Optimización de Datos de Entrenamiento vs Recuperación en Tiempo Real: Estrategias de Optimización
Compara la optimización de datos de entrenamiento y las estrategias de recuperación en tiempo real para IA. Aprende cuándo usar fine-tuning versus RAG, implicaciones de costos y enfoques híbridos para un rendimiento óptimo de la IA.
Publicado el Jan 3, 2026.Última modificación el Jan 3, 2026 a las 3:24 am
La optimización de datos de entrenamiento y la recuperación en tiempo real representan enfoques fundamentalmente diferentes para dotar de conocimiento a los modelos de IA. La optimización de datos de entrenamiento implica incrustar el conocimiento directamente en los parámetros del modelo mediante fine-tuning con conjuntos de datos específicos del dominio, creando un conocimiento estático que permanece fijo tras completar el entrenamiento. La recuperación en tiempo real, en cambio, mantiene el conocimiento externo al modelo y recupera información relevante dinámicamente durante la inferencia, permitiendo el acceso a información dinámica que puede cambiar entre solicitudes. La diferencia fundamental radica en cuándo se integra el conocimiento en el modelo: la optimización de datos de entrenamiento ocurre antes del despliegue, mientras que la recuperación en tiempo real ocurre durante cada llamada de inferencia. Esta diferencia fundamental impacta en todos los aspectos de la implementación, desde los requisitos de infraestructura hasta las características de precisión y consideraciones de cumplimiento. Comprender esta distinción es esencial para que las organizaciones decidan qué estrategia de optimización se alinea con sus casos de uso y restricciones específicas.
Cómo Funciona la Optimización de Datos de Entrenamiento
La optimización de datos de entrenamiento funciona ajustando sistemáticamente los parámetros internos de un modelo mediante la exposición a conjuntos de datos curados y específicos del dominio durante el proceso de fine-tuning. Cuando un modelo se encuentra repetidamente con ejemplos de entrenamiento, internaliza gradualmente patrones, terminología y experiencia de dominio mediante backpropagation y actualizaciones de gradiente que remodelan los mecanismos de aprendizaje del modelo. Este proceso permite a las organizaciones codificar conocimiento especializado—ya sea terminología médica, marcos legales o lógica empresarial propietaria—directamente en los pesos y sesgos del modelo. El modelo