beneficiarse de resúmenes jerárquicos combinados con fragmentación semántica.
Las pruebas y validaciones son fundamentales antes de implementar cualquier estrategia de gestión de tokens en producción. Crea casos de prueba que excedan los límites de tokens de tu modelo y evalúa cómo diferentes estrategias afectan la precisión, latencia y costos. Mide métricas como relevancia de la respuesta, precisión factual y eficiencia de tokens para asegurar que el enfoque elegido cumple con tus requisitos. Los errores comunes incluyen resúmenes demasiado agresivos que pierden detalles críticos, sistemas de recuperación que omiten información relevante y estrategias de fragmentación que dividen el contenido en puntos semánticamente inapropiados.
Los límites de tokens continúan expandiéndose a medida que los modelos se vuelven más sofisticados y eficientes. Técnicas emergentes como los mecanismos de atención dispersa y los transformers eficientes prometen reducir el costo computacional de procesar ventanas de contexto grandes. Los modelos multimodales que gestionan texto, imágenes, audio y video simultáneamente presentan nuevos retos y oportunidades en tokenización. Los tokens de razonamiento—tokens especiales usados por los modelos para “pensar” problemas complejos—representan una nueva categoría de consumo de tokens que permite una resolución de problemas más sofisticada pero requiere una gestión cuidadosa.
La tendencia es clara: a medida que las ventanas de contexto se expanden y el procesamiento de tokens se vuelve más eficiente, el cuello de botella se traslada de la capacidad bruta a la selección inteligente de contenido. El futuro pertenece a los sistemas que pueden identificar y recuperar eficazmente la información más relevante de grandes bases de conocimiento, en lugar de sistemas que simplemente procesan mayores volúmenes de datos. Esto hace que técnicas como RAG y la búsqueda semántica sean cada vez más importantes para construir aplicaciones de IA escalables y rentables.
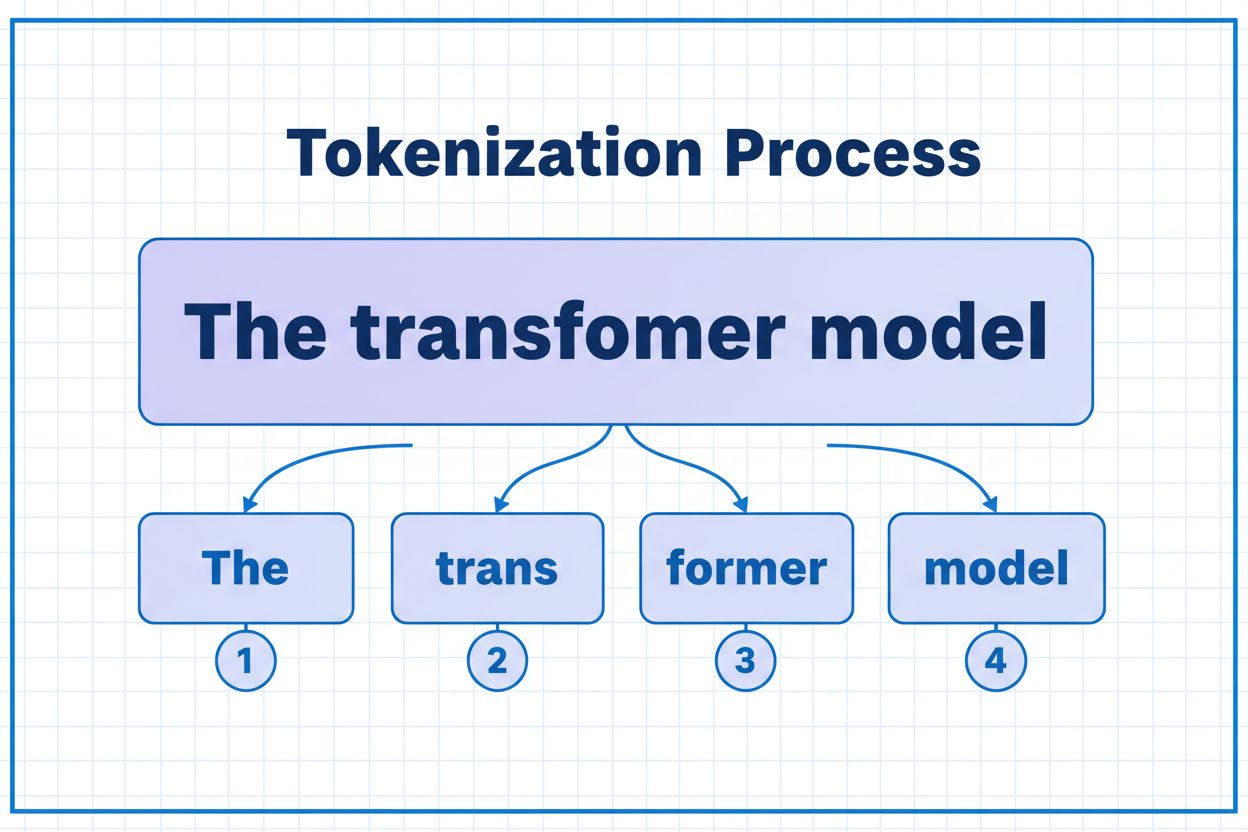
Un token es la unidad más pequeña de datos que procesa un modelo de IA. Los tokens pueden ser caracteres individuales, subpalabras o palabras completas según el algoritmo de tokenización. Por ejemplo, la palabra 'transformer' podría dividirse en 'trans' y 'former' como dos tokens separados. A cada token se le asigna un identificador numérico único que el modelo utiliza internamente para el cálculo.
