
¿Qué son los embeddings en la búsqueda con IA?
Aprende cómo funcionan los embeddings en motores de búsqueda con IA y modelos de lenguaje. Comprende las representaciones vectoriales, la búsqueda semántica y s...
10 min de lectura

Descubre cómo las incrustaciones vectoriales permiten que los sistemas de IA comprendan el significado semántico y relacionen el contenido con las consultas. Explora la tecnología detrás de la búsqueda semántica y la coincidencia de contenido mediante IA.

Las incrustaciones vectoriales son la base numérica que impulsa los sistemas modernos de inteligencia artificial, transformando datos sin procesar en representaciones matemáticas que las máquinas pueden comprender y procesar. En esencia, las incrustaciones convierten texto, imágenes, audio y otros tipos de contenido en arreglos de números—normalmente que van de docenas a miles de dimensiones—que capturan el significado semántico y las relaciones contextuales dentro de esos datos. Esta representación numérica es fundamental para que los sistemas de IA realicen tareas de coincidencia de contenido, búsqueda semántica y recomendación, permitiendo que las máquinas comprendan no solo qué palabras o imágenes están presentes, sino qué significan realmente. Sin incrustaciones, los sistemas de IA tendrían dificultades para captar las relaciones sutiles entre conceptos, por lo que son infraestructura esencial para cualquier aplicación de IA moderna.
La transformación de datos sin procesar a incrustaciones vectoriales se logra mediante sofisticados modelos de redes neuronales entrenados con enormes conjuntos de datos para aprender patrones y relaciones significativas. Cuando introduces texto en un modelo de incrustación, pasa por múltiples capas de redes neuronales que extraen progresivamente la información semántica, produciendo finalmente un vector de tamaño fijo que representa la esencia de ese contenido. Modelos populares de incrustación como Word2Vec, GloVE y BERT adoptan diferentes enfoques—Word2Vec utiliza redes neuronales superficiales optimizadas para la velocidad, GloVE combina factorización global de matrices con ventanas de contexto local, mientras que BERT aprovecha la arquitectura de transformadores para entender el contexto bidireccional.
| Modelo | Tipo de dato | Dimensiones | Uso principal | Ventaja clave |
|---|---|---|---|---|
| Word2Vec | Texto (palabras) | 100-300 | Relaciones entre palabras | Rápido, eficiente |
| GloVE | Texto (palabras) | 100-300 | Relaciones semánticas | Combina contexto global y local |
| BERT | Texto (frases/docs) | 768-1024 | Comprensión contextual | Conciencia de contexto bidireccional |
| Sentence-BERT | Texto (frases) | 384-768 | Similitud de frases | Optimizado para búsqueda semántica |
| Universal Sentence Encoder | Texto (frases) | 512 | Tareas multilingües | Independiente del idioma |
Estos modelos producen vectores de alta dimensión (a menudo de 300 a 1,536 dimensiones), donde cada dimensión captura diferentes aspectos del significado, desde propiedades gramaticales hasta relaciones conceptuales. Lo valioso de esta representación numérica es que permite operaciones matemáticas—puedes sumar, restar y comparar vectores para descubrir relaciones que serían invisibles en texto sin procesar. Esta base matemática es lo que hace posible la búsqueda semántica y la coincidencia inteligente de contenido a gran escala.
El verdadero poder de las incrustaciones surge a través de la similitud semántica, la capacidad de reconocer que diferentes palabras o frases pueden significar esencialmente lo mismo en el espacio vectorial. Cuando las incrustaciones se crean eficazmente, conceptos semánticamente similares se agrupan naturalmente en el espacio de alta dimensión—“rey” y “reina” están cerca, al igual que “coche” y “vehículo”, aunque sean palabras distintas. Para medir esta similitud, los sistemas de IA usan métricas de distancia como la similitud coseno (que mide el ángulo entre vectores) o el producto punto (que mide magnitud y dirección), que cuantifican cuán cerca están dos incrustaciones entre sí. Por ejemplo, una consulta sobre “transporte automovilístico” tendrá alta similitud coseno con documentos sobre “viaje en coche”, permitiendo que el sistema relacione contenido según el significado y no solo por coincidencia exacta de palabras clave. Esta comprensión semántica es lo que diferencia la búsqueda moderna por IA de la simple coincidencia por palabras clave, permitiendo a los sistemas entender la intención del usuario y ofrecer resultados realmente relevantes.