resultante se vuelve altamente especializado para su dominio objetivo, logrando con frecuencia un rendimiento comparable al de modelos mucho más grandes; investigaciones de Snorkel AI demostraron que modelos pequeños fine-tuned pueden rendir de forma equivalente a modelos 1,400 veces más grandes. Las características clave de la optimización de datos de entrenamiento incluyen:
Integración permanente del conocimiento: Una vez entrenado, el conocimiento pasa a formar parte del modelo y no requiere consultas externas
Latencia reducida en la inferencia: Sin sobrecarga de recuperación durante la predicción, permitiendo respuestas más rápidas
Estilo y formato consistentes: Los modelos aprenden patrones de comunicación y convenciones específicos del dominio
Capacidad de operación offline: Los modelos funcionan de manera independiente sin fuentes de datos externas
Alto costo computacional inicial: Requiere importantes recursos de GPU y preparación de datos de entrenamiento etiquetados
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
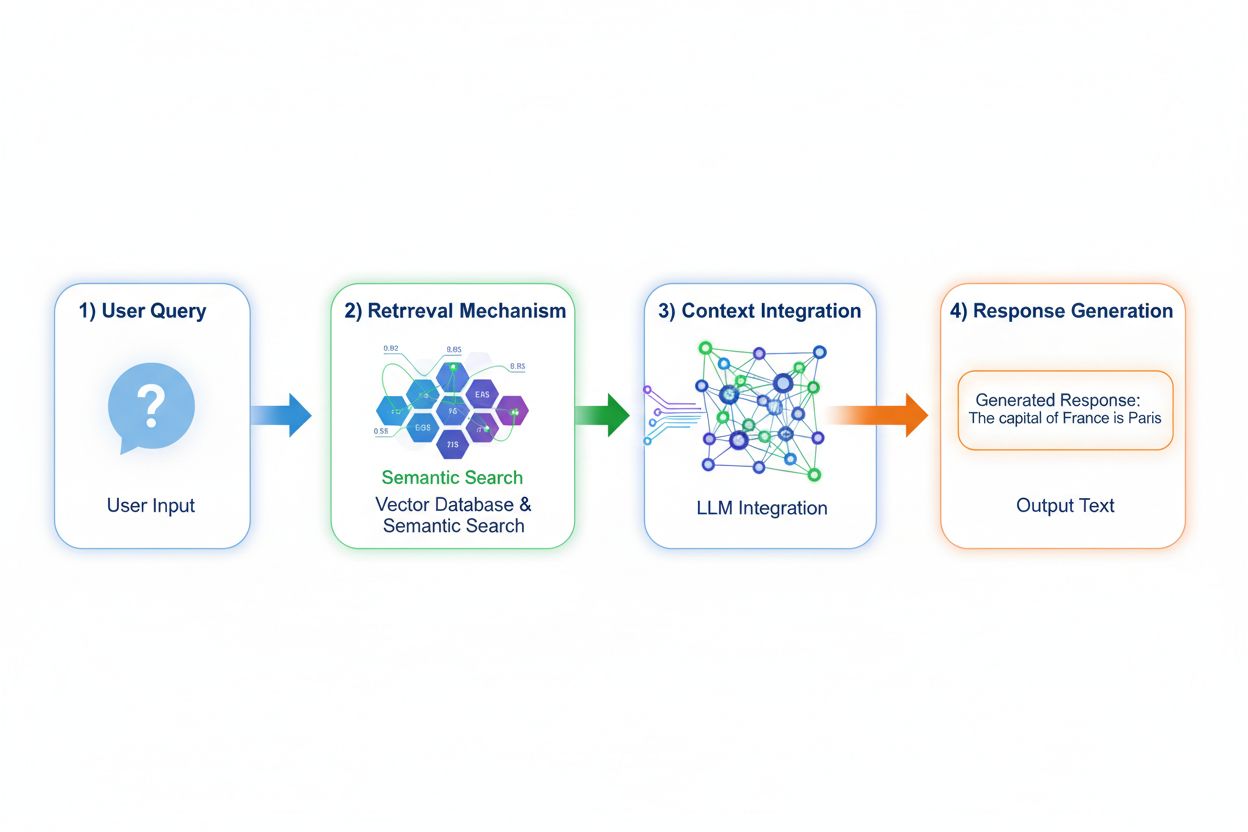
La Generación Aumentada con Recuperación (RAG) cambia fundamentalmente la forma en que los modelos acceden al conocimiento implementando un proceso de cuatro etapas: codificación de consulta, búsqueda semántica, clasificación de contexto y generación con fundamentación. Cuando un usuario envía una consulta, RAG primero la convierte en una representación vectorial densa usando modelos de embedding, luego busca en una base de datos vectorial que contiene documentos indexados o fuentes de conocimiento. La etapa de recuperación utiliza búsqueda semántica para encontrar pasajes contextualmente relevantes en lugar de simples coincidencias de palabras clave, clasificando los resultados por puntajes de relevancia. Finalmente, el modelo genera respuestas manteniendo referencias explícitas a las fuentes recuperadas, fundamentando su output en datos reales en vez de parámetros aprendidos. Esta arquitectura permite a los modelos acceder a información que no existía durante el entrenamiento, haciendo que RAG sea especialmente valioso para aplicaciones que requieren información actual, datos propietarios o bases de conocimiento frecuentemente actualizadas. El mecanismo RAG transforma esencialmente el modelo de un repositorio de conocimiento estático en un sintetizador de información dinámica que puede incorporar nuevos datos sin reentrenamiento.