Los límites de tokens definen la cantidad máxima de información que tu modelo de IA puede procesar en una sola solicitud. Cuando excedes este límite, tu aplicación falla por completo. Incluso al permanecer dentro de los límites, enfoques ingenuos como la truncación pueden degradar la precisión al eliminar contexto crítico. Los límites de tokens también impactan directamente en los costos, ya que normalmente pagas por cada token consumido.
Los tokens de entrada son los tokens en tu mensaje y datos que envías al modelo, mientras que los tokens de salida son los que el modelo genera en su respuesta. Ambos comparten un presupuesto combinado definido por la ventana de contexto del modelo. Si tu entrada usa el 90% de una ventana de 128K tokens, solo queda el 10% para la salida del modelo.
La truncación es fácil de implementar pero riesgosa. Elimina información sin que el modelo sepa qué se perdió, lo que lleva a análisis incompletos y posibles alucinaciones. Aunque útil como último recurso, enfoques mejores como RAG, fragmentación o resumen preservan la fidelidad de la información manejando el consumo de tokens de manera más efectiva.
La Generación Aumentada por Recuperación (RAG) recupera solo la información más relevante en tiempo de consulta en lugar de incluir documentos completos. Tus documentos se convierten en embeddings y se almacenan en una base de datos vectorial. Cuando un usuario consulta, el sistema recupera solo fragmentos relevantes y los inyecta en el mensaje, reduciendo drásticamente el consumo de tokens y mejorando la precisión.
La mayoría de las plataformas de IA ofrecen utilidades de conteo de tokens y tableros en tiempo real para rastrear patrones de uso. Monitorea qué consultas o funciones consumen más tokens, luego implementa estrategias de optimización como RAG para aplicaciones con muchos documentos, resumen para conversaciones largas o redirección a modelos más grandes para tareas complejas. Mide el rendimiento real y los costos para validar tus decisiones.
Los servicios de IA generalmente cobran por token consumido. Los costos escalan linealmente con el uso de tokens, por lo que la optimización de tokens impacta directamente en tus gastos. Una reducción del 20% en el consumo de tokens se traduce en una reducción del 20% en el costo. Comprender la eficiencia de tokens te ayuda a elegir la estrategia de optimización adecuada para tus restricciones de presupuesto.
Los límites de tokens continúan expandiéndose a medida que los modelos se vuelven más sofisticados. Técnicas emergentes como los mecanismos de atención dispersa prometen reducir los costos computacionales de procesar grandes contextos. El futuro se centra en la selección y recuperación inteligente de contenidos en lugar de solo capacidad de procesamiento, haciendo que técnicas como RAG sean cada vez más importantes para aplicaciones de IA escalables.
Comprende la eficiencia de tokens y rastrea cómo los modelos de IA citan tu marca con la plataforma integral de monitoreo de citas de IA de AmICited.
Descubre qué son los tokens en los modelos de lenguaje. Los tokens son unidades fundamentales de procesamiento de texto en sistemas de IA, representando palabra...

Descubre cómo los modelos de IA procesan texto mediante tokenización, embeddings, bloques transformadores y redes neuronales. Comprende toda la cadena desde la ...
Aprende estrategias esenciales para optimizar tu contenido de soporte para sistemas de IA como ChatGPT, Perplexity y Google AI Overviews. Descubre las mejores p...
Consentimiento de Cookies
Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.