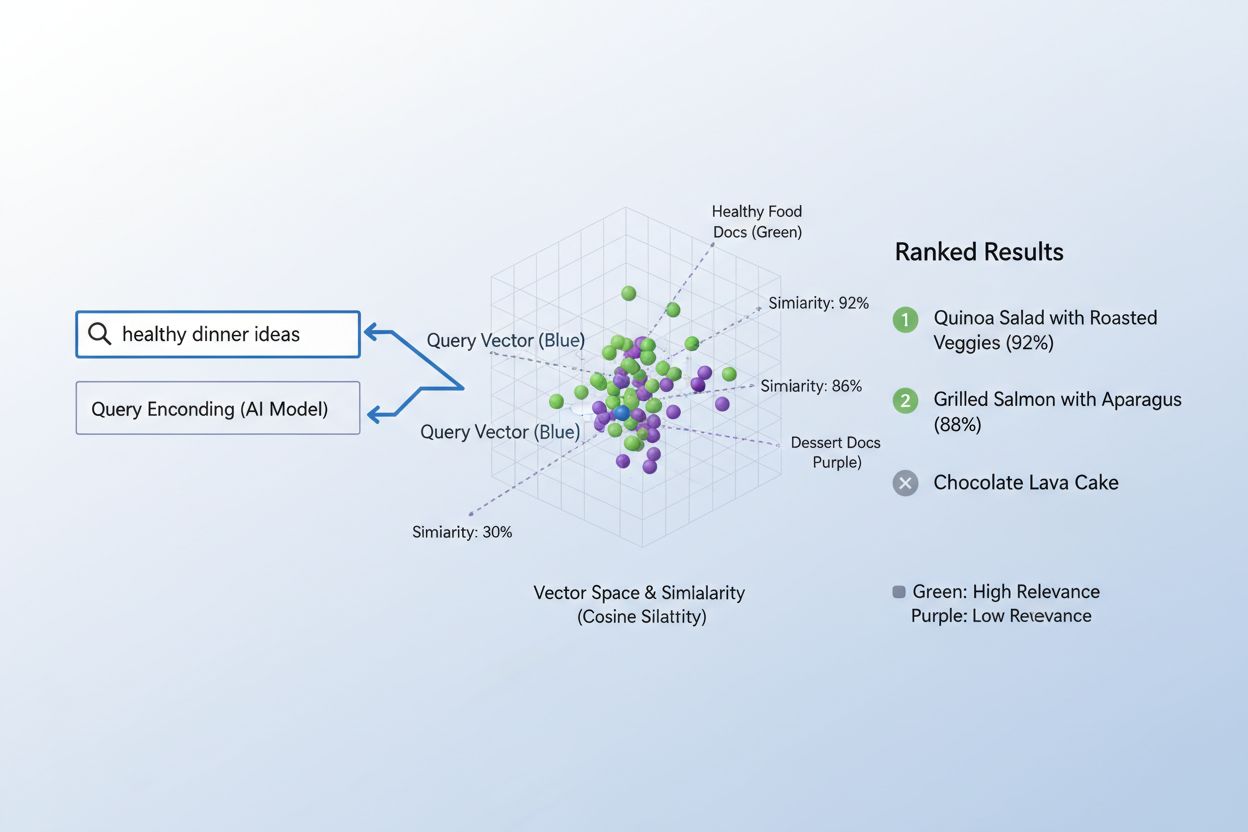
El proceso de relacionar contenido con consultas usando incrustaciones sigue un flujo de trabajo elegante en dos pasos que impulsa desde motores de búsqueda hasta sistemas de recomendación. Primero, tanto la consulta del usuario como el contenido disponible se convierten de manera independiente en incrustaciones utilizando el mismo modelo—una consulta como “mejores prácticas para aprendizaje automático” se convierte en un vector, al igual que cada artículo, documento o producto en la base de datos del sistema. Luego, el sistema calcula la similitud entre la incrustación de la consulta y cada incrustación de contenido, normalmente usando similitud coseno, que produce una puntuación indicando cuán relevante es cada pieza de contenido respecto a la consulta. Estas puntuaciones de similitud se ordenan, mostrando al usuario el contenido mejor puntuado como los resultados más relevantes. En un motor de búsqueda real, cuando buscas “cómo entrenar redes neuronales”, el sistema codifica tu consulta, la compara contra millones de incrustaciones de documentos y te devuelve artículos sobre aprendizaje profundo, optimización de modelos y técnicas de entrenamiento—todo sin requerir coincidencias exactas de palabras clave. Este proceso de coincidencia ocurre en milisegundos, lo que lo hace práctico para aplicaciones en tiempo real que atienden a millones de usuarios simultáneamente.