Comparación de Rendimiento y Precisión
Los perfiles de precisión y alucinación de estos enfoques difieren significativamente en formas que afectan el despliegue en el mundo real. La optimización de datos de entrenamiento produce modelos con profundo entendimiento de dominio pero capacidad limitada para reconocer los límites de su conocimiento; cuando un modelo fine-tuned se encuentra con preguntas fuera de su distribución de entrenamiento, puede generar con confianza información plausible pero incorrecta. RAG reduce sustancialmente las alucinaciones al fundamentar las respuestas en documentos recuperados—el modelo no puede afirmar información que no aparece en su material fuente, creando límites naturales a la invención. Sin embargo, RAG introduce otros riesgos de precisión: si la etapa de recuperación no encuentra fuentes relevantes o clasifica documentos irrelevantes en alto, el modelo genera respuestas basadas en un contexto deficiente. La actualidad de los datos se vuelve crítica para los sistemas RAG; la optimización de datos de entrenamiento captura una instantánea estática del conocimiento en el momento del entrenamiento, mientras que RAG refleja continuamente el estado actual de los documentos fuente. La atribución de fuentes es otra diferencia: RAG habilita intrínsecamente la citación y verificación de afirmaciones, mientras que los modelos fine-tuned no pueden señalar fuentes específicas para su conocimiento, lo que complica la verificación de hechos y el cumplimiento.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Implicaciones de Costos e Infraestructura
Los perfiles económicos de estos enfoques crean estructuras de costos distintas que las organizaciones deben evaluar cuidadosamente. La optimización de datos de entrenamiento requiere un costo computacional significativo al principio: clústeres de GPU funcionando durante días o semanas para el fine-tuning, servicios de anotación de datos para crear conjuntos de datos de entrenamiento etiquetados y experiencia en ingeniería de ML para diseñar pipelines de entrenamiento efectivos. Una vez entrenado, el costo de servir el modelo es relativamente bajo ya que la inferencia sólo requiere infraestructura estándar de despliegue del modelo sin consultas externas. Los sistemas RAG invierten esta estructura de costos: menores costos iniciales de entrenamiento ya que no se realiza fine-tuning, pero gastos de infraestructura continuos para mantener bases de datos vectoriales, modelos de embedding, servicios de recuperación y pipelines de indexación de documentos. Los factores clave de costo incluyen:
Fine-tuning: Horas de GPU ($10,000-$100,000+ por modelo), anotación de datos ($0.50-$5 por ejemplo), tiempo de ingeniería
Infraestructura RAG: Licencias de bases de datos vectoriales, servicio de modelos de embedding, almacenamiento e indexación de documentos, optimización de latencia de recuperación
Escalabilidad: Los modelos fine-tuned escalan linealmente con el volumen de inferencias; los sistemas RAG escalan tanto con el volumen de inferencias como con el tamaño de la base de conocimiento
Mantenimiento: El fine-tuning requiere reentrenamiento periódico; RAG exige actualizaciones continuas de documentos y mantenimiento del índice
Consideraciones de Seguridad y Cumplimiento
Las implicaciones de seguridad y cumplimiento divergen sustancialmente entre estos enfoques, afectando a organizaciones en industrias reguladas. Los modelos fine-tuned crean desafíos de protección de datos porque los datos de entrenamiento quedan embebidos en los pesos del modelo; extraer o auditar el conocimiento que contiene el modelo requiere técnicas sofisticadas y surgen preocupaciones de privacidad cuando datos sensibles de entrenamiento influyen en el comportamiento del modelo. El cumplimiento de regulaciones como GDPR se vuelve complejo porque el modelo efectivamente “recuerda” datos de entrenamiento de formas que resisten su eliminación o modificación. Los sistemas RAG ofrecen perfiles de seguridad diferentes: el conocimiento permanece en fuentes de datos externas y auditables en vez de en los parámetros del modelo, permitiendo controles de seguridad y restricciones de acceso directas. Las organizaciones pueden implementar permisos detallados sobre las fuentes de recuperación, auditar qué documentos accedió el modelo para cada respuesta y eliminar rápidamente información sensible actualizando los documentos fuente sin reentrenar. Sin embargo, RAG introduce riesgos de seguridad relacionados con la protección de la base de datos vectorial, la seguridad del modelo de embedding y la garantía de que los documentos recuperados no filtren información sensible. Las organizaciones de salud reguladas por HIPAA y empresas europeas sujetas a GDPR suelen preferir la transparencia y auditabilidad de RAG, mientras que las organizaciones que priorizan la portabilidad del modelo y la operación offline prefieren el enfoque auto-contenido del fine-tuning.
Marco de Decisión Práctico
Seleccionar entre estos enfoques requiere evaluar restricciones organizacionales específicas y características del caso de uso. Las organizaciones deben priorizar el fine-tuning cuando el conocimiento es estable y es poco probable que cambie con frecuencia, cuando la latencia de inferencia es crítica, cuando los modelos deben operar offline o en entornos aislados, o cuando son esenciales el estilo consistente y el formato específico de dominio. La recuperación en tiempo real es preferible cuando el conocimiento cambia regularmente, cuando la atribución de fuentes y la auditabilidad son importantes para el cumplimiento, cuando la base de conocimiento es demasiado grande para codificarse eficientemente en los parámetros del modelo, o cuando las organizaciones necesitan actualizar información sin reentrenar el modelo. Casos de uso específicos que ilustran estas distinciones:
Fine-tuning: Bots de atención al cliente para información de productos estable, asistentes médicos especializados en diagnóstico, análisis de documentos legales para jurisprudencia establecida
RAG: Sistemas de resumen de noticias que requieren eventos actuales, soporte al cliente con catálogos de productos que se actualizan frecuentemente, asistentes de investigación que acceden a literatura científica dinámica
Marco de decisión: Evaluar estabilidad del conocimiento, requisitos de cumplimiento, restricciones de latencia, frecuencia de actualización y capacidades de infraestructura
Enfoques Híbridos y Estrategias Combinadas
Los enfoques híbridos combinan fine-tuning y RAG para capturar los beneficios de ambas estrategias y mitigar sus limitaciones individuales. Las organizaciones pueden ajustar modelos en fundamentos de dominio y patrones de comunicación mientras usan RAG para acceder a información actual y detallada—el modelo aprende cómo pensar sobre un dominio mientras recupera qué hechos específicos incorporar. Esta estrategia combinada resulta especialmente efectiva para aplicaciones que requieren tanto experiencia especializada como información actual: un bot asesor financiero fine-tuned en principios de inversión y terminología puede recuperar datos de mercado en tiempo real y estados financieros empresariales a través de RAG. Implementaciones híbridas en el mundo real incluyen sistemas de salud que hacen fine-tuning en conocimiento médico y protocolos mientras recuperan datos específicos del paciente mediante RAG, y plataformas de investigación legal que hacen fine-tuning en razonamiento jurídico mientras recuperan jurisprudencia actual. Los beneficios sinérgicos incluyen reducción de alucinaciones (por el fundamento en fuentes recuperadas), mejor comprensión de dominio (por el fine-tuning), inferencia más rápida en consultas comunes (conocimiento fine-tuned cacheado) y flexibilidad para actualizar información especializada sin reentrenar. Cada vez más, las organizaciones adoptan este enfoque de optimización a medida que los recursos computacionales se vuelven más accesibles y la complejidad de las aplicaciones reales demanda tanto profundidad como actualidad.
Monitoreo de Respuestas de IA y Seguimiento de Citas
La capacidad de monitorear respuestas de IA en tiempo real es cada vez más crítica a medida que las organizaciones implementan estas estrategias de optimización a escala, especialmente para entender qué enfoque da mejores resultados para casos de uso específicos. Los sistemas de monitoreo de IA rastrean las salidas del modelo, la calidad de recuperación y las métricas de satisfacción del usuario, permitiendo a las organizaciones medir si los modelos fine-tuned o los sistemas RAG sirven mejor a sus aplicaciones. El seguimiento de citas revela diferencias cruciales entre enfoques: los sistemas RAG generan naturalmente citas y referencias de fuentes, creando una pista de auditoría de qué documentos influyeron en cada respuesta, mientras que los modelos fine-tuned no proporcionan un mecanismo inherente de monitoreo de respuestas o atribución. Esta distinción es relevante para la seguridad de marca y la inteligencia competitiva—las organizaciones necesitan entender cómo los sistemas de IA citan a sus competidores, referencian sus productos o atribuyen información a sus fuentes. Herramientas como AmICited.com abordan esta necesidad monitoreando cómo los sistemas de IA citan marcas y empresas en diferentes estrategias de optimización, proporcionando un seguimiento en tiempo real de patrones y frecuencia de citas. Al implementar un monitoreo integral, las organizaciones pueden medir si su estrategia de optimización elegida (fine-tuning, RAG o híbrida) realmente mejora la precisión de las citas, reduce alucinaciones sobre competidores y mantiene la atribución adecuada a fuentes autorizadas. Este enfoque orientado a datos para el monitoreo permite la mejora continua de las estrategias de optimización basándose en el rendimiento real y no en expectativas teóricas.