Diferentes tipos de incrustaciones cumplen distintos propósitos según lo que quieras relacionar o comprender. Las incrustaciones de palabras capturan el significado de palabras individuales y funcionan bien para tareas que requieren comprensión semántica detallada, mientras que incrustaciones de frases e incrustaciones de documentos agregan significado a través de fragmentos de texto más largos, siendo ideales para relacionar consultas completas con artículos o documentos enteros. Las incrustaciones de imágenes representan contenido visual en forma numérica, permitiendo que los sistemas encuentren imágenes visualmente similares o relacionen imágenes con descripciones de texto, mientras que incrustaciones de usuario e incrustaciones de producto capturan patrones de comportamiento y características, potenciando sistemas de recomendación que sugieren elementos basados en las preferencias del usuario. La elección entre estos tipos de incrustaciones implica compensaciones: las de palabras son computacionalmente eficientes pero pierden contexto, mientras que las de documento preservan el significado completo pero requieren más poder de procesamiento. Las incrustaciones específicas de dominio, ajustadas con conjuntos de datos especializados como literatura médica o documentos legales, suelen superar a los modelos de uso general para aplicaciones en industrias concretas, aunque requieren datos de entrenamiento adicionales y más recursos computacionales.
En la práctica, las incrustaciones potencian algunas de las aplicaciones de IA más impactantes que usamos a diario, desde los resultados de búsqueda que ves hasta los productos que te recomiendan en línea. Los motores de búsqueda semántica usan incrustaciones para entender la intención de la consulta y mostrar contenido relevante sin importar coincidencias exactas, mientras que los sistemas de recomendación en Netflix, Amazon y Spotify aprovechan incrustaciones de usuario y producto para predecir qué querrás ver, comprar o escuchar después. Los sistemas de moderación de contenido emplean incrustaciones para detectar contenido dañino comparando publicaciones de usuarios con incrustaciones de infracciones conocidas, mientras que sistemas de preguntas y respuestas relacionan preguntas de usuarios con artículos relevantes hallando contenido semánticamente similar. Motores de personalización usan incrustaciones para comprender preferencias de usuario y personalizar experiencias, y sistemas de detección de anomalías identifican patrones inusuales reconociendo cuándo nuevos datos se alejan de los clústeres esperados de incrustaciones. En AmICited, aprovechamos las incrustaciones para monitorear cómo se usan los sistemas de IA en internet, relacionando consultas y contenido para rastrear dónde aparece contenido generado o asistido por IA, ayudando a las marcas a comprender su huella en IA y asegurar la atribución adecuada.
Implementar correctamente las incrustaciones requiere prestar atención a varias consideraciones técnicas que impactan tanto el rendimiento como el costo. La selección del modelo es crítica: debes equilibrar la calidad semántica de las incrustaciones con los requisitos computacionales, ya que modelos más grandes como BERT producen representaciones más ricas pero requieren más procesamiento que alternativas ligeras. La dimensionalidad implica una compensación clave: incrustaciones de mayor dimensión capturan más matices pero consumen más memoria y ralentizan los cálculos de similitud, mientras que las de menor dimensión son más rápidas pero pueden perder información semántica importante. Para gestionar la coincidencia a gran escala de manera eficiente, los sistemas emplean estrategias de indexación especializadas como FAISS (Facebook AI Similarity Search) o Annoy (Approximate Nearest Neighbors Oh Yeah), que permiten encontrar incrustaciones similares en milisegundos en lugar de segundos, organizando los vectores en estructuras de árbol o esquemas de hash sensibles a la localidad. El ajuste fino de modelos de incrustación con datos de dominio puede mejorar notablemente la relevancia para aplicaciones especializadas, aunque requiere datos etiquetados y mayor carga computacional. Las organizaciones deben equilibrar continuamente velocidad versus precisión, costo computacional versus calidad semántica, y modelos de propósito general versus alternativas especializadas según sus casos de uso y restricciones.
El futuro de las incrustaciones apunta a mayor sofisticación, eficiencia e integración con sistemas de IA más amplios, prometiendo capacidades aún más poderosas de coincidencia y comprensión de contenido. Las incrustaciones multimodales que procesan simultáneamente texto, imágenes y audio ya están surgiendo, permitiendo a los sistemas relacionar entre distintos tipos de contenido—encontrando imágenes relevantes para consultas de texto o viceversa—y abriendo nuevas posibilidades para el descubrimiento y comprensión de contenido. Los investigadores están desarrollando modelos de incrustación cada vez más eficientes que ofrecen calidad semántica comparable con muchos menos parámetros, haciendo que capacidades avanzadas de IA sean accesibles para organizaciones pequeñas y dispositivos en el borde. La integración de incrustaciones con grandes modelos de lenguaje está creando sistemas capaces no solo de relacionar contenido semánticamente, sino también de entender contexto, matiz e intención a niveles sin precedentes. A medida que los sistemas de IA se vuelven más frecuentes en internet, la capacidad de rastrear, monitorear y comprender cómo se relaciona y utiliza el contenido cobra mayor importancia—aquí es donde plataformas como AmICited aprovechan las incrustaciones para ayudar a las organizaciones a monitorear la presencia de su marca, rastrear patrones de uso de IA y asegurar que su contenido sea correctamente atribuido y utilizado apropiadamente. La convergencia de mejores incrustaciones, modelos más eficientes y herramientas sofisticadas de monitoreo está creando un futuro en el que los sistemas de IA serán más transparentes, responsables y alineados con los valores humanos.
Una incrustación vectorial es una representación numérica de datos (texto, imágenes, audio) en un espacio de alta dimensión que captura significado semántico y relaciones. Convierte datos abstractos en arreglos de números que las máquinas pueden procesar y analizar matemáticamente.
Las incrustaciones convierten datos abstractos en números que las máquinas pueden procesar, permitiendo a la IA identificar patrones, similitudes y relaciones entre diferentes fragmentos de contenido. Esta representación matemática hace posible que los sistemas de IA comprendan el significado y no solo coincidan palabras clave.
La coincidencia por palabras clave busca coincidencias exactas, mientras que la similitud semántica comprende el significado. Esto permite a los sistemas encontrar contenido relacionado aunque no tenga palabras idénticas, por ejemplo, relacionando 'automóvil' con 'coche' en función de su relación semántica y no solo por coincidencia exacta de texto.
Sí, las incrustaciones pueden representar texto, imágenes, audio, perfiles de usuario, productos y más. Existen modelos de incrustación optimizados para diferentes tipos de datos, desde Word2Vec para texto hasta CNN para imágenes o espectrogramas para audio.
AmICited utiliza incrustaciones para comprender cómo los sistemas de IA relacionan y mencionan tu marca semánticamente a través de diferentes plataformas y respuestas de IA. Esto ayuda a rastrear la presencia de tu contenido en respuestas generadas por IA y garantizar la atribución adecuada.
Los desafíos clave incluyen elegir el modelo adecuado, gestionar los costos computacionales, manejar datos de alta dimensión, ajustar para dominios específicos y equilibrar velocidad versus precisión en los cálculos de similitud.
Las incrustaciones permiten la búsqueda semántica, que entiende la intención del usuario y devuelve resultados relevantes basados en significado y no solo en coincidencia de palabras clave. Esto permite que los sistemas encuentren contenido conceptualmente relacionado aunque no contenga los términos exactos de la consulta.
Los grandes modelos de lenguaje usan incrustaciones internamente para comprender y generar texto. Las incrustaciones son fundamentales para que estos modelos procesen información, relacionen contenido y generen respuestas contextualmente apropiadas.
Las incrustaciones vectoriales potencian sistemas de IA como ChatGPT, Perplexity y Google AI Overviews. AmICited rastrea cómo estos sistemas citan y hacen referencia a tu contenido, ayudándote a comprender la presencia de tu marca en respuestas generadas por IA.
Aprende cómo funcionan los embeddings en motores de búsqueda con IA y modelos de lenguaje. Comprende las representaciones vectoriales, la búsqueda semántica y s...
Aprende cómo la búsqueda vectorial utiliza embeddings de aprendizaje automático para encontrar elementos similares basándose en el significado en lugar de palab...

Aprende qué son los embeddings, cómo funcionan y por qué son esenciales para los sistemas de IA. Descubre cómo el texto se transforma en vectores numéricos que ...