Tendencias Futuras y Patrones Emergentes
La industria está evolucionando hacia enfoques híbridos y adaptativos más sofisticados que seleccionan dinámicamente entre estrategias de optimización según las características de la consulta y los requisitos de conocimiento. Las mejores prácticas emergentes incluyen la implementación de fine-tuning aumentado con recuperación, donde los modelos se ajustan sobre cómo usar eficazmente la información recuperada en vez de memorizar hechos, y sistemas de enrutamiento adaptativo que dirigen consultas a modelos fine-tuned para conocimiento estable y a sistemas RAG para información dinámica. Las tendencias indican una creciente adopción de modelos de embedding y bases de datos vectoriales especializadas optimizadas para dominios concretos, permitiendo búsquedas semánticas más precisas y reduciendo el ruido en la recuperación. Las organizaciones están desarrollando patrones de mejora continua del modelo que combinan actualizaciones periódicas de fine-tuning con aumento en tiempo real mediante RAG, creando sistemas que mejoran con el tiempo y mantienen acceso a información actual. La evolución de las estrategias de optimización refleja un reconocimiento generalizado en la industria de que ningún enfoque único sirve óptimamente a todos los casos de uso; es probable que los sistemas futuros implementen mecanismos inteligentes de selección que elijan entre fine-tuning, RAG y enfoques híbridos de manera dinámica según el contexto de la consulta, la estabilidad del conocimiento, los requisitos de latencia y las restricciones de cumplimiento. A medida que estas tecnologías maduren, la ventaja competitiva se desplazará de elegir un solo enfoque a implementar experta y adaptativamente sistemas que aprovechen las fortalezas de cada estrategia.
Preguntas frecuentes
¿Cuál es la principal diferencia entre la optimización de datos de entrenamiento y la recuperación en tiempo real?
La optimización de datos de entrenamiento incorpora el conocimiento directamente en los parámetros del modelo mediante fine-tuning, creando conocimiento estático que permanece fijo después del entrenamiento. La recuperación en tiempo real mantiene el conocimiento externo y recupera información relevante dinámicamente durante la inferencia, lo que permite acceder a información dinámica que puede cambiar entre solicitudes. La distinción clave es cuándo se integra el conocimiento: la optimización de datos de entrenamiento ocurre antes del despliegue, mientras que la recuperación en tiempo real ocurre durante cada llamada de inferencia.
¿Cuándo debería usar fine-tuning en lugar de RAG?
Utiliza fine-tuning cuando el conocimiento es estable y es poco probable que cambie con frecuencia, cuando la latencia de inferencia es crítica, cuando los modelos deben operar sin conexión o cuando son esenciales el estilo consistente y el formato específico de dominio. El fine-tuning es ideal para tareas especializadas como diagnóstico médico, análisis de documentos legales o atención al cliente con información de productos estable. Sin embargo, el fine-tuning requiere importantes recursos computacionales iniciales y resulta poco práctico cuando la información cambia con frecuencia.
¿Puedo combinar la optimización de datos de entrenamiento con la recuperación en tiempo real?
Sí, los enfoques híbridos combinan fine-tuning y RAG para capturar los beneficios de ambas estrategias. Las organizaciones pueden ajustar modelos sobre fundamentos del dominio mientras utilizan RAG para acceder a información actual y detallada. Este enfoque es especialmente efectivo para aplicaciones que requieren tanto experiencia especializada como información actual, como bots de asesoría financiera o sistemas de salud que necesitan tanto conocimiento médico como datos específicos del paciente.
¿Cómo reduce RAG las alucinaciones en comparación con el fine-tuning?
RAG reduce sustancialmente las alucinaciones al fundamentar las respuestas en documentos recuperados: el modelo no puede afirmar información que no aparece en su material fuente, creando limitaciones naturales a la invención. Los modelos fine-tuned, por el contrario, pueden generar con confianza información plausible pero incorrecta cuando enfrentan preguntas fuera de su distribución de entrenamiento. La atribución de fuentes en RAG también permite la verificación de afirmaciones, mientras que los modelos fine-tuned no pueden señalar fuentes específicas para su conocimiento.
¿Cuáles son las implicaciones de costos de cada enfoque?
El fine-tuning requiere costos iniciales considerables: horas de GPU ($10,000-$100,000+ por modelo), anotación de datos ($0.50-$5 por ejemplo) y tiempo de ingeniería. Una vez entrenados, los costos de servicio permanecen relativamente bajos. Los sistemas RAG tienen menores costos iniciales pero gastos continuos de infraestructura para bases de datos vectoriales, modelos de embedding y servicios de recuperación. Los modelos fine-tuned escalan linealmente con el volumen de inferencias, mientras que los sistemas RAG escalan tanto con el volumen de inferencias como con el tamaño de la base de conocimiento.
¿Cómo ayuda la recuperación en tiempo real al seguimiento de citas de IA?
Los sistemas RAG generan naturalmente citas y referencias de fuentes, creando una pista de auditoría de qué documentos influyeron en cada respuesta. Esto es crucial para la seguridad de marca e inteligencia competitiva: las organizaciones pueden rastrear cómo los sistemas de IA citan a sus competidores y referencian sus productos. Herramientas como AmICited.com monitorean cómo los sistemas de IA citan marcas en diferentes estrategias de optimización, proporcionando seguimiento en tiempo real de patrones y frecuencia de citas.
¿Qué enfoque es mejor para industrias altamente reguladas?
RAG es generalmente mejor para industrias con alta regulación como salud y finanzas. El conocimiento permanece en fuentes de datos externas y auditables en lugar de en los parámetros del modelo, lo que permite controles de seguridad y restricciones de acceso directas. Las organizaciones pueden implementar permisos detallados, auditar qué documentos accedió el modelo y eliminar rápidamente información sensible sin reentrenar. Organizaciones sujetas a HIPAA o GDPR suelen preferir la transparencia y auditabilidad de RAG.
¿Cómo monitoreo la efectividad de mi estrategia de optimización elegida?
Implementa sistemas de monitoreo de IA que rastreen las salidas del modelo, la calidad de recuperación y métricas de satisfacción del usuario. Para sistemas RAG, monitorea la precisión de la recuperación y la calidad de las citas. Para modelos fine-tuned, rastrea la precisión en tareas específicas de dominio y tasas de alucinaciones. Utiliza herramientas como AmICited.com para monitorear cómo tus sistemas de IA citan información y comparar el rendimiento entre diferentes estrategias de optimización basadas en resultados reales.
Monitorea cómo los sistemas de IA citan tu marca
Rastrea citas en tiempo real a través de GPTs, Perplexity y Google AI Overviews. Comprende qué estrategias de optimización están usando tus competidores y cómo son referenciados en las respuestas de IA.
Datos de Entrenamiento vs Búsqueda en Vivo: Cómo los Sistemas de IA Acceden a la Información
Comprende la diferencia entre los datos de entrenamiento de IA y la búsqueda en vivo. Descubre cómo los límites de conocimiento, RAG y la recuperación en tiempo...
Descubre la adaptación de IA en tiempo real: la tecnología que permite a los sistemas de IA aprender continuamente de los acontecimientos actuales y los datos. ...
Cómo Optimizar tu Contenido para los Datos de Entrenamiento de IA y Motores de Búsqueda de IA
Aprende cómo optimizar tu contenido para la inclusión en los datos de entrenamiento de IA. Descubre las mejores prácticas para hacer que tu sitio web sea visibl...
11 